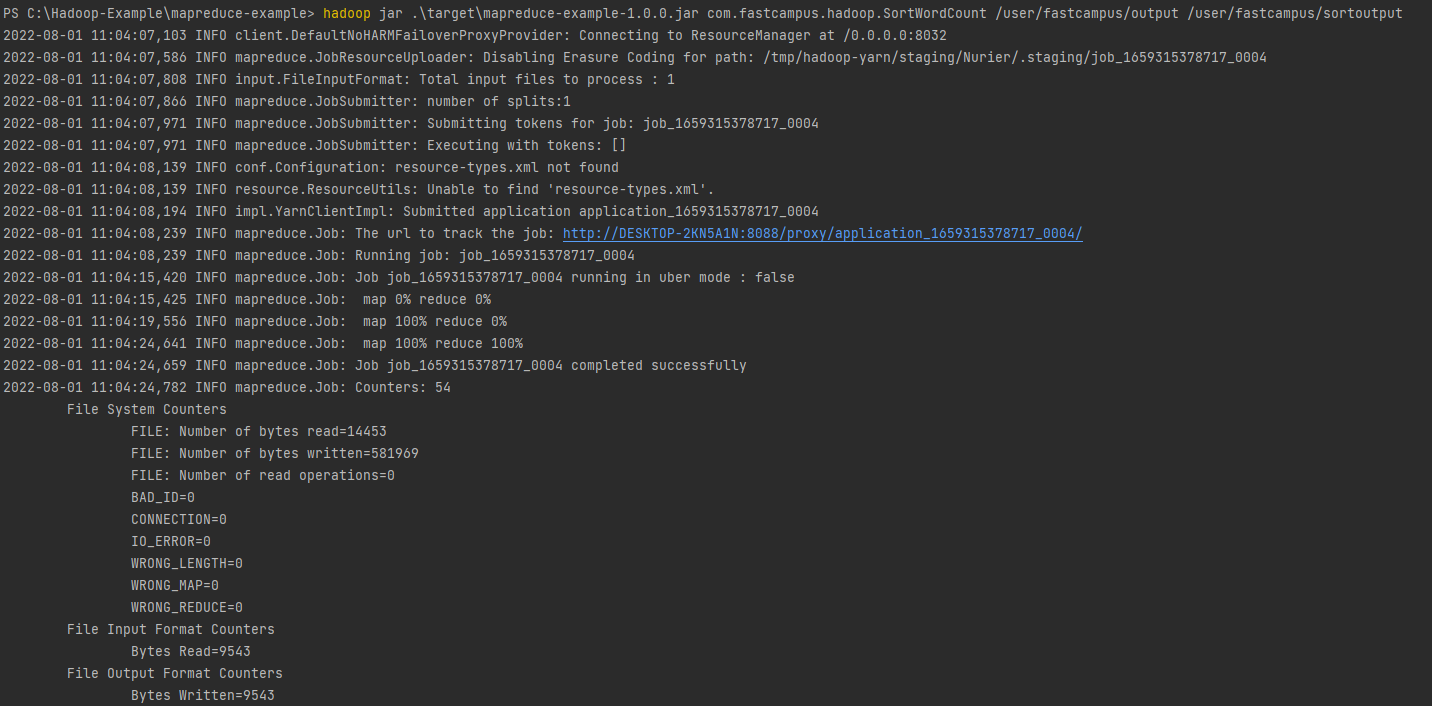
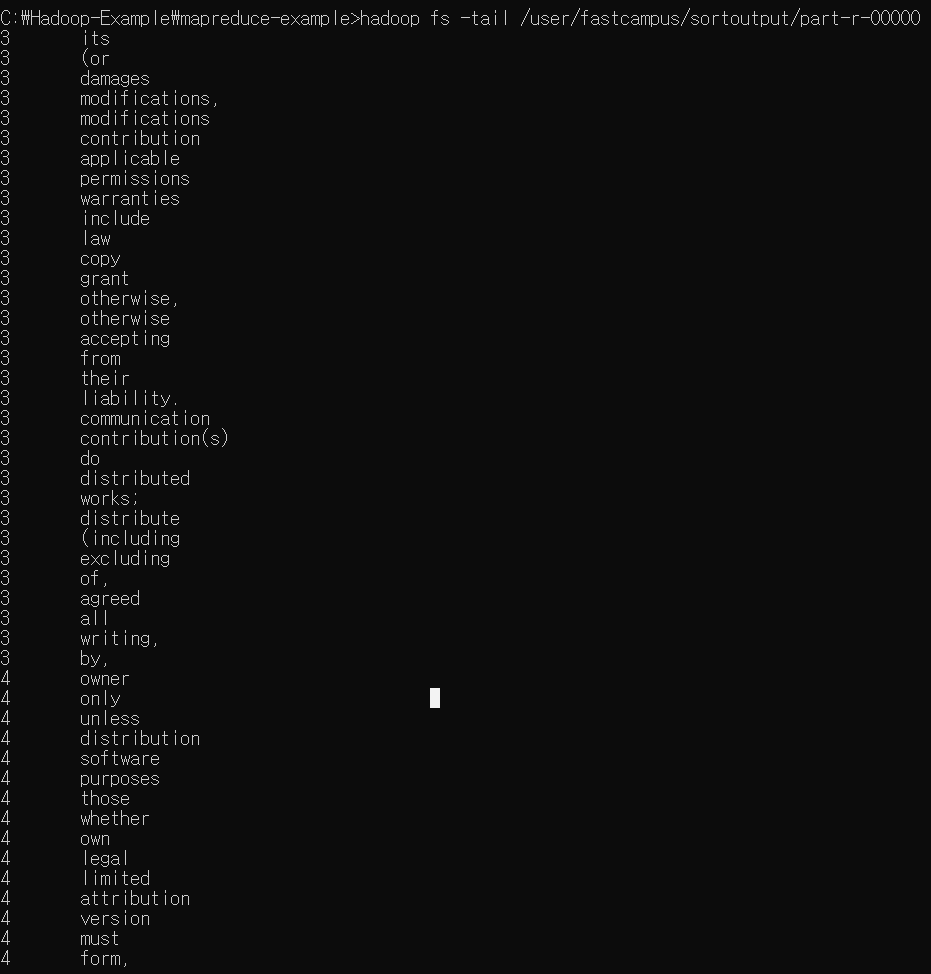
정렬 실습 1
SortWordCount
package com.fastcampus.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/** input Format을 기존에 사용했던 텍스트인풋포맷이 아닌 키밸류텍스트인풋포맷을 사용할 예정
* 키밸류텍스트인풋포맷같은 경우 라인별로 데이터를 읽어서 키와 밸류로 파싱을 할 수 있게 인풋포맷이다.
* 키와 밸류를 구분하기 위한 새퍼레이터 값을 지정해주어야 한다
* */
public class SortWordCount extends Configured implements Tool {
public static class SortMapper extends Mapper<Text, Text, LongWritable, Text> {
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
// (hadoop 3)
context.write(new LongWritable(Long.parseLong(value.toString())), key);
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", "\t");
Job job = Job.getInstance(conf, "SortWordCount");
job.setJarByClass(SortWordCount.class);
job.setMapperClass(SortMapper.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setNumReduceTasks(1);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new SortWordCount(), args);
System.exit(exitCode);
}
}
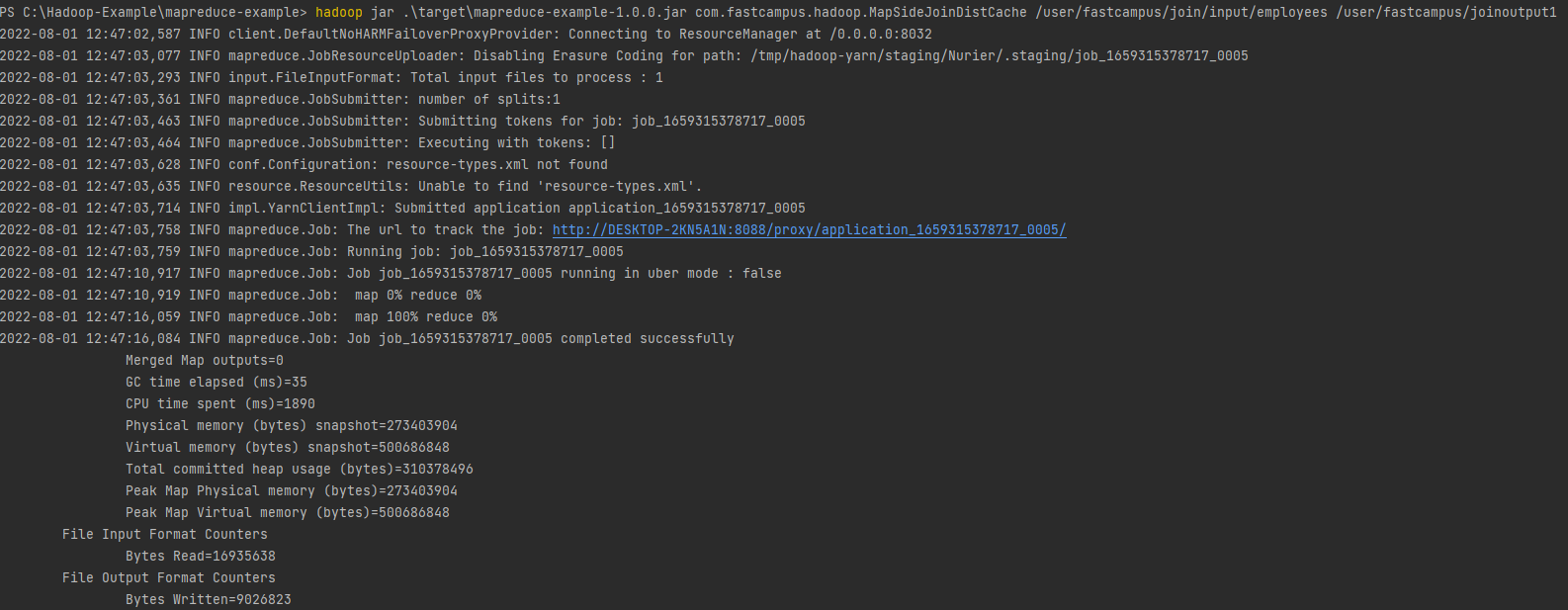
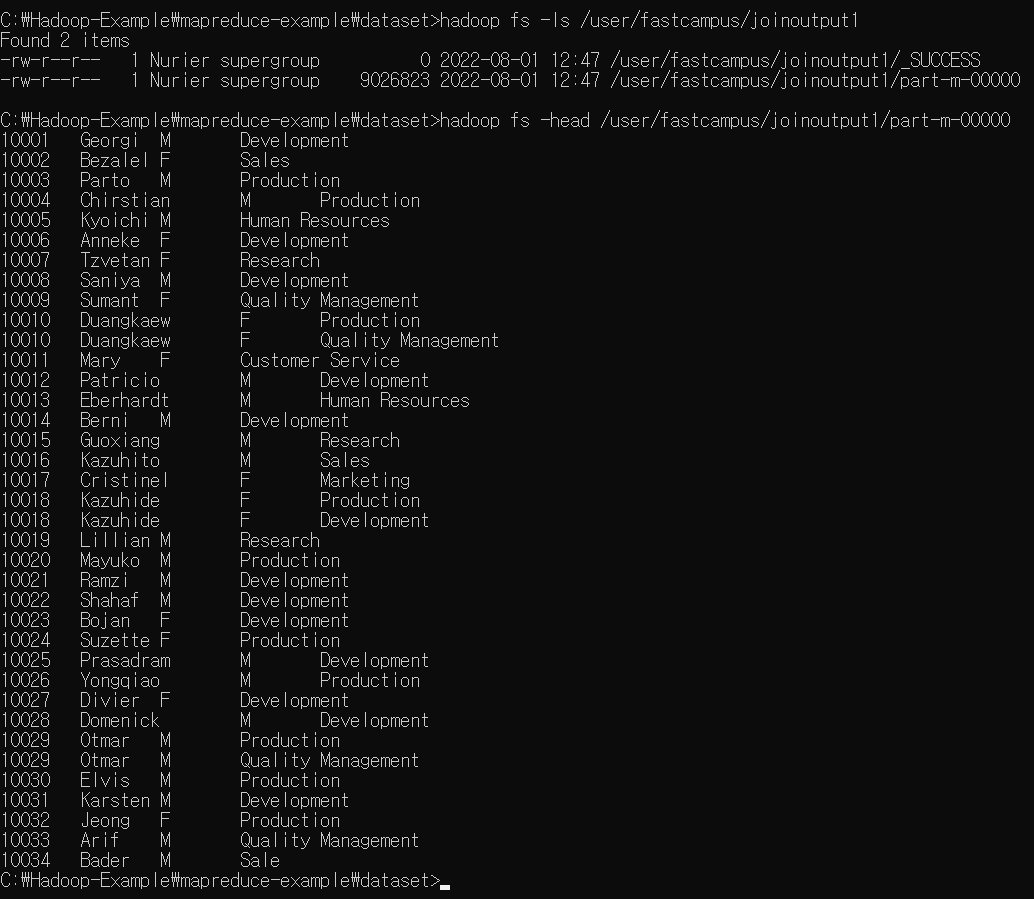
Map-side join 실습
MapSideJoinDistCache
package com.fastcampus.hadoop;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
/** Java API를 이용하여 분산캐시 등록하기 */
public class MapSideJoinDistCache extends Configured implements Tool {
public static class MapSideJoinMapper extends Mapper<LongWritable, Text, Text, Text> {
HashMap<String, String> departmentsMap = new HashMap<>();
Text outKey = new Text();
Text outValue = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] uris = context.getCacheFiles();
for (URI uri : uris) {
Path path = new Path(uri.getPath());
loadDepartmentMap(path.getName());
}
}
private void loadDepartmentMap(String fileName) throws FileNotFoundException, IOException {
String line = "";
try (BufferedReader br = new BufferedReader(new FileReader(fileName))) {
while ((line = br.readLine()) != null) {
String[] split = line.split(",");
departmentsMap.put(split[0], split[1]);
}
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// emp_no, birth_date, first_name, last_name, gender, hire_date, dept_no
String[] split = value.toString().split(",");
outKey.set(split[0]);
String department = departmentsMap.get(split[6]);
department = department == null ? "Not Found" : department;
outValue.set(split[2] + "\t" + split[4] + "\t" + department);
context.write(outKey, outValue);
}
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "MapSideJoinDistCache");
job.addCacheFile(new URI("/user/fastcampus/join/input/departments"));
job.setJarByClass(MapSideJoinDistCache.class);
job.setMapperClass(MapSideJoinMapper.class);
job.setNumReduceTasks(0);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MapSideJoinDistCache(), args);
System.exit(exitCode);
}
}
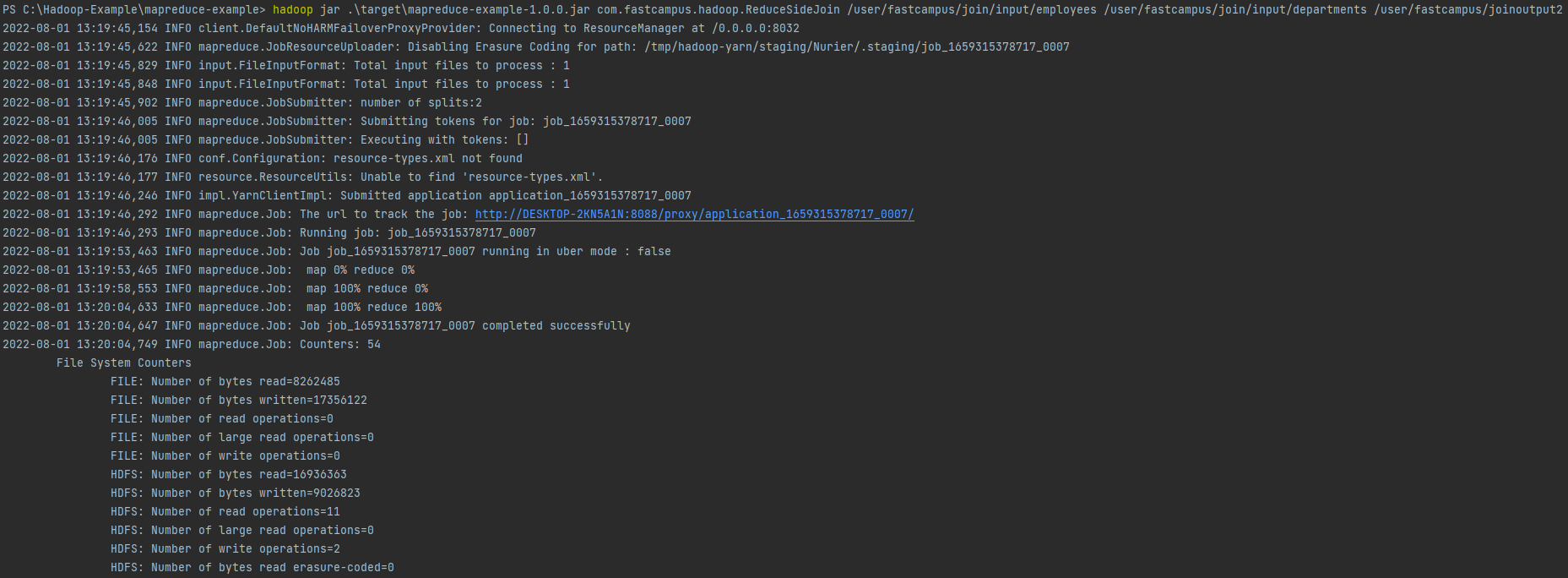
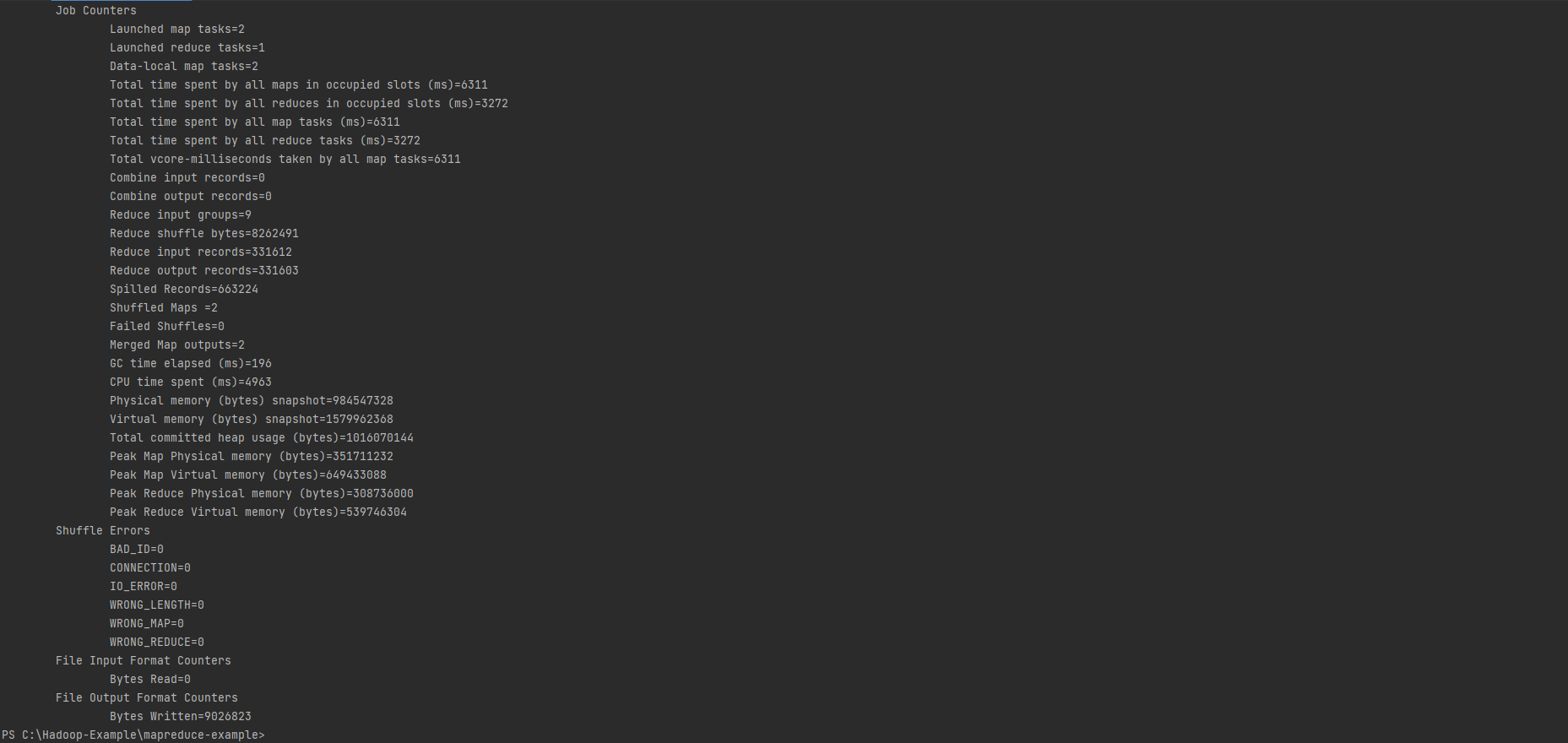
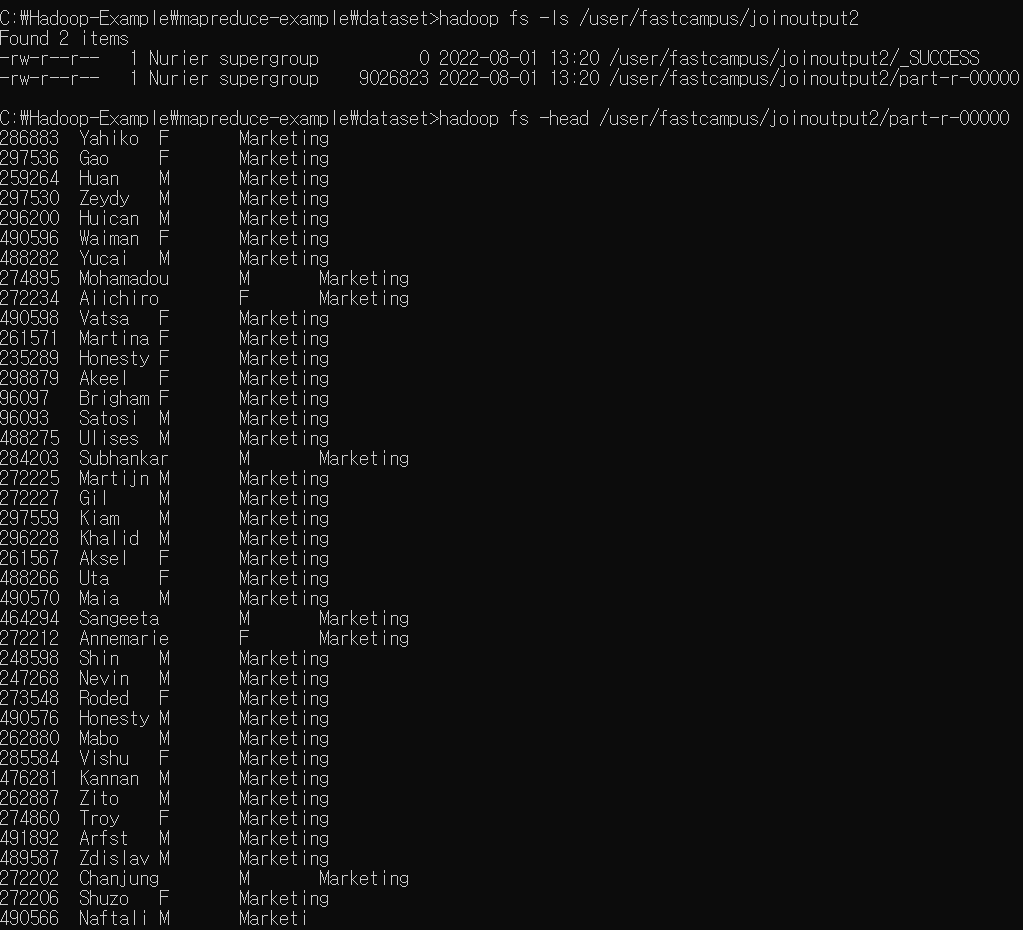
Reduce-side join 실습 1
ReduceSideJoin
package com.fastcampus.hadoop;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class ReduceSideJoin extends Configured implements Tool {
public static class EmployeeMapper extends Mapper<LongWritable, Text, Text, Text> {
Text outKey = new Text();
Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// emp_no, birth_date, first_name, last_name, gender, hire_date, dept_no
String[] split = value.toString().split(",");
outKey.set(split[6]);
outValue.set("1\t" + split[0] + "\t" + split[2] + "\t" + split[4]);
context.write(outKey, outValue);
}
}
public static class DepartmentMapper extends Mapper<LongWritable, Text, Text, Text> {
Text outKey = new Text();
Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// dept_no, dept_name
String[] split = value.toString().split(",");
outKey.set(split[0]);
outValue.set("0\t" + split[1]);
context.write(outKey, outValue);
}
}
public static class ReduceJoinReducer extends Reducer<Text, Text, Text, Text> {
Text outKey = new Text();
Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
HashMap<String, String> employeeMap = new HashMap<>();
String department = "";
for (Text t : values) {
String[] split = t.toString().split("\t");
if (split[0].equals("0")) {
department = split[1];
} else {
employeeMap.put(split[1], split[2] + "\t" + split[3]);
}
}
for (Map.Entry<String, String> e : employeeMap.entrySet()) {
outKey.set(e.getKey());
// department 이름이 join 된 값으로 셋팅
outValue.set(e.getValue() + "\t" + department);
context.write(outKey, outValue);
}
}
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "ReduceSideJoin");
job.setJarByClass(ReduceSideJoin.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, EmployeeMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, DepartmentMapper.class);
FileOutputFormat.setOutputPath(job, new Path(args[2]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new ReduceSideJoin(), args);
System.exit(exitCode);
}
}