
얘네 아님
Introduction
recurrence, convolution을 쓰지 않고 attention만으로 인코더-디코더를 구현한 트랜스포머를 소개.
Background
Convolution을 쓰는 모델들은 연산 수가 신호(표현을 말하는 듯) 간 거리에 따라 증가하는데, 그러면 먼 거리의 위치 간 의존성을 학습하기가 어려워짐. 트랜스포머는 이 문제를 병렬 연산 (multi-head attention)으로 해결함.
Self-attention: 하나의 시퀀스의 다른 위치를 연결. 독해, 요약, 함의 등의 태스크에 쓰임.
End-to-end: recurrent attention 기반. 질의응답, 언어 모델에 쓰임.
트랜스포머는 오직 어텐션에 기반해서 인풋과 아웃풋의 표현을 학습하는 첫 모델임.
Model Architecture
인코더는 의 인풋 시퀀스를 연속표현 으로 매핑함. 이 으로 디코더가 아웃풋 시퀀스 를 내뱉음. 모든 스텝에서 모델은 auto-regressive, 즉 이전 심볼을 다음 스텝의 인풋으로 사용.
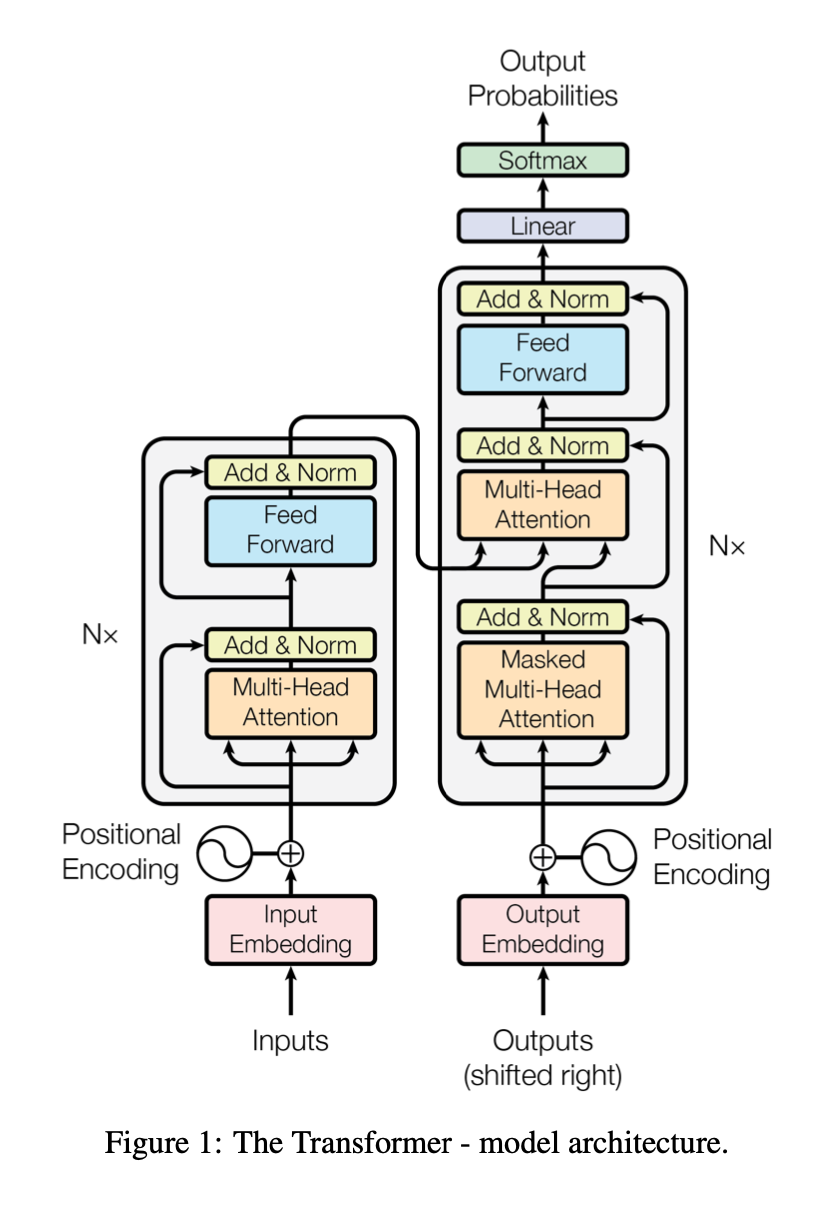
Encoder
6개의 레이어, 하나의 레이어에는 두 개의 서브 레이어.
- Multi-head Attention
- residual connection, layer normalization
- Position-wise feed-forward
- residual connection, layer normalization
Decoder
역시 6개의 레이어
- Masked Multi-head Attention
- residual connection, layer normalization
- Multi-head Attention
- residual connection, layer normalization
- Position-wise feed-forward
- residual connection, layer normalization
Masked Multi-head Attention은 미래의 단어를 참고하는 행위를 방지
Attention
어텐션은 query와 key-value를 매핑
Scaled Dot-Product Attention
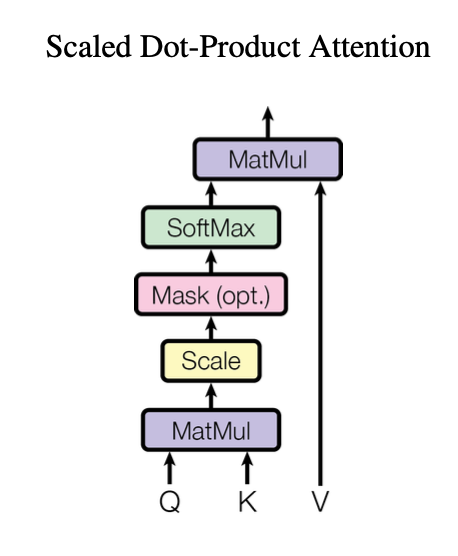
어텐션에는 additive와 dot-product 두 가지가 있음.
트랜스포머에서는 일반 도트 프로덕트 어텐션에서 루트 씌워서 스케일링. 도트 프로덕트는 훨씬 빠르고 메모리도 효율적임.
Multi-Head Attention
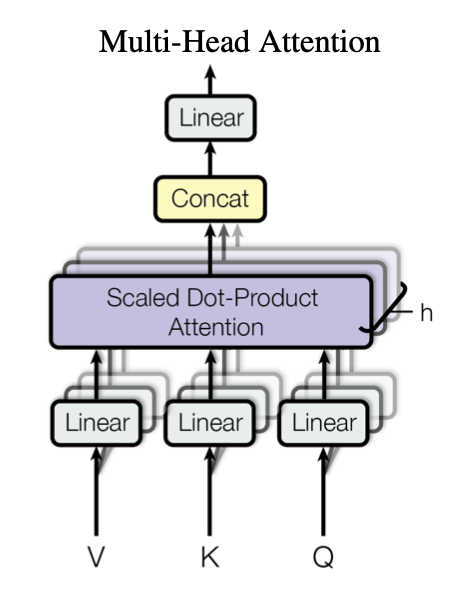
병렬 연산. , , 의 차원을 병렬로 연산하면 아웃풋은 이 나올 것. 이걸 다 concatenate.
다른 위치의 정보를 한꺼번에 어텐션할 수 있음.
8개로 head를 나누면 각각 64개의 차원이 나옴.

적용
- 인코더-디코더 어텐션: 쿼리는 디코더에서, 키와 밸류는 아웃풋에서 옴. 디코더의 모든 포지션이 인풋의 모든 포지션을 어텐드할 수 있음
- 인코더의 셀프 어텐션: 모든 키, 밸류, 쿼리가 인코더 안의 이전 층의 아웃풋에서 옴. 모든 포지션이 이전 포지션을 어텐드 가능.
- 디코더의 셀프 어텐션: 마찬가지로 디코더 내에서 이전 층의 포지션을 어텐드함. 다만 미래의 단어 어텐드를 막기 위해 마스킹.
Position-wise Feed-Forward Networks
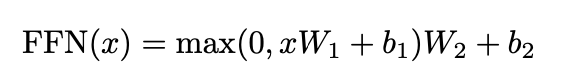
모든 포지션에 같게 적용. 파라미터는 층별로 다름. 1x1 사이즈의 convolution과 똑같은 원리.
Embeddings and Softmax
임베딩으로 인풋, 아앗풋 토큰을 d_model 차원의 벡터로 변환. 선형 변환, 소프트맥스 사용.
Positional Encoding
트랜스포머는 위치 정보를 따로 담을 수 없기 때문에 위치 정보를 따로 임베팅해주어야 함.
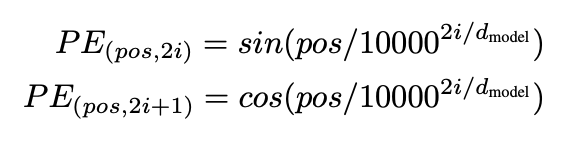
짝수 차원은 사인 함수, 홀수 차원은 코사인 함수 사용.
Why Self-Attention

왜 셀프 어텐션인가? -> recurrence, convolution과 비교했을 때 다음의 장점이 있음:
- 한 층의 연산 복잡도
- 병렬 연산 수
- 장기 의존성의 길이: 포지션 간 경로가 짧아야 장기 의존성을 학습하기도 쉬워짐.
셀프 어텐션은 모든 포지션을 정수 개의 연산으로 연결하는 반면 recurrent는 의 연산이 필요. 대부분의 번역 모델이 그렇듯 시퀀스 길이 n이 차원 d보다 작기 때문에 셀프 어텐션이 더 빠름.
추가적으로 r의 이웃만 고려하게 하면 (범위 설정인듯) 더 복잡도를 줄일 수 있음.
컨볼루션의 경우 모든 인풋과 아웃풋이 연결되지 않기 때문에 O(n/k)나 O(logk(n))의 연산이 필요함. 이렇게 하면 두 위치 간의 길이를 늘리게 됨. 분리 컨볼루션은 복잡도를 줄여주는데 셀프 어텐션, 즉 이 모델에서 한 방법과 같음. 따라서 셀프 어텐션은 컨볼루션에 비해 연산이 적다는 뜻인 듯 하다.
셀프 어텐션은 모델의 해석 가능성을 더 높여준다. 또한 syntactic, semantic적 특성을 더 잘 포착한다.
Training
- 영-불 데이터셋
- Adam optimizer
- Residual dropout, Label smoothing의 정규화 사용
Results
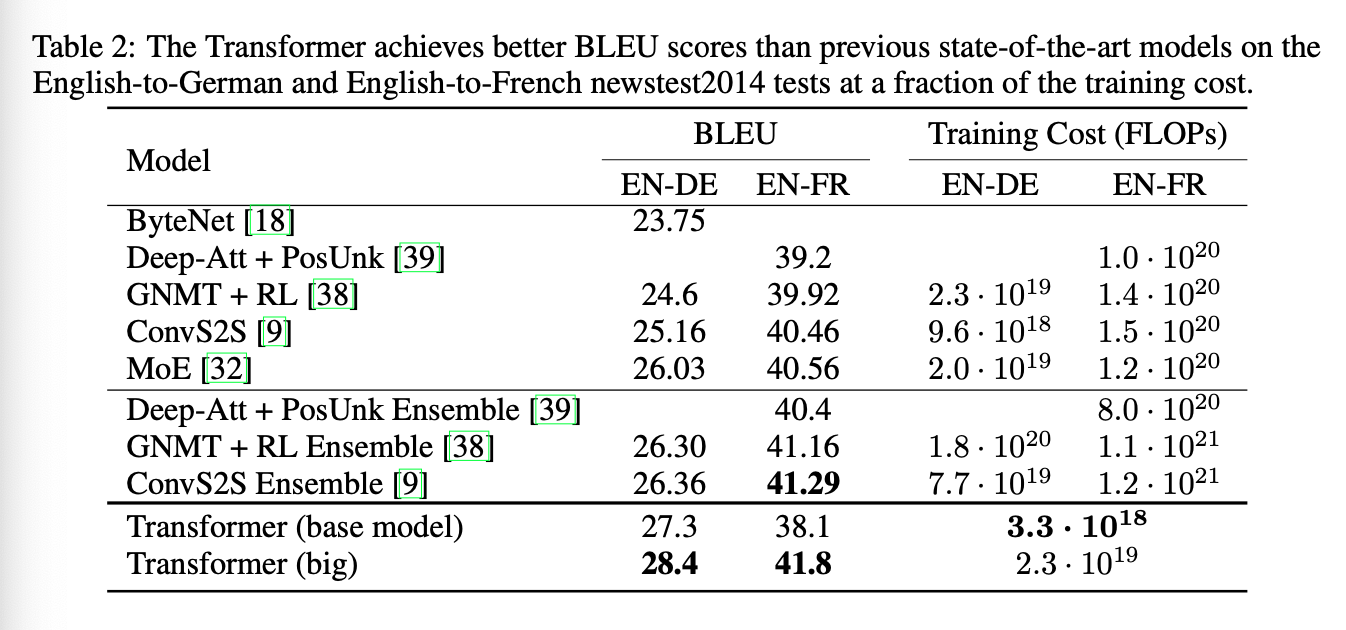
다른 모델에 비해 번역 태스크 빠르게 수행. sota 달성.
constituency parsing도 해봄. 아웃풋에 제한이 많고 인풋보다 길다는 문제점. 또한 RNN seq2seq모델은 sota 달성을 하지 못한 태스크임.
4개의 층으로 반지도학습 시킴. sota는 아니지만 꽤 좋은 결과
