개발환경
OS : MacOS
Pytorch : 2.2.0
Python : 3.9.13
데이터셋 및 코드 출처
https://github.com/IlliaOvcharenko/lung-segmentation%C3%9F%E2%88%9A
https://github.com/milesial/Pytorch-UNet
학부 때 Image Denoising 연구를 메인으로 하다보니 Oject Detection이나 Segmentation과 같은 다른 Vision Task에 대해 잘 알지 못하여서 이번 기회에 공부해보려합니다.
첫 번째로 공부한 분야는 U-Net 모형으로 잘 알려진 Image Segmentation(이미지 분할)입니다.
1. Segmentation?
segmentation(세그멘테이션)은 영상, 이미지를 구성하는 픽셀들을 특정 클래스, 라벨로 분할하는 일련의 과정을 의미합니다. 보통 이미지내의 객체들을 분할하는 작업을 말합니다. 예를들어 강아지 한마리 사진이 있다면, 강아지와 뒤의 배경을 분할하는 작업이 바로 segmentation입니다.
의료영상, 자율주행 등 다양한 분야에 접목되어 사용되고 있습니다.

출처 : Tensorflow 홈페이지
2. U-Net
논문 링크
Conference: MICCAI 2015
Title : U-Net: Convolution Networks for Biomedical Image Segmentation
https://arxiv.org/abs/1505.04597
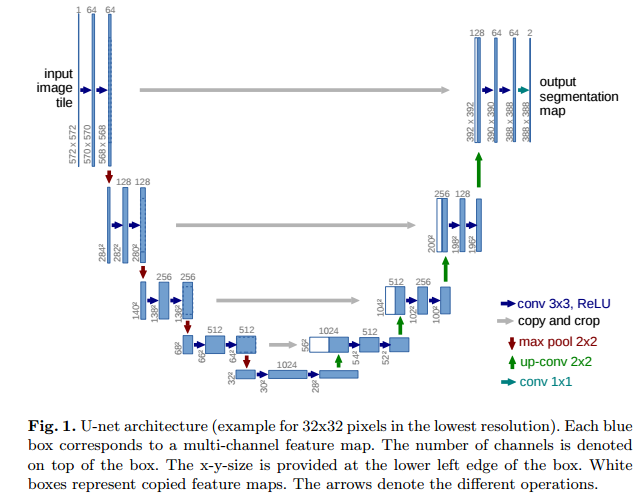
Segmentation의 가장 대표적인 모델은 바로 U-Net입니다. 모형의 구조가 "U"형태를 닮아 붙여졌다.
U-Net은 크게 두 부분으로 두 부분, 수축경로(Contracting Path)와 확장경로(Expanding Path)로 구성된다.
Contracting Path
Convolution, Batchnorm, Maxpooling Layer를 통해 이미지의 차원을 줄이면서 특징을 추출하는 구간이다,
Expanding Path
축소 경로에서 얻은 특징 맵을 사용하여 이미지의 크기를 다시 원본 크기로 복원한다(논문에서는 input과 ouput 사이즈 다름). 이 과정에서 Upsampling과 Covolution Layer가 사용되며, 축소 경로에서 얻은 특징 맵과 결합(concatenation)하여 정밀한 위치 정보를 복원한다.
Bottle Neck
수축 경로에서 확장 경로로 전환되는 구간을 의미한다.
Skip Connection
수축 경로(Contracting path)에서 얻은 특징 맵을 확장 경로(Expanding path)의 대응하는 레이어와 결합하는 방식을 말한다. 이 과정은 깊은 네트워크에서 정보가 손실되는 것을 방지하고, 더 세밀한 세부 정보를 세그멘테이션 결과에 포함시키기 위해 사용한다.
3. Code Baseline Using Pytorch
라이브러리 & 파이토치 버전 확인
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pathlib import Path
from PIL import Image
from sklearn.model_selection import train_test_split
# torch version
print(torch.__version__)
print(torchvision.__version__)
# device 변수 선언
device = torch.device("mps") #for macOS
데이터셋 생성 함수
class XRayDataset(torch.utils.data.Dataset):
def __init__(self, origin_mask_list, origins_folder, masks_folder, transforms=None):
self.origin_mask_list = origin_mask_list
self.origins_folder = origins_folder
self.masks_folder = masks_folder
self.transforms = transforms
def __getitem__(self, idx):
origin_name, mask_name = self.origin_mask_list[idx]
origin = Image.open(self.origins_folder / (origin_name + ".png")).convert("P")
mask = Image.open(self.masks_folder / (mask_name + ".png"))
if self.transforms is not None:
origin, mask = self.transforms((origin, mask))
origin = torchvision.transforms.functional.to_tensor(origin) - 0.5
mask = np.array(mask)
mask = (torch.tensor(mask) > 128).long()
return origin, mask
def __len__(self):
return len(self.origin_mask_list)
# 사이즈 변경
class Resize():
def __init__(self, output_size):
self.output_size = output_size
def __call__(self, sample):
origin, mask = sample
origin = torchvision.transforms.functional.resize(origin, self.output_size)
mask = torchvision.transforms.functional.resize(mask, self.output_size)
return origin, mask
# 원본이미지와 mask 이미지를 합성하여 반환하는 함수
def blend(origin, mask1=None, mask2=None):
img = torchvision.transforms.functional.to_pil_image(origin + 0.5).convert("RGB")
if mask1 is not None:
mask1 = torchvision.transforms.functional.to_pil_image(torch.cat([
torch.zeros_like(origin),
torch.stack([mask1.float()]),
torch.zeros_like(origin)
]))
img = Image.blend(img, mask1, 0.2)
if mask2 is not None:
mask2 = torchvision.transforms.functional.to_pil_image(torch.cat([
torch.stack([mask2.float()]),
torch.zeros_like(origin),
torch.zeros_like(origin)
]))
img = Image.blend(img, mask2, 0.2)
return img
data_folder = Path(".", "dataset/dataset")
origins_folder = data_folder / "images"
masks_folder = data_folder / "masks"
models_folder = Path("models")
images_folder = Path("images")
origins_list = [f.stem for f in origins_folder.glob("*.png")]
masks_list = [f.stem for f in masks_folder.glob("*.png")]
origin_mask_list = [(mask_name.replace("_mask", ""), mask_name) for mask_name in masks_list]
# Split the dataset into train and validation and test
train_origin_mask_list, test_origin_mask_list = train_test_split(origin_mask_list, test_size=0.2, random_state=42)
train_origin_mask_list, val_origin_mask_list = train_test_split(train_origin_mask_list, test_size=0.2, random_state=42)
val_test_transforms = torchvision.transforms.Compose([
Resize((256, 256)),
])
# Create the datasets
train_dataset = XRayDataset(train_origin_mask_list, origins_folder, masks_folder, transforms=torchvision.transforms.Compose([
Resize((256, 256))
]))
test_dataset = XRayDataset(test_origin_mask_list, origins_folder, masks_folder, transforms=val_test_transforms)
val_dataset = XRayDataset(val_origin_mask_list, origins_folder, masks_folder, transforms=val_test_transforms)
batch_size= 4
# Create the dataloaders
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)평가지표 함수
import pandas as pd
import numpy as np
def jaccard(y_true, y_pred):
""" Jaccard a.k.a IoU score for batch of images
"""
num = y_true.size(0)
eps = 1e-7
y_true_flat = y_true.view(num, -1)
y_pred_flat = y_pred.view(num, -1)
intersection = (y_true_flat * y_pred_flat).sum(1)
union = ((y_true_flat + y_pred_flat) > 0.0).float().sum(1)
score = (intersection) / (union + eps)
score = score.sum() / num
return score
def dice(y_true, y_pred):
""" Dice a.k.a f1 score for batch of images
"""
num = y_true.size(0)
eps = 1e-7
y_true_flat = y_true.view(num, -1)
y_pred_flat = y_pred.view(num, -1)
intersection = (y_true_flat * y_pred_flat).sum(1)
score = (2 * intersection) / (y_true_flat.sum(1) + y_pred_flat.sum(1) + eps)
score = score.sum() / num
return score
이미지 출력
#train_loader에서 첫번쨰 이미지를 plt로 출력해보자
origin, mask = next(iter(train_loader))
print(origin.shape)
print(mask.shape)
plt.imshow(origin[0].permute(1, 2, 0) + 0.5, cmap="gray")
plt.imshow(mask[0], alpha=0.5, cmap="Reds")
plt.show()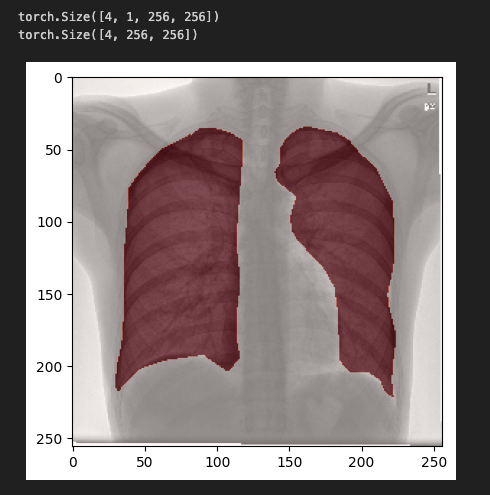
# 이미지 , 마스크 따로따로, 합쳐서 출력해보기
origin, mask = next(iter(train_loader))
print(origin.shape)
print(mask.shape)
# subplot을 이용하여 이미지와 마스크를 따로따로 출력해보기
fig, ax = plt.subplots(1, 3, figsize=(10, 5))
ax[0].imshow(origin[0].permute(1, 2, 0) + 0.5, cmap="gray")
ax[1].imshow(mask[0], cmap="Greens")
ax[2].imshow(blend(origin[0], mask[0]), cmap="gray")
plt.show()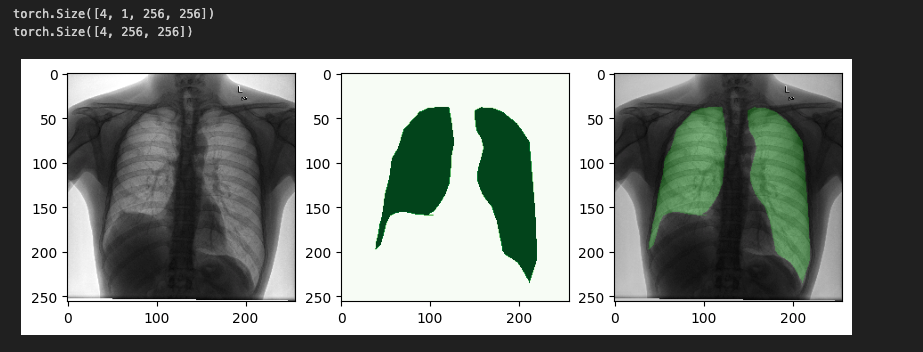
U-Net 모형 정의
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
#==========================================================================
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = (DoubleConv(n_channels, 64))
self.down1 = (Down(64, 128))
self.down2 = (Down(128, 256))
self.down3 = (Down(256, 512))
factor = 2 if bilinear else 1
self.down4 = (Down(512, 1024 // factor))
self.up1 = (Up(1024, 512 // factor, bilinear))
self.up2 = (Up(512, 256 // factor, bilinear))
self.up3 = (Up(256, 128 // factor, bilinear))
self.up4 = (Up(128, 64, bilinear))
self.outc = (OutConv(64, n_classes))
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
def use_checkpointing(self):
self.inc = torch.utils.checkpoint(self.inc)
self.down1 = torch.utils.checkpoint(self.down1)
self.down2 = torch.utils.checkpoint(self.down2)
self.down3 = torch.utils.checkpoint(self.down3)
self.down4 = torch.utils.checkpoint(self.down4)
self.up1 = torch.utils.checkpoint(self.up1)
self.up2 = torch.utils.checkpoint(self.up2)
self.up3 = torch.utils.checkpoint(self.up3)
self.up4 = torch.utils.checkpoint(self.up4)
self.outc = torch.utils.checkpoint(self.outc)
# Create the model
# n_classes = 분할 클래스 수
model = UNet(n_channels=1, n_classes=2, bilinear=True).to(device)
# Create the optimizer
optimizer = optim.Adam(model.parameters(), lr=0.0001)
# Create the loss function
criterion = nn.CrossEntropyLoss()
Train 함수 정의
# Create the training loop
train_loss = []
val_loss = []
train_jaccard = []
val_jaccard = []
train_dice = []
val_dice = []
def train(model, train_loader, val_loader, criterion, optimizer, epochs, device):
for epoch in range(epochs):
model.train()
running_train_loss = 0.0
running_train_jaccard = 0.0
running_train_dice = 0.0
for origin, mask in train_loader:
origin = origin.to(device)
mask = mask.to(device)
optimizer.zero_grad()
output = model(origin)
loss = criterion(output, mask)
loss.backward()
optimizer.step()
running_train_loss += loss.item()
running_train_jaccard += jaccard(mask, torch.argmax(output, dim=1)).item()
running_train_dice += dice(mask, torch.argmax(output, dim=1)).item()
model.eval()
running_val_loss = 0.0
running_val_jaccard = 0.0
running_val_dice = 0.0
with torch.no_grad():
for origin, mask in val_loader:
origin = origin.to(device)
mask = mask.to(device)
output = model(origin)
loss = criterion(output, mask)
running_val_loss += loss.item()
running_val_jaccard += jaccard(mask, torch.argmax(output, dim=1)).item()
running_val_dice += dice(mask, torch.argmax(output, dim=1)).item()
train_loss.append(running_train_loss / len(train_loader))
val_loss.append(running_val_loss / len(val_loader))
train_jaccard.append(running_train_jaccard / len(train_loader))
val_jaccard.append(running_val_jaccard / len(val_loader))
train_dice.append(running_train_dice / len(train_loader))
val_dice.append(running_val_dice / len(val_loader))
print(f"Epoch {epoch+1}/{epochs} - "
f"Train Loss: {train_loss[-1]:.4f} - "
f"Val Loss: {val_loss[-1]:.4f} - "
f"Train Jaccard: {train_jaccard[-1]:.4f} - "
f"Val Jaccard: {val_jaccard[-1]:.4f} - "
f"Train Dice: {train_dice[-1]:.4f} - "
f"Val Dice: {val_dice[-1]:.4f}")
# Train the model
train(model, train_loader, val_loader, criterion, optimizer, epochs=10, device=device)
# Save the model
model_name = "unet_epoch10.pth"
torch.save(model.state_dict(), models_folder / model_name)학습 중 Loss와 Metric 시각화
# Plot the loss and metrics
fig, ax = plt.subplots(1, 3, figsize=(15, 5))
ax[0].plot(train_loss, label="Train Loss")
ax[0].plot(val_loss, label="Val Loss")
ax[0].set_title("Loss")
ax[0].legend()
ax[1].plot(train_jaccard, label="Train Jaccard")
ax[1].plot(val_jaccard, label="Val Jaccard")
ax[1].set_title("Jaccard")
ax[1].legend()
ax[2].plot(train_dice, label="Train Dice")
ax[2].plot(val_dice, label="Val Dice")
ax[2].set_title("Dice")
ax[2].legend()
plt.show()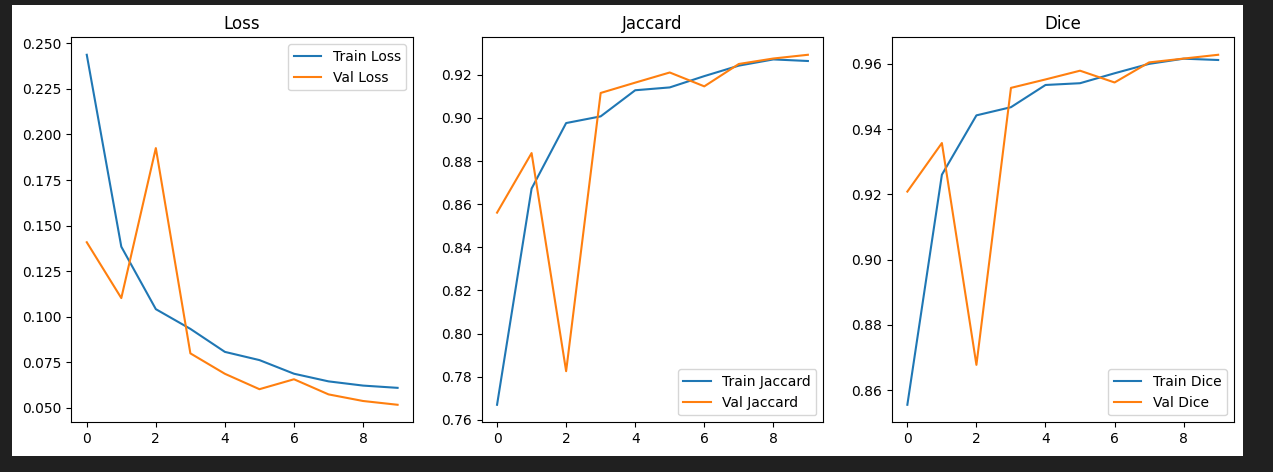
Test 데이터 Predict
model.eval()
import random
# Initialize lists to store results
all_origins = []
all_masks = []
all_outputs = []
with torch.no_grad():
for origin, mask in test_loader:
origin = origin.to(device)
mask = mask.to(device)
output = model(origin)
output = torch.argmax(output, dim=1)
# Append results to lists
all_origins.append(origin.cpu())
all_masks.append(mask.cpu())
all_outputs.append(output.cpu())
# Convert lists to tensors
all_origins = torch.cat(all_origins, dim=0)
all_masks = torch.cat(all_masks, dim=0)
all_outputs = torch.cat(all_outputs, dim=0)
# Plot 10 random samples
fig, axs = plt.subplots(10, 3, figsize=(15, 50))
for i in range(10):
idx = random.randint(0, len(all_origins) - 1)
axs[i, 0].imshow(all_origins[idx].permute(1, 2, 0) + 0.5, cmap="gray")
axs[i, 1].imshow(all_masks[idx], cmap="Greens")
axs[i, 2].imshow(all_outputs[idx], cmap="Greens")
plt.show()
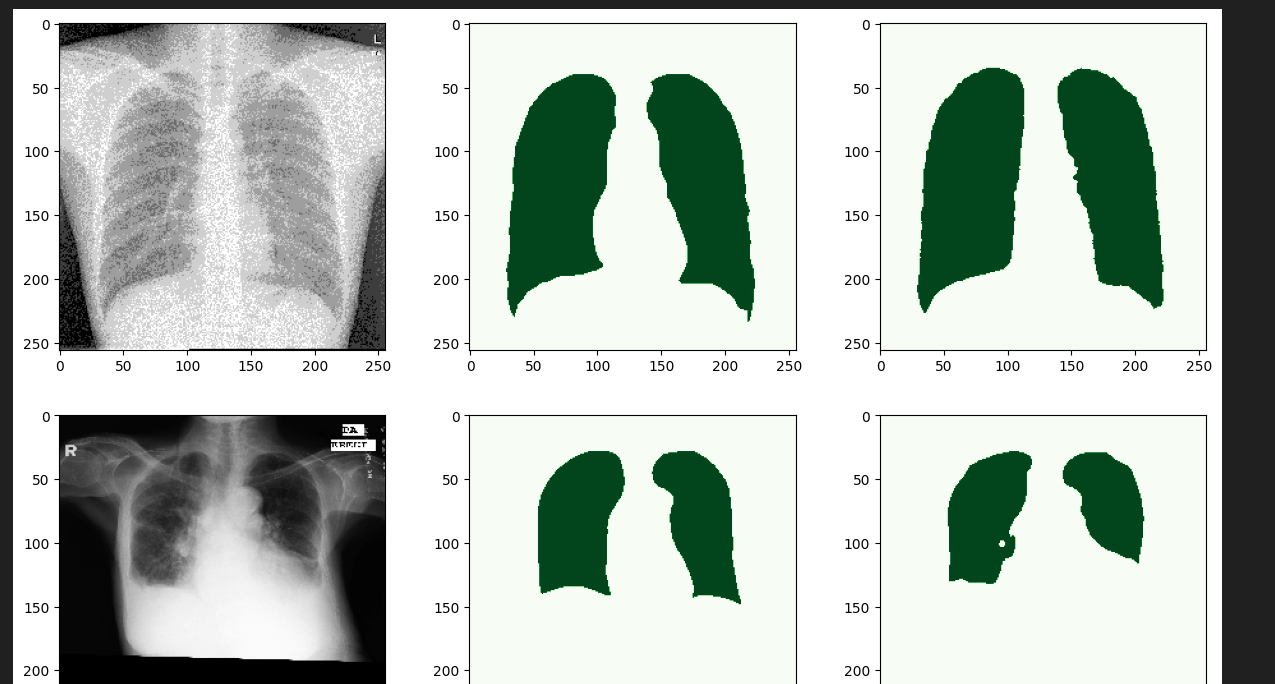
열 번밖에 학습을 시키지 못해 성능은 좋지 않지만, Segmentation 학습 및 예측 프로세스에 대해 파악할 수 있었습니다.해당 Baseline으로 다른 모형을 사용하거나, 다른 평가 지표를 추가해보는 것도 좋을 것 같습니다.
감사합니다.
