Part1 : Machine Learning의 개념과 종류
Machine Learning의 개념
"무엇(X)으로 무엇(Y)을 예측하고 싶다"
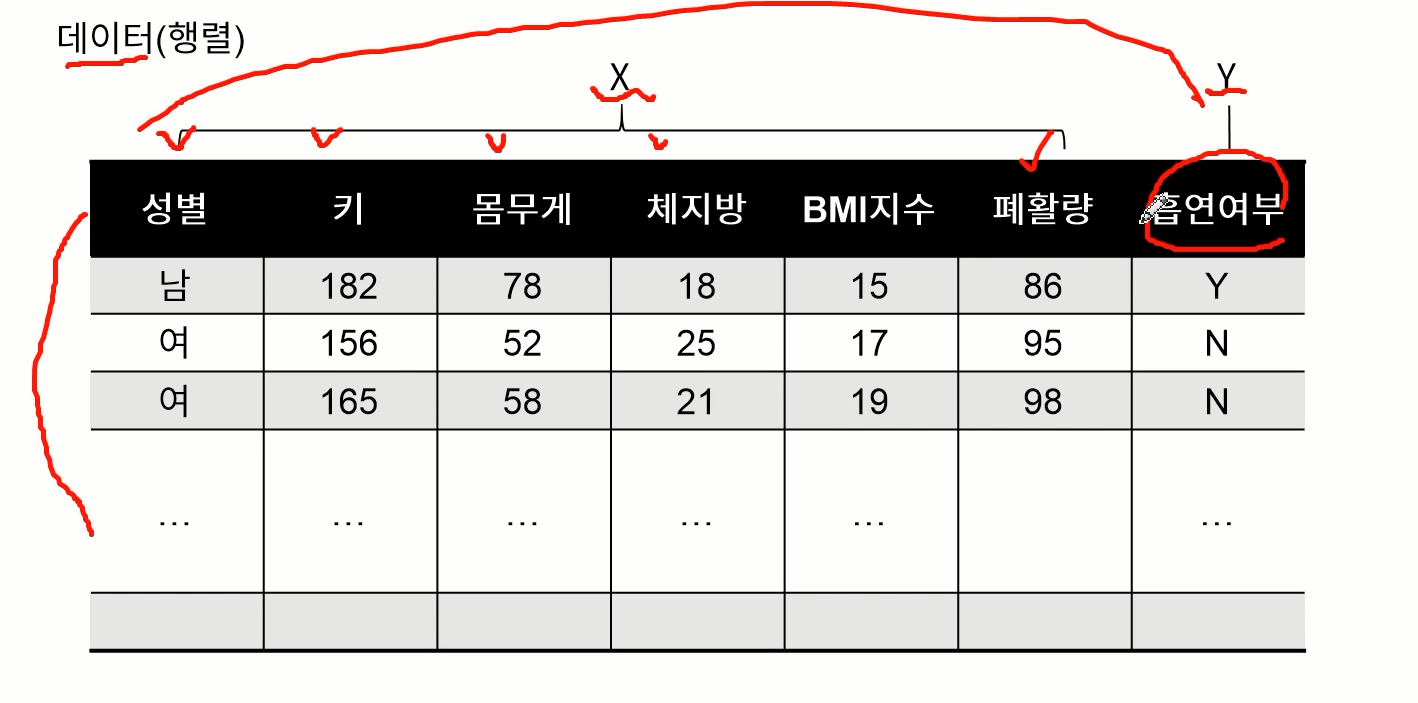
데이터는 행과 열로 이루어져 있어야 한다.
예측하고 싶은 대상을 Y로 두었고 Y에 쓰이는 대상을 X로 주었다.
X를 가지고 Y를 예측하고 싶을때 이럴경우 머신러닝을 사용한다
기계 학습 또는 머신 러닝(영어 : machine learning)은 인공 지능의 한 분야로, 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야를 말한다 (위키피디아)
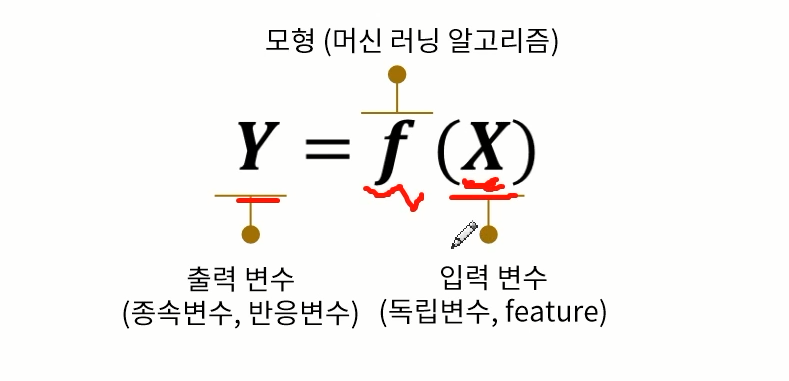
- 주어진 데이터를 통해서 입력변수와 출력변수간의 관계를 만드는 함수 f를 만드는 것
- 주어진 데이터 속에서 데이터의 특징을 찾아내는 함수 f를 만드는 것
즉 함수 f가 머신러닝이다. 그런데 하나 더 x를 가지고 y를 예측하는 것 뿐만 아니라 x에 대해서 x끼리의 숨겨진 패턴을 찾아낸다거나 이 데이터안에서 새로운 특징을 찾아내는거 또한 머신러닝이다.
Machine Learning으로 할 수 있는 것들

예측 탐지 모델, 이상 탐지 모델, 이미지 분류 모델 등등
X들로만 가지고 할 수 있는 것들 : Segmentation, 로그기록을 이용해서 맞춤 상품 추천 시스템, 소셜 및 사회 이슈 파악 등등
f란 무엇인가 (회귀 분석인 경우)
- f를 구하기 위해서 입력 변수와 출력 변수가 필요함
- p개의 입력 변수 X1, X2, ... Xp가 있고, 출력 변수 Y가 있을 때, X = (X1, X2, ..., Xp)라 하면 입력 변수와 출력 변수의 관계를 나타내는 식은 다음과 같음
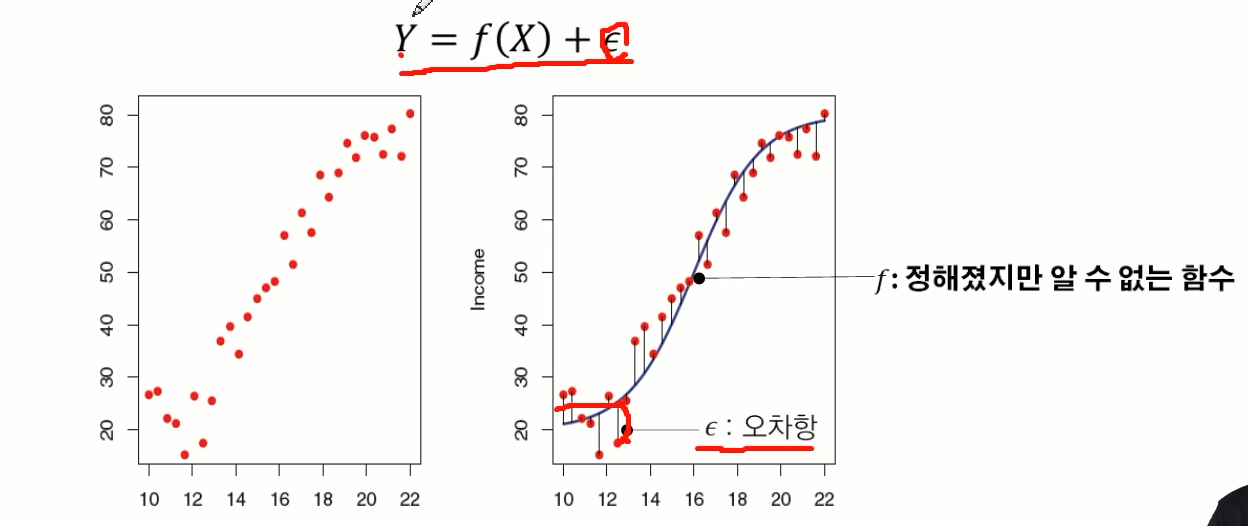
앱실론 : 오차항
예측치와 실제 값의 차이를 오차항(앱실론)이라 부른다.
실제 Y값을 예측 할려면 f(X) + 앱실론 을 해야 한다.
함수 f : 정해졌지만 알 수 없는 함수
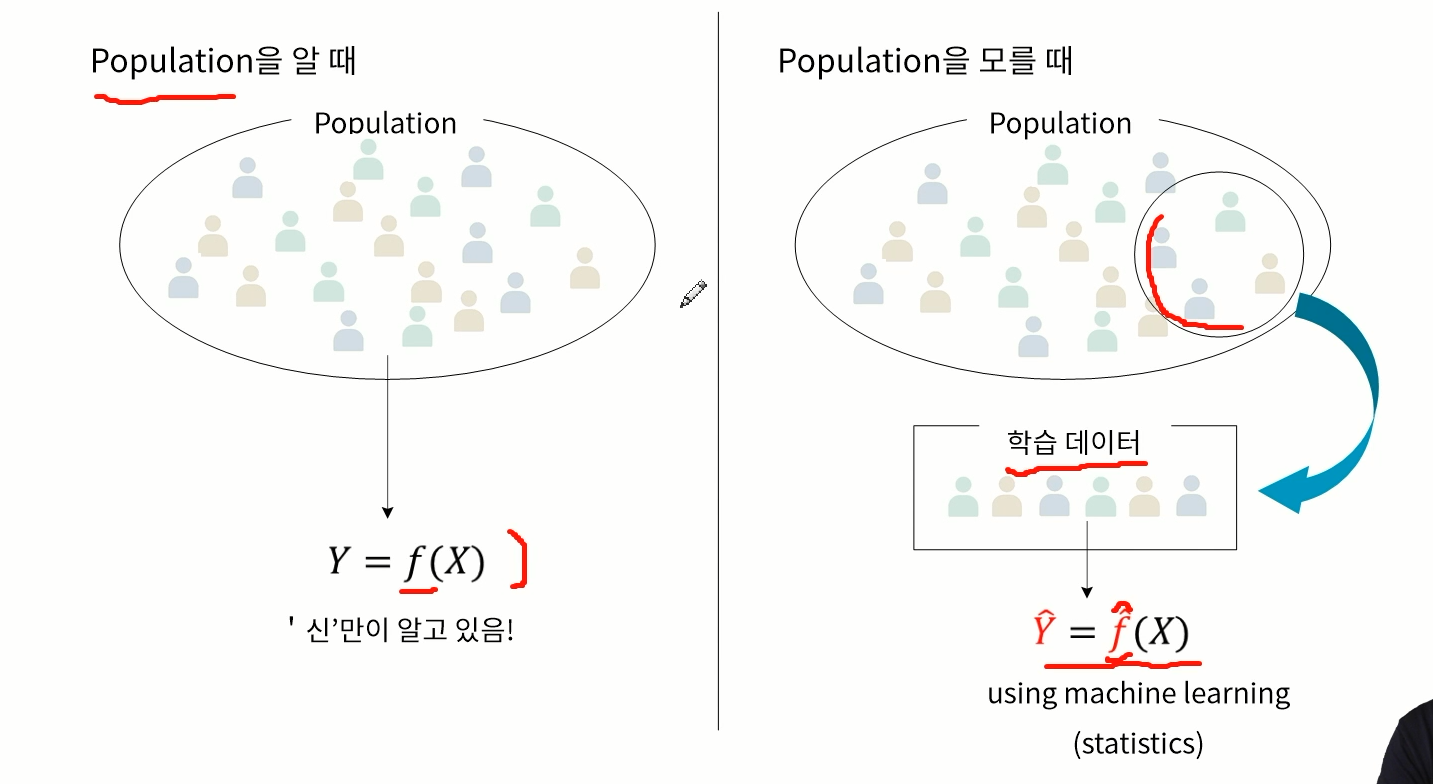
Population(모집단)을 알고 있다면 함수 f는 완벽하게 알 수 있다. 허나 모집단을 완벽하게 알 수 없으니 예측을 하는것
Population을 모를 때 샘플을 뽑아서 데이터를 학습하고 그 데이터를 가지고 함수 f를 추정한다. (추정을 하기 때문에 모자를 씌운다) 즉 Y햇
지도학습과 비지도학습
지도 학습(supervised learning)

Y가 연속형 변수일 때 우리는 이 문제를 회귀(regression) 문제 라고 이야기 하고, 그때의 모형을 회귀 모형(regression model)이라 한다. Y가 연속형이다 라는 뜻은 Y가 어떠한 실수값을 가질때를 얘기한다. 키, 몸무게, BMI 지수 이런것들을 다 모두 연속형 변수라고 한다.
Y가 이산형 변수를 가질 때 즉 어떠한 클래스를 가질 때 우리는 이 문제를 분류(Classification) 문제 라고 이야기 하고 이 때의 모형을 분류 모형(Classification model)이라 한다. 이산형 변수라는 것은 성별, 흡연여부, 질병여부, 주가 오른다 내린다, 불량이다 정상이다, 비만여부 등 이런것들을 이산형 변수라고 한다.
비지도 학습(unsupervised learning)
- 출력 변수(Y)가 존재하지 않고, 입력 변수(X)간의 관계에 대해 모델리 ㅇ하는 것
- 군집 분석 - 유사한 데이터끼리 그룹화
- PCA - 독립변수들의 차원을 축소화

X들끼리 어떠한 패턴을 찾아내는것을 비지도학습이라 한다.
가장 대표적인 예가 군집 분석이다.
PCA는 새로운 축을 만들어서 아에 새로운 변수를 만드는것이 PCA 기법이다.
강화학습(reinforcementlearning)
- 수 많은 시뮬레이션을 통해 현재의 선택이 먼 미래에 보상이 최대가 되도록 학습
- Agent가 action을 취하고 환경에서 보상을 받고 이 보상이 최대가 되도록 최적의 action을 취하는 방법을 배움
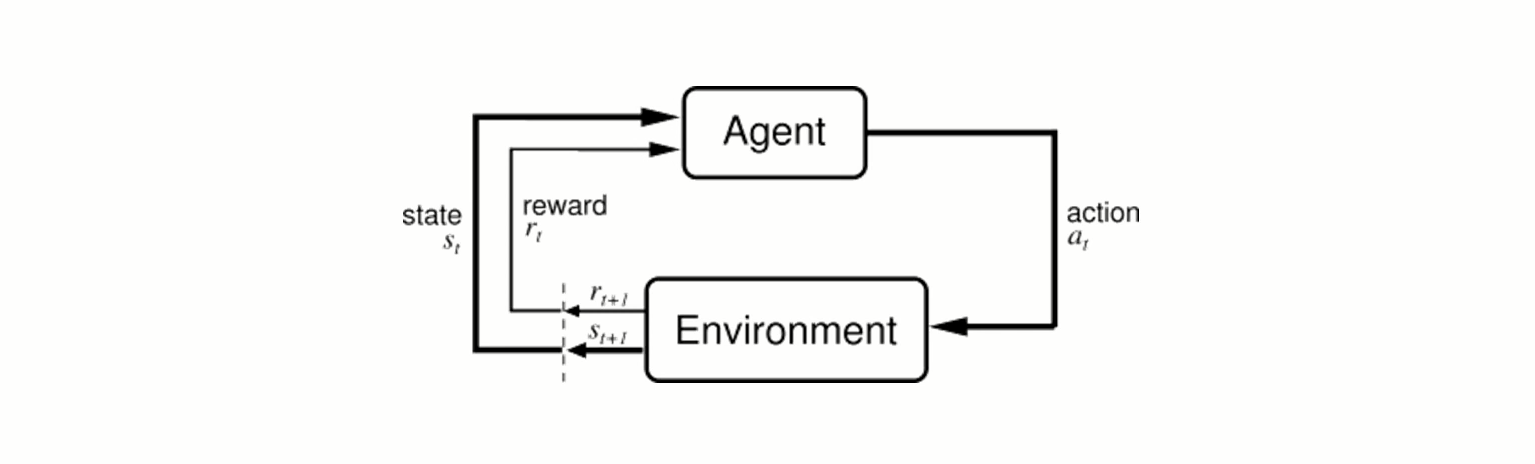
최근에는 강화학습도 머신러닝의 일부라고 주장하는 사람들도 많다.
에이전트가 어떤 상태일때 어떤 액션을 취해야 먼 미래에 큰 보상을 받느냐가 기준이된다.
강화학습의 가장 유명한 예 : 알파고 -> 에이전트 : 바둑기사, 액션 : 바둑의 모든 수 state : 바둑 판, reward : 대국이 끝났을 대 이겼느냐 졌느냐를 따지는것
정리
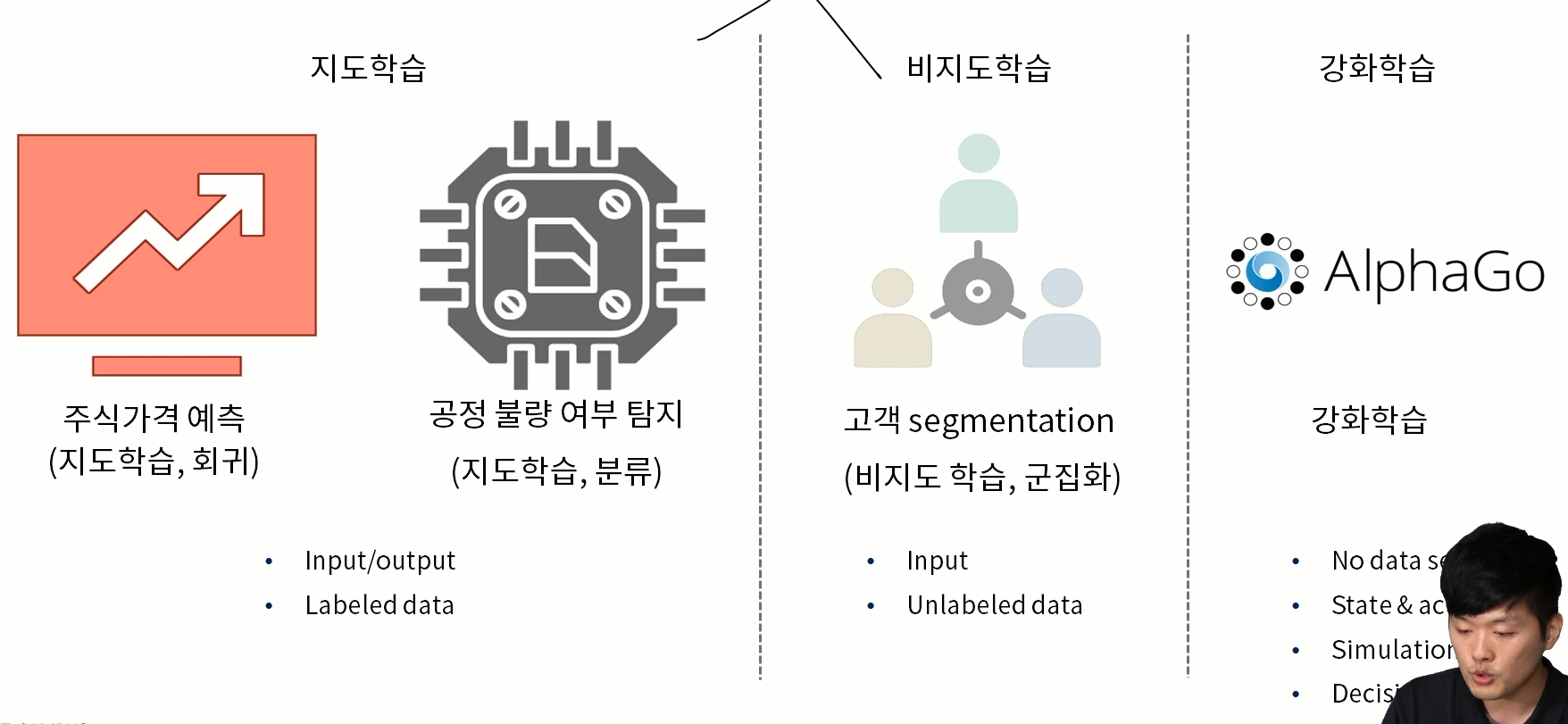
머신러닝은 지도학습과 비지도학습으로 나뉠수 있는데 지도학습은 회귀와 분류로 나누고
비지도학습은 PCA나 군집화 기타 등등 많은 알고리즘들이 있고 두개의 큰 차이점은 Labeled data의 존재유무 차이이다.
요즘에는 강화학습도 머신러닝의 일부라고 주장하는 사람들도 있다.
Machine Learning의 종류
선형 회귀분석(Liner Regression)
- 독립변수와 종속변수가 선형적인 관계가 있다라는 가정하에 분석
- 직선을 통해 종속변수를 예측하기 때문에 독립변수의 중요도와 영향력을 파악하기 쉬움
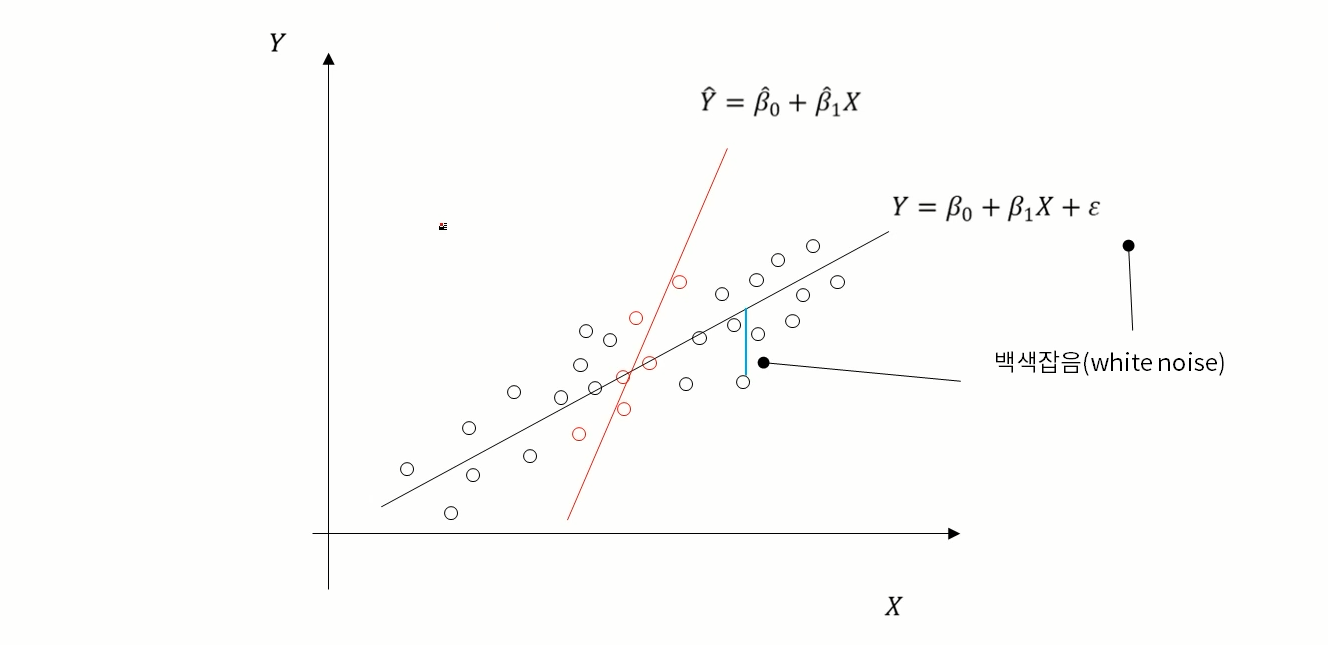
선형 회귀분석은 어떤 직선을 그어서 이 직선을 가지고 X를 가지고 Y를 예측하고 싶어 한다
선형적인 관계가 있다 : X가 증가/감소할때 Y도 증가/감소해야 선형적인 관계가 있다라고 한다
단점은 비선형관계에 관해서는 표현을 잘 못한다.
의사결정나무(Decision Tree)
- 독립 변수의 조건에 따라 종속변수를 분리 (비가 내린다 -> 축구를 하지 않는다)
- 이해하기 쉬우나 overfitting이 잘 일어남

이 모델은 너무 직관적이다. 머신러닝을 잘 모르는 사람들도 이 그림을 보면 아 이런 모델이구나 라고 생각할 수 있을 정도로 직관적이다.
간단한 문제에는 잘 맞고 복잡한 문제에는 잘 맞지 않는 단점이 있다.
KNN(K-Nearest Neighbor)
- 새로 들어온 데이터의 주변 k개의 데이터의 class로 분류하는 기법
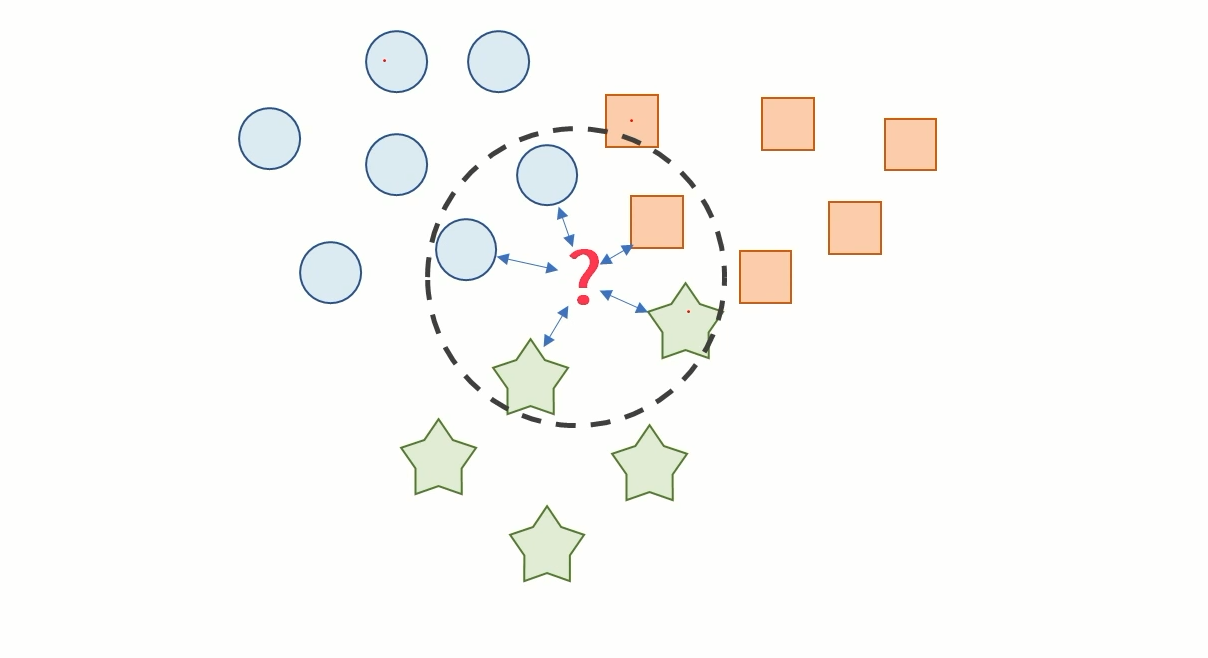
굉장히 간단한 모델이다.
이 데이터 내에서 3개의 클래스가 있다고 했을 때 물음표에 해당하는 데이터가 들어왔을때 이 주변 k개 데이터를 봐서 어느 클래스에 더 가까운지 묻고 그에 해당하는 대답에 대한 클래스로 분류하는것이 KNN이다. 여기서 k는 사람이 지정해주는 거라 k에 따라서 성능이 달라진다.
사람이 지정해 주어야 하는 파라미터를 하이퍼 파라미터라고 한다.
Neural Network
- 입력, 은닉, 출력층으로 구성된 모형으로서 각 층을 연결하는 노드의 가중치를 업데이트하면서 학습
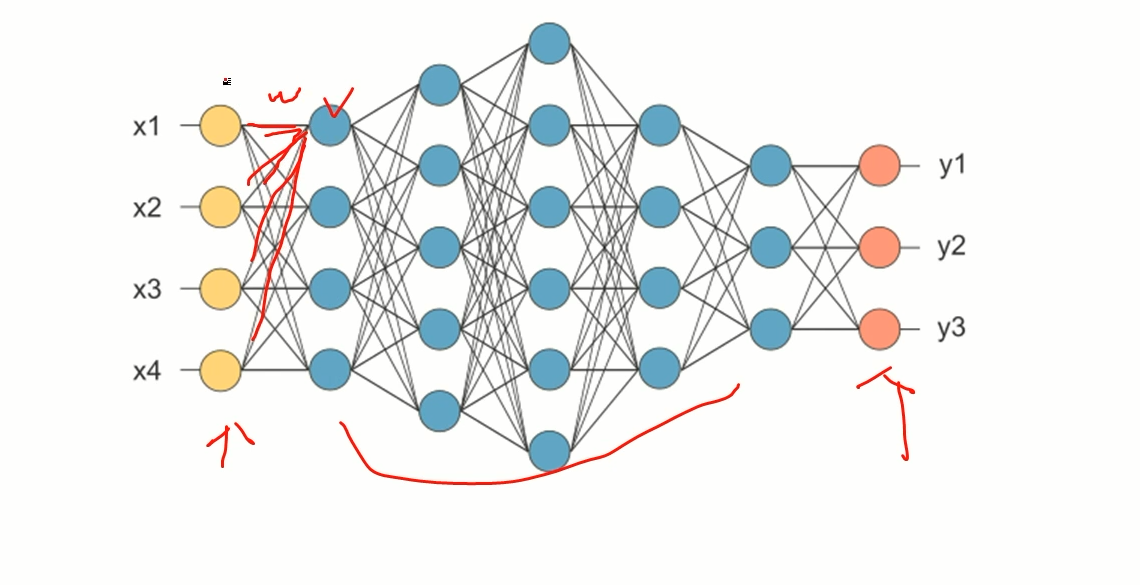
딥러닝 모델의 근간이 되는 네트워크 모델이다.
수 많은 직선을 이용을 해서 복잡한 모형을 만들 수 있게 되는게 뉴럴 네트워크이다.
출력값을 내 뱉고 실제값과 출력값의 차이를 보고 다시 weight를 업데이트 시켜 분류가 잘 되게끔 학습을 시키는게 뉴럴 네트워크의 기본 원리라고 생각하면 된다.
치명적인 단점은 오버피팅이 너무 잘된다. 그래서 잘 쓰이지 않게 되었다.
SVM(Support Vector Machine)
- Class 간의 거리(margin)가 최대가 되도록 decision boundary를 만드는 방법
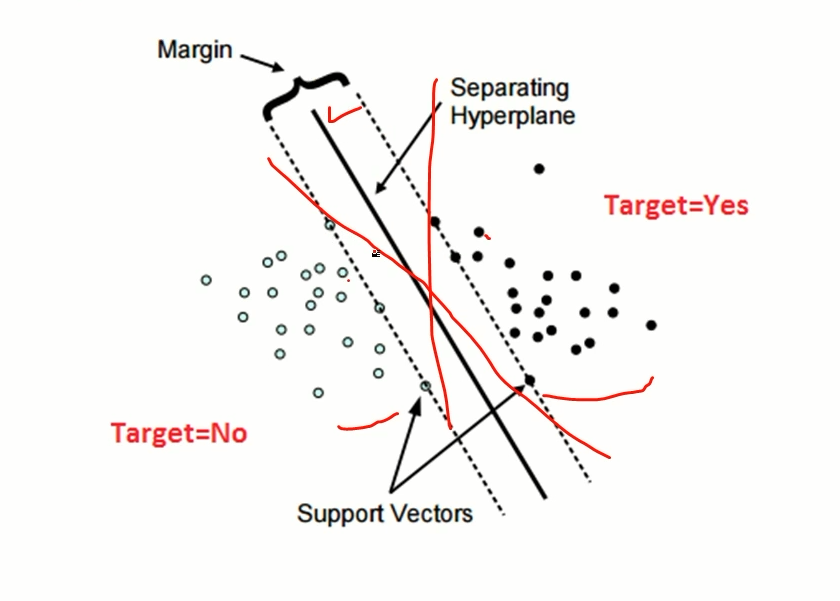
2000년대 초중반까지 잘 쓰인 모델
이 클래스간의 거리가 최대가 되게끔 직선을 긋기 때문에 좀 더 decision boundary를 좋게 그을 수 있다.
실제 데이터에는 잘 맞지않는 오버피팅이 잘 발생하였다.
SVM은 학습 과정 내에서 어느정도 오차는 허용한다.
학습하는 시간이 너무 오래걸리는 단점이 있다. 데이터가 커질 수록 더더욱 오래걸린다.
예를들어 일반적인 데스크탑인 경우 10000개의 데이터라고 가정할때, 칼럼이 4000개라면 SVM은 하루정도 걸릴수 있다.
Ensemble Learning
- 여러 개의 모델(classifier or base learner)을 결합하여 사용하는 모델
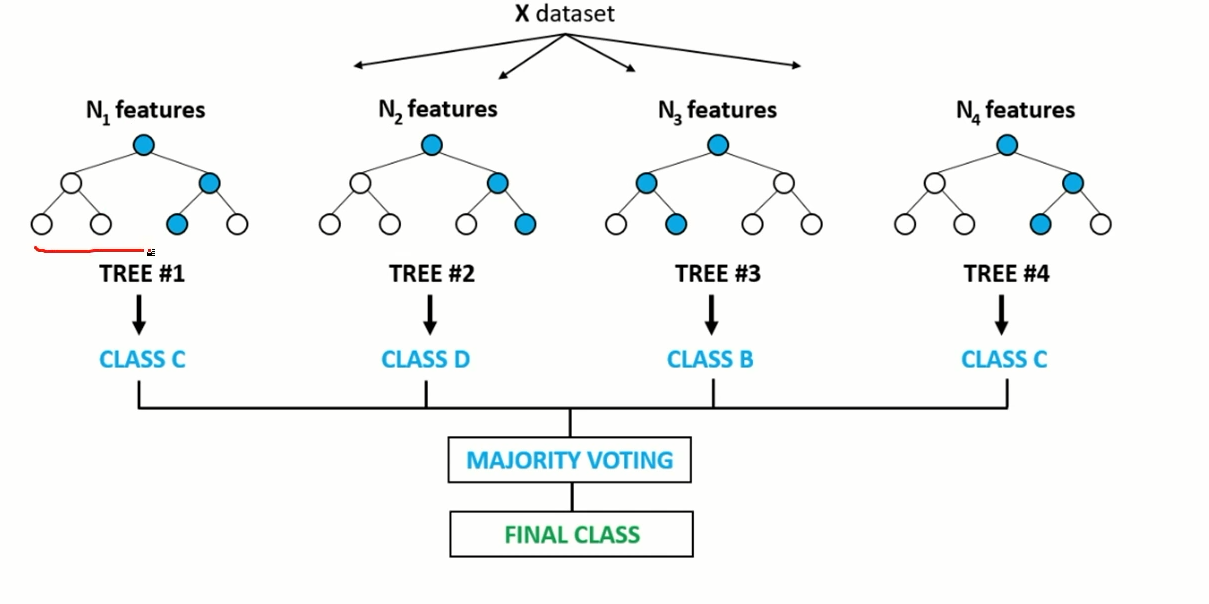
요즘 가장 많이 쓰이고 있는 앙상블 러닝
앙상블이라는 뜻 자체가 화합을 이루다 조화를 이루다라는 뜻
앙상블 러닝의 기본 모델은 classifier, base learner 이다.
디시전 트리를 많이 사용 한다. 디시전 트리를 기반으로 앙상블 러닝을 많이 사용하고 크게 3가지 정의가 있는데 다음시간에 배움.
여러개의 모델을 만든 다음에 데이터가 들어 왔을 때 예측을 하고 각각의 모델들이 아웃풋을 내뱉을건데 그때의 아웃풋을 평균을 내거나 투표를 한다.
앙상블 러닝 같은 경우에는 이 베이스 언어를 어떻게하면 다양하게 만들 수 있을까 좀 더 다양한 모델을 만들어서 하나의 새로운 성능이 좋은 분류기를 만들 수 있을까가 핵심이다.
앙상블 러닝에 크게 3가지 정의가 있을뿐이지 그 3개가 전부가 아니다.
K-means clustering
- Label 없이 데이터의 군집으로 k개로 생성
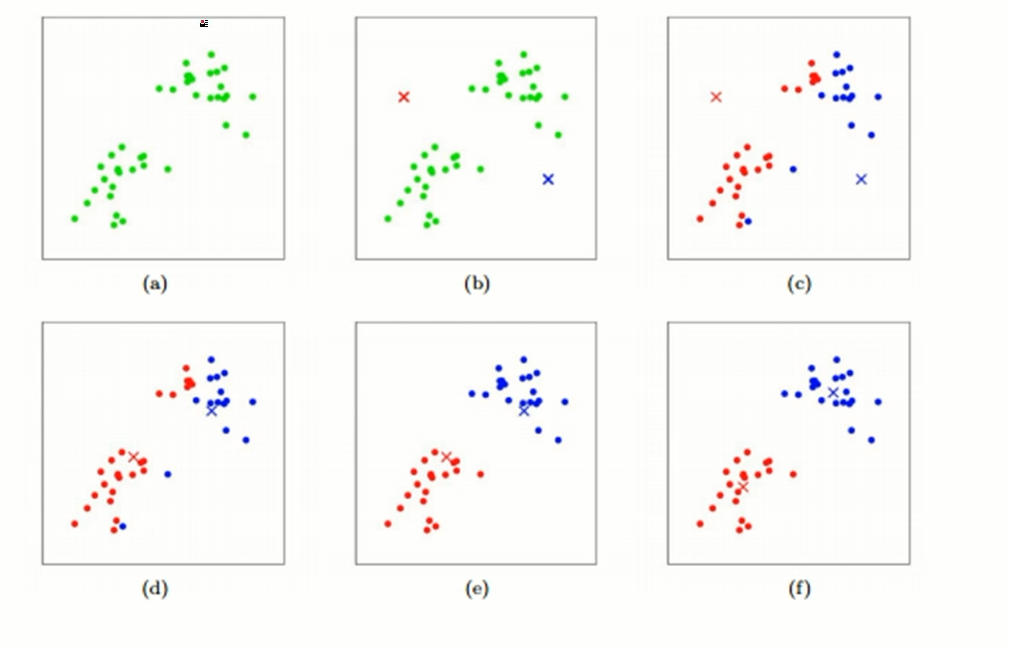
언슈퍼바이저드 러닝의 가장 대표적인 예인 군집분석이고 가장 유명한 K-means clustering
데이터가 (a)처럼 되어있따고 가정 하면은 랜덤하게 포인트 2개를 찍고(b) 그 다음에 이 주변에 가까운 각각의 데이터들을 할당을 시킨다(c) 그 다음에 이 데이터의 중심점을 다시 찍는다(d) 다시 그 주변의 데이터들을 할당한다(e) 또 다시 데이터의 중심점을 찍는다(f)
k개를 어떻게 설정에 하느냐에 따라서 성능이 달라지는 단점이 있다.
