Intro
- Google Cloud Storage에서 데이터를 읽어와 처리하는 실습을 진행해보겠습니다.
- textfile파일을 읽을때 infer_schema 기능을 사용하지 않고 명시적으로 schema를 적어보겠습니다.
- streamData를 처리하는 실습을 진행해 보겠습니다.
- 사용하는 데이터는 ml-1m 데이터와 log data 입니다.
Contents
Data with Schema

- StructType을 통해 미리 schema를 작성하여 movie데이터의 type을 정할 수 있습니다.
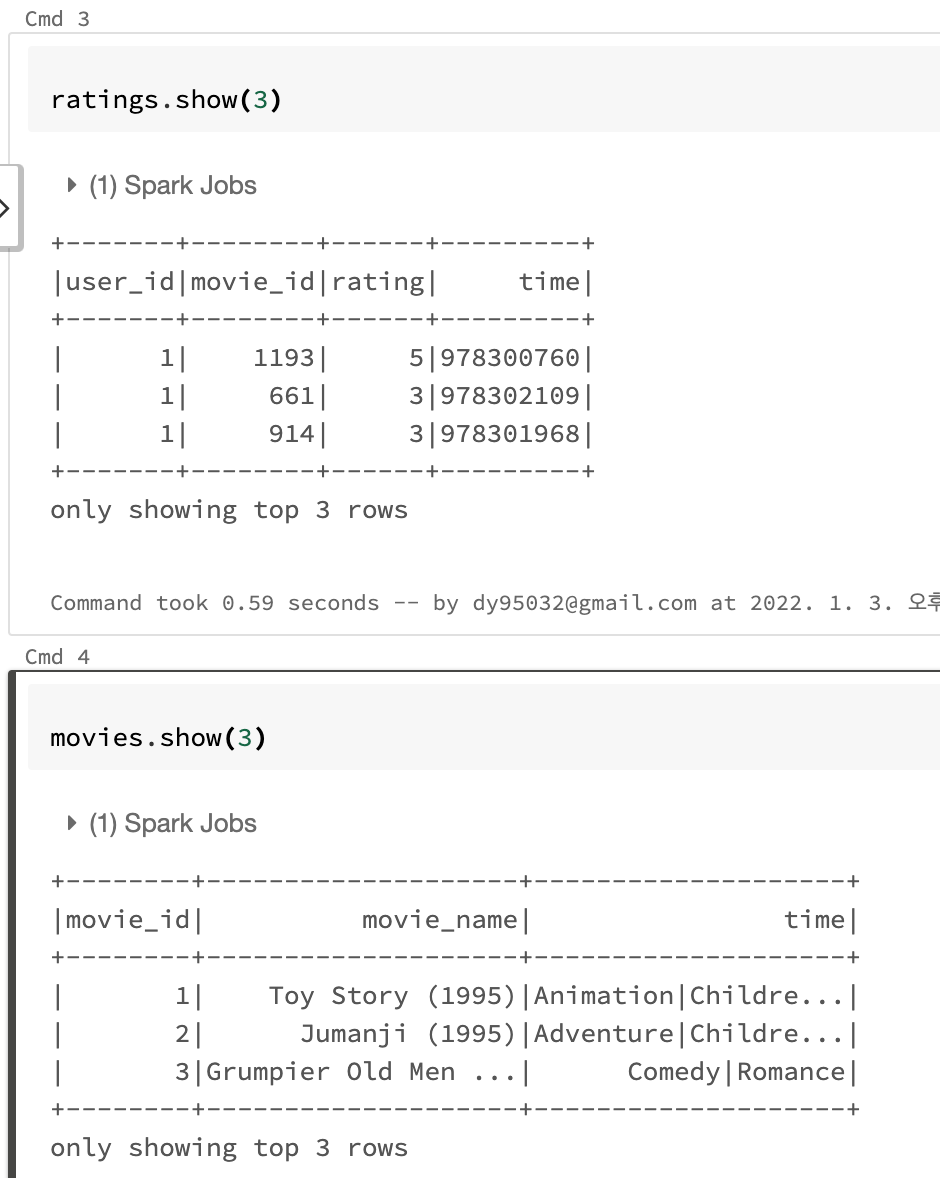
- show()를 호출하면 위와 같은 결과를 얻을 수 있습니다.
Spark에서는 show와 같은 action이 호출되어야 그전의 transform들이 실행이 됩니다. 작성한 즉시 실행되는것이 아닙니다.
StreamData
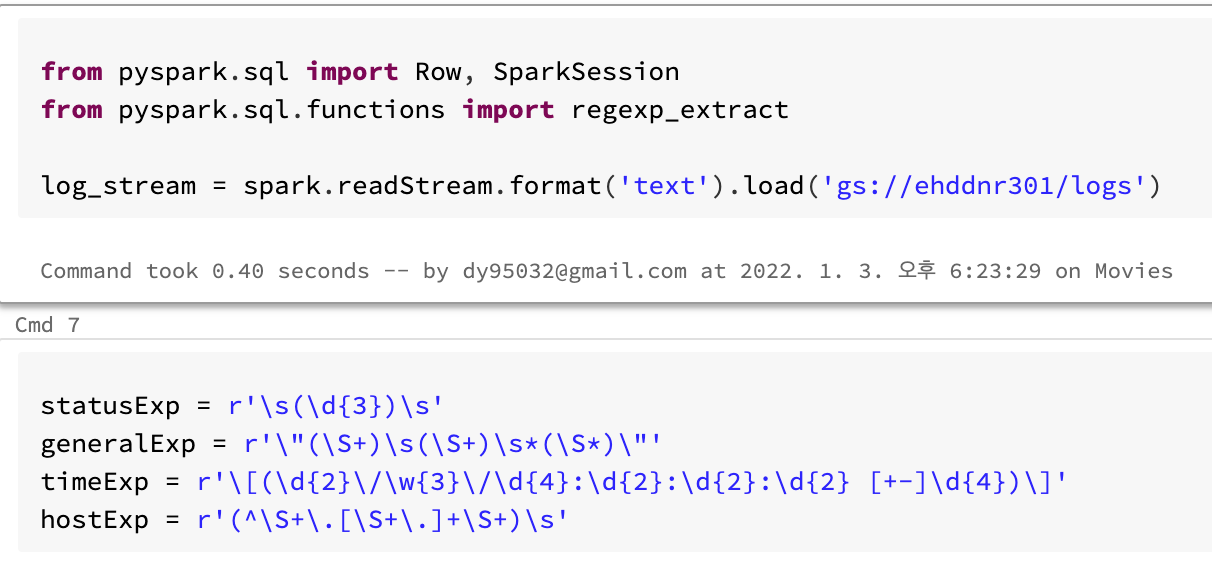
- ehddnr301이름의 bucket에 logs라는 폴더안의 text파일들을 readStream 합니다.
- 해당 폴더안에는 다운받은 kaggle log file을
head -100000 access.log > log_file.txt를 통해 10만 row만 뺀 txt 파일을 업로드 해둡니다.
31.56.96.51 - - [22/Jan/2019:03:56:16 +0330] "GET /image/61474/productModel/200x200 HTTP/1.1" 200 5379 "https://www.zanbil.ir/m/filter/b113" "Mozilla/5.0 (Linux; Android 6.0; ALE-L21 Build/HuaweiALE-L21) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.158 Mobile Safari/537.36" "-"- 간단한 regexp 설명
- statusExp: 공백 사이에 숫자 세개가 연속됨
- status_code를 의미함 위 예시에서
200
- status_code를 의미함 위 예시에서
- generalExp: "" 사이 3가지 경우
- 공백이 아닌 무엇인가의 연속, 위 예시에서
GET - 공백이 아닌 무엇인가의 연속, 위 예시에서
/image/61474/productModel/200x200 - 공백이 아닌 무엇인가의 연속, 위 예시에서
HTTP/1.1
- 공백이 아닌 무엇인가의 연속, 위 예시에서
- timeExp: [] 사이의 숫자, 문자 연속갯수 지정
- 위 예시에서
[22/Jan/2019:03:56:16 +0330]
- 위 예시에서
- hostExp: 라인의 처음에서 공백이아닌문자.공백이아닌문자,,,, 로 검출
- 위 예시에서
(^\S+\.[\S+\.]+\S+)\s
- 위 예시에서
- statusExp: 공백 사이에 숫자 세개가 연속됨
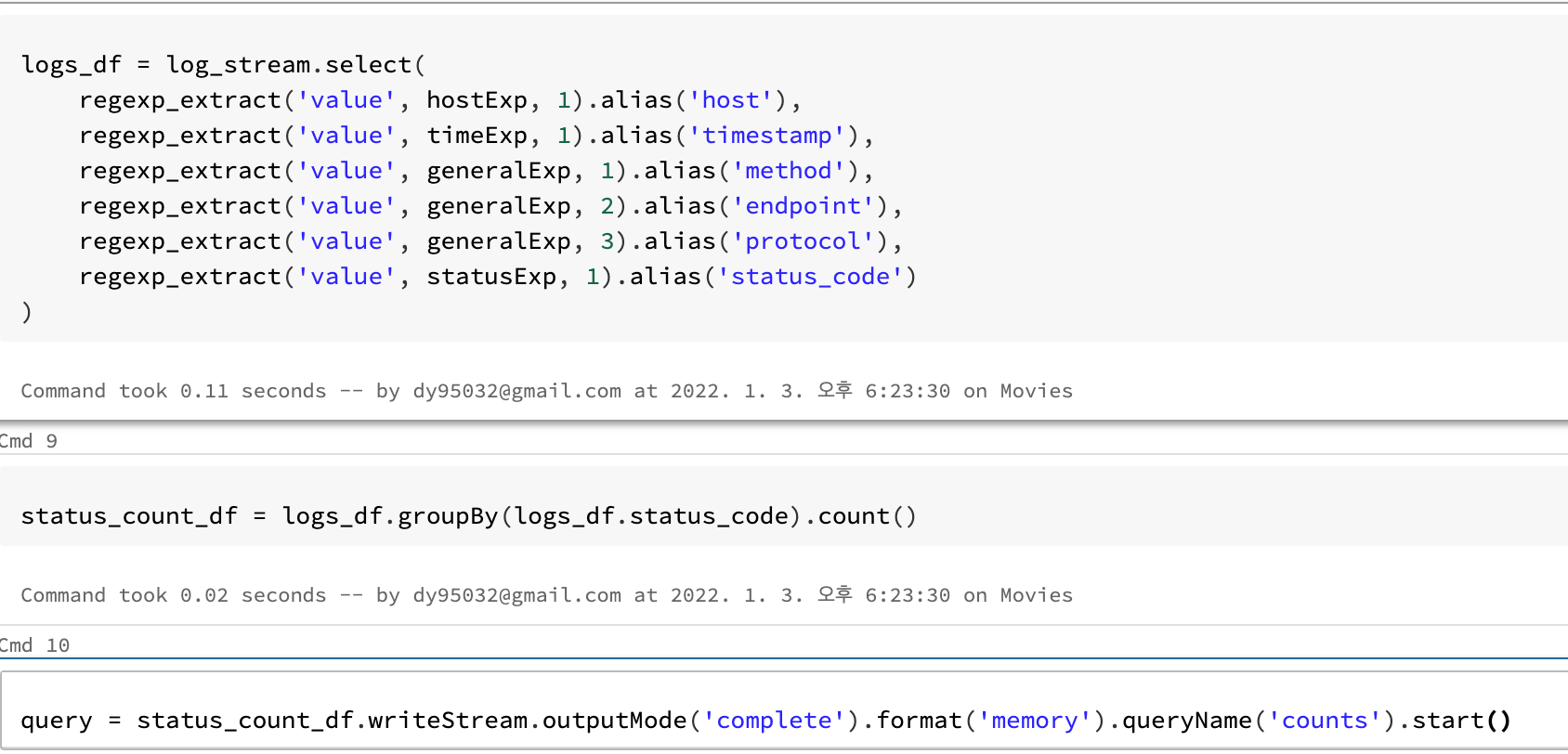
- regexp_extract로 regexp으로 검출해서 alias를 통해 column화 시키는듯 합니다.
- readStream으로 읽어서 해당경로에 추가되는것이 있으면 writeStream 하는 코드입니다.
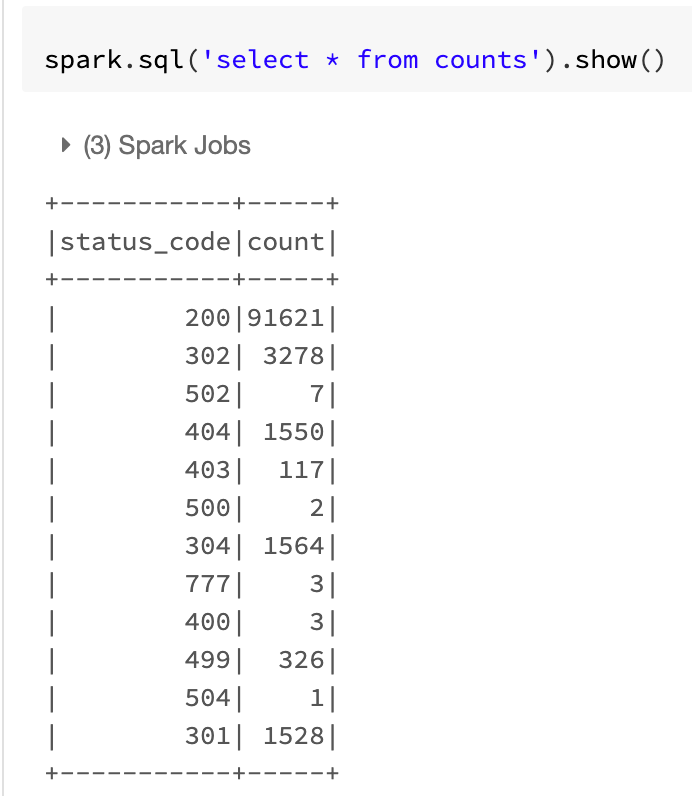
- 처음엔 200 status_code 인 것이 91621개인것을 볼 수 있습니다.
- 해당 폴더에
tail -n 100000 access.log > log_file2.txt를 통해 생성한 파일을 한번 더 업로드 할 경우 아래와 같이 progress bar가 다시 업데이트 됩니다.

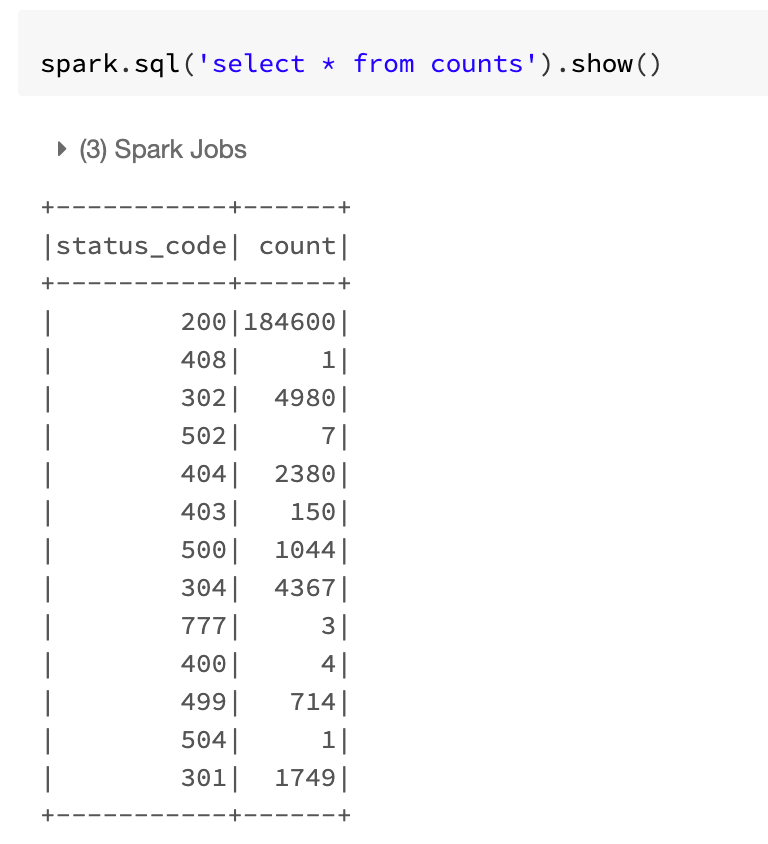
- 다시 progress 가 완료되면 위와 같이 갯수가 업데이트 된 모습을 볼 수 있습니다.
Outro

- StreamData를 처리하는 실습을 해보았습니다.
- 추후에 google bigquery에 업데이트 하는 실습을 진행해보겠습니다.

공부해서 남주자