
NoSQL
✏️ NoSQL 등장 배경
- 1998년 카를로 스트로찌(Carlo Strozzi)라는 엔지니어가 공개한 표준 SQL 인터페이스를 채용하지 않은 자신의 경량 Open Source 관계형 데이터베이스를 NoSQL이라고 명명한데서 유래
- 2009년에는 요한 오스칼손(Johan Oskarsson)이라는 엔지니어가 Open Source기반의 분산 데이터베이스 관련 행사를 준비하면서 NoSQL이라는 용어를 사용
- 2009년 이후 기존 관계형 데이터베이스 시스템의 주요 특성을 보장하는 ACID 특성을 제공하지 않지만, 뛰어난 확장성이나 성능 등의 특성을 갖는 비관계형, 분산 데이터베이스들이 등장, 이를 NoSQL이라는 용어를 보편적으로 사용하기 시작
✏️ NoSQL과 SQL 차이점
- 관계형 모델을 사용하지 않으며 테이블간의 조인 기능 없음
- 직접 프로그래밍을 하는 등의 비SQL 인터페이스를 통한 데이터 엑세스
- 대부분 여러 대의 데이터베이스 서비스를 묶어서(클러스터링) 하나의 데이터베이스를 구성
- 관계형 데이터베이스에서는 지원하는 Data퍼리 완결성(Transaction ACID) 미보장
- 데이터의 스키마와 속성들을 다양하게 수용 및 동적 정의(Schema-less)
- 데이터베이스의 중단 없는 서비스와 자동 복구 기능지원
- 다수가 Open Source로 제공
- 확장성, 가용성, 높은 성능
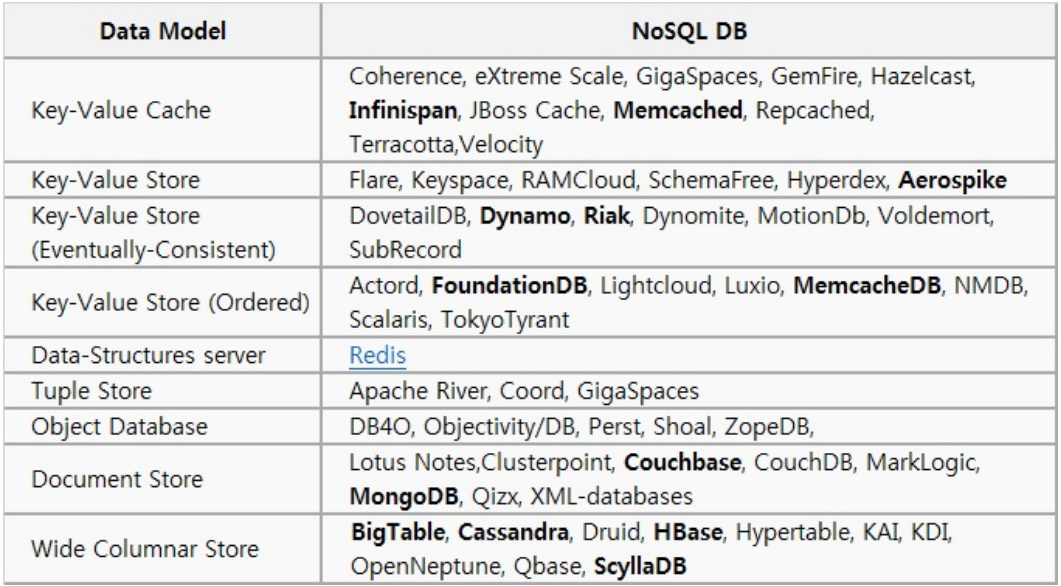
✏️ NoSQL 종류
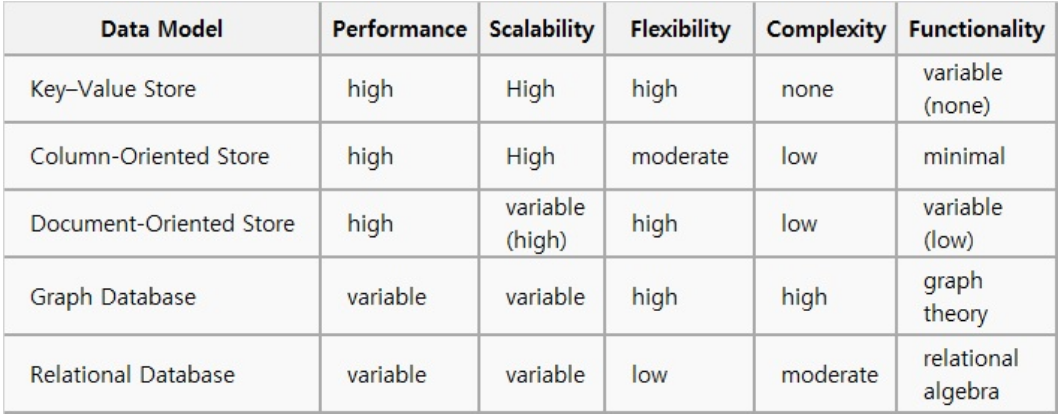
✏️ NoSQL 성능
MongoDB
✏️ MongoDB란?
- NoSQL 중 가장 많이 쓰이는 비관계형 데이터베이스 관리 시스템으로 자유 오픈소스 소프트웨어
- C++로 작성된 오픈소스 문서지향(Document-Oriented) 크로스 플랫폼 데이터베이스
✏️ MongoDB 특징
- 가용성, 확장성, 성능
- Document 기반 데이터베이스
- Database -> Collection -> Document -> Field 계층
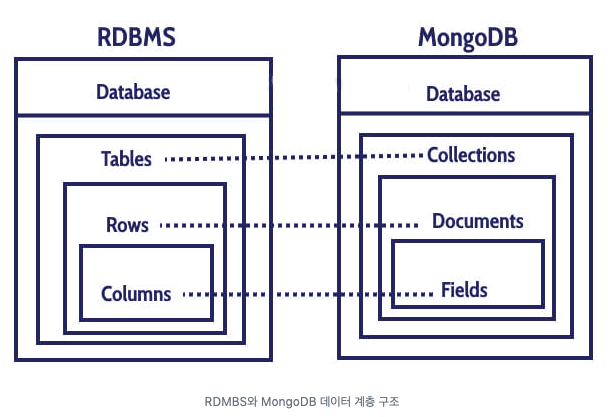
- Database -> Collection -> Document -> Field 계층
- ObjectId (12 bytes)
- UNIX Timestamp(4 bytes) + Random Value(5 bytes) + Count (3 bytes)
- Primary Key와 같은 고유한 키
- 클라이언트에서 생성
- MongoDB 클러스터 내에서 Sharding된 데이터를 빠르게 가져올 수 있음
- BASE (완화된 ACID)
- Basically Avaliable : 언제든지 사용 가능(가용성이 필요)
- Soft state : 외부의 개입이 없어도 정보가 변경될 수 있다는 의미
- Eventually consistent : 일시적으로 일관적이지 않은 상태가 되어도 일정 시간 후에는 일관적인 상태가 되어야 한다는 의미
- Full Index Support
- Single Field Indexes : 기본적인 인덱스 타입
- Compound Indexes : RDBMS의 복합 인덱스 타입
- Multikey Indexes : 배열에 매칭되는 값이 하나라도 있으면 인덱스에 추가되는 멀티키 인덱스
- Geospatial Indexes and Queries : 위치 기반 인덱스와 쿼리
- Text Indexes : String에도 인덱싱이 가능
- Hashed Index : BTree 인덱스가 아닌 Hash 타입 인덱스도 사용 가능
- Replicaset & High Availability : 간단한 설정으로 데이터 복제 지원(가용성)
- Auto-Sharding : 처음부터 자동으로 데이터를 분산하여 저장하며, 하나의 컬렉션처럼 사용할 수 있게 지원(scale-out)
- Aggregation Pipeline : 문서는 여러 단계의 파이프라인을 거쳐서 변화하고, 하나의 문서 형태로 집계 가능
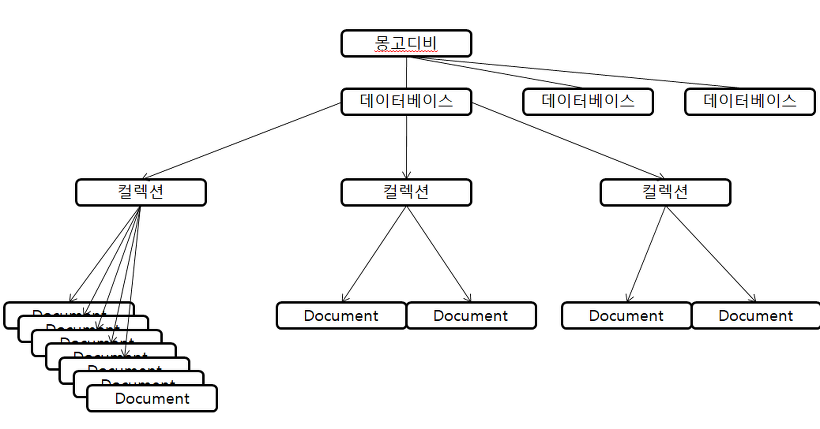
✏️ MongoDB 구조
✏️ MongoDB 장점
- Schema-less 구조(다양한 형태의 데이터 저장 가능)
- Read/Write 성능이 뛰어남
- Scale Out 구조 (많은 데이터 저장 가능, 장비 확장이 간단)
- JSON 구조(데이터를 직관적으로 이해가능)
- 사용 방법이 쉽고 개발이 편리
✏️ MongoDB 단점
- 데이터 업데이트 중 장애 발생 시, 데이터 손실 가능
- 많은 인덱스 사용시 충분한 메모리 확보 필요
- 데이터 공간 소모가 RDBMS에 비해 많음(비효율적인 Key 중복 입력)
- 복잡한 JOIN 사용시 성능 제약이 따름
- 트랜잭션 지원이 RDBMS 대비 미약
- 제공되는 MapReduce 작업이 Hadoop에 비해 성능이 떨어짐
✏️ 사용 사례
- 적절
- 로그성 데이터나 빅데이터 처리의 중간 저장소
- 설정 데이터의 보관소
- NULL 필드가 많이 존재할 때
- 압도적인 포퍼먼스가 필요할 때
- NoSQL 계열에서 압도적인 Index활용도
- 집계 연산, paging, 복잡한 쿼리가 필요할 때
- 스키마 관리가 불필요함
- 부적절
- 데이터 무결성이 가장 중요한 가치일 때
- 데이터 처리량보다 일관성 있는 데이터 구조가 중요할 때
- 운용 이슈에 대한 우려 사항들이 해소가 덜 됐을 때
- 데이터 무결성이 무엇보다 중요할 때
- 엄격한 데이터 타입 검사나 연관 관계가 중요할 때
✏️ MongoDB 면접 질문 예제
참고

프로그래밍 언어 공부 정리