업비트 API를 이용하여 가져오는 실시간 데이터를 AWS의 dynamoDB에 저장해보자.
kafka upbit 토픽으로 들어오는 실시간 거래 데이터를 dynamoDB에 저장하는 consumer 파일을 작성한다.
dynamo_consumer.py (kafka 모듈)
import json
import boto3
from kafka import KafkaConsumer
import datetime
from decimal import Decimal
def process_message(message, table):
# Parse the message as JSON
data = json.loads(message.value.decode('utf-8'), parse_float=Decimal)
market = data[0]['market'] #마켓구분코드
trade_date_utc = data[0]['trade_date_utc'] #체결 일자(UTC기준)
trade_time_utc = data[0]['trade_time_utc'] #체결 시간(UTC기준)
timestamp = data[0]['timestamp'] #체결 타임스탬프
trade_price = data[0]['trade_price'] # 체결가격
trade_volume = data[0]['trade_volume'] #체결량
prev_closing_price = data[0]['prev_closing_price'] #전일종가
change_price = data[0]['change_price'] #변화량
ask_bid = data[0]['ask_bid'] #매도/ 매수
sequential_id = data[0]['sequential_id'] #체결 번호 (유니크)
utc_datetime = datetime.datetime.utcfromtimestamp(timestamp/1000)
kst_datetime = utc_datetime + datetime.timedelta(hours=9)
kst_time = kst_datetime.strftime('%Y-%m-%d %H:%M:%S') #체결 시간 (KST)
item = {
'market' : market,
'trade_date_utc' : trade_date_utc,
'trade_time_utc' : trade_time_utc,
'kst_time' : kst_time,
'timestamp' : timestamp,
'trade_price' : trade_price,
'trade_volume' : trade_volume,
'prev_closing_price' : prev_closing_price,
'change_price' : change_price,
'ask_bid' : ask_bid,
'sequential_id' : sequential_id
}
#print(item)
# Store the data in DynamoDB
response = table.put_item(Item=item)
print('Stored record:', response)
if __name__ == '__main__':
# Connect to the DynamoDB table
dynamodb = boto3.resource('dynamodb',region_name='ap-northeast-2', aws_access_key_id='accesskey',aws_secret_access_key='secretkey')
table = dynamodb.Table('upbit')
# Configure the Kafka consumer
consumer = KafkaConsumer("upbit",
bootstrap_servers=[
'kafka-01:9092', 'kafka-02:9092', 'kafka-03:9092'],
auto_offset_reset="latest", # 어디서부터 값을 읽어올지 (earlest >가장 처음 latest는 가장 최근)
enable_auto_commit=True, # 완료되었을 떄 문자 전송
#value_deserializer=lambda x: json.loads(x.decode('utf-8')),# >역직렬화 ( >받을 떄 ) ; 메모리에서 읽어오므로 loads라는 함수를 이용한다. // 직렬화 (보낼 떄)
#consumer_timeout_ms=1000 # 1000초 이후에 메시지가 오지 않으면 없는 것으로 취급.
)
# Consume and process messages
try:
for msg in consumer:
process_message(msg, table)
except KeyboardInterrupt:
pass
finally:
consumer.close()dynamo_consumer.py (confluent_kafka 모듈)
import json
import boto3
from confluent_kafka import Consumer, KafkaError
import datetime
from decimal import Decimal
def process_message(message, table):
# Parse the message as JSON
data = json.loads(message.value(), parse_float=Decimal)
market = data[0]['market'] #마켓구분코드
trade_date_utc = data[0]['trade_date_utc'] #체결 일자(UTC기준)
trade_time_utc = data[0]['trade_time_utc'] #체결 시간(UTC기준)
timestamp = data[0]['timestamp'] #체결 타임스탬프
trade_price = data[0]['trade_price'] # 체결가격
trade_volume = data[0]['trade_volume'] #체결량
prev_closing_price = data[0]['prev_closing_price'] #전일종가
change_price = data[0]['change_price'] #변화량
ask_bid = data[0]['ask_bid'] #매도/ 매수
sequential_id = data[0]['sequential_id'] #체결 번호 (유니크)
utc_datetime = datetime.datetime.utcfromtimestamp(timestamp/1000)
kst_datetime = utc_datetime + datetime.timedelta(hours=9)
kst_time = kst_datetime.strftime('%Y-%m-%d %H:%M:%S') #체결 시간 (KST)
item = {
'market' : market,
'trade_date_utc' : trade_date_utc,
'trade_time_utc' : trade_time_utc,
'kst_time' : kst_time,
'timestamp' : timestamp,
'trade_price' : trade_price,
'trade_volume' : trade_volume,
'prev_closing_price' : prev_closing_price,
'change_price' : change_price,
'ask_bid' : ask_bid,
'sequential_id' : sequential_id
}
#print(item)
# Store the data in DynamoDB
response = table.put_item(Item=item)
print('Stored record:', response)
if __name__ == '__main__':
# Connect to the DynamoDB table
dynamodb = boto3.resource('dynamodb',region_name='ap-northeast-2', aws_access_key_id='accesskey',aws_secret_access_key='secretkey')
table = dynamodb.Table('upbit')
# Configure the Kafka consumer
consumer_conf = {
'bootstrap.servers': 'kafka-01:9092, kafka-02:9092, kafka-03:9092',
'group.id': 'mygroup',
'auto.offset.reset': 'latest'
}
consumer = Consumer(consumer_conf)
consumer.subscribe(['upbit'])
# Consume and process messages
try:
while True:
msg = consumer.poll(1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
print('End of partition event received')
else:
print('Error while consuming message: {}'.format(msg.error()))
else:
process_message(msg, table)
consumer.commit()
except KeyboardInterrupt:
pass
finally:
consumer.close()다음 파일을 실행시키게 되면 upbit 토픽으로 들어온 데이터를 dynamoDB에 저장한다.
DynamoDB 데이터 삭제하기
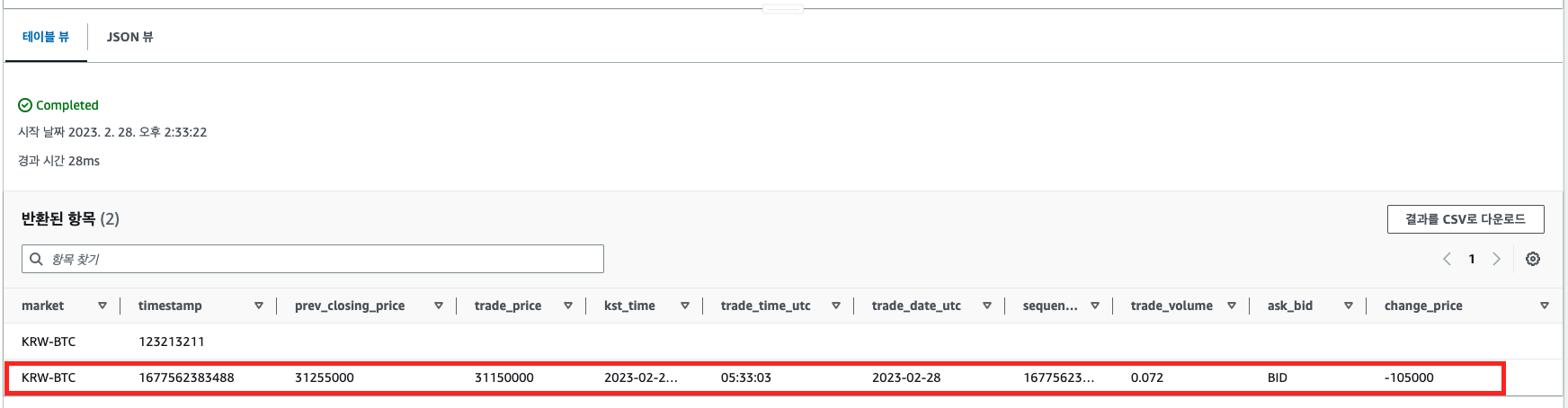
테스트시 사용한 데이터를 삭제해보자.
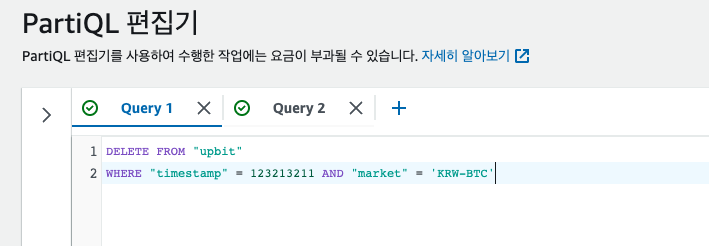
삭제 시 파티션 키에 대한 조건이 없으면 ValidationException: Where clause does not contain a mandatory equality on all key attributes 오류 발생
dynamo_consumer.py 실행하여 실시간 데이터를 적재해봤다.
💡참고
python if __name__ == '__main__':" 의 의미
__name__ == __main__은 인터프리터에서 직접 실행했을 경우에만 if문 내의 코드를 돌리라는 명령이 됩니다.
.py파일을 import했을 때는 해당 구문 밑에 부분은 실행되지 않는다.
python confluent_kafka 모듈과 kafka 모듈의 차이점
The main differences between the confluent_kafka module and the kafka module are in the configuration of the consumer. In the kafka module, the KafkaConsumer class is used to create a consumer object, which is configured using various parameters. These parameters include the topic to subscribe to, the bootstrap servers to connect to, the auto offset reset behavior, and the consumer group ID.
The KafkaConsumer object returns an iterator that can be used to consume messages from the Kafka topic. In this modified code, we use a for loop to iterate over the messages and call the process_message function for each message received.
Note that the enable_auto_commit parameter is set to True in the KafkaConsumer configuration, which automatically commits the offset of each message after it has been processed. This is different from the confluent_kafka module, where the offset must be manually committed using the commit() method of the consumer object.
confluent_kafka 모듈과 kafka 모듈의 주요 차이점은 소비자 구성에 있습니다. kafka 모듈에서 KafkaConsumer 클래스는 다양한 매개변수를 사용하여 구성된 소비자 개체를 만드는 데 사용됩니다. 이러한 매개변수에는 구독할 주제, 연결할 부트스트랩 서버, 자동 오프셋 재설정 동작 및 소비자 그룹 ID가 포함됩니다.
KafkaConsumer 개체는 Kafka 주제에서 메시지를 소비하는 데 사용할 수 있는 반복자를 반환합니다. 이 수정된 코드에서는 for 루프를 사용하여 메시지를 반복하고 수신된 각 메시지에 대해 process_message 함수를 호출합니다.
KafkaConsumer 구성에서 enable_auto_commit 매개변수가 True로 설정되어 처리된 후 각 메시지의 오프셋을 자동으로 커밋합니다. 이는 소비자 개체의 commit() 메서드를 사용하여 오프셋을 수동으로 커밋해야 하는 confluent_kafka 모듈과 다릅니다.
