
ElasticSearch란
검색에 최적화 되어있는 광범위한 개방형 검색 플래폼이며 다양한 프로그래밍 언어와 HTTP의 JSON 인터페이스를 지원해줍니다.
Elasticsearch 용도
ElasticSearch는 검색 엔진이며 로그분석, 이벤트 분석, 성능 분석등 분석 및 인사이트를 제공해줍니다.
Elasticsearch는 트랜잭션 및 JOIN을 지원해주지 않습니다.
Elasticsearch 요청과 응답
모든 동작을 REST API로 제공합니다.
- 입력 : PUT
- 조회 : GET
- 삭제 : DELETE
- 수정 : POST
Elasticsearch 요소
다큐먼트
- RDBMS의 Row와 유사
- 데이터가 저장되는 기본 단위
- JSON 형식의 필드와 값
Document

Document와 RDBMS의 Table의 차이

| ElasicSearch | RDBMS |
|---|---|
| Index | Table |
| Document | Row |
| Field | Column |
| Mapping | Schema |
인덱스
- RDBMS의 Table과 유사
- 다큐먼트를 저장하고 모아둔 논리적 구조, 단위
- 모든 도큐먼트는 인덱스에 포함
- 하나의 인덱스에는 많은 다큐먼트 포함
- 하나의 인덱스에는 동일한 스키마
- 스키마에 따라 인덱스가 달라야 함
인덱스 템플릿
- 새로운 인덱스가 만들어질 때 적용될 설정을 사전에 정의하는 기능
- 인덱스 템플릿은 다양한 설정을 포함할 수 있으며 매핑, 설정, 분석기, 별칭 및 기타 설정을 포함
- 인덱스 템플릿을 사용하면 인덱스를 생성할 때마다 동일한 설정을 해결
- 인덱스 템플릿을 사용하여 모든 인덱스에서 공통적으로 사용할 수 있는 분석기 설정을 정의
- 인덱스 템플릿은 Elasticsearch 클러스터의 모든 노드에 자동으로 배포
- 클러스터 내의 모든 노드에서 일관된 설정이 유지
매핑
- RDBMS의 Schema와 유사
- 매핑의 종류
- 동적 매핑 (다이나믹 매핑)
- ES가 데이터 타입을 보고 자동으로 매핑
- 인덱스 규모가 커지면 성능에 영향을 받는다.
- 직접 매핑 (명시적 매핑)
- 인덱스 매핑을 직접 하는 것
- 인덱스 생성시 매핑 설정
- 매핑 API 이용
- 동적 매핑 (다이나믹 매핑)
엘라스틱서치의 대표 데이터 타입
| 분류 | 데이터 타입 | 설명 |
|---|---|---|
| Boolean | boolean | true / false |
| 이진값 | binary | Base64 string 같이 인코딩된 바이너리 데이터 |
| 실수형 | float, double | |
| 정수형 | integer, short, byte, long | |
| 객체 | object | JSON 객체 |
| IP | ip | IP 주소의 값 |
| 텍스트 | text | 전문 검색용, 텍스트 분석기가 텍스트를 분리 |
| keyword | 분석용으로 사용하지 않는다. 정렬, 집계에 사용 | |
| 날짜 | date | 날짜나 시간 값 |
| 범위 | integer_range, float_range, Long_range, date_range, ip_range | 최소값과 최대값으로 범위를 설정한 데이터 |
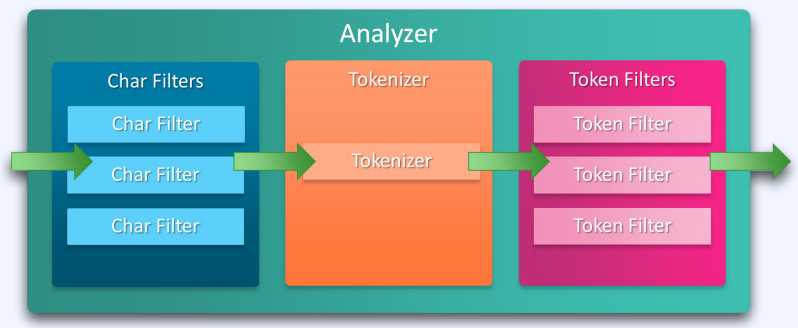
분석기
분석기는 캐릭터 필터, 토크나이너, 토큰 필터로 구성되어있습니다.
분석기는 역인덱싱 기술을 지원합니다.
역인덱싱이란 긴 텍스트를 특정 기준으로 나누어서 인덱싱하는 기술입니다.
| 분석기 구성 요소 | 설명 |
|---|---|
| Char Filter | 입력을 받은 원본 텍스트 문자열을 추가, 변경, 제거 |
| Tokenizer | 문자열을 받아서 분리 기준에 따라 문자열을 토큰 분리 |
| Token Filter | 토큰을 추가하거나 수정 또는 제거 |
분석기 처리 예시
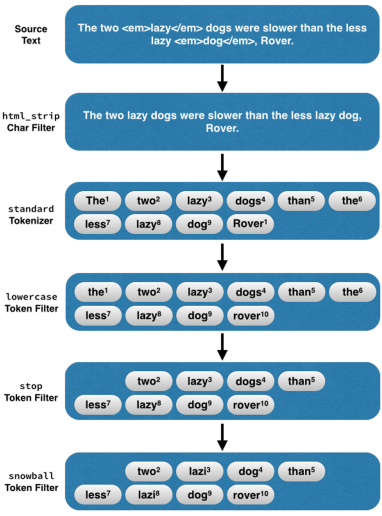
- 문자열 소스 통째로 받습니다.
- HTML Strip Char Filter -> html 블록을 지웁니다.
- standard Tokenizer -> 영문 기준으로 문자열을 분해합니다.
- lowercase Token Filter -> 나눈 문자열을 소문자로 변경합니다.
- stop Token Filter -> 불용어를 제거합니다.
- snowball Token Filter -> 접미사나 접두사를 제거합니다.
이외에도 whitespace Token Filter와 Keyword Token Filter등등 다양한 내장 분석기가 존재합니다.
역인덱스
역인덱스는 단어가 포함된 문서의 목록입니다.
특정 단어가 포함된 문서를 빠르게 찾을 수 있습니다.
예시
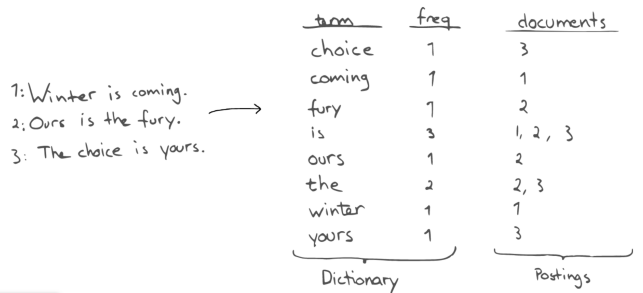
Elasticsearch 검색
서비스가 커지고 트래픽이 늘어나면 관계형 데이터베이스로는 한계가 있습니다.
Elasticsearch를 이용하면 텍스트 매칭, 텍스트 변형 검색, 랭킹 시스템, 유사어나 동의어 처리에 최적화 되어있습니다.
쿼리 사용 방법
쿼리 스트링
rest-api에서 제공해주는 쿼리 스트링 방법입니다.
간단한 쿼리에는 효율적이지만 쿼리가 길어지면 가독성이 안좋고 복잡해집니다.
쿼리 DSL
쿼리 DSL은 Json 기반으로 쿼리를 작성하는 방법입니다.
복잡한 쿼리를 처리하기 좋은 방법입니다.
쿼리 종류
리프 쿼리
리프 쿼리는 특정 필드를 대상으로 쿼리하는 방법입니다.
리프 쿼리의 종류
- 매치 쿼리
- 용어 쿼리
- 범위 쿼리
리프 쿼리의 방식
- 전문 쿼리 (full text query)
- 텍스트 타입의 필드를 대상으로 전체 검색을 하는 방식
- 매치 쿼리, 매치 프레이즈 쿼리, 멀티 매치 쿼리
- 용어 수준 쿼리 (term level query)
- 단어, 키워드, 숫자, 범위 형태의 필드를 대상으로 검색을 하는 방식
- 정확히 단어와 순서가 일치 해야 쿼리가 됩니다.
- 용어 쿼리, 여러 용어 쿼리
- 단어, 키워드, 숫자, 범위 형태의 필드를 대상으로 검색을 하는 방식
복합 쿼리
리프 쿼리를 조합해서 쿼리하는 방식입니다.
- 논리 쿼리
Elasticsearch 집계
메트릭 집계
특정한 필드를 기준으로 수치 계산이나 통계값을 구하는 기능입니다.
RDBMS에 집계함수와 같은 기능이며 avg, min, max, sum, percentiles, stats 등등
버킷 집계
특정 기준에 따라 문서를 묶어주는 기능입니다.
RDBMS에 Group by, having과 같은 기능이며 histogram, range, date_range, terms, filters 등등
Node
Elasticsearch 클라우드를 구성하는 하나의 인스턴스입니다.
노드는 최소한의 단위이며 여러기능을 하는 노드가 존재합니다.
각 노드들의 기능을 한 노드에게 몰아줄 수 있지만 성능 및 확장성, 복잡성을 생각하여 분리를 하는것을 권장합니다.
- 마스터 노드 : 클러스터의 모든 정보를 관리 담당
- 데이터 노드 : 데이터의 CRUD, 검색, 집계 담당
- 투표 전용 노드 : 마스터 노드 선정에 투표 참여 담당
- 인제스트 노드 : 문서의 가공과 처리 담당
- 머신러닝 노드 : 머신러닝 기능을 담당
- 코디네이터 노드 : REST API 요청의 처리 담당
백업
백업은 기본적으로 자주하는 것이 중요합니다.
Elasticsearch의 백업은 증분 백업이라 자주 백업이 가능합니다.
스냅샷
- 모든 데이터 저장 또는 특정 인덱스의 데이터만 저장
- 이후에는 증분만 저장
스냅샷 복원
- 찍어둔 스냅샷을 이용해서 데이터 복원
출처 : FastCampus
