- 본 문서는 Matt.Lee(이성욱)님께서 번역해주신 Emmanuel Goossaert씨의 'Coding for SSD' 문서를 읽고 정리 및 요약한 자료입니다. 이 문서로부터 발생하는 모든 지식에 대한 감사는 Emmanuel Goossaert씨와 Matt.Lee(이성욱)님께 드립니다. 좋은 글 정말 감사합니다.
- 출처: https://tech.kakao.com/2016/07/13/coding-for-ssd-part-1/
- 본 문서는 기존의 글을 조금 더 이해하기 쉽고 깔끔하게 다듬는 수정과정을 거쳤습니다. 수정 과정에서 본의 아니게 그 뜻과 의미가 왜곡된 경우가 발생할 수 있음을 안내드립니다.
Chapter 1. SSD 아키텍처와 벤치마크
1. SSD의 구조
1.1. NAND Flash memory cell
- SSD를 이루는 NAND flash memory의 하나의 cell의 구조는 다음과 같이 이뤄져있다.
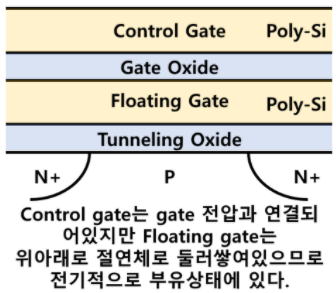
- NAND Flash는 제한된 (Wearing-off) 수명 (P/E Cycles)을 가지고 있다는 중요한 특징이 있다.
매 P/E cycle마다 floating gate에 갇히는 일부 전자가 일정 수준을 넘어서게 되면 해당 셀은 사용할 수 없게 된다.
1.2. SSD의 구성과 종류

- Host의 요청은
host interface를 통해서 전달되며 가장 일반적인 것으로는 SATA와 PCIe 타입이 있다. - SSD는 자체적으로 DRAM을 가지고 있고 여기에는 address mapping을 위한 정보 (i.e. table)가 저장되거나 캐시 용도로 사용된다.
- SSD의 소자들은 PCB 기판 위에 실장하는 형식의 SMT (Surface Mounted Technology)공법으로 만들어진다.
- SSD는 하나의 메모리 셀에 저장하는 데이터 비트수에 따라 여러가지 종류로 나뉜다.
- SLC (Single Level Cell): 하나의 메모리 셀에 하나의 비트만 저장된다. 가장 빠른 속도와 긴 수명을 가지지만 큰 용량을 가질 수는 없다.
- MLC (Multiple Level Cell): 2개의 비트를 저장할 수 있다. SLC에 비해서 상대적으로
latency가 높고 짧은 수명을 가진다. - TLC (Triple Level Cell): 3개의 비트를 저장할 수 있다. 대용량으로 만들 수 있으며 읽기가 매우 많다면 TLC가 가장 적절한 선택이 될 수 있다. 실제 서비스 수준의 workload로 수행한 벤치마크 결과에 따르면 TLC 타입의 메모리 수명도 크게 문제되지 않는 것으로 확인되었다.
- Flash는 여러 개의
plane으로 구별되며 하나의 Plane은 여러개의block을 가지고 있고 또 하나의 block은 여러 개의page를 갖고있다. 제조사 및 제품마다 다르지만 보통 하나의 page는 2~16KB 정도의 용량을 가지고 있다.
2. 벤치마킹과 성능 매트릭
2.1. Pre-conditioning의 필요성
- 벤치마크는 수행자의 의도에 따라 원하는 결과를 의도적으로 만들어낼 수 있다.
- SSD는 전체 공간에 대해 0.5~3시간 정도 사용하는 수준의 대량 워크로드에 대해 공통적으로 눈에 띄는 성능 저하 (Throughput 저하, Latency 증가)를 보인다.
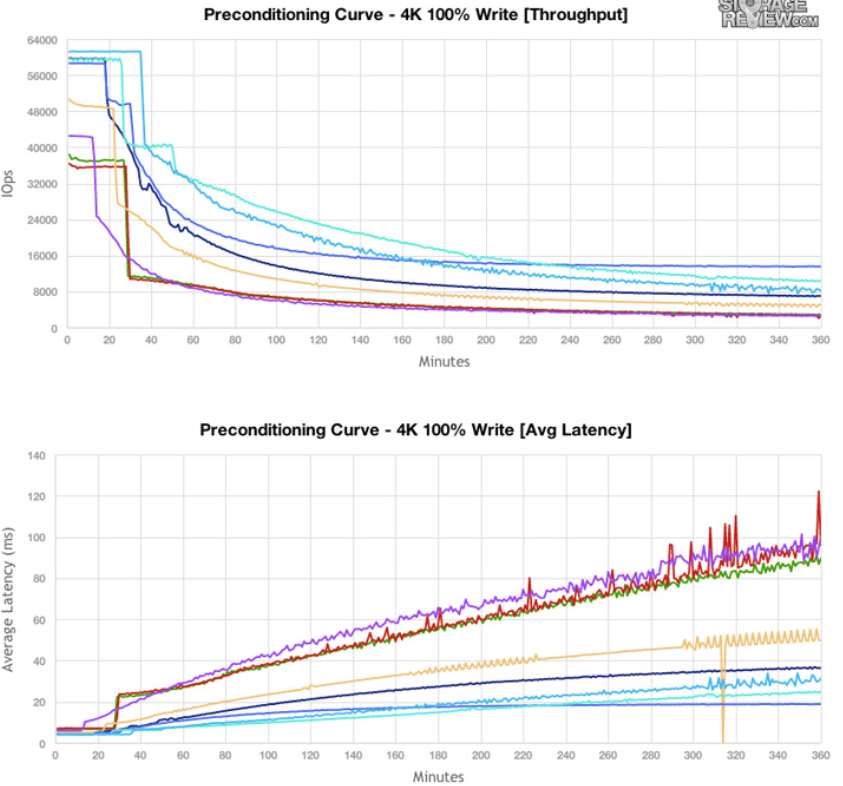
- 이렇게 의도적으로 쓰기 부하를 발생시켜 최악의 상황을 만드는 것을 Pre-conditioning이라고 하며 좀 더 신뢰성 있는 벤치마크 결과를 얻을 수 있다.
- Pre-conditioning의 원리는 다음과 같다. 대량의 랜덤 쓰기로 인해 SSD가
sustaining mode로 진입하면garbage collection이 host의 foreground request가 들어올 때마다 먼저 block을 지우는 선행작업을 수행해야하기 때문에 심각한 성능 저하가 발생하게 된다. - 그러나 현명한 소비자라면 단순히 pre-conditioning에서 우수한 성능을 보이는 SSD를 구매하는 것이 아니라 실제 본인의 사용 환경과 유사한 워크로드에 대한 벤치마크 결과를 보고 구매하는 것이 좋다.
2.2. 성능 메트릭
- Workload type: 사용자로부터 수집되는 데이터에 기반한 특정 패턴을 보이는 시퀀셜 또는 랜덤 데이터 접근의 벤치마크.
- Queue length & depth: SSD로 읽기/쓰기 명령을 전송하는 동시 쓰레드의 개수를 의미
- Throughput
- IOPS (Input & Output Per Second): 초당 읽고 쓰기의 회수를 의미하며 일반적으로 초당 읽고 쓸 수 있는 4KB의 데이터 청크의 개수를 의미한다. 초당 1000 IOPS는 으로 환산할 수 있다.
- Latency: 입출력 명령이 전달된 후 응답을 받기까지의 시간을 의미한다.
가장 중요한 것은 SSD를 장착하고자 하는 시스템에서 어떤 메트릭이 가장 크리티컬한 요소인지를 파악하는 것이다.
Chapter 2. Page & Block & FTL
3. Basic Operation
3.1. Read & Write & Erase
- NAND flash는 특정 셀을 단독으로 읽고 쓰는 작업이 불가능하다.
- READ: 읽기는 page 단위로 수행한다. 하나의 page 크기보다 작은 크기의 데이터만 따로 읽을 수는 없기 때문에 불필요한 데이터를 많이 읽게 된다.
- WRITE: 쓰기도 page 단위로 수행한다. 단 1-byte를 쓰는 경우라도 반드시 전체 페이지를 기록해하는데 이런 현상을
Write Amplification이라고 한다. Write은 반드시 free 상태인 page에 대해서만 가능하기 때문에 덮어쓰기 (overwrtie)가 불가능하다. 만일 덮어쓰기를 수행하고 싶다면 해당 page의 내용을 내부 레지스터로 복사한 후 레지스터에서 변경되어 새로운 free 상태인 page에 쓰게 된다. 이때 기존의 page는 stale (invalid) 상태가 되며 추후 GC에 의해 지워진다. - ERASE: 지우기는 block 단위로 이뤄지며 stale 상태의 페이지들의 데이터를 지워서 free 상태로 만들어주는 역할을 한다.
3.2. Write Amplification
- Page 크기와 일치하지 않는 모든 쓰기는 추가적인 쓰기 부하 (Write amplification)가 필요하다.
- 해당 페이지의 내용을 캐시에 저장한 뒤 write 후 다시 해당 페이지에 기록해야하므로 바로 기록하는 것보다 느릴 수 밖에 없다. (
Read-modify-write과정) - Throughput을 최대화하기 위해서 가능하면 작은 쓰기는 메모리에 버퍼링해둔 뒤 버퍼가 가득 차면 단일 쓰기로 최대한 많은 데이터를 기록할 수 있도록 하자. (
Align writes)
3.3. Wear Leveling
- SSDC의 중요한 역할 중 하나는 모든 block의 P/E cycle이 골고루 분사되게끔 쓰기를 실행하는 것이다.
- 최고의 wear leveling을 위해서 때로는 특정 block을 다른 곳으로 옮겨야 될 수도 있다. 이때 또 다른 'write amplification'이 발생할 수 있다.
- 따라서 write amplification으로 인한 성능 저하와 wear leveling으로 인한 수명 향상 사이에서 FTL 및 컨트롤러는 적절한 타협점을 찾아야 한다.
4. FTL (Flash Translation Layer)
4.1. FTL의 등장과 필요성
SSD의 인기 비결
- SSD가 HDD의 자리를 뺴앗을 정도로 선풍적인 인기를 얻을 수 있었던 가장 큰 원인은 HDD보다 우월하게빠른 average access speed 덕분이라 알려져있다.
- 하지만 숨겨진 비밀은 바로 SSD가 HDD와 동일한 host interface를 사용한다는 점이 없었더라면 SSD의 빠른 속도로도 이렇게 갑작스럽게 시장을 점유할 수 없었을 것이다.
- Physical address를 사용하는 SSD가 HDD와 동일한 host interface를 사용하기 위해서는 부가적인 컴포넌트가 필요했는데 이것이 바로 FTL (Flash Translation Layer)다.
FTL의 두 가지 주요 역할
- FTL은 host로부터 전달되는 logical address를 physical address로 mapping 해주는 역할을 한다.
- FTL은 NAND의 stale한 block을 erase 해주는 garbage collection을 foreground 또는 background에서 제어하는 역할을 수행한다.
4.2. Logical Block Mapping
- 앞서 언급했다시피 NAND의 physical address를 control하기 위해서는 host의 logical address에 대한 요청을 physical address로 mapping 해주는 작업이 반드시 필요하다.
- Mapping에 필요한 정보가 담긴 table은 빠른 access를 위해 SSD 내부의 DRAM에 저장된다.
- SSD에 전원이 공급되는 동안 table의 정보는 DRAM에 있다가 전원공급이 중단되면 NAND flash에 저장된다.
- 다시 전원이 공급되면 FTL은 저장된 flash의 mapping table을
fetch - decode - execute - store해서 메모리에 저장한다. - Mapping table을 만드는 방식은 세 가지가 있다.
- Page-level Mapping: Mapping table을 하나의 page 단위로 구성한다. 이는 가장 단순한 방법이고 빠른 접근을 실현하는 좋은 방법이지만 table의 크기가 굉장히 커진다는 단점이 있다.
- Block-level Mapping: Mapping table을 하나의 block 단위로 구성한다. 만일 하나의 block이 256~512개의 page로 구성된다면 1번 방법보다 table의 크기가 256~512배 작아진다는 장점이 있다. 그러나 페이지 하나만 기록되어도 될 정도의 작은 데이터를 자주 업데이트하는 경우에도 블록 전체를 통째로 기록해야하기 때문에 write amplification이 폭발적으로 증가한다는 단점이 있다.
- Hybrid Log-block Mapping: (본문의 내용 뿐만 아니라 구글링 조사결과의 내용 모두 이해가 불가함. 추후 지식을 채워넣어야 함)
4.3. Garbage Collection (GC)
- Foreground GC: Free space가 얼마 남지않은 드라이브에 대해 큰 데이터 청크를 write한다고 가정하면 용량 확보를 위해 stale state block을 최대한 free state block으로 만들어주는 과정이 필요하다. Foreground GC가 필요한 정도의 과도한 쓰기 부하를 필요로 하는 워크로드는 흔하지 않다.
- Background GC: SSD가 idle time일 때 FTL은 자동으로 GC를 수행한다. Background GC 수행은 foreground에서의 사용자의 명령 수행을 방해 할 수 있다.
- GC 최적화를 위해 데이터가 더 이상 필요하지 않거나 삭제해야 할 때는 최대한 모아서 단일 오퍼레이션에 삭제하는 것이 좋다. 이는 GC가 한 번에 큰 영역을 처리하도록 해주며 내부 fragmentation을 최소화시켜 준다.
4.4. 업계상황
- SSD 컨트롤러의 mapping 전략은 SSD의 전체적인 성능을 결정하므로 아주 중요한 요소다.
- 경쟁이 심한 SSD 시장에서 자사의 FTL 알고리즘에 대한 상세한 내용을 전혀 공개하지 않는 이유가 바로 이 때문이다.
- 일부 학자는 워크로드와 벤치마크를 분석해서 SSD가 사용중인 mapping 알고리즘을 리버스 엔지니어링 할 수 있다고 주장하지만, 저자는 정확히 판단하기는 어렵다고 생각한다.
- 또한 하나의 맵핑 알고리즘을 알기위해 리버스 엔지니어링을 한다고 해도 여러 사용 환경에 따라 다른 최적화 결과를 내기 때문에 그다지 의미 있는 일도 아니다.
Chapter 3. 고급기능과 내부 병렬 처리
5. 고급기능
5.1. TRIM
- TRIM은 OS가 해당 logical space가 더 이상 필요하지 않음을 SSDC에 전달해 주는 기술이다.
- 불필요한 block들에 대한 정보는 GC가 불필요한 copy-erase-write을 수행하지 않고 효율적인 erase를 할 수 있도록 해준다.
- (구체적인 과정에 대해서 조사하고 써놓기. 너무 추상적임)
- 대부분의 SSD는 TRIM 명령을 지원하고 OS, SSDC, 파일 시스템 3개가 모두 TRIM을 지원해야 사용이 가능하다.
5.2. Over Positioning
- SSD의 공간 중 OS와 파일 시스템이 볼 수 없는 일부 공간 (약 7~25%)을 할당하는 기술이다.
- Over positioning의 역할은 두 가지다.
- 임의의 page와 block이 수명이 다 되는 경우 자동으로 대체되는 공간으로 사용한다.
- 과도한 foreground random write 요청이 들어오는 경우 여분의 free space가 부족하게 되서 foreground GC가 성능을 깎아내리는 문제가 있는데 이때 충분한 크기의 buffer로 사용된다.
- 해당 공간은 OS가 사용하지 않음이 명백한 공간이므로 미리 GC가 가능하며 이는 TRIM 명령 효과를 낸다.
5.3. Secure Erase
- FTL mappting table을 초기화함으로써 SSD를 초기 상태로 만들어서 성능을 회복시키는 기술.
- 하지만 memory cell의 P/E cycle을 초기화 시켜주는 것은 아니다.
- (보안과 관련된 사항은 이 문서에 기재되어있지 않음)
5.4. Native Command Queueing (NCQ)
- Host가 busy한 경우 최대한 빠르게 데이터 접근을 해소해주기 위해 유입되는 명령들의 우선순위를 높혀서 latency를 낮춰주는 기술이다.
- NCQ는 host의 명령을 queueing하여 우선순위를 재설정하고 때로는 지연처리 한다.
5.5. 전력 차단 보호 (Power-loss Protection)
- 갑작스러운 전원 차단으로부터 SSD를 보호하기 위한 기술이다.
super capacitor를 이용해서 전원 공급이 차단되었을 때 요청된 남은 I/O를 처리한다.- 전원 실패 (Power Failure, 정전)에 대한 데이터 손상 문제를 해결해주는 여러 기술 중 하나다.
6. SSD의 내부 병렬 처리

- SSD는 넓은 범위에서 좁은 범위 순으로 채널 (Channel), 패키지 (Package), 칩 (Chip), 플레인 (Plane), 블록 (Block), 페이지 (page) 레벨로 구성되어 있고, 각 레벨에서 다양한 병렬 처리 능력을 제공한다.
- Channel-level Parallelism: 각 channel은 서로 독립적이며 동시에 액세스 가능하다. 각 개별 channel은 여러 패키지로 구성되어 있다.
- Package-level Parallelism: 각 package도 서로 독립적이며 동일 channel을 공유하는 package들은
Interleaving모드로 동시에 명령 실행이 가능하다. - Chip-level Parallelism: 하나의 package는 하나 또는 두 개의 chip을 가지며 각 chip들은 독립적으로 병렬 접근이 가능하다.
- Plane-level Parallelism: 각 칩은 2개 이상의 plane을 가지며 동일 operation은 여러 plane에 대해서 동시 실행될 수 있다.
- 여러 chip에 걸쳐서 한 번에 접근할 수 있는 여러 block을
clustered block이라고 하고 HDD의 RAID striping 전략과 비슷하다.- 하나의 clustered block은 약 16~32MB 크기를 가진다.
- SSD의 read/wrtie의 단위는 clustered page, erase 단위는 clustered block이라고 이해하면 된다. 이는 내부 병렬 처리 능력을 최대한 활용할 수 있는 크기이기 때문이다.
- 물리적인 한계 떄문에 비동기 방식의 NAND 플래시 I/O 버스는 32~40MB/s의 대역폭 이상을 서비스할 수 없다.
- SSD 제조사 입장에서 성능을 향상시킬 수 있는 방법은 다수의 패키지를 병렬로 처리하거나 인터리빙(interleaving) 모드로 동작하도록 설계를 변경하는 것이다.
Chapter 4. 접근 방법과 최적화
7. Access Pattern (접근 방식, 방법)
7.1. Sequential & Random I/O 정의
- 이전 I/O operation의 마지막 LBA가 시작 LBA인 경우를
sequential하다 라고 하고 그렇지 않은 경우를random하다 라고 한다. - 오판하지 말아야 한다. 연속적인 LBA일지라도 실제 물리적인 데이터의 위치가 연속적이지는 않을 수 있다.
7.2. Write pattern
- Random write이 언제나 sequential write보다 느리지는 않다.
- Clustered block의 크기보다 작은 write에서는 sequential write이 빠르다.
- 메모리의 모든 update는 많은 write을 발생시키는데, 작고 빈번한 random write은 mapping table을 자주 갱신해줘야 하기 때문이다.
- Sequential write은 mapping table의 변경을 덜 필요로 하기 때문에 동기화하는 회수도 줄어들게 된다.
- 작은 random write은 stale page들이 일부 영역에 집중화 (localization)되는 것이 아니라 전체 공간에 골고루 퍼지는 '내부 프레그멘테이션 (internal fragmentation)'을 생성한다.
- 이러한 내부 프레그멘테이션은 GC가 free page를 만들어내기 위해 많은 block erase를 실행하게 만드는
cleaning efficiency를 유발한다.
- Clustered block의 크기와 같거나 그 배수 정보의 큰 write에서는 random write이 sequential write과 비슷한 성능을 낸다.
- 이는 해당 크기에서 SSD 내부 병렬 처리의 최대 능력을 활용할 수 있기 때문이다.
- 대량의 데이터를 기록하는 경우에는 sequential이든 random이든 동일한 내부 병렬 처리방식을 모두 사용하기 때문이다.
- Clustered block의 크기보다 작은 write에서는 sequential write이 빠르다.
7.3. Read pattern
- Sequential read와 random read의 성능은 workload에 의존적이다.
- Read는 write 뒤에 따라오는 결과물이기 때문에 write patten에 의존적이다.
- Read 또한 내부 병렬 처리 능력을 활용할 수 있도록 연관된 데이터들은 동일 page, block 또는 clustered block에 저장해야 좋다.
- 하나의 큰 write은 내부 병렬 처리 기법들에 의해 여러 chip 또는 block에 분산되어 저장됐을 것이다.

-
위 그림은 이해를 돕기 위해 SSD의 내부 병렬 처리 기능을 활용한 write과 read 과정을 표현한 그림이다.
- 예시 그림의 SSD는 4개의 chip과 4개의 plane 그리고 2개의 channel을 가지고 있다.
- Clustered block 크기의 sequential write 요청
(A, B, C, D)가 들어오면 빠른 처리를 위해interleaving mode를 이용해서 4개의 plane으로 striping한다. 따라서 4개의 block은 연속된 LBA를 가지지만 실제 내부적으로는 서로 다른 물리적 위치에 저장되는 것을 확인할 수 있다. - 사용자로부터 2번의 read 요청
(A, B, E, F)와(A, B, G, H)가 들어왔다고 가정하자.- A와 E, B와 F는 동일한 plane에 있고 모두 동일한 channel에 있으므로
(A, B, E, F)는 1개의 channel의 2개의 plane으로부터 read 한다. - A, B, E, F는 모두 다른 plane에 저장되어 있기 때문에
(A, B, G, H)는 2개의 channel의 4개의 plane으로부터 동시에 read 할 수 있다.
- A와 E, B와 F는 동일한 plane에 있고 모두 동일한 channel에 있으므로
- Read에 더 많은 channel과 plane을 이용할 수 있다는 것은 좀 더 내부 동시성 처리 기능을 활용할 수 있음을 의미하며 더 나은 읽기 성능을 보장받을 수 있게 된다.
-
단일 쓰레드의 큰 read가 멀티 쓰레드의 작은 read보다 낫다.
- 동시 랜덤 read는 SSD의 Read ahead 메커니즘을 제대로 활용하지 못할 수도 있다.
- 여러 LBA를 동시에 접근하는 방식은 내부적인 병렬 처리 기능을 제대로 활용하지 못하고 결국 같은 chip으로 집중될 수도 있다.
- 큰 read는 연속된 주소에 접근함으로써 read ahead buffer를 활용할 수 있다. 결과적으로 한번에 대량의 데이터를 읽는 방법이 추천된다.
7.4. Write & read pattern
-
때로는 읽고 쓰기를 동시에 해야하는 경우가 생길 수 있지만 이는 좋은 방법이 아니다.
- 같은 resource에 read와 write이 동시에 발생에서 race condition이 발생할 우려가 있기 때문이다.
- 내부적인 캐싱이나 read ahead buffer 매커니즘을 제대로 활용할 수 없기 때문이다.
-
동시에 read와 write을 수행하는 것은 피하고 하나씩 큰 용량의 데이터 청크를 read하고 write 하는 것이 좋다.
예를 들어 1,000개의 파일이 업데이트 되어야 한다고 가정할 때, 하나씩 read하고 write 하는 방법도 있지만 이보다는 1,000개를 한 번에 read하고 그 다음에 한 번에 write 하는 것이 좋다.
8. SSD 최적화
본 절에서는 SSD를 최적화하기 위한 여러가지 시스템적 (주로 리눅스) 방법을 소개한다.
- 파티션 얼라인먼트 (Partition Alignment)
- 페이지 크기에 맞는 write은 read-modify-write 과정 없이 바로 기록될 수 있다.
- 따라서 write에서 파티션이 NAND flash page size와 물리적으로 맞춰졌는지 (align)는 매우 중요한 고려사항이다.
- 구글링을 통해 특정 SSD 드라이브 모델의 page, block, clustered block의 크기를 확인할 수 있다. 파티션 얼라인먼트를 통해서 성능을 상당히 끌어올릴 수 있다는 것은 이미 여러 문서에서 확인됐다.
- TRIM 명령 활성화
- 파일 시스템과 리눅스 커널이 TRIM 명령을 지원하는지 확인한다.
- 다시 말하지만, TRIM 명령은 host에서 삭제되는 block의 정보를 SSDC에 전달해서 GC 때 삭제된 블록에 대한 불필요한 복사 작업을 수행하지 않도록 도와준다.
- OS I/O 스케줄러 조정
- 리눅스의 기본 I/O 스케줄러는
CFQ(Completely Fair Queueing)이다. - CFQ는 I/O 요청을 재정렬해서 배치 프로세스로 처리하기 때문에 기존의 기계적인 스피닝 방식을 이용하던 HDD에 대한 seek-time을 최소화해줄 수 있었다. 하지만 SSD에는 그런 배려가 필요하지 않기 때문에
NOOP이나DEADLINE알고리즘으로 바꾸는 것이 좋다는 의견이 있다. - 하지만 저자는 굳이
CFQ스케줄러에서NOOP이나DEADLINE으로 바꿀 필요는 없다고 본다.
- 리눅스의 기본 I/O 스케줄러는
- 스왑 및 임시 파일 (Swap & Temp files)
- Swap이 자주 사용되는 경우에는 많은 I/O 요청이 발생하기 때문에,SSD 에 swap 파티션이 있는 경우 random write이 자주 발생해서 수명이 훨씬 더 빨리 줄어들 수 있다

임베디드 시스템 공학자를 지망하는 컴퓨터공학+전자공학 복수전공 학부생입니다. 타인의 피드백을 수용하고 숙고하고 대응하며 자극과 반응 사이의 간격을 늘리며 스스로 반응을 컨트롤 할 수 있는 주도적인 사람이 되는 것이 저의 20대의 목표입니다.