[week12] 2021/10/18-22
강의 리뷰
Semantic Segmentation 3강 - Semantic Segmentation의 기초와 이해
- FCN
- VGG를 backbone으로 사용.
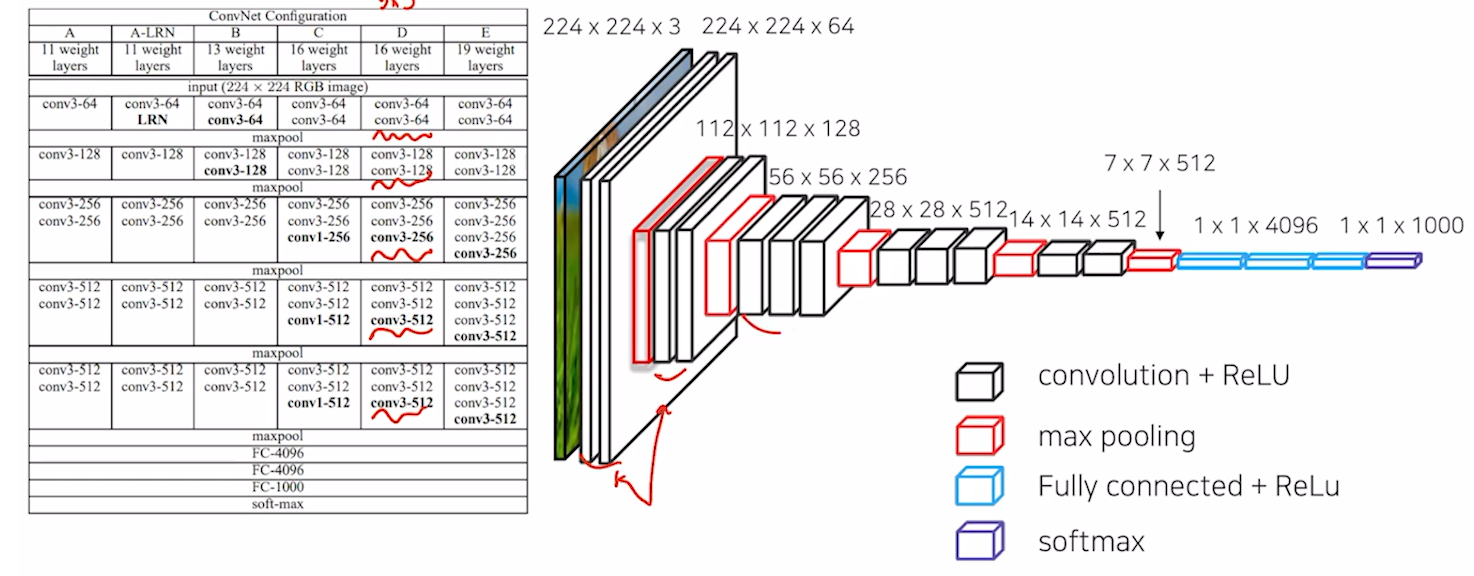
- FC layer를 convolution으로 대체.
: 각 픽셀의 위치정보를 해치지 않은채로 특징 추출. 이미지의 height나 width와 상관이 없음. - Transposed Convolution(upsampling)을 이용해서 Pixel Wise Prediction수행.
- FCN의 성능향상을 위한 방법
: MaxPooling에 의해서 잃어버린 정보를 복원해주는 작업을 진행. Upsampled size를 줄여주기에 좀 더 효율적인 이미지 복원 가능. - 평가지표: Pixel Accuracy = True pixel/Total pixel. mIoU.
- VGG를 backbone으로 사용.
- 결론
- 11을 77 conv로 바꾸면, padding이 없기때문에 출력값이 matching이 안됨. 따라서 입력에 zero padding 100으로 입력크기를 키워줌. crop image로 출력을 맞춰줌.
Semantic Segmentation 4강 - FCN의 한계를 극복한 모델들 1
-
FCN의 한계점
- 객체가 크거나 작은 경우 예측을 잘하지 못함.(convolution자체의 receptive field의 문제 때문)
- 디테일한 모습들이 사라지는 문제. (Deconv절차가 너무 간단해서)
-
Decoder 개선.
-
DeconvNet
- Decoder와 Encoder를 대칭으로 만든 형태

- 하나의 conv는 conv-BN-ReLU를 포함. Deconv는 unpooling-deconvolution-ReLU로 이루어짐.
- pooling은 노이즈를 제거하는 장점이 있지만, 정보가 손실되는 문제가 존재함.Unpooling은 지워진 경계의 정보를 복원하여 디테일을 표현. 하지만 sparse한 activation map을 가지기 때문에 Transposed convolution을 해야함.
- Deconvolution(Transposed convolution): input object의 모양을 복원. 얕은층의 경우 전반적인 특징을, 깊은 층의 결루 복잡한 패턴을 잡아냄. -
SegNet
: segmentation의 realtime이 중요함을 적용

- FC layer를 제거하여 파라미터 수를 줄여 학습시 속도를 향상.
-
-
Skip connection을 적용한 모델
- FC DenseNet
- Unet
-
Receptive Field를 확장시킨 models
- DeepLab v1

- Receptive field: 서로 다른 RF에서는 정보량이 다르기 때문에 segmentation결과가 다르다. conv와 Max pooling을 적절히 반복하면 RF를 넓힐 수 있다. 단 Max pooling을 할경우 upsampling후 activation 결과가 좋지 않을 수 있다. => 이미지크기를 많이 줄이지 않고, 파라미터 수도 변함이 없는채로 RF를 넓히는 방법: "Dilated Convolution"
- Dilated Convolution
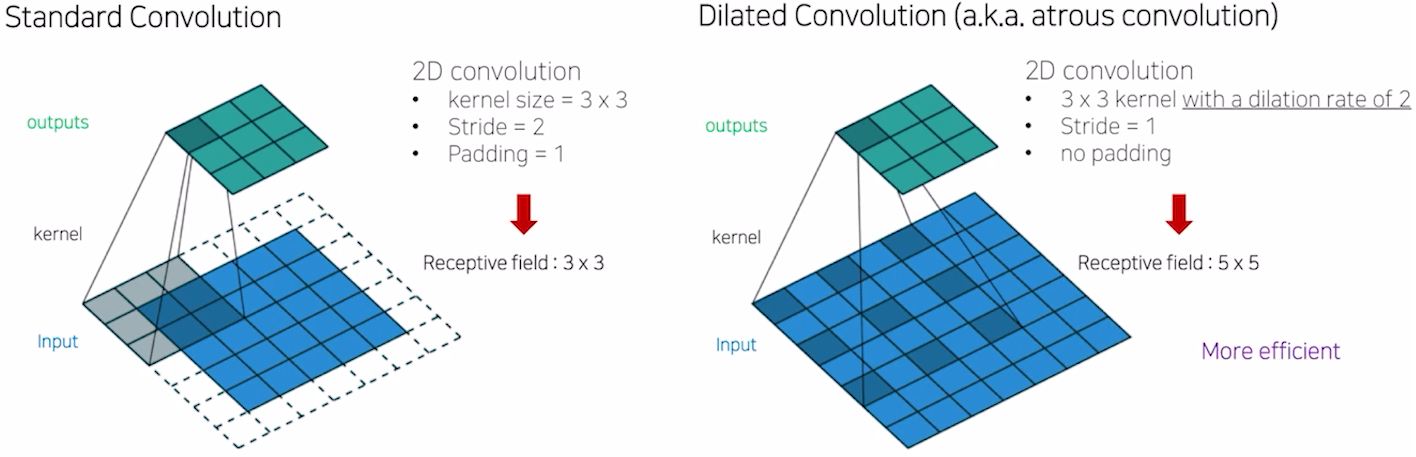
- Bilinear Interpolation
: 내분을 통해서 채워주는 과정.
- Dense CRF
: bilinear interpolation은 픽셀단위의 정교한 segmentation이 어려워 경계선을 정교하게 만드는 방법. - DilatedNet

- DeepLab v1
Semantic Segmentation 5강 - FCN의 한계를 극복한 모델들 2
- DeepLab v2
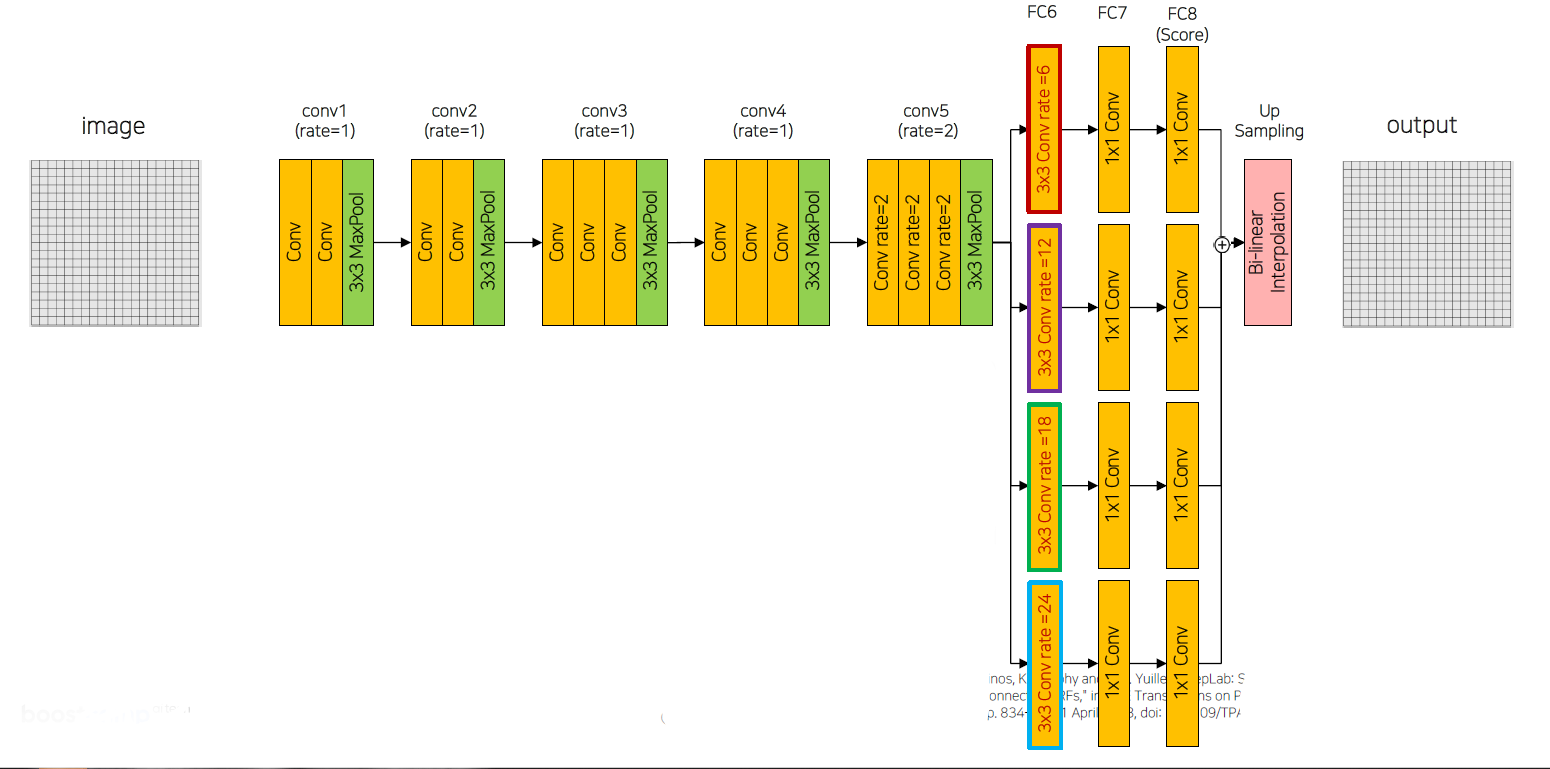
- backbone은 기존과 동일. ResNet101.
- v1의 average pooling layer가 사라지고, 서로 다른 네가지 dilated convolution rate를 가지는 branch형태(ASPP)를 가지고 뒤에서 sum.
- conv에서 나온 feature를 rate에 따라서 크기가 다른 object에 각각 집중하여 성능 향상.
- PSPNet
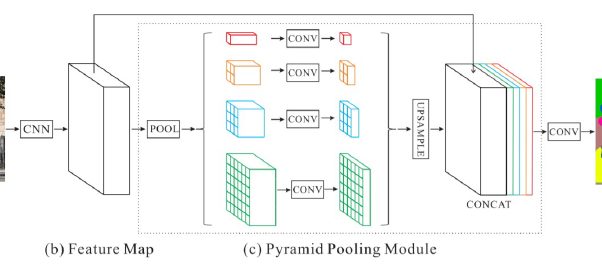
- 객체들간의 관계를 제대로 캐치하지 못하는점, 비슷한 클래스를 혼동하는 문제와 무늬가 비슷하고 작은 객체를 잘 분류하지 못하는 점을 개선하기위해 출현. => global한 context를 검출
- FCN은 maxpool하였지만, 실제의 receptive field가 이론과는 다름. => global average pooling도입.(주변정보를 파악해서 객체를 예측하는데 사용)
- sub-region 각각에 conv진행하여 channel이 1인 feature map생성.그후 upsamplinggn, concat.
- Deeplab v3
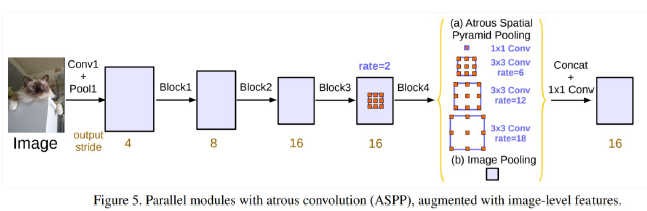
- ASPP에 global average pooling을 추가. 결과:1*1 => bilinear interpolation적용.
- 네개의 conv결과에는 zero padding을 넣어서 크기가 변하지 않도록함.
- Deeplab v3+
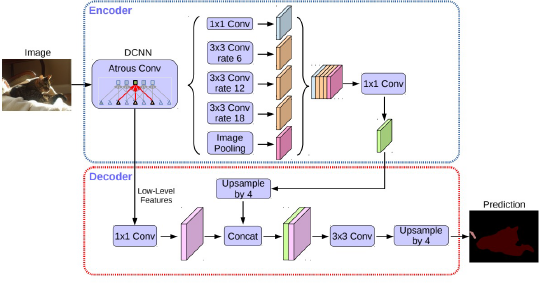
- backbone: 수정된 Xception사용(encoder)
- Encoder와 Decoder구조를 사용. Encoder에서 spatial dimension의 축소로 인해 손실된 정보를 decoder에서 점진적 복원
- Astrous seprable convolution을 적용한 ASPP모듈 사용.(encoder)
- backbone내 low-level feature와 ASPP모듈 출력을 모두 decoder에 전달(encoder)
- ASPP모듈의 출력을 (bilinear)upsampling하여 low-level feature와 결합.(decoder)
- 결합된 정보는 conv와 upsampling하여 최종결과 도출(decoder)
- 기존의 단순한 upsampling연산을 개선하여 디테일을 유지(decoder)
- Modified Xception:
(original) Depthwise Seperable Convolution(각 채널마다 다른 filter를 사용하여 conv후 결합하는 depthwise conv + 1*1conv인 pointwise conv)을 사용.
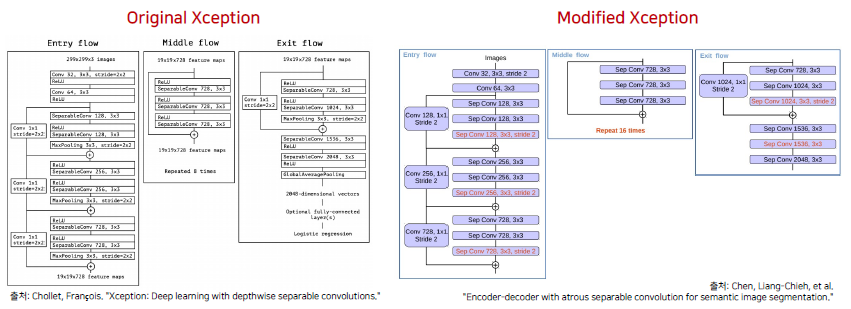
(modified) entry flow의 max pooling -> Depthwise Seperable Conv + BN + ReLU, exit flow의 maxpooling -> stride=2의 depthwise seperable conv + BN + ReLU
Semantic Segmentation 6강 - High Performance를 자랑하는 Unet계열의 모델들
- U-Net
- 데이터 부족의 문제와 cell segmenation(BIO계열)시 인접한 부분 경계 구분의 어려움을 개선.
- contracting path(입력이미지의 전반적인 특징)와 expanding path(줄어든 정보를 upsampling해 localization)가 대칭인 구조.
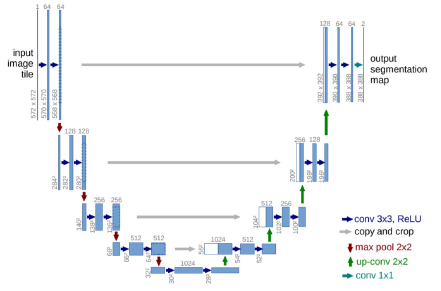
- 채널수가 2배씩 증가후 2배씩 감소.
- Contracting Path
- (3*3 conv + BN +ReLU) * 2, No zero-padding으로 patch-size감소.
- 2*2 max pooling(stride=2), feature map크기가 1/2
- maxpooling후 채널 2배 증가
- (3*3 conv + BN +ReLU) * 2, No zero-padding으로 patch-size감소. - Expanding Path
- 2*2 Up-conv사용(Transposed Conv), feature map 크기가 2배. 채널수 1/2
- contracting에서 얻은 feature map을 concat
- (3*3 conv + BN +ReLU) * 2, No zero-padding으로 patch-size감소.
- 1*1 conv, output channel 수 = class수 - Data Augmentation: Random elastic deformations
- Pixel-wise loss weight를 계산하기 위한 weight map생성. 같은 클래스를 가지는 인접한 셀을 분리하기 위해 해당 경계부분에 가중치를 제공.
- 한계점: 깊이가 4로 고정-> 최고성능보장 x. 단순한 skip connection.
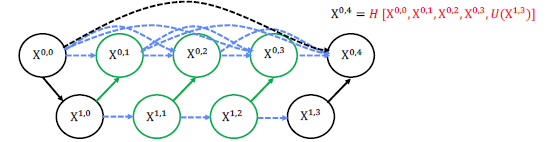
- U-Net++
- Encoder를 공유하는 다양한 깊이의 U-Net을 생성
- Skip connection을 동일한 깊이에서의 feature maps이 모두 결합되도록 유연한 feature map생성.
- Dense Skip connection도입.
- Ensemble
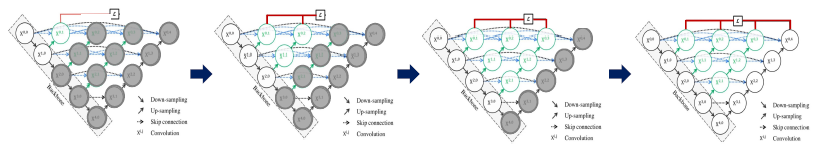
- hybrid loss = pixel wise CE + soft Dice loss
- deep supervision: 로스를 결과마다 적용.
- 한계점: 복잡하여 parameter 너무 많음. 많은 connection의 메모리 증가. 다양한 scale의 정보를 반영하기 힘듬.
- U-Net3+
- conventional: encoder로부터 same-scale feature maps받음
- inter: encoder로부터 low-level feature maps받아 풍부한 공간정보를 통해 경계 강조
- intra: decoder로부터 larger-scale의 high-level feature maps받아 어디에 위치하는지 위치 정보 구현.
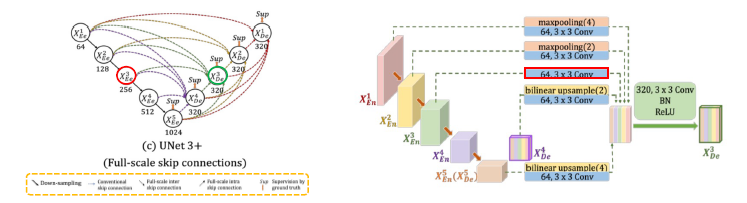
- Classification-guided Module, CGM
: low-level layer에 남아있는 background의 noise발생하여, 많은 false-positive발생. 정확도를 높이고자, extra classification task진행. high-level feature maps인 X5를 활용(Dropout, 1*1conv, adaptive max pooling,sigmoid를 통과하여 Argmax를 통해서 organ이 없으면 0 있으면 1, 얻은결과를 각 low-layer마다 나온결과와 곱). - focal loss + ms-ssim loss + iou loss
- 다른 버전의 U-Net
- Residual-UNet
- Mobile-UNet
- Eff-UNet

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)