[Compression] Fast and High Performance Learned Image Compression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation 리뷰
Image Compression
논문 제목
Fast and High-Performance Learned ImageCompression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation
(Submitted to Trans. Journal)
URL: https://arxiv.org/abs/2309.02529
인용수 : 3회 (25.2.17 기준)
Abstract
- 딥러닝 기반의 이미지 압축 방법들의 일부는 serial context-adaptive entropy model을 사용하여 RD 성능을 향상시켰다. 하지만 이는 속도가 매우 느리고, 인코딩 & 디코딩 복잡도가 높아 실질적인 사용에는 적합하지 않다.
- 본 논문에서는 네 가지 방법을 통해 복잡도와 성능 간 trade-off를 맞췄다고함.
- Deformable convolutional module을 도입하여 입력 이미지의 중복성을 더 효과적으로 제거.
- Improved Checkerboard Context Model을 통해 별도의 두 개의 확률 분포 추정 네트워크와 서로 다른 확률 모델을 사용. 이를 통해 성능은 유지하면서 병렬 디코딩 가능해짐.
- Three-Pass Knowledge Distillation을 통해 디코더를 경량화했다고 한다. Teacher Network의 최종 결과뿐만 아니라 중간 결과까지 Student Network로 Transfer하여 학습을 보조.
- L1 Regularization을 도입하여 latent representation를 더 sparse하게 만들고, 인코딩 및 디코딩 과정에서 non-zero 채널만 부호화하여 비트율을 낮추고 인코딩 및 디코딩 속도를 줄인다.
Related Work
Context Models
대부분의 학습 기반 이미지 압축 기법은 Autoencoder 아키텍처를 기반이며, 입력 이미지의 압축된 latent representation을 효과적으로 추출하는 방식으로 설계된다.
Autoregressive(AR) Model은 Causal Context로 부터 잠재 표현을 예측하는 데 사용됨. 보통 Hyperprior를 부착하여 추가적인 side information을 학습하여 컨텍스트 기반 예측을 보정할 수 있도록 한다. 이를 통해 Context Model과 Hyperprior를에서 얻은 데이터를 결합하여 양자화된 잠재 변수의 확률 분포를 학습하고, 이를 엔트로피 부호화 과정에서 활용하는 방식이 일반적이다.
일반적으로 Gaussian Model이 사용되며, Gaussian Mixture Model(GMM)과 Gaussian-Laplacian-Logistic Mixture Model(GLLMM)을 도입하여 SOTA 성능을 달성해왔다.
하지만 Serial Context Model은 디코딩 과정에서 병렬 연산이 어렵다는 단점이 있음. 이를 해결하기 위해 Channel-wise Autoregressive Entropy Model(ChARM)이 제안되어서 컨텍스트 모델 내에서 요소 단위 직렬 처리를 최소화했다. 또한 Spatial-Channel Contextual Adaptive Model(SCCTX)와 같은 컨텍스트 모델을 통해 속도 저하 없이 R-D성능을 향상시켜왔다.
직렬 문제 해결을 위해 Checkerboard Context Model (CCM)이 제안되었고, 데이터를 체커보드 패턴을 기반으로 두 개의 그룹으로 나누어 병렬 처리가 가능하도록 설계했다. 그러나 이러한 방법은 Kodak 데이터셋에서 R-D 성능이 약 0.2-0.3dB 감소하는 문제가 있다.
Deformable Convolution
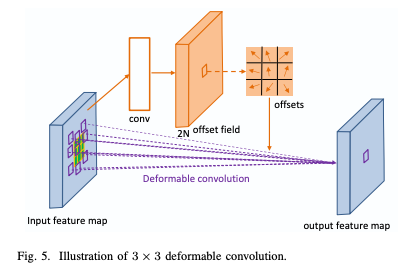
Deformable Convolution은 신경망의 모델링 능력 향상을 위해 learned offset maps을 도입한 구조이다. 이는 object detection과 semantic segmentation와 같은 복잡한 비전 태스크에서 classical convolutions networks보다 우수한 성능을 보였다. 이후 action recognition, video super-resolution 등의 분야에도 적용되었고, video compression에도 활용된 연구 또한 존재한다.
Deformable Convolution은 dynamic kernels을 가지고 있으며, non-rigid motion patterns을 보다 정교하게 캡쳐해서 모션 보정 성능 향상 및 이후 residual compression module의 부담을 줄일 수 있다고 한다.
이 논문은 Deformable Convolution(v1)을 학습 기반 이미지 압축 프레임워크에 통합하는 첫 번째 시도임.
Knowledge Distillation
지식 증류는 Teacher Network의 지식을 Student Network로 전달하는 방법이다.
Student Model은 예측값과 Soft Teacher Targets 간의 차이를 측정하는 Distillation Loss을 사용한다.
Learned Image Compression에도 지식 증류가 도입된 사례가 있으나, GAN구조를 활용하여 낮은 비트율에서 visual performance에 초점을 맞췄고, Hyper Network가 없다. 따라서, 성능이 제한적임. 그리고 지식 증류 과정에서 교사 네트워크의 최종 출력값만 고려하였으며, 중간 결과는 증류에 활용되지 않았다.
최초 적용 논문 : "Microdosing: Knowledge distillation for gan based compression"
The Proposed Image Compression Framework
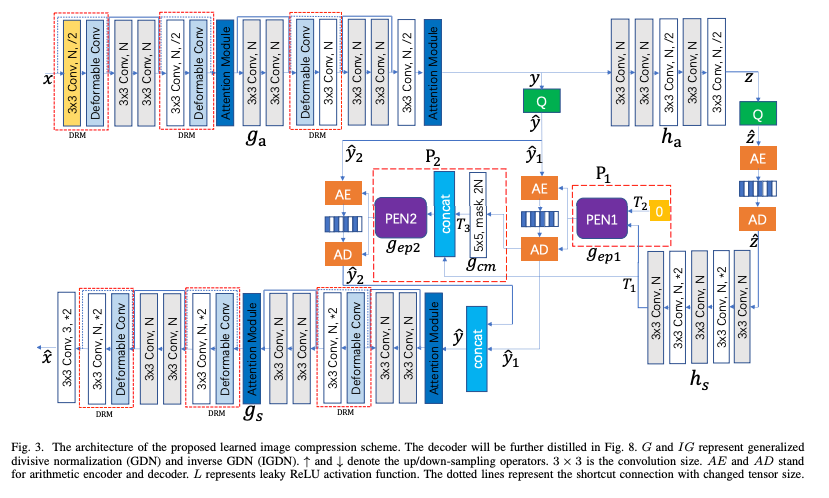
The Overall Architecture of the System
위 이미지는 제안 프레임워크 구조이다.
원본 이미지 x의 크기는 WxHx3이며, 여기서 W와 H는 각각 이미지의 너비와 높이를 나타낸다.
, 는 인코더 / 디코더 네트워크, ,는 하이퍼프라이어를 의미한다.
제안 압축 모델의 흐름은 아래 순서이다.
1. 입력 이미지 x가 를 통해 압축된 latent representation 로 변환된다.
2. 는 양자화를 통해 가 되며, 본 논문에서는 두 개의 집합으로 분할 된다.
3. 두 집합의 확률 분포 매개변수는 Parameter Estimation Networks(PENs)를 통해 추정.
4. 이후 Arithmetic Coding을 통해 을 비트스트림으로 압축한다.
5. 비트스트림은 decoding을 통해 로 되며, 에 입력되어 압축된 이미지 를 출력함.
Deformable Residual Block (DRB)
deformable convolution은 Receptive Field의 유연한 모델링을 가능하게 하여 CNN이 더 나은 특징을 추출하고 객체를 효과적으로 표현할 수 있도록 한다. 이를 통해 정확한 공간적 이해와 객체 감지가 필요한 작업에서 성능을 향상시킨다.
본 논문에서는 Deformable Residual Module(DRM)을 제안하고 이를 이미지 압축에 적용함. DRM에서는 변형 가능한 모듈과 기존의 컨볼루션을 결합하고, shortcut 연결을 추가하였다. DRM은 Upsampling 또는 Downsampling이 포함된 경우에 사용되며, 이러한 경우에는 그림 2에서 점선으로 표시된 숏컷을 따른다.
DRM은 입력 이미지의 Spatial Redundancy을 줄이는 역할을 하며, 이를 통해 이미지 압축 성능을 향상시킬 수 있다. 또한 deformable module은 기존 컨볼루션과 비교했을 때 모델의 복잡도를 거의 증가시키지 않는다고 한다.
Improved Checkerboard Context Model and Coding
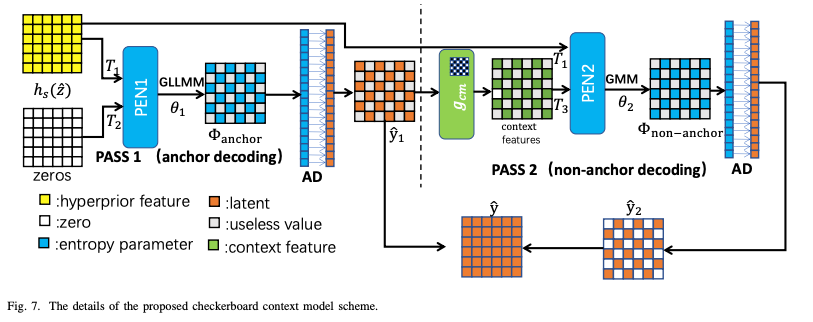
Checkerboard Context Model은 디코딩 병렬화를 위해 21년에 제안된 컨텍스트 모델이다.
본 논문에서는 양자화된 잠재표현 를 두개의 subset으로 나눈 후 앵커(), 비앵커()로 구분하여 처리한다.
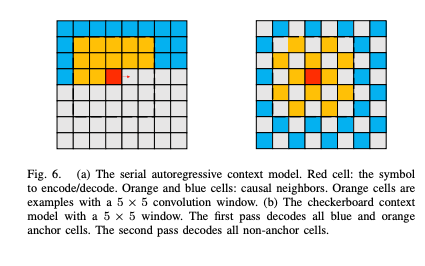
이 과정에서 첫 번째 단계는 앵커부분을 인코딩 & 디코딩하는 것이고, 두 번째 단계는 비앵커 부분을 앵커 정보를 기반으로 인코딩 & 디코딩하는 방식으로 진행된다.
물론 CCM을 사용했을 때 속도 향상은 뛰어나지만 이미지 품질 측면에서 성능이 감소하는 문제가 있다.
성능 저하의 주요 원인은 아래와 같다.
1. 앵커 부분이 Hyperprior만을 이용해 부호화되며, Context Model을 사용하지 않음
2. 두 하위 집합의 확률 분포 매개변수를 단일 네트워크에서 추정
이를 해결하기 위해 논문에서는 더 개선된 두 기법을 제안했다.
1. 각 하위 집합의 확률 분포 매개변수를 개별적으로 추정하기 위해 두 개의 서로 다른 네트워크 사용.
2. 앵커 부분을 컨텍스트 모델 없이 부호화해야 하므로, 보다 강력한 확률 분포 모델을 사용하여 성능 개선.
본 논문에서는 앵커 부분에 대해서는 GLLMM을 적용하였고, 비앵커부분은 기존과 동일하게 GMM을 사용했다고 한다.
인코딩 및 학습 과정
앵커와 비앵커를 추출한후 과 를 생성한다. 첫 번째 PASS에서는 앵커(파란색 셀)을 부호화 및 학습한다. 이 단게에서는 컨텍스트 모델은 적용되지 않으며, 하이퍼프라이어 정보만 사용한다. 비앵커 는 두 번째 단계에서 CCM과 하이퍼프라이어 모두 활용하여 부호화한다.
디코딩 과정
디코딩 과정에서는 의 모든 값을 알 수 없으므로 과 를 순차적으로 디코딩해야 한다. 과 는 초기 상태에서는 값은 0으로 설정된다.
먼저 하이퍼프라이어 디코더에서 를 생성한다. 과 zero 값을 가지는 를 결합하여 PEN1에 입력하여 앵커의 확률분포 매개변수 을 추정한다.
기존의 CCM과 달리 본 논문에서는 보다 강력한 GLLMM을 적용하여 컨텍스트 모델 없이도 성능을 향상시켰다고 한다. 컨텍스트 모델이 없기 때문에, 모든 앵커는 병렬로 복호화할 수 있다.
PEN1을 통과 후 복호화된 앵커 을 업데이트함. 은 Checkerboard Mask가 적용된 단일 컨볼루션 레이어를 통과 하여 Context Feature 를 생성한다.
와 을 결합한 후 PEN2의 입력값으로 사용되어 비앵커의 확률분포 매개변수 를 추정한다.
비앵커 역시 병렬로 복호화 가능.
PEN1과 PEN2는 각각 독립적으로 학습되므로, 기존 단일 네트워크를 사용했던 방식보다 더 나은 성능을 달성할 수 있다.
Improving the Decoder Using Knowledge Distillation
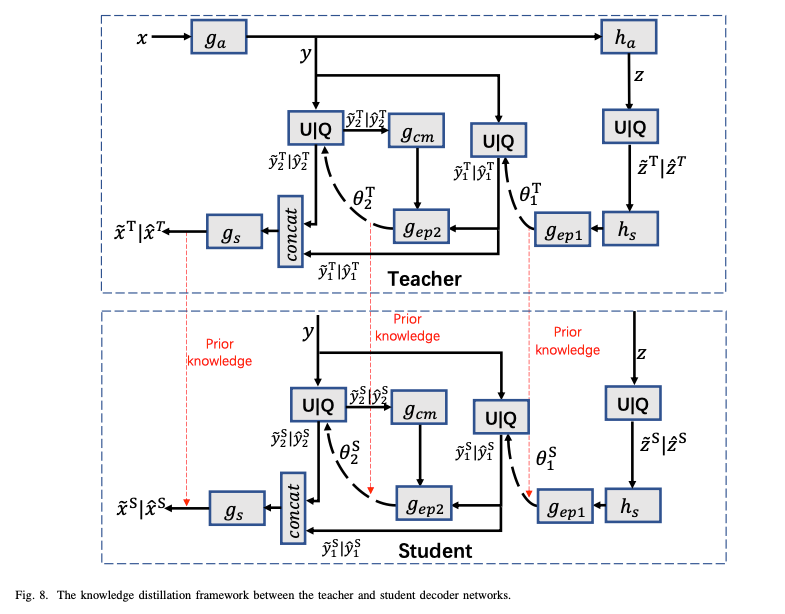
본 논문에서는 decoder network의 복잡도를 줄이는 방법을 knowledge distillation을 사용하여 제안함. 실험을 통해 지식 증류는 단순히 복잡도를 줄이는 것뿐만 아니라 R-D 성능을 향상시키는 데에도 기여할 수 있음을 확인하였다.
본 논문에서는 전체 학습 과정을 세 단계로 구성했다고 한다.
모든 학습 기반 이미지 압축에서 공통적으로 사용하는 함수를 사용했다. 하지만 여기에 정규화 손실함수를 추가했다고 한다.
Teacher Model 훈련이 완료된 후, 새로운 Student Decoder 네트워크를 도입하며, 이는 초기에는 Teacher Decoder와 동일한 구조를 가진다. 본 연구의 목표는 지식 증류를 통해 Student Decoder의 R-D 성능을 향상시키는 것이다. 기존 연구에서는 Prior Knowledge를 학생 네트워크로 전이했으나, 본 연구에서는 확률 분포 매개변수 & 또한 전달한다.
인코더, Teacher & Student 디코더 네트워크는 아래 손실함수를 사용하여 joint로 다시 학습된다고 한다.
여기서 는 이전에 정의된 손실함수이며, 는 지식 증류 손실 함수로 교사 네트워크와 학생 네트워크 간의 복원 이미지 오류와 확률 분포 매개변수 &의 차이를 포함한다. 다른 연구에서는 이 차이를 Softmax를 활용하여 산출했으나, 본 논문에서는 MSE를 활용한 실험이 더 나은 결과를 제공했다고 함.
Training
훈련 이미지는 CLIC 데이터셋 및 LIU4K 데이터셋에서 수집했으며, 2000×2000 해상도로 균일하게 리스케일링했다고 한다. 데이터 증강 기법을 사용하여 384×384 해상도의 81,650개 이미지를 학습 시켰다고 한다.
Experimental Results
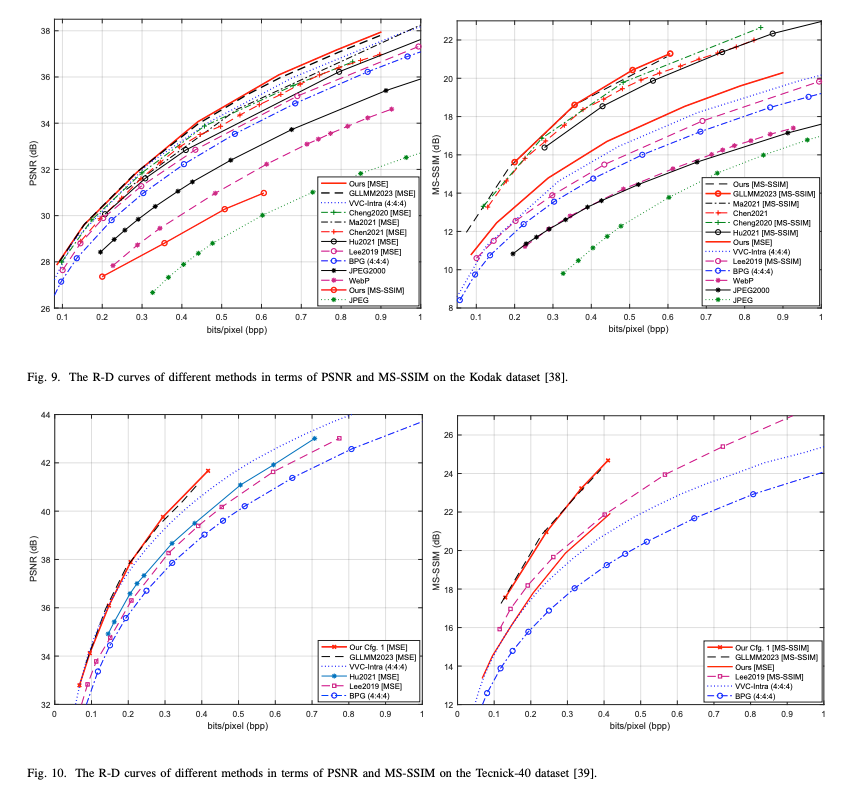
Ablation Experiments
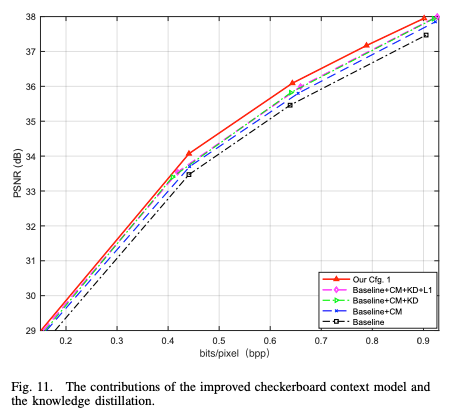
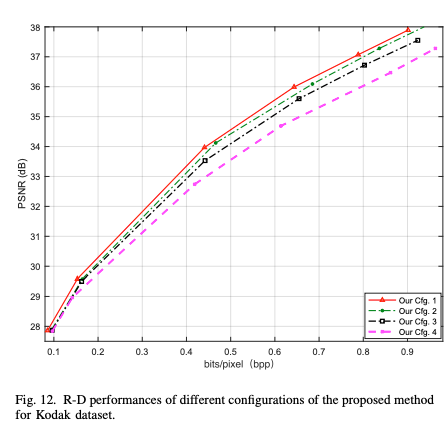
본 논문에서 제안하는 Improved CCM, DRM, KD, L1 Loss의 기여도를 평가함.
모든 모듈 및 방법론을 모두 적용했을 때 성능 향상이 된 것을 확인할 수 있다.
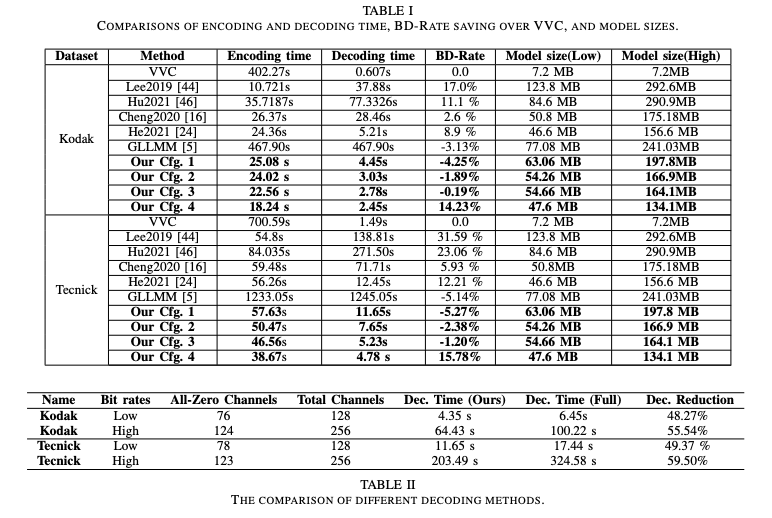
여기서 Student Model의 구조를 변경한 설정 값들이다.
Config1 : 제안 방법론 모두 적용한 모델 + 동일한 디코더 사용
Config2 : 어텐션 및 일부 residual module 제거
Config3 : 필터 개수 (25%) 감소
Config4 : 필터 개수 (50%) 감소
Conclusions
본 논문에서는 딥러닝 기반 이미지 압축의 R-D 성능을 개선하고 모델 복잡도를 줄이기 위한 네 가지 기법을 제안하였음.
1. Deformable Residual Module을 통해 잠재표현의 공간적 중복을 감소 + 압축 성능 향상
2. 개선된 CCM을 활용하여 잠재 표현을 두 개의 서브셋으로 나누고, 두 단계의 Checkerboard 엔트로피 부호화를 수행하여 확률 분포 파라미터를 추정
3. 3단계 Knowledge Distillation을 사용하여 모델을 재훈련 - 디코더 네트워크의 복잡도를 줄이면서 성능저하 최소화
4. L1 정규화를 통해 잠재 표현을 sparse하게 하게하고, 0이 아닌 채널만 인코딩 및 디코딩하여 연산량을 대폭 줄이면서도 압축 성능을 유지.
학습 기반 이미지 압축 연구를 하면서 보통 0.001의 PSNR이나 BPP 개선을 위해 개선된 모델 구조를 사용하지만,, 보통 좋은 아키텍쳐를 도입하면 모델의 크기가 커져서 추론 속도나 학습 속도를 느리게 만든다.
이미 성능은 SOTA 벤치마크 1~10등 모델 정도면 충분히 고점이라고 생각한다. PSNR은 이제 사람 눈으로 보면 거의 티가 안날정도로 충분히 높아졌다고 생각한다. 이젠 압축 기능을 활용한 실용적인 솔루션 개발이나, 경제성을 고려한다면 Pruning, Quantization, Knowledge Distillation처럼 어느정도의 퍼포먼스 감소를 감수하더라도 모델 경량화도 연구를 해야하지 않나 싶다..
