참고한 링크 및 문헌
참고한 도서📚 : 시작하세요! 엘라스틱서치
[elasticsearch] 대량(bulk) 문서 색인시 오류 처리](https://m.blog.naver.com/koys007/221694251672)
엘라스틱서치의 검색 기능은 query(질의)명령어를 이용해 수행된다.
query는 REST API에 문자열 형식의 매개변수를 이용한 URI 방식과 http 데이터를 이용한 request body 방식이 있다.
질의는 타입, 인덱스, 그리고 여러 개의 인덱스를 묶어서 멀티 인덱스 범위로 질의할 수 있다.
여러 인덱스를 묶어서 처리하는 엘라스틱서치의 특징을 멀티 테넌시(Multi Tenancy)라고 한다.
⛔The bulk request must be terminated by a newline
검색 기능을 활용해보기 전에 데이터를 입력해보려고 하는데 갑자기
The bulk request must be terminated by a newline [\n] 라는 오류가 나며 데이터 추가가 되지 않았다.
검색해보니 json(request body) 가장 마지막에 enter 한번만 눌러줘서 줄바꿈 하면 된다고 해서 반신반의로 해보니까 진짜 되네😅
검색(_search) API
엘라스틱서치에서 검색은 인덱스 또는 타입 단위로 수행된다.
도큐먼트는 그 자체가 1개의 최소 데이터 단위이므로 도큐먼트 단위로 검색한다는 것은 성립되지 않는다.
다음은 book 타입에서 hamlet이라는 검색어로 검색을 수행한 과정이다
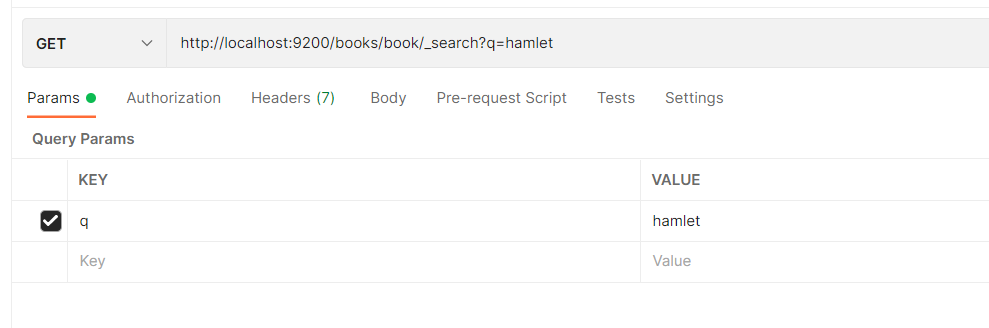
위와 같이 검색하고자 하는 인덱스와 타입을 uri로 줌과 동시에 이후에 _search를 붙이고
검색하고자 하는 쿼리(질의)를 params의 q로 주면 된다.
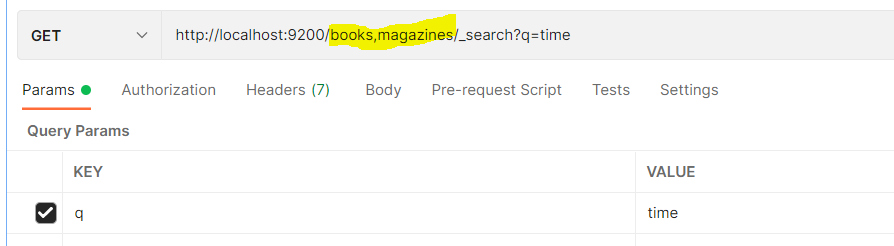
books 인덱스 단위로도 검색 가능하다.
멀티테넌시(multi tenancy)활용하기
엘라스틱서치는 여러 인덱스에서의 조회도 지원하기 때문에 멀티테넌시를 활용할 수 있다.
방법은 단순하다. 인덱스 단위로 검색할 때 , 로 여러 인덱스를 구분해서 입력해주면 된다.
URI 검색
엘라스틱서치의 두 가지 주요 검색 방법 중 먼저 URI 검색은 http 주소에 검색할 명령을 매개변수 형식으로 포함해서 호출하는 검색이다.
리퀘스트 바디 검색과 비교해서 사용 방법은 간단하지만 복잡한 질의(쿼리)를 입력하기 어려운 단점이 있다.
참고로 위의 검색에서는 여태까지 URI 검색 방법을 활용했다.
Query
q는 질의 명령을 입력하는 가장 기본적인 검색 매개변수(parameter)이다.
특정 필드에서만 검색하기
특정 필드만 검색하려면 q 매개변수에 필드명:질의어 형태로 값을 입력한다
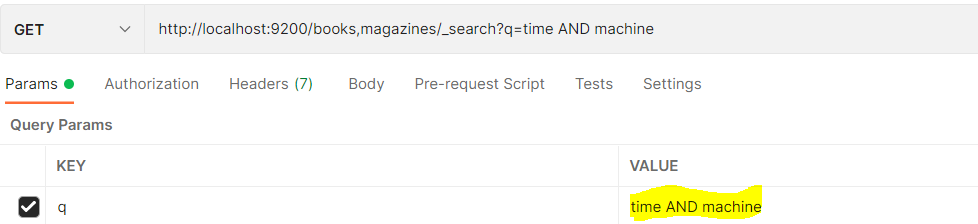
특정 필드에 값 두 개 이상이 동시에 들어간 값을 찾는 명령을 하고 싶다면 조건 명령어 q매개변수에 AND 또는 OR 값을 공백과 함께 넣어 지정할 수 있다.
- 조회 결과
"_source": {
"title": "The Time Machine",
"author": "H. G. Wells",
"category": "Science fiction novel",
"written": "1895-11-01T05:01:00",
"pages": 227,
"sell": 22100000,
"plot": "The book's protagonist is an English scientist and gentleman inventor living in Richmond, Surrey in Victorian England, and identified by a narrator simply as the Time Traveller. The narrator recounts the Traveller's lecture to his weekly dinner guests that time is simply a fourth dimension, and his demonstration of a tabletop model machine for travelling through it. He reveals that he has built a machine capable of carrying a person, and returns at dinner the following week to recount a remarkable tale, becoming the new narrator."
}df(Default field)
q 질의에 필드명을 넣는 대신 df 매개변수를 통해 검색할 필드를 지정할 수 있다.
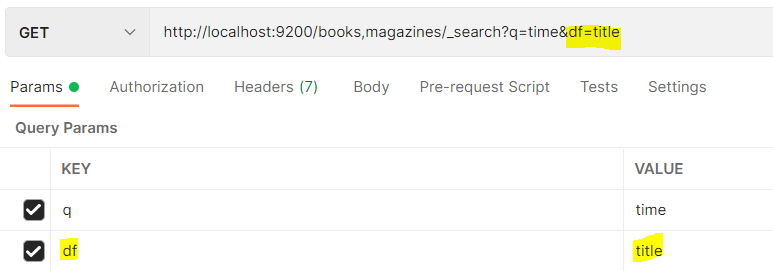
이렇게 하면 자동으로 title 필드에서 검색어가 time인 결과가 조회결과로 나온다.
default_operator : OR
조건 명령어를 지정하지 않고 공백으로 질의어를 나누면 기본값인 OR로 인식한다.
아래 두 명령어는 같다.
/_search?q=title:time OR machine
/_search?q=title:time machine만약 default operator를 변경하고 싶다면 매개변수(파라미터) default_operator로 변경할 operator를 제시해주면 된다.
explain
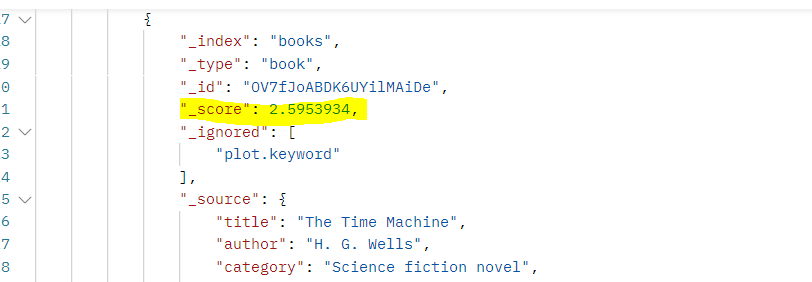
explain 매개변수를 추가하면 각 검색 처리에 대해 해당 검색 결과의 점수 계산에 사용된 상세 값이 출력 결과에 표시된다. 점수는 검색어에 해당하는 데이터의 정확도를 계산한 값이며 기본적으로 점수가 높을 수록 결과값의 상위에 나타나게 된다.
source
_source 매개변수의 값을 flase로 설정하면 검색 결과에서 도큐먼트 내용은 표시하지 않고 전체 hit 수와 점수 등의 메타 정보만 출력한다.
fields
fields 매개변수를 사용해서 출력 결과에 표시할 필드를 지정할 수 있다.
이 기능은 SQL의 SELET와 같다고 생각하면 된다.
표시할 필드를 쉼표(,)로 구분해서 입력할 수 있다.
sort
sort 매개변수를 사용해서 검색 결과의 출력 순서를 정할 수 있다.
기본적으로 검색 결과는 점수(_score, 검색 정확도) 순으로 정렬된다.
정렬할 기준을 변경하려면 sort 매개변수에 필드명 형식으로 값을 주어 지정한다.
이렇게 따로 지정할 경우 기본적으로 오름차순으로 정렬되며 내림차순으로 정렬하려면 필드명:desc로 입력한다.
주의할 점은 sort 매개변수에 정렬할 필드를 지정하면 해당 필드의 색인 된 검색어들 중에서 오름차순 그리고 내림차순에 사용될 가장 우선순위가 높은 값을 선택해서 이 값들을 기준으로 정렬하게 된다.
만약 색인된 데이터가 아니라 필드 값 전체를 대상으로 정렬하고 싶다면 데이터를 색인하기 전에 해당 필드를 not_analyzed로 매핑해서 설정해줘야 한다.
sort 매개변수로 정렬할 필드를 지정하면 _score 값이 null이 되기 때문에 만약 score도 같이 보고싶다면 track_scorces=true로 변수를 주어야 한다.
From & size
size 매개변수는 검색된 결과 도큐먼트를 몇 개까지 표시할지 지정한다.
지정하지 않으면 기본값은 10이다.
from은 조회 결과를 몇 번째 도큐먼트부터 가져올지 지정한다.
from과 size 매개변수를 함께 사용하면 페이지 기능을 구현할 수 있다. from으로 몇 번째 페이지를 출력할지 정하고 size로 한 페이지에 출력할 결과 수를 지정한다.
search_type
search_type 은 검색을 수행하는 방법을 지정한다.
query_then_fetch: 전체 샤드의 검색이 다 수행된 후에 결과를 출력한다. 전체 취합된 결과를 size 매개변수에서 지정한 개수만큼 출력한다.query_and_fetch: 사드 별로 검색되는 대로 결과를 받아 출력한다.dfs_query_then_fetch: 검색 방식은 query_then_fetch와 같으며 정확한 스코어링을 위해 검색어들을 사전에 처리한다.dfs_query_and_fetch: 검색 방식은 query_and_fetch와 같으며 정확한 스코어링을 위해 검색어들을 사전에 처리한다.count: 검색된 도큐먼트 정보를 배제하고 전체 hits 수만 출력한다. 속도가 가장 빠르다scan: scroll과 같이 사용되며 검색 결과를 바로 보여주지 않고 scroll에 저장했다가 _scroll_id를 사용해서 나중에 결과를 출력한다. 검색 방식은 query_and_fetch와 같다.
리퀘스트 바디 검색
엘라스틱서치에서 검색할 조건을 JSON 데이터 형식의 질의로 입력해서 사용할 수 있다.
이러한 방식의 검색을 requestBody 검색이라고 하며 URI 검색보다 좀 더 복잡한 형식으로 검색할 수 있다.
리퀘스트바디 검색은 엘라스틱서치의 질의 언어인 QueryDSL을 사용한다.
size, from, fields
URI 검색에서 사용했던 size, from, fields 등의 매개변수를 옵션으로 지정할 수 있다.
참고로 query에서 전체 필드를 검색하려면 필드명에 _all을 입력한다.
{
from : 1
size : 2
fields : ["title", "category"],
"query" : {
"term" : {"_all" : "time"} //전체에서 time이 들어간 도큐먼트의 title과 category필드를 보여줌
}
}sort
sort 옵션을 사용해서 검색 결과의 출력 순서를 정할 수 있다.
정렬을 하지 않은 기본적인 검색 결과의 출력은 _score 값을 기준으로 정렬된다.
배열을 정렬할 필드를 여러 개 정할 수도 있다.
{
"fields" : ["title","author","category","pages"],
"sort" : [{"category":"desc"},"pages","title"],
"query" : {
"term" : {"_all" : "time"}
}
}오름차순, 내림차순은 order 필드로 지정할 수 있다.
이외에도 여러 개의 값을 가진 필드는 mode 필드를 이용해 해당 필드의 특정 값을 지정해서 sort에 사용할 수 있다.
- min : 해당 필드의 값 중 최소값을 선택 / max : 최대값을 선택
- avg : 해당 필드 값의 평균값을 대입. sum: 해당 필드 값의 합계 대입
특정 필드로 sort를 실행하면 점수가 표시되지 않는다.
track_scores 필드를 true로 설정하고 실행하면 점수가 표시된다.
_source
_source 필드 값을 false로 설정하면 검색 결과에서 도큐먼트 내용은 표시하지 않고 전체 hit수와 점수 등의 메타 정보만 출력한다.
include, exclude 필드를 사용하면 특정 패턴의 필드를 포함하거나 배제할 수 있다.
{
"_source" : {
"include" : "c*",
"exclude" : "*ry"
}
}partial_fields, fielddata_fields
fields 옵션을 이용해 지정한 필드들만 출력할 수 있지만, fields 옵션은 _source와 달리 기본적으로는 와일드카드(include, exclude)를 지정할 수 없다.
_source 는 검색 결과를 기존에 입력된 값 그대로 출력하지만 field는 json데이터로 가공해서 출력한다.
_source와 같이 필드명에 와일드카드와 include, exclude 기능을 이용하려면 partial_fields르 사용한다.
다음은 partial_fields를 사용해서 c로 시작하면서 ry로 끝나지 않는 필드만 출력하게 했다.
출력을 위해 partial_fields에 임의의 필드명을 입력한다.
{
"partial_fields" : {
"partial_1" : {
"include" : "c*",
"exclude" : "*ry"
}
}
}highlight
highlight 옵션을 이용하면 검색 결과에 검색 조건에 대한 부분을 강조해서 표시할 수 있다.
