postgres, elasticsearch 검색 테스트 like, keyword기반 검색 테스트
문득 데이터베이스를 공부하다가 실제로 얼마나 유의미하게 검색기능이 차이가 나는지 궁금하기도 해서 성능을 비교해보고자 한다.
데이터베이스는 두 가지로 postgresql과 elasticsearch(opensearch)로 하고자 한다.
두 데이터베이스의 비교를 위해 같은 cpu, memory 환경의 호스트에서 진행했으며 도커 컴포즈로 postgres 레플리카 세개와 opensearch도 클러스터링 하여 노드 세개로 진행하였다. (이렇게 진행한다해서 완벽히 같은 리소스를 요구하진 않지만 그래도 맞춰주는 것이 좋다 생각했다.)
그렇다면 검색 성능에서 주로 보이는 ELK 스택에서의 elasticsearch의 검색기능이 얼마나 차이가 나는지 대충 비교해보자면,
Elasticsearch
- 데이터 저장방식은 Nosql으로 검색방식은 역색인 방식을 따른다. 여기서 역색인의 특징을 알아보자. 쉽게 이해하자면, 먼저 우리가 사전을 검색할 때, 보통은 맨앞자리 목차를 펼쳐보고 해당하는 내용을 찾는데, 역색인은 이 과정을 반대로 한다고 생각하면된다. 특정키워드를 기준으로 먼저 검색을 한다고 생각하면 이해가 쉬울 것 같다.
그렇다면 postgres 혹은 mysql같은 rdb에서는 keyword 검색할 때, Like %keyword%를 쓰는 경우가 많은데 이러한 기능을 쓰면 full table scan으로 인해 데이터가 많으면 많을 수록 많은 테이블들을 스캔하기때문에 성능이 저하되기도 한다.
테스트
- 총 10만개의 데이터 영어 기사를 csv 파일로 만들었다. TITLE,과 CONTENT밖에 없는 간단한 데이터지만 총 10만개를 만들었다. (이후 한글 검색도 테스트를 해야하고, 추가적인 필드를 만들어야하는거 아닌가 했지만 사실 순전히 얼마나 차이가 나는지 궁금했기때문에 테스트는 간략하게 진행했다.)
elasticsearch는 _bulk로 데이터를 넣으면 훨씬 빨리 넣을 수 있다.
추가적으로 깔려있는 것이 OPENSEARCH이기때문에 테스트는 opensearch로 진행했다.
const fs = require("fs");
const csv = require('fast-csv');
const {Client : ElasticClient } = require("@opensearch-project/opensearch");
const CSV_FILE_PATH = "./10_________________.csv";
const esClient = new ElasticClient({
node: "https://호스트:9200",
auth: {
username: "사용자 계정",
password: '패스워드'
},
ssl: {
rejectUnauthorized: false,
},
});
async function pushElasticSearch(){
let count = 0;
const stream = fs.createReadStream(CSV_FILE_PATH).pipe(csv.parse({ headers: true }));
for await (const row of stream) {
const { title, content } = row;
// OpenSearch 삽입
await esClient.index({
index: "articles",
body: { title, content },
});
count++;
if (count % 1000 === 0) console.log(`Inserted ${count} records...`);
}
console.log(" 데이터 삽입 완료!");
}
pushElasticSearch().catch(console.error)
const fs = require("fs");
const csv = require("fast-csv");
const { Client } = require("pg");
const CSV_FILE_PATH = "./10_________________.csv";
const pgClient = new Client({
user: "계정",
host: "호스트",
database: "데이터베이스",
password: "비밀번호",
port: 5432,
});
async function pushPostgres() {
try {
await pgClient.connect();
console.log(" PostgreSQL 연결 성공!");
await pgClient.query(`
CREATE TABLE IF NOT EXISTS articles (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT
);
`);
console.log(" 테이블 생성 완료!");
let count = 0;
const stream = fs
.createReadStream(CSV_FILE_PATH)
.pipe(csv.parse({ headers: true }));
for await (const row of stream) {
const { title, content } = row;
await pgClient.query("INSERT INTO articles (title, content) VALUES ($1, $2)", [title, content]);
count++;
if (count % 1000 === 0) console.log(`Inserted ${count} records...`);
}
console.log(" 모든 데이터 삽입 완료!");
} catch (error) {
console.error(" PostgreSQL 오류 발생:", error);
} finally {
await pgClient.end();
console.log(" PostgreSQL 연결 종료");
}
}
pushPostgres().catch(console.error);
테스트 코드
const { Client } = require("pg");
const { Client : ElasticClient} = require("@opensearch-project/opensearch");
const pgClient = new Client({
user: "계정",
host: "호스트",
database: "데이터베이스",
password: "비밀번호",
port: 5432,
});
const esClient = new ElasticClient({
node: "https://호스트:9200",
auth: {
username: "사용자 계정",
password: '패스워드'
},
ssl: {
rejectUnauthorized: false,
},
});
async function searchPostgresILike(keyword) {
try {
await pgClient.connect();
console.log(" PostgreSQL 연결 성공!");
const start = Date.now();
const res = await pgClient.query("SELECT * FROM articles WHERE content ILIKE $1", [`%${keyword}%`]);
const duration = Date.now() - start;
console.log(` PostgreSQL ILIKE 검색 (${keyword}): ${res.rowCount}개 결과, ${duration}ms`);
return duration;
} catch (error) {
console.error(" PostgreSQL 검색 오류:", error);
} finally {
await pgClient.end();
console.log(" PostgreSQL 연결 종료");
}
}
async function searchElasticsearchWildcard(keyword) {
try {
const start = Date.now();
const res = await esClient.search({
index: "articles",
body: {
query: {
wildcard: {
content: {
value: `*${keyword}*`,
case_insensitive: true // 대소문자 구분 없음
}
}
}
}
});
const duration = Date.now() - start;
console.log(` Elasticsearch wildcard 검색 (${keyword}): ${res.body.hits.total.value}개 결과, ${duration}ms`);
return duration;
} catch (error) {
console.error(" Elasticsearch 검색 오류:", error);
}
}
searchElasticsearchWildcard("single");
searchPostgresILike("single");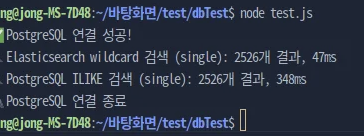
- 총 10만개중 해당 2526개의 데이터를 검색하는 응답시간은 위와 같았다.
- 약 8배 정도의 응답 차이가 나는데, 그렇다면, full table scan 방식말고 해당 검색에 인덱스를 걸면 어떻게 얼마나 차이나는지 궁금해졌다.
postgres gin index, pg_trgm
-
pg_trgm확장기능을 사용하면, gin index를 사용하면 빠른 검색을 할 수 있다.
-
해당 인덱스를 적용하면 index 스캔을 사용한다.
-
pg_trgm을 사용하면, 문자 단위의 검색을 사용할 수 있기 때문에 속도가 향상된다.
-
정확한 단어가 아니더라도 검색이 가능하고, 짧은 단어에 유리하다.
-- 1. 확장 기능 활성화
CREATE EXTENSION IF NOT EXISTS pg_trgm;
-- 2. GIN 인덱스 생성
CREATE INDEX idx_articles_content_trgm ON articles USING GIN (content gin_trgm_ops);
-- 3. LIKE, ILIKE 성능 테스트
EXPLAIN ANALYZE SELECT * FROM articles WHERE content ILIKE '%검색어%';
그렇다면, GIN INDEX와 PG_TRGM을 사용한다면, 얼마나 향상 되나?
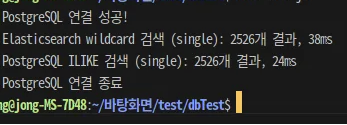
- 실제로 간단한 키워드지만, opensearch 보다 더 빠른 응답을 할 때도 있었다. 토크나이저라던지 한글 형탱소 검색에 대한 내용은 다른 인덱싱이나 확장 기능을 사용할 수도 있지만, 간단한 검색같은 기능 같은 것에는 GIN 인덱싱을 해도되지 않나 생각이 든다. elasticsearch를 도입하면 실제로 리소스가 비싼경우가 많기 때문에 간단한 토이프로젝트정도에는 검색기능에 인덱싱만 잘해도 될거같다.

왜 요즘은 글 안 올리시나요ㅠ