부유 쓰레기
해양 부유 쓰레기 데이터를 찾아 직접 촬영하여 데이터 셋을 만든다. 수집한 데이터들을 이용하여 자료구조 문제를 해결한다.
📝데이터 소개
하천 부유 쓰레기 사진 데이터를 직접 구성하고, 공유하여 본인의 데이터 베이스를 구축한다.
데이터 수집 정보
쓰레기의 종류를 5가지로 고정한다. Rubbish, Plastics, Cans, Glass, Papers로 종류를 나누며 Rubbish는 일반쓰레기에 해당하며 이외의 다른 종류와 겹치지 않는다. 각 종류별 4개~5개의 부유 쓰레기 데이터를 수집한다. 촬영한 원본은 총 35개의 데이터가 모이게 된다.
(계획한 총 20개~25개 데이터를 초과한 데이터를 삭제하지 않고 데이터 섹에 추가하였다.)
데이터 수집 장소
집과 학교 주변의 부유 쓰레기가 있을 만한 담수생태계를 탐색한다. 습지 공원과 호수, 하천을 골라 데이터를 수집하였다.
- 강서 습지 생태공원(서울특별시 강서구 방화3동 2-15)
- 서울 식물원 호수공원(서울특별시 강서구 마곡동 811-3)
- 성북천(서울특별시 성북구 동선동)
데이터 처리 정보
촬영한 부유 쓰레기 데이터는 모두 jpg파일로 저장되어 있다. jpg파일은 손실 압축 파일 포맷으로 압축 과정에서 원본 데이터에서의 정보손실(훼손)이 발생한다. 이를 방지하기 위해 비손실 압축 파일 포맷인 png확장자를 이용하여 압축 과정에서 이미지의 정보가 손실되는 것을 방지할 수 있다.
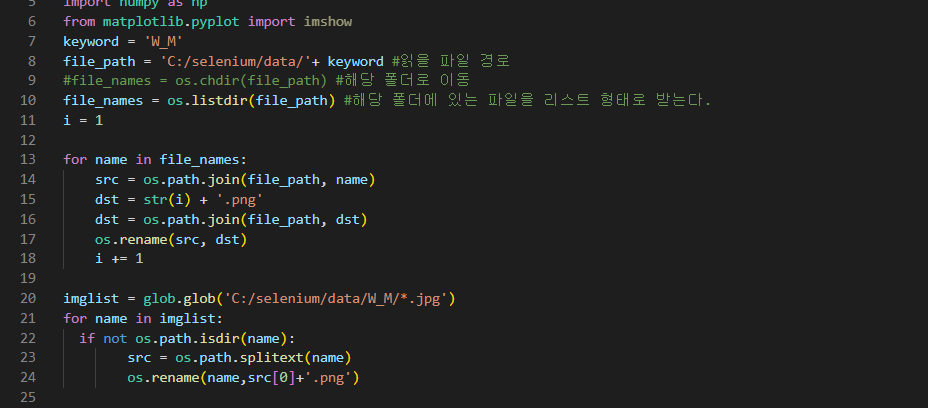
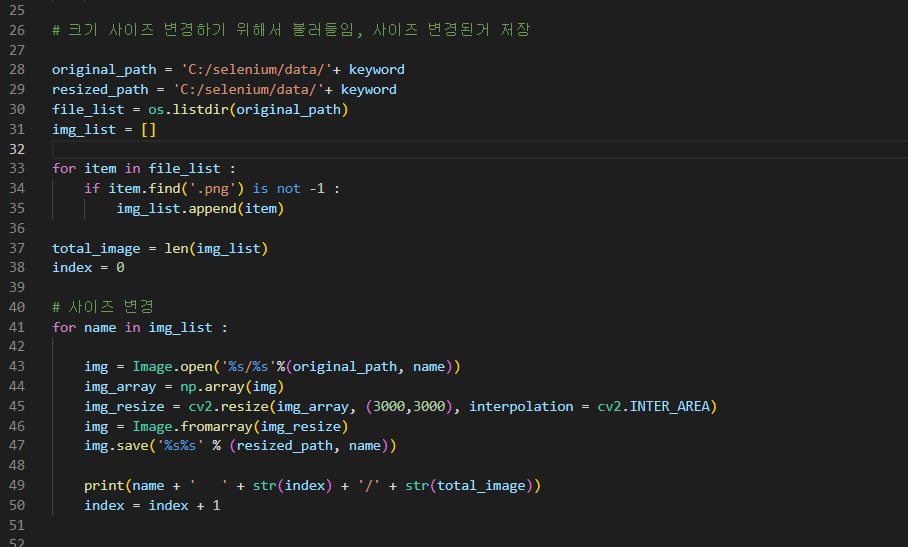
수집한 데이터는 크기가 제각각이다. 데이터의 크기를 픽셀단위로 저장하며 데이터의 화질을 고려하여 3000 X 3000 픽셀로 통일한다.
(데이터 처리 정의시 224 X 224 픽셀로 지정하였으나 데이터의 화질을 고려해 3000 x 3000 픽셀로 변경하였다.)

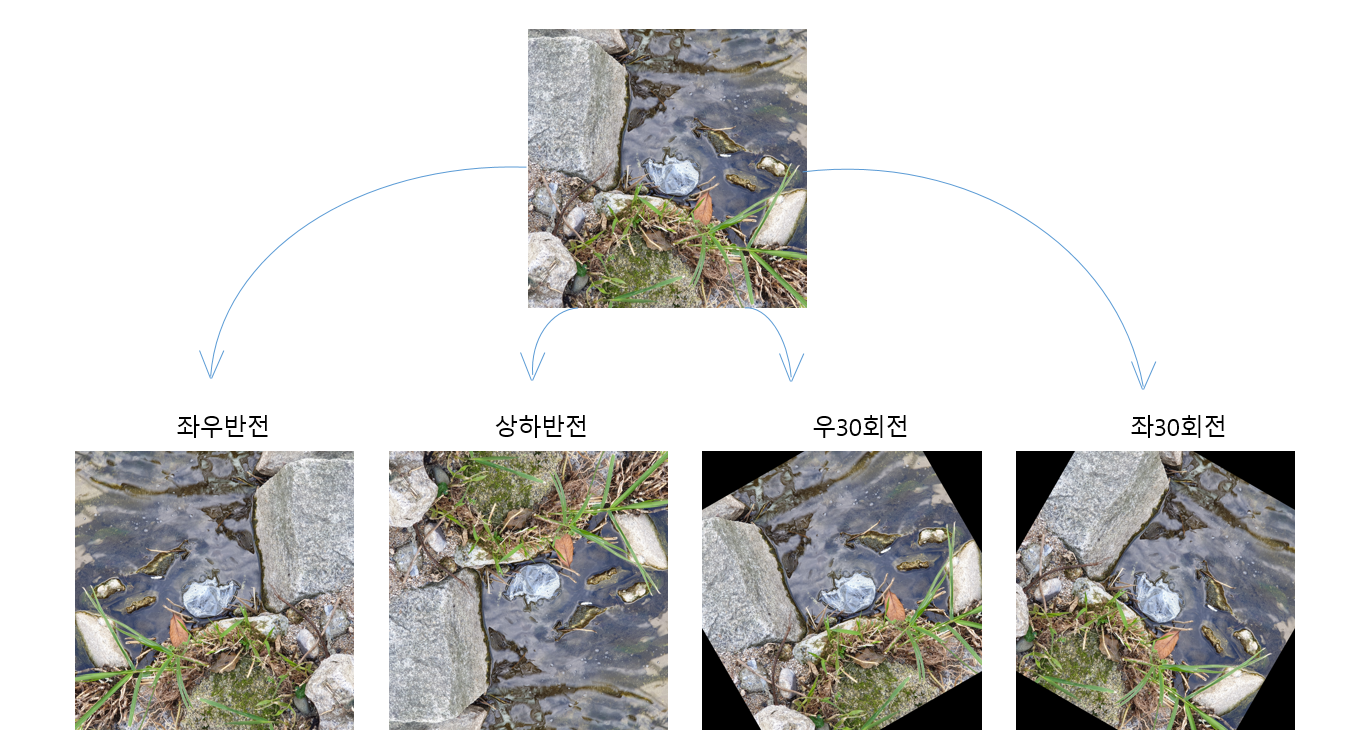
35장의 원본 데이터를 수집하였다. 데이터를 증식시켜 100장 이상의 데이터를 만든다. 원본 데이터를 좌우반전, 상하반전, 좌회전 30도, 우회전 30도시켜 데이터를 4배 증식한다. 증식시킨 데이터도 하나의 독립된 데이터로 인식하며 총 175장의 데이터가 모이게 된다.

데이터 명
csv파일에 총 데이터의 정보를 저장한다. 각 데이터의 명은 수집한 장소의 위치와 종류에 따라 지정한다. 해당 장소의 주소와 이름을 참고한다.
위치 : E(강동), W(강서), S(강남), N(강북)
종류 : M(습지), L(호수), R(하천)
강서 습지 생태공원 : W_M
서울 식물원 호수공원 : W_L
성북천(동선동) : N_R
데이터 위치
csv파일에 총 데이터의 정보를 저장한다. 각 데이터의 위치 정보를 추출하여 데이터 정보에 입력한다. 위치 정보는 촬영한 이미지의 GPS값을 이용하여 수집 장소를 찾을 수 있다. 첫번째 값은 위도(Latitude), 두번째 값을 경도(Longitude)로 값을 정리한다. 소숫점 아래 3번째까지만 반영한다.
강서 습지 생태공원 : 37.5865208, 126.8186729
서울 식물원 호수공원 : 37.5700935, 126.8323798
성북천(동선동) : 37.5892014, 127.0181027
📝문제 소개
수집한 데이터들로 구축한 데이터 베이스를 바탕으로 원하는 문제를 정의하고, 자료구조를 이용하여 문제를 해결한다.
문제 설명
마포 자원 회수 시설에서 쓰레기차가 서울의 부유 쓰레기를 수거하려고 한다. 전체 부유 쓰레기의 데이터를 불러와 가장 많은 양을 차지하는 1가지의 쓰레기 종류만을 수거한다. 가까운 지점부터 방문하며 방문하는 지점은 하천, 호수, 습지 등과 같으며 해당 종류의 쓰레기가 없으면 방문하지 않아도 된다. 가장 많은 1가지 종류의 부유 쓰레기를 모두 수거하였을 때 출발했던 회수 시설로 돌아온다. 쓰레기차가 1가지의 부유 쓰레기들을 수거하는 경로가 최단거리가 되도록하며 이때 걸린 총 소요 시간을 구하여라
문제 조건
한 개의 쓰레기를 수거하는 소요 시간 : 2분
다른 지점으로 이동하는 위도 경도 차이에 따른 이동 소요 시간 : x분(미정)
쓰레기차가 회수할 수 있는 쓰레기의 최대 개수는 20개이며, 수거한 쓰레기의 양이 20개일 경우 출발했던 회수 시설로 돌아가 쓰레기를 비운 뒤 다시 수거를 진행한다.
문제 접근
본인이 수집한 데이터 외에 다른 데이터를 불러와 데이터를 추가한다. 추가한 데이터도 위와 같이 부유 쓰레기 이미지 데이터의 정보를 정리한다. 회수 시설은 시작노드이며 다른 여러 지점들을 노드로 지정한다. 노드들 간의 위치 정보( 위도, 경도 )를 이용하여 가중치를 할당한다.
기존 데이터에 가중치를 추가하여 새로운 데이터 셋 파일을 만든 후 파일을 불러온다.
부유 쓰레기를 수거하는 경로가 최단 거리가 되어야 하기 때문에 가중치 정보를 이용한 최단 거리 알고리즘을 사용한다.
최단 거리 알고리즘
- Floyd Warshall 알고리즘
모든 정점에서 모든 정점으로의 최단 경로를 구하는 알고리즘- Bellman Ford 알고리즘
시작 정점부터 특정 정점까지의 최단거리를 알기 위한 알고리즘 음수 가중치 O- KrusKal 알고리즘
가중치가 증가하는 순서대로 정렬
가중치가 가장 작은 간선이 사이클을 만들지 않으면 트리 간선으로 선택- A* 알고리즘
시작 노드에서 목적지 노드를 지정해주면 이 2개의 노드 간의 최단 경로를 분석하는 알고리즘- Dijkstra 알고리즘
시작 노드를 지정하면 다른 모든 노드에 대한 최단 경로를 분석하는 알고리즘
매 상황에서 가중치가 적은 노드를 선택하고 이를 반복한다. 음의 간선 x
회수 시설이라는 시작 노드와 다른 노드들의 위치 정보를 기반으로 하는 가중치가 가지고 있기 때문에 문제 해결에 가장 적합한 Dijkstra 알고리즘을 사용한다.
예시
수집한 데이터를 바탕으로 다익스트라 알고리즘을 사용하는 예시를 만들어 보았다.
실제 지도를 보고 그린 트리이다.
가중치를 실제 지도에서 대략적으로 가장 작은 거리를 기준으로 상수배 적용한다.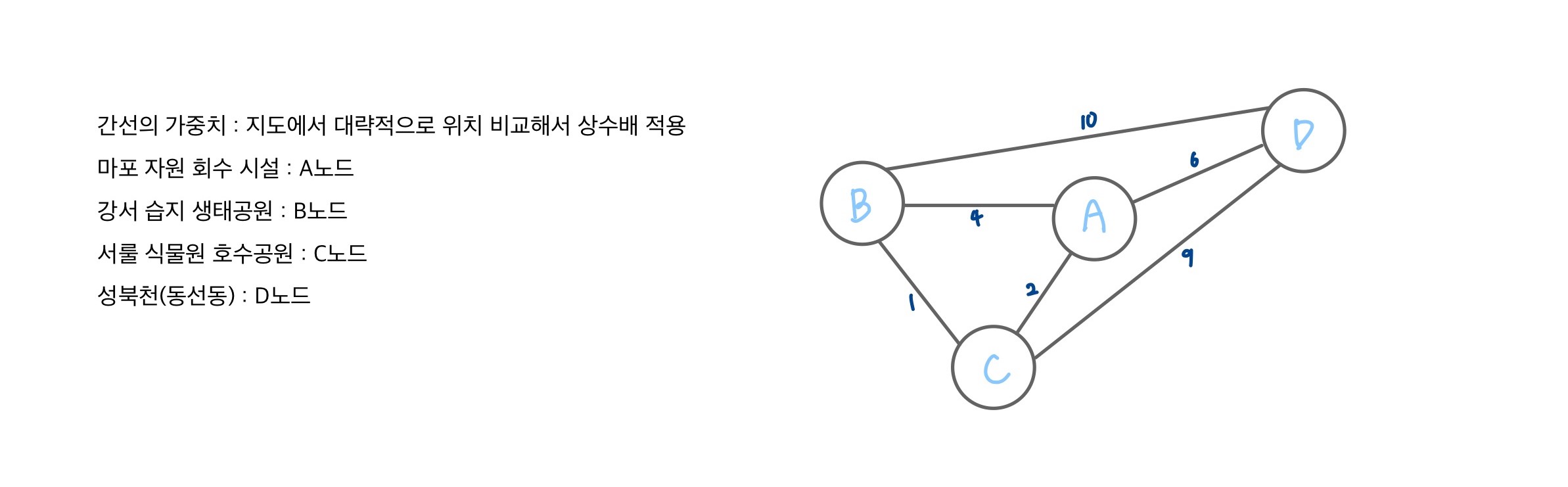 시작노드 A를 방문한다.
시작노드 A를 방문한다.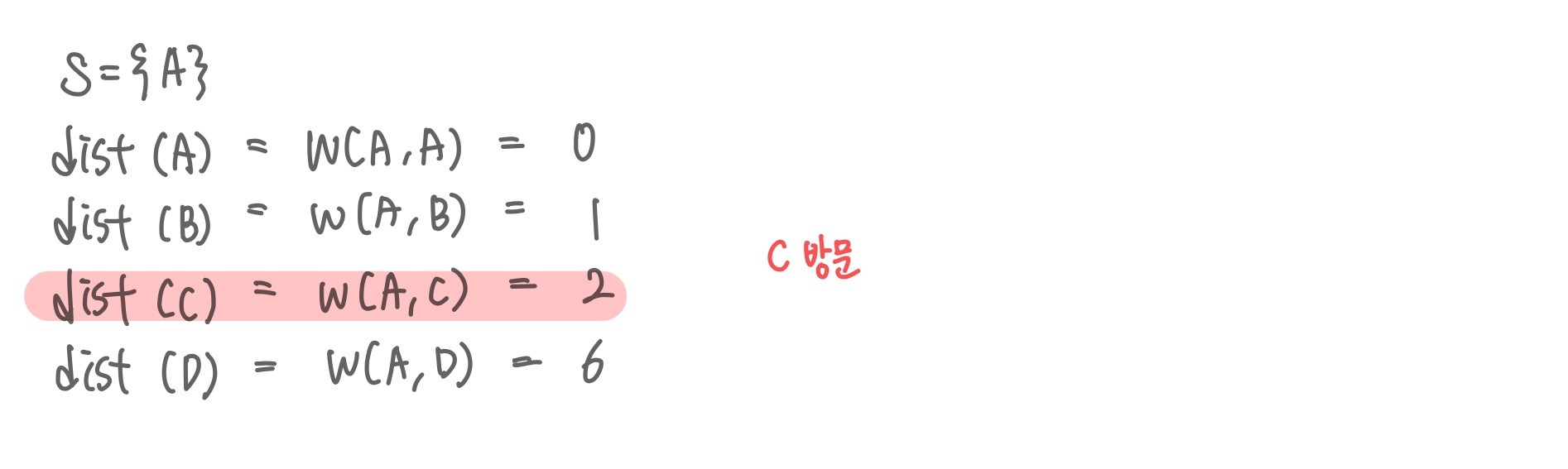
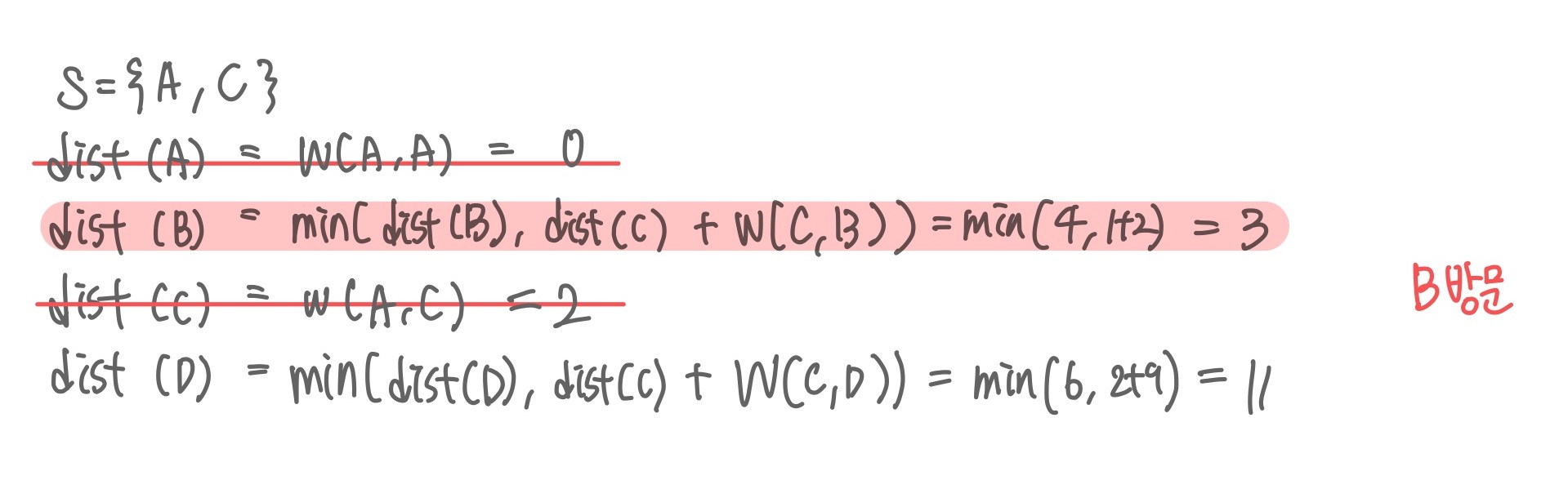
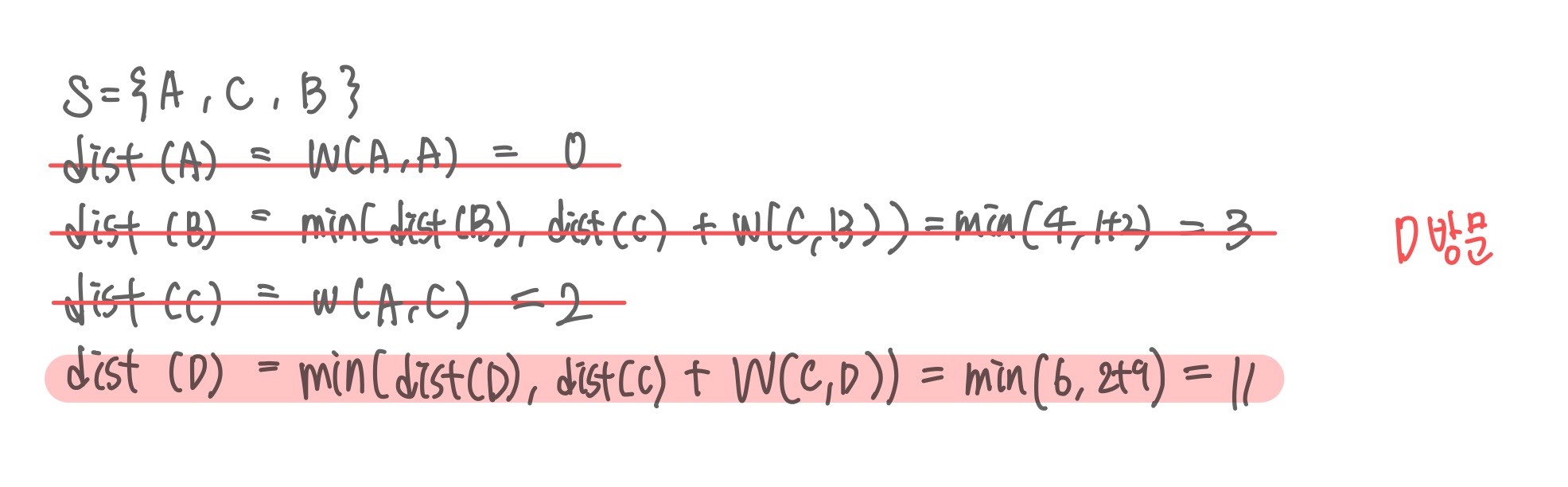
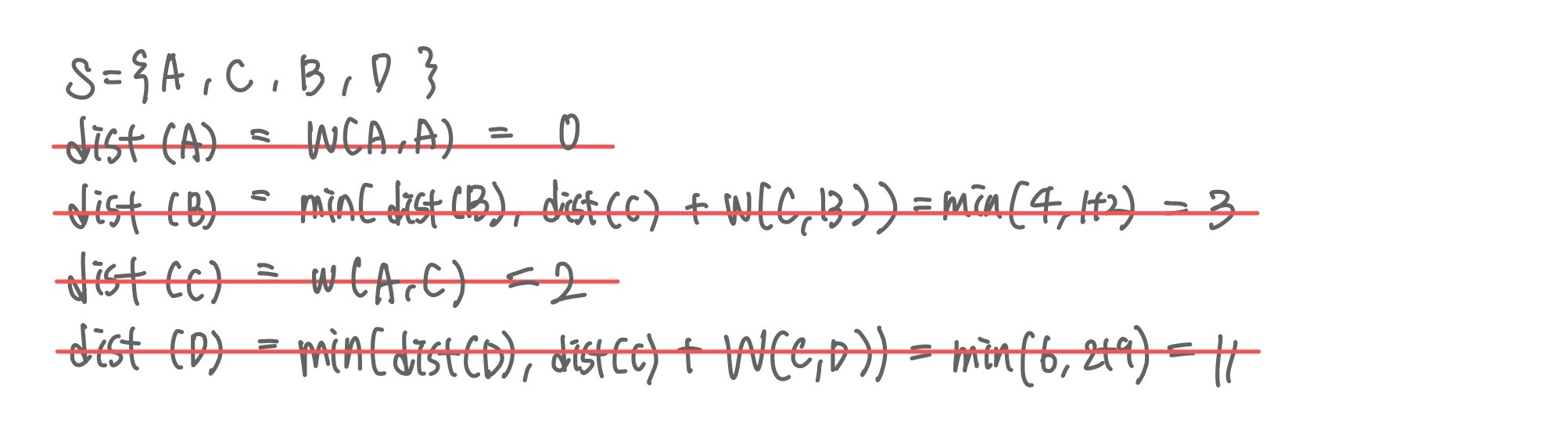 최종적으로 A, C, B, D순으로 최단 경로가 정해진다. 특정 한가지의 부유쓰레기를 수거하는 시간과 이동 시간을 적용시키고, 수거하는 데이터 양을 저장하는 배열값을 만들어 최대 20일 경우 회수 시설로 돌아가도록 한다.
최종적으로 A, C, B, D순으로 최단 경로가 정해진다. 특정 한가지의 부유쓰레기를 수거하는 시간과 이동 시간을 적용시키고, 수거하는 데이터 양을 저장하는 배열값을 만들어 최대 20일 경우 회수 시설로 돌아가도록 한다.
📝데이터 공유
데이터
전체 데이터
https://drive.google.com/drive/folders/1TbRkEGnlOGBP2a0nn5PAs7X39B6JiMTq?usp=sharing
원본 데이터
https://drive.google.com/drive/folders/1lZB6cbnq-8wVRrE_-evGDcyna-nu9iw8?usp=sharing
참고(데이터 찾을 때 유용!)
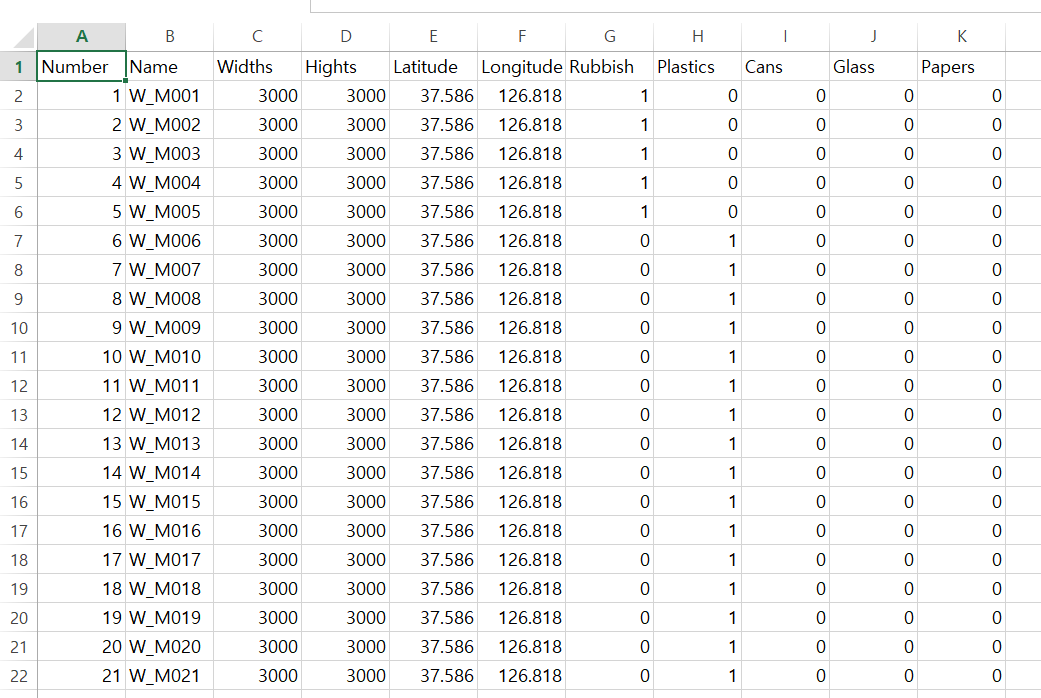 수집한 데이터의 정보를 csv파일에 정리한다. csv파일은 총 11개의 열정보를 가진다. 데이터의 총 개수는 175장이며 각 종류별 4~5개로 맞추었지만 추가로 수집한 데이터들을 삭제하지 않고 데이터를 포함시켰다.
수집한 데이터의 정보를 csv파일에 정리한다. csv파일은 총 11개의 열정보를 가진다. 데이터의 총 개수는 175장이며 각 종류별 4~5개로 맞추었지만 추가로 수집한 데이터들을 삭제하지 않고 데이터를 포함시켰다.
1열 Number : 넘버링
2열 Name : 데이터 명
3열 Widths : 데이터의 너비 값
4열 Hights : 데이터의 높이 값
5열 Latitude : 데이터의 위치 정보 위도
6열 Longitude : 데이터의 위치 정보 경도
7~11열 : Rubbish, Plastic, Cans, Glass, Papers 순서로 데이터 분류
총 데이터 175장
데이터의 순서 W_M -> W_L -> N_R
전체 데이터는 하나의 원본 데이터를 시작으로 만들어진 증식 데이터를 나열한다. 원본 데이터와 하나의 원본 데이터로 만들어지는 4장의 데이터를 순서대로 나열한다. (원본 좌우반전 상하반전 우30회전 좌30회전)
첫번째 : 장소로 분류
전체 데이터 175장 중
W_M데이터 45장 ( W_M001.png ~ W_M045.png )
W_L데이터 55장 ( W_L001.png ~ W_L055.png )
N_R데이터 75장 ( N_R001.png ~ N_R075.png )
두번째 : 종류로 분류
- W_M데이터 45장 중
Rubbish ( W_M001.png ~ W_M005.png )
Plastic ( W_M006.png ~ W_M025.png )
Cans ( W_M026.png ~ W_M030.png )
Glass ( W_M031.png ~ W_M040.png )
Papers ( W_M041.png ~ W_M045.png ) - W_L데이터 55장 중
Rubbish ( W_L001.png ~ W_L020.png )
Plastic ( W_L021.png ~ W_L025.png )
Cans ( W_L026.png ~ W_L035.png )
Glass ( W_L036.png ~ W_L045.png )
Papers ( W_L046.png ~ W_L055.png ) - N_R데이터 75장 중
Rubbish ( N_R001.png ~ N_R045.png )
Plastic ( N_R046.png ~ N_R060.png )
Cans ( N_R061.png ~ N_R065.png )
Glass ( N_R066.png ~ N_R070.png )
Papers ( N_R071.png ~ N_R075.png )
데이터 위치
(An = a + (n-1) d )를 통해 구할 수 있다.
원본 데이터 위치 : 1 + (n-1) 5
좌우반전 데이터 위치 : 2 + (n-1) 5
상하반전 데이터 위치 : 3 + (n-1) 5
우30회전 데이터 위치 : 4 + (n-1) 5
좌30회전 데이터 위치 : 5 + (n-1) 5
📝data.csv
전체 데이터들의 정보를 확인할 수 있다.
https://drive.google.com/file/d/1v9n4Gm_6VhOV0-2kKuIEwYaWZwf6cPpb/view?usp=sharing
