
컴파일러
우리가 작성한 코드는 컴파일러에 의해 기계어로 변환된다.
컴파일 도중 Tokenizing, Lexing, Parsing이 일어나게 되는데, 오늘은 그 세 가지 과정이 무엇인지에 대해 알아볼 것이다.
위 세 과정은 코드를 기계가 읽기 편하도록 실제 기계어 번역 전에 알맞게 변환하는 것인데, Tokenizing, Lexing, Parsing 순서대로 일어나게 된다.
Tokenizing
토큰이란, 어떠한 의미를 갖는 문자 그룹을 뜻하며, 일반적으로 단어 혹은 문장부호, 특수기호를 포함한다.
토크나이징이란 본래의 코드를 쪼개어 여러 개의 토큰으로 구분하는 작업으로, 보통 탭, 스페이스, 개행문자 등과 같은 문자들을 기준으로 쪼개게 된다.
예를 들어 다음과 같은 코드가 있다고 하자.
int a;
a = 3;
{ int b = 4; }이 코드를 토크나이저가 토크나이징을 하면 다음과 같이 변하게 된다.
무조건 이렇게 변하는 것은 아니니, 참고 수준으로 보자. 구현에 따라 바뀔 수 있다. Tokenizing, Lexing, Parsing의 이해를 돕고자 예시를 든 것이지, 실제 구현된 프로그래밍 언어의 컴파일 과정은 이와 같지 않을 수 있다.
[int, a, ;, a, =, 3, ;, {, int, b, =, 4, ;, }]이렇게 토크나이징 된 코드는 Lexer에게 넘겨져 렉싱이 일어나게 된다.
Lexing
렉싱이란 토크나이저와 역할이 비슷하다고 할 수도 있으나, 토크나이저가 단순히 토큰들을 구분하기만 했다면 렉서에서는 보통 그 토큰의 의미 혹은 맥락을 함께 고려하게 된다.
위 토큰들을 렉싱 과정을 거치게 하면 다음 예시와 같이 될 것이다.
[
[<declare: int> <variable name: a> <end of statement>],
[<variable name: a> <assignment operator> <int literal 3> <end of statement>],
[<start of scope>],
[<declare: int> <variable name: b> <assignment operator> <int literal: 4> <end of statement>]
[<end of scope>],
]Parsing
파서는 렉서로부터 토큰을 받아, AST(abstract syntax tree)로 변환한다.
AST란, 소스코드로부터 기계어의 용이한 변환을 위해, 컴파일러에서 소스코드를 구조적으로(트리 형태로) 나타낸 것이다.
위 예시를 파싱한 결과 AST를 그려보면 다음과 같다.
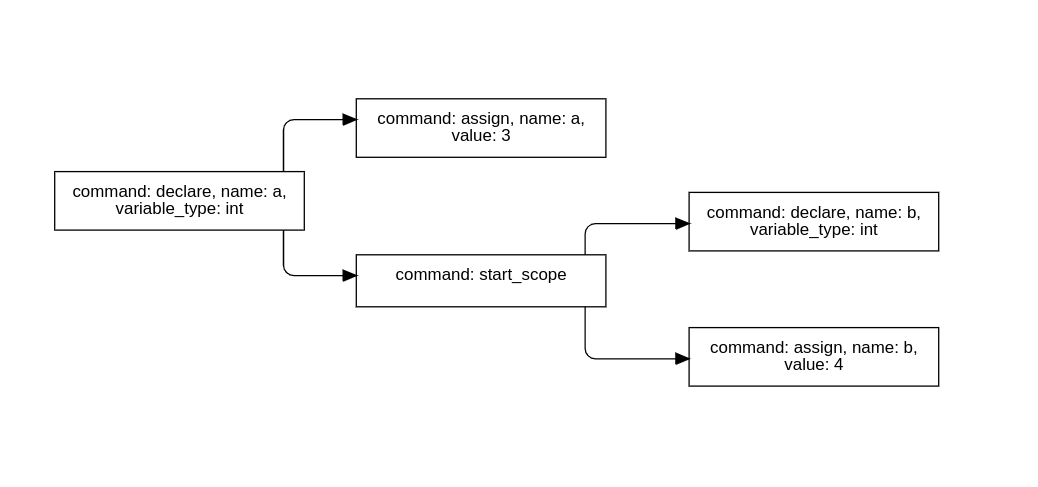
의의
그렇다면 왜 이런 과정을 거쳐 코드를 AST로 만드는 것일까?
- 문법적으로 지켜야 할 규칙들에서 벗어나, 컴퓨터가 이해하는 데에 편리한 구조로 만든다.
- 코드 최적화가 가능해진다. 비효율적인 코드를 식별해 최적화를 할 수 있다.
- 코드를 분석해 잠재적 버그 혹은 보안 문제를 발견할 수 있다.
- 서로 다른 프로그래밍 언어로 변경할 수 있는 매개체가 된다. (e.g. 파이썬→자바스크립트)
import ast
import astor
code = """
x = 1
y = 2
print(x + y)
"""
tree = ast.parse(code)
# Transform the tree to a JavaScript AST
js_tree = astor.to_source(tree, 'js')
# Print the resulting JavaScript code
print(js_tree)var x = 1;
var y = 2;
console.log(x + y);references
[컴파일러] 토크나이저, 렉서, 파서 (Tokenizer, Lexer, Parser)
Understanding Abstract Syntax Trees (AST) in Software Development
