강화학습의 종류
- 강화학습의 종류
- 가치 기반의 강화학습 (value-based)
- 정책 기반의 강화학습 (policy-based)
- 가치 기반의 강화학습
- 최적의 큐함수는 벨만 최적 방정식을 이용한 시간차 예측을 이용
- 큐함수의 수렴: 시간차 오차가 0이될때 -> 예측값이 타겟값에 가까워지도록 학습
- DQN (Deep Q Network)
- 합성곱 신경망(CNN)을 이용해 상태마다 각 행동의 큐함수 값들을 근사
- 장점:
- 모든 상태와 행동에 대한 큐함수 값을 따로 저장하지 않고 큐함수값에 대한 추정 수행
- 많은 상태와 행동이 존재하는 환경에서도 좋은 성능을 보이도록 학습이 가능
- 흐름
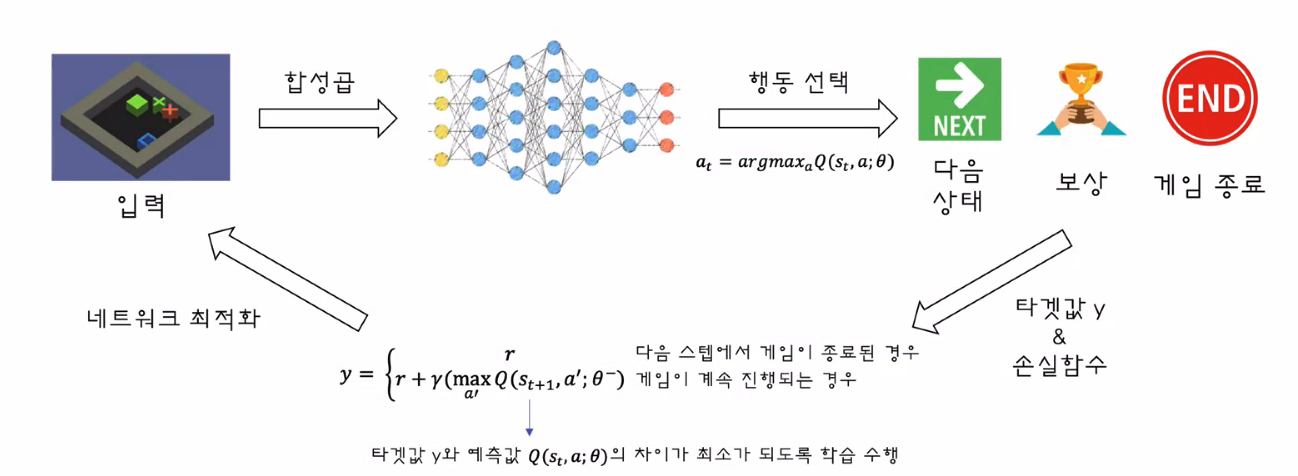
- DQN 알고리즘 기법
- 경험 리플레이 (Experience Replay)
- 경험을 데이터로 사용 (현재상태, 현재 행동, 보상, 다음 상태, 게임 종료 정보) -> 리플레이 메모리에 저장
- 매 스텝마다 리플레이 메모리
- 장점: 전체 경험에
- 타겟 네트워크 (Target Network)
- 일반 네트워크: 행동을 결정하거나 큐함수값을 예측
- 타겟 네트워크: 학습에 필요한 타겟값을 계산, 매 특정 스탭마다 한번씩 일반 네트워크값을 복제
- 경험 리플레이 (Experience Replay)

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)