논문 제목
MetaFormer Baselines for Vision (TPAMI 2024)
URL: https://arxiv.org/abs/2210.13452
Github : https://github.com/sail-sg/metaformer
인용수 : 256회 (25.7.1 기준)
본 논문은 아래 논문의 후속 연구논문입니다. 같이 읽어보시면 좋을 것 같습니다.
MetaFormer Is Actually What You Need for Vision(CVPR 2022 oral)
URL : https://arxiv.org/abs/2111.11418
Github : https://github.com/sail-sg/poolformer
인용수 : 1,377회 (25.7.1 기준)
Abstract
- MetaFormer는 Transformer의 추상화된 아키텍처로 경쟁력 있는 성능을 달성하는 데 중요한 역할을 함.
- 해당 연구는 토큰 믹서 설계에서 벗어나 가장 기본적인 믹서를 사용한 MetaFormer 기반 모델들(IdentityFormer, RandFormer, ConvFormer, CAFormer)의 성능이 우수함을 입증함.
- 기존 연구들에서 GELU를 사용했지만 본 논문에서는 StarReLU 활성화 함수를 제안하여 GELU 대비 FLOPs를 71% 줄이면서도 더 나은 성능을 제공했음.
Introduction
최근 몇 년 동안 Transformer 는 다양한 컴퓨터 비전 태스크에서 성능 개선을 보여줬음. Transformer의 역량은 오랫동안 어텐션 모듈(MHSA)의 영향으로 여겨져 왔다. 이에 따라 Vision Transformer(ViT)를 강화하기 위해 많은 어텐션기반의 토큰 믹서가 제안되었다. 그럼에도 불구하고 일부 연구 에서는 Transformer의 어텐션 모듈을 공간 MLP 또는 푸리에 변환 과 같은 간단한 연산자로 대체하더라도 결과 모델이 여전히 성능을 낸다는 것을 발견했음.
본 연구에서는 Transformer를 MetaFormer라고 불리는 일반적인 아키텍처로 추상화하고 모델이 경쟁력 있는 성능을 달성하는 데 필수적인 역할을 하는 것이 바로 MetaFormer라고 가정함. 이 가설을 검증하기 위해 토큰 믹서로 매우 간단한 연산자인 pooling을 채택했고, PoolFormer가 정교한 ResNet/ViT/MLP-like baseline의 성능을 능가한다는 것을 발견하여 MetaFormer의 중요성을 확인함.
(PoolFormer는 CVPR2022 연구에서 제안했던 모델임.)
Method
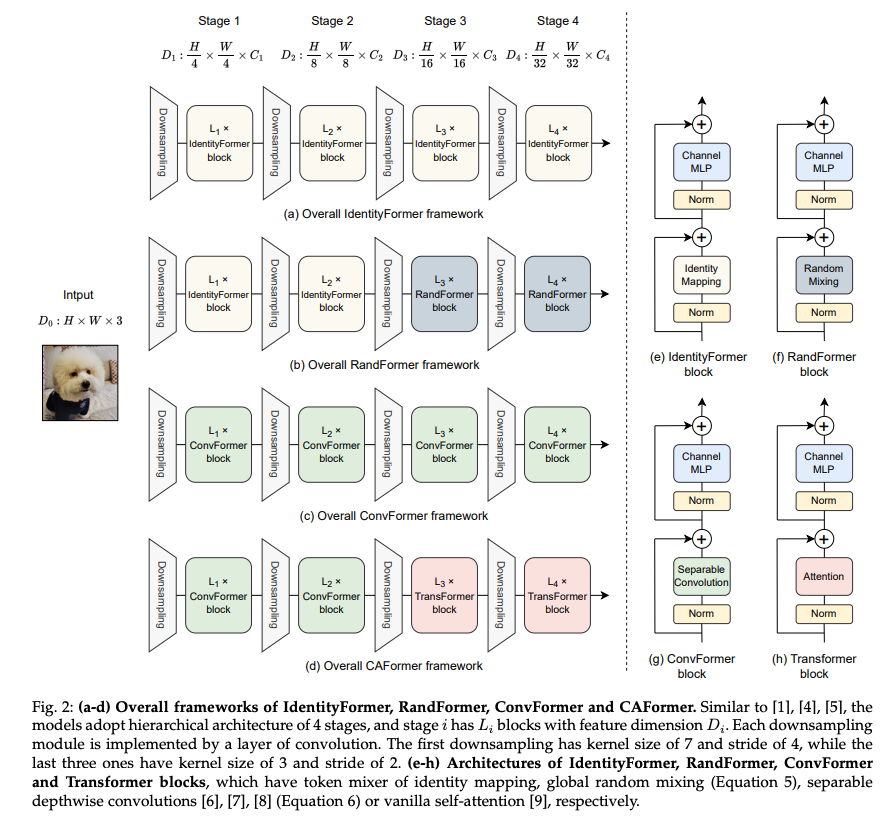
위 그림은 MetaFormer의 다양한 변형 모델의 구조입니다.
Recap the concept of MetaFormer
MetaFormer 개념은 특정 모델이 아닌 일반적인 아키텍처이며 토큰 믹서를 지정하지 않음으로써 Transformer에서 추상화된 구조임.
우선 입력은 특징(토큰) 시퀀스로 임베딩됨.
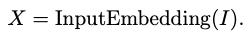
그다음 N과 채널 차원 C를 가진 토큰 시퀀스 가 반복되는 MetaFormer 블록에 입력됨. 블록 내 수식은 아래와 같이 정의될 수 있음.
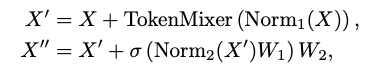
과 는 정규화이며 , 는주로 토큰 간의 정보 전파를 위한 토큰믹서를 의미함.
는 활성화 함수를 나타내며 과 는 채널 MLP의 학습 가능한 파라미터이다. 토큰 믹서를 구체적인 모듈로 지정함으로써 MetaFormer는 특정 모델로 인스턴스화된다.
논문에서는 총 4개의 인스턴스화된 MetaFormer 구조가 있다. (IdentityFormer, RandFormer, ConvFormer, CAFormer)
IdentityFormer and RandFormer
MetaFormer의 역량을 추가로 탐구하기 위해 본 논문에서는 토큰 믹서를 기본적인 연산자로 인스턴스화하고자 했다. 첫 번째로 고려한 것은 항등 매핑(identity mapping)임.

항등 매핑은 어떤 토큰 혼합도 수행하지 않으므로 실제로는 토큰 믹서로 간주될 수 없다. 편의상 여전히 이를 다른 토큰 믹서와 비교하기 위해 토큰 믹서의 한 유형으로 취급한다.
다른 기본 토큰 믹서는 global random mixing이다.
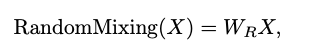
여기서 는 시퀀스 길이 N과 채널 차원 C를 가진 입력이며, 은 무작위 초기화 후 고정되는 행렬임. 이 토큰 믹서는 토큰 수에 이차적(quadratic)으로 비례하는 추가적인 고정 매개변수와 계산 비용을 초래하므로 많은 토큰 수에는 적합하지 않다.
ConvFormer and CAFormer
위에서는 기본 토큰 믹서를 사용하여 성능의 하한선과 토큰 믹서의 모델 보편성을 조사했다. 이 섹션에서는 새로운 토큰 믹서를 설계하지 않고, 일반적으로 사용되는 연산자로 토큰 믹서를 지정하여 최첨단 성능을 달성하기 위한 모델 잠재력을 조사한다. 우리가 선택한 첫 번째 토큰 믹서는 Depthwise Separable Convolution이다.
모듈은 MobileNetV2의 inverted separable convolution 모듈을 사용했다고 함.
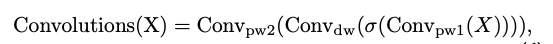
여기서 과 는 Pointwise Convolution이고, 는 Depthwise Convolution이며, 는 비선형 활성화 함수를 의미한다. 커널 크기를 7로 설정하고 expansion ratio를 2로 설정함.
컨볼루션 외에 또 다른 일반적인 토큰 믹서는 Transformer에 사용되는 Vanilla Self-Attention이다. 이 전역 연산자는 장거리 의존성을 포착하는 더 나은 능력을 가질 것으로 예상됨. 그러나 Self-Attention의 계산 복잡도가 토큰 수에 이차적(O(N^2))으로 비례하므로, 많은 토큰을 가진 첫 두 단계에서 바닐라 Self-Attention을 채택하는 것은 번거로울 것이다.
컨볼루션은 토큰 길이에 선형적인 계산 복잡도를 가진 지역 연산자임.
Techniques to improve MetaFormer
StarReLU
이 논문은 복잡한 토큰 믹서를 도입하지 않음. 대신 MetaFormer를 개선하기 위해 새로운 활성화 함수 StarReLU와 다른 두 가지 수정 사항을 도입.
Transformer에서는 ReLU가 활성화 함수로 선택되었으며, 다음과 같이 표현될 수 있음.
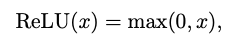
여기서 x는 입력의 임의의 신경 단위를 나타낸다. 이 활성화는 각 단위당 1 FLOP의 비용이 든다. 나중에 GPT는 GELU를 활성화 함수로 사용했으며, 이후 많은 Transformer 모델이 기본적으로 GELU를 사용함. GELU는 다음과 같이 근사될 수 있다.
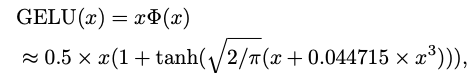
여기서 는 가우시안 분포의 누적 분포 함수(CDFGD)이다. ReLU보다 더 나은 성능을 보여주지만, GELU는 약 14 FLOPs의 비용을 가져 ReLU의 1 FLOP보다 훨씬 크다.
GELU를 단순화하기 위해, 는 CDFGD를 ReLU로 대체할 수 있음을 발견했음.(SquaredReLU 연구)
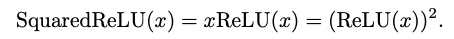
각 입력 단위당 2 FLOPs의 비용만 든다. Squared ReLU의 단순성에도 불구하고, 우리는 이미지 분류 작업에서 일부 모델에 대해 GELU의 성능을 따라잡지 못한다는 것을 발견했음.
본 논문에서는 성능 저하의 이유를 출력의 distribution shift로 인해 발생할 수 있다고 가정함.
x가 평균 0 분산 1의 정규 분포를 따를 때(일 때) 다음을 얻는다.
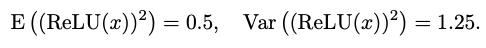

위 활성화함수를 곱셈(*)이 많이 사용되기 때문에 StarReLU라고 명명했다고함.
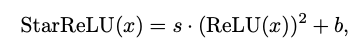
여기서 와 는 각각 스케일과 바이어스를 나타내는 스칼라로, 모든 채널에 공유되며 다른 StarReLU 변형을 얻기 위해 상수 또는 학습 가능하게 설정할 수 있다.
StarReLU는 4 FLOPs(s 또는 b만 있으면 3 FLOPs)만 비용이 들며, GELU의 14 FLOPs보다 훨씬 적지만 더 나은 성능을 달성했다고함.
Other modifications
Scaling branch output
Transformer 모델 크기를 깊이에서 확장하기 위해 출력을 학습 가능한 벡터로 곱하는 LayerScale라는 방법론이 있음.
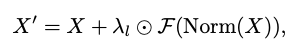
여기서 는 시퀀스 길이 N과 채널 차원 C를 가진 입력 특징을 나타내며, 는 정규화이고, 는 토큰 믹서 또는 채널 MLP 모듈을 의미하며, 는 1e−5와 같은 작은 값으로 초기화된 학습 가능한 LayerScale 매개변수를 나타내고, ⊙는 요소별 곱셈을 의미한다.
LayerScale과 유사하게 다른 연구에서는 ResScale을 사용하여 아키텍처를 안정화하려고 시도했음.
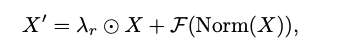
여기서 는 1로 초기화된 학습 가능한 매개변수를 나타낸다. 명백히, 위 두 가지 기술을 모든 브랜치를 스케일링하여 BranchScale로 명명.
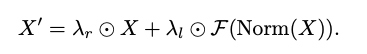
이 세 가지 스케일링 기술에 대한 비교 실험을 진행하였고 ResScale이 가장 좋은 성능을 보인다는 것을 발견함. 따라서 이 논문에서는 기본적으로 ResScale을 채택.
Disabling biases
MetaFormer 블록의 fully-connected 층, 컨볼루션 (있는 경우), 그리고 정규화의 바이어스를 비활성화함. 이는 성능을 저하시키지 않고 Ablation Study에서 보여진 특정 모델에 대해 약간의 개선을 가져올 수 있음을 발견했다고함.
단순화를 위해 기본적으로 MetaFormer 블록의 바이어스를 비활성화함.
Experiments
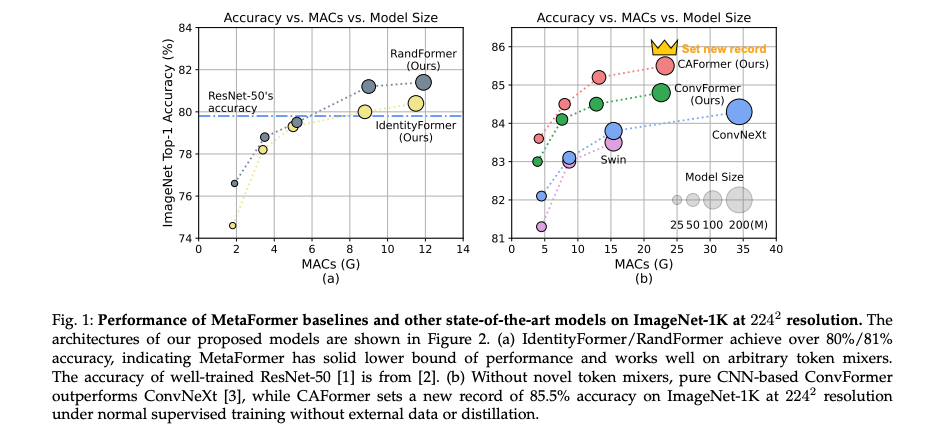
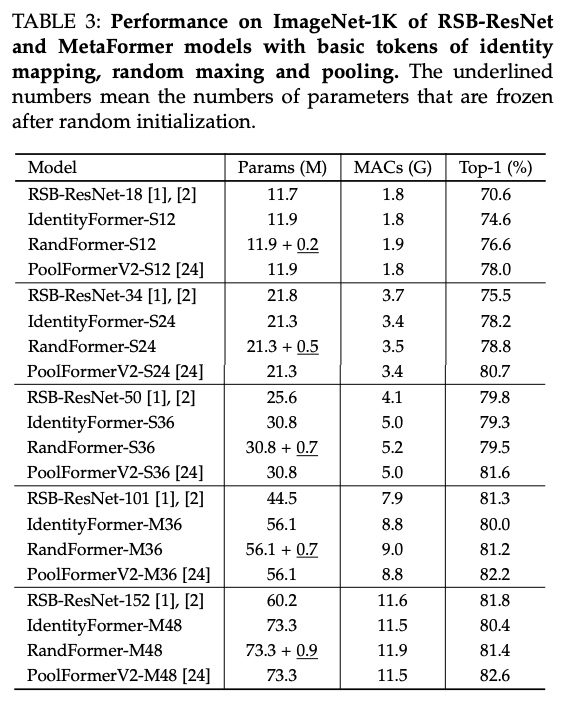
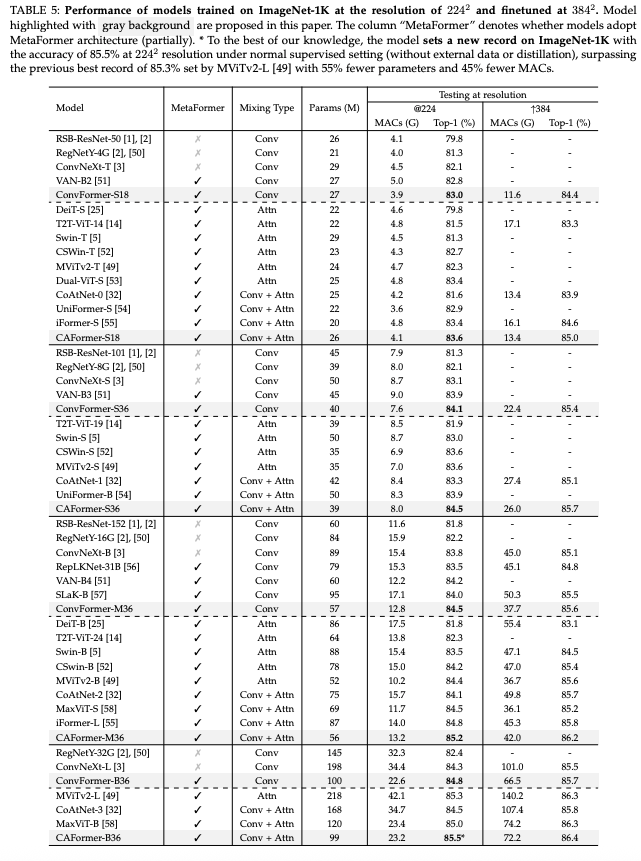
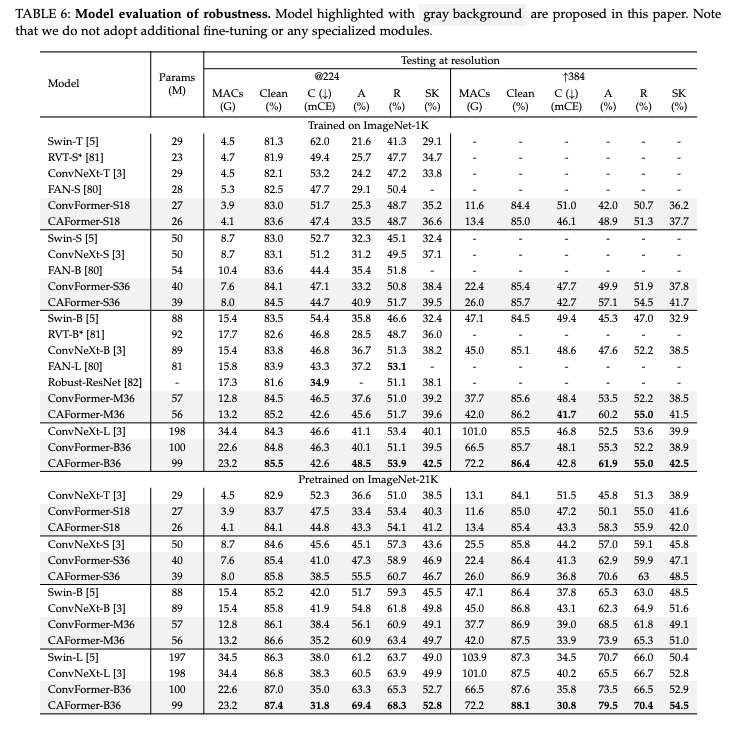
이미지넷에 대한 비교 실험 결과는 아래 이미지와 같다.
Transformer구조에 컨볼루션을 활용한 구조인 ConvNeXt, Swin Transformer 등 우수한 모델들보다 우수한 성능을 보였다.
Ablation
이 논문은 새로운 토큰 믹서를 설계하지 않고 MetaFormer에 세 가지 기술을 활용한다.
사용 모델은 ImageNet-1K의 ConvFormer-S18 및 CAFormer-S18을 기준선으로 사용했다고함.

StarReLU가 ReLU로 대체될 때, ConvFormer-S18/CAFormer의 성능은 각각 83.0%/83.6%에서 82.1%/82.9%로 크게 감소함.
StarReLU는 GELU에 비해 활성화 FLOPs를 71% 감소시킬 뿐만 아니라, ConvFormer-S18/CAFormer-S18에서 각각 0.3%/0.2% 정확도 향상으로 더 나은 성능을 달성한다. 이 결과는 MetaFormer와 유사한 모델 및 기타 신경망에서 StarReLU의 유망한 적용 가능성을 보여준다.
브랜치 스케일링 중에서는 ResScale이 가장 좋은 성능을 보였다. 각 블록에서 바이어스를 비활성화하는 것은 ConvFormer-S18의 성능에 영향을 미치지 않으며 CAFormer-S18의 경우 0.1%의 개선을 가져올 수 있다. 따라서 논문에서는 ResScale과 각 블록의 바이어스 비활성화 셋팅을 적용.
Benchmark speed

제안된 StarReLU와 일반적으로 사용되는 GELU의 속도를 NVIDIA A100 GPU에서 벤치마킹했으며 결과는 위 표와 같다. GELU와 비교할 때 StarReLU는 NVIDIA A100 GPU에서 1.7배 빠른 상당한 속도 향상을 보인다는 것을 알 수 있다.
하지만 StarReLU가 GELU(PyTorch API)보다 느린 것을 알 수 있다. 이는 현재 StarReLU 구현이 CUDA 최적화되어 있지 않기 때문이라고하며 최적화되면 속도가 더 빨라질 가능성이 높다고함.
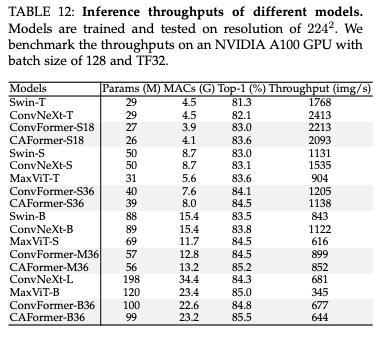
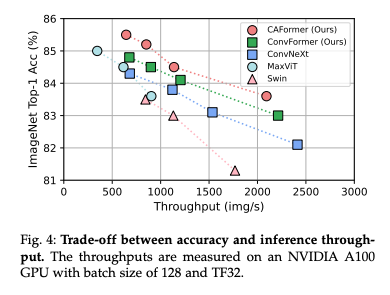
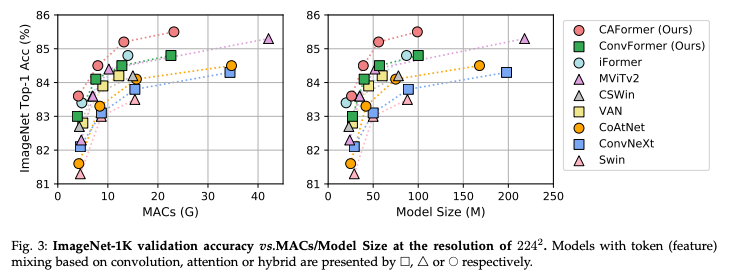
ConvFormer 및 CAFormer의 StarReLU를 GELU로 대체하고 처리량 실험에 대한 결과이다. 유사한 모델 크기와 MACs에서 ConvNeXt가 가장 높은 처리량을 가진다는 것을 알 수 있다. 이는 ConvNeXt 블록에 하나의 잔차 연결만 있는 반면 MetaFormer 블록에는 두 개가 있기 때문이다. 그러나 ConvFormer 및 CAFormer는 이러한 모델 중에서 더 높은 정확도를 얻었으며 Swin 및 MaxViT보다 상대적으로 높은 처리량을 달성하여 Fig. 4에 나타난 바와 같이 정확도와 처리량 사이에서 더 나은 trade-off를 이룬다.
Conclusion
- 본 논문에서는 Transformer의 추상화된 아키텍처인 MetaFormer의 역량을 연구하기 위한 탐구를 수행.
- 토큰 믹서 설계에서 벗어나서 가장 기본적인 또는 "old-fashioned" 토큰 믹서만을 사용하여 MetaFormer 모델인 IdentityFormer, RandFormer, ConvFormer, CAFormer를 제안.
- IdentityFormer, RandFormer는 MetaFormer의 견고한 성능 하한선과 토큰 믹서에 대한 보편성을 보여주고, ConvFormer, CAFormer는 기존 방법 대비 우수한 성능을 보임.
- 또한 새로운 활성화 함수인 StarReLU가 GELU에 비해 더 나은 성능을 달성할 뿐만 아니라 활성화 함수의 FLOPs를 크게 줄인다는 것을 발견.
이 논문에서는 Transformer의 아키텍쳐 최적화를 다룬 논문이였기에 여러 구조를 제안했다.
그리고 성능 향상을 위한 추가적인 활성화함수를 제안하여 Transformer의 구조 내에 대부분 사용되는 GELU 보다 우수한 성능을 가짐을 보였다. 하지만 실제로 코드를 실행해보니 논문처럼CUDA 최적화가 덜되어서 속도가 확실히 느리네요... 성능보다 속도가 중요한 태스크에서는 쓰면 안될 것 같습니다.
그래도 CAFormer같은 구조는 다른 태스크에서 충분히 시도해볼만한 가능성이 있어서 얼른 구현에서 실험 돌려봐야겠네요.
