본 글은 야간모드에 최적화 되어있습니다. 우측 상단에서 해 혹은 달모양을 클릭시어 velog 설정을 야간모드로 해주시면 더욱 편안하게 읽으실 수 있습니다.
🤔 Problem Date : 22.08.08
👊 Solve Date : 22.08.08
오늘은 출근하자마자 터진 스펙타클한 상황을 조치한 내용을 작성해보려고한다.
인수인계 받은지 2주일밖에 안됐는데 이러니 조금 당황스러웠는데, 의심가는 상황들을 찾아보고 원인을 파악해서 수정을 했다. 완벽한 수정은 아니지만 미봉책같은... 그러한 조치이다.
개발자로써 떨떠름하기는 하지만 아래와 같은 상황이기 때문에 최대한 버틸만큼 버텨보려고한다 ㅋㅋ
문제 상황
밑바탕에 깔린 배경상황으로는 지금 우리 회사는 FE,BE 서비스 재구성을 위한 과도기에 있다.
서버 상태가 굉장히 불안정한 편이고 원인은 찾아 냈지만 여러모로 건드렸다가는 해결을 하기 어려운 상태인지라 임시 조치만 간단하게 취해놓은 상태이다.
그 상태로 조금씩 버텨오면서 지내고 있는데, 오늘 생각지도 못한 이슈가 하나 터져버렸다.
Elastic Search를 통해 강사 정보를 불러오도록 해주는 것으로 교체를 했었는데, 출근하고 나니 강사정보가 3명밖에 보이지 않는다는 것이다. 어느때처럼 기능 유지보수를 실천하려했는 월요일 첫날에 이런 문제가 생기니 당혹감이 그지 없었다.
원인 파악
기존에 작업했을 때 QA 및 테스트케이스를 전부 거치고 사업부와 C라인의 확인 및 허가아래 배포를 했던 내용인지라, 처음부터 하나하나 짚어보는 것으로 결정했다.
- API GateWay의 문제인가?
- Lambda function 내 코드에서 발생하는 문제인가?
- 강사 개개인의 정보 업데이트 코드에 문제가 있나?
- 강사 정보 전체 업데이트에 문제가 있나?
위 4가지 사항이 가장 먼저 생각이 되었기 때문에 가장 큰 부분부터 시작해서 차근차근 짚어나갔다.
1. API GateWay의 문제인가 ?
일단 lambda를 통해 작성된 함수로 es 업데이트를 하고 API Gateway를 통해 호출을 하기 때문에, API Gateway부터 점검을 거쳤다.
사이트 내에서 일단 API response status는 200인걸보니 Gateway 문제는 아니라고 생각했지만, 혹여나 해서 게이트웨이에서 API 테스트를 돌려본 결과 일단 응답 데이터는 비정상이지만 응답 값은 정상적으로 도달했다.
역시 게이트웨이 문제는 아니었다.
2. Lambda function 내 코드에서 발생하는 문제인가?
결론부터 얘기하면 이곳에서 발생하는.. (정상적이라면 발생하지 않을) 예외케이스가 발생해서 생긴 문제가 하나 있었다. 자세한 내용은 아래에서 후술
3. 강사 개개인의 정보를 업데이트 하는 곳의 문제?
강사의 정보 종류가 굉장히 다양해서 모든 케이스에 es 업데이트를 걸어놓은 상태였다.
강의 활성화/비활성화를 하는 케이스에도 es 업데이트를 걸어놓은 상태였기때문에, 가장 간단하게 확인해볼수 있는 백오피스를 통해서 그 부분부터 확인해보니 정상적으로 잘 반영 되었고, 운영계에서 테스트용으로 빼둔 계정끼리 예약을 시도해보니 시간표도 잘 반영이 되었다.
보이지 않는 강사도 비활성화 이후 다시 활성화를 시키니 잘 표기 되는것을 확인해서 해당 부분의 문제는 아니라고 판단했다.
4. 강사 전체 정보를 업데이트 하는 곳에 문제가 있는 것인가?
3번에서 설명했던 Lambda function 내에 있는 이 부분이 문제였다. 1차적으로는 강사정보 업데이트가 필요한 곳에서 기존 es 데이터와 다르게 변동이 일어나는 경우 es에 무조건 업데이트를 시키도록 설정해두었고, 2차적으로는 1시간마다 es에서 전체 데이터를 꾸준히 업데이트 해주도록 스케쥴러를 돌렸는데, 이 부분에서 문제가 나왔다.
문제 해결
우선 우리 서비스에서 사용하고 있는 es에 업데이트가 되고 캐시된 데이터를 가져가는 과정은 아래와 같다.
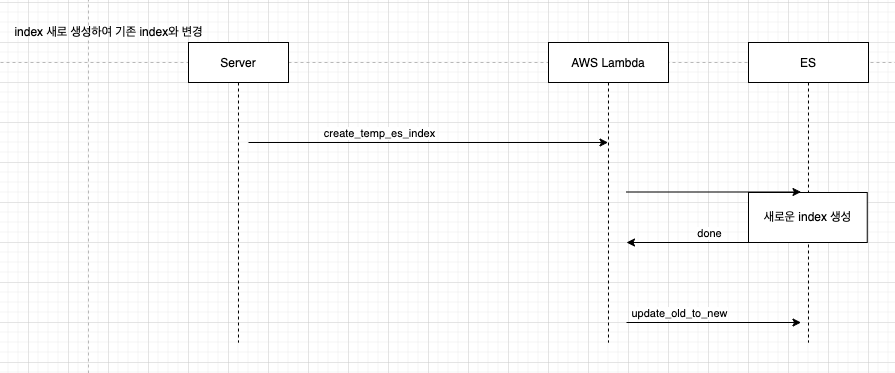
- 프론트에서 강사리스트 조회 요청 혹은 강사 정보 업데이트 요청이 들어온다.
- 프론트에서는 AWS Lambda로 ES에 인덱스를 생성하게 호출하고
- AWS Lambda는 1차적으로 우리 DB에 있는 데이터를 캐시하여 인덱스를 가지고 ES로 넘겨준다.
- ES는 해당 인덱스 생성이 완료되면 ES로 부터 AWS lambda에 해당 인덱스를 넘겨주고
- 프론트는 캐시된 ES의 데이터를 AWS lambda로 부터 전달 받아 뿌려준다.
- 업데이트가 필요한 상황에서는 AWS lambda 함수를 통해 es로 정보 갱신 요청을 하고 es는 해당 데이터를 전달받아 es에는 새롭게 캐시된 데이터를 가지고 있는다.
이 과정의 반복인데, 각각 개별적으로 업데이트를 요청하는 부분에서는 문제가 되지 않았다.
하지만, 전체를 업데이트하는 과정에서 아래 구분을 보면 우리 서버로 강사정보를 요청하는 부분이 있는데, 이때 강사의 수업시간표와 예약정보, 그리고 강사 정보까지 모든 강사에 대해서 가져와서 업데이트를 하도록 한 부분이 있었다.
def update_tutors():
... 중략
# 임시 인덱스 삭제
try:
es.indices.delete(index="tutor-info-temp")
except:
pass
# 임시 인덱스 새로 생성
for tutor in tutor_list:
es.index(index="tutor-info-temp", id=tutor['tutor_id'], document=tutor)
es.indices.delete(index="tutor-info")
es.indices.refresh(index="tutor-info-temp")
res = es.reindex(source={"index": "tutor-info-temp"}, dest={"index": "tutor-info"})
es.indices.refresh(index="tutor-info")
else:
pass
... 중략위에 있는 이 임시 인덱스 생성 부분에서 문제가 발생했다.
try-catch로 묶어 두긴했는데 강사의 모든 데이터 자체를 우리서버에서 불러오다보니, 서버 요청이 오래 걸리던터라 1~2초의 지연이 발생했는데,
해결 방법으로 임시 캐시데이터를 만들어서 그쪽을 바라보도록 처리하고,새로운 데이터는 백그라운드 상태로 빼서 작업을 처리하도록 했다.
그 과정에서 문제는 없었지만 우리 서버가 불안정한게 문제였다..
위에서 서술했듯 우리 서버는 아예 다른 서버로의 완전한 리팩토링과 마이그레이션을 준비중인터라 기존 서버는 간신히 명맥만 유지하는? 모습을 취하고 있었기때문에 쿠버네티스 파드가 멈추어서 서버요청을 못받게 되면 강제로 파드를 재생성하도록 하는 임시방편을 달아두었는데 이게 문제였다.
기존에 존재하는 임시 인덱스를 먼저 삭제하고 서버에서 불러온 데이터를 토대로 임시데이터를 다시 짜는데, 이때 튜터 데이터를 불러오다가 서버가 다운되어 파드가 재생성되면 서버간 통신이 원활하지 못해 그 중간까지 받은 데이터로만 튜터를 생성한 것이다.
그래서 해당 부분을 실행하기 전에 아래 코드처럼 서버의 헬스체크를 진행하고 정상일 경우에만 진행하고 그게 아니라면 전체 업데이트는 진행하지 않고 넘어가도록 변경했다.
health_check = api_urls.base_api_url + "/access-test"
try:
health_check_response = requests.get(health_check)
if health_check_response.status_code == 200:
... { 위의 코드 실행 }다행이도 이렇게 진행 한 이후로는 동일 증상이 발생하는 없었다.
조금 걸리는 것이라면, 헬스체크를 할 시점에는 정상이었지만 안에서 새로 임시 인덱스를 만들 때 해당 증상이 발생하는 것도 문제라는 점인데, 그때는 그냥 전체 업데이트에 대해서 스케쥴러를 내려버릴까도 고민중이다.
일단 위 기능이 2차 방지책으로 사용하기위해 올려두었다는 것이고, 학생들의 예약,취소 및 강사들이 입력하는 모든 정보의 CRUD가 이루어지는 곳에는 es 업데이트를 전부 달아놓았고 정상인 것을 확인했으니 충분하다고 생각이 들었다.
2차 방지책으로 올려둔게 오히려 역효과로 운영서비스에 문제를 주면 안되는거니깐 고려해볼만 한 듯 하다.
다른 곳에서는 자신들의 서버가 죽는 경우가 없겠지만, 이럴 경우에는 어떻게 대처할까? 궁금해진다.
찾아보고 배울만한 내용이 있다면 해당 글에 추가해봐야겠다.
