
CNN과 Augmentation을 활용한 O/X 이미지 분류
CNN(Convolutional Neural Networks)
최근 여러 분야에서 딥러닝에 대한 관심과 활용이 많아지고 있습니다. 특히, 의료, 생물정보 분야에서는 MRI나 CT 같은 의료 이미지로 학습한 뒤, 질병을 진단하는 연구가 많이 진행되고 있습니다. 이러한 이미지 처리에 널리 쓰이는 모델로 바로 CNN이 있습니다.
CNN(Convolutional Neural Networks)은 수동으로 특징을 추출할 필요 없이 데이터로부터 직접 학습하는 딥러닝을 위한 신경망 아키텍처입니다. CNN의 구조는 크게 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나뉩니다. 특징 추출 영역은 합성곱층(Convolution layer)과 풀링층(Pooling layer)을 여러 겹 쌓는 형태(Conv+Maxpool)로 구성되어 있으며, 이미지의 클래스를 분류하는 부분은 Fully connected(FC) 학습 방식으로 이미지를 분류 합니다.[1]

CNN은 주로 이미지나 영상 데이터를 처리할 때 쓰이는데, 영상에서 객체, 얼굴, 장면 인식을 위한 패턴을 찾을 때 특히 유용하며, 오디오, 시계열, 신호 데이터와 같이 영상 이외의 데이터를 분류하는 데도 효과적입니다. 또한, 자율주행 차량 및 얼굴 인식 응용 분야와 같이 객체 인식과 컴퓨터 비전이 필요한 응용 분야에서도 CNN이 많이 사용되고 있습니다.[2]
그럼 CNN을 사용하여 직접 그린 O, X 이미지를 분류해 보도록 하겠습니다.
과정 :
1. 데이터셋 준비
2. 경로 지정 및 데이터 살펴보기
3. 이미지 데이터 전처리
4. 모델 구성
5. 모델 학습
6. 테스트 평가
7. 모델 저장
데이터셋 준비
O, X 이미지는 그림판에 직접 그려서 만들었습니다. 처음엔, 총 30개 정도의 제가 그린 O, X 이미지로만 학습을 진행하였으나, 다른 형태나 굵기의 O, X 이미지에 대해 테스트 성능이 좋지 않아, 제가 그린 O, X 이미지와 지인들이 그려준 다른 형태와 굵기의 O, X 이미지들도 포함하여 총 104개의 O, X 이미지(각각 54개)로 진행하였습니다.
먼저 train, validation, test 폴더를 생성하였고, train에 38개씩, validation에 8개씩, test에 6개씩 각 O, X 폴더로 나누어 이미지들을 저장하였습니다. 각 train, validation, test 폴더 안에,'O', 'X'로 명명된 폴더에 O, X별로 이미지가 저장되어 있는 것입니다.
경로 지정 및 데이터 살펴보기
경로 지정
우선 O, X 이미지들을 읽어 들일 디렉토리 경로를 지정합니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import set_matplotlib_hangul
%matplotlib inline
import tensorflow as tf
import os
import PIL
import shutil
# 기본 경로
base_dir = './OX_images/'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
# 훈련용 O/X 이미지 경로
train_o_dir = os.path.join(train_dir, 'O')
train_x_dir = os.path.join(train_dir, 'X')
print(train_o_dir, train_x_dir)
# 검증용 O/X 이미지 경로
validation_o_dir = os.path.join(validation_dir, 'O')
validation_x_dir = os.path.join(validation_dir, 'X')
print(validation_o_dir, validation_x_dir)
# 테스트용 O/X 이미지 경로
test_o_dir = os.path.join(test_dir, 'O')
test_x_dir = os.path.join(test_dir, 'X')
print(test_o_dir, test_x_dir)
이미지 파일 이름 조회
os.listdir()을 사용하여 경로 내에 있는 파일의 이름을 리스트의 형태로 반환받아 확인합니다.
# 훈련용 이미지 파일 이름 조회
train_o_fnames = os.listdir(train_o_dir)
train_x_fnames = os.listdir(train_x_dir)
print(train_o_fnames)
print(train_x_fnames)
각 디렉토리별 이미지 개수 확인
각 디렉토리에 저장되어 있는 이미지 파일의 수를 확인합니다.
print('Total training o images :', len(os.listdir(train_o_dir)))
print('Total training x images :', len(os.listdir(train_x_dir)))
print('Total validation o images :', len(os.listdir(validation_o_dir)))
print('Total validation x images :', len(os.listdir(validation_x_dir)))
print('Total test o images :', len(os.listdir(test_o_dir)))
print('Total test x images :', len(os.listdir(test_x_dir)))
이미지 확인
# 이미지 확인
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
nrows, ncols = 4, 4
pic_index = 0
fig = plt.gcf()
fig.set_size_inches(ncols*3, nrows*3)
pic_index += 8
next_o_pix = [os.path.join(train_o_dir, fname) for fname in train_o_fnames[pic_index-8:pic_index]]
next_x_pix = [os.path.join(train_x_dir, fname) for fname in train_x_fnames[pic_index-8:pic_index]]
for i, img_path in enumerate(next_o_pix+next_x_pix):
sp = plt.subplot(nrows, ncols, i+1)
sp.axis('OFF')
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()
- 위와 같은 이미지들로 구성 되어 있습니다.
- 동일한 형태나 크기의 O, X가 아닌 여러 형태와 크기의 O, X 이미지를 사용했습니다.
이미지 데이터 전처리
아무래도 이미지가 총 102개 밖에 안 되기 때문에, 데이터가 부족하다고 생각했습니다. 적은 수의 이미지에서 모델이 최대한 많은 정보를 뽑아내서 학습할 수 있도록, augmentation을 적용하였습니다.
Augmentation이라는 것은, 이미지를 사용할 때마다 임의로 변형을 가함으로써 마치 훨씬 더 많은 이미지를 보고 공부하는 것과 같은 학습 효과를 내게 해줍니다. 기존의 데이터의 정보량을 보존한 상태로 노이즈를 주는 방식인데, 이는 다시 말하면, 내가 가지고 있는 정보량은 변하지 않고 단지 정보량에 약간의 변화를 주는 것으로, 딥러닝으로 분석된 데이터의 강하게 표현되는 고유의 특징을 조금 느슨하게 만들어는 것이라고 생각하면 됩니다. Augmentation을 통해 결과적으로 과적합(오버피팅)을 막아 모델이 학습 데이터에만 맞춰지는 것을 방지하고, 새로운 이미지도 잘 분류할 수 있게 만들어 예측 범위도 넓혀줄 수 있습니다.
이런 전처리 과정을 돕기 위해 케라스는 ImageDataGenerator 클래스를 제공합니다. ImageDataGenerator는 아래와 같은 일을 할 수 있습니다:
- 학습 과정에서 이미지에 임의 변형 및 정규화 적용
- 변형된 이미지를 배치 단위로 불러올 수 있는 generator 생성
- generator를 생성할 때 flow(data, labels), flow_from_directory(directory) 두 가지 함수를 사용 할 수 있습니다.
- fit_generator(fit), evaluate_generator 함수를 사용하여 generator로 이미지를 불러와 모델을 학습시키고 평가 할 수 있습니다.
이미지 데이터 생성
ImageDataGenerator를 통해서 데이터를 만들어줄 것입니다. 어떤 방식으로 데이터를 증식시킬 것인지 아래와 같은 옵션을 통해서 설정합니다.
참고로, augmentation은 train 데이터에만 적용시켜야 하고, validation 및 test 이미지는 augmentation을 적용하지 않습니다. 모델 성능을 평가할 때에는 이미지 원본을 사용해야 하기에 rescale만 적용해 정규화하고 진행합니다.
# 이미지 데이터 전처리
from tensorflow.keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Image augmentation
# train셋에만 적용
train_datagen = ImageDataGenerator(rescale = 1./255, # 모든 이미지 원소값들을 255로 나누기
rotation_range=25, # 0~25도 사이에서 임의의 각도로 원본이미지를 회전
width_shift_range=0.05, # 0.05범위 내에서 임의의 값만큼 임의의 방향으로 좌우 이동
height_shift_range=0.05, # 0.05범위 내에서 임의의 값만큼 임의의 방향으로 상하 이동
zoom_range=0.2, # (1-0.2)~(1+0.2) => 0.8~1.2 사이에서 임의의 수치만큼 확대/축소
horizontal_flip=True, # 좌우로 뒤집기
vertical_flip=True,
fill_mode='nearest'
)
# validation 및 test 이미지는 augmentation을 적용하지 않는다;
# 모델 성능을 평가할 때에는 이미지 원본을 사용 (rescale만 진행)
validation_datagen = ImageDataGenerator(rescale = 1./255)
test_datagen = ImageDataGenerator(rescale = 1./255) 이제 데이터를 불러옵니다. flow_from_directory() 함수를 사용하면 이미지가 저장된 폴더를 기준으로 라벨 정보와 함께 이미지를 불러올 수 있습니다.
이미지 데이터 수가 적어서, batch_size를 결정하는 것에 여러 시행착오와 어려움이 있었습니다. Generator 생성시 batch_size와 steps_per_epoch(model fit할 때)를 곱한 값이 훈련 샘플 수 보다 작거나 같아야 합니다. 이에 맞춰, flow_from_directory() 옵션에서 batch_size와 model fit()/fit_generator() 옵션의 steps_per_epoch 값을 조정해 가며 학습을 시도하였습니다.
# flow_from_directory() 메서드를 이용해서 훈련과 테스트에 사용될 이미지 데이터를 만들기
# 변환된 이미지 데이터 생성
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=16, # 한번에 변환된 이미지 16개씩 만들어라 라는 것
color_mode='grayscale', # 흑백 이미지 처리
class_mode='binary',
target_size=(150,150)) # target_size에 맞춰서 이미지의 크기가 조절된다
validation_generator = validation_datagen.flow_from_directory(validation_dir,
batch_size=4,
color_mode='grayscale',
class_mode='binary',
target_size=(150,150))
test_generator = test_datagen.flow_from_directory(test_dir,
batch_size=4,
color_mode='grayscale',
class_mode='binary',
target_size=(150,150))
# 참고로, generator 생성시 batch_size x steps_per_epoch (model fit에서) <= 훈련 샘플 수 보다 작거나 같아야 한다.
- 총 102개의 데이터를 인식했고, 2개의 classes로 분류하였습니다.
- 앞서 말했지만, O, X 각 폴더의 이름을 'O', 'X'로 명명하였습니다. ImageDataGenerator가 각 분류 데이터를 읽어올 때, 폴더별로 category를 자동으로 인식합니다.
라벨 확인
# class 확인
train_generator.class_indices
- O는 0으로, X는 1로 분류되었습니다.
Augmentation 적용 확인
Augmentation이 어떻게 적용되는지 보기 위해, 이미지 데이터를 하나 불러왔습니다.
# 이미지 하나 불러오기
sample_img = mpimg.imread(next_o_pix[0])
plt.imshow(sample_img)
plt.show()
위의 이미지 하나가 augmentation을 통해 학습 과정에서 아래의 이미지들과 같이 변형되어 학습 됩니다. 그럼 더 많은 이미지들을 보고 학습된 것과 같겠죠?
max_iter = 4
cnt = 1
sample_img2 = sample_img[np.newaxis, ...]
# 축을 하나 추가했는데, 하나의 이미지만 바꿔주는게 아니라 동시에 여러개의 이미지를 바꿔줄 수 있기에,
# 그림 개수/장수 까지 받아서 4차원으로 (개수/장수, h, w, channel) 이렇게 받는다
# 쉽게 말해, 받는 형식이 4차원이라서 4차원 형태로 만들어 준것
plt.figure(figsize=(10,10))
for img in train_datagen.flow(sample_img2):
plt.subplot(1, max_iter, cnt)
plt.imshow(image.array_to_img(img[0]))
if cnt == max_iter:
break
cnt += 1
- 위치가 옮겨지거나, 뒤집어지거나, 확대되는 등 여려 변형이 적용 됩니다.
모델 구성
합성곱 신경망 모델을 구성합니다. 출력층의 활성화함수로 ‘sigmoid’를 사용하였습니다. 이는 0과 1 두 가지로 분류되는 ‘binary’ 분류 문제에 적합하기 때문입니다.
# 합성곱 신경망 모델 구성하기
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 1)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary() # 신경망의 구조 확인
모델 학습
모델 컴파일
모델 컴파일 단계에서는 compile() 메서드를 이용해서 손실 함수(loss function)와 옵티마이저(optimizer)를 지정합니다.
- 손실 함수로 ‘binary_crossentropy’를 사용했습니다.
- 또한, 옵티마이저로는 RMSprop을 사용했습니다. RMSprop(Root Mean Square Propagation) 알고리즘은 훈련 과정 중에 학습률을 적절하게 변화시켜 줍니다.
from tensorflow.keras.optimizers import RMSprop
# compile() 메서드를 이용해서 손실 함수 (loss function)와 옵티마이저 (optimizer)를 지정
model.compile(optimizer=RMSprop(learning_rate=0.001), # 옵티마이저로는 RMSprop 사용
loss='binary_crossentropy', # 손실 함수로 ‘binary_crossentropy’ 사용
metrics= ['accuracy'])
# RMSprop (Root Mean Square Propagation) Algorithm: 훈련 과정 중에 학습률을 적절하게 변화시킨다.모델 학습
generator 데이터도 fit()을 통해 학습을 진행할 수 있습니다.
- 훈련과 테스트를 위한 데이터셋인 train_generator, validation_generator를 입력합니다.
- epochs는 데이터셋을 한 번 훈련하는 과정을 의미합니다.
- steps_per_epoch는 한 번의 에포크 (epoch)에서 훈련에 사용할 배치 (batch)의 개수를 지정합니다.
- validation_steps는 한 번의 에포크가 끝날 때, 테스트에 사용되는 배치 (batch)의 개수를 지정합니다.
처음에 epoch을 50을 주어 학습시켰지만, 성능이 조금 떨어진다고 판단하여, 100으로 변경하여 다시 학습시켰습니다.
# 모델 훈련
history = model.fit_generator(train_generator, # train_generator안에 X값, y값 다 있으니 generator만 주면 된다
validation_data=validation_generator, # validatino_generator안에도 검증용 X,y데이터들이 다 있으니 generator로 주면 됨
steps_per_epoch=4, # 한 번의 에포크(epoch)에서 훈련에 사용할 배치(batch)의 개수 지정; generator를 4번 부르겠다
epochs=100, # 데이터셋을 한 번 훈련하는 과정; epoch은 100 이상은 줘야한다
validation_steps=4, # 한 번의 에포크가 끝날 때, 검증에 사용되는 배치(batch)의 개수를 지정; validation_generator를 4번 불러서 나온 이미지들로 작업을 해라
verbose=2)
# 참고: validation_steps는 보통 내가 원하는 이미지 수에 flow할 때 지정한 batchsize로 나눈 값을 validation_steps로 지정
결과 확인 및 평가
학습된 모델 결과와 성능을 확인합니다.
# 모델 성능 평가
model.evaluate(train_generator)
model.evaluate(validation_generator)
epoch을 100으로 변경하여 학습된 모델의 성능 평가 결과, train에 대해선 accuracy가 98.7%를 달성했습니다. validation에 대해선 100%의 정확도로 나타났습니다. 상당히 괜찮은 결과라고 생각합니다.
정확도 및 손실 시각화
훈련 과정에서 epoch에 따른 정확도와 손실을 시각화화여 확인합니다.
# 정확도 및 손실 시각화
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'go', label='Training loss')
plt.plot(epochs, val_loss, 'g', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
- Training accuracy와 validation accuracy 모두 epoch이 증가하면서 비슷한 수준으로 증가했습니다.
- 다행히 과적합 되지 않은 것 같습니다.
테스트 평가
마지막으로, test 이미지들을 사용하여 모델을 테스트 했습니다. O 6개, X 6개의 총 12개의 test 이미지들을 사용했습니다.
# 이제 테스트 이미지 분류
import numpy as np
from keras.preprocessing import image
# 테스트용 O 이미지 경로 설정
test_dir = './OX_images/test/'
test_o_dir = os.path.join(test_dir, 'O/')
test_o_filenames = os.listdir(test_o_dir)
test_o_filenames
# 테스트용 X 이미지 경로 설정
test_dir = './OX_images/test/'
test_x_dir = os.path.join(test_dir, 'X/')
test_x_filenames = os.listdir(test_x_dir)
test_x_filenames
# O,X를 key로, 이미지 파일 이름들을 value로 dictionary 생성
dic_ox_filenames = {}
dic_ox_filenames['O'] = test_o_filenames
dic_ox_filenames['X'] = test_x_filenames
# O/X 분류 테스트
for ox, filenames in dic_ox_filenames.items():
fig = plt.figure(figsize=(16,10))
rows, cols = 1, 6
for i, fn in enumerate(filenames):
path = test_dir + ox + '/' + fn
test_img = image.load_img(path, color_mode='grayscale', target_size=(150, 150), interpolation='bilinear')
x = image.img_to_array(test_img)
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
fig.add_subplot(rows, cols, i+1)
if classes[0]==0:
plt.title(fn + " is O")
plt.axis('off')
plt.imshow(test_img, cmap='gray')
else:
plt.title(fn + " is X")
plt.axis('off')
plt.imshow(test_img, cmap='gray')
plt.show();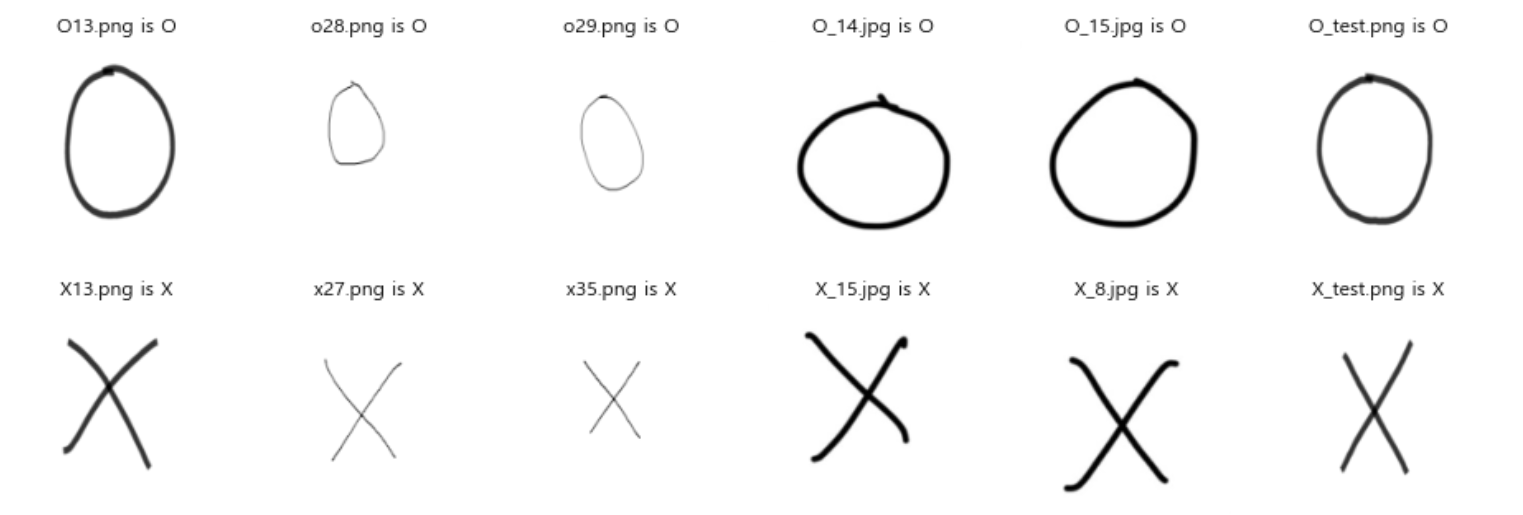
- 앞서 확인했듯이, O는 0으로, X는 1로 class가 분류되어 있습니다. test 이미지에 대해 모델이 분류한 class에 따라 해당 이미지와 분류 결과를 출력하게 만들었습니다.
- 모델 테스트 결과 O, X 모두 다 제대로 분류된 것을 볼 수 있습니다. 다 맞췄네요!
# 모델 성능 평가
model.evaluate(test_generator)
- 모델 평가 결과도 test 데이터에 대해 100%의 정확도로 나타납니다.
모델 저장
마지막으로, 학습된 모델을 저장합니다. 잘 간직합니다.
# 모델 저장
model.save('ox_class_cnn.h5')결론
모델 학습 및 평가 결과 train에 대해 accuracy 98.7%, validation에 대해 100%, 그리고 test에 대해 100%의 성능을 보여줍니다. 적은 데이터를 사용하여 성능이 과연 잘 나올지 걱정하였는데, 결과가 좋아 다행입니다. 역시 CNN의 성능은 대단한 것 같습니다.
재미있는 경험이었습니다. 다음엔, 더 다양하고 많은 이미지들을 사용하고 다른 기술도 적용하여 분류에 도전해 보겠습니다.
References
[1] https://www.insilicogen.com/blog/346
[2] https://kr.mathworks.com/discovery/convolutional-neural-network-matlab.html

안녕하세요~ 제가 대학교에서 CNN을 배워서 검색하다보니 포스팅을 찾아보게 되었습니다.
혹시 팀 과제로 제출할 때 참고해도 될까요?