
📍목차
- 메모리 관리의 개요
- 메모리 주소
- 단일 프로그래밍 환경의 메모리 할당
- 다중 프로그래밍 환경의 메모리 할당
- 분할 컴파일과 메모리 관리
1️⃣ 메모리 관리의 개요
오늘날의 운영체제, 폰노이만 구조에서 프로그램은 메모리에 올라와야만 실행할 수 있다.
메모리는 유일한 작업 공간이며, 메모리를 어떻게 관리하느냐에 따라 성능에 막대한 영향을 미친다.
본 포스팅에서는 메모리 관리 기법, 프로세스를 어떻게 메모리에 할당하는지에 대해 알아보자.
✔️ 소스코드의 번역과 실행
메모리 관리를 이해하기 위해, 프로그램을 만드는 소스코드의 번역과 실행 과정을 살펴보자.
이는 번역 단계에서 프로그램의 메모리 구조가 정의되며, 실행 단계에서 메모리를 동적으로 관리하기 때문에 중요하다.
소스코드 번역 방식
컴퓨터는 기계어를 실행할 수 있으나, 기계어는 사람이 배우기 어려워 오늘날에는 C, Java 등의 고급언어를 이용해 프로그램을 만든다.
언어 번역 프로그램은 고급언어로 작성한 소스코드를 기계어로 번역하는데,
대표적인 방식이 컴파일러와 인터프리터다.

- 컴파일러 : 소스코드를 기계어로 번역한 후 한 번에 실행
- 인터프리터 : 소스코드를 한 행씩 번역하여 실행
✔️ 컴파일러 방식
컴파일러 방식을 사용하는 이유는 아래와 같다.
-
오류 발견
컴파일러 방식은 심벌 테이블을 사용해 실행 전에 오류를 검출한다.
심벌 테이블은 변수 선언부에 명시한 각 변수의 이름과 종류를 모아놓는다.
이를 통해 선언하지 않은 변수를 사용했는지, 변수에 맞지않는 종류의 데이터를 저장하지는 않았는지 알 수 있다. -
소스코드 최적화
컴파일러 방식을 통해 사용하지 않는 변수를 검출하고, 중복되는 연산 변환 등 최적화를 통해 성능을 향상시킬 수 있다.
컴파일러의 컴파일 과정
컴파일러가 실행 파일을 만드는 과정을 살펴보자.
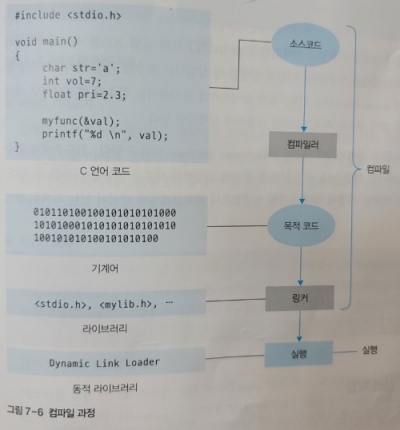
-
컴파일러는 오류를 점검하고 필요없는 변수와 코드를 삭제한다. 이를 통해 목적 코드가 만들어진다.
기계어 코드 전의 초벌 번역 상태이다. -
목적 코드가 만들어지면, 라이브러리가 필요한 부분을 비워놓고 컴파일한다.
이후 실행할 때 라이브러리의 코드를 가져오는데, 이러한 방식을 동적 라이브러리라고 한다.
동적 라이브러리를 사용하지 않던 시절에는 목적 코드를 만든 후 링커를 통해 라이브러리에 있는 코드를 목적 코드에 삽입했다. 그러나 이러한 방식은 라이브러리가 변경될 때마다 컴파일을 다시 해야해 현재 사용되지 않는다.
메모리 관리 작업
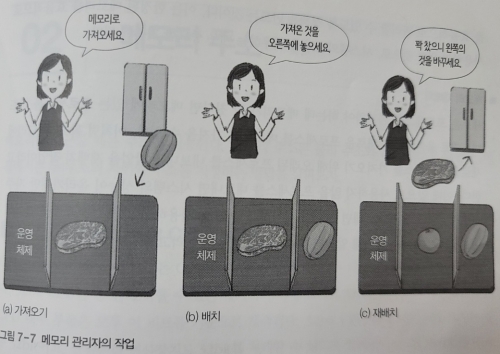
메모리 관리 작업은 아래와 같다.
- 가져오기(fetch) : 실행할 프로세스와 데이터를 메모리로 가져오는 작업
- 배치(placement) : 가져온 프로세스와 데이터를 메모리의 어느 부분에 올려놓을지 결정하는 작업
- 재배치(replacement) : 꽉 찬 메모리에 새로운 프로세스를 가져오기 위해 오래된 프로세스를 내보내는 작업
2️⃣ 메모리 주소
메모리에 접근할 때는 주소를 이용하고, 메모리 주소는 물리 주소와 논리 주소로 나뉜다.
두 주소의 차이를 이해해보자.
메모리 영역의 구분
메모리 관리를 설명하기 위해 메모리 구조를 살펴보자.
메모리 관리자는 메모리를 운영체제 영역과 사용자 영역으로 나누어 관리한다.
이는 사용자가 운영체제를 침범하지 못하게 하기 위함이다.

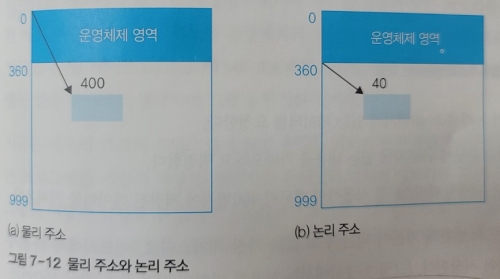
위 사진처럼 운영체제 영역이 359번지까지 차지한다면, 사용자 프로세스는 360번지부터 적재될 수 있다.
그러나 운영체제의 크기가 커져 399번까지 사용된다면, 사용자 프로세스는 400번지부터 적재되어야 한다.
이처럼 운영체제의 크기에 따라 사용자 프로세스가 적재될 위치가 변하는 것이 번거로우므로,
논리 주소와 물리 주소를 구분하여 메모리에 적재한다.
여기서 물리 주소는 메모리의 입장에서 바라본 주소이며, 논리 주소는 사용자 프로세스 입장에서 바라본 주소이다.
즉, 물리 주소의 시작점은 0번지로 램 메모리의 실제 주소이며, 논리 주소는 사용자 영역의 시작점을 기준으로 잡았을 때의 주소이다.
추가로, 사용자 영역이 운영체제 영역으로 침범하는 것을 막기 위해 CPU 내 경계 레지스터를 이용한다.
경계 레지스터는 운영체제 영역과 사용자 영역의 경계 지점 주소를 갖는다.
사용자가 요청한 작업이 경계 레지스터의 값을 벗어나면 해당 프로세스를 종료한다.
✔️ 논리 주소와 물리 주소의 변환
char alp = 'A'와 같은 코드를 컴파일하여 40번지에 저장되었다고 하자.
이때 중요한 것은 실행 파일에 40번지의 A가 들어간다고 해서 실제 물리 메로리의 40번지에 A가 들어가는 것이 아니라는 것이다. 40번지는 프로세스가 갖는 논리 주소이기 때문이다.
따라서, 논리 주소로 이루어진 프로세스를 실행하면 이를 물리 주소로 변환하는 작업이 필요하다.
이 작업은 메모리 관리 유닛이 담당하고, CPU 내에 존재한다.
메모리 관리 유닛이 논리 주소를 물리 주소로 변환하는 과정을 알아보자.

- 사용자 프로세스가 논리 주소 40번지에 있는 데이터를 요청한다.
- CPU는 메모리 관리 유닛에게 40번지에 있는 데이터를 가져오라고 명령한다.
- 메모리 관리 유닛은 재배치 레지스터를 사용해 메모리 400번지에 저장된 데이터를 가져온다.
여기서 재배치 레지스터란 주소 변환의 기본이 되는 주소 값을 가진 레지스터로, 메모리에서 사용자 영역의 시작 주소 값이 저장된다.
위 사진에서는 사용자 영역의 시작 주소 값이 360이므로 재배치 레지스터에 360이 저장되며,
운영체제 영역이 커져 사용자 영역의 시작 주소 값이 400이 된다면 재배치 레지스터에 400이 저장된다.
3️⃣ 단일 프로그래밍 환경의 메모리 할당
✔️ 메모리 오버레이
만일 실행하려는 프로그램이 메모리보다 크면 어떻게 해야할까?
프로그램이 실제 메모리보다 클 때, 프로그램을 적당한 크기로 잘라 가져오는 기법을 메모리 오버레이라고 한다.
메모리 오버레이는 프로그램을 몇 개의 모듈로 나누고, 메모리에 필요한 모듈만 올려놓고 나머지는 필요할 때마다 가져와 사용한다.

문서 편집기에서 맞춤검 검사 모듈과 인쇄 모듈이 있을 때, 맞춤법 검사가 필요하면 맞춤법 검사 모듈만 올려놓고 실행하고, 안쇄가 필요하면 맞춤법 검사기를 쫓아낸 후 인쇄 모듈을 적재하여 실행한다.
메모리 오버레이에서 어떤 모듈을 가져오거나 내보낼지는 프로그램 카운터가 결정한다.
CPU 레지스터 중 하나인 프로그램 카운터는 다음에 실행할 명령어의 위치를 가리키는 레지스터로,
해당 모듈이 없으면 메모리 관리자에게 해당 모듈을 가져올 것을 명령한다.
메모리 오버레이는 한정된 메모리보다 큰 프로그램을 실행할 수 있다는 점과,
프로그램의 일부만 메모리에 올라와도 실행할 수 있다는 점에서 의미가 크다.
✔️ 스왑
그러면 메모리 공간이 부족해 쫓겨난 모듈은 어디로 가야할까?
아직 종료된 프로세스가 아니기 때문에 별도의 공간이 필요하다.
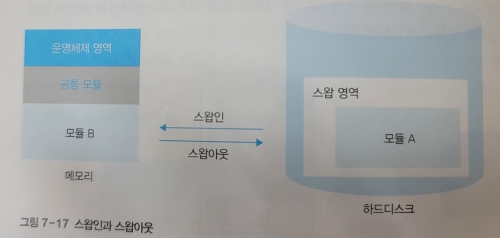
이처럼 메모리가 모자라서 쫓겨난 프로세스를 모아두는 저장장치의 별도 공간을 스왑 영역이라고 한다.
스왑 영역에서 메모리로 가져오는 작업을 스왑인, 메모리에서 스왑 영역으로 내보내는 작업을 스왑아웃이라고 한다.
스왑 영역은 메모리 관리자가 관리한다.
저장장치 관리자가 아닌 메모리 관리자가 관리하는 이유는, 저장장치는 장소만 빌려줄 뿐 메모리 관리자가 스왑인/스왑아웃을 결정하기 때문이다.
이러한 스왑 영역을 통해 사용자는 실제 메모리와 스왑 영역의 크기를 합한 것을 전체 메모리의 크기로 인식하게 된다.
물론 실제 메모리의 크기가 4GB인 것이 실제 메모리가 1GB, 스왑 영역이 3GB인 것보다 빠르지만 사용자 입장에서는 실제 메모리 크기에 상관없이 큰 프로그램을 실행할 수 있다.
4️⃣ 다중 프로그래밍 환경의 메모리 할당
앞서 살펴본 예시는 하나의 프로세스가 실행될 때의 메모리 오버레이와 스왑에 대해 살펴봤다.
그러면 오늘날처럼 여러 프로세스가 동시에 실행될 때의 메모리 관리에 대해 살펴보자.
✔️ 메모리 분할 방식
메모리를 어떤 크기로 나눌 것인가는 메모리 배치 정책에 해당한다.
메모리에 여러 개의 프로세스를 배치하는 방법은 가변 분할 방식과 고정 분할 방식으로 나뉜다.
- 가변 분할 방식 : 프로세스의 크기에 따라 메모리를 나눈다.
- 고정 분할 방식 : 프로세스의 크기와 상관없이 메모리를 같은 크기로 나눈다.
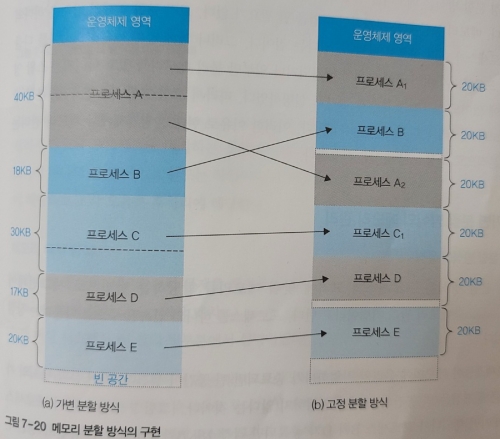
✔️ 가변 분할 방식
구현
가변 분할 방식에서는 프로세스의 크기에 맞게 메모리가 분할되므로 프로세스가 차지하는 메모리 영역의 크기가 다양하다.
한 프로세스가 메모리의 연속된 공간에 배치되어 연속 메모리 할당이라고도 한다.
특징
가변 분할 방식에서 프로세스가 종료되면 빈 공간이 생기고, 이때 빈 공간의 크기는 일정하지 않다.
이렇게 발생한 빈 공간을 단편화라고 하는데, 가변 분할 방식에서 단편화는 조각이 프로세스의 바깥에 위치하기 때문에 외부 단편화라고 한다.
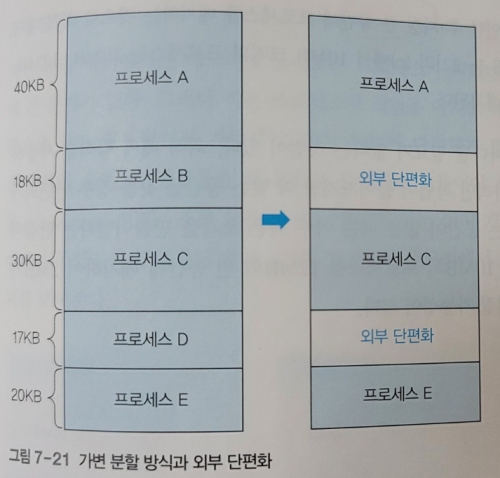
위 사진의 경우 18KB와 17KB의 공간, 총 35KB의 빈 공간이 있음에도 18KB를 넘는 프로세스를 실행할 수 없는 문제점이 발생한다.
이러한 외부 단편화 문제를 해결하기 위해 메모리 배치 방식이나 조각 모음을 사용한다.
메모리 배치 방식은 조각이 발생하지 않도록 프로세스를 배치하는 것이고(선처리),
조각 모음은 작은 조각들을 모아 하나의 큰 조각으로 만드는 작업이다(후처리).
외부 단편화 해결 : 메모리 배치 방식
대표적인 메모리 배치 방식으로 최초 배치, 최적 배치, 최악 배치, 버디 시스템이 있다.
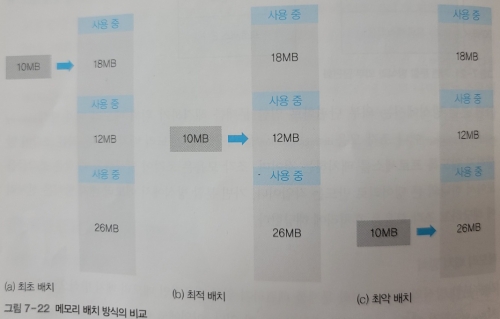

- 최초 배치 : 빈 공간을 차례대로 찾가다 첫 번째로 발견한 공간에 프로세스를 배치한다.
- 최적 배치 : 메모리의 빈 공간을 모두 확인한 후, 크기가 가장 비슷한 곳에 프로세스를 배치한다.
- 최악 배치 : 메모리의 빈 공간을 모두 확인한 후, 크기가 가장 큰 곳에 프로세스를 배치한다.
- 버디 시스템 : 프로세스의 크기에 맞게 메모리를 절반씩 자른 후 배치한다.
외부 단편화 해결 : 조각 모음
외부 단변화가 여러 번 발생하면 작은 조각이 여러 개 생기게 되는데, 새로운 프로세스의 할당을 위해 서로 떨어져 있는 여러 조각을 하나의 큰 조각으로 만들어야 한다. 이를 조각 모음이라고 한다.
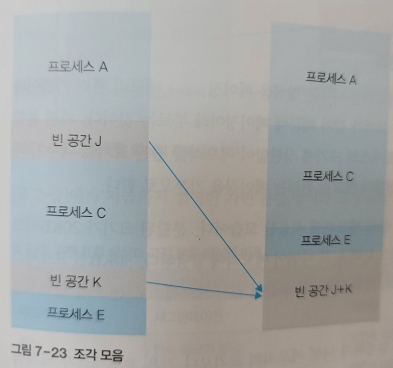
조각 모음은 아래와 같은 순서로 진행된다.
1. 조각 모음을 하기 위해 이동할 프로세스의 동작을 멈춘다.
2. 프로세스를 이동한 후, 프로세스의 논리 주소 값을 변경한다.
3. 프로세스를 재시작한다.
이와 같이 프로세스 중지, 이동, 주소 변경, 재시작 등으로 인해 시간이 걸리고 복잡하기 때문에 가변 분할 방식에서의 메모리 관리는 복잡하다.
✔️ 고정 분할 방식
구현
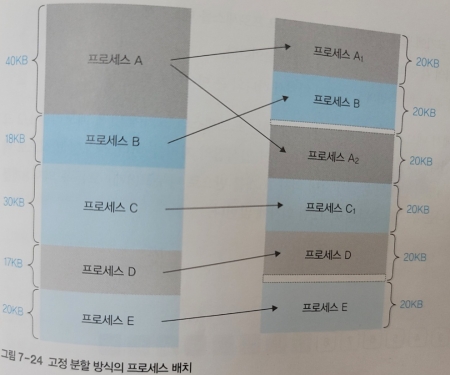
고정 분할 방식에서는 프로세스의 크기에 상관없이 동일한 크기로 나뉜다.
따라서 하나의 프로세스가 일부는 메모리에 적재되고, 일부는 스왑 영역에 적재될 수 있다.
하나의 프로세스에 해당하는 주소 공간이 불연속적으로 배치될 수 있어 비연속 메모리 할당이라고도 한다.
특징
고정 분할 방식에서 프로세스는 모두 같은 크기로 잘리고, 책에서 모든 페이지의 크기가 같기 때문에 페이징 메모리 관리 기법이라고도 한다.
모두 같은 크기로 나뉘기 때문에 메모리 관리가 편해 현대의 메모리 관리는 고정 분할 방식을 기본으로 한다.
고정 분할 방식도 단점이 있는데, 나뉜 메모리의 크기보다 작은 프로세스가 배치되면 낭비되는 공간이 생긴다는 점이다. 이때 나뉘어진 크기의 안쪽에 조각이 발생하기 때문에 내부 단편화라고 한다.
가변 분할 방식의 외부 단편화와 달리, 내부 단편화는 조각 모음을 할 수 없고 남는 공간에 다른 프로세스를 배정할 수도 없다.
따라서 내부 단편화를 줄이기 위해 어떤 크기로 나눌지 신중하게 결정해야 한다.
5️⃣ 분할 컴파일과 메모리 관리
이렇게 메모리 관리 방식에 대해 알아봤다.
부가적인 내용으로, 컴파일 과정에서 메모리가 어떻게 배정되는지 알아보자.
✔️ 분할 컴파일
앞서 고급언어로 작성한 소스코드는 컴파일 과정을 거쳐 목적 코드가 된다는 것을 살펴봤다.
컴파일러는 오류를 점검하고, 최적화를 통해 불필요한 변수와 코드를 삭제하며 고급언어를 기계어로 번역한다.
여러 개의 소스코드 파일을 하나로 합친 뒤 컴파일해 하나의 실행 파일로 만드는 것을 다중 소스코드라고 하고,
여러 개의 소스코드를 각각 컴파일해 하나의 실행 파일로 만드는 것을 분할 컴파일이라고 한다.
다중 소스코드 방식에서는 두 개의 파일을 컴파일 하기 위해 한쪽의 소스코드를 복사하여 다른 한쪽에 붙인 후 하나의 소스코드로 만든 후 컴파일을 한다.
그러나 이러한 방식은 다른 파일의 오류까지 검출해야 해서 번거롭다.
분할 컴파일 방식에서는 파일별로 각각 컴파일하여 목적 코드를 만든다.
이후 소스코드 대신 목적 코드를 전달해 오류 검사를 다시 할 필요가 없게 된다.
✔️ 변수와 메모리 할당
컴파일과 메모리 사이의 연관 관계를 알아보자.
char str = 'a';
int vol = 7;
float pri = 2.3;문자형을 1B, 정수형을 4B, 실수형을 8B로 가정하면,
char str = 'a'; 는 기계어에서 메모리 주소 0번지에 a 를 넣으라는 명령으로 번역된다.
int vol = 7; 도 마찬가지로 컴파일러는 메모리의 1번지부터 4번지까지 확보한 후 그곳에 정수7 을 넣는다.
즉, char, int, float 등은 자료의 형태 뿐 아니라 사용하려는 메모리의 크기를 나타낸다.
컴파일러는 프로그래머가 지정한 자료형에 따라 메모리를 확보하고 그곳에 값을 집어넣는다.
그리고 모든 변수에 대해 메모리를 확보하고 오류 검출을 위한 심벌 테이블을 유지한다.
위 예시 코드의 심벌 테이블은 아래와 같다.
| 이름 | 종류 | 범위 | 주소 |
|---|---|---|---|
| str | char | main() | 0 |
| vol | int | main() | 1 |
| pri | float | main() | 5 |
여기서 범위는 각 변수를 사용할 수 있는 영역을 나타내며, 변수마다 크기가 정해져있기 때문에 주소는 시작 주소만 명시하면 크기는 자동으로 정해진다.
사실 기계어 입장에서는 변수명을 알 필요가 없다. 기계어는 메모리 주소만 알면 데이터에 접근할 수 있기 때문이다.
그럼에도 변수명을 사용하는 이유는 프로그래머가 주소 값만으로는 무엇을 나타내는지 기억하기 어렵기 때문이다.
👏 마무리
이렇게 메모리 관리 기법에 대해 알아보았고, 컴파일과 메모리 사이의 연관 관계에 대해 정리해보았다.
다음 포스팅에서는 물리 메모리의 크기에 상관없이 메모리를 이용할 수 있게 하는 기술인 가상 메모리에 대해 알아보자.
참고 자료
💕좋아요와 댓글은 큰 힘이 됩니다.💕
