[Day1] 2021/08/09
강의 리뷰
-DL Basic 1강: 딥러닝 기본용어 설명 - Historical Review
- good deep learner의 조건
- Implementation Skill: pytorch
- math skill: 선형대수, 확률
- 최근 논문들을 많이 알기
- 딥러닝의 필수요소
- 데이터
- 모델
- loss 함수
- 알고리즘
- Historical Review
- 2012: Alexnet
- 2013: DQN
- 2014: Encoder/Decoder, Adam
- 2015: GAN, ResNet
- 2017: Transformer
- 2018: Bert
- 2019: Big Language Models(GPT-X)
- 2020: Self-Supervised Learning
-DL Basic 2강: 뉴럴 네트워크 -MLP(Multi-Layer Perceptron)
- 신경망: 행렬의 비선형 연산을 하는 함수 근사 모델
- Linear Neural Networks: 선형회귀 개념을 이용, 층을 깊게 쌓아서 표현, 활성함수를 이용해 근사.
- 다층 신경망(MLP): 두개 이상의 층
- 손실함수: 회귀- MSE, 분류- CE, 추론- MLE
과제
- [필수과제] MLP Assignment
- Mnist 데이터 train: 60000, test: 10000
- Batch_Size= 256 (+ Shuffle)
- Model - MultiLayerPerceptron
xdim = 784, hdim = 256, ydim = 10
linear를 2개
Forward(X -> lin_1 -> Relu -> lin_2) -> CrossEntropyLoss -> opti: Adam
피어세션
- 질문:
Q : 필수과제에서 Train 데이터셋에서는 /255로 정규화를 해주지 않았지만 test셋에서는 /255로 정규화 한뒤 테스트 한 이유? A : 과제 베이스 코드 작성중 실수라고 생각됨. 추후에 질의응답으로 질문
Q : Kaiming_normal에 대하여 A : 파라미터 초기화의 한 방법
Q : 문자열 처리에서 정규식 사용 유무의 속도차이와 complie A : 정규식을 사용하면 문자열 처리보다 속도가 느려지지만 코드를 매우 단순화 시킬 수 있어서 자주 사용한다. 자주 사용되는 패턴일 경우에는 패턴을 complie해서 사용하는게 바람직하다. - 계획:
질문은 피어세션에서 질문을 슬랙 스레드로 남기고 답변,
Computer science 스터디를 진행하는 대신 Computer science 질의 응답도 진행
마무리
본격적으로 딥러닝의 입문단계를 배우는 한 주의 시작이다. 첫날이라 사실 가벼운 느낌은 있었지만 피어세션에서 다른 분들과 얘기를 나눠보면 긴장해야겠다는 느낌이 든다.
[Day2] 2021/08/10
강의 리뷰
-DL Basic 3강: Optimization
- gradient descent: w와 b의 편미분을 빼서 학습하여 local minimum을 구하는 방법
- Generalization(일반화): 학습 반복은 training error가 줄어드는데, 이때 test error는 오히려 성능이 떨어질 수 있다. 이때의 차이를 generalization gap이라고 한다.
- overfitting(과적합): 학습 데이터에 잘 맞췄지만, 네트워크가 다소 이상함, uderfitting: 학습을 적게 시키거나 너무 간단한.
- Cross-validation: train,test 데이터와는 별개로 학습시 확인용으로 따로 데이터를 쓴다.
Bias and Variance: 평균과 떨어진 정도, 분산되어 있는 정도. 완전한 반지례는 아니지만 그런 양상을 보임. 따라서 적정값을 찾아줘야 함. - bootstrapping: subsampling을 통해 여러 모델을 만들어 유추를 하는 방법.
- bagging: 학습 데이터를 여러개 만들고 bootstrapping을 하는 방법.
- bosting: 모델을 간단하게 만들고 학습데이터의 일부를 이용하고 나머지 데이터들에 대해 모델을 만든후 두 모델을 합침.
- Gradient Descent Methods
- Stochastic gradient descent: 하나의 샘플을 통해서 업데이트
- Mini-batch gradient descent: 일부를 사용
- Batch gradient descent: 전체를 활용.
:적정한 batch-size를 찾는 것이 매우 중요하다. 크면 sharp-minimum, 작으면 flat-minimum
- Grdient decent:
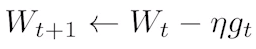
: lr을 적절히 잡는게 어려움 - Momentum:
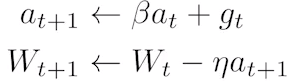
: 관성을 이용하는 optimiztion. 모멘텀이 포함된 gradient. - Nesteroc Acceleated Gradient:
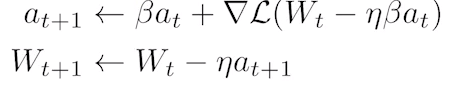
:gradient를 계산할때 lookahead gradient를 계산. - Adagrad:
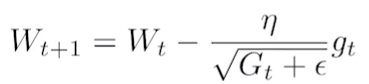
: 많이 변한 parameter는 적게, 적게 변한 것은 많이 변화 시킬때 사용. - Adadelta:
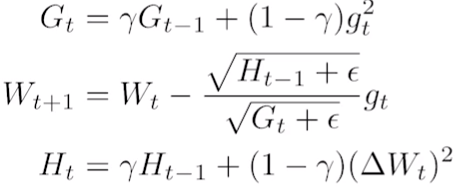
: Adagrad의 Gt이 너무 커지는 것을 방지하는 방법 중 하나. lr이 없어서 잘 활용하지는 않는다. - RMSprop:
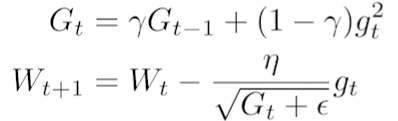
: 논문으로 나오진 않았지만, 하나의 방법. - Adam:
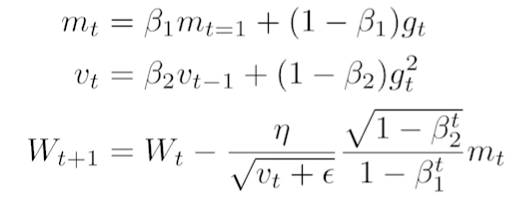
: lr과 momentum을 같이 활용하는 방법. - Regularization:
- Early stopping: validtion error가 재 증가하기전에 학습을 멈추는 방법.
- Prameter Norm Penalty: 함수를 최대한 부드러운 함수로 봄.
- Data Augmentation: 일반적으로 데이터가 많을수록 학습이 잘 됨. 따라서 데이터 셋을 회전,확대 등을 통해 늘리는 방법.
- Noise Robustness: 입력데이터와 웨이트에 노이즈를 넣는 방법. 의외로 학습효과가 좋음!
- label Smoothing: 임의의 두개의 학습 데이터의 입출력을 섞어서 쓰는 방법.
- Dropout: 몇몇의 뉴런을 0으로 바꿈.
- Batch Normalization: layer의 statistic을 정규화시키는 방법.
과제
-
optimization: Regression with Different Optimizers
-
Model: layer에 linear_regression, 부드럽게 해주기위해서 tanh()를 사용, Kaiming으로 w초기화, bias는 0으로.
-
optimizer를 sgd, momentum, adam을 각각 사용.
-
Train:
# Update with Adam y_pred_adam = model_adam.forward(batch_x) loss_adam = loss(y_pred_adam,batch_y) optm_adam.zero_grad() loss_adam.backward() optm_adam.step() -
-
결과:
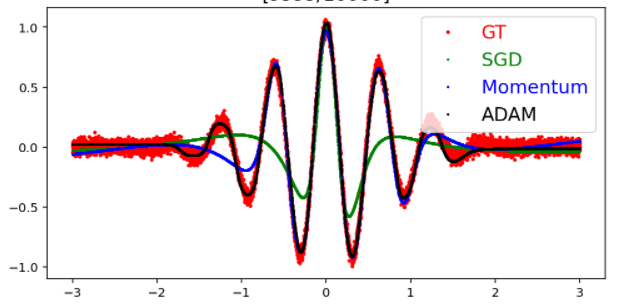
: Adam은 momentum과 adaptive lr을 같이 써서 결과가 좋고 빠르다.
피어세션
Q : Bagging에서 데이터를 랜덤 샘플링할때 만약에 샘플링된 데이터셋들이 같은 분류타입을 가지게 되면 학습이 오히려 비효율적이게 되지 않나요?
A : Bagging의 특성상 input의 작은 변화가 output의 큰 변화를 일으킬 때 -> bagging 효율적, stable classifier + large dataset 인 경우, bagging은 더 비효율적이다
Q : 파이토치 데이터 전처리에서 이미지 데이터는 torchvision.transforms 쓰면될것 같은데, 이미지 뿐만 아니라 보통 숫자형이면 똑같이 torchvision 쓰나요? 아니면 사이킷런 쓰나요?
A : torchvision은 이미지 전처리에서 유용한 함수가 있고, 사이킷런에는 표준화, 정규화 등 함수를 지원하고 있기에 각각 필요에 맞게 쓰면된다.
Q : 머신러닝과 딥러닝에 차이는 무엇인가요?
A:

마무리
- 도메인 특강: Attention is All you need 논문 여러번 읽어보기, 관심없는 분야도 일단 들어보고 해보기, CS전공 지식도 갖추기...
- 마스터 클래스: data visualization의 중요성.
- 도메인 선택에 대한 고민이 굉장히 컸다. 가장 인상 깊었던 말씀 중 하나는 일단 여러분야의 강의를 참여하여 시도해보라는 것이었다. 부족한 정보와 경험으로 고민만 하고 있을 시간에 뭐라도 하나 더 경험해봐야겠다.
[Day3] 2021/08/11
강의 리뷰
-DL Basic 4강: Convolutional Neural Networks
- Convolution 연산:
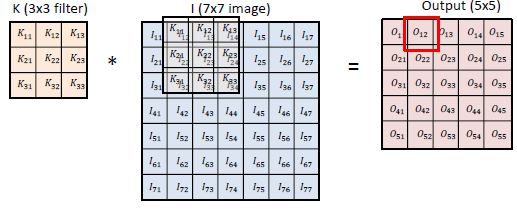
- RGB Image convolution:

- Stride:
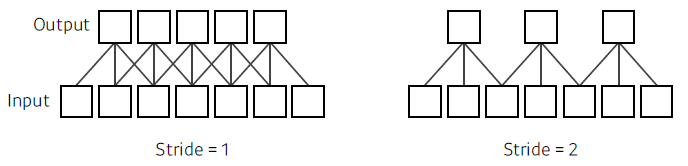
- Padding:
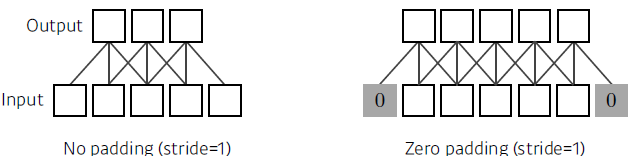
- CNN은 Covolution layer, pooling layer와 fully_connected layer로 이루어졌다. 이때, Covolution layer와 pooling layer는 feature 추출을, fully_connected layer는 분류와 같은 결정을 한다.
- Parameters of Model
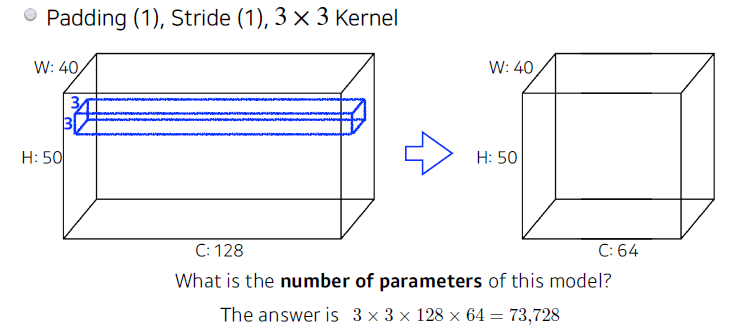
: 위 모델의 파라미터 수는 3 * 3 * 128 * 64 이다. - 1*1 convolution을 하는 이유?
- Dimension reduction
- parameter수 감소
-DL Basic 5강: Modern Convolutional Neural Networks
- AlexNet:
- Rectified Linear Unit(ReLU) 활설함수.
- 2 GPU
- LRN, Overlapping pooling
- Data Augmentation
- Dropout
- VGGNet
- 3 * 3 convolution: 3 * 3 을 두개 쓰는 것은 5 * 5 하나 쓰는것과 같은 receptive field를 가지지만 feature수가 훨씬 적다.
- GoogleNet
- Network-in-network(NiN)
- Inception block: 1*1 convolution을 통해 parameter 수를 줄임.
- ResNet
- Add an identity map(skip connetion) : 깊게 쌓아도 학습이 가능.
- Add an identity map After nonlinear activations
- Batch Normalization After convolutions
- Bottleneck architecture: output feature map의 channel의 차원을 맞춤.
- DenseNet
- concatenation instesd of addition: 채널이 커짐
- Desnse Block: concatenation
- Transition Block: 1*1 convolution으로 차원 축소.
-DL Basic 6강: Computer Vision Applications
-
Semantic Segmentation: 이미지의 모든 픽셀이 어떤 라벨에 해당하는지 보는 것.
+ FUlly Convolutional Network: Dense layer를 없앤 Network, hear map를 출력.
+ Deconvolution(conv transpose): convolution 역연산.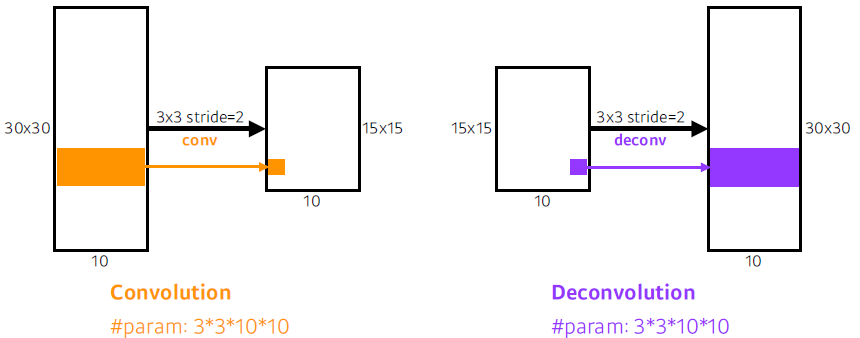
-
Detection
- RCNN: 2000개의 region을 뽑고, 크기를 맞춘 후 feature추출(AlexNet)하고 분류(linear SVMs).
- SPPNet: RCNN과 다르게 CNN을 한번만.
- Fast RCNN: CNN을 한번만, 각각에 대해 ROI Pooling, 분류와 bounding-box regressor 출력.
- Faster RCNN: Region Proposal Network + Fast R-CNN
- Region Proposal Network:
-
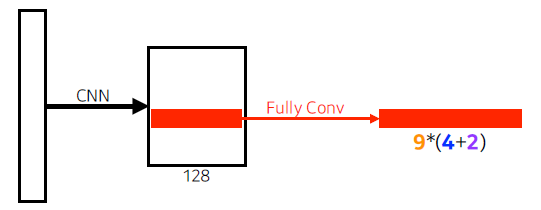
- YOLO: 이미지에서 바로 분류. bounding box를 따로 뽑는 단계가 없음. 입력이미지를 S*S그리드로 나눔. 각각에서 C개의 class로 => S*S*(B*5+C)사이즈의 tensor로.
과제
-
CNN model:
# Convolutional layers self.layers = [] prev_cdim = self.xdim[0] for cdim in self.cdims: # for each hidden layer self.layers.append( nn.Conv2d(in_channels = prev_cdim, out_channels = cdim, kernel_size= self.ksize, stride = (1,1), padding = self.ksize//2)) if self.USE_BATCHNORM: self.layers.append(nn.BatchNorm2d(cdim)) # batch-norm self.layers.append(nn.ReLU(True)) # activation self.layers.append(nn.MaxPool2d(kernel_size=(2,2), stride=(2,2))) # max-pooling self.layers.append(nn.Dropout2d(p=0.5)) # dropout prev_cdim = cdim # Dense layers self.layers.append(nn.Flatten()) prev_hdim = prev_cdim*(self.xdim[1]//(2**len(self.cdims)))*(self.xdim[2]//(2**len(self.cdims))) for hdim in self.hdims: self.layers.append(nn.Linear(prev_hdim,hdim,bias = True)) self.layers.append(nn.ReLU(True)) # activation prev_hdim = hdim # Final layer (without activation) self.layers.append(nn.Linear(prev_hdim,self.ydim,bias=True)): CNN 구현의 필수적이며 앞으로도 쓸 일이 많을 것 같아 익숙해져야겠다.
피어세션
Q : colab에서 함수 설명 보는 법?
A : 함수앞이나 끝에 ? 입력하면된다. ex)?np.where()
Q : 왜 Relu함수가 vanishing gradient 문제에 효과적인가?
A : sigmoid나 tanh는 값이 크게되면 기울기가 0에 가까이 가지만 relu함수는 0보다 큰값이면 언제나 기울기가 1이기 때문이다. 그래서 sigmoid는 분류문제에서 제일 마지막단에 정규화된 pixel을 출력하기 위해서 많이 사용한다.
Q : tensorflow나 pytorch 둘 중 하나만 잘해도 되나요?
A : keras같은 라이브러리에서만 구현되있고 pytorch에서 구현되지 않는 함수를 구현하려면 tensorflow를 알고 참고하는게 좋기 때문에 둘다 아는 것이 좋다.
마무리
- github 특강1: 들었던 강의 중에 가장 차근차근 배우는 느낌이 들었다. 물론 답답한 분들도 있었겠지만 github과 덜 친한 나로써는 매우 흥미로운 시간이 되었다. 다른분들이 이고잉님을 이미 알고 계신 듯 했는데, 혼자만 몰랐던 것 같아 앞으로 좀 더 관심을 넓혀야겠다는 생각이 들었다.
[Day4] 2021/08/12
강의 리뷰
-DL Basic 7강: Sequential Models - RNN
-
Sequetial Model
+ Naive sequence model:
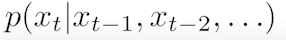
+ Autoregressive model: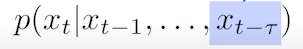
+ Markov model:
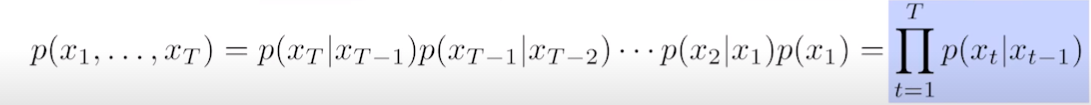
- latent autoregressive model:
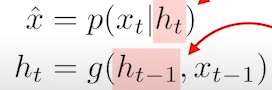
- latent autoregressive model:
-
Recurrent Neural Network
: 과거의 정보가 취합될때 오래된 과거가 영향을 주기 힘듬. -> LSTM이 이를 보완하기 위해 출현. -
LSTM

- Forget gate: 어떤 정보를 버릴지
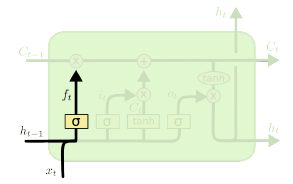
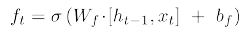
- Input gate: 어떤 정보를 받을지
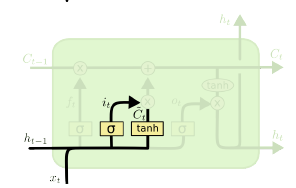
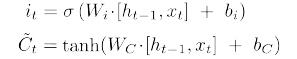
- Update cell: cell state를 업데이트
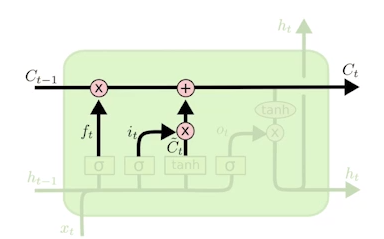
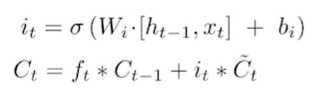
- Output gate: 업데이트된 cell state를 이용해 출력
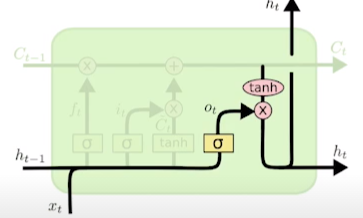
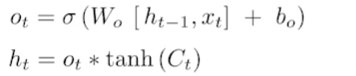
- Forget gate: 어떤 정보를 버릴지
-
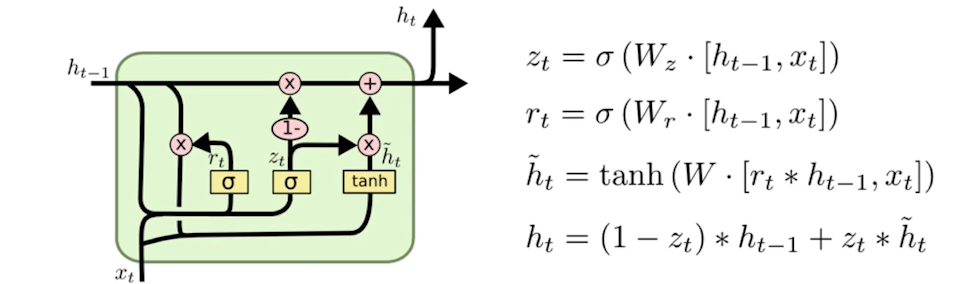
Gated Recurrent Unit
: gate가 2개, reset gate와 update gate
-DL Basic 8강: Sequential Models - Transformer
-
Sequential modeling이 어려운 이유:
몇개가 빠져있거나
대응구조가 완벽하지 않거나
중간에 다소 밀리거나 한 경우 -
Transformer
: 재귀적인 구조가 없고 attention이라는 구조를 활용한 모델- 분류, detection에도 활용된다.
- Transformer의 대략적인 작동구조:
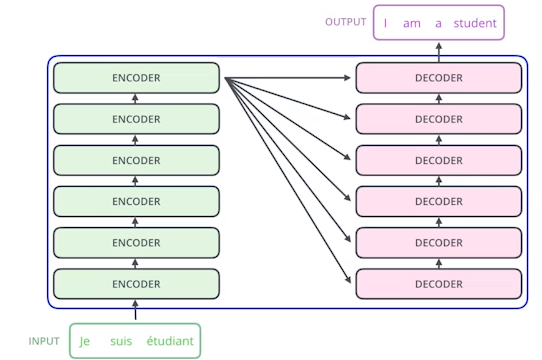
- Encorder: ( Self-Attention -> Feed Forward Neural Network)
- self-attetion으로 각각의 단어를 feature vectors로 encode.
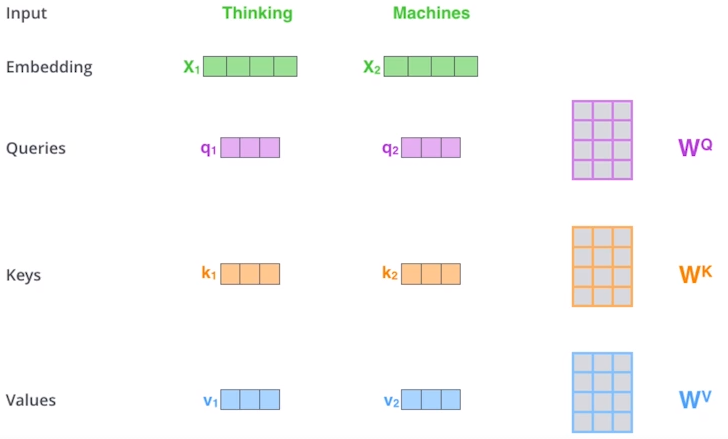
-
한 단어에 q,k,v벡터를 만든다. -> score를 구함. score = q * k -> 8로 나눔 -> softmax => attention weight를 구함 -> value벡터와 weight sum = encoding vector
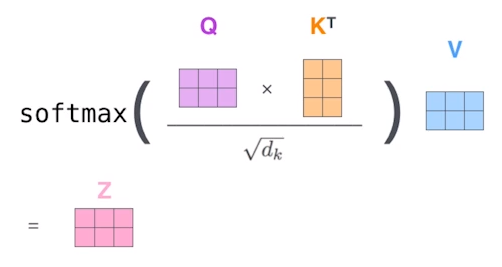
-
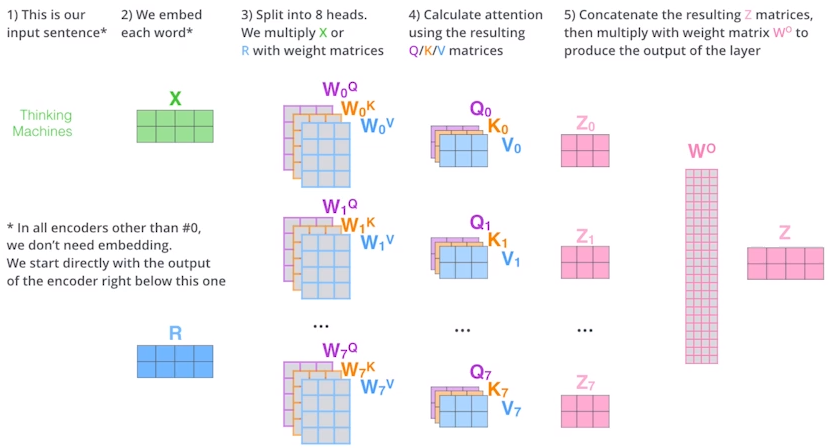
Multi-headed attetion(MHA): n개의 벡터를 만듬.
-
posiotional encoding이 필요한 이유?
: order-independent -
Encorder의 전체 구조
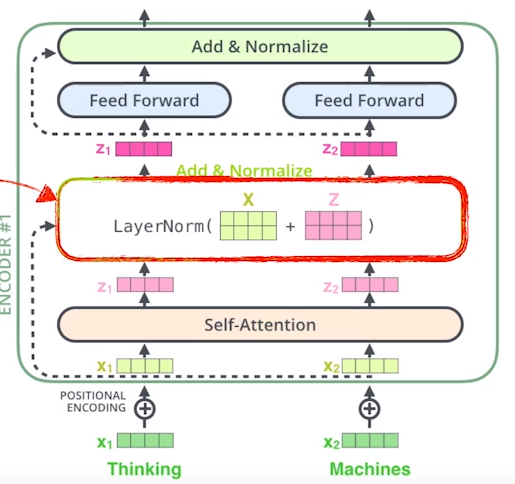
-
Transformer 는 상위단어의 key와 value벡터를 decorder로 전달한다.
-
output sequence는 autoregressive하게 나온다.
-
decorder에서 self-attention layer는 커서 마스킹을 활용해서 미래의 정보를 쓰지 않는다.
-
decorder 구조:
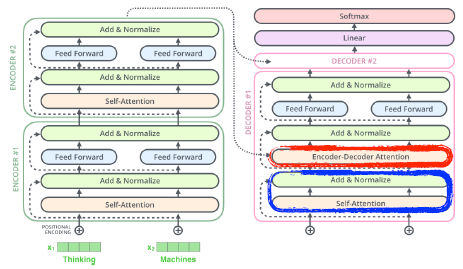
피어세션
- 알고리즘 문제풀이: DFS,BFS
마무리
-
github 특강 2: github와 VScode를 통한 협업 방법을 설명듣고 실습하면서 재밌었다. 왜 사람들이 이고잉님을 연예인처럼 모시는 줄 알 것 같다. 초보자들을 배려심이 일단 너무 좋다. 물론 오늘 수업으로 github를 완전 정복하진 못했으니 간간이 연습해서 익숙해져야겠다.
-
멘토링: 두번째 멘토링이지만 멘토님의 열정에 감탄했다. 오늘 backpropagation을 line-by-line 설명해주셨는데 정말 깔끔히 복습된 느낌이였다. 그리고 CS를 양식이라도 미리미리 준비하라고 저번 멘토링에 이어 이번에도 강조해주셨으니 쓸 내용은 딱히 없지만 준비해보는 걸루..
-
오피스아워: 사실 이번 선택과제는 손대기가 어려웠고 설명을 들었는데도 쉽지않아서 주말에 다시 한번 복습해보고 모르는 부분은 멘토님께 질문해야겠다.
벌써 2주차가 끝나간다. 마음이 점점 조급해지는데 오늘 많은 멘토분들이 조급할 필요없고 그냥 꾸준하게 지금해야할 것에 집중하라고 하셨다. 덕분에 마음이 많이 안정되었고, 아직 한 주가 끝나진 않았지만 주말 복습 계획을 미리미리 짜서 이제까지 배운 내용을 내 것으로 만드는 시간을 가져야겠다.
[Day5] 2021/08/13
강의 리뷰
-DL Basic 9강: Generative Models 1
-
Learning a Generative Model
: 강아지 이미지들이 주어졌을때, 확률 분포 p(x)에 대해 알고자 한다.- Generation: xnew는 강아지 같아야한다.
- Density estimation: p(x)는 강아지일때 높아야하고, 그렇지 않으면 낮아야한다.(anomaly detection, 이상행동 감지에 활용) - explicit model
- Unsupervised representation learning: 이 이미지들이 공통점이 무엇이인지 배움. (feature learning)
-
p(x)를 알기 위한 Basic Discrete Distributions
- Bernoulli distribution: 동전던지기
: parameter는 1개 필요. - Categorical distribution: m-sided 주사위
: parameter m-1개 필요. (나머지는 1에서 빼면되니까)
- Bernoulli distribution: 동전던지기
-
Conditional Independence

- chian rule을 이용할때, parameter의 수 = 2^n - 1
- markov assumption의 경우 2n-1.
- 이와 같은 모델을 auto-regressive model이라고 한다.
-
NADE: Neural Autoregressive Density Estimator
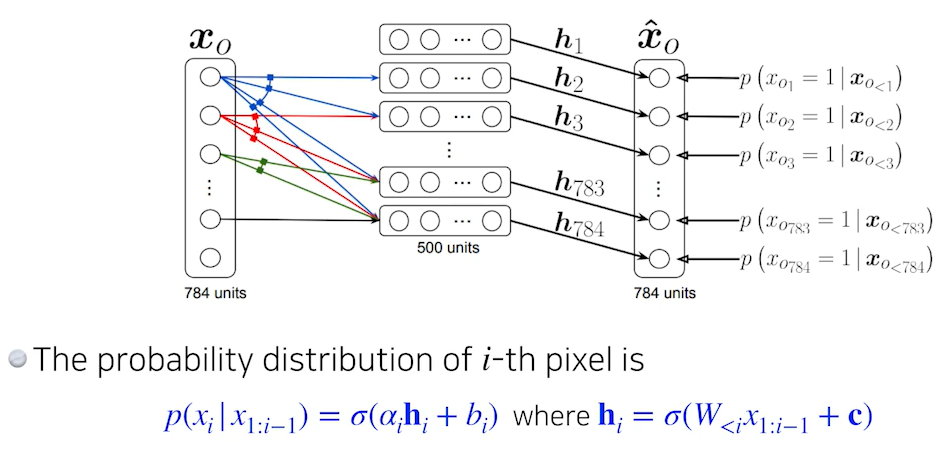
- NADE는 generation뿐만아니라 확률을 계산할 수 있는 explicit model이다.
- 784개의 픽셀로 이루어진 bianary 이미지가 있다고 할때, conditional probability를 independent하게 구해 joint probability를 계산할 수 있다.
- continuous output일때는 마지막 layer에 gaussian mixture model을 활용하여 continuous distribution을 만든다.
-
Pixel RNN
+ RNN을 이용한 autoregressive model.

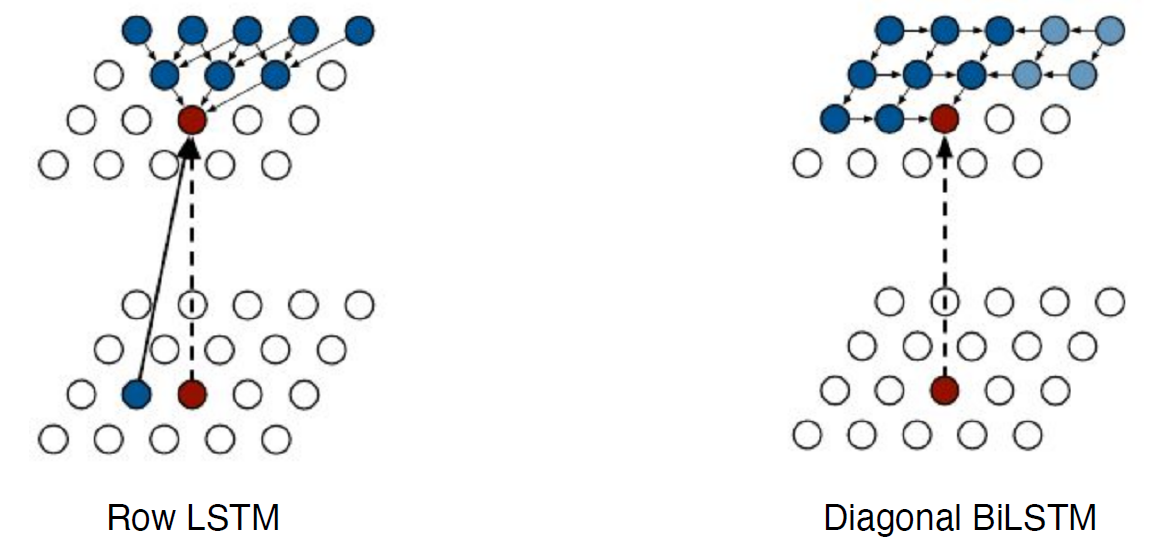
-DL Basic 10강: Generative Models 2
-
Variational Auto-encorder
- Variational inference(VI): VI의 목적은 posterior distribution을 가장 잘 맞춘 variational distribution을 optimize하는 것이다.

- VI에서는, KL divergence를 활용해서 variational distribution과 true posterior를 줄인다.
- VI는 ELBO를 maximizing하여 objective를 최소화한다.

- VA는 interactable model이다.(likelihood를 구하기 어려운)
- prior fitting term은 미분가능해야해서 diverse latent prior distribution을 이용하기 어렵다.
- 그래서 isotropic Gaussian을 사용해야한다.
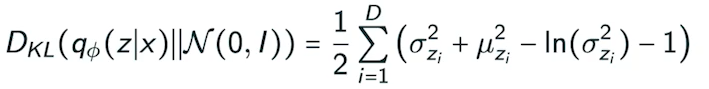
- Variational inference(VI): VI의 목적은 posterior distribution을 가장 잘 맞춘 variational distribution을 optimize하는 것이다.
-
Adversarial Auto-encoder
: GAN을 활용해서 latent distribution사이의 분포를 맞춰준다. -
GAN(Generative Adversarial Network)
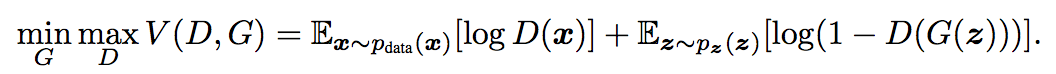
- Generator와 discirminator의 minimax game.
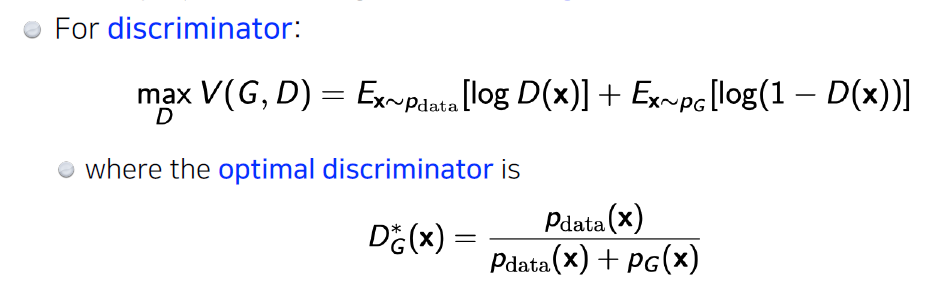

- GAN 이후에 DCGAN, Info-GAN, Text2Image, Puzzle-GAN, CycleGAN, Star-GAN, Progressive-GAN등이 나왔다.
- Generator와 discirminator의 minimax game.
피어세션
- 팀회고를 통해서 우리 팀의 좋은점과 개선해야 할 점을 찾아봤다. 팀원들 모두 소통에 적극성을 가져야할 필요가 있다고 느꼈다.
- 스페셜 피어세션: 우리 팀말고 다른 팀원들을 만나보며 그들의 열정을 느꼈고, 다른 팀들은 어떻게 피어세션을 하고있는지 알아봤는데 어떤 팀은 todo list를 공유한다고 했다. 서로 자극도 되고 방향성도 찾는 기회가 되어 우리 팀도 시도해보기로 했다.
마무리
- 마스터클래스: 솔직하게... 정말 못 알아들었다. 갑자기 단계가 확 튄 느낌..현재로서 할 수 있는 결정은 열심히해서 이 강의를 다시 들어보고 싶다..
- 일주일이 정말 빠르게 지나갔다. 이번 주말에 Transformer논문을 읽어보고 알고리즘 공부를 할 것이며 CS를 어떻게 공부해야할지 생각을 해볼 계획이다.
