
명령어
- set {key} {value}
- Insert (RDB기준)
- get {key}
- select
- keys *
- 키 값 전체조회(select * ) ※성능에 영향이 크기에 실제로 사용 자제!
- dbsize
- 모든 데이터 개수 조회 count(*)
- flushall
- 모든 데이터 삭제 delete *
String Type
- 가장 기본적인 데이터 타입으로 제일 많이 사용됨
- 바이트 배열을 저장(binary-safe)
- 바이너리로 변환할 수 있는 모든 데이터를 저장 가능(JPG와 같은 파일 등)
- 최대 크기는 512MB
- webBrowser에서 Cash 처리에 많이 사용
String 주요 명령어
SET - 특정 키에 문자열 값을 저장한다. ex) SET say hello GET - 특정 키의 문자열 값을 얻어온다. ex) GET say INCR 특정 키의 값을 Integer로 취급하여 1 증가시킨다. ex) INCR mycount DECR 특정 키의 값을 Integer로 취급하여 1 감소시킨다. ex) DECR mycount MSET 여러 키에 대한 값을 한번에 저장한다. ex) MSET mine milk yours coffee MGET 여러 키에 대한 값을 한번에 얻어온다. ex) MGET mine yours
INCR , DECR은 atomic하기 때문에 중복이나 누락이 발생하지 않는다.
ex) 멀티스레드 환경인 여러 서버에서 하나의 redis 서버에 increase , decrease 연산을 무수히 많이 발생시켜도 누락이 절대 발생하지 않는다.
항상 정확한 결과가 나옴
MSET, MGET의 장점
set이나 get을 작은 사이즈로 여러번 네트워크 호출을 하게 되면 비용이 무수히 많이 든다.
MSET, MGET은 한번에 네트워크 통신을 처리 할 수 있다.MSET mine{key} milk{value} yours{key} coffee{value} MGET mine{key} yours{key}
Lists Type
- Linked-list 형태의 자료구조 (인덱스 접근은 느리지만 데이터 추가/삭제가 빠름)
- Queue와 Stack으로 사용할 수 있음 // Deque 구조
- redis - List의 명령어
LPUSH - 리스트의 왼쪽에 새로운 값을 추가 ex) LPUSH mylist apple RPUSH - 리스트의 오른쪽에 새로운 값을 추가 ex) RPUSH mylist banana LLEN - 리스트에 들어있는 아이템 개수를 반환 ex) LLEN mylist LRANGE - 리스트의 특정 범위를 반환 ex) LRANGE mylist 0 -1 ※0은 시작점 -1은 오른쪽끝점 , -2는 오른쪽에서 두번째값... LPOP - 리스트의 왼쪽에서 값을 삭제하고 반환 ex) LPOP - mylist RPOP - 리스트의 오른쪽에서 값을 삭제하고 반환 ex) RPOP mylist
Sets Type
- 순서가 없는 유니크한 값의 집합
- 검색이 빠름(빠르게 값이 들어있는지 확인)
- 개별 접근을 위한 인덱스가 존재하지 않고, 집합 연산이 가능(교집합,
합집합 등)
※한개의 set 안에 중복된 여러개의 데이터를 넣으면 하나로만 표시됨
ex) 위 그림에서 10을 추가해도 중복으로 추가되지않음
Set의 명령어
ex) SADD myset apple SREM Set에서 데이터를 삭제 ex) SREM myset apple SCARD Set에 저장된 아이템 개수를 반환 ex) SCARD myset SMEMBERS Set에 저장된 아이템들을 반환 ex) SMEMBERS myset SISMEMBER 특정 값이 Set에 포함되어 있는지를 반환 ex) SISMEMBER myset apple
set의 사용예제
배달 어플에서 쿠폰을 뿌리는 이벤트를 진행한다.
각 유저는 쿠폰을 하나씩만 받을 수 있다.
유저가 쿠폰을 받았는지를 엄청 빠르게 확인 할 수 있게 Set에 유저의 id값을 넣어두면 된다.
Hash Type
• 하나의 key 하위에 여러개의 field-value 쌍을 저장
• 여러 필드를 가진 객체를 저장하는 것으로 생각할수 있음
• HINCRBY 명령어를 사용해 카운터로 활용 가능
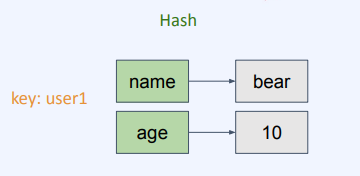
- String Object로도 "set user1_name bear"와 같은 모형으로 만들거나 "set user1 name:bear,age:10"와 같은 json형태로도 만들 수 있다.
- 여러필드를 동시에 접근하기엔 효율적이지만 단일 데이터를 가져올 땐 비효율적...
단일데이터를 많이 가져올 상황과 카운터를 사용할 상황에선 hash를 사용하자!
ex) increase , decrease 사용할때
ex) HSET user1 name bear age 10 HGET - 특정 필드의 값을 반환 ex) HGET user1 name HMGET - 한개 이상의 필드 값을 반환 ex) HMGET user1 name age HINCRBY - 특정 필드의 값을 Integer로 취급하여 지정한 숫자 증가 ex) HINCRBY user1 age 1, HINCRBY user1 age -1 HDEL - 한개 이상의 필드를 삭제 ex) HDEL user1 name age
Sorted Sets Type
- Set과 유사하게 유니크한 값의 집합
- 각 값은 연관된 score를 가지고 정렬되어 있음 //sets와 다른점
- 정렬된 상태이기에 빠르게 최소, 최대값을 구할 수 있음
- 순위 계산, 리더보드 구현 등에 활용
※리더보드 : 게임에서 상위 랭커 같은...

ZADD - 한개 또는 다수의 값을 추가 또는 업데이트 ex) ZADD myrank 10 apple 20 banana ZRANGE - 특정 범위의 값을 반환 (오름차순 정렬) ex) ZRANGE myrank 0 1 ZRANK - 특정 값의 위치(순위)를 반환 (오름차순 정렬) ex) ZRANK myrank apple ZREVRANK - 특정 값의 위치(순위)를 반환 (내림차순 정렬) ex) ZREVRANK myrank apple ZREM - 한개 이상의 값을 삭제 ex) ZREM myrank apple
Bitmap Type
비트 벡터를 사용해 N개의 Set을 공간 효율적으로 저장
• 하나의 비트맵이 가지는 공간은 4,294,967,295(2^32-1)
• 비트 연산 가능

BitMaps 주요 명령어
ex) SETBIT visit 10 1 GETBIT 비트맵의 특정 오프셋의 값을 반환 ex) GETBIT visit 10 BITCOUNT 비트맵에서 set(1) 상태인 비트의 개수를 반환 ex) BITCOUNT visit BITOP 비트맵들간의 비트 연산을 수행하고 결과를 비트맵에 저장 ex) BITOP AND result today yesterday
실행예시
success -> setbit today_visit {userId} 0 success -> setbit today_visit {userId} 1 error -> setbit today_visit {userId} 2
예제
사이트에 방문한 유저 등록!
setbit today_visit kim 1 setbit today_visit lee 1 setbit today_visit park 1
사이트에 방문한 유저의 수 확인!
bitcount today_visit -> return 3※ setbit today_visit kim 1을 한번 더 입력해도 return 3;
실용 예제
어제도 방문하고 오늘도 방문한 유저의 수 구하기
• 어제 방문한 유저 등록
setbit yesterday_visit kim 1 setbit yesterday_visit lee 1
• and 연산
bitop {연산} {연산의 값을 담을 객체} {비교할 객체} {비교할 객체2} ex) bitop and result yesterday_visit today_visit
• 어제도 방문하고 오늘도 방문한 유저의 수
bitcount result -> return 2
HyperLogLog Type
- 유니크한 값의 개수를 효율적으로 얻을 수 있음
- 확률적 자료구조로서오차가 있으며, 매우 큰 데이터를 다룰 때 사용
- 18,446,744,073,709,551,616(2^64)개의 유니크 값을 계산 가능
- 12KB까지 메모리를 사용하며 0.81%의 오차율을 허용
- bitmap은 value에 0 or 1 밖에 넣을 수 없지만 HyperLogLog는 용량이 매우 크기에 text와 같은 데이터도 입력이 가능!
※HyperLogLog는 값을 저장하는 형태가 아님!
PFADD - HyperLogLog에 값들을 추가
ex) PFADD visit Jay Peter JanePFCOUNT - HyperLogLog에 입력된 값들의 cardinality(유일값의 수)를 반환
ex) PFCOUNT visitPFMERGE - 다수의 HyperLogLog를 병합
//중복이 제거되어 유니크한 값을 가져오게됨
ex) PFMERGE result visit1 visit2
예제
오늘과 어제의 방문자 입력
PFADD 2023-01-18 kim lee PFADD 2023-01-17 kim lee park jung
비교 연산
PFMERGE result 2023-01-18 2023-01-17
결과 확인
PFCOUNT result -> return 2
출처 및 링크 : fastcampus
