데이터 모델링이란?
- 현실에서 일어나는 사건들을 데이터화는 과정
- 하지만 너무 복잡하여 개념화(추상화)하여 단순하게 표현
→ 모델링을 하기 위해서는
- 고객과의 의사소통을 통해 고객의 업무 프로세스를 이해
- 업무 프로세스를 추상화하고, 분석/설계하면서 점점 상세하게 설계한다
- 업무 프로세스를 이해하고, 규칙을 정해서 데이터 모델로 표현
데이터 모델링 단계
- 개념적 모델링
- 현실에서 일어나는 사건들을 데이터 관점으로 표현
- 개념적 ERD를 산출물로 만드는 과정
- 복잡하지 않고, 중요한 부분 위주로 모델링
- 엔티티(개체)와 속성 도출
- 논리적 모델링
- 개념적 → 논리적 모델링으로 변환
- 식별자 도출, 필요한 릴레이션 정의
- 정규화 수행
- 물리적 모델링
엔티티 (Entity)
- 업무에서 관리해야하는 데이터 집합의 의미
- 저장되고 관리되어야 하는 데이터
- 엔티티는 개념, 사건, 장소 등의 명사
- 테이블
- 예) 부서, 사원
속성 (Attribute)
- 데이터의 가장 작은 논리적 단위
- 하나의 엔티티는 한개 이상의 속성으로 구성
- 엔티티의 특성, 상태 등을 기술
- 칼럼
예) 부서 엔티티의 속성: 부서번호, 부서명, …
예) 사원 엔티티의 속성: 사원번호, 사원명, …
고객, 계좌 - 엔티티
테이블 안에 있는 - 속성

Entity 특징
- 식별자
- 엔티티는 유일한 식별자가 있어야 함
- 예) 회원ID, 계좌번호
- 인스턴스 집합
- 2개 이상의 인스턴스 필요
- 예) 2명 이상의 고객 정보
- 속성
- 엔티티는 반드시 속성을 갖고 있어야 함
- 예) 계좌 안에 계좌번호, 계좌명, 예금, 개설지점, 계좌 담당자
- 관계
- 엔티티는 다른 엔티티와 최소 한개 이상의 관계
- 예) 고객은 계좌를 개설
- 업무
- 엔티티는 업무에서 관리되어야 하는 집합
- 예) 고객, 계좌
속성의 종류
- 분해여부에 따른 속성의 종류
- 단일 속성
- 하나의 의미로 구성 된 것 : ID, 이름 등
- 복합 속성
- 다중값 속성
- 단일 속성
- 특성에 따른 속성의 종류
- 기본 속성
- 원래 필드
- 설계 속성
- 데이터 모델링 과정에서 발생되는 속성
- 예) 상품코드, 지점코드
- 파생 속성
- 다른 속성에 의해 만들어지는 속성
- 기본 속성
관계 (Relationship)
엔티티간의 관련성을 의미, 존재관계와 행위관계로 분류
- 존재 관계 - 엔티티간의 상태를 의미
- 예) 고객이 은행에 회원가입 → 관리점 할당 → 할당점으로 관리점에서 고객을 관리
- 행위 관계 - 엔티티 간의 어떤 행위가 있는 것
- 예) 보험회사에서 보험상품 만듦, 가입
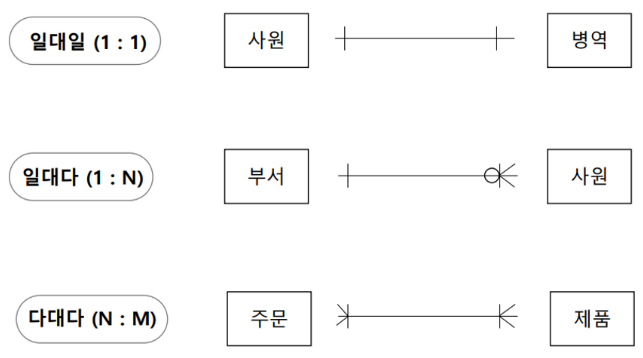
관계 차수 (Relationship Cardinality)
- 두개의 엔티티 간의 관계에 참여하는 수
- 예) 한명의 고객은 여러 계좌 개설 가능 (1:N 관계)

필수적 관계와 선택적 관계
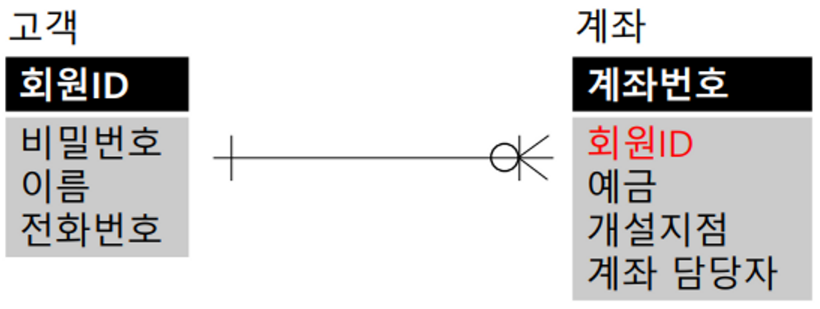
식별관계 (Identification Relationship)
- 고객 엔티티의 PK인 회원ID를 계좌 엔티티의 PK의 하나로 공유하는 것
- 고객과 계좌 엔티티에서 고객은 독립적으로 존재할 수 있는 강한 개체 (Strong Entity)
- Strong Entity - 다른 엔티티에게 의존하지 않고 독립적으로 존재 가능, 다른 엔티티와 관계를 가질 때 다른 엔티티에게 PK 공유
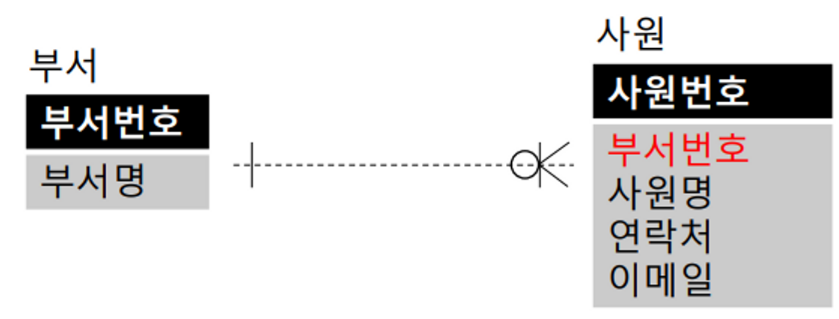
비식별관계 (Non-Identification Relationship)
- 강한 개체의 기본키를 다른 엔티티의 기본키가 아닌 일반 칼럼으로 관계를 가짐
- Weak Entitiy - 비식별, 의존적
식별자 (Identifier)
- 엔티티 내에서 인스턴스들을 구분할 수 있는 구분자
- 엔티티를 대표할 수 있는 유일성을 만족하는 속성
- 예) 회원ID, 계좌번호, 직원번호 등
Primary Key (주식별자, 기본키)
- 엔티티를 대표할 수 있어야 함
- 엔티티의 인스턴스를 유일하게 식별
- NOT NULL + UNIQUE 속성 기본 부여
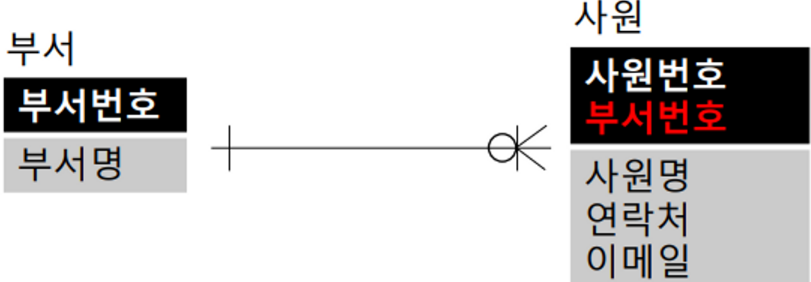
Foreign Key (외래키)
- 관계가 있는 두 엔티티를 부모, 자식 엔티티로 구분
- 부모 엔티티의 주식별자 속성을 자식 엔티티의 속성으로 추가
정규화 (Normalization)
- 일관성, 중복 제거, 유연성을 위한 방법이며 데이터를 분해하는 과정
- 비즈니스에 변화가 발생하여도 데이터 모델의 변경을 최소화 할 수 있음
- 한마디로 테이블 쪼개기
- 쪼갠 테이블은 나중에 join으로 다시 합집합으로 조회 가능
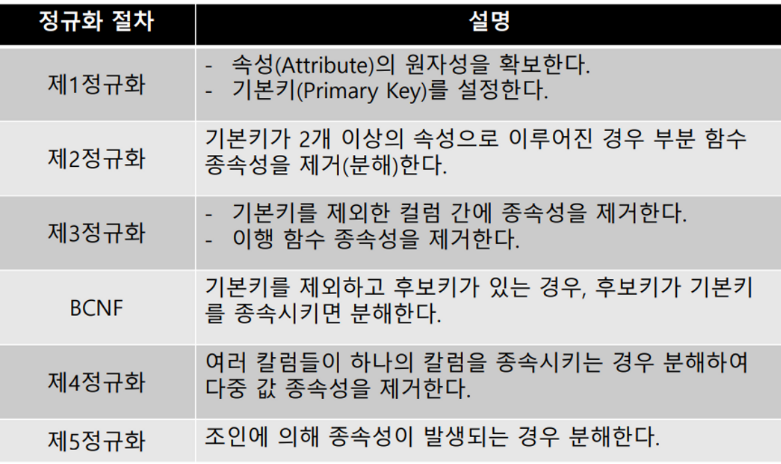
정규화의 성능
- 테이블을 분해, 중복 제거하기 때문에 모델의 유연성 높임
- 데이터 조회 시 join을 유발하기 때문에 리소스(CPU, 메모리) 사용이 높아짐
- 테이블간의 조인 시 건수*건수의 비교 필요 (데이터 양 증가시 효율 떨어짐)
- 비효율 문제 해결 방안으로 인덱스(Index)와 옵티마이저(Optimizer)를 통해 해결 (하지만 완벽하지 않음)
반정규화 (De-Normalization)
디비 성능 향상 됨 - 조인 줄이고 데이터 중복 허용, 하지만 유연성이 낮아짐
반정규화를 수행하는 경우
- 수행속도가 느려지는 경우
- 다량의 범위를 자주 처리해야하는 경우
- 특정 범위의 데이터만 자주 처리하는 경우
- 요약/집계 정보가 자주 요구되는 경우
반정규화 기법
- 미리 결과를 계산하여 그 값을 특정 컬럼에 추가
- 테이블 수직분할 - 하나의 테이블을 컬럼 기준으로 두개 이상 테이블로 분할
- 테이블 수평분할 - 하나의 테이블에 있는 값을 기준으로 분할
- 테이블 병합 - 1대1, 1대다 관계의 테이블을 병합하여 성능 향상 (데이터 중복 발생)

개발자가 되기까지