
Exercise 00: BraiiiiiiinnnzzzZ
1. Subject
먼저 private 속성의 string형 name과 void announce(void); 을 멤버함수로 가지는 Zombie 클래스 를 만들어라.
그리고 아래 두 함수를 만들어라
Zombie* newZombie(std::string name);이 함수는 좀비를 만들고, 이름을 붙이고, 리턴하여 니가 함수스코프밖에서도 사용할 수 있을 것이다.
void randomChump(std::string name);이 함수는 좀비를 생성하고, 이름 붙이고, 좀비가 스스로 말하게 할 것이다.
2. Point
핵심 개념
- 동적할당과 정적할당
- 프로그램 사용과 메모리
1) c++에서의 동적할당
c언어에서는 malloc과 free함수를 이용해서 동적할당을하고 해제했지만 c++에서는 new와 delete라는 함수를 사용한다.
- new
new type형태로 쓰고, 해당 타입 사이즈 만큼의 메모리를 동적할당해 객체를 만든 다음 할당된 메모리의 주소가 포함된 포인터를 반환한다. 이 포인터를 역참조해서 메모리에 접근할 수 있다.
int *ptr = new int;
*ptr = 7
//new 사용 예시- delete
동적할당된 객체의 할당을 해제한다.
delete 변수명형태로 사용한다.
delete ptr;
//delete 사용 예시2) 프로그램 실행 시 메모리의 사용
이번 과제를 풀려면 프로그램이 실행될 때 메모리의 어떤 영역을 사용하는지 알아야한다. 여기까지 온 사람이라면 이미 알고있겠지만 한번 더 간단하게 짚고 넘어가자.
메모리는 아래 그림 처럼 코드-데이터-힙-스택 영역으로 나뉘어져있다.
#include <stdlib.h>
int *malloc_int(int value)
{
int *result;
result = (int *)malloc(sizeof(int));
*result = value;
return (result);
}
int get_sum(int a, int b)
{
int _sum = a + b;
return (_sum);
}
int main()
{
int sum;
int *malloced_int;
sum = get_sum(1, 2);
malloced_int = malloc_int(3);
free(malloced_int);
}위 코드를 프로그램에 올린다고 생각해보면서 과정을 생각해보자.
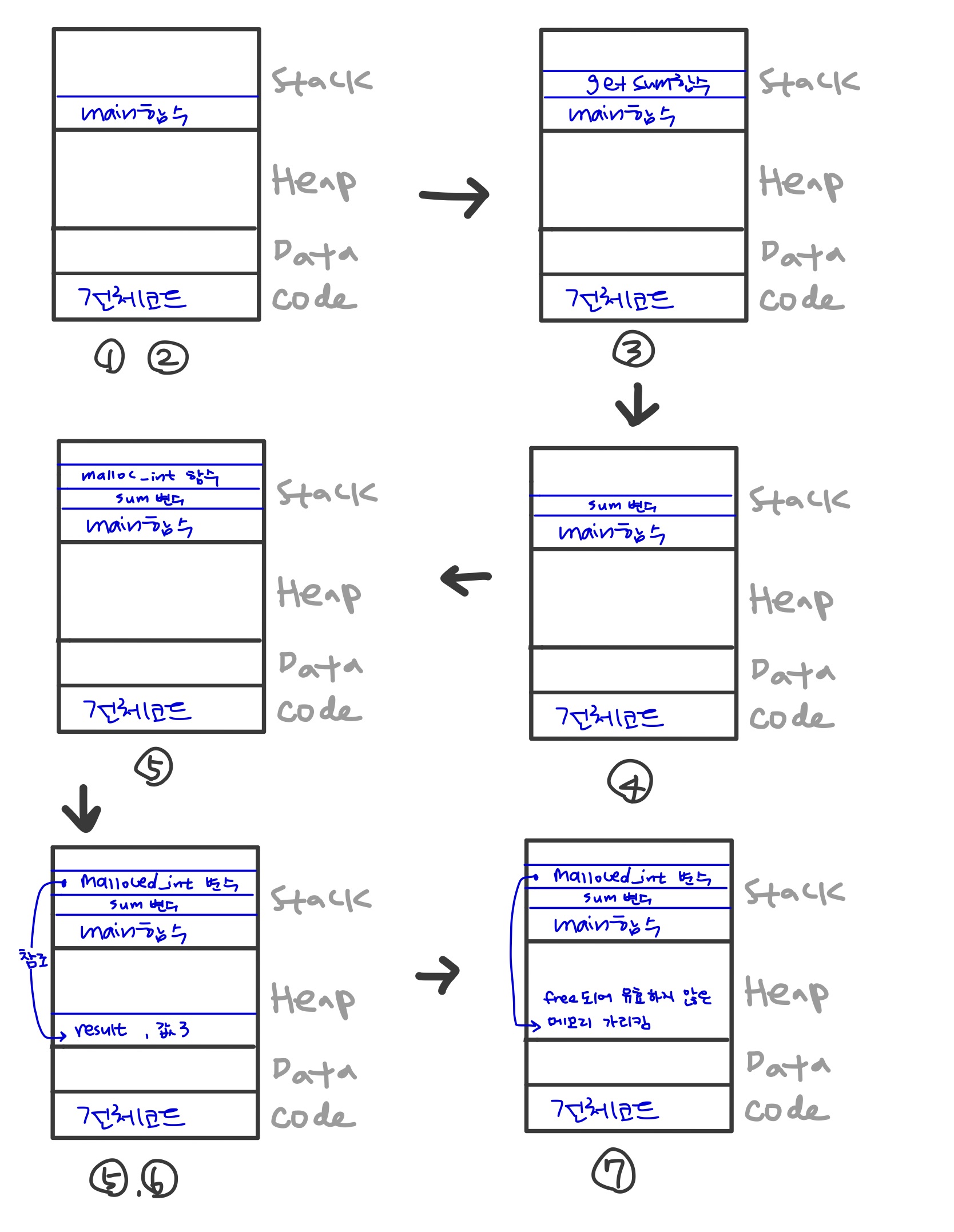
- 프로그램이 실행되면 프로그램의 코드가 코드 영역에 저장된다. cpu는 코드영영에 저장된 명령어를 하나씩 가져가서 처리한다.
- 일단 함수들은 실행될 때 메모리에 올라갈 것이니 가장 먼저 실행되는 main함수가 stack메모리에 할당된다.
- get_sum함수가 실행되면서 stack메모리에 할당된다.
- get_sum함수의 반환값을 main함수의 sum변수에 저장하면서 stack영역에 sum변수가 할당된다.
- malloc_int함수가 실행되면서 stack메모리에 할당된다.
- result변수가 동적할당되면서 heap영역에 할당되고, malloc_int함수가 result변수를 리턴하면서 stack영역에서 해제된다. result변수의 값을 참조하는 malloced_int변수는 stack영역에 할당된다.
- result변수가 해제되면서 malloced_int변수는 유효하지 않은 메모리를 가리키게 된다.
- main함수가 끝나면서 stack메모리에서 해제된다.
3) 동적할당과 정적할당
이번 과제에서 가장 큰 포인트는 동적할당과 정적할당의 메모리상의 차이를 이해하는 것이다. 메모리 관점에서의 동적할당과 정적할당의 가장 큰 차이는 동적할당은 지정한 사이즈만큼 heap영역에 메모리를 할당해주고 프로그램이 끝나기 전에 꼭 해제를 해주어야한다. 정적할당은 컴파일시 stack영역에 메모리를 할당해주고 사용하고 나면 자동으로 해제된다.
나는 newZombie에서는 zombie를 생성할 때 동적할당을 했고, randomChump에서는 정적할당을 선택했다. 왜 이렇게 나누었는지 먼저 코드를 보면서 설명하도록 하겠다.
먼저 newZombie의 코드를 살펴보자
class Zombie{
private:
std::string name;
public:
Zombie(std::string name);
~Zombie();
void announce(void);
};
Zombie* newZombie(std::string name)
{
Zombie *zombie;
zombie = new Zombie(name);
return (zombie);
}
int main()
{
std::string name;
std::cout << "enter the zombie name" << std::endl;
std::getline(std::cin >> std::ws, name);
Zombie *zombie = newZombie(name);
delete zombie;
}newZombie함수의 리턴값은 Zombie 클래스 객체의 포인터값이다. 만약 newZombie함수의 zombie를 동적할당하지 않는다면 stack영역에 할당된 zombie의 포인터값을 리턴하는 순간 stack영역에서 해제될 것이고, main함수의 zombie변수는 알 수 없는 메모리를 참조하게 되기 때문에 오류가 난다.
randomChump함수는 매개변수로 넘겨준 zombie의 이름을 받고 객체를 생성한뒤 객체안의 announce함수를 실행하는 함수이다.
반환값이 없기 때문에 동적할당과 해제를 해줄 필요가 없다고 판단하여 정적할당으로 변수를 생성하였다.
class Zombie{
private:
std::string name;
public:
Zombie(std::string name);
~Zombie();
void announce(void);
};
void randomChump(std::string name)
{
Zombie zombie(name);
zombie.announce();
}
int main()
{
std::string name;
std::cout << "enter the zombie name" << std::endl;
std::getline(std::cin >> std::ws, name);
randomChump(name);
delete zombie;
}당연히 randomChump함수도 아래코드처럼 동적으로 생성할 수는 있다.
void randomChump(std::string name)
{
Zombie *zombie = new Zombie(name);
zombie.announce();
delete zombie;
}Exercise 01: Moar brainz!
1. Subject
한 번에 N개의 좀비를 할당하는 Zombie* zombieHorde(int N, std::string name); 함수를 만들어라.
2. Point
핵심 개념
- 배열의 동적할당과 초기화
1) 배열의 동적할당 방법
이번 과제는 클래스 객체의 배열을 생성하고 초기화하는 방법에 대해 알아보는 것이다. 객체의 배열은 new class이름[요소의 수] 의 형식으로 동적할당하면 된다.
하지만 배열의 각 요소에 동적할당하면서 초기화를 하는 new의 특성을 이용하는 방법은 찾지 못해 반복문을 이용해 값을 넣어주었다.
Zombie* zombieHorde(int N, std::string name)
{
Zombie* zombie;
zombie = new Zombie[N];
for(int i = 0; i < N; i++)
{
zombie[i].setName(name);
}
return (zombie);
}할당을 해제할 때는 delete 변수이름[] 형태로 쓰면 된다.
delete[] zombies;3. Test Code
00에서 사용한 cin을 이용해 직접 입력받아서 생성하는 방식으로 테스트코드를 작성해보았다.
int main()
{
Zombie *zombies;
std::string name;
int n;
std::cout << "Enter the name of zombie" << std::endl;
std::getline(std::cin >> std::ws, name);
while (1)
{
std::cout << "How many " << name << "s do you want?" << std::endl;
std::cin >> n;
if (std::cin.eof() || std::cin.fail())
{
whenEof();
std::cin.ignore(255, '\n');
std::cout << "Wrong input!" << std::endl;
}
else
break ;
}
zombies = zombieHorde(n, name);
for(int i = 1; i <= n; i++)
{
zombies[i - 1].announceInOrder(i);
}
delete[] zombies;
}
//사용자 입력에 의한 테스트int main()
{
Zombie *zombies;
zombies = zombieHorde(0, "First");
zombies = zombieHorde(1, "Second");
for(int i = 1; i <= 1; i++)
{
zombies[i - 1].announceInOrder(i);
}
delete[] zombies;
zombies = zombieHorde(10, "Third");
for(int i = 1; i <= 10; i++)
{
zombies[i - 1].announceInOrder(i);
}
delete[] zombies;
zombies = zombieHorde(1000, "Fourth");
for(int i = 1; i <= 1000; i++)
{
zombies[i - 1].announceInOrder(i);
}
delete[] zombies;
}
//정적테스트코드Exercise 02: HI THIS IS BRAIN
1. Subject
포인터와 레퍼런스 변수를 각각 만들고 이 둘을 비교해라
2. Point
핵심 개념
- 참조자(reference)
1) 참조자(reference)
참조자를 다뤄보는 문제이다. 참조자란 c++에서 처음 도입된 개념이다.
(1) 참조자란?
어떤 변수의 별명과 같은 개념으로 해당 변수를 직접 가리키는 역할을 한다.
(2) 참조자의 사용
int a = 3;
int &another_a = a;
std::cout << a << std::endl; //3이 출력됨
std::cout << another_a = std::endl; //3이 출력됨
a = 10;
std::cout << a << std::endl; //10이 출력됨
std::cout << another_a = std::endl; //10이 출력됨
참조자는 주소연산자(&)을 변수앞에 붙임으로써 선언할 수 있으며 원본 값이 변하면 참조자의 값도 바뀐다.
(3) 참조자의 특징
- 정의 시 어떤 변수를 참조하는지 명시해야한다.
- 참조대상을 변경할 수 없다.
- 참조자의 참조자를 만들 수 없다.
- 리터럴은 참조할 수 없다. 하지만 상수참조자는 리터럴을 참조할 수 있다.
- NULL도 참조할 수 없다.
2) 포인터와 참조자의 차이
포인터와 비슷한 개념이라고 생각할 수 있으나 포인터는 메모리의 주소값을 저장하는 변수이고, 할당된 하나의 공간에 다른 이름을 붙인 것을 참조자라고 한다.
❓포인터가 있는데 참조자를 사용하는 이유는 무엇일까?
참조자는 원본에 접근은 가능하지만 포인터와 다르게 가리키는 대상, 원본, 주소는 변경하지 못하게 막았기 때문에 안전한 포인터라고 생각할 수 있다.
또 참조자를 사용하면 코드가 간결해진다.
#include <iostream>
int main()
{
std::string brain = "HI THIS IS BRAIN";
std::string* pBrain = &brain;
std::string& rBrain = brain;
std::cout << "brain's address : "<< &brain << std::endl;
std::cout << "pBrain's address : "<< &pBrain << std::endl;
std::cout << "rBrain's address : "<< &rBrain << std::endl;
std::cout << "Brain's value : "<< brain << std::endl;
std::cout << "rBrain's value : "<< pBrain << std::endl;
std::cout << "rBrain's value : "<< rBrain << std::endl;
}위 코드로 참조자와 포인터를 썼을때를 비교할 수 있다.
참조자를 사용하면 주소연산자(&)와 참조연산자(*)를 사용할 필요가 없어 코드가 간결해보인다.
3. Opinion
1) 참조자, 참조변수, 레퍼런스에 대한 용어 정리
공부를 하면서 참조자, 참조변수, 레퍼런스가 똑같은 것을 가리키는지에 대한 의문이 들었다. 세 가지 용어는 대부분 혼용해서 사용되고 있고 명확한 정의가 없는 것 같아 나만의 정의를 내려보았다. 먼저 참조자와 레퍼런스는 한국어와 영어 버전의 이름이라고 생각한다. 그렇다면 참조자와 참조변수 사이에는 어떤 차이가 있을까?
먼저 변수와 참조자에 대한 정의를 살펴보자. 컴퓨터 과학에서 변수란 할당된 메모리 공간에 붙여진 이름을 의미하고, 참조자는 어떤 변수의 별명을 가진 것이라고 정의된다.
즉 참조자는 개념을 가리키는 단어이며, 참조변수는 참조자의 역할을 하는 변수라고 볼 수 있다.
int a = 3;
int &another_a = a;위 코드로 예를 들면 위 코드는 참조자를 만드는 코드이고, another_a는 참조변수라고 할 수 있다.
Exercise 03: Unnecssary violence
1. Subject
Weapon클래스와 이 클래스를 가지고 있는 HumanA, HumanB 클래스를 만들어라. HumanA는 Weapon을 생성자로 갖지만 HumanB는 Weapon을 가질수도 가지지 않을 수도 있다.
2. Point
핵심 개념
- 참조자 멤버 변수와 포인터 멤버 변수
- 초기화리스트
1) 초기화리스트
초기화리스트란 생성자 호출과 동시에 멤버 변수들을 초기화해주는 것이다. 아래 형태로 사용하면 된다.
(생성자 이름) : var1(arg1), var2(arg2) {}- 생성자 사용 예시
class Marine {
int hp;
int coord_x, coord_y;
int damage;
bool is_dead;
public:
Marine();
Marine(int x, int y);
};
Marine::Marine() : hp(50), coord_x(0), coord_y(0), damage(5), is_dead(false) {}
Marine::Marine(int x, int y) : coord_x(x), coord_y(y), hp(50), damage(5), is_dead(false) {}❓왜 초기화리스트를 사용하는 걸까?
초기화리스트를 사용하지 않는다면 생성을 먼저하고 그 다음 대입을 수행하게 되기 때문에 동작을 한 번 더 하게된다. 반면에 초기화리스트를 사용하면 생성과 동시에 멤버 변수들을 초기화해주어 좀 더 효율적이다.
그리고 클래스 내부에 레퍼런스 변수나 상수를 넣고 싶다면 무조건 초기화 리스트를 사용해서 초기화 시켜주어야한다.
이번 과제에서는 HumanA클래스의 멤버 Weapon클래스는 레퍼런스로, HumanB클래스의 멤버 Weapon클래스는 처음에 NULL값을 갖도록 설정해야해서 포인터로 선언했다. 이런 경우 HumanA클래스는 꼭 초기화리스트로 초기화해주어야한다.
Exercise 04: Sed is for losers
1. Subject
매개변수로 filename, s1, s2가 들어오면 filename file안의 s1단어를 모두 s2로 변경하는 프로그램을 만들어라. 즉 sed 명령어와 같은 동작을 하는 프로그램을 만들어라.
2. Point
핵심 개념
- file을 다루는 클래스
1) file을 다루는 클래스
cpp00에서 입출력스트림에 대해 다뤄보았다.
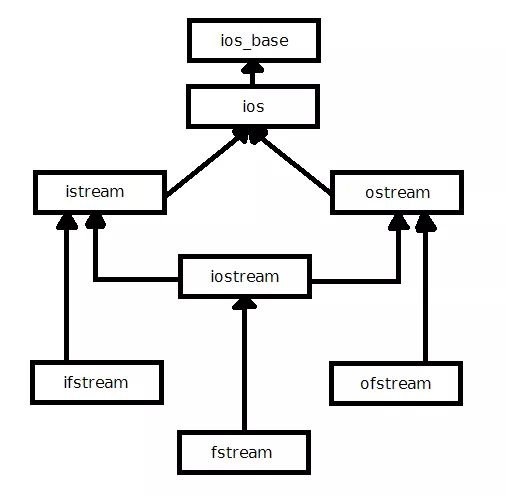
c++입출력 라이브러리 클래스의 구성 <출처: https://modoocode.com/213>
파일 입출력 라이브러리 클래스로는 istream을 상속받은 ifstream(읽기), ostream을 상속받은 ofstream(쓰기), 이 둘을 합친 fstream(읽기/쓰기)가 있다.
객체를 통해 프로그램과 파일을 연결하여 파일을 읽고, 파일에 쓰도록 해주는 클래스이다. 이번 과제는 이 클래스를 이용해 filestream을 다뤄보는 문제이다.
사용할 때는 <fstream>헤더를 추가하고 각각의 객체를 만들어서 사용하면 된다.
#include <fstream>
int main()
{
ifstream inputFile;
inputFile.open("test.txt");
inputFile.close("test.txt");
}
//ifstream 사용 예시 코드3. Solution
1) Pseudo code
class Sed
{
private:
std::string inputFile이름
std::string 이전글자
std::string 새글자
std::string tempFile이름
std::ifstream input파일에_대한_ifstream클래스
std::oftsream 출력할_파일_이름
Sed생성자(char *파일이름, char *이전글자, char *새글자)
public:
bool fileProcess() : input파일을 open하고 성공하면 temp파일도 open하는 함수
bool rewriteProcess() : input파일을 한 줄씩 받고 이전 글자가 있으면 새글자로 바꿔 쓴 후 tempfile에 옮겨넣는다.
}
Sed::Sed(char *파일이름, char *이전글자, char *새글자)
{
private 멤버변수 파일이름, 이전글자, 새글자를 초기화한다
}
bool Sed::fileProcess()
{
inputFile이름의 파일을 open한다. 실패시 경고메세지와 false반환
inputFile이름뒤에 _temp를 붙인 temp파일이름을 생성한다.
생성한 tempFile이름을 가진 file을 오픈한다. 실패시 경고메세지와 false반환
true 반환
}
bool Sed::rewriteFile()
{
while (getLine함수로 inputFile을 한 줄씩 받는다)
{
받은 줄에 이전글자가있는지 확인하고 있으면 새글자로 고쳐서 없으면 그대로 tempFile에 쓴다. 마지막에 개행도 같이 쓴다.
}
inputFile을 삭제한다. 실패시 경고메세지와 false를 반환한다.
tempFile이름을 inputFile이름으로 바꾼다. 실패시 경고메세지와 false를 반환한다.
}
bool Sed::closeFile()
{
tempFile을 close한다.
}
int main()
{
if (인자갯수 != 4)
{
경고문 출력후 종료
}
Sed sed(파일이름, 바꿔야하는 이전글자(old), 바뀔 새글자(new)) : Sed클래스의 객체 생성
if (sed.fileProcess() == false)
return (1);
if (sed.rewriteProcess() == false)
return (1);
if (sed.closeFile() == false)
return (1);
}
2) 문자열을 찾는 함수
- std::find
size_type find(const basic_string& str, size_type pos = 0) const;
문자열을 찾는 함수로 pos는 검색할 위치이며, 초기값은 0이다.
문자열을 찾았다면 해당 문자열의 시작 위치를 리턴하고 그렇지 않은 경우 npos를 리턴한다.
파일로부터 읽은 한 줄에 찾는 문자가 있는지 확인하는 rewrite함수이다.
void Sed::rewrite()
{
size_t position;
position = readLine.find(oldWord);
while (position != std::string::npos)
{
readLine = readLine.substr(0, position) + newWord + readLine.substr(position + oldWord.length());
position = readLine.find(oldWord);
}
}한 줄을 읽으면서 찾는 문자가 나오면 substr을 이용해 대체 문자로 변경하고 처음부터 다시 읽었다. 찾는 문자가 없을 때를 반복문의 종료조건으로 두었다.
3) 파일에 입력하는 방법
파일에 쓰기 위해 사용해야하는 입출력클래스는 ofstream이다. 이 ofstream의 객체를 만들어서 파일에 입력하면 된다.
int main()
{
std::ofstream tempFile;
if (!tempFile.open("tempFilename"))
{
std::cout << "file open error" << std::endl;
return (1)
}
tempFile << readLine << std::endl;
}텍스트파일 입출력은 <<, >> 연산자를 이용할 수 있다.
4) 파일 삭제, 이름 변경 하는 방법
- std::remove
int remove( const char* fname );
fname이름을 가진 파일을 삭제한다.
bool Sed::removeInputFile()
{
if (std::remove(inputFileName.c_str()) != 0)
{
std::cerr << "Error: remove input file" << std::endl;
return (false);
}
return (true);
}
//remove example- std::rename
int rename( const char* old_filename, const char* new_filename );
bool Sed::renameTempFile()
{
if (std::rename(tempFileName.c_str(), inputFileName.c_str()) != 0)
{
std::cerr << "Error: rename temp file" << std::endl;
return (false);
}
return (true);
}
//rename exampleold_filename을 new_filename으로 변환한다.
Exercise 05: Harl 2.0
1. Subject
컴플레인 단계에 맞는 메세지를 출력하는 프로그램을 만들어라. 단 if- else쌍을 쓰지 않고! 하지만 함수포인터는 꼭 사용해야한다!
2. Point
핵심 개념
- 함수포인터
2) 함수포인터
1) 함수 포인터란?
이번 과제에서는 함수 포인터를 꼭 사용하라는 조건이 있다. 함수도 주소를 가지고 있는데 이 함수의 주소를 포인터 변수에 저장해서 사용하는 것을 함수포인터라고 한다.
함수 포인터의 선언은 리턴타입 (*변수이름)(함수의 매개변수타입, 함수의 매개변수타입)형식으로 쓴다.
int (*f)(int, int)
//함수 포인터 예시f 라는 포인터 안에 함수의 주소를 저장해서 사용할 수 있다.
2) 함수포인터의 매개변수로의 사용
함수포인터도 다른 변수와 동일하게 매개변수로 사용가능한다.
아래는 예시 코드이다.
#include <iostream>
using namespace std;
int (*f)(int, int)
int add(int a, int b)
{
return (a + b);
}
void print_odd(int a, int b, int (*f)(int, int)) //매개변수로 함수 add를 받음
{
int ret = f(a, b);
if (ret % 2 == 1)
cout << ret << endl;
else
cout << "홀수가 아니에요!" << endl;
}
int main(void)
{
Test test; // 클래스 Test를 인스턴스화 시켜 객체로 만듭니다.
int (Test::*f)(int, int) = &Test::add;
//함수포인터 f는 Test의 멤버함수를 사용하겠다고 Test::를 통해 명시해줍니다.
//그리고 함수의 주소 또한 Test의 멤버함수라고 명시해 주고 다른 함수 포인터와 달리
//항상 명시적으로 &연산자를 통해 함수의 주소를 가져와야 합니다.
cout << (test.*f)(1, 2) << endl;
//함수포인터의 사용 또한 해당 클래스의 객체를 통해서 사용해야 합니다.
//만약 class의 멤버함수 내에서 함수포인터를 사용한다면 this를 통해서 접근할 수 있습니다.
//접근은 멤버 포인터 연산자인 .* 또는 ->*연산자로 접근해야 합니다.
}3) class 멤버함수의 함수포인터 사용
class의 멤버함수도 함수포인터로 사용이 가능하다.
하지만 class내부의 멤버함수는 객체를 통해서만 출력이 가능하고, 함수포인터의 선언 또한 해당 클래스의 범위 내에 있는 함수포인터라고 명시해줘야 사용이 가능하다.
#include <iostream>
using namespace std;
class Test
{
public:
int add(int a, int b) //클래스 Test안에 멤버함수 add가 있습니다.
{
return (a + b);
}
};
int main(void)
{
Test test; // 클래스 Test를 인스턴스화 시켜 객체로 만듭니다.
int (Test::*f)(int, int) = &Test::add;
//함수포인터 f는 Test의 멤버함수를 사용하겠다고 Test::를 통해 명시해줍니다.
//그리고 함수의 주소 또한 Test의 멤버함수라고 명시해 주고 다른 함수 포인터와 달리
//항상 명시적으로 &연산자를 통해 함수의 주소를 가져와야 합니다.
cout << (test.*f)(1, 2) << endl;
//함수포인터의 사용 또한 해당 클래스의 객체를 통해서 사용해야 합니다.
//만약 class의 멤버함수 내에서 함수포인터를 사용한다면 this를 통해서 접근할 수 있습니다.
//접근은 멤버 포인터 연산자인 .* 또는 ->*연산자로 접근해야 합니다.
}3. Solution
1) Pseudo code
class Harl
{
private:
void debug(void) : debug메세지를 출력하는 함수
void info(void) : info메세지를 출력하는 함수
void warning(void) : warning메세지를 출력하는 함수
void error(void) : error메세지를 출력하는 함수
void complain(std::string level) : 레벨에 맞는 함수를 불러와 실행하는 함수
}
void Harl::complain(std::string level)
{
void (Harl::*executeComplain[4])() = {&Harl::debug, &Harl::info, &Harl::warning, &Harl::error}
: Harl 클래스의 함수를 사용하는 함수포인터의 배열 선언
std::string complainTypeArr[4] = {"debug", "info", "warning", "error"};
: 디버그레벨을 판단할 문자열의 배열 선언
int complainType : 어떤 컴플레인 타입인지 판단 후 저장한 변수
while (complainType < 4)
{
if (level == complainTypeArr[complainType])
break ;
complainType++;
}
:if-else문을 최소화하여 어떤 컴플레인 타입인지 판단하는 부분
switch문에서는 case에 문자를 넣을 수 없어 이렇게 구현하였다.
swtich(complainType)
{
case 0:
(this->*executeComplain[0])();
break;
... case 3까지 반복
default:
오류메세지 출력
}
}2) class의 멤버함수에 접근하기
과제에서 if-else문 사용을 지양한다고 하여 switch문을 사용해서 구현했다. switch문에 대한 설명은 다음 문제에서 하겠다.
if-else문을 사용하지 않기 위해 함수포인터를 배열에 넣었고, 어떤 레벨이 들어오는지에 대한 판단도 레벨 문자열을 담은 문자열의 배열로 판단하였다.
또 여기서 중요한 점은 객체 자신class의 멤버함수에 접근할 때는 this-> 키워드를 사용해야한다는 것이다.
class Harl
{
private:
void debug(void);
void info(void);
void warning(void);
void error(void);
public:
void complain(std::string level);
};
void Harl::complain(std::string level)
{
void (Harl::*executeComplain[4])() = {&Harl::debug, &Harl::info, &Harl::warning, &Harl::error};
std::string complainTypeArr[4] = {"debug", "info", "warning", "error"};
int complainType = 0;
while (complainType < 4)
{
if (level == complainTypeArr[complainType])
break;
complainType++;
}
switch(complainType)
{
case 0:
(this->*executeComplain[0])();
break;
case 1:
(this->*executeComplain[1])();
break;
case 2:
(this->*executeComplain[2])();
break;
case 3:
(this->*executeComplain[3])();
break;
default:
std::cout << "Wrong complaint type input" << std::endl;
}
}
Exercise 06: Harl filter
1. Subject
Exercise 05번 문제에서 만든 프로그램에서 원하는 레벨 이상의 컴플레인만 볼 수 있는 필터를 붙인 프로그램을 만들어라
2. Point
핵심 개념
- switch문
switch문
05번 문제와 이어지는 문제여서 switch문과 코드에 대한 설명은 여기서 해보겠다.
먼저 if-else문을 사용하지 않으려면 switch문을 사용해야한다. 그리고 6번 문제는 꼭 switch문을 사용하라는 내용이 있다.
❓ switch문과 if-else문은 어떻게 다를까?
if문은 case를 하나하나 비교한다. 즉 최악의 경우 O(n)의 시간복잡도를 가지게된다. switch문에서 일정하게 정렬된 값이 들어온다면 컴파일러는 switch 테이블이라는 case문을 위한 메모리 공간을 배열로 생성하여 case에 해당하는 주소를 찾아가게 된다. 정렬된 값의 비교라면 switch문이 더 효율적이라고 한다.
case가 일정할 경우 if문보다 switch문의 성능이 더 뛰어나다고 할 수 있다.
3. Solution
1) switch와 break
이번 과제에서는 switch의 break문을 조작해본다.
해당 컴플레인이 들어오면 그 컴플레인 상위의 컴플레인 메세지는 모두 출력하는 형식으로 필터를 만드는 것이다.
switch(complainType)
{
case 0:
(this->*executeComplain[0])();
case 1:
(this->*executeComplain[1])();
case 2:
(this->*executeComplain[2])();
case 3:
(this->*executeComplain[3])();
break;
default:
std::cout << "Wrong complaint type input" << std::endl;
}이는 간단히 마지막 case의 break문을 제외하고 다른 break문은 없애주면된다.
4. Opinion
switch의 break문을 없애는 부분에 대해서 고민을 많이 했다.
It will display all messages from this level and above. For example:
$> ./harlFilter "WARNING"
[ WARNING ]
I think I deserve to have some extra bacon for free.
I've been coming for years whereas you started working here since last month.
[ ERROR ]
This is unacceptable, I want to speak to the manager now.
$> ./harlFilter "I am not sure how tired I am today..."
[ Probably complaining about insignificant problems ]과제에는 이렇게 나와있는데 기능적으로 생각해봤을 때 단순히 필터를 적용하면 해당 레벨이하의 컴플레인만 무시하고 level로 들어온 컴플레인만 나오게 하면 된다고 생각했다.
그러나 기준 level을 넘으면 해당 level이상의 컴플레인은 모두 출력되게 해야된다는 이야기를 들었고 어떤 것이 맞는지는 문제와 예시만으로는 명확하게 알 수 없어 문제의 의도를 생각해보았다.
이 문제는 switch의 break문이 없으면 어떻게 될지 생각해보는 문제라고 생각되어 기준 level을 넘으면 모든 level의 컴플레인을 출력하도록 구현하였다.
📚 reference
