이 글에서는..
컴퓨터는 레지스터와 여러 메모리 영역들(코드, 데이터, 힙, 스택 영역)을 이용해 코드를 해석하고 실행한다.
이 글에서는 코드가 해석되는 동안 코드에 필요한 데이터들이 어디에 저장되는지, 함수 호출과 종료 시에 무슨 일이 일어나는지 살펴본다.
메모리 영역
프로세스가 실행되기 위해서는 그 프로세스가 사용할 메모리 공간이 필요하다. 프로세스가 할당받는 메모리 공간은 통상 네 가지로 분류되는데, 각각 code 영역, data 영역, heap 영역, stack 영역이다.
이는 실제 자료구조 heap과 stack과는 아주 직접적인 관련은 없다. (물론 heap 영역이 heap으로, stack 영역이 stack으로 구현될 수 있고, 그것이 일반적이다)
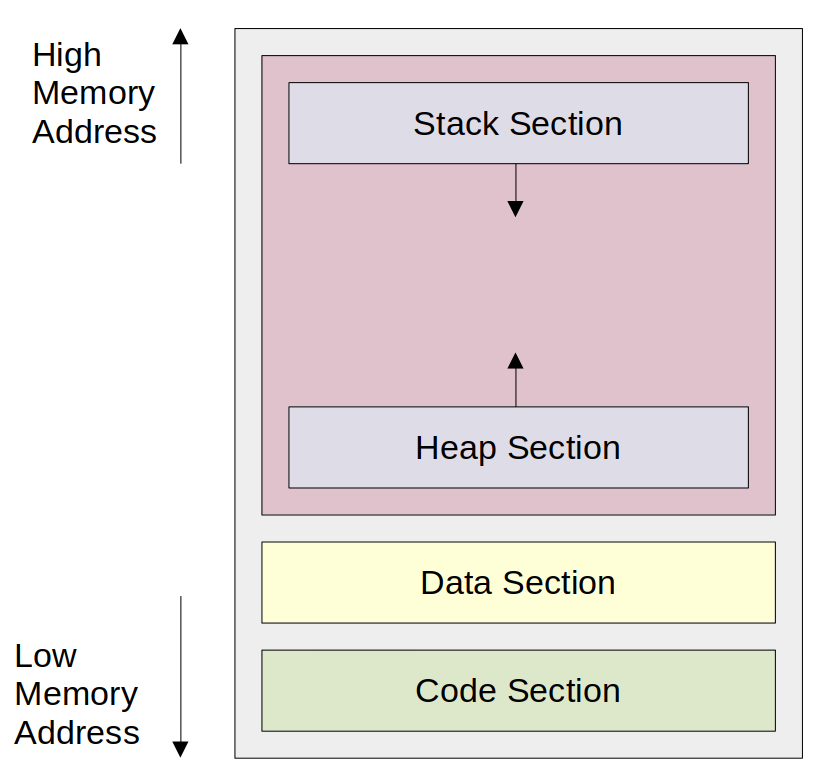
- code 영역(text 영역): 실행 가능한 코드가 위치한다.
- data 영역: 전역 변수들이 위치한다.
- heap 영역: 프로그램이 동작 중 동적으로 할당된 메모리의 영역이다.
- stack 영역: 함수를 동작시킬 때 사용하는 임시 데이터 저장 영역이다. (예: 함수의 인자, return값, 로컬 변수 등)
네 개의 영역 중 code 영역이 가장 낮은 메모리 주소를 가지고, 그 다음으로 데이터 영역, heap 영역, stack 영역 순서대로 높은 메모리 주소를 가진다.
프로그램 실행 이후에는 일정한 크기를 유지하는 code 영역과 data 영역과는 달리, heap 영역과 stack 영역은 프로그램 동작 중에 그 크기가 변화한다.
그리고 특이하게도, 프로그램이 동작하며 heap 영역은 낮은 메모리 주소에서부터 높은 메모리 주소 순서대로 메모리를 사용하는 반면, stack 영역은 높은 메모리 주소로부터 낮은 메모리 주소 순서대로 메모리를 사용한다. 즉, heap 영역과 stack 영역이 마주보고 자라난다는 것이다.
그리고 만약 heap 영역과 stack 영역이 서로 겹치는 일이 발생한다면 메모리가 부족해 에러가 나게 된다.
이렇게 heap이 위쪽으로, stack이 아래쪽으로 자라나게 된 뚜렷한 역사적인 근거는 없지만, 이와 같은 메모리 아키텍처가 만들어지기 시작한 당시 사용 가능한 메모리가 제한되어 있었으므로 stack과 heap 영역을 구분하는 것이 메모리 측면에서 낭비였을 거라는 추측, 또는 그 당시 CPU 동작 방식 때문에 그랬을 것이라는 추측 등이 존재한다.
레지스터
코드를 동작시키기 위해 필요한 주요 레지스터들을 설명한다.
pc
pc는 program counter의 약자로, 지금 어디에 있는 코드를 실행하고 있는지를 저장하는 코드의 주소값이다. (personal computer의 PC와 약자는 같지만, 완전히 다른 말이다)
CPU가 pc에 위치한 코드를 읽어오고, pc의 값을 변화시키는 과정을 반복하며 아래의 코드를 정해준 순서대로 실행하게 된다.
0 int b = 5;
1 int sum(int x, int y) {
2 int result = x + y;
3 return result;
4 }
5 int main() {
6 int a = 3;
7 int c = sum(a, b);
8 }예를 들어 위와 같은 코드가 있다고 해보자. (물론, 이 코드는 어셈블리어로 번역되기 때문에, 아래와 같이 C언어를 대입해 설명하는 것은 정확한 설명이 아니다. 이러한 일이 어셈블리어에서 일어난다고 생각하고 읽어주길 바란다.)
만약 int b = 5; 줄이 코드 영역의 0번 메모리 주소에 저장되어 있다면, 이 프로그램의 실행 순서는 0→5 → 6→ 7→ 1→ 2→ 3→ 7 → 8번 메모리에서 명령어를 차례대로 읽어온 순서일 것이다.
즉 pc는 일반적인 경우에서는 순서대로 다음의 메모리 주소를 가리키고, 함수 호출, 반복문 또는 조건문 사용과 같은 경우에는 그에 맞는 명령어를 실행할 수 있는 자리에 위치하도록 pc 값을 변경해준다고 할 수 있다.
lr
lr은 link register의 약자로, 함수 호출 시 증가된 pc의 값을 저장하는 레지스터이다.
lr을 이용하여 함수 종료 후 lr 값을 참조하여 이전 코드 실행 위치로 돌아갈 수 있다.
sp
sp는 stack pointer의 약어로, 현재 stack이 어디까지 차 있는지를 나타내는 포인터이다.
sp의 값을 늘리고 줄임으로써 stack 영역에 push(데이터 입력) 또는 pop(데이터 버림)을 해줄 수 있다.
fp
fp가 무엇인지 설명하기 이전에 stack frame을 먼저 이해해야 한다.
stack frame이란, 스택 영역에 차례대로 저장되는 함수의 호출 정보를 말한다. stack frame을 활용하여 함수의 호출이 모두 끝난 뒤에, 해당 함수가 호출되기 전 상태로 돌아갈 수 있다.
fp는 frame pointer의 약어로, 현재 stack frame의 위치를 가리키는 포인터이다.
함수의 호출 전 상태로 되돌아가는 자세한 과정은 아래에 추가적으로 설명하도록 하겠다.
위와 같은 값들은 프로그램의 실행에 매우 중요함과 동시에 자주 사용되는 값이기 때문에, 레지스터에 저장되어 프로세스가 실행되도록 한다.
그밖에도 많은 레지스터들이 존재하지만, 우선 아래의 내용을 이해하기 위해서 4개의 레지스터가 핵심적으로 이용되기 때문에 여기까지 설명하겠다.
변수 선언 및 할당
그렇다면, 변수가 선언되고 할당되는 부분을 먼저 살펴보자.
0 int b = 5;
1 int sum(int x, int y) {
2 int result = x + y;
3 return result;
4 }
5 int main() {
6 int a = 3;
7 int c = sum(a, b);
8 }이 부분도 위에서 예시로 들었던 코드를 그대로 예시로 사용한다.
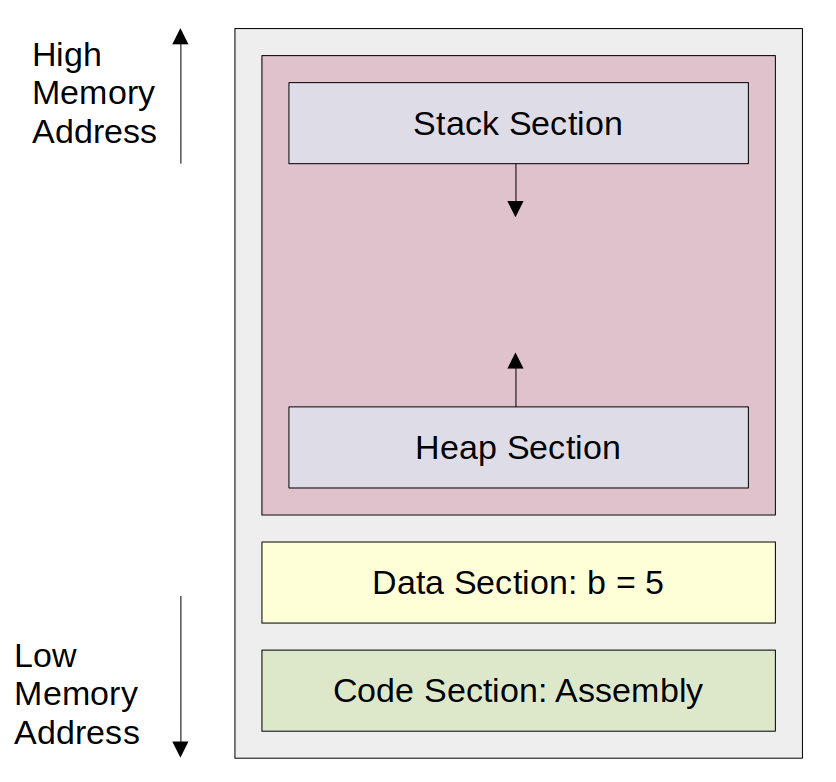
위와 같이 코드 영역과 데이터 영역이 모두 채워진 상태에서, main 함수의 int a=3 부분이 프로세스에게 읽혀져 실행되었다고 해보자.
주의: 그림에서는 이해를 돕기 위해 a와 같은 변수의 이름을 사용했지만, 실제로 변수의 이름과 변수의 타입 등의 정보들은 저장되지 않음에 유의하자.
변수의 이름과 타입은 runtime에는 이용 불가능하다. 컴파일러만이 어디에 어떤 변수가 저장될 것인지를 알 뿐이고, 그 정보를 이용해 적절한 메모리 주소에 접근하고 그 메모리 주소에 해당하는 값을 변화시키는 코드를 만들어내는 것이다.
함수의 이름과 타입 또한 마찬가지인데, main과 sum 함수는 구분되며 main 함수는 5번째 메모리 위치에, sum 함수는 1번째 메모리 위치에 위치한다는 정보를 가지고 컴파일러가 코드를 만들어내는 것이다.
함수의 인자, return값, 로컬 변수 등 함수를 동작시키기 위한 데이터들은 stack 영역에 값이 들어가므로, 메모리 상태는 아래와 같이 변하게 된다.
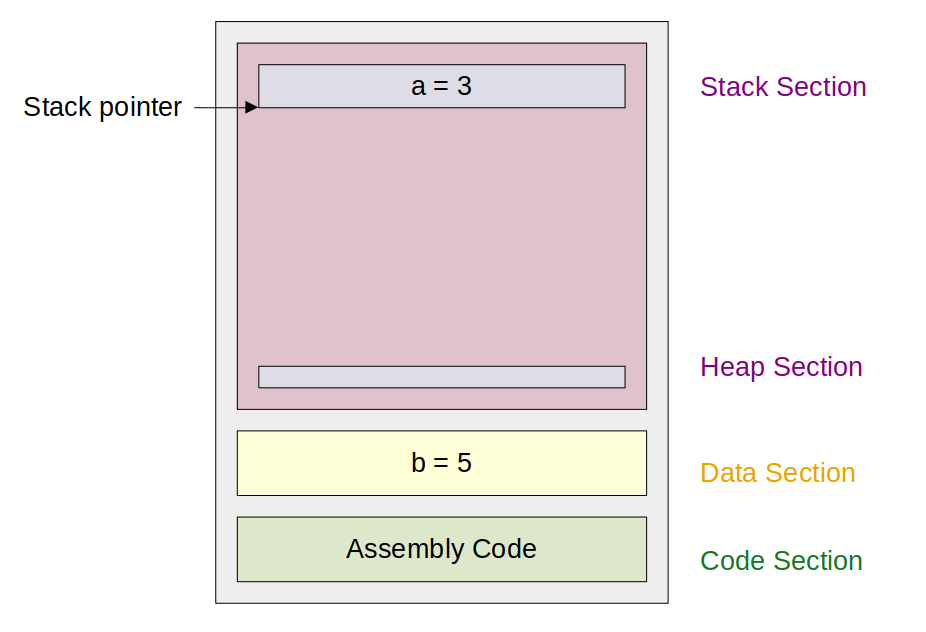
stack 영역에 a=3이 들어가 있고, stack pointer sp가 stack의 맨 끝 지점을 가리키는 모양새이다.
그 다음으로는 함수 sum이 실행되는데, 함수 호출과 종료 처리는 아래에서 따로 설명하겠다.
함수 호출과 종료 처리
함수 호출이란, 그저
- 호출한 함수가 있는 위치로 가서, 그 함수가 끝날 때까지 실행함
- 함수가 끝나면, 함수가 호출되었던 위치로 돌아감
- 이때, 함수를 실행하기 전 상태와 실행하기 후 상태는 같아야 함
이것들을 만족시켜주는 것이다.
여기에서 앞서 살펴보았던 레지스터들인 pc, lr, sp, fp가 활용된다.
함수 호출과 종료 - sp, lr
0 int b = 5;
1 int sum(int x, int y) {
2 int result = x + y;
3 return result;
4 }
5 int main() {
6 int a = 3;
7 int c = sum(a, b);
8 }pc는 현재 실행되고 있는 명령어의 주소값을 가진다.
int a = 3; 코드 이후 sum 함수가 호출되며 pc 값은 코드 라인 1에 해당하는 명령어의 주소값을 가리키게 된다.
함수의 주소값은 컴파일러가 코드를 읽으며 코드 영역에 이미 기록해두었으므로, 코드에 적혀 있는 주소값대로 pc의 값을 바꾼다. (jump)
코드 라인 3에서 sum 함수의 return문을 만나게 되면, main 함수의 이전 상태로 돌아가야 한다. 따라서 pc는 이전에 실행되고 있던 라인인 7번 라인에 해당하는 명령어의 주소값을 가져야 한다.
이때, pc가 이전 값으로 되돌아가기 위해서는 pc 하나만으로는 할 수 없고, 이전 값을 따로 기억해야만 하는데, 그 역할을 하는 것이 lr이다.
위 코드에서는 lr이 코드 라인 7에 해당하는 명령어 주소값을 저장하여, sum 함수의 return 이후에 lr의 값을 pc에 대입하게 된다.
함수 호출과 종료 - sp, fp
sum 함수를 실행하면 함수에 관련된 데이터들을 stack 영역에 push한 후, 그 stack 위에 그 함수에서 사용하는 로컬 변수 등을 저장하게 된다. 즉 2번 라인까지 실행한 결과 메모리의 상태는 다음과 같다.
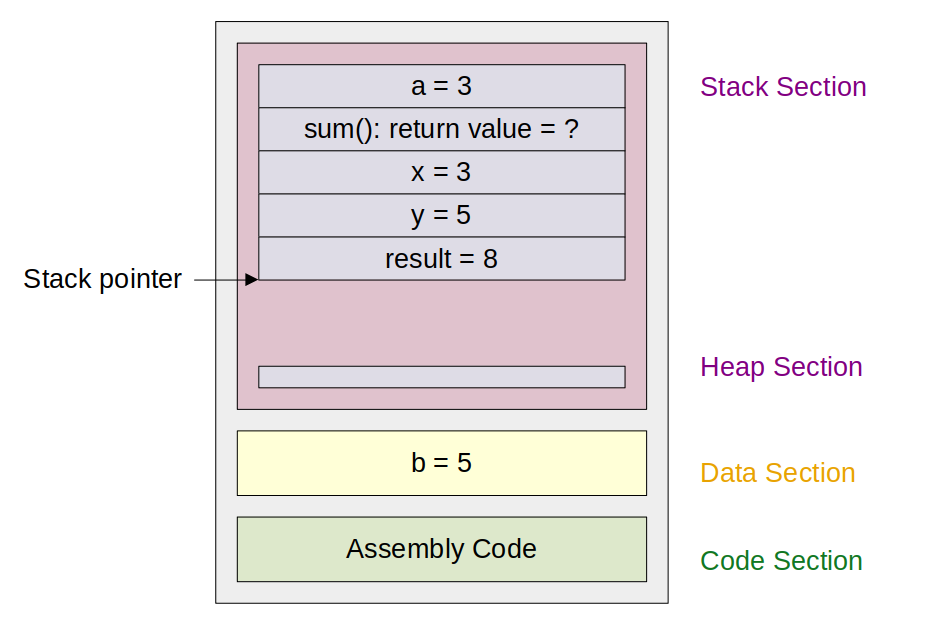
return을 하게 되면 추가되었던 데이터인 sum(): return value = ? 부터 result = 8까지의 값을 제거해, 이전 상태와 같도록 만들어줘야 할 것이다.
그렇다면, 앞서 살펴봤던 pc와 lr의 관계처럼, 이전의 변수 상태가 어땠는지 따로 기록을 해 줘야 할 것이다.
예상했을 테지만 그 역할을 하는 것이 fp이다. fp는 아래와 같이 이전 sp의 값이 무엇이었는지 기억한다.
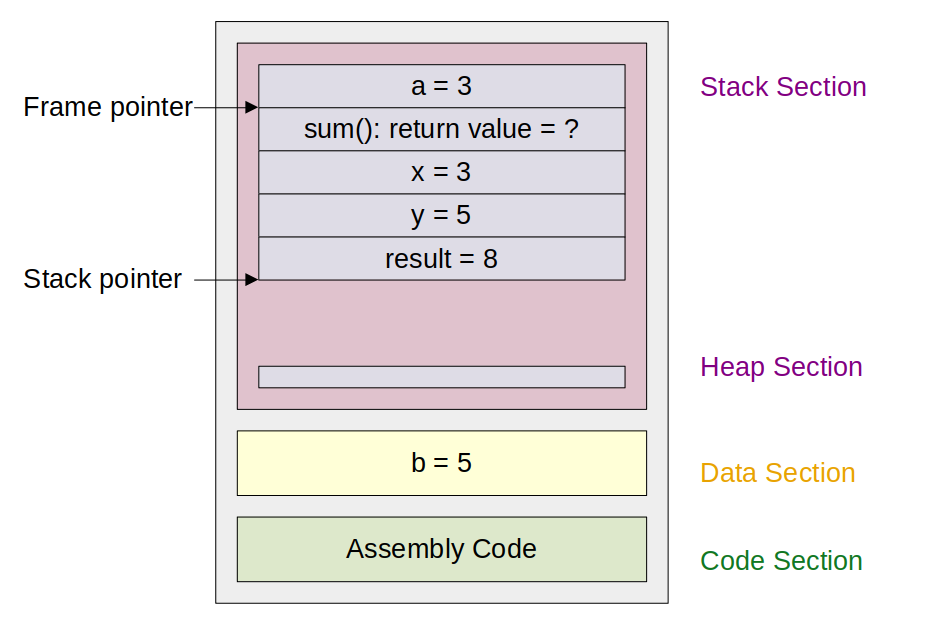
sum 함수가 return을 하게 되면 sp에는 fp의 값이 대입되어, 이전의 상태로 돌아갈 수 있게 된다.
또한, 이로써 main 함수에서는 local variable인 x, y, result에 접근할 수 없게 된다.
호출 스택이 더 깊어지면?
지금까지는 main() → sum()의 호출 스택(call stack, 함수가 실행중인 상태에서 계속 다른 함수를 호출하여 stack과 같이 나타난 것)만을 살펴보았는데, 만약 호출 스택이 더 깊어지면 어떻게 될까?
lr과 fp가 이전의 pc 값과 fp 값을 저장한다고 한들, 깊이 n의 호출 스택이라면 n-1개의 pc 값과 fp 값을 저장해야 하기 때문에 단일 값만으로는 이전 pc와 fp 값을 저장할 수 없을 것이다.
따라서, lr과 fp를 stack의 top을 가리키는 주소값으로 두고 함수가 새로 호출되면 pc와 fp 값을 push, 함수가 return되면 pc와 fp 값을 pop을 하는 방식으로 구현할 수 있을 것이다.
힙 영역
힙 영역에 대해서는 자세히 다루지 않았는데, 힙 영역은 프로세스 실행 중 프로그래머가 직접 동적으로 할당한 데이터가 들어가는 영역이다.
힙 영역의 데이터의 할당과 해제는 C언어의 malloc와 free, 또는 C++언어의 new와 delete 등을 통해 이뤄지게 된다.
앞서 힙 영역도 스택 영역과 같이 그저 ‘자라난다’라는 표현을 쓰기는 했지만, 선입후출(FILO, first in last out)의 정해진 형태로 동작하는 stack 영역과는 달리 heap 영역은 언제 어떤 얼마나 큰 값이 어디에 할당되고, 어디에 있는 어떤 값이 언제 해제될지 전혀 예측할 수 없기 때문에, 추가적인 처리가 필요하다.
힙 영역을 사용하다 보면 필연적으로 메모리를 순차적으로 모두 사용하는 것이 아니라 어딘가는 비어 있고, 어딘가는 차 있는 형태로 (구멍난 형태, hole) 이뤄지게 될 것인데, 이렇게 힙 영역을 방치하다 보면 사용 가능한 메모리의 영역이 줄어들게 될 것이다.
따라서 이러한 문제점을 방지하기 위한 defragmentation 방법을 준비해야 할 것이고, 만일 garbage collector가 메모리를 관리하는 managed 언어일 경우에는 garbage collector를 구현하여, 힙 영역에 메모리 누수(memory leakage)가 발생하지 않도록 해야 할 것이다.
references
Operating System Concepts, Tenth Edition (Abraham Silberschatz, Peter Baer Galvin, Greg Gagne; WILEY)
Memory 구조 (code, data, stack, heap)
Why does the stack grow downward?
Where are the variable/reference names or types stored in memory for stack/heap variables?


잘봤습니다.