SQL
1.[프로그래머스 - SQL] - 상위 n개 레코드

상위 n개 레코드ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPON
2.[프로그래머스 - SQL] - 최댓값 구하기

최댓값 구하기ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPON_I
3.[프로그래머스 - SQL] - 중복 제거하기

중복 제거하기ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPON_I
4.[프로그래머스 - SQL] - 고양이와 개는 몇 마리 있을까

고양이와 개는 몇 마리 있을까ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, S
5.[프로그래머스 - SQL] - 동명 동물 수 찾기

동명 동물 수 찾기ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPO
6.[프로그래머스 - SQL] - 입양 시각 구하기

입양 시각 구하기ANIMAL_OUTS 테이블은 동물 보호소에서 입양 보낸 동물의 정보를 담은 테이블입니다. ANIMAL_OUTS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, NAME, SEX_UPON_OUTCOME는 각각
7.[프로그래머스 - SQL] - 입양 시각 구하기(2)

입양 시각 구하기(2)ANIMAL_OUTS 테이블은 동물 보호소에서 입양 보낸 동물의 정보를 담은 테이블입니다. ANIMAL_OUTS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, NAME, SEX_UPON_OUTCOME는
8.[프로그래머스 - SQL] - NULL 처리하기

NULL 처리하기ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPON
9.[프로그래머스 - SQL] - DATETIME에서 DATE로 형 변환

DATETIME에서 DATE로 형 변환ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NA
10.[프로그래머스 - SQL] - 중성화 여부 파악하기

중성화 여부 파악하기ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UP
11.[SQL 성능개선하기] - 업무에 바로 쓰는 SQL 튜닝입문
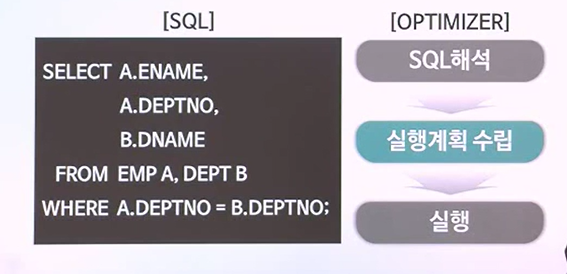
만약 SQL문이 속도에 문제를 나타내고 있다면, 무엇보다도 실행계획을 확인해서 분석을 통해 원인을 규명해야한다. 여기서 실행계획이 무엇이냐면 사용자가 SQL을 실행하여 데이터를 추출하려고 할 때, 옵티마이저가 수립하는 작업절차를 뜻한다.SQL에 대한 실행계획만을 확인할
12.[SQL 성능분석하기] - 옵티마이저

옵티마이저란?사용자가 실행한 SQL을 해석하고, 데이터 추출을 위한 실행계획을 수립하는 프로세스기본적으로 15개의 순위가 매겨진 규칙이 있음\-> 이를 기초로 해서 실행계획을 수립함SQL에 대한 실행계획이 하나 이상일 경우엔, 순위가 높은 규칙을 이용수립될 실행계획이
13.[SQL 성능개선하기] - 옵티마이저 - 실전예제문제

A라고 되어있는 테이블은 2개의 컬럼으로 만들어놓은 primary key가 있다. B라고 되어있는 테이블은 4개의 컬럼으로 이루어진 EC_TASK_TERM_IDX00을 가지고 있다. 지금 WHERE절 조건은 B라는 테이블에 걸려져있다.B에서 먼저 읽어와서 A를 조인(B
14.[SQL 성능개선하기] - 인덱스

데이터베이스에 저장된 자료를 더욱 빠르게 조회하기 위해 인덱스를 생성하요 사용함모든 SQL이 인덱스를 사용해야만 하는가? \-> 일반적으로, 인덱스는 전체 데이터 중에서 10~15% 이하의 데이터를 처리하는 경우에 효울적이며, 그 이상의 데이터를 처리할 땐 인덱스를
15.[SQL 성능개선하기] - 인덱스 - 실전문제

현재 쿼리는 PK를 사용하되 전체 28건의 데이터를 찾는다. 이 중 한건이 MIN과 MAX이다. 26건은 MIN도 아니고 MAX도 아니다.따라서 MIN과 MAX를 1건씩 찾게하라면 각각 쿼리를 나눠야한다.각각 1건씩 찾고 있어, 성능이 훨신 향상된다.
16.[SQL 성능개선하기] - 결합인덱스

인덱스 머지인 경우는 각각 단 하나의 컬럼으로 구성된 인덱스가 하나의 테이블에 2개 이상 있었을 때, 그 인덱스를 동시에 사용해 돌아가는 현상을 가리킨다. ROWID가 다른 경우는, ROWID가 작은쪽을 SCAN해가면서 ROWID가 같은 값을 찾아가고자 INDEX를 계
17.[SQL 성능개선하기] - 인덱스 활용이 불가능한 경우
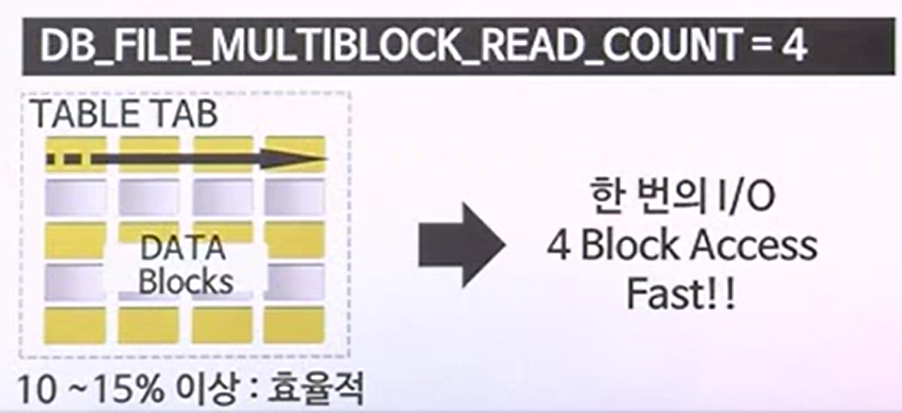
조건에 의한 처리범위가 넓어짐으로 인해 분포도가 나빠지는 경우가 있는데, 이 경우 인덱스 스캔을 하는것보다는 FULL TABLE SCAN을 하는 것이 바람직함한번에 읽어낼 수 있는 BLOCK갯수 4개를 의미하는 것이 DB_FILE_MULTIBLOCK_READ_COUNT
18.[SQL 성능개선하기] - 인덱스 활용이 불가능한 이유 - 실전 예제 문제

위의 쿼리는 인덱스를 사용하지 말아야할 쿼리이다.위의 힌트는 인덱스를 강제적으로 사용하기 위한 것이다.소요시간(elapsed : 12.34초)실행계획에 따르면 인덱스가 사용되어지고 있다.현재 옵티마이저는 CBO로 되어있다.(ALL_ROWS)찾는 데이터가 13만 8천여건
19.[SQL 성능개선하기]- NESTED LOOPS 조인

옵티마이저가 Driving Table을 결정함(Outer Table)Driving Table이 아닌 테이블은 Driven Table로 지정함\->(Inner Table)이라고도 함Driving Table의 각 row에 대해 이들이 추출될 때마다 Driven Table의
20.[SQL 성능개선하기]- SORT/MERGE/HASH 조인

연결 고리에 인덱스가 전혀 없는 경우대용량의 자료를 조인해야 함으로써 인덱스 사용에 따른 랜덤 액세스의 오버헤드가 많은 경우SORT/MERGE JOIN은 DRIVING 테이블이 없다.튜닝 포인트 \- 각 테이블로부터 데이터를 빨리 읽어 들이도록 함. (읽어들인 데이터
21.[SQL 성능개선하기] - 조인 조건이 없는 조인

WHERE절이 없는 조인 수행조인을 위한 조건 없이 조인 수행'데이터 복제'라는 개념을 활용하기 위해 사용하지만, 잘못 사용하게 되면 오히려 데이터를 부푸리는 원인이 되기 때문에 퍼포먼스를 오히려 나쁘게 할 수도 있음
22.[SQL 성능개선하기] SUBQUERY와 함수의 활용
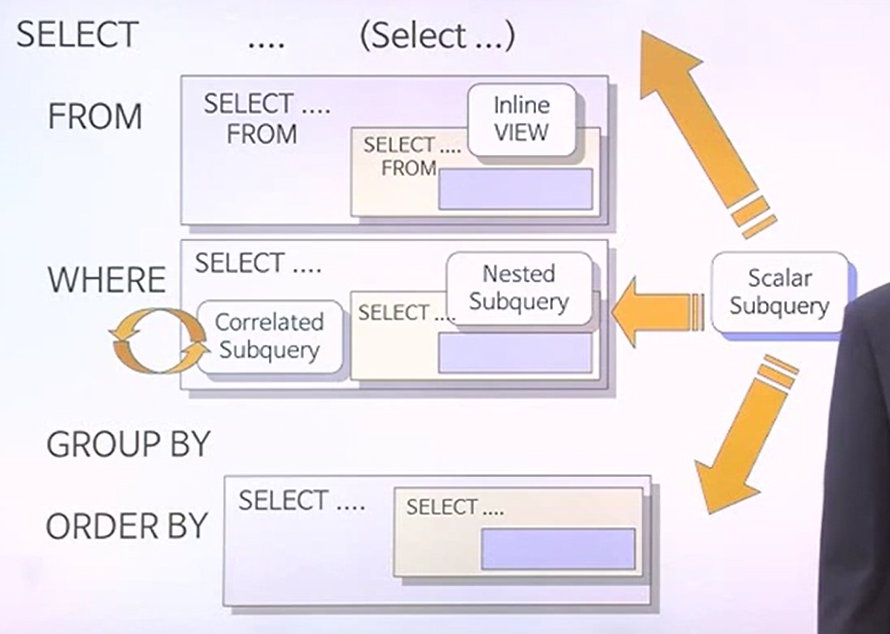
SELECT문에 대해서 문법적으로 나타낸 사진이다.GROUP BY에는 서브쿼리가 위치할 수 없다.WHERE절에는 Nested subquery, Correlated Subquery 등이 있다.FROM절에는 INLINE VIEW가 있다.위와 같은 것들을 서브쿼리라고 할 수