QuickSort
Quick Sort는 분할 정복(divide and conquer)방법을 통해 주어진 배열을 정렬하는 방법이다.
작동 원리
- 배열 가운데서 하나의 원소를 고른다. 이를 Pivot이라 한다.
- Pivot 앞에는 Pivot보다 값이 작은 원소들이 오고, Pivot 뒤에는 Pivot보다 큰 값이 오도록 위치한다. 배열을 이러한 방식으로 분할한다
- 분할한 배열에 대해 재귀(Recursion) 방식으로 반복한다.
PythonCode
from typing import MutableSequence
def qsort(a,left,right):
pl = left
pr = right
x = a[(left+right)//2]
while pl <= pr:
while a[pl]<x : pl += 1
while a[pr]>x : pr -= 1
if pl <= pr:
a[pl],a[pr] = a[pr],a[pl]
pl += 1
pr -= 1
if left<pr:qsort(a,left,pr)
if pl<right:qsort(a,pl,right)
def quick_sort(n):
qsort(n,0,len(n)-1)
if __name__=='__main__':
print('퀵 정렬을 수행합니다.')
num = int(input('원소 수를 입력하세요. : '))
x = [None]*num #원소 수가 num인 배열을 생성
for i in range(num):
x[i] = int(input(f'x[{i}]'))
quick_sort(x)
print('오름차순으로 정렬했습니다')
for i in range(num):
print(f'x[{i}] = {x[i]}')시간복잡도
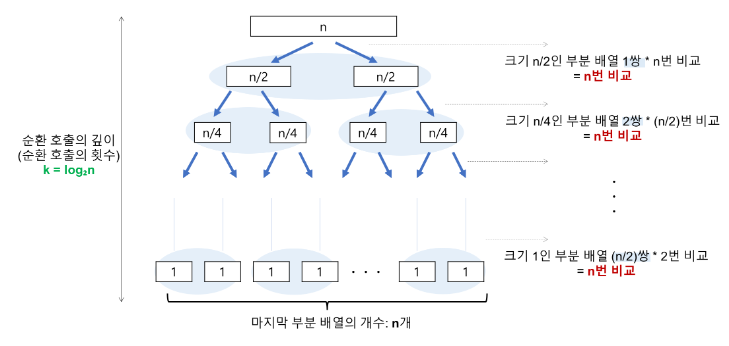
-
비교횟수 (log2n)
n이 2의 거듭제곱이라고 가정(n=2^k)했을 때, n=2^3의 경우, 2^3->2^2->2^1->2^0 순으로 줄어들어 호출의 깊이가 3임을 알 수 있다. 일반화를 통해 n=2^k인 경우 k = log2n으로 표현할 수 있다. -
각 순환 호출 단계의 비교 연산(n)
각 순환 호출에서는 전체 리스트의 대부분의 레코드를 비교해야 하므로 평균 n번 정도의 비교가 이루어진다.
따라서, 최선의 시간복잡도는 순환 호출의 깊이 * 각 순환 호출 단계의 비교 연산 = nlog2n이 된다.
최악의 경우
최악의 경우는 정렬하고자 하는 배열이 오름차순 정렬되어 있거나, 내림차순 정렬되어 있는 경우다.
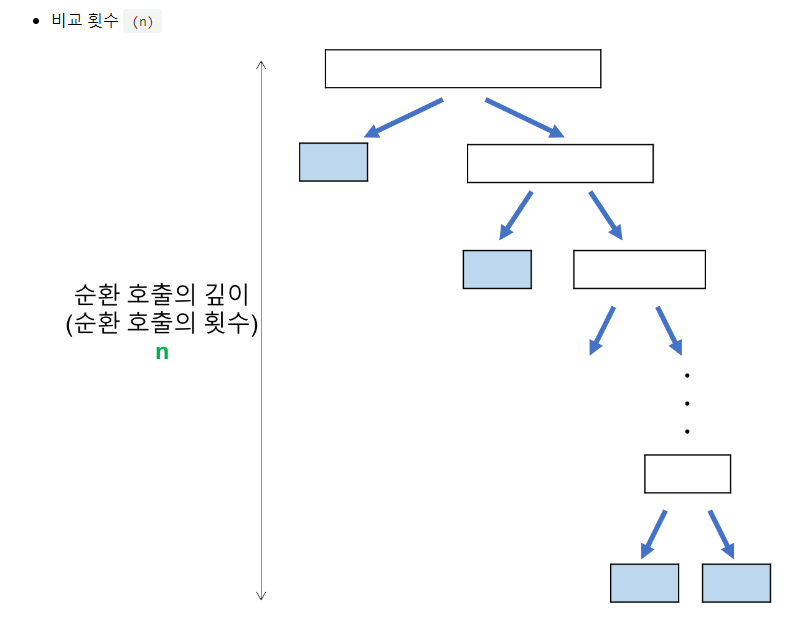
순환 호출 단계에서 평균 n번의 비교가 이루어 질 때,
순환 호출의 깊이 * 각 순환 호출 단계의 비교연산 = n^2이다.
공간 복잡도
주어진 배열 안에서 교환(swap)을 통해, 정렬이 수행되므로 O(n)이다.
장점
- 불필요한 데이터의 이동을 줄이고 먼 거리의 데이터를 교환할 뿐만 아니라, 한번 결정된 피벗들이 추후 연산에서 제외되는 특성 때문에, 시간 복잡도가 O(nlog2n)을 가지는 다른 정렬 알고리즘(heap,merge)과 비교했을 때, 속도가 가장 빠르다
- 정렬하고자 하는 배열 안에서 교환하는 방식으므로, 다른 메모리 공간을 필요로 하지 않는다.
단점
- 불안정한(Unstable sort)이다.
- 정렬된 배열에 대해서는 Quick Sort의 불균형 분할에 의해 오히려 수행시간이 더 많이 걸린다.
개선 방안
정렬된 배열과 역순 배열일 때, 퀵 정렬의 속도가 느려지는 것은 pivot으로 정해진 위치의 값을 택하기 때문에, 가장 큰 값이나 가장 작은 값이 pivot이 되기 때문이다.
1. 난수 분할을 사용한 퀵 정렬 개선
- pivot을 선택하는 대안으로 pivot을 난수로 선택하는 것이다. 확률적으로 퀵 정렬의 속도 향상을 기대할 수 있다.
- 0 ~ n-1 범위의 난수를 발생시켜 난수의 위치와 배열의 제일 오른쪽 요소의 위치를 바꾼 후에 퀵 정렬 알고리즘을 수행한다.
- 평균적으로 고른 속도 향상은 있을 수도 있지만 속도의 결과가 확률에 맡겨지게 된다.
2. 삽입 정렬을 사용한 퀵 정렬 개선
- 삽입 정렬은 구현이 간단하고 크기가 작은 배열에서는 매우 효율이 좋다.
- 삽입 정렬은 추가적인 메모리를 필요로 하지 않는다.
- 작은 구간에 대해서는 삽입 정렬을 사용하면서 퀵 정렬의 재귀의 깊이를 줄여줌으로써 속도의 향상을 기대할 수 있다.
- 구간의 크기가 너무 큰 경우 삽입 정렬은 큰 크기의 배열에서 성능이 좋지 못하여 전체적인 성능이 떨어진다.
- 퀵 정렬 종료 조건을 분할 리스트의 크기가 적절한 크기(100~200) 보다 작을 때로 변경하고, 작을 때는 삽입 정렬을 수행하도록 변경한다.
3. 세 값의 중위 값을 구한 퀵 정렬의 개선
- 배열의 가장 왼쪽 값 a[left], 가장 오른쪽 값 a[right], 중간의 값 a[(left+right)/2] 3개의 값을 사용한다. 이 세 값을 오름차순으로 정렬한다.
- 중간 값 a[(left+right)/2]을 가장 오른쪽의 앞의 값 a[right-1]과 위치를 바꾼다.
- 배열의 첫 번째 값은 마지막의 앞의 값보다 항상 작고, 마지막 값은 마지막 앞의 값보다 항상 크다. a[left] < a[right-1] < a[right]
- 분할 구간은 배열 앞에서 두번째 값과 뒤에서 세번째 값으로 좁혀진다
<a[left+1] 부터 a[right-2]> - 정렬 범위에서 2개를 줄이므로 재귀의 깊이를 줄일 수 있으며, 분할도 대부분 중앙에서 이루어진다.
- 최악의 경우인 정렬된 배열이나 역순의 배열의 경우 분할을 중앙에서 할 수 있으므로 이 방법을 쓰면 속도가 빨라진다.
