A Performance Counter Architecture for Computing Accurate CPI Compenents
1. Introduction
CPI breakdowns 를 통한 분석은 한 애플리케이션 프로세스가 마이크로프로세서에서 어떤 행동을 보이는지 좋은 통찰력을 주는 도구이다. 소프트웨어 엔지니어 또는 컴퓨터 아키텍트는 이러한 분석을 통해 어떻게 SW를 혹은 HW를 설계할지 그 지표로 사용할 수 있다. 그러나 modern SS, OoO processor에서는 다양한 miss event of CPI components들이 겹쳐서 발생하기에 그 분석이 힘들다. (e.g. cache miss, branch misprediction, TLB miss, 등) 본 논문에서 어떻게 CPI stacks가 이러한 프로세서에서 의미있고 정확하게 계산되는지 보여준다.
2. Contructing CPI Stacks
한 프로세서에서의 CPI 는 기본적으로 base CPI 에 다양한 CPI를 증가시키는 요인들이 쌓여서(e.g. cache miss, TLP miss, branch mispred. ..) 계산된다. 따라서 이런 breakdown을 ‘CPI stack’이라 부른다!
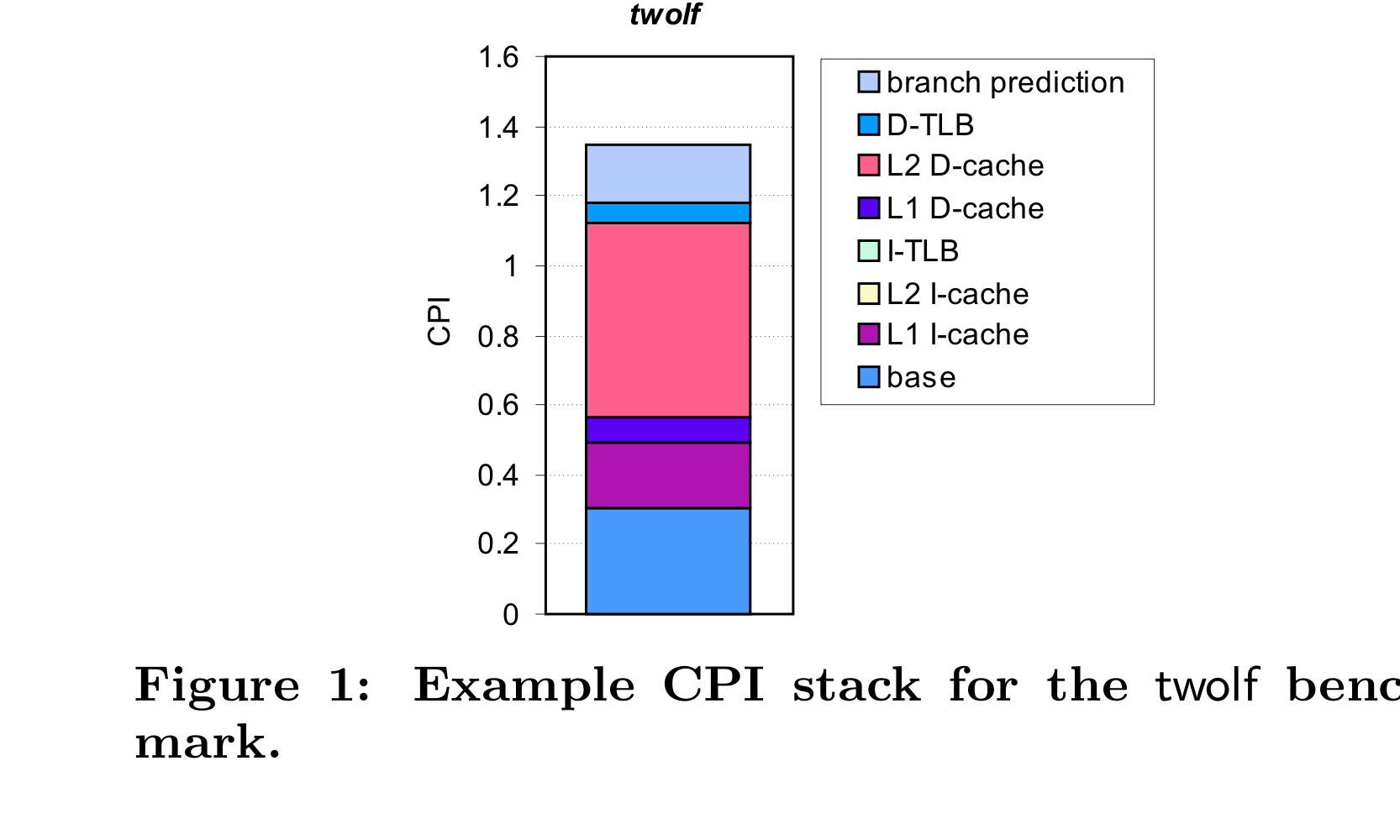
Application 개발자는 위와 같은 표를 보고 SW를 최적화할 수 있다. 예를 들어 CPI stack에서 i-cache miss에 대한 portion이 크다면, instruction locality를 높임으로써 전체 CPI를 최소화할 수 있고, d-cache miss에 대한 portion이 크다면 data layout을 바꾸거나 SW prefetching 을 하여 CPI를 최소화할 수 있다. (Ahmdals Law를 마음에 품고 어떤 부분을 speed up 할지 생각해야 할듯!!)
그러나, SS + OoO processor에서 위와 같은 표를 계산하기는 굉장히 까다롭다. 나이브한 방법의 예시로, L2 miss의 portion을 계산하기 위해 L2 miss횟수와 L2 AMAT을 계산해 곱하는 방법이 있다. = naive approach
이 방법의 문제는 무엇인가? averagy penalty가 프로그램에 따라 달라지며, averagy penalty cycle이 명확하지도 않다. 또한 OoO가 이 다양한 miss event penalty들을 overlap시킴으로써 숨긴다는 중요한 사실을 반영하지 않는다. 예로, 잘 짜여진 OoO 프로세서에서 L1 data cache miss는 상당수 그 penalty hiding이 이루어지고, non-blocking L2 cache에서 mutiple cache miss를 어떻게 처리했는지 생각해봐라! 절대 sequential 하지 않다. 마지막으로, 이 방법은 misprediction으로 인해 flush되어야 할 instruction들의 miss 또한 포함하여 계산한다.
마지막의 문제(misspeculated path의 instruction이 포함된)를 해결하기 위해 Pentium 4의 경우는 instruction completion이 된 경우에만 counter를 업데이트한다. = naive-non-spec approach
IBM PowerPC 5의 경우 이 카운팅을 위한 HW를 만든다. 주어진 사이클 안에 명령어가 completion되었는지 조사하고, 그렇지 않다면 적절한 stall counter를 올려준다. 이러한 방법으로 특정 stall condition에 의해 몇 사이클이나 stall 되었는지 계산할 수 있다. 이런 stall을 발생시키는 원인에는 무엇이 있는가?
- ROB is empty.
- I-cache 혹은 I-TLB miss에 의해 새로운 명령어가 파이프라인에서 ROB로 넘어가지 않는다. 결국 ROB가 drain되다가 텅 비게 된다. POWER5 mechanism의 경우 ROB가 비면 i-cache에 대응하는 counter를 증가시켜 몇 cycle stall되는지 계산한다.
- Branch misprediction에 의해 파이프라인이 flush된 경우이다. PC를 맞는 path로 redirect하고 새로운 instruction을 fetch하여 ROB에 들어가기 까지 시간이 걸리고, 이 사이클을 계산하여 branch misprediction stall counter를 증가시킨다.
- Head of ROB cannot commited for some reason.
- ROB head의 instruction이 d-cache(or D-TLB) miss에 의해 stall당해있는 경우. D-cache completion stall counter 를 증가시킨다.
- Mult, Div 등 여러 pipeline 사이클을 필요로 하는 operation인 경우. long-latency completion stall counter를 증가시킨다.
지금까지 논의된 naive, naive-non-spec, 보다 복잡한 POWER5의 approach 모두 bottom-up approach이다. 그러나 CPI stack을 계산하기 위한 방법으로 이것들은 적절하지 않다.
3. Underlying Performance Model
지금까지 논의된 방법론들의 허점을 보완하기 위해 ‘interval analysis’라는 top-down approach를 소개한다.
Execution time이 disruptive miss events를 기준으로 discrete interval들로 나뉜다. 각 interval의 타입으로 processor의 행동과 성능을 결정하고 이렇게 모인 interval들을 aggregate하여 전체 퍼포먼스를 추정한다.
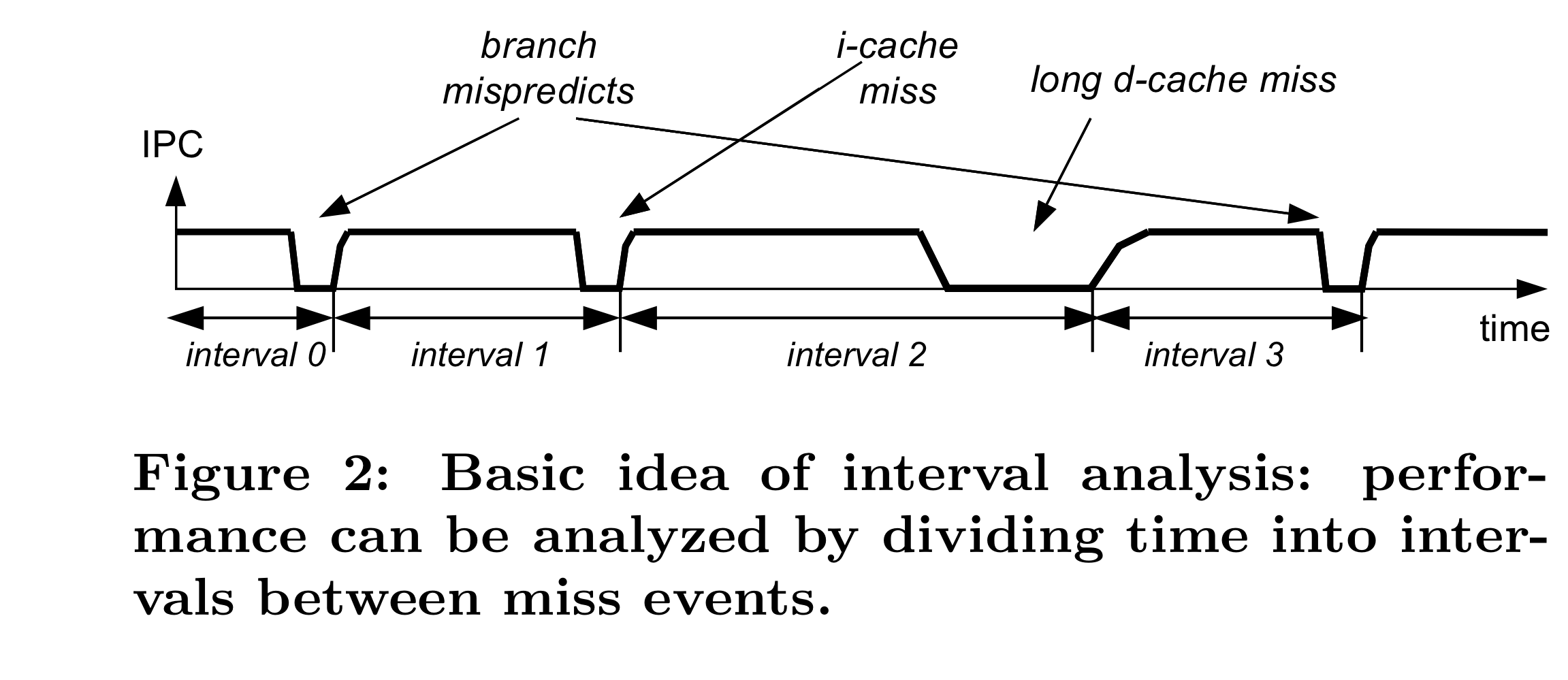
Interval 을 정확히 정의하면, 위의 그림에서와 같이 이전의 miss event로부터 회복하여 useful instruction을 issue하기 시작한 시점으로부터, 그 다음의 miss event가 일어나기까지의 시간이다. 본문에선 frontend miss event(i-cache, i-TLB, branch misprediction)과 backend miss event(L1 d-cache, L2 d-cache, d-TLB)를 나누어 설명한다.
Frontend misses
- Instruction cache and TLB misses
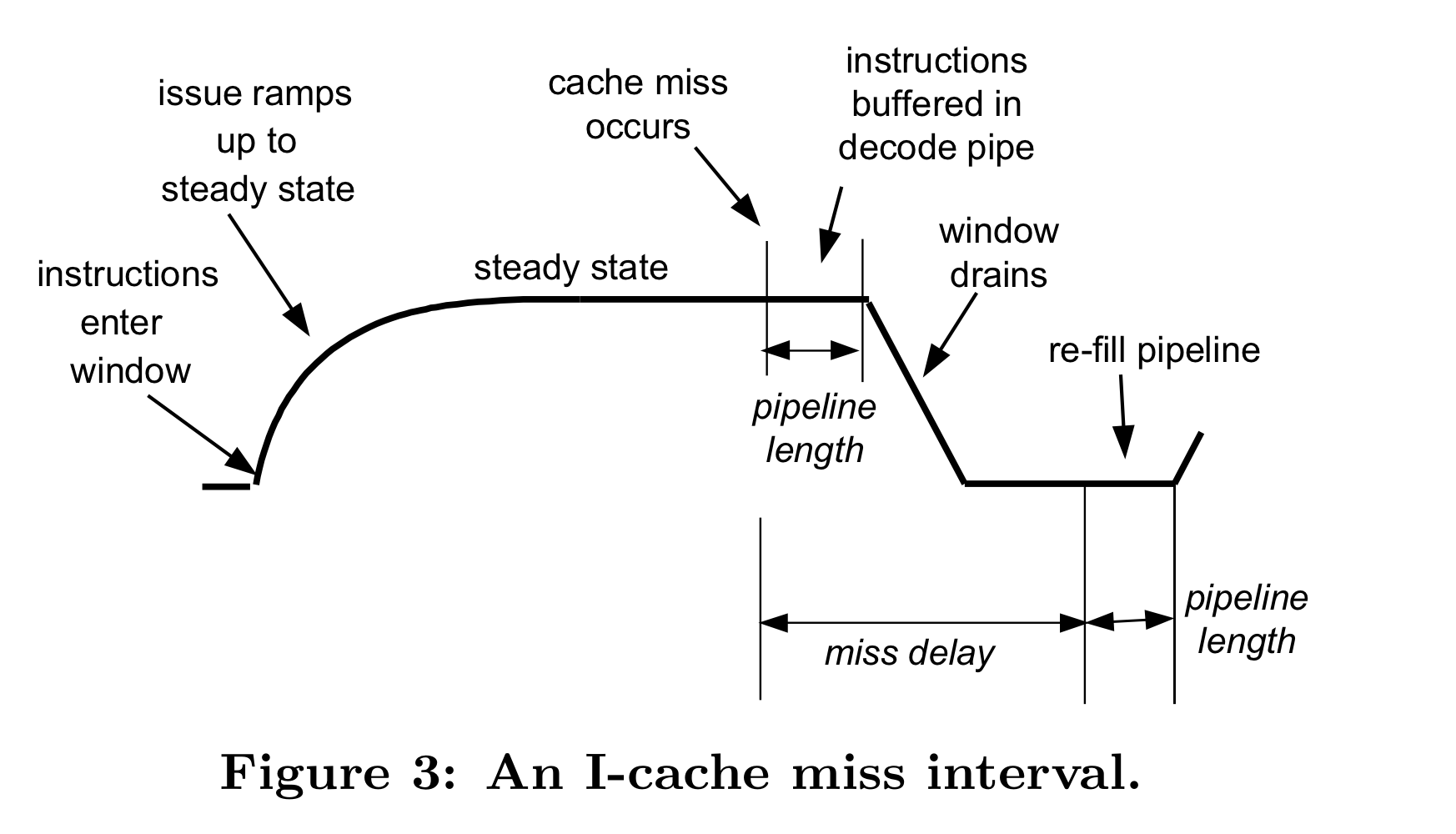
전형적인 i-cache miss에 대한 interval의 모습은 위와 같다.(i-TLB의 경우도 유사)
위 figure의 instruction buffered in decode pipe와 L2 cache로부터 line을 받아 다시 frontend pipeline을 채우는 cycle (re-fill pipeline) 이 일치하기 때문에 전체 penalty는 L1 miss delay와 같다.
POWER5 mechnism의 경우 이 페널티를 ROB가 empty가 되었을 때부터 계산한다. (ROB가 drain되는 시간 - 위 figure의 음의 기울기 영역 - 을 페널티에서 빼고 계산) 따라서 POWER5의 경우 i-cache miss penalty를 significantly underestimate한다. 심지어 ROB에서 drain되는 시간이 L1 refill시간보다 크면 i-cache miss가 발생해도 이를 캐치하지 못한다. (ROB에서 drain 되는 시간이 길다? → low ILP or convoy effect by long-latency operations)
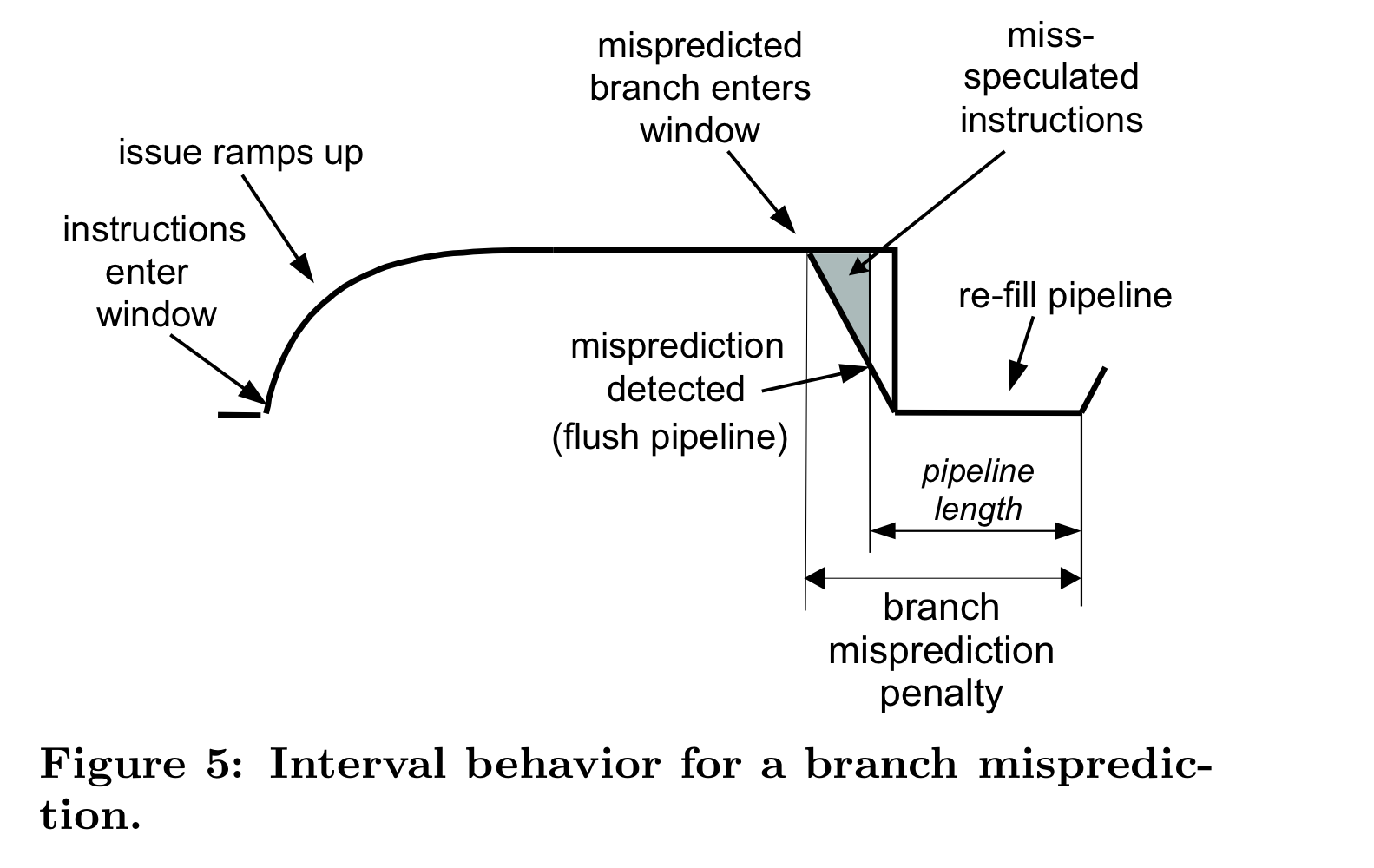
- Branch misprediction
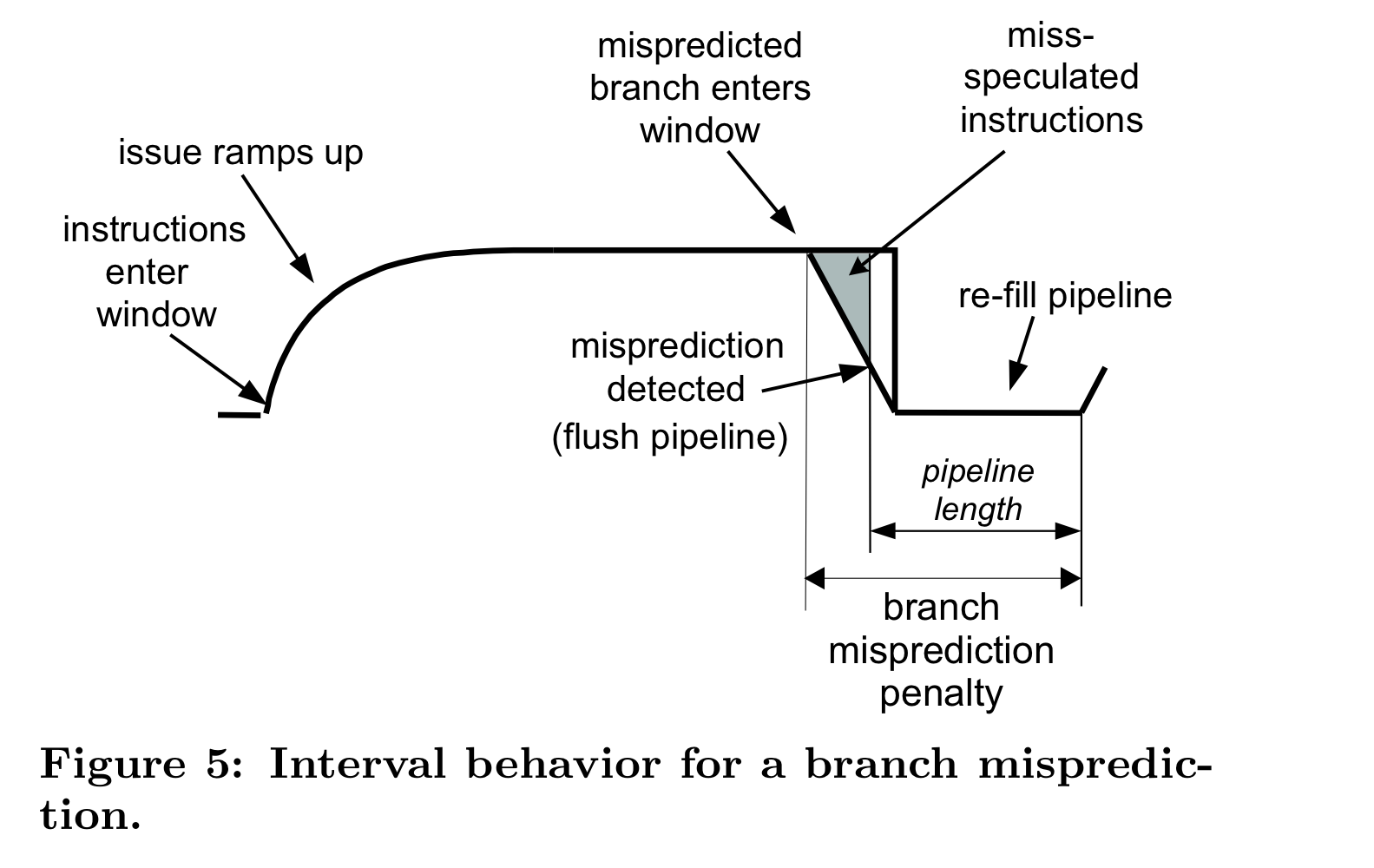
위의 그림을 보면, branch misprediction penalty는 mispredicted branch가 execution window를 들어간 순간부터, correct path의 instruction으로 redirect하여 이가 execution window로 들어가기까지의 시간임을 알 수 있다. (i.e. branch resolution time + frontend pipeline length)
cf. window of execution
여기서, HW가 mispredicted branch가 언제 들어갔는지 알아야, 이 시간을 tracking할 수 있다. 그러나 현존하는 아키텍쳐에는 이런 기능이 없기에, naive approach 및 POWER5 method 모두 branch misprediction penalty를 significantly underestimate한다.
Backend misses
- Short misses (L1 d-cache misses)
L1 d-cache miss의 경우 zero-issue region을 보통 만들어내지 않는다. Well-designed OoO processor라면 이정도의 memory latency hiding이 가능케 한다. (그동안 다른 independent한 OoO execution이 일어나는중일 것 → long latency operation과 비슷하게 행동할 뿐이 된다)
- Long misses (L2 d-cache misses & D-TLB misses)
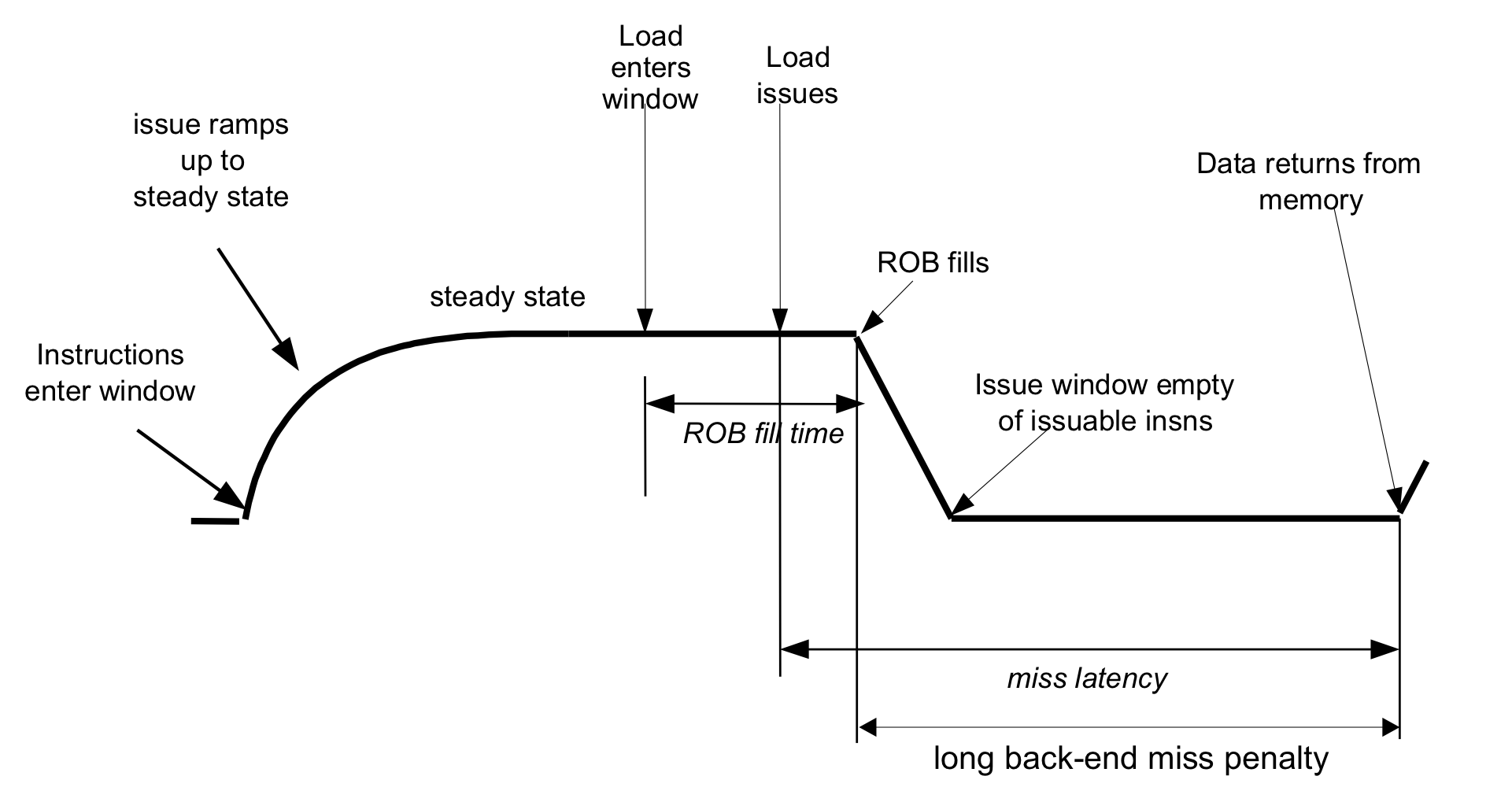
L2 miss가 발생해서 L3에서 line을 가져와야 하는 경우, 수백 사이클 정도가 소요되기 때문에, ROB head가 해당 메모리 명령어인 채로 ROB가 곽차게 될 것이다. 이에 따라 결국 commit 및 issue모두가 멈추게 된다. 이때 총 penalty는 ROB가 꽉차는 순간부터 data를 받아와서 다시 commit-issue가 시작되는 순간까지이다.
같은 ROB안에 들어오는 수준(혹은 같은 window size내로 들어오는 정도의) 연속한 long-misses가 발생하면, 그 페널티의 대부분이 overlap될 것이기 때문에 additional penalty가 발생하지 않는다.
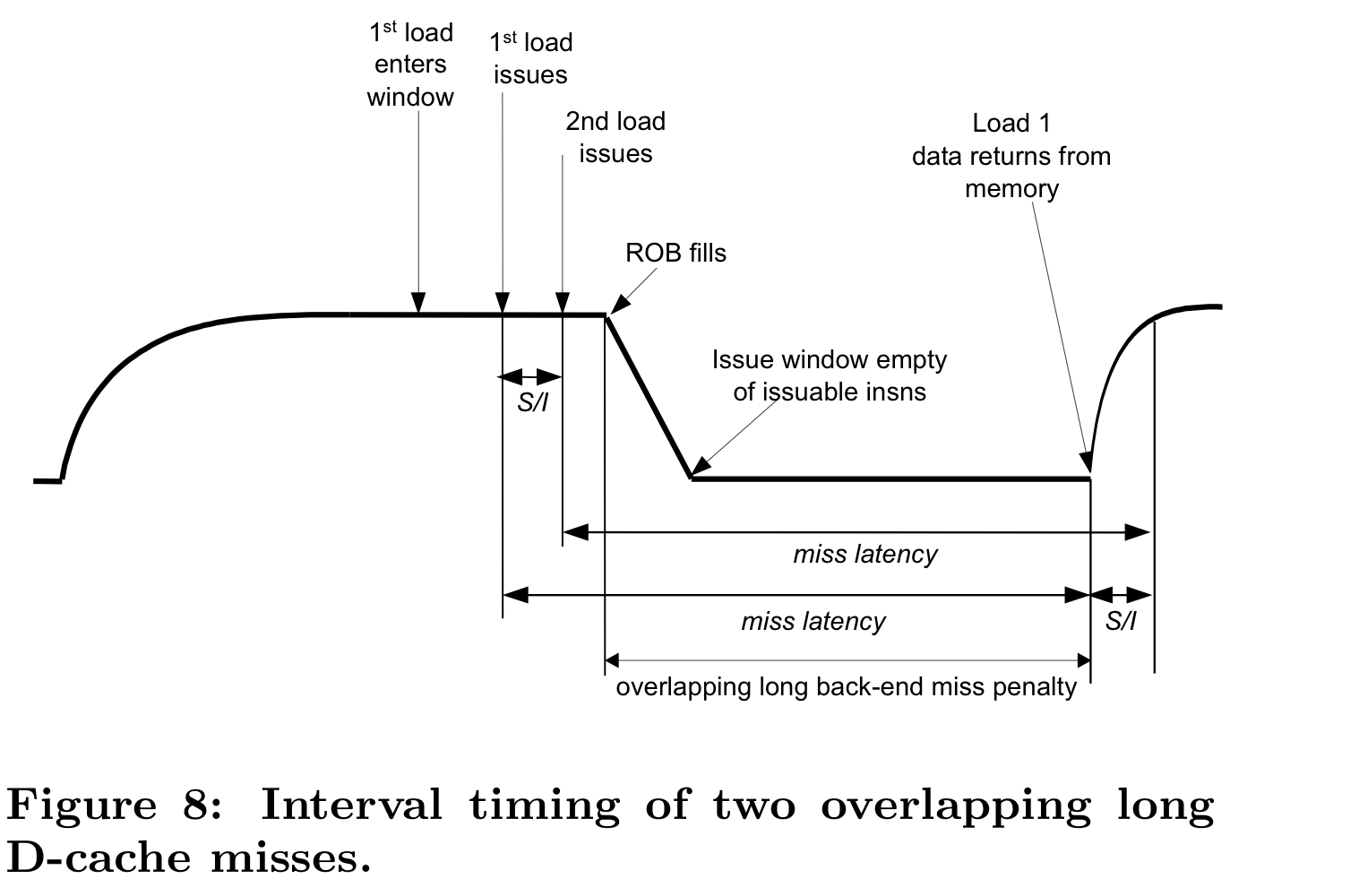
위의 figure은 첫번째 load/store miss(최소 L2 miss) 가 발생한 이후 S개의 instruction 이후 또다른 load/store miss 가 발생함을 가정하였는데, 이때 S는 miss penalty에 영향을 주는 변수가 아님을 주목하라! S가 같은 ROB안에 들어올 정도로 작으면 이 스토리는 완성된다. 또 몇 개의 miss가 발생하던지 첫번째 miss 명령어와의 거리만이 중요하다는 점을 이해해야 한다.
POWER5 method가 좋은 approximation을 줌과 다르게, naive approach의 경우 overlapping을 생각하지 못하고 단순히 횟수와 latency를 곱해 버리기에, overestimate함을 확인 할 수 있다.
Interactions between miss events
- Between frontend miss events
대부분의 경우 penalty가 overlap되지 않는다. 한 가지 생각해야 할 것은, misspeculative path의 i-cache miss를 count하면 안된다는 점이다. 지금까지 논의된 방법(naive, naive-non-spec, POWER5, ours)중 이를 페널티에 포함하는 방법론은 naive-approach뿐이다.
- Between frontend and long backend miss events
이 경우는 더욱 복잡하다. backend miss와 frontend miss가 함께 발생할 수 있기 때문이다. 그렇다면, 둘 중 무엇에 집중해야 하는가? 이 질문에 답하기 위해 두 종류의 miss가 동시에 발생한 때의 fraction of the total cycle을 측정하였다.
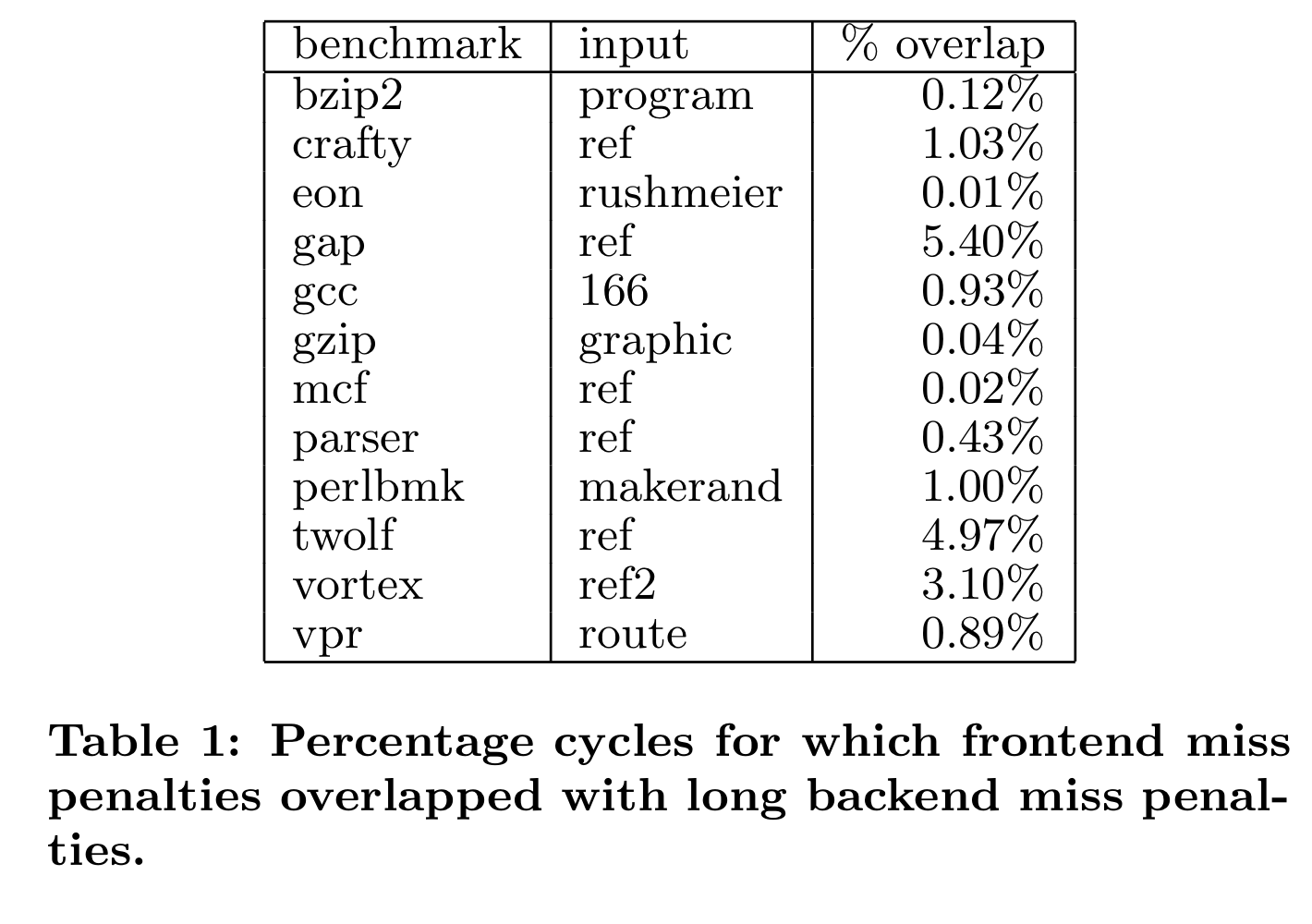
그 portion이 매우 작음을 확인되기에, CPI stack을 계산하기 위해 둘 중 어떤 방법을 사용하여도 꽤나 정확할 것이라는 생각이 든다. 따라서 본 논문에선 겹치는 경우 frontend CPI component로 계산하기로 선택하였다.(ROB가 꽉 차지 않는다면 - ROB가 꽉 차면 long backend miss events로 계산된다)
4. Counter Architecture
HW performance counter는 다음과 같이 구성되어 있다.
1개의 total cycle counter + 8개의 global CPI component cycle counters(각각 L1 i-cache miss, L2 i-cache miss, i-TLB miss, L1 d-cache miss, L2 d-cache miss, d-TLB miss, branch misprediction, stall by long latency operation을 잰다)
위 카운터들의 구성에 의해
임을 쉽게 알 수 있다. steady state는 peak issue를 내고 있는 상황이었음을 기억하자.
그렇다면 이 8가지 종류의 global CPI component를 계산하는 HW방법은 무엇일까.
Frontend misses initial design : FMT
Frontend miss event table(FMT) 라고 하는 HW table을 제안한다. 이는 여러 행을 가지는 circular buffer로 구현된다.
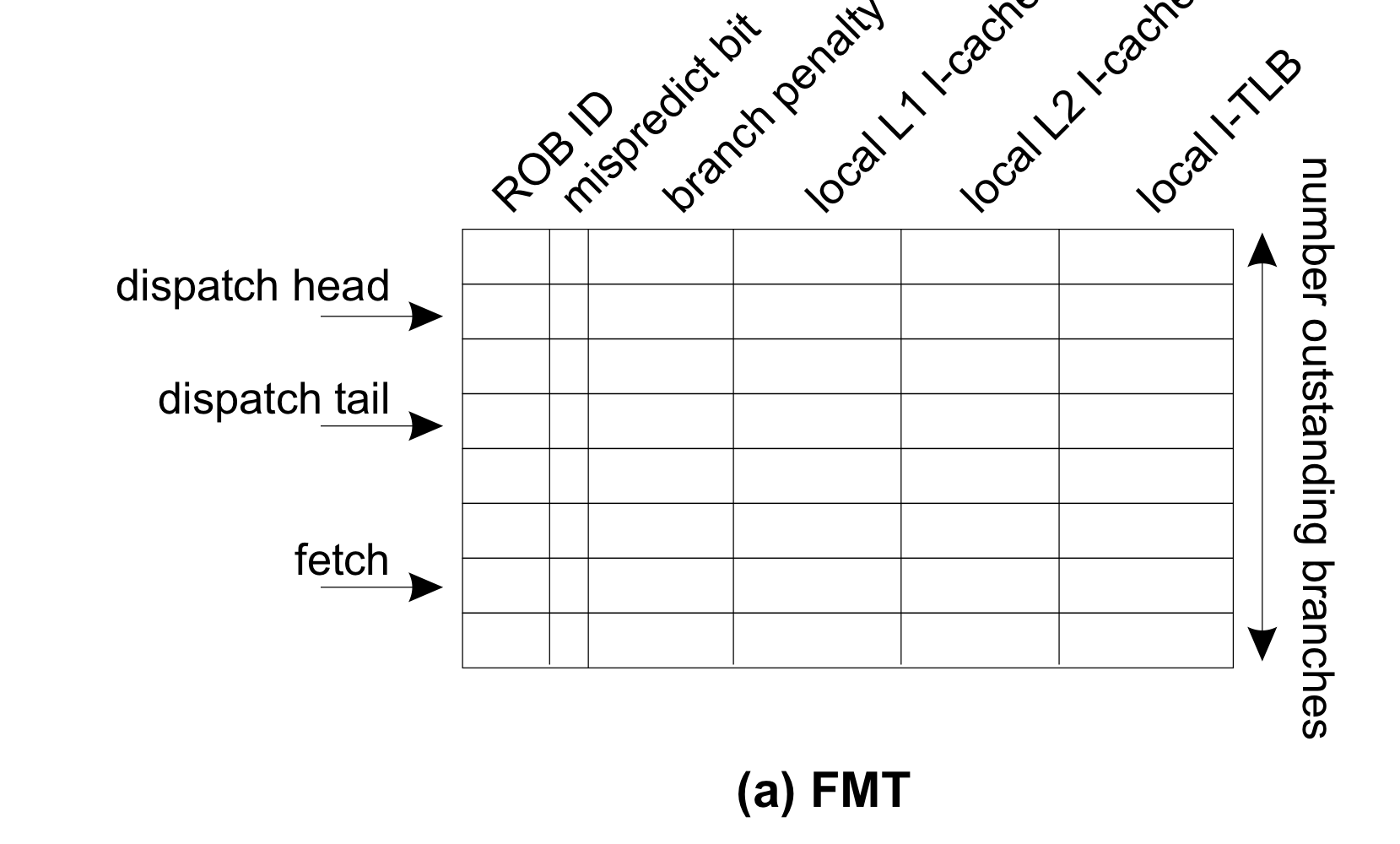
FMT의 fetch pointer, dispatch tail pointer, dispatch head pointer는 각각 branch fetched & decoded, branch dispatched, branch commited의 시점에 한 칸씩 전진한다. 해당 branch가 들어간 ROB ID를 FMT에 적어 주고, 이후 misprediction일 경우 이를 tagging함으로써 mispredict bit를 켜준다. frontend miss event penalties는 다음과 같이 계산된다. L1, L2 i-cache miss 또는 i-TLB miss에 의해 파이프라인으로 새로운 명령어가 들어가지 못하고 있다면 적절한 local counter in FMT entry(pointed by fetch pointer)를 증가시킨다. 그렇게 되면 interval analysis를 위한 penalty cycle만큼이 계산된다. 왜 그런지 위로 돌아가 천천히 생각해보자…
branch의 경우, misprediction branch instruction이 ROB에 들어온 순간부터 correct path로 redirect해서 알맞은 instruction들이 execution window로 들어오기까지가 페널티였다는것을 생각해라. FMT의 branch penalty는 해당 명령어가 ROB에 들어가자마자 incrementing을 시작하고(이에 따라 dispatch tail과 head 사이에 있는 FMT entry의 branch penalty counter는 계속 증가중일 것이다. ㅇㅈ?) commit될때까지 counting된다.
이렇게 계산된 local counter들은 branch instruction이 커밋될 때 global counter에 누적되어 들어가게 된다.
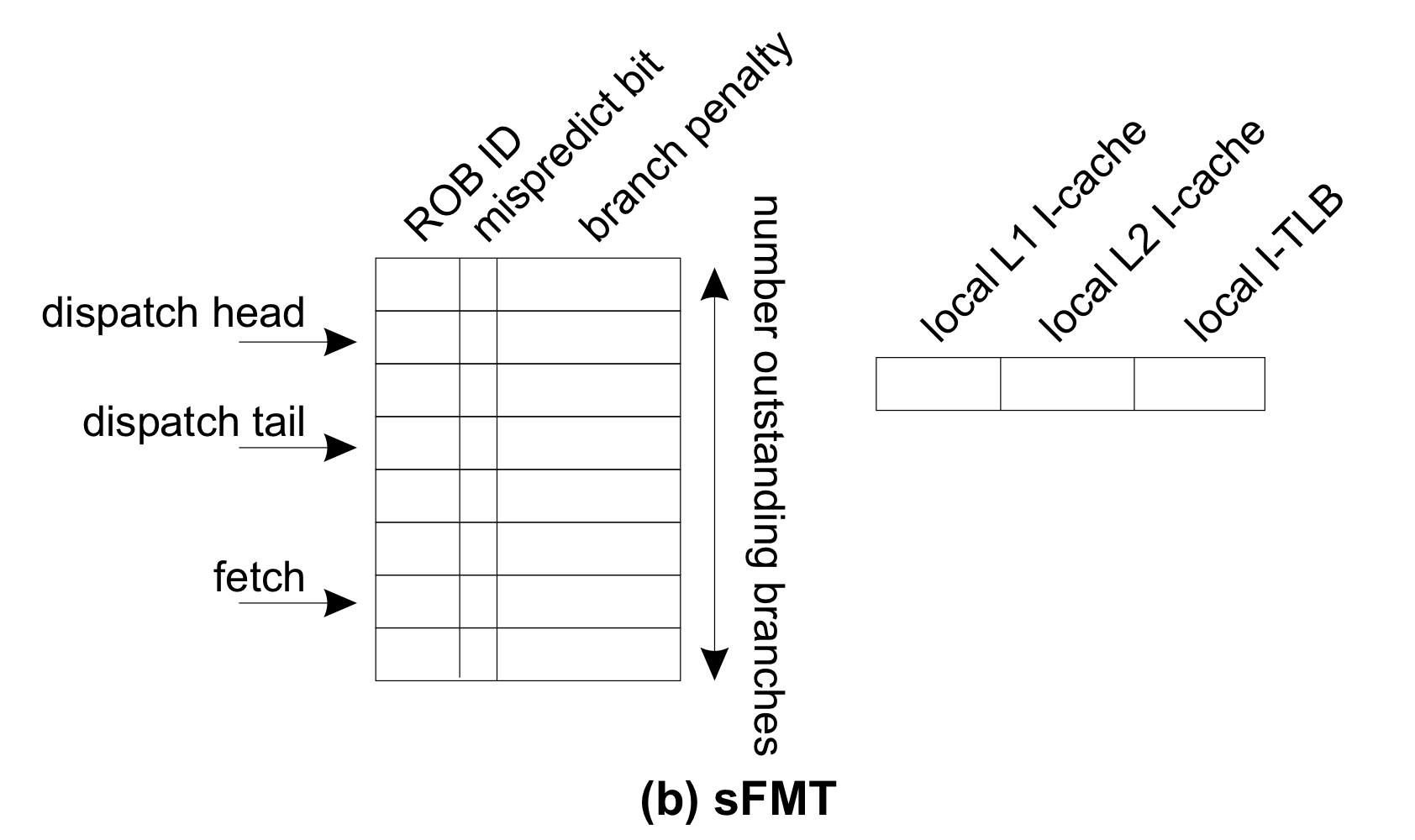
위의 FMT 방식에선, fetch poinet가 가리키는 중인 entry의 local counter에 i-cache miss나 i-TLB miss cycle들을 기록하는데, 이를 통해 misspeculative path에서의 miss cycle을 카운팅하지 않고 잘 솎아낸다. 그러나 이렇게 per branch별로 counter들을 가지지 않고 하나의 shared local counter를 가지면 어떻게 될까? (위의 sFMT그림 참조) HW cost를 아낄 수 있을 것으로 보인다. 5252 그런데 그렇게하면 방금 말한 misspeculative path에서 miss event cycle을 세지 않고 잘 걸러낸다는 장점이 사라져버린다구! 하지만 괜찮다 왜와이? i-cache miss와 branch misprediction은 보통 bursts로 일어나기 때문에 앞서 말한 misspeculative path에서의 cycle increment가 일어나는 시나리오는 매우 드물다. 아래의 ‘evaluation’에서 FMT와 sFMT의 error를 확인해서 그 사실을 확인해보자.
Long Backend misses
d-cache miss 혹은 d-TLB miss에 의해 손실되는 cycle을 계산하는 것은 비교적 ez하다. ROB가 꽉찼는지 확인하고 blocking의 원인이 L2 d-cache miss, d-TLB miss일때 각각에 해당하는 카운터를 증가시키면 된다.
Long latency unit stalls
ROB의 head가 commit되지 못하고 blocking되어있는 상황에서, L1 d-cache miss에 의한 것이 아니라면 long latency instruction에 의한 것이다.
5. Evaluation
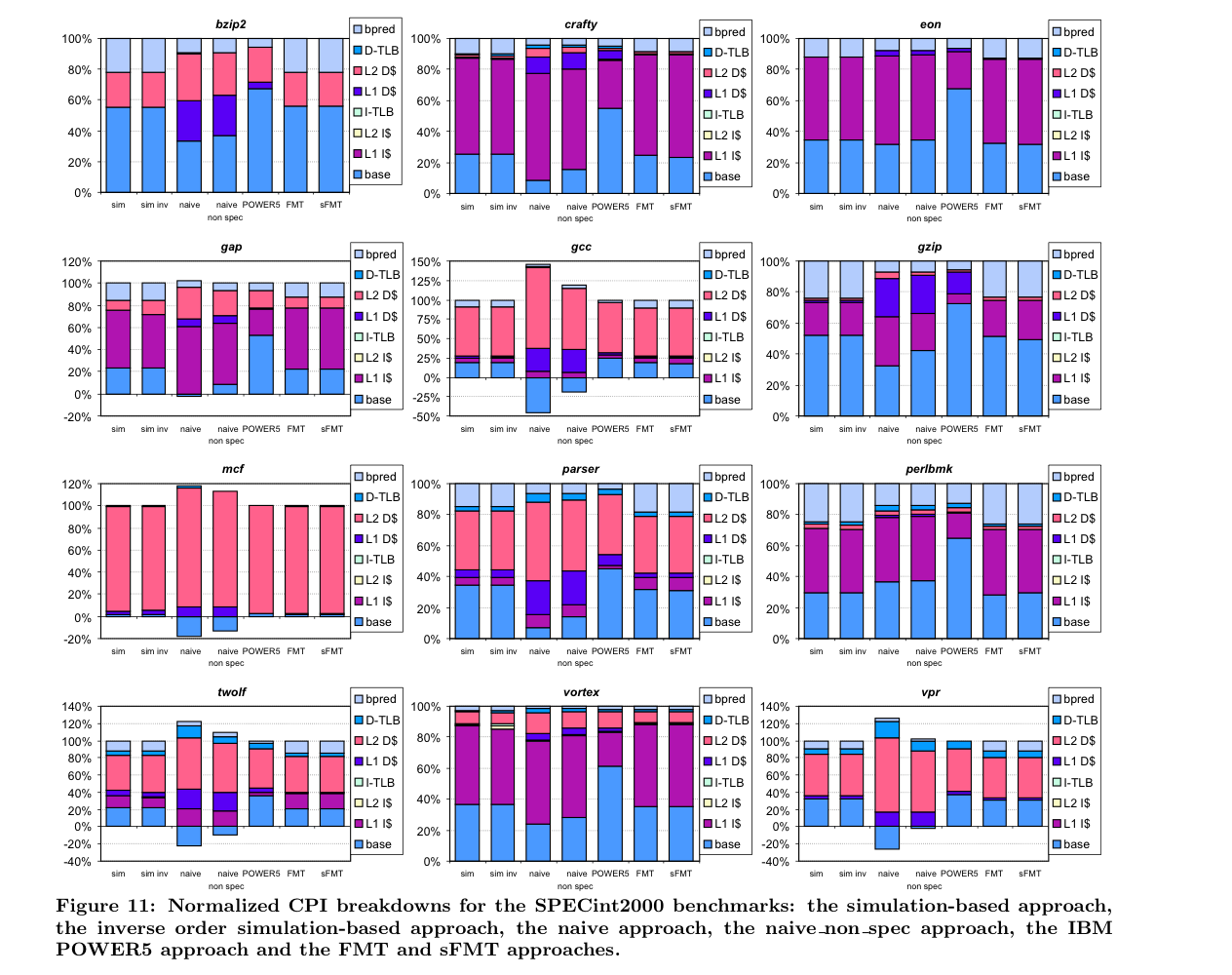
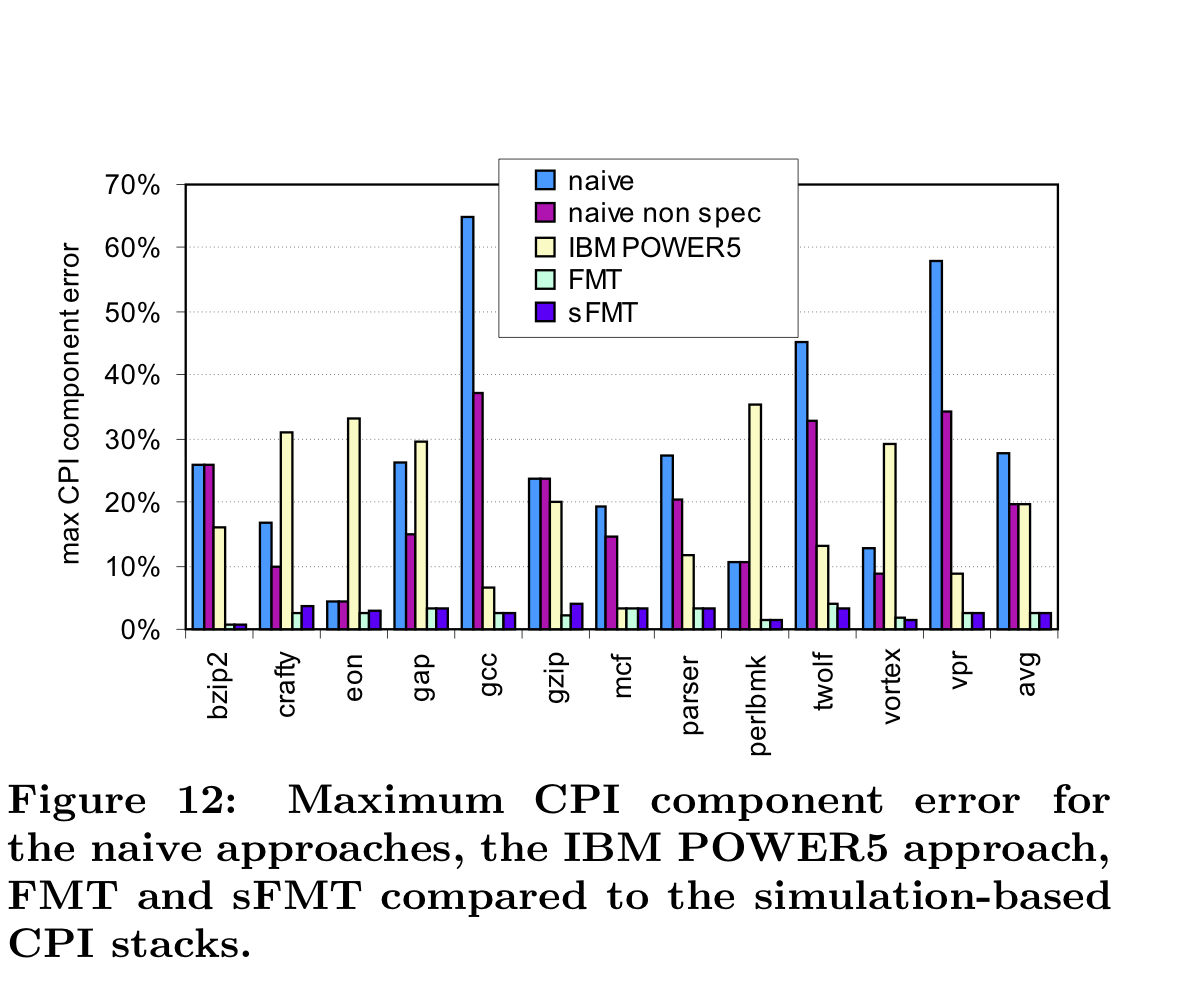
6. Related Works
7. Conclusion
