참고한 링크
Elasticsearch로 간단한 자동 완성 생성
[Server] Elasticsearch 개념 이해
[ELK] 엘라스틱서치(ElasticSearch) 시작하기
[spring boot] 스프링부트 에서 elasticsearch 시작하기
https://kmhan.tistory.com/498?category=943757
https://idea-sketch.tistory.com/60?category=547413
windows환경에서 elasticsearch 설치 및 실행
[Elasticsearch] 엘라스틱서치 벼락치기(1) - 기본개념
📚참고 서적: 시작하세요!엘라스틱 서치
이슈
- localhost:9200으로 접속시 user과 password입력 필요, 그러나 뭔지 모르겠음😢
Elastic Search 란?
Elastic Search 사용 사례
- 위키피디아 : 전문검색(Full Text Search) ,실시간 타이핑 검색, 추천 검색어 기능
- 더 가디안: 방문객 로그 분석을 통한 소셜 데이터를 생성해 실시간 응대와 기사에 대한 반응 분석
- 스택오버플로우: 검색 내용과 결과를 통합해 유사한 질문과 해답을 연결하는데 활용
- 깃허브: 방대한 양의 코드 검색
- 골드만 삭스: 주식 시장 변동 분석
데이터 양이 많은 경우 빠른 검색 플랫폼을 구축하는 것이 필요하다.
일반적인 RDB(내가 주로 사용하는 mysql 등)에 대한 검색 속도는 O(N)이다.
내가 개발하려고 하는 기능이 검색어 자동완성 기능인 만큼, 유저가 실시간으로 자음이나 모음 하나 검색창에 타자칠 때마다 해당 input을 포함하는 데이터를 모두 실시간으로 반응해서 보여줘야 하는데
이 과정에서 RDB를 사용하여 O(N)의 시간 효율을 내는 것은 너무너무너무너무너무X100 비효율적이다.
Elasticsearch는 이러한 이유 때문에 사용하게 된다.
Elasticsearch는 해시 테이블 주고의 역색적인 방식으로 데이터를 구축해놓기 때문에 검색 속도는 O(1) 로 매우 빠른 속도를 낸다.
이러한 시간효율 덕분에 Elasticsearch는 상품 검색, 본문 검색, 매트릭 수집 및 분석, 로그 모니터링, 데이터 수집 및 분석과 추천 등에서 많이 쓰인다.
Elasticsearch는 확장성이 뛰어난 오픈소스 풀텍스트 검색 및 분석 엔진이다.
방대한 양의 데이터를 신속하게, 거의 실시간으로 저장, 검색, 분석할 수 있도록 지원한다.
일반적으로 복잡한 검색 기능 및 요구 사항이 있는 애플리케이션을 위한 기본 엔진/기술로 사용된다.
Elasticsearch는 루씬 기반의 검색 엔진이다.
HTTP 웹 인터페이스와 스키마에서 자유로운 JSON문서와 함께 분산 멀티테넌트 지워 전문 검색 엔진을 제공한다.
Elastic Search의 장점
Elastic Search 의 장점에는 여러 가지가 있지만 ⭐ 표시한 부분이 이번 개발에서 활용할 핵심 장점이다!
- 빠르고 효과적인 검색⭐⭐⭐
- 역색인(Inverted Index)과 전문 검색(Full texted search) 기능을 지원한다.
- 대량 비정형 데이터 보관과 검색⭐⭐
- 기존 데이터베이스로는 처리하기 어려운 대량의 비정형 데이터 검색이 가능하며, 검색엔진이지만 mongoDB나 Hbase처럼 대용량 스토리지로 활용할 수 있다.
- 형태소 분석을 통한 자연어 처리
- 한국어는 복합어, 합성어 등 변형이 복잡한 언어인 형태소 분석기만 있으면 간편한 자연어 처리가 가능하다.
- 높은 확장성과 가용성
- Elasticsearch는 데이터를 샤드(Shard)라는 작은 단위로 나누어 제공한다. 데이터의 종류와 성격에 따라 데이터를 분산하여 빠르게 처리하기 때문에 확장성과 가용성이 높다.
- 자동완성 검색 기능
- 초성검색⭐
- 부분일치⭐
- 한영 변환
- 오타 검색어 제안
역색인(Inverted Index) 방식
RDB와는 차별화된 ElasticSearch의 장점은 바로 이 역색인 방식에 있다.
앞서 언급했다시피 이는 기존의 검색 속도의 O(N)을 O(1)로 바꿔주는 핵심 기능이다.
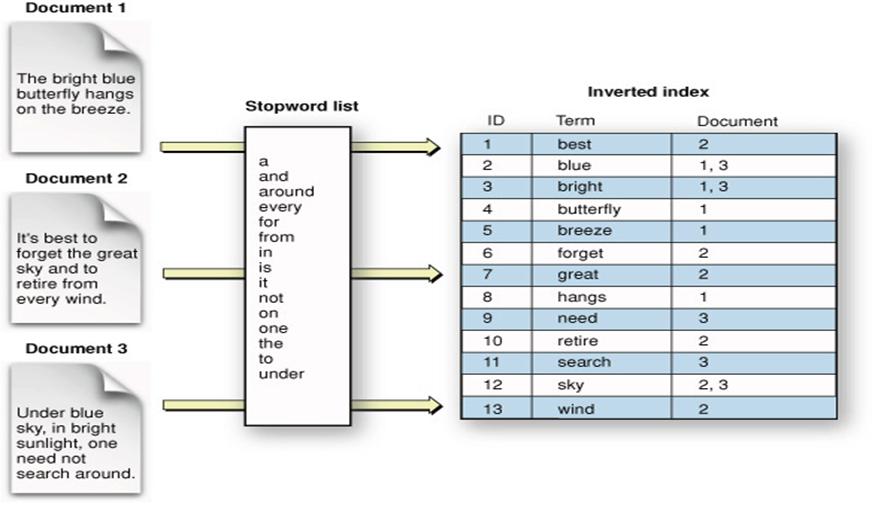
🔺사진 출처 : https://danidani-de.tistory.com/52
역색인 방식은 아주 단순하다.
한마디로 기존에 검색어로 제시될 단어나 문장 등의 검색 타겟을 미리 쪼개놓은 뒤에 저장해두는 것이다
여기서 쪼개진 단어나 형태소 등은 단순히 테이블에 저장되는 것이 아니라 해쉬 테이블 방식으로 저장되어 검색 속도를 O(1)의 성능을 내도록 한다.
그 후 유저로부터 키워드가 검색될 때 마다 미리 쪼개놓은 데이터 해쉬 테이블에서 바로 검색해서 찾아와 리턴하는 방식이다.
한 마디로 역색인 방식은
-
키워드를 통해 문서를 찾아내는 방식
-
아주 빠른 전체 텍스트 검색이 가능
-
문서에 나타나는 모든 고유한 단어 목록을 만들고, 각 단어가 발생하는 모든 문서를 식별
-
해쉬 테이블 방식으로 검색시 O(1)의 성능
Elastic Search 특징
1. 아파치 루씬 기반
아파치 루씬은 자바 언어로 개발된 검색 라이브러리이다. 아파치 루씬은 사용자 위치 정보(geolocation), 다국어 검색, 철자 수정기능, 자동완성, 미리 보기 등의 다양한 기능을 지원한다.
2. 실시간 분석
엘라스틱 서치에 저장된 데이터는 검색에 사용되기 위해 별도의 재시작이나 상태의 갱신이 필요하지 않다. 데이터는 색인 작업이 완료됨과 동시에 바로 검색할 수 있다.
3. 분산 시스템
엘라스틱 서치는 여러 개의 노드로 구성되는 분산시스템이다.
-
노드란? : 데이터를 색인하고 검색 기능을 수행하는 엘라스틱서치의 단위 프로세스
시스템의 규모가 늘어나면 기존 노드에 새 노드를 실행해 연결하는 것으로 규모확장 가능, 데이터는 각 노드에 분산 저장되고 복사본을 유지해 각종 충돌로부터 노드 데이터의 유실을 방지한다.4. 높은 가용성
하나 이상의 노드로 구성, 각 노드는 1개 이상의 데이터 원본과 복사본을 가지고 있어 서로 다른 위치에 나누어 저장한다. 노드가 종료되거나 실행에 실패하는 경우 엘라스틱서치는 노드들의 상태를 감지하고 종료된 노드가 가지고 있던 데이터를 다른 노드로 옮기는 작업을 수행한다.
5. 멀티 테넌시
엘라스틱서치의 데이터는 여러 개로 분리된 인덱스들에 그룹으로 저장된다.
-
인덱스란? 관계형 DB의 데이터베이스로 생각하면 됨.
rdb에서는 다른 db 데이터 접근시 커넥션을 생성해야 하지만 엘라스틱서치에서는 데이터를 검색할 때 다른 인덱스의 데이터를 하나의 질의로 묶어서 검색하고 여러 검색 결과를 하나의 출력으로 도출한다.6. 전문검색(Full Text Search)
데이터 색인을 이용한 전문검색을 지원한다.
7. JSON 문서 기반
모든 데이터는 기본적으로 문서의 모든 필드가 색인되어 JSON 구조로 저장된다. 또한 NoSQL과 같이 스키마프리를 지원하므로 별도의 사전 매핑 없이도 JSON 문서 형식으로 데이터를 입력하면 바로 검색 가능하다.
8. RESTFul API
Restful API를 지원하고 있다.
Elastic Search의 구조
🌿도큐먼트
-
도큐먼트(Document): Elasticsearch 저장의 기본 단위인 JSON 개체이다. rdb에 비교하자면 테이블의 row와 같다고 생각하면 된다. (각각의 DATA이다)
Document는 키와 값으로 정의된 필드(Field)들로 구성되어 있는데 , 키는 필드의 이름이며 값은 String, Number, Boolean, Object, Array 등의 다양한 유형일 수 있다.Document에는 다음과 같이 문서를 구성하기 위한 예약된 필드가 포함되어 있다.
- _index : Document가 저장되어 있는 Index 정보
- _type : Document의 유형을 나타내는 정보
- _id : Document의 유니크한 고유값
🌿타입
- 타입(Type) : 타입은 Document를 유형별로 모아놓은 집합이다. rdb와 비교하자면 테이블과 같다고 생각하면 된다.
🌿인덱스
-
인덱스(Index) : 인덱스는 Elasticsearch의 가장 큰 데이터 단위이다. rdb랑 비교하자면 데이터베이스 그 자체와 같다고 생각하면 된다. elasticsearch 7.0부터는 하나의 인덱스가 하나의 타입만을 갖도록한다. Elasticsearch에서는 원하는 만큼의 Index를 가질 수 있고, 각 Index는 고유한 Document를 보유하게 된다.
Index는 아래 두 가지 유형으로 구분할 수 있다.- 샤드(shard) : 샤드는 단일 루씬 Index이다. Index는 저장할 수 있는 Document의 제한이 없기 때문에 호스팅 서버의 제한을 초과하는 디스크 공간을 차지할 수 있는데 이런 경우 발생하는 문제에 대응하기 위해 Index의 데이터를 분산해 저장하고 이렇게 나뉜 조각들을 샤드라고 한다.
- 복제셋(Replicas) : 복제셋은 이름에서 알 수 있듯이 Index의 분산된 Shared들을 복사한 것이다. 이는 노드에 문제가 생길 때 백업시스템으로 사용된다. Elasticsearch에서는 가용성을 보장하기 위해 원본 샤드와 복제셋을 같은 노드에 놓을 수 없다.
🌿노드
-
노드 (Node) : 데이터를 저장하고 색인 하는 등의 중요한 역할을 하는 Elasticsearch 인스턴스 이다. Node는 다음과 같은 유형들로 나눠서 각자의 역할을 수행한다.
- Data Node: 데이터를 저장하거나 검색과 집계 등 데이터와 연관된 작업을 한다.
- Master Node: 노드의 추가, 제거 등 클러스터의 관리 및 구성 작업을 담당한다.
- Ingestion Node: 색인 전에 Document를 사전처리하는 용도로 사용한다.
- Machine learning Node : 머신러닝 작업을 가능하게 하는 용도로 사용한다.
🌿클러스터
-
클러스터 (Cluster) : Cluster는 하나이상의 Node로 구성되어 있어야 하며 그 하나의 Node는 Master Node의 역할을 할 수 있어야 한다.
Cluster라는 용어에서 알 수 있듯이 여러 개의 Node 가 모여서 하나의 시스템처럼 동작하게 하는 Node의 집합이다.
ElasticSearch 설치
elasticsearch 사이트에서 elasticsearch를 다운로드 받는다.
1. cmd 창에서 cd ..\elasticsearch-버전\bin 실행
2. sudo elasticsearch.bat 실행

3. 브라우저에서 localhost:9200접속
⛔user와 password를 알지 못함 ㅠㅠ
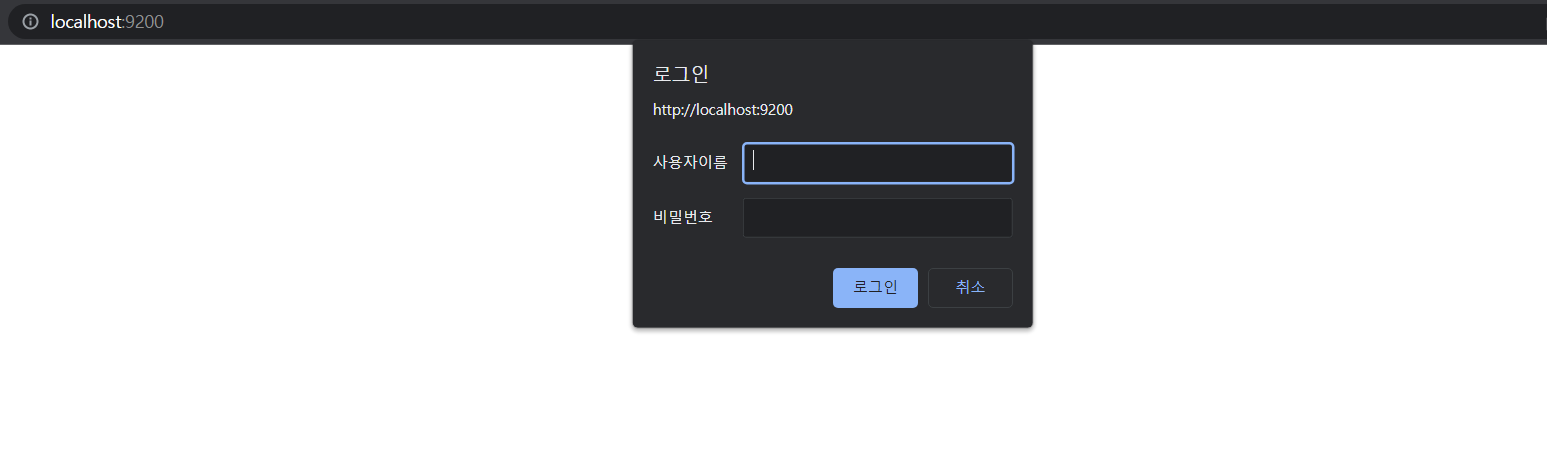
Aㅏ... 로그인 하라는데 이게 뭐고
사용자이름이랑 비밀번호 default값을 구글링해서 찾아냈는데 여전히 로그인 안되고

위와 같은 오류만 내뱉었다.. 뭔가가 바뀐모양이다..진짜 웃겨
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/get-started-built-in-users.html
결국 여기서 하라는 대로 비밀번호 새로 만들고 아이디는 elastic 그대로 쓰니까 접속이 되었다.
🌼🌷🌼🌷🌼🌷🌼🌷 🌼🌷🌼🌷🌼🌷🌼🌷 🌼🌷🌼🌷🌼🌷🌼🌷 🌼🌷🌼🌷🌼🌷🌼🌷 🌼🌷🌼🌷🌼🌷🌼🌷
-
sudo elasticsearch-service.bat install명령어 실행 -
Elasticsearch 실행 : bin 폴더까지 들어간 후
elasticsearch-service start -
Elasticsearch 중지 : bin 폴더까지 들어간 후
elasticsearch-service stopElastic 실행
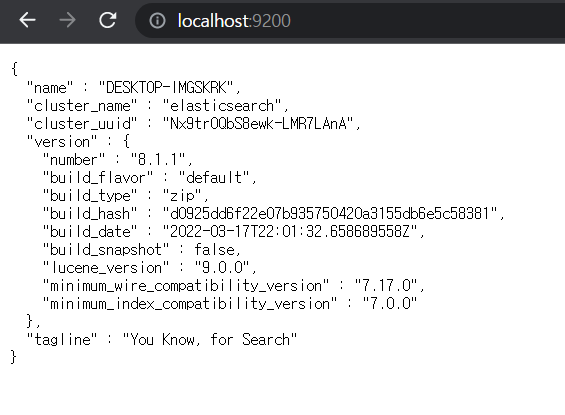
- 조회 명령어 :
curl -XGET localhost:9200

보안 문제시 비밀번호, 아이디 옵션을 같이 주어서 실행해야 한다.
curl -XGET -u 아이디:비밀번호 localhost:9200
