
Join
데이터베이스에서 ‘두 개 이상의 테이블’을 연결하여 ‘하나의 결과의 테이블’로 만드는 것
사용하는 이유
RDBMS 특성상 정규화를 통해 분리된 데이터를 효율적으로 검색하고 처리할 수 있음.
유형
INNER JOIN
- INNER JOIN : 두 테이블에서 일치하는 튜플만 반환
SELECT *
FROM 테이블1
INNER JOIN 테이블2
ON 테이블1.열 = 테이블2.열;
-- INNER JOIN
SELECT employees.name, departments.name
FROM employees
INNER JOIN departments
ON employees.department_id = departments.id;- SELF INNER JOIN : 자기 자신과 조인
SELECT 테이블1.열, 테이블2.열
FROM 테이블1 t1
JOIN 테이블1 t2
ON 테이블1.열 = 테이블2.열;OUTER JOIN
두 테이블에서 '공통된 값을 가지지 않는 행'도 반환
- LEFT [OUTER] JOIN : ’왼쪽 테이블의 모든 행’과 ‘오른쪽 테이블에서 왼쪽 테이블과 공통된 값’을 가지고 있는 행들을 반환
SELECT *
FROM 테이블1
LEFT JOIN 테이블2
ON 테이블1.열 = 테이블2.열;
-- LEFT JOIN
SELECT employees.name, departments.name
FROM employees
LEFT JOIN departments
ON employees.department_id = departments.id;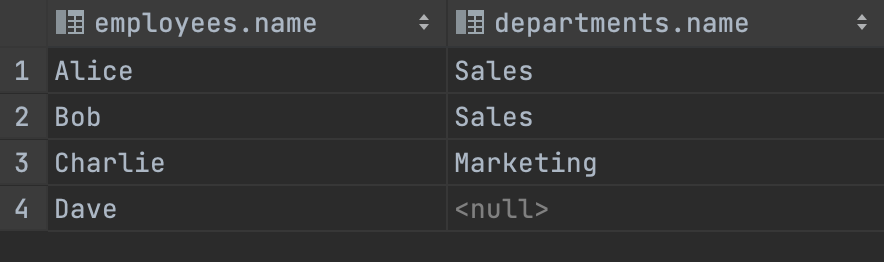
- RIGHT OUTER JOIN : ‘오른쪽 테이블의 모든 행’과 ‘왼쪽 테이블에서 오른쪽 테이블과 공통된 값’을 가지고 있는 행들을 반환
SELECT *
FROM 테이블1
RIGHT JOIN 테이블2
ON 테이블1.열 = 테이블2.열;
-- RIGTH JOIN
SELECT employees.name, departments.name
FROM employees
RIGHT JOIN departments
ON employees.department_id = departments.id;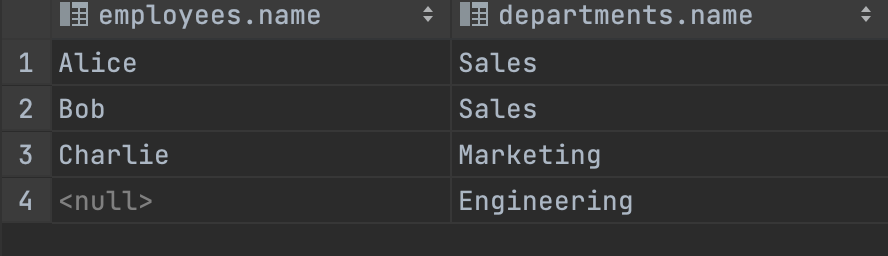
- FULL OUTER JOIN : 두 테이블에서 ‘모든 값’을 반환. 만약 공통된 값을 가지고 있지 않는 행이 있다면 NULL 값을 반환
SELECT *
FROM 테이블1
FULL OUTER JOIN 테이블2
ON 테이블1.열 = 테이블2.열;
-- FULL JOIN
SELECT employees.name, departments.name
FROM employees
FULL JOIN departments
ON employees.department_id = departments.id;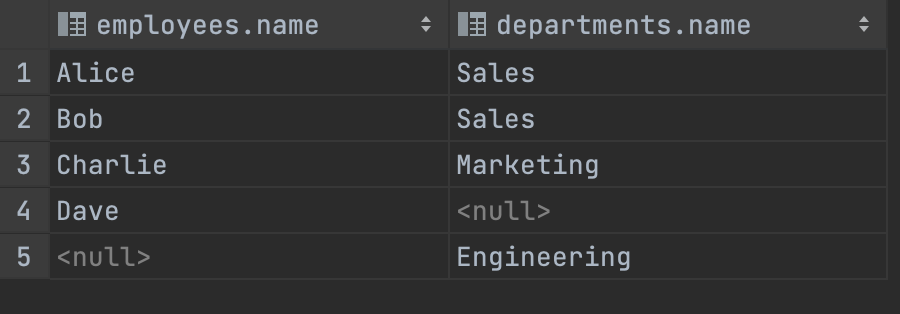
JOIN 알고리즘
💡 Nested Loop Join
- 하나의 테이블을 루프 하면서 다른 테이블을 루프 하며 두 테이블의 조인 조건이 맞는지 확인한다. 두 테이블 중 작은 테이블을 먼저 루프 하고, 큰 테이블을 뒤에 루프 하면 효율적이다.
- 하지만 데이터 양이 많을 경우 성능이 좋지 않다. 이는 루프 내에서 매 번 조인 조건을 비교하기 때문이다.
💡 Block Nested Loop Join
- Nested Loop Join의 성능을 개선한 알고리즘.
Block Nested Loop Join은 두 테이블을 블록 단위로 처리한다. 블록은 메모리에 올라가는 크기로 결정되며, 블록 단위로 조인을 수행한다. 이를 통해 Nested Loop Join의 성능 문제를 완화할 수 있다.
하지만 블록 크기를 결정하는 것이 어렵기 때문에 최적의 성능을 보장하지 못할 수 있다.
💡 Sort Merge Join
- 두 테이블을 각각 정렬한 다음에 조인하는 알고리즘.
정렬된 데이터를 이용하기 때문에 Nested Loop Join보다 빠른 속도를 갖는다. - 하지만 정렬에 대한 비용이 추가되므로, 조인할 데이터의 크기가 작을 경우에는 Nested Loop Join이 더 빠를 수 있다.
💡 Index Join
- Index Join은 Join 대상 테이블의 인덱스를 이용하여 조인하는 알고리즘.
Index Join은 인덱스를 이용하기 때문에 매우 빠른 퍼포먼스를 보여준다. - 하지만 인덱스를 만들어야 하기 때문에 인덱스 생성 비용이 추가된다. 또한, 인덱스를 이용할 수 있는 경우가 제한적이기 때문에 모든 경우에 적용할 수 없다.
💡 Hash Join
- 두 테이블을 Hash Table로 변환한 다음에 조인하는 알고리즘.
Hash Table을 이용하기 때문에 매우 빠른 퍼포먼스를 보여주다. - 하지만 Hash Table을 만드는 데에는 메모리가 많이 필요하며, 조인할 데이터의 크기가 클 경우에는 디스크 I/O가 많아져 성능이 떨어질 수 있다.
SELECT
테이블의 데이터를 조회할 때 사용하는 SQL 문이다.
쿼리 순서
- FROM: 데이터 소스 테이블을 결정
- JOIN: 필요한 경우 조인 연산을 수행
- WHERE: 조건에 맞는 행을 필터링
- GROUP BY: 데이터를 그룹화
- HAVING: 그룹화된 결과에 대해 조건 적용
- SELECT: 필요한 열을 선택
- DISTINCT: 중복된 행을 제거
- ORDER BY: 결과를 정렬
- LIMIT/OFFSET: 반환할 행의 수를 제한
MySQL/MariaDB SELECT 쿼리 순서
- FROM
- JOIN
- WHERE
- GROUP BY
- WITH ROLLUP (추가)
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT/OFFSET

한 걸음씩 꾸준히