Spring WebFlux + Coroutine 환경 비동기 개발에서 살아남기 💪 - Spring WebFlux, Reactive Stream 그리고 R2DBC
Spring Webflux + Coroutine
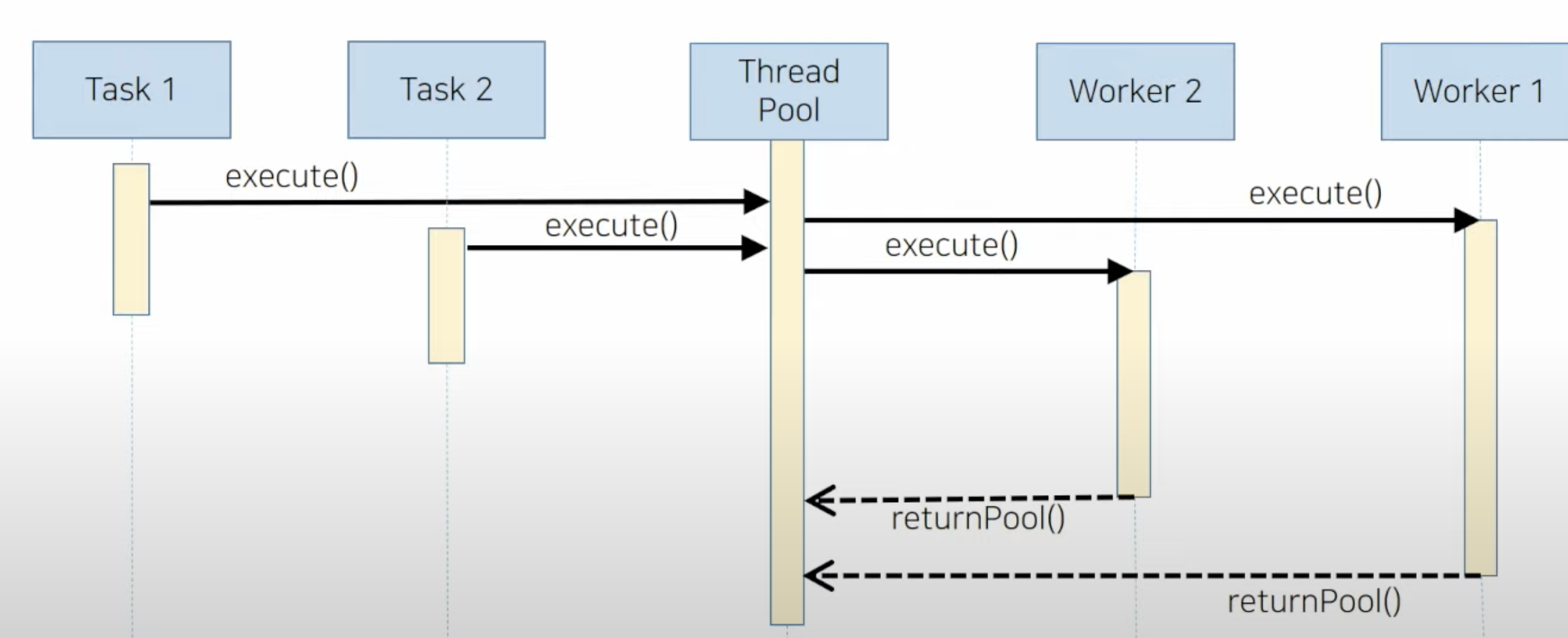
Spring Webflux
지속적으로 하나의 요청에 대한 응답을 전송할 수 있는 웹서버 기술
webflux는 reactive-streams 라이브러리의 구현체이다

일반 웹서버는 HTTP 동작 원리에 따라 요청에 대한 응답을 주고 세션을 끊어버린다
그런데 비동기 Non-blocking하게 서버를 운영하기 위해서는 IO작업 등을 요청한 쓰레드가 해당 작업을 기다리지 않고 바로 제어권을 갖음과 동시에 나중에 해당 작업이 끝났음을 알리기 위해서는 단 한번의 요청과 응답만으로는 해결되지 않는다.
특히 IO작업 등이 끝났다는 것을 비동기적으로 알려주기 위해서는 요청했던 곳으로 나중에 다시 응답을 해 줄 필요가 있다.
따라서 HTTP 연결을 끊지 않고 응답을 지속적으로 하기 위해서 연결을 유지해야 하는데 그러기 위해 Stream을 사용하게 된다.
Spring Webflux에서는 기존 Servlet의 HttpServeletRequest/ HttpServeltResponse 가 ServerRequest/ServerResponse로 대체된다
What is Stream Processing
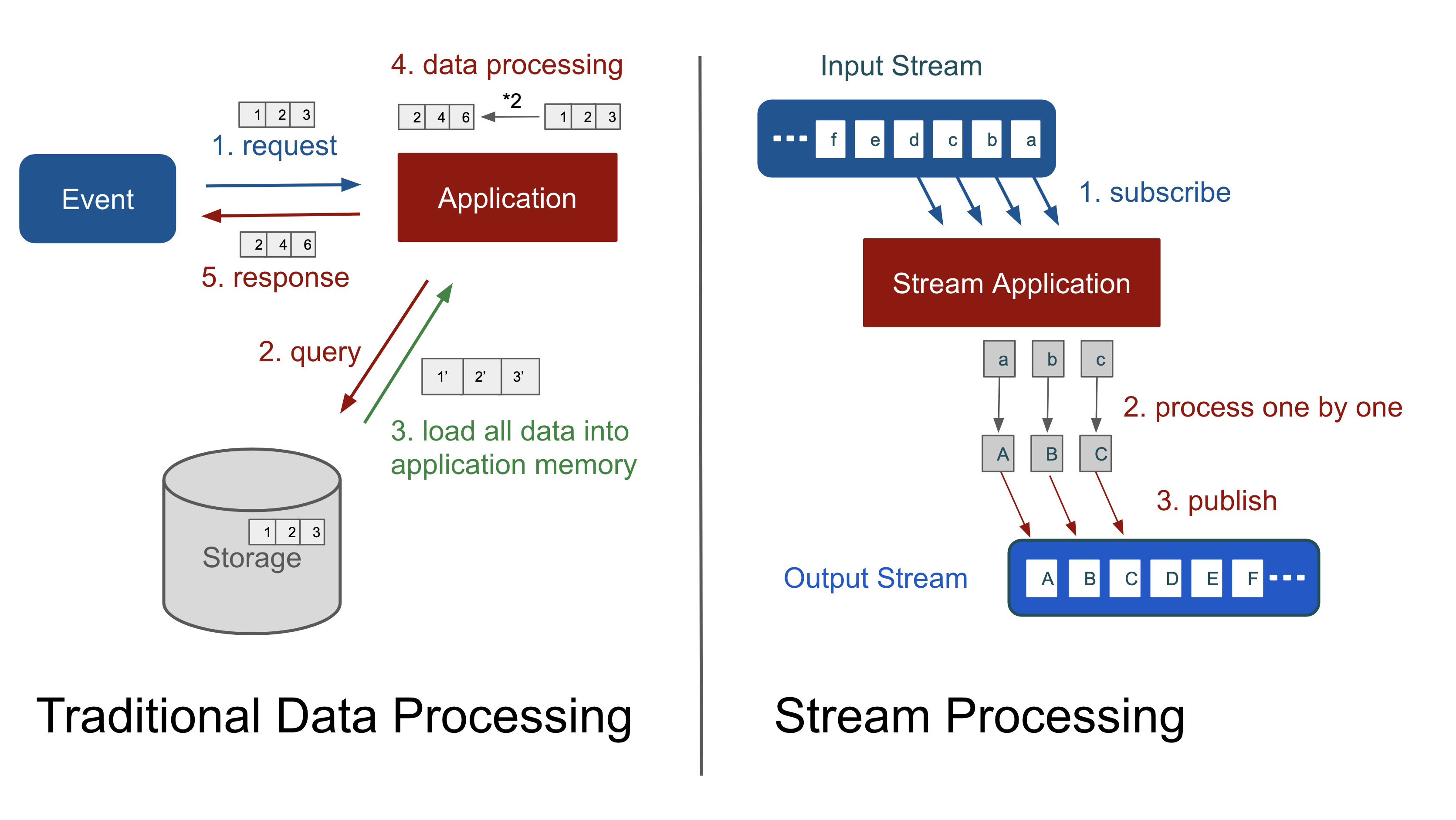
전통적인 데이터 처리 방식은 요청에 따른 데이터를 모두 어플리케이션 메모리에 저장한 후 처리한다.
만약 필요한 데이터의 크기를 어플리케이션 메모리가 감당할 수 없게 되면 OOM이 발생하거나 순간적으로 많은 요청이 몰리면 다량의 GC가 발생하여 서버가 정상적으로 응답하지 못하는 경우가 생긴다.
그런데 많은 양의 데이터를 처리하는 어플리케이션 스트림 처리 방식은 크기가 작은 시스템 메모리로도 많은 양의 데이터를 처리할 수 있다. 입력 데이터에 대한 파이프라인 형식으로 물흐르듯 subscribe하고 publish한다
Reactive-stream
☑️ non-blocking backPressure을 이용하여 비동기 서비스를 할 때 기본이 되는 스펙
☑️ ava의 RxJava, Spring5 Webflux의 Core에 있는 ProjectReactor 프로젝트, Java9에 추가된 Flow에서 reactive stream 스펙을 채택하여 사용
-
Reactive
Reactive라는 용어는 IO 이벤트에 반응하는 네트워크 컴포넌트, 마우스 이벤트에 반응하는 UI 컨트롤러 등과 같이 변화에 대한 반응을 중심으로 구축된 프로그래밍 모델
non-blocking은 작업이 완료되거나 데이터를 사용할 수 있는 상태가 되면 알림에 반응하기 때문에 reactive하다고 한다 -
back pressure
Reactive Streams는 back pressure가 있는 비동기 컴포넌트간의 상호작용을 정의하는 소규모 사양이다. Reactive Streams의 주된 목적은 Subscriber가 Publisher의 데이터 생성 속도를 제어하는 것이다.
기본적으로 reactive stream은 옵저버 패턴과 상당히 유사하지만 기존 옵저버 패턴에서는 데이터 변화를 publisher가 subscriber에게 밀어넣는 notify 형태였다면 backpressure는 리액티브 스트림만의 차별점이라고 할 수 있다. (이 pull 과정에서 Iterator 패턴으로 onNext()가 쓰였다)
Reactive Stream Flow
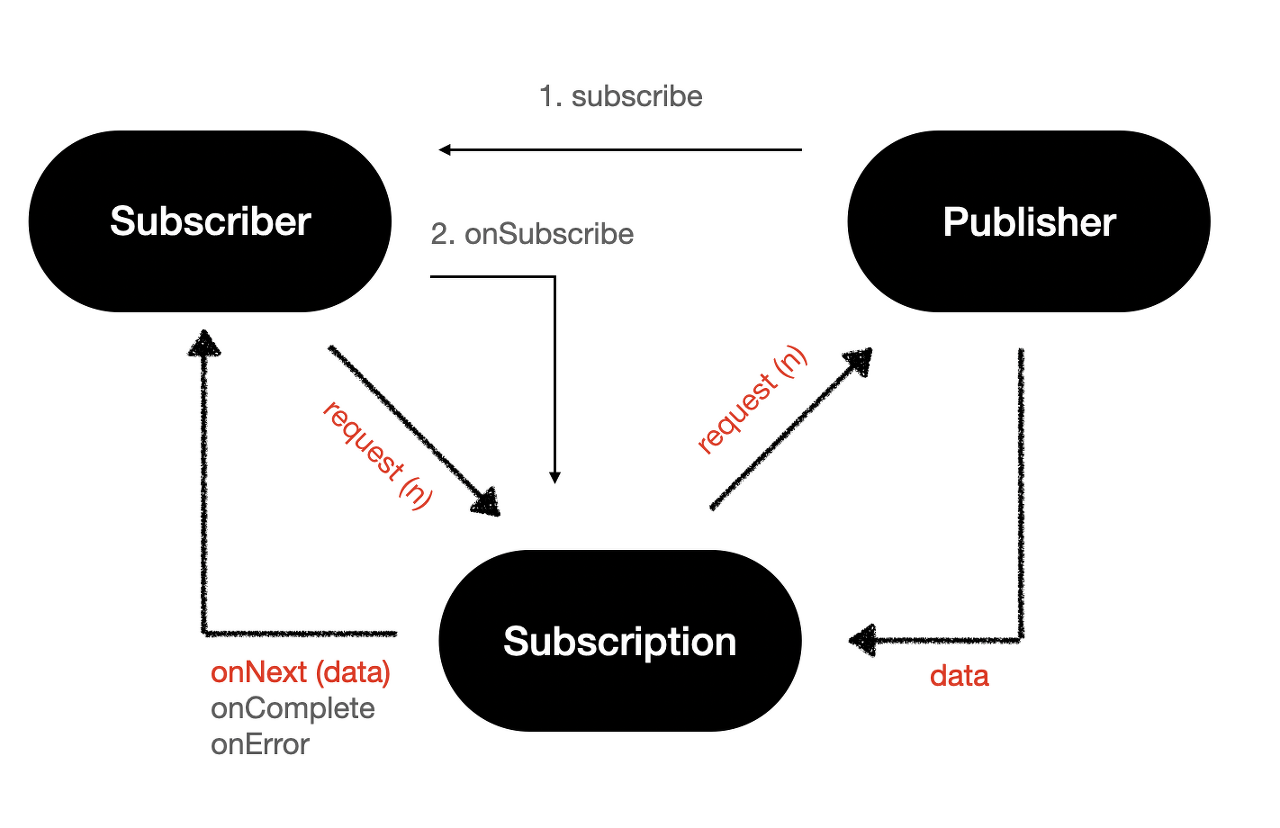
- publisher에 본인이 소유할 Subscription 을 구현하고 publishing할 데이터를 만듦
- publisher는
subscribe()메서드로 subscriber를 등록 - subscriber는
onsubscribe()메서드를 통해 subscription을 등록, publisher 구독 시작 - subscriber는 subscription 메서드의
request()또는cancel()을 호출해서 data의 흐름 제어 가능 - subscriber는 subscription 메서드의
onNext()onComplete()onError()를 호출해 데이터 흐름을 제어하는데request()cancel()함수 내부적으로 호출해서 제어
Reactor
Reactive Stream의 구현체
무한 반복문을 실행해서 이벤트가 발생할 때까지 대기하다가 이벤트가 발생하면 처리할 수 있는 핸들러에게 디스패치
- Flux
* 0..N의 데이터를 만들어내는 Publisher- Data 흐름 단위 (Complete/ Error)가 되기 전까지는 무한 생성 가능한 Stream
- 기존 동기 코드는 try catch로 예외를 처리했지만 비동기에서는 Error Event를 받아서 처리해야 한다. 데이터 흐름 중 에러가 발생하면 해당 Flux는 종료되기 때문에 이전에 받은 데이터들에 대한 처리 등을 생각해야 함
- Mono
* 0..1개의 데이터를 만들어내는 Publisher
Reactive-Stack의 장점
- 리소스 감소
적은 양의 스레드와 최소한의 하드웨어 자원으로 동시성을 핸들링하기할 수 있다
- blocking 문제
하나의 스레드가 하나의 IO 연산을 담당하는데 IO가 시작되면 sleep 상태로 바뀌고 끝난 뒤 다시 load되어 나머지 task 진행, 요청이 많아지면 따라서 context switching이 많아지고 thread가 많아짐에 따라 memory 사용량 증가, 확장성이 떨어진다
-> 많은 요청이 들어왔을 때 비효율적으로 리소스를 사용하게 된다
- 성능상 이점
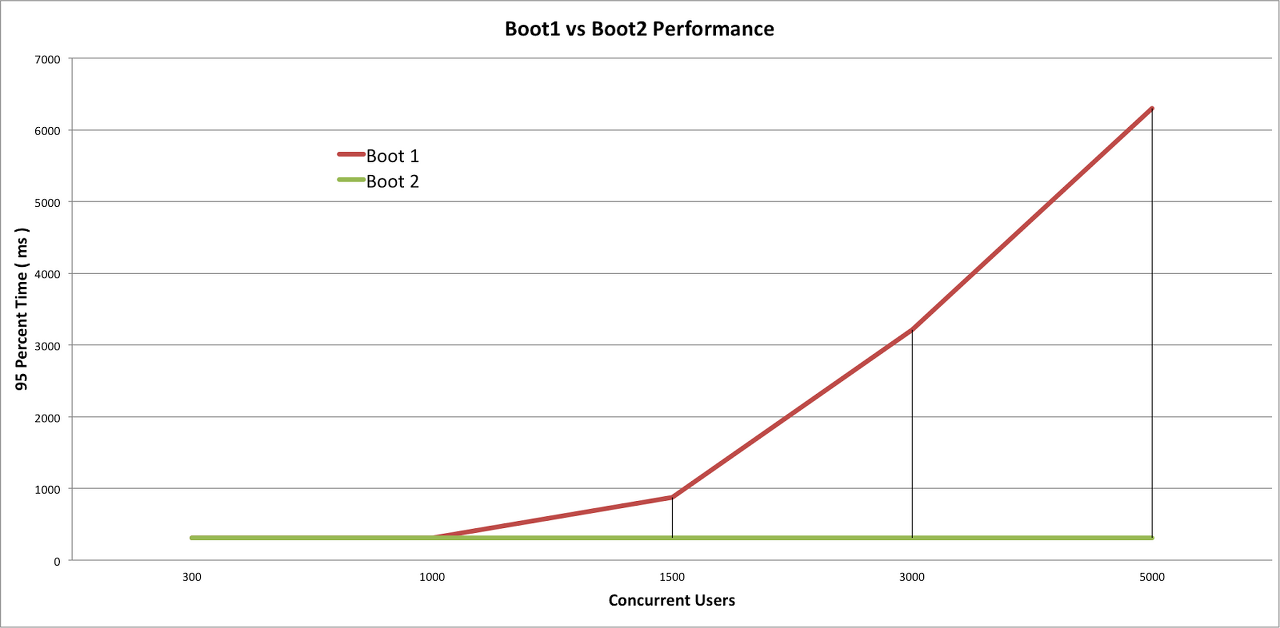
Spring MVC 방식은 서버의 하드웨어 성능으로 커버 가능한 구간을 지나면 쓰레드 풀이 점점 많아져 Queue가 쌓이기 때문에 느려지게 된다. 한편 WebFlux 방식은 non-blocking을 이용해서 IO 작업을 처리하기 때문에 request Event-Driven 을 통해 효율적으로 처리한다.
concurrent user가 1000명 이상인 경우에는 성능상 이점이 두드러지게 보이나, 그렇지 않은 경우는 크게 차이가 없는 것으로 알려져있다. 트래픽이 튀는 이벤트성 시기에는 이점이 있을 수 있겠지만 사실 scale out으로 일시적으로 대응을 해주는 경우가 대부분이다.
그럼에도 불구하고 매번 scale out을 하지 않아도 되고 리소스를 효율적으로 활용할 수 있다는 측면에서 reactive stack이 장점이 있다
Reactive Stream 상호 운영
non-blocking 프로그래밍을 할 때 가장 주의해야 하는 부분은 blocking 전파이다
non-blocking 특성 상, 한 부분에서라도 blocking이 일어나면 나면 non-blocking의 이점을 잃을 수 있기 때문이다
특히 webflux를 써서 비동기 논블로킹 웹서버를 운영한다고 해도 IO 작업이 blocking하게 이루어진다면 결국 논블로킹 프로그래밍의 이점을 하나도 얻어갈 수 없다
따라서 spring webflux는 mongoDB, redis, r2dbc 같은 reactive한 db 사용만을 권장하고 있다.
이러한 db들은 저장소의 데이터를 Reactive Stream으로 조회하도록 지원해준다.
예를 들어 MongoDB에서 조회한 데이터를 연산 처리한 후 HTTP 응답으로 보낸다고 가정할 때,
ReactiveStream을 이용해서 MongoDB에서 조회한 데이터를 조회하게 될 경우
우선 데이터를 구독받을 수 있는 Publisher만 반환된다 (즉각 반환되기 때문에 non-blocking)
subscriber가 subscription을 통해 request를 호출하기 전까지 실제 데이터는 전달되지 않는다
subscriber가 request를 호출해서 필요한 만큼의 정보를 간헐적으로 받는다
데이터 소비가 끝나면 응답이 종료된다
JDBC
JDBC는 자바 프로그램 내에서 DB 종류에 상관없이 DB 작업을 처리할 수 있도록 도와주는 API
일반적인 동기 방식의 쿼리 처리
Thread에서 쿼리를 요청하면 커넥션 풀에서 커넥션을 가져와 해당 커넥션을 통해 쿼리를 처리하고 그 결과를 받는데, 이 과정 자체가 blocking 하게 구현되어 있다.
R2DBC
Reactive Relational DabaBase Connectivity
JDBC의 한계를 보완하기 위해 만들어진 데이터베이스 작업처리 connectivity
ConnectionFactory connectionFactory = ConnectionFactories.get(url);
final Publisher<? extends Connection> connPub = connectionFactory.create();
connPub.subscribe(new BaseSubscriber<Connection>() {
@Override
protected void hookOnNext(Connection conn) {
Statement stmt = conn.createStatement("select id, name from member where name = ?name");
stmt.bind("name", "Movie");
Publisher<? extends Result> resultPub = stmt.execute();
resultPub.subscribe(...);
}
});ConnectionFactory의 create 메서드가 생성한 Publisher는 연결에 성공하면 next신호로 Connection을 보낸다
Subscriber는 onNext() 메서드로 Connection을 받아 쿼리를 실행한다
쿼리를 실행하기 위한 Statement는 execute 메서드를 통해 실행되는데 Publisher<Result 타입을 리턴한다
Result는 쿼리 실행 결과를 제공한다
resultPub.subscribe(new BaseSubscriber<Result>() {
@Override
protected void hookOnNext(Result result) {
Publisher<Member> memberPub = result.map((row, meta) ->
new Member(row.get(0, String.class), row.get(1, String.class))
);
memberPub.subscribe(new BaseSubscriber<Member>() {
@Override
protected void hookOnNext(Member member) {
logger.info("회원 데이터 : {}", member);
}
});
}
@Override
protected void hookFinally(SignalType type) {
conn.close().subscribe(...);
}
});쿼리 실행 결과 처리는 Result를 map으로 받고자 하는 객체의 publisher로 만들어준다.
SpringMVC vs SpringWebFlux
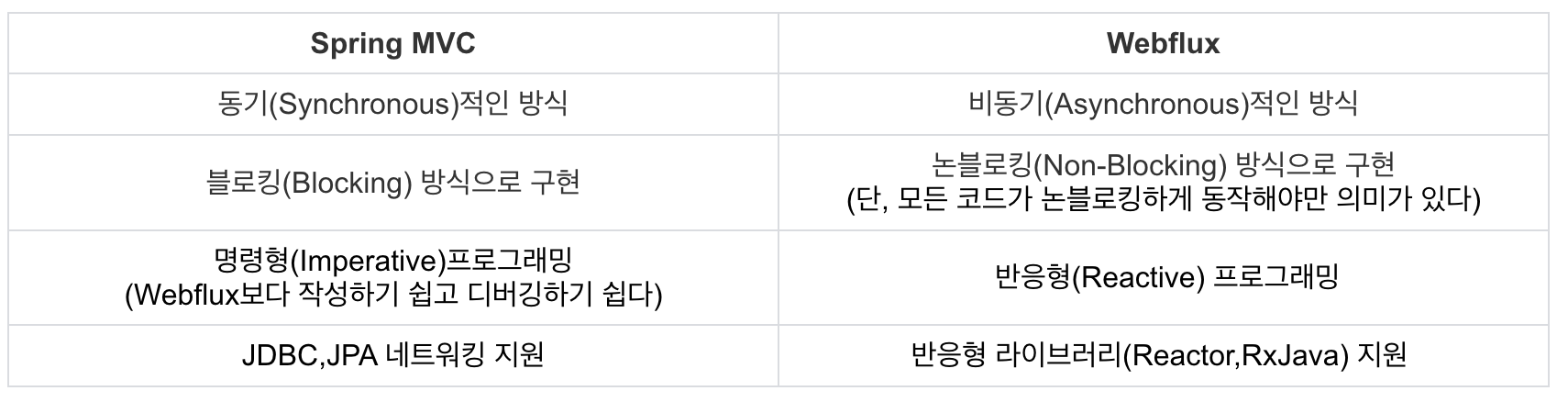
지금까지 Spring MVC는 서블릿 컨테이너에 Servlet API를 기반으로 한 프레임워크였지만
Spring Webflux는 Servlet API를 사용하지 않고 Reactive Streams와 그 구현체인 Reactor를 기반으로 한 새로운 HTTP API다
따라서 Spring mvc는 thread per request Model이기 때문에 서버 부하가 높은 상황에서는 context swtiching 문제가 생긴다.
한편 Spring Webflux는 Event Loop 모델로 동작한다. 사용자들의 요청이나 애플리케이션 내부에서 처리해야 되는 작업들은 모두 Event 단위로 관리되고 Event Queue에 적재되어 순서대로 처리되는 구조이다. 그리고 이벤트를 처리하는 thread pool이 존재하는데 이 풀안의 스레드들을 이벤트 루프라고 부른다. Event Loop는 Event Queue에서 Event를 뽑아서 하나씩 처리한다. 네티의 쓰레드 갯수는 core 갯수의 두배이다.
WebFlux가 비효율적인 상황?
webflux는 상대적으로 적은 쓰레드pool을 유지하기 때문에 CPU 사용량이 높은 작업이 많거나 blocking IO를 사용한다면 이벤트 루프가 빨리 빨리 이벤트 큐에 있는 이벤트를 처리할 수 없다.
runnable 상태의 스레드가 CPU를 점유하고 있기 때문
예를들어 동영상 인코딩, 문서 암호화 encryption decryption은 적합하지 않다!!
부록) Reactive Programming vs Reactive System
공부하다가 이 개념 두개의 차이가 무엇인지 궁금해서 간단하게 정리해야지
보는 관점의 차이라고 할 수 있는데 Reactive Programming은 어플리케이션 레벨의 관점으로 바라본 것으로 Event Driven이다 (어플리케이션에서 event를 비동기적으로 처리하는 프로그래밍)
Reactive System은 시스템 아키텍처 관점으로 바라본 것으로 단순히 프로그래밍 레벨이 아니라 예를 들어 카프카 같은 메세지 브로커를 설계한다든지 등, 전반적인 시스템 설계 흐름이 비동기적으로 진행되도록 하는 것이다. 따라서 이는 Message Driven이라고 한다
리액티브 프로그래밍을 한다고 시스템 아키텍처를 리액티브 시스템으로 만드는 것이 아니다
리액티브 시스템이 되기 위해서는 각 컴포넌트들이 메세지 브로커 등으로 message기반 통신이 이루어져야 한다.
또한 요청에 대한 탄력성과 유연성이 보장되어야 한다.
참고링크
https://velog.io/@neity16/WebFlux-2-WebFlux-%EB%9E%80-SpringMVC-vs-WebFlux
https://engineering.linecorp.com/ko/blog/reactive-streams-with-armeria-1/
https://engineering.linecorp.com/ko/blog/reactive-streams-with-armeria-2/
https://www.getoutsidedoor.com/2020/11/23/reactive-streams-%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C/
https://javacan.tistory.com/entry/R2DBC-1-intro
