이 문서는 웹에 어떠한 컨텐츠를 보여주고자 할 때, 어떤 식으로 검색엔진이 인지하고는지와 구조화된 데이터의 작동방식에 대하여 다루고 있습니다.
Overview
schema.org
구글, 빙 등의 검색엔진들은 유저들이 원하는 검색결과를 쉽게 얻을 수 있도록 schema.org markup을 활용하고 있습니다. 2020년 05월 01일에 8.0 버전이 릴리즈 되었고, 여전히 많은 웹페이지들이 이를 토대로 구조화된 데이터를 구성하고 있습니다. 예시로 뉴욕타임즈의 구조화된 데이터는 다음과 같이 생겼습니다.
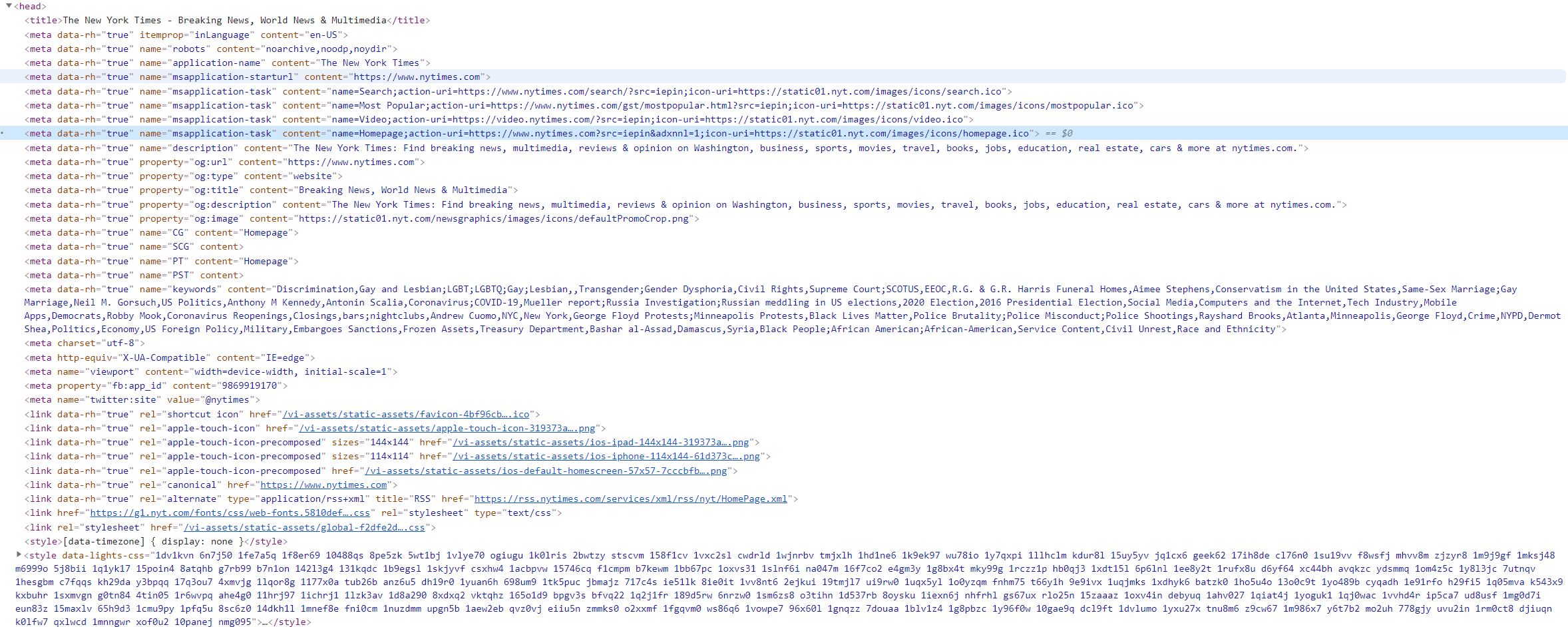
open graph protocol을 이용한다는 점을 명시하고 있고, og 뿐 아니라 linked data, rich snippet 등을 비롯해 다양한 방식으로 데이터를 구조화하고 웹사이트르 노출을 최적화하고 있습니다. 콘텐츠 중신의 사이트이기 떄문에 다양한 요구사항을 맞추기 위해 엄청나게 많은 메타 태그가 존재하는 것을 알 수 있지요.
구글이 og를 그대로 쓰긴 어렵기도 하고 검색엔진은 og나 twiter card 이상의 요약정보이상의 내용이 필요하기 때문에 MS, Yahoo, Google은 schema.org를 발표하게 됩니다. schema.org는 웹 페이지의 정보를 구조화해서 검색엔진이 더 정확하게 분석할 수 있게 한 것으로 2020년 6월 16일 현재 829 Types, 1351 Properties, and 339 Enumeration values로 구성되어 있습니다.
Vocabularies
| 형식 | 설명 |
|---|---|
| JSON-LD | JavaScript Object Notation for Linked Data, 페이지 헤드 또는 본문의 <script> 태그 내에 삽입되는 자바스크립트 표기입니다. 마크업은 중첩된 데이터 항목(예: Event의 MusicVenue의 PostalAddress의 Country)을 더 쉽게 표현하며 사용자가 볼 수 있는 텍스트와 함께 표시되지 않습니다. 또한 Google에서는 자바스크립트 코드나 콘텐츠 관리 시스템에 삽입된 위젯과 같이 JSON-LD 데이터가 페이지의 콘텐츠에 동적으로 삽입될 때 JSON-LD 데이터를 읽을 수 있습니다. |
| MicroData | HTML 콘텐츠 내에 구조화된 데이터를 중첩하는 데 사용되는 개방형 커뮤니티 HTML 사양입니다. RDFa와 같이 HTML 태그 속성을 사용해 구조화된 데이터로 표시하려는 속성의 이름을 지정합니다. 대개 페이지 본문에 사용되지만 헤드에 사용될 수도 있습니다. |
| RDFa | Resource Description Framework in Attributes, 사용자에게 표시되며 검색엔진에 제시하려는 콘텐츠에 해당하는 HTML 태그 속성을 도입하여 연결된 데이터를 지원하는 HTML5 확장입니다. RDFa는 일반적으로 HTML 페이지의 헤드와 본문 섹션 모두에 사용됩니다. |
| Structured Data | 구조화된 데이터는 페이지에 관한 정보를 제공하고 페이지 콘텐츠를 분류하기 위한 표준화된 형식으로, 예를 들어 레시피 페이지의 경우 재료, 조리 시간, 온도, 칼로리 등이 여기에 해당합니다. |
- Microdata는 명세 작업이 거의 멈춘 상태입니다. 지금은 별문제 없지만, 앞으로 나올 다른 요구사항에 대한 추가 작업을 기대하기 어렵습니다.
- Microdata는 HTML에서만 사용할 수 있지만 RDFa는 HTML 외 XML이나 SVG 같은 다른 마크업에서도 사용할 수 있습니다.
- Microdata는 한 콘텐츠에서 하나의 vocabulary만 사용할 수 있지만 RDFa는 접두사가 있어서 여러 vocabulary를 섞어서 사용할 수 있습니다.
구글은 JSON-LD의 사용을 권장하고 있으며, 이 포스트 또한 JSON-LD를 이용해서 구조화된 데이터를 구성하고자 합니다.
작동방식
구글의 구조화된 데이터 작동 방식 이해 를 참고.
구조화된 데이터 구성하기
구조화된 데이터는 페이지에 관한 정보를 제공하고 페이지 콘텐츠를 분류하기 위한 표준화된 형식입니다. 검색엔진들은 웹에서 찾은 구조화된 데이터를 사용하여 페이지의 콘텐츠를 파악할 뿐 아니라 웹 및 전반적인 세상에 관한 정보를 수집하고 있습니다. 또한 특수 검색결과 기능 및 강화 기능을 실현할 수 있습니다.
기본작업
SEO의 가장 기본적인 작업은 검색엔진에서 시작한다. 이 검색엔진들이 우리 서비스를, 사이트를 얼마나 잘 이해하도록 정보를 제공할 것인가가 SEO의 핵심이라고 할 수 있습니다.
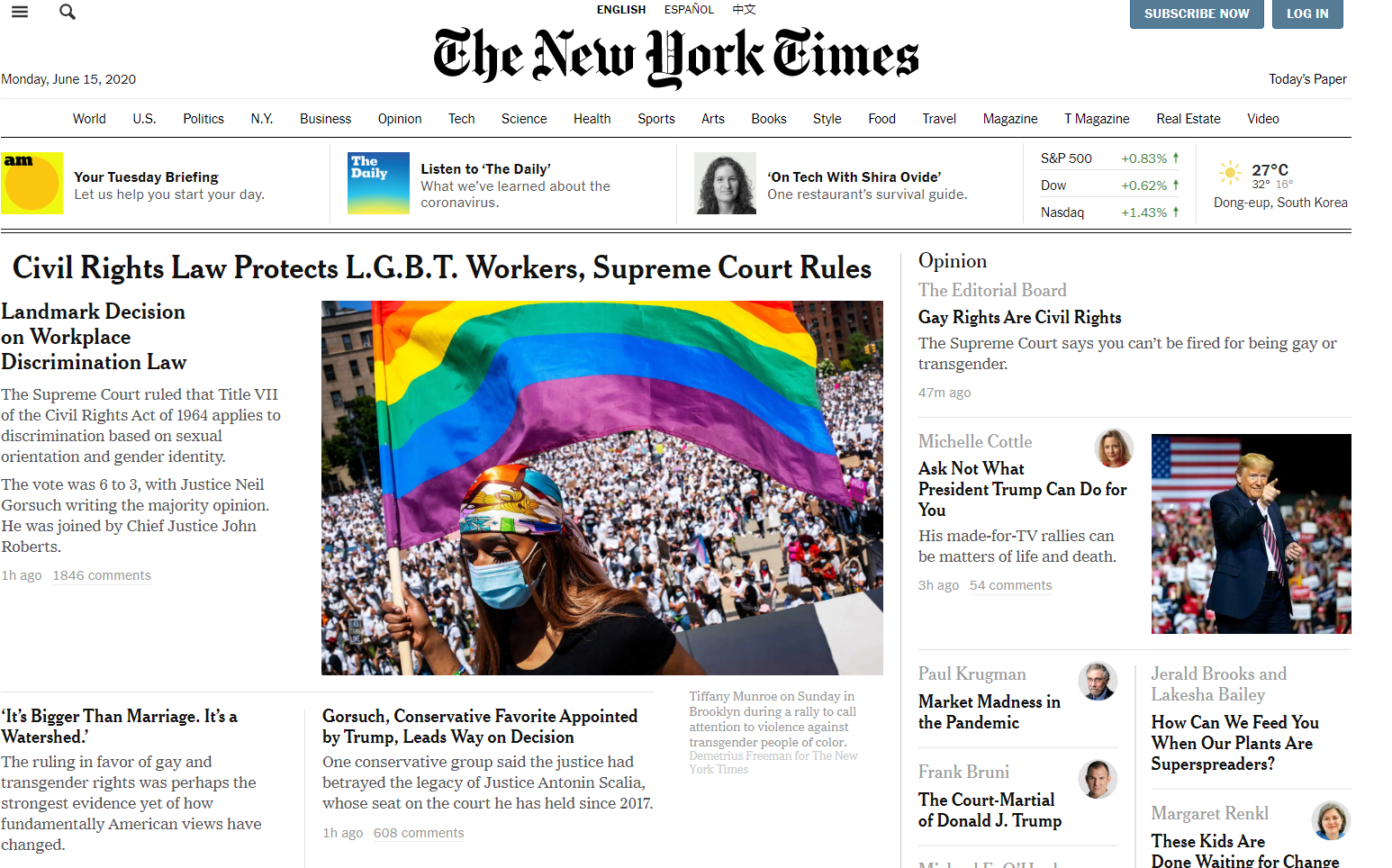
로봇도 겉핥기를 좋아해요. 지금 당신이 이 글을 읽는 이 시간에도 엄청나게 많은 웹페이지가 생성되고 있지요. 검색엔진의 첫 페이지는 한정적인 결과만을 보여주기 떄문에, 무언가를 알리고 싶어하는 사람이라면 검색엔진의 상단에 자신의 결과물이 노출되길 원합니다. 로봇들이 모든 페이지들을 실시간으로 방문하고, 색인을 구성하면 좋겠지만, (만일 그렇게 한다면 주 52시간 근무를 초과하게 되어 로동법을 위반하게 됩니다!) 자연링크를 통해 색인을 생성해야하므로, 로봇이 사이트의 모든 콘텐츠를 찾지 못할 수도 있습니다.
따라서 검색엔진 로봇들이 핥아갈 때, 어디를 핥으면 좋을지 알려주고, 최대한 양질의 정보를 제공할 수 있도록 조치를 취해보도록 합시다.
검색엔진 웹마스터 도구 등록
가장 기초적인 접근방법은 검색엔진마다 존재하는 웹마스터 도구에 우리의 사이트를 등록하는 것입니다.
현재 alda homepage 는 구글, 네이버에 site verification이 되어있는 상태.
그렇지만 국내에서 통용되는 검색엔진은 네이버와 구글 외에도 다음카카오, 줌(expolorer의 농간입니다!!), MSBING(누가 쓰는지 너무 궁금!) 이 있습니다. 특히나 네이버는 점점 검색엔진 점유율이 떨어지고 있고, 모바일 인덱스 친화적이지도 않으면서, 동시에 네이버 서비스 내의 컨텐츠가 아니라면 상위에 노출되기도 어렵습니다. 이쯤되면 네이버는 검색엔진의 특성을 갖추었다기보다 거대한 인트라넷이라고 보는게 적절할지도 모릅니다. 아무튼 나머지 검색엔진들도 빼놓으면 섭섭하니 웹마스터 도구에 등록을 해봅시다!!
대체로 웹마스터 도구들은 다음과 같은 데이터를 제출할 것을 요구하므로 준비해봅시다.
- sitemap.xml
- robot.txt
robots.txt는 로봇 배제 표준을 따르는 일반 텍스트 파일입니다. robots.txt 파일은 하나 이상의 규칙으로 구성됩니다. 각 규칙은 특정 크롤러가 웹사이트에서 지정된 파일 경로에 액세스할 권한을 차단하거나 허용합니다.
검색엔진 색인생성
검색엔진은 컨텐츠 검색 수준을 높이고, 관리하기 위하여 색인을 생성합니다. 이 색인을 토대로 검색엔진들은 결과를 출력하게 되고, 색인을 어떻게 관리하느냐에 따라 검색에 필요한 리소스 등이 결정됩니다. 페이지 URL이 없으면 크롤링이 불가하여 검색결과에 표시할 수 없게됩니다. 또한, 색인이 생성된다고 해서 검색결과에 반드시 노출되는 것은 아닙니다. 그러나 적극적인 URL 관리를 통해 검색결과의 성능을 향상시킬 수 있으며, 도달 범위를 확장해나갈 수 있습니다.
- 새로운 또는 업데이트된 URL 제출
- 수정사항 타임스탬프가 포함된 사이트맵 제출
모바일 인덱스 생성
검색을 하거나 웹에 액세스할 때 휴대기기를 이용하는 사용자가 늘어나고 있습니다! 웹사이트를 모바일 친화적으로 만드는 것은 고객을 위해서나 기업을 위해서나 중요한 일이 되었습니다. 알다 웹페이지의 모바일 친화적인 요소를 극대화하고, 사용자 경험을 향상시켜봅시다.
- 구글은 같은 규칙을 토대로 검색엔진의 모바일 인덱스 생성에 대한 가이드라인을 제공하고 있습니다.
- 모바일과 데스크톱 사이트에서 동일한 메타 로봇 태그를 사용합니다. 모바일 사이트에서 다른 메타 로봇 태그를 사용하는 경우(특히 noindex 또는 nofollow) 사이트에 모바일 중심 색인 생성이 사용 설정되면 Google에서 페이지를 크롤링하거나 색인을 생성하지 못할 수 있습니다.
- 사용자 상호작용 시 주 콘텐츠에 대해 지연 로드 방식을 사용하지 않습니다.
Google에서 리소스를 크롤링할 수 있도록 합니다. 일부 리소스의 경우 모바일 사이트와 데스크톱 사이트의 URL이 다릅니다. Google에서 URL을 크롤링하도록 하려면 disallow 명령어로 URL을 차단하지 않는지 확인하세요.
구글 마이비즈니스
구글 마이비즈니스 등록을 통해서 매력적인 검색 결과를 생성하면서 동시에 서비스의 공신력을 높여봅시다.
주소, 영업시간 등 기본적인 정보를 입력하면 구글 마이비즈니스에 등록할 수 있습니다. 그러나 모든 기능을 활용하기 위해서는 인증이 필요합니다. 이 인증은 구글에서 직접 사무실의 주소로 코드가 적힌 엽서를 보내게 됩니다. 엽서를 받는데에는 통상 2주 - 3주 정도 걸립니다.
기다리는 동안 우리가 할 수 있는 것들을 해보도록 합시다.
구조화된 데이터
드디어 구조화된 데이터에 대하여 알아볼 수 있게 되었습니다! 이제부터는 정말 실전입니다. 까리한 검색결과를 구성하고 친구들과 만나면 ‘나 이런거 해 ㅎㅎ 구글에 쳐봐 ㅎㅎ’ 하면서 구글 검색결과를 보여주도록 합시다.
코드스니펫 생성과 테스트(Based on Google)
D3 | Data-Driven Documents or D3.js
Appendix
D3 RDFS in JSON-LD
A simplification of the Schema.org type hierarchy, in which each type has at most one super-type, represented in a hybrid format that combines JSON-LD, RDFS and D3: tree.jsonld.
This file is made available to support developers using the D3 JavaScript library for manipulating documents based on data. It uses JSON-LD to declare that D3's default "children" JSON field represents "subClassOf" relationships, but expressed in the reverse direction (example usage).
JSON for Linking Data
D3 | Data-Driven Documents
![]()
Introduction
D3 (Data-Driven Documents or D3.js) 는 웹표준을 이용하여 데이터시각화를 가능케해주는 자바스크립트 라이브러리입니다. SVG, Canvas and HTML 등을 이용해 데이터를 가져올 수 있습니다. 브라우저 상에서 동적이고 인터렉티브한 정보시각화를 구현할 수 있도록 해줍니다. 각종 차트게 필요한 기능들을 함수단위로 제공하면서 동시에 브라우저 내장 요소 검사기를 통해 쉽게 디버깅이 가능합니다.
D3는 2011년 2월 18일 Mike Bostock, Jason Davies, Jeffrey Heer, Vadim Ogievetsky, and community에 의해 최초로 릴리즈 되었고, 2020년 4월 20일 5.16.0 버전이 최신으로 제공되고 있습니다.
자세한 내용은 D3 Github Repository 를 참조하세요
설치
D3를 설치하는 방법은 두 가지가 있습니다.
-
직접 설치
d3 공식홈페이지에서 d3.zip을 다운받아 직접 폴더에 삽입하는 방식입니다. -
CND 방식
<script src="https://d3js.org/d3.v5.min.js"></script>
위 스니펫을 삽입합니다.
Reference
Schema.org로 웹 콘텐츠 구조화하기
Schema.org vocabulary (schema)
Google Webmaster Guidelines
Yahoo! Webmaster Guidelines
네이버 검색엔진 최적화 기본 가이드
구글 마이비즈니스
