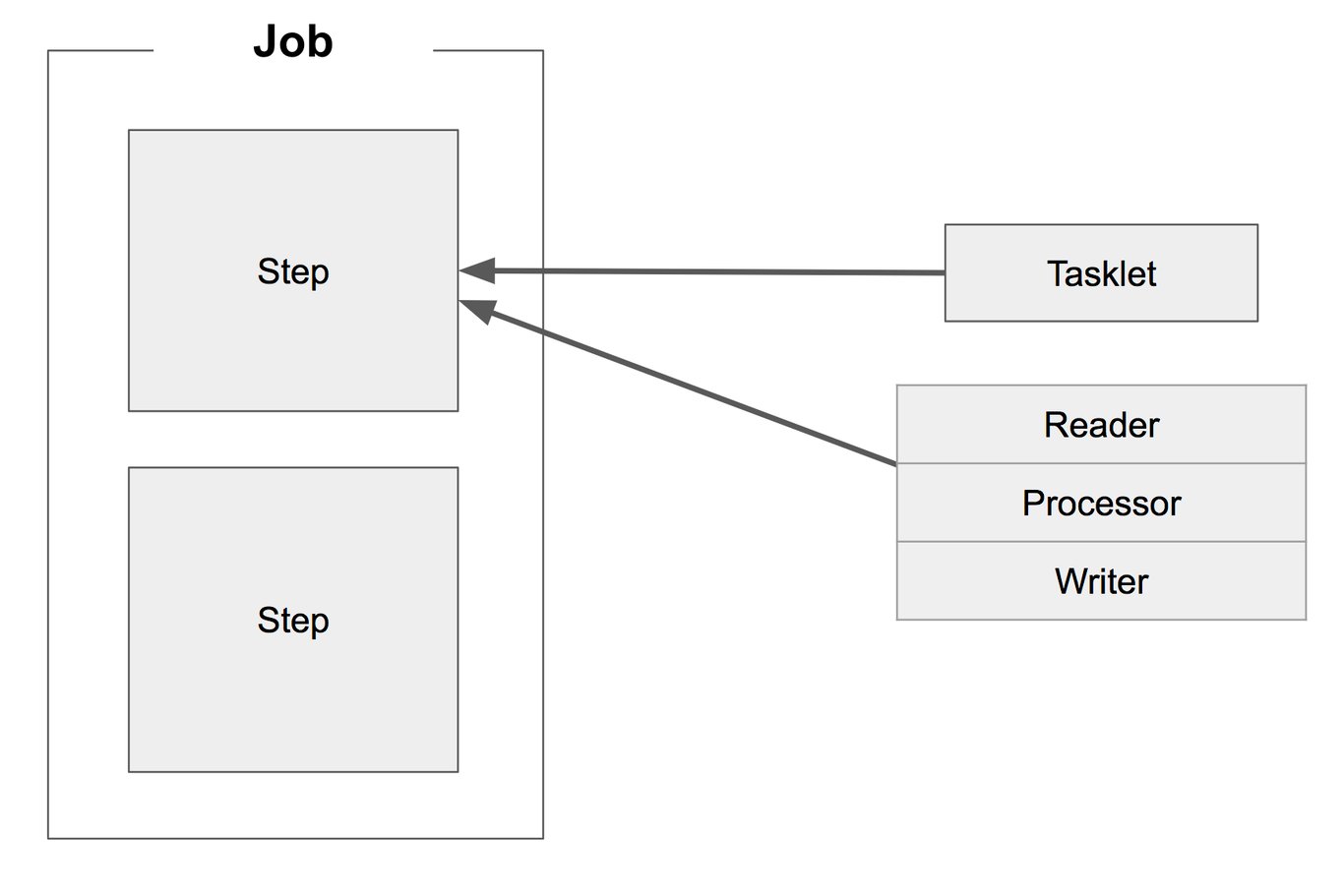
- Job:
- Step:메타데이터 테이블
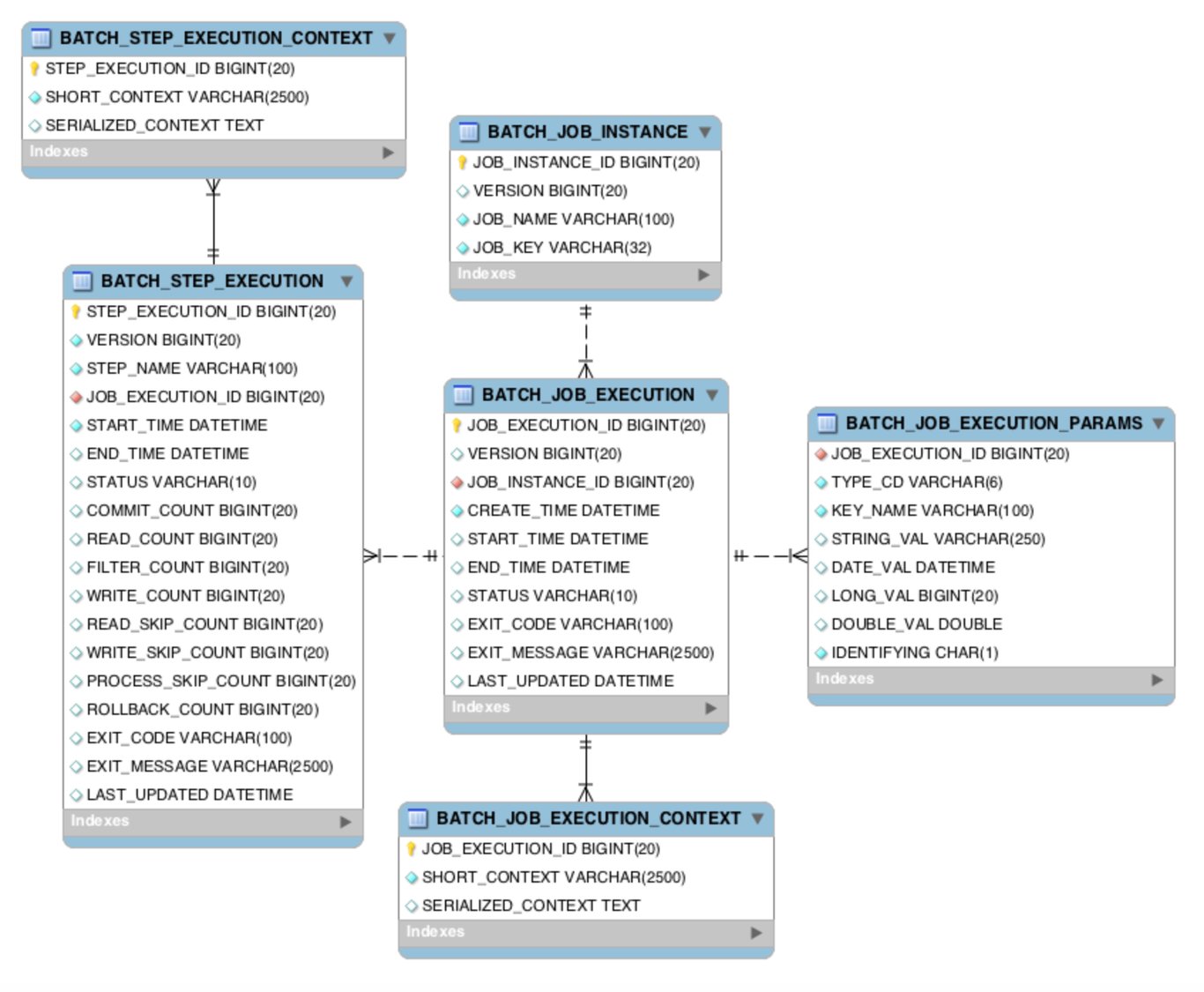
- 이전에 실행한 Job이 어떤 것들이 있는지
- 최근 실패한 Batch Parameter가 어떤 것들이 있고, 성공한 Job은 어떤것들이 있는지
- 다시 실행한다면 어디부터 시작할지
- 어떤 Job에 어떤 Step들이 있었고, Step들 중 성공,실패를 구분하여 저장BATCH_JOB_INSTANCE
- JOB_INSTANCE_ID -> 테이블의 PK
- JOB_NAME -> 수행한 BatchJobName
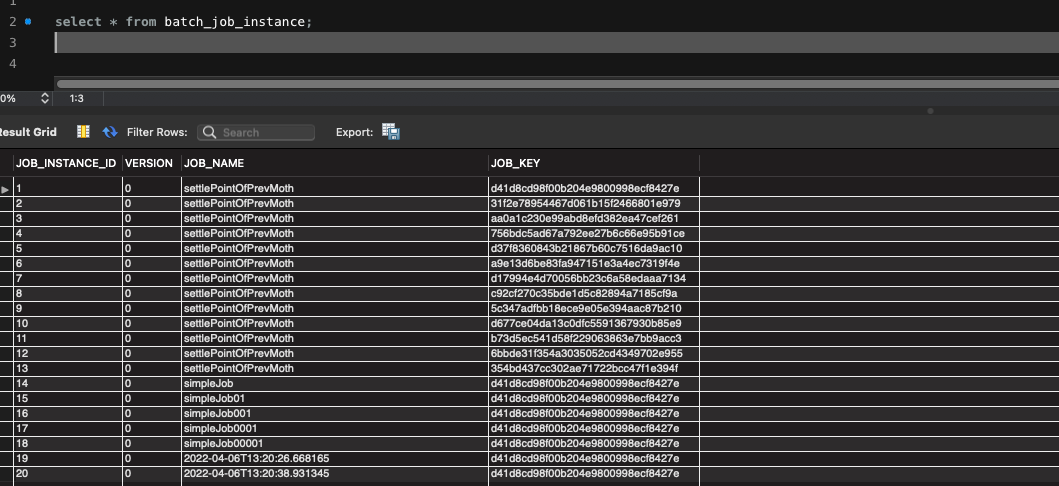
- 해당 테이블은 Job Parameter에 따라 생성되는 테이블이다.
- Job Parameter란 Spring Batch가 실행될때 외부에서 받을 수 있는 파라미터이다.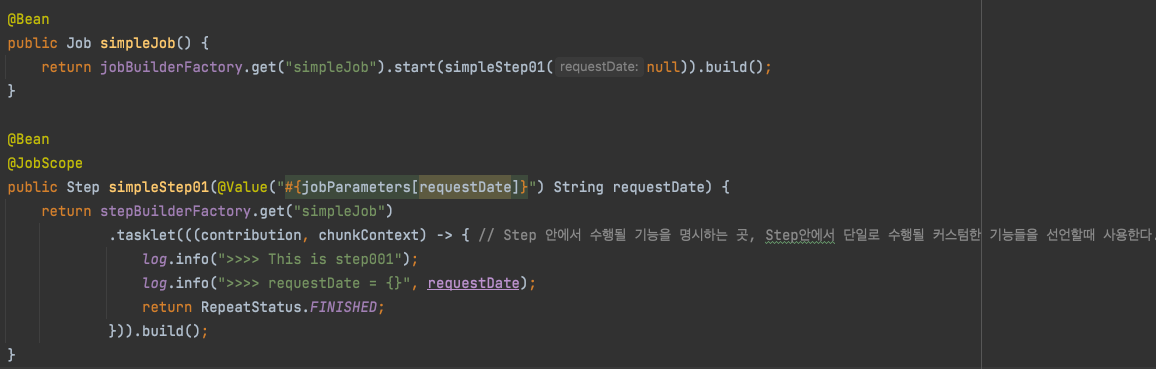


동일한 파라미터로 2번 이상 실행할경우 예외가 발생한다.
-> 즉 동일한 Job Parameter는 여러개 존재 할 수 없다.
BATCH_JOB_EXECUTION
- batch_job_instance 테이블과 부모자식 관계의 테이블이라고 생각하면 좋다
- 가장 큰 차이첨은 job_instance_id 는 unique key가 아니다. ( instance 테이블 PK)
- JOB의 실행 히스토리를 관리하는 테이블이라 볼 수 있다.
- Spring Batch는 동일한 Job Parameter로 성공한 기록이 있을때만 재수행이 안된다Next
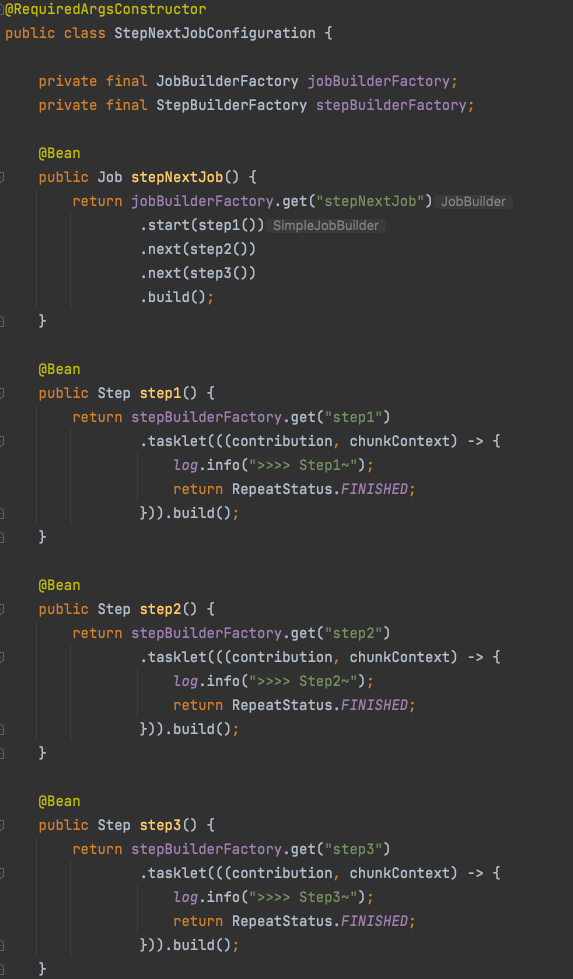

- step들을 순차적으로 연결시킬때 사용된다.
- 앞의 step에서 오류가 나면 나머지 뒤에 있는 step들은 실행되지 못한다.Next의 조건별 흐름제어
step1에서 정상일때는 step2로 오류가 났을때는 step3로 수행하길 원할경우를 대비해 Spring Batch Job에서는 조건별로 Step을 사용할 수 있다.
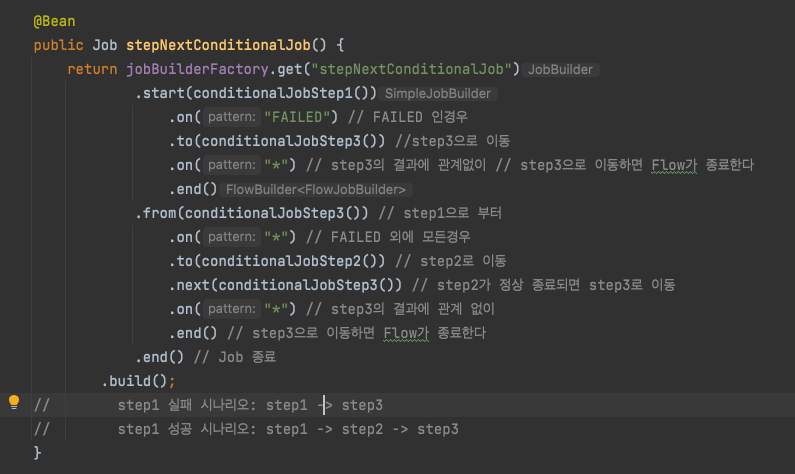
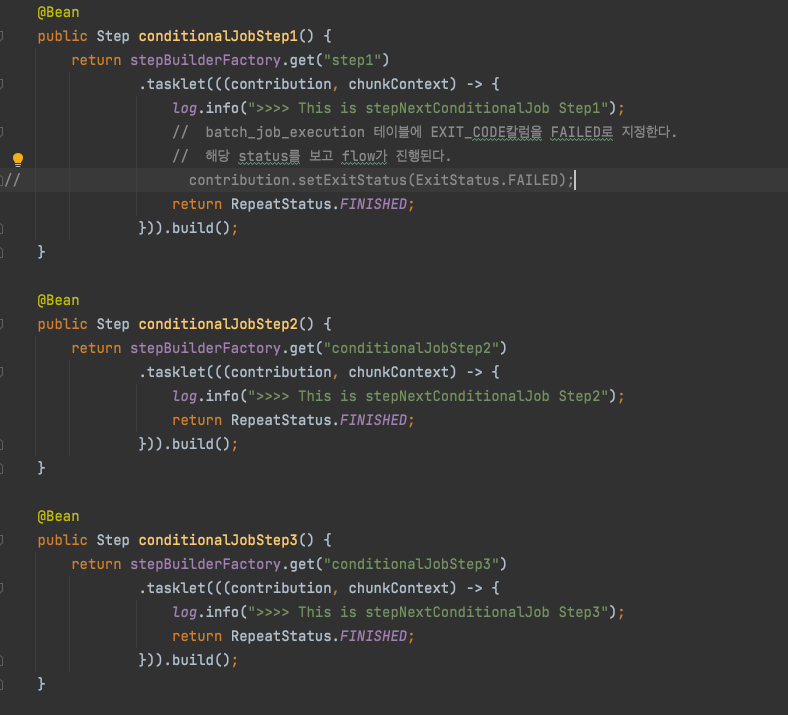
- on() -> 캐치할 ExitStatus 지정 ( * 일 경우 모든 ExitStatus)
- to() -> 다음으로 이동할 Step 지정
- from() -> 이벤트 리스너 역할로 FAILED되 있는 상태에서 추가로 이벤트 캐치하려면 from을 써야만 한다.Batch Status vs Exit Status
- Batch Status -> Job 또는 Step의 실행 결과를 Spring에서 기록할때 사용하는 Enum
- Exit Status -> Step의 실행 후 상태를 나타낸다.Decide
- Step의 결과에 따라 서로 다른 Step으로 이동할때 사용 한다.
- JobExecutionDecider는 Step들의 Flow속에서 분기만 담당한다
@Slf4j
@Configuration
@RequiredArgsConstructor
public class DeciderJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job deciderJob() {
return jobBuilderFactory.get("deciderJob")
.start(startStep())
.next(decider()) // 홀,짝 구분
.from(decider()) // decider의 상태가
.on("ODD") // ODD라면
.to(oddStep()) //oddStep으로 간다
.from(decider()) // decider의 상태가
.on("EVEN") // EVEN이라면
.to(evenStep()) //evenStep으로 간다
.end().build();
}
@Bean
public Step startStep() {
return stepBuilderFactory.get("startStep")
.tasklet((contribution, chunkContext) -> {
log.info(">>>>> START!");
return RepeatStatus.FINISHED;
}).build();
}
@Bean
public Step evenStep() {
return stepBuilderFactory.get("evenStep")
.tasklet(((contribution, chunkContext) -> {
log.info(">>>> 짝수");
return RepeatStatus.FINISHED;
})).build();
}
@Bean
public Step oddStep() {
return stepBuilderFactory.get("oddStep")
.tasklet(((contribution, chunkContext) -> {
log.info(">>>> 홀수");
return RepeatStatus.FINISHED;
})).build();
}
@Bean
public JobExecutionDecider decider() {
return new OddDecider();
}
public static class OddDecider implements JobExecutionDecider {
@Override
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
Random random = new Random();
int randomNumber = random.nextInt(50) +1;
log.info("랜덤숫자:{}", randomNumber);
if (randomNumber % 2 == 0) {
return new FlowExecutionStatus("EVEN");
} else {
return new FlowExecutionStatus("ODD");
}
}
}
}JobParameter와 Scope (@StepScope, @JobScope)
- JobParameter -> SpringBatch 외부 혹은 내부에서 파라미터를 받아 여러 Batch컴포넌트에서 사용할 수 있게 지원해주는 파라미터
- JobParameter를 사용하기 위해선 항상 Spring Batch전용 Scope를 선언해야 한다. (@StepScope, @JobScope)
- 사용법 -> @Value("#{jobParameters[파라미터명]}"}
- @JobScope는 Step 선언문에서 사용 가능하고, @StepScope는 Tasklet이나 ItemReader, ItemWriter, ItemProcessor에서 사용할 수 있다
- 두가지 Scope모두 각각의 실행 시점에 Bean이 생성되도록 지연된다.
- JobScope, StepScope 역시 Job이 실행되고 끝날때, Step이 실행되고 끝날때 생성/삭제가 이루어진다- Step 혹은 Job의 실행시점으로 지연시키면서 얻는 장점
1) JobParameter의 LateBinding이 가능하다, Application 실생 시점이 아닌 Controller or Service 와 같은 비즈니스로직 처리 단계에서 Job Parameter를 할당 시킬 수 있다.
2) 동일한 컴포넌트를 병렬 혹은 동시에 사용할 때 유용하다. @StepScope가 있다면 각각의 Step에서 별도의 Tasklet을 생성하고 관리하기 때문의 서로의 상태를 침범할 일이 없다.
Chunk
- Chunk란 데이터 덩어리로 작업 할 때 각 커밋 사이에 처리되는 row 수를 의미한다.
- 즉 Chunk지향 처리란 한번에 하나씩 데이터를 읽어 Chunk라는 덩어리를 만든 뒤, Chunk단위로 트랜잭션을 다루는 것을 말한다.
여기에서 트랜잭션의 의미는 Chunk단위로 트랜잭션을 수행하기 때문에 실패 한 경우 해당 Chunk만큼만 롤백이 되고 이전에 커밋된 트랜잭션 범위까지는 반영이 된다는 것 이다.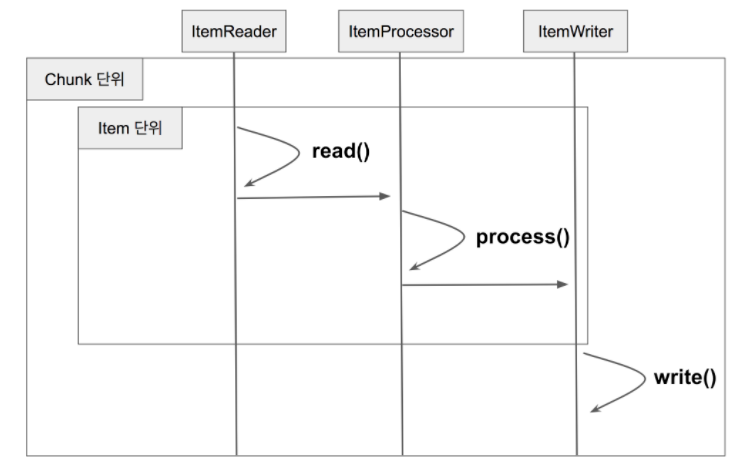
- reader와 process에서는 1건씩 데이터가 다루어지고, Writer에선 Chunk단위로 처리된다.
Page Size Vs Chunk Size
- Chunk Size는 한번에 처리될 트랜잭션의 단위를 이야기하낟.
- Page Size는 한번에 조회할 Item의 양을 이야기한다.
- 만약 PageSize가 10이고, ChunkSize가 50이라면 Page조회 5번이 일어나면 1번의 트랜잭션이 발생하여 Chunk가 처리된다. (일반적으로 두개의 단위는 동일하게 설정하길 권장한다)참고
- Spring Batch가 Chunk지향 처리를 하고 있으며 이를 Job과 Step으로 구성되어 있다.
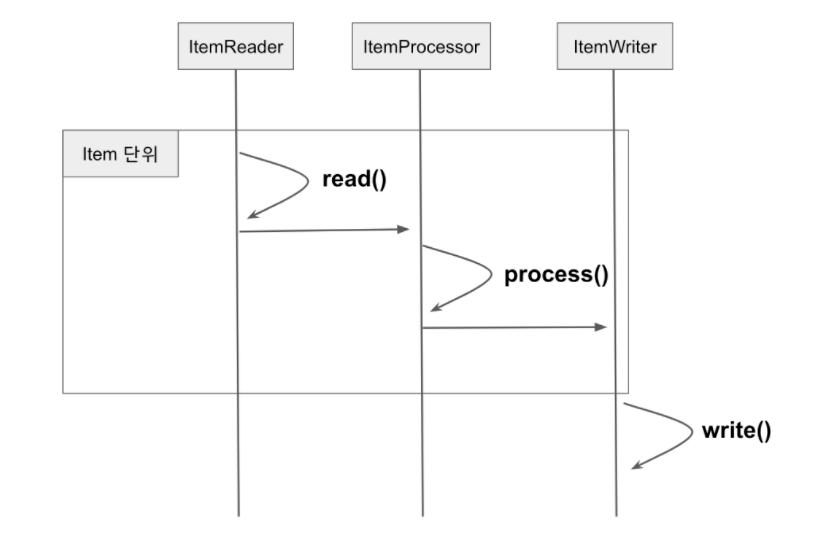
Step은 Tasklet단위로 처리되고, Tasklet중에서 ChunkOrientedTasklet을 통해 Chunk를 처리하며 이를 구성하는 3요소로
ItemReader,ItemWriter,ItemProcessor 가 있다.ItemReader
Spring Batch의 Chunk Tasklet은 아래와 같은 과정을 통해 진행된다.
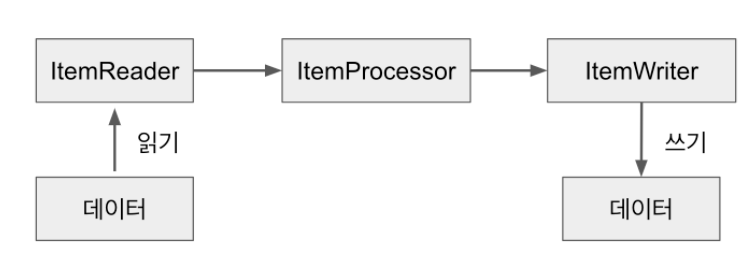
여기에서 데이터는 꼭 DB의 데이터만을 의미하지 않는다.
File, XML,JSON 등 다른 데이터 소스를 배치 처리의 입력으로 사용 할 수 있다.
Database Reader
보통 실시간 처리가 어려운 대용량 데이터나 대규모 데이터일 경우에 배치 어플리케이션을 작업합니다.
수백만개의 데이터를 조회하는 쿼리가 있는 경우에 해당 데이터를 모두 한 번에 메모리에 불러오길 원하는 개발자는 없을 것입니다.
그러나 Spring의 JdbcTemplate은 분할 처리를 지원하지 않기 때문에 (쿼리 결과를 그대로 반환하니) 개발자가 직접 limit, offset을 사용하는 등의 작업이 필요합니다.
Spring Batch는 이런 문제점을 해결하기 위해 2개의 Reader 타입을 지원합니다.CursorItemReader
CursorItemReader는 Paging과 다르게 Streaming 으로 데이터를 처리합니다.
쉽게 생각하시면 Database와 어플리케이션 사이에 통로를 하나 연결하고 하나씩 빨아들인다고 생각하시면 됩니다.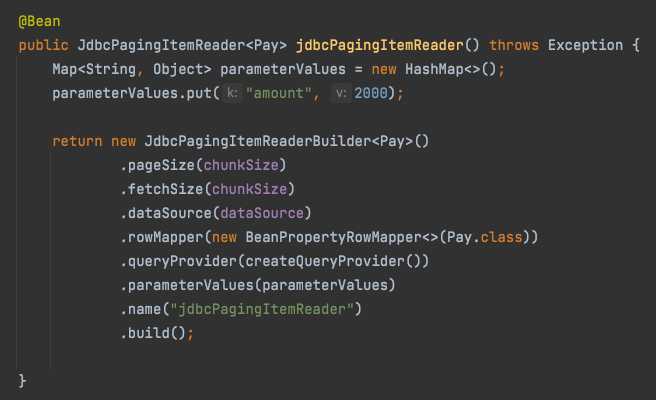
chunk
<Pay, Pay> 에서 첫번째 Pay는 Reader에서 반환할 타입이며, 두번째 Pay는 Writer에 파라미터로 넘어올 타입을 얘기합니다.
chunkSize로 인자값을 넣은 경우는 Reader & Writer가 묶일 Chunk 트랜잭션 범위입니다.
fetchSize
Database에서 한번에 가져올 데이터 양을 나타냅니다.
Paging과는 다른 것이, Paging은 실제 쿼리를 limit, offset을 이용해서 분할 처리하는 반면, Cursor는 쿼리는 분할 처리 없이 실행되나 내부적으로 가져오는 데이터는 FetchSize만큼 가져와 read()를 통해서 하나씩 가져옵니다.
dataSource
Database에 접근하기 위해 사용할 Datasource 객체를 할당합니다
rowMapper
쿼리 결과를 Java 인스턴스로 매핑하기 위한 Mapper 입니다.
커스텀하게 생성해서 사용할 수 도 있지만, 이렇게 될 경우 매번 Mapper 클래스를 생성해야 되서 보편적으로는 Spring에서 공식적으로 지원하는 BeanPropertyRowMapper.class를 많이 사용합니다
sql
Reader로 사용할 쿼리문을 사용하시면 됩니다.
name
reader의 이름을 지정합니다.
Bean의 이름이 아니며 Spring Batch의 ExecutionContext에서 저장되어질 이름입니다.
(출처:https://jojoldu.tistory.com/325?category=902551)
ItemWriter
- BeanMapped Vs columnMapped
-> Map<String, Object> 냐, Pay.class와 같은 Pojo 타입이냐 입니다.