MoveNet: Next Generation Pose Estimation with MoveNet and TensorFlow.js
0
높은 정확도를 보장하며 속도 또한 빠른 모델은 찾기 쉽지않은데, MoveNet의 속도, 모델 사이즈, 이미지 사이즈, 정확도 등의 성능을 보고 놀랐다. 0_0
출처:https://blog.tensorflow.org/2021/05/next-generation-pose-detection-with-movenet-and-tensorflowjs.html
Architecture
-
Bottom-up
-
heatmap 방식
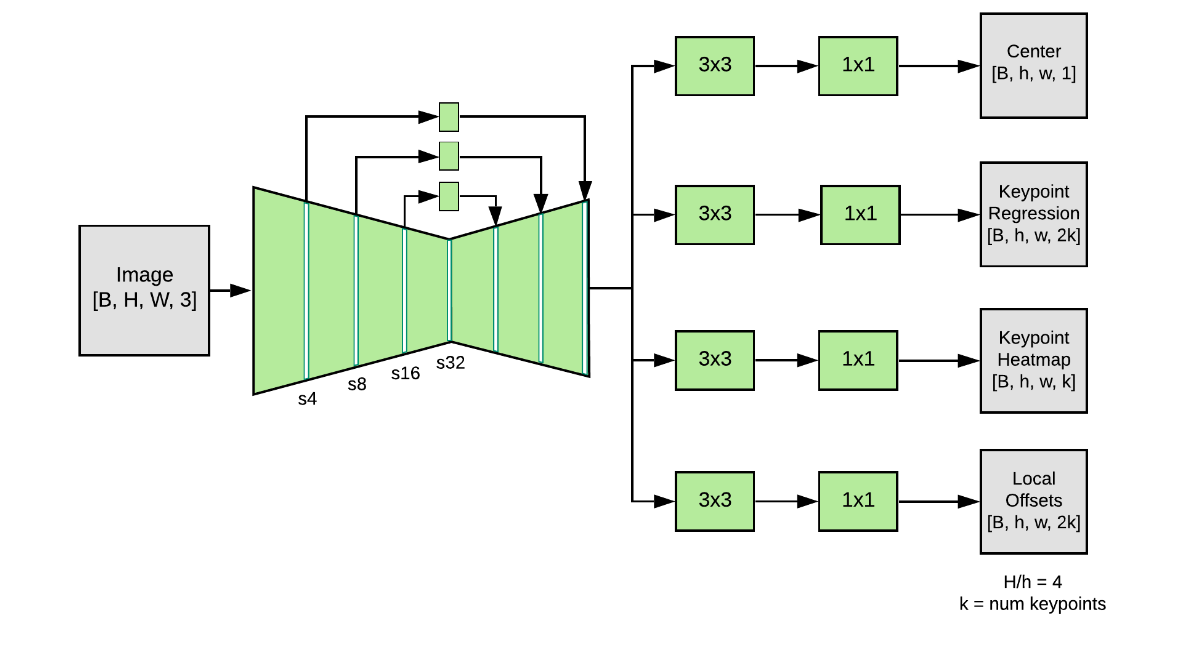
-
Feature extractor + Prediction heads
- Feature Extractor:
- MobileNetV2 (+ FPN: feature pyramid network): high resolution rich feature map
- MobileNetV2의 첫번째 레이어를 제외하고, Depthwise separable convolutions씀
- Prediction Heads(4개):
- loosely follow CenterNet
- Person Center heatmap: geometric center
- Keypoint regression field: full set os keypoints
- Person keypoint heatmap: alll keypoints
- 2D keypoint offset field
- Feature Extractor:
-
작동 방식:

- Step 1: 모든 조인트의 arithmetic mean으로 계산된 사람 객체의 중심을 찾는다. Inverse-distance로 weighted된 방식으로 가장 높은 곳을 선택.
- Step 2: 객체의 중심에 해당하는 픽셀로부터 keypoint regression output을 slice함으로써 한 세트의 사람 조인트들을 찾는다. (아직 정확도가 낮음)
- Step 3: 키포인트 히트맵의 각 픽셀은 해당 regressed 키포인트와의 거리와 반비례하는 weight가 곱해진다. 배경에 있는 사람에 대해서 낮은 점수를 줌으로 제외시키는 효과.
- Step 4: maximum heatmap values로 최종 키포인트 추론됨.
-
tf.math.top_k ->tf.math.argmax : 속도 향상
-
이미지 사이즈를 192로, 대신 intelligent cropping based on detections from the previous frame 적용
-
키포인트 추정 결과 스무딩: 자연스러운 시각화
Training Dataset
- COCO + Active(Google Dataset): +
- COCO: 64k(2명 이하)
- 크기나 장면 occlusion이 너무 다양해서, 피트니스나 댄스에는 적합하지 않다.
- Active: 23.5k(1명)
- Youtube에 가져온 영상(요가, 댄스 등)을 COCO 포맷으로 제작(Google)
- more motion blur 와 self-occlusion을 포함한 다양한 자세
- 현실의 조명, 노이즈, 모션등을 잘 포함하는 이미지들로 정제
- COCO: 64k(2명 이하)
- image size: 192 192(V.lightning), 256 256(V.Thunder)
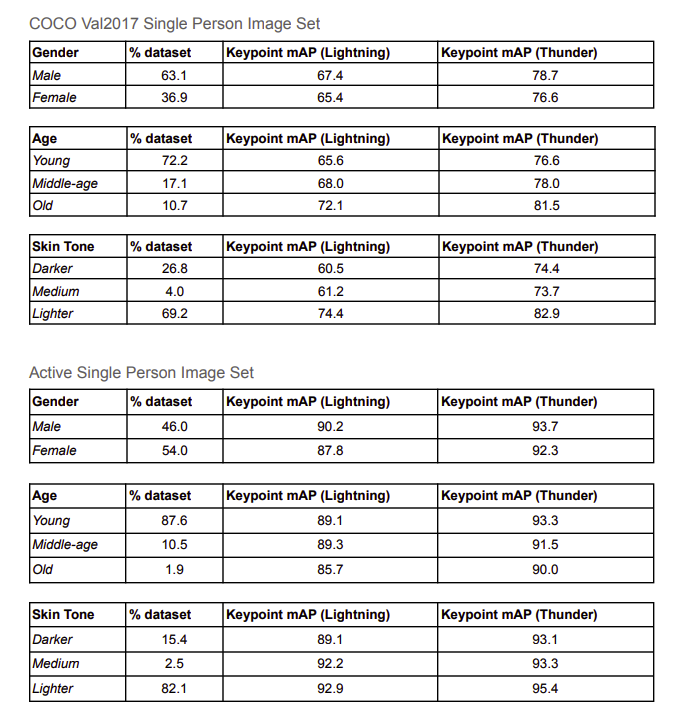
- 여기서 주장하는 바에 따르면, COCO 데이터는 너무 어렵기 때문에 정확도가 낮다.
- 개인적인 생각 1: Scale에서 문제라면 앞에 detector를 끼워준다면....? bottom-up방식이라서 사실 detector가 따로 필요없지만.. 게다가, 모델이 가볍고 매우 빠르기 때문에 디텍터가 붙어도 충분히 빠를 것으로 예상
- 여기서 주장하는 바에 따르면, COCO 데이터는 너무 어렵기 때문에 정확도가 낮다.
이후 방향
- Multiperson (이미 나옴)

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)