논문 제목
Variational image compression with a scale hyperprior (ICLR 2018)
URL: https://arxiv.org/abs/1802.01436
인용수 : 1766회 (24.09.23 기준)
학습기반 이미지 압축 (Learned Image Compression) 연구분야에서 가장 유명한 분이라고 할 수 있는 Johannes Ballé씨의 Hyperprior 제안 논문이다.
이 논문이후 대부분의 딥러닝 기반 이미지 압축 모델은 Hyperprior와 Context Module을 통해 이미지를 보다 효율적으로 압축할 수 있게 되었다.
요약
- 잠재 표현 (Latent Representation)에서 공간적 종속성을 효과적으로 포착하기 위해 Hyperprior를 사용함.
- Hyperprior는 이미지 코덱(codecs)에서 보편적으로 사용되는 side information과 관련이 있지만 딥러닝 이미지 압축에서는 거의 연구되지 않은 개념임.
- 기존 오토인코더 기반 압축 방식과 달리, Hyperprior 네트워크를 함께 학습하는 모델을 제안하였고, 정성&정량 평가에서 기존 방법들보다 성능이 우수함을 증명하였음.
Introduction
- 기존 이미지 압축 방법의 문제 : Lossy Compression에서 잠재 표현을 양자화하고 엔트로피 코딩으로 압축을 진행하지만, 잠재 표현 간. 통계적 종속성을 고려하지 않아 최적의 압축 성능 달성을 못하였음.
- Side Information : 기존 압축 모델에 부가적인 정보를 주는 네트워크를 활용해서 이미지 특성을 더 잘 반영할 수 있음.
- VAE + Hyperprior : VAE 기반의 모델에 엔트로피 모델의 매개변수로 사용하는 Hyperprior를 추가하여 잠재표현의 공간적 종속성을 학습 시킴.
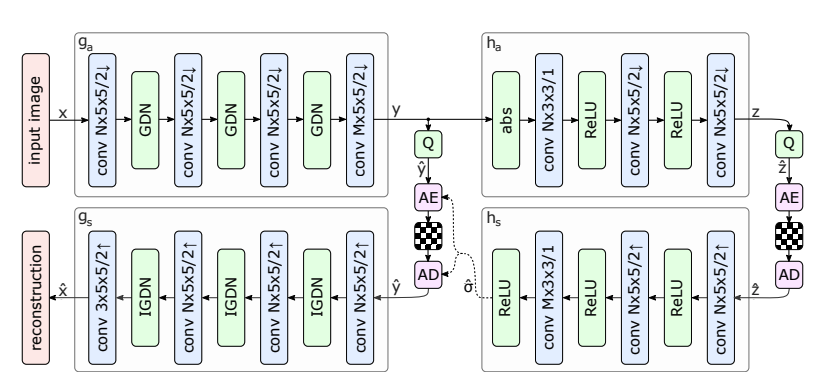
Compression with Variational Models, Scale Hyperprior
-
Transform Coding : 이미지 벡터 x를 인코더가 Analysis Transform()을 사용하여 잠재표현 y로 변환하고, 이를 양자화된 를 엔트로피 코딩을 통해 압축함.
디코더는 양자화된 잠재 표현을 복원하고(), 복원된 이미지 를 생성. -
Rate-Distortion : 압축과정에서 양자화로 생기는 오류를 고려하여 Rate(Bit-Rate)와 Distortion(PSNR,MS-SSIM)의 균형을 맞추는 최적화를 진행. 여기서 Rate는 Cross Entropy를 사용.
-
VAE 최적화 : VAE 최적화 방식을 통해, generative모델과 inference 모델을 사용하여 KL발산을 최소화여 Rate-Distortion을 최적화함.
-
양자화 : 양자화를 하면 미분이 되지 않는 문제가 발생하기 때문에 학습 중 Gaussian Noise를 추가함.
-
Prior Model 확장 : 2017년 Ballé 논문의 모델델은 완전히 Factorized)된 Prior Model을 사용함.(잠재 표현의 각 요소들이 서로 독립이라고 가정하는 방식) 하지만 이 방법은 잠재표현의 spatial dependency를 잘 표현하지 못함.
Hyperprior는 잠재표현 y의 각 요소가 독립적이지 않고, 그들의 Scale이 공간적으로 관련이 있다는 것을 모델로 구현. 이를 위해 추가적인 잠재변수 z를 도입하여 잠재표현 y의 스케일 정보를 추정. 이 추가적인 잠재변수 z는 잠재표현 y의 스케일을 설명하는데 사용, 이를 통해 잠재변수 간의 상관관계를 더 잘 모델링할 수 있음.
Hyperprior의 모델은 다음과 같이 표현됨.
모델 구조
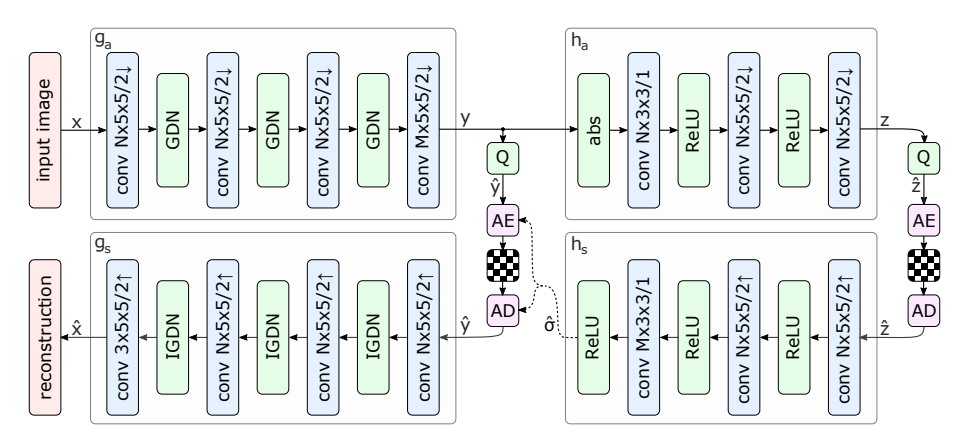
Convolution Layer와 비선형 함수인 GDN/IGDN, ReLU를 번갈아 사용하였음.
EXPERIMENTS
학습
- 데이터는 JPEG 100만장 사용하였고, 256x256 크기로 랜덤 크롭하여 학습에 사용.
- ADAM 사용하였고 LR은 0.0001로 설정
- 8개의 람다 값을 설정하였고 손실함수의 Distortion은 PSNR과 MS-SSIM으로 각각 학습되었다고함.
성능 평가
이미지 압축의 대표적인 벤치마크 데이터셋인 Kodak 데이터셋을 사용하여 평가 진행.
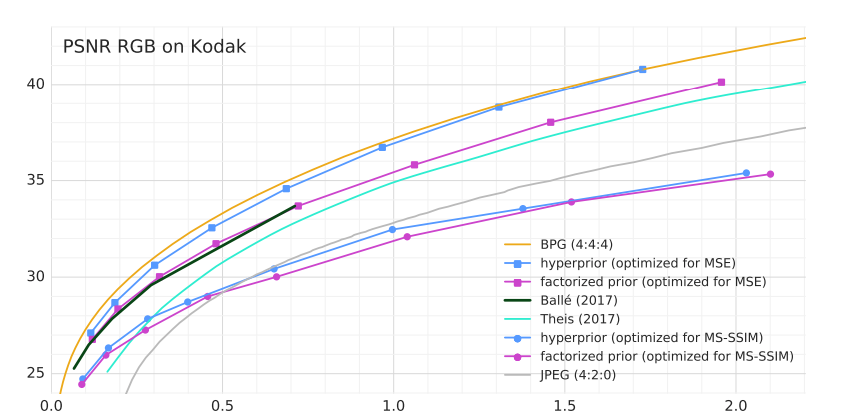
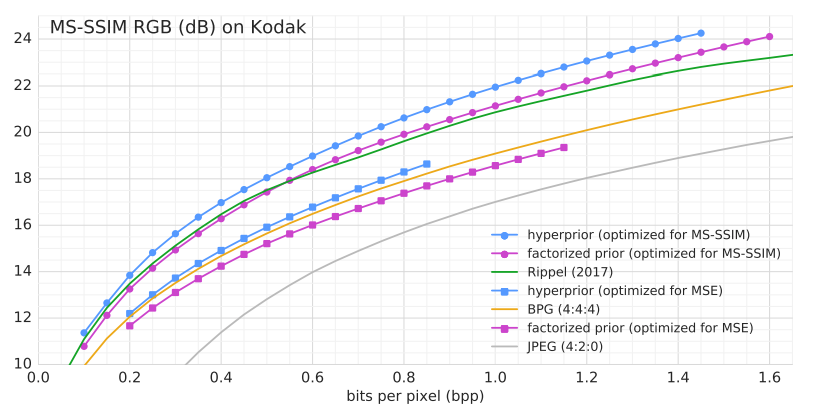
- Scale Hyperprior 모델이 기존 딥러닝 기반의 모델들보다 더 우수한 성능을 보였음.
- Hyperprior가 사용한 Bit-rate는 전체 압축된 Bit-rate의 작은 비율이지만 성능 개선이 크게 이루어졌음.
- PSNR측면에서는 여전히 BPG와 같은 전통적인 방식이 나은 성능을 보임.
하이퍼프라이어는 잠재 표현에서의 공간적 종속성(spatial dependency)을 효과적으로 포착하며, 더 나은 압축 성능을 보였던 논문이고 Compression 연구에서 무조건 사용하는 방법이 된 방법론이다.
다음 리뷰할 논문은 같은해에 나온 "Joint Autoregressive and Hierarchical Priors for Learned Image Compression"에서 제안된 Context Model이다. 이 또한 구글의 David Minnen, Johannes Ballé가 저자이다.
이 논문에서는 컨텍스트 모델(context model)과 하이퍼프라이어(hyperprior)를 결합하여 잠재 표현의 확률 분포를 더 정확하게 예측하고, 이를 통해 이미지 압축 성능을 향상 시킨 논문이다.
