스택
스택의 특성
- 물건을 쌓아 올리듯 자료를 쌓아 올린 형태의 자료구조
- 스택에 저장된 자료는 선형 구조를 가짐
- 선형구조 : 자료 간의 관계가 1대1
- 비선형구조 : 자료 간의 관계가 1대 N
- 스택에 자료를 삽입하거나 스택에서 자료를 꺼낼 수 있음
- 마지막에 삽입한 자료를 가장 먼저 꺼낸다(후입 선출 Last In First Out)
스택의 구현
스택을 프로그램에서 구현하기 위해서 필요한 자료구조와 연산
- 자료구조 : 자료를 선형으로 저장할 저장소
- 배열을 사용할 수 있다
- 저장소 자체를 스태이라 부르기도 한다
- 스택에서 마지막 삽입된 원소의 위치를 top라 부른다
- 연산
- 삽입 : push라고 부름
- 삭제 : pop이라고 부름
- 스택이 공백인지 아닌지를 확인 : isEmpty
- 스택의 top에 있는 item을 반환하는 연산 : peek
스택의 삽입 / 삭제 과정
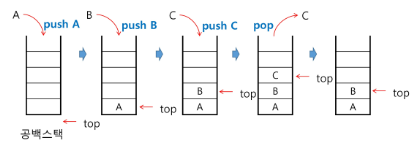
스택의 push
append() 사용- 파이썬의 append를 사용하면 편함 but 느리다,,,
- 또한 가능하면 스택의 크기 정해놓고 사용하려함
-> 메모리의 효율적 사용
이러한 면에서 append는 적합하진 않음
def push(item):
s.append(item)append안사용- 크기가 정해진 스택을 만들어 사용하는 것 중요함
def push(item, size):
global top
top += 1
if top == size :
print('overflow')
else:
stack[top] = item
size = 10
stack = [0] * size
top = - 1
push(10, size)
top += 1 # push(20)
stack[top] = 20
print(stack) 스택의 pop
pop() 사용
def pop():
if len(s) == 0:
# underflow
return
else:
return s.pop()- 안사용
def pop():
global top
if top == -1 :
print('underflow')
return 0
else:
top -= 1
return stack[top + 1]
print(pop())
if top > -1 :
top -= 1
print(stack[top + 1])스택 구현 고려 사항
-
1차원 배열을 사용하여 구현할 경우 구현이 용이하다는 장점이 있지만 스택의 크기를 변경하기가 어렵다는 단점이 있다 .
-
이를 해결하기 위한 방법으로 저장소를 동적으로 할당하여 스택을 구현하는 방법이 있다.
Function call
- 프로그램에서의 함수 호출과 복귀에 따른 수행 순서를 관리
- 가장 마지막에 호출된 함수가 가장 먼저 실행을 완료하고 복귀하는 후입선출 구조
- 함수 정보가 저장 되는 메모리도 스택이라 부름
- 함수 호출이 발생하면 호출한 함수 수행에 필요한 지역변수, 매개변수 및 수행 후 복귀할 주소 등의 정보를 스택 프레임(stack frame)에 저장하여 시스템 스택에 삽입
- 함수의 실행이 끝나면 시스템 스택의 top 원소(스택 프레임)를 삭제(pop)하면서 프레임에 저장되어 있던 복귀주소를 확인하고 복귀
재귀호출
-
자기 자신을 호출하여 순환 수행되는 것
-
함수에서 실행해야 하는 작업의 특성에 따라 일반적인 호출방식보다 재귀호출방식을 사용하여 함수를 만들면 프로그램의 크기를 줄이고 간단하게 작성
-
재귀호출은 깊이가 깊지않다 -> 많은 호출은 제한적
'''
# 재귀호출의 기본형
f(i, k) # i : 단계, k : 목표
if i == k : # 목표도달
return
else:
f(i+1,k) # 다음단계
'''
def f(i,k):
if i == k: # 목표에 도달하면
print(B)
return
else:
B[i] = A[i]
f(i+1, k)
A = [10,20,30]
B = [0] * 3
f(0,3)Memoization
-
피보나치 수를 구하는 함수를 재귀함수로 구현한 알고리즘은 문제점 있음
-> '엄청난 중복 호출이 존재' -
memoization은 컴퓨터 프로그램을 실행할 때 이전에 계산한 값을 메모리에 저장해서 매번 다시 계산하지 않도록 하여 전체적인 실행속도를 빠르게 하는 기술 -> 동적 계획법의 핵심 기술
-
메모이제이션을 사용하면 실행시간을 줄일 수 있음
def fibo1(n):
global memo
if n >= 2 and memo[n] == 0 :
memo[n] = (fibo1(n-1) + fibo1(n-2))
return memo[n]
n= 10
memo = [0] * (n+1) #[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
memo[0] = 0
memo[1] = 1
print(fibo1(3)) # 2DP
-
동적 계획 알고리즘은 그리디 알고리즘과 같이 최적화 문제를 해결하는 알고리즘이다.
-
먼저 입력 크기가 작은 부분 문제들을 모두 해결한 후에 그 해들을 이용하여 보다 큰 크기의 부분 문제들을 해결하여, 최종적으로 원래 주어진 입력의 문제를 해결하는 알고리즘이다.
def fibo2(n):
f = [0]*(n+1)
f[0], f[1] = 0, 1
for i in range(2,n+1):
f[i] = f[i-2] + f[i-1]
return f[n]
print(fibo2(3)) # 2DP 구현 방식
- memoization을 재귀적 구조에 사용하는 것보다 반복적 구조로 DP를 구현한 것이 성능 면에서 보다 효율적이다
- 재귀적 구조는 내부에 시스템 호출 스택을 사용하는 오버헤드가 발생하기 때문
DFS
-
비선형 구조인 그래프 구조는 그래프로 표현된 모든 자료를 빠짐없이 검색하는 것이 중요
-
시작 정점의 한 방향으로 갈 수 있는 경로가 있는 곳까지 깊이 탐색해 가다가 더이상 갈 곳이 없게 되면, 가장 마지막에 만났던 갈림길 간선이 있는 정점으로 되돌아와서 다른 방향의 정점으로 탐색을 계속 반복하여 결국 모든 정점을 방문하는 순회방법
-
가장 마지막에 만났던 갈림길의 정점으로 되돌아가서 다시 깊이 우선 탐색을 반복해야 하므로 후입선출 구조의 스택 사용
-
시작 정점 v를 결정해서 방문
-
정점 v에 인접한 정점 중
- 방문하지 않은 정점 w가 있으면, 스택에 push하고 정점 w를 방문
- 방문하지 않은 정점이 없으면, 탐색의 방향을 바꾸기 위해서 스택을 pop하여 받은 가장 마지막 방문 정점을 v로 하여 다시 2.를 반복
- 스택이 공백이 될때까지 2. 를 반복
