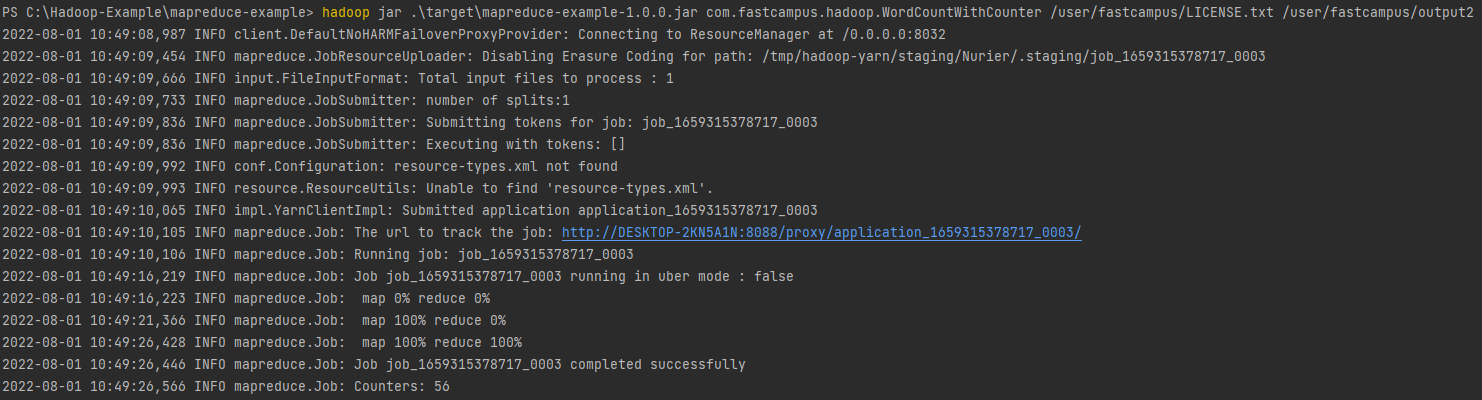
Wordcount 해부
WordCount Driver
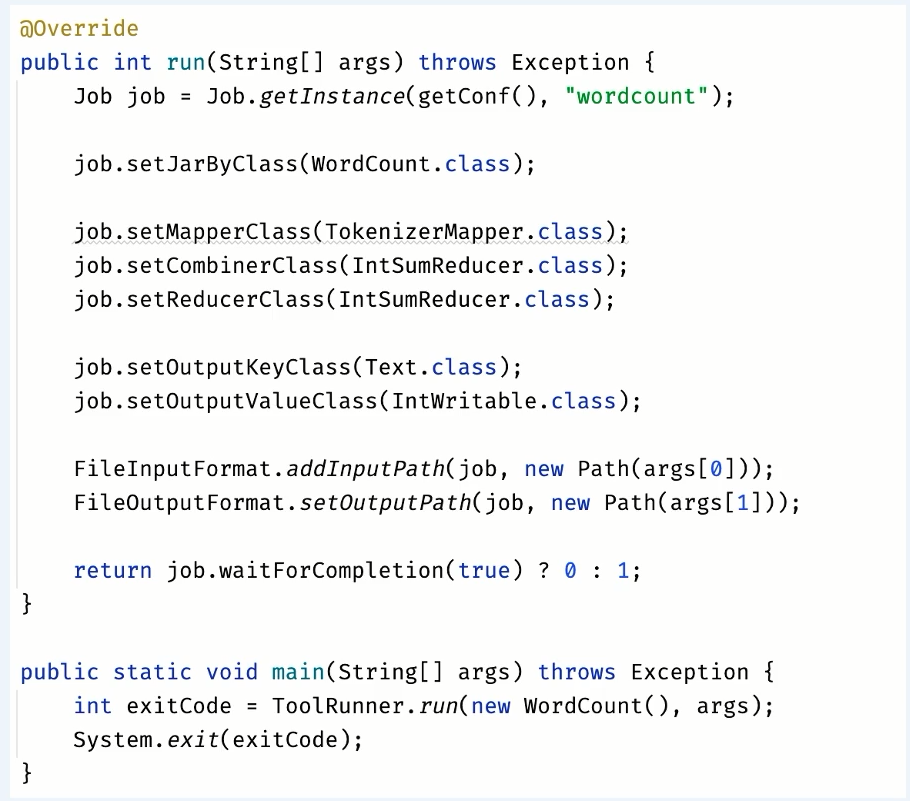
메인 함수를 보면 ToolRunner 라는것을 이용해서 실제로 워드카운트를 실행중이다.
하둡에서는 제네리 옵션 파서는 하둡잡을 커맨드라인을 통해 실행할 때 하둡의 컨피그레이션들을 실행인자를 통해서 설정이 가능하도록 지원해주는 도구
제너리 옵션 파서를 편리하게 사용할 수 있도록 하둡에서는 Tool이라는 인터페이스를 제공해주고있다
그래서 Job을 명세할때 Tool 인터페이스에 런 함수를 정의해서 맵리듀스 드라이버를 정의해준다
Driver에서는 잡을 정의해준다
setOutput 클래스 정보는 리듀스 함수의 출력타입을 지정하는 것이다. 출력키로 텍스트 클래스를 지정했고 출력벨류로 IntWritable 클래스로 정의했다.
입력파일의 패쓰와 출력파일의 패쓰를 다음과 같이 지정해주었다
잡이 제출한 후 끝날때까지 기다디도록 하고 메소드 인자로 true를 전달을 해주게 되면 콘솔로 진행사항을 출력해줍니다. 해당 함수가 성공적으로 종료됐는지 여부를 불린값을 통해서 리턴해주게 되구 그 결과를 받아서 리턴해주고 있다.
Mapper

맵리듀스의 모든 Mapper 클래스는 org.apache.hadoop.mapreduce 라는 패키지 안에 있는 mapper 클래스를 상속받아서 구현을 합니다
매퍼 클래스에는 4개의 타입 매게변수를 전달하고 있습니다. 4개의 타입매게변수가 의미하는것은
매퍼의 입력키클래스와, 입력벨류클래스, 매퍼의 출력키클래스와, 출력밸류클래스를 의미합니다
map의 내부구현을 살펴보면은 라인데이터를 토큰 단위로 나눈 후에 while문을 통해서 반복하면서 나와있는 단어와 숫자 1을 map의 아웃풋으로 출력해주고 있다.
Reducer

Reducer 클래스는 org.apache.hadoop.mapreduce 라는 패키지 안에 있는 Reducer 클래스를 상속받아서 구현을 합니다
매퍼와 마찬가지로 입력 키밸류 클래스, 출력 키밸류클래스를 전달하고있다
reduce 함수에서는 단어가 key가 되서 같은 단어들끼리 한곳에 하나의 reducer로 모이게 되고 하나의 모인 reducer 에서는 모인 값의 수를 합쳐서 결과를 기록한다.
IntWritable 타입 :
Writable
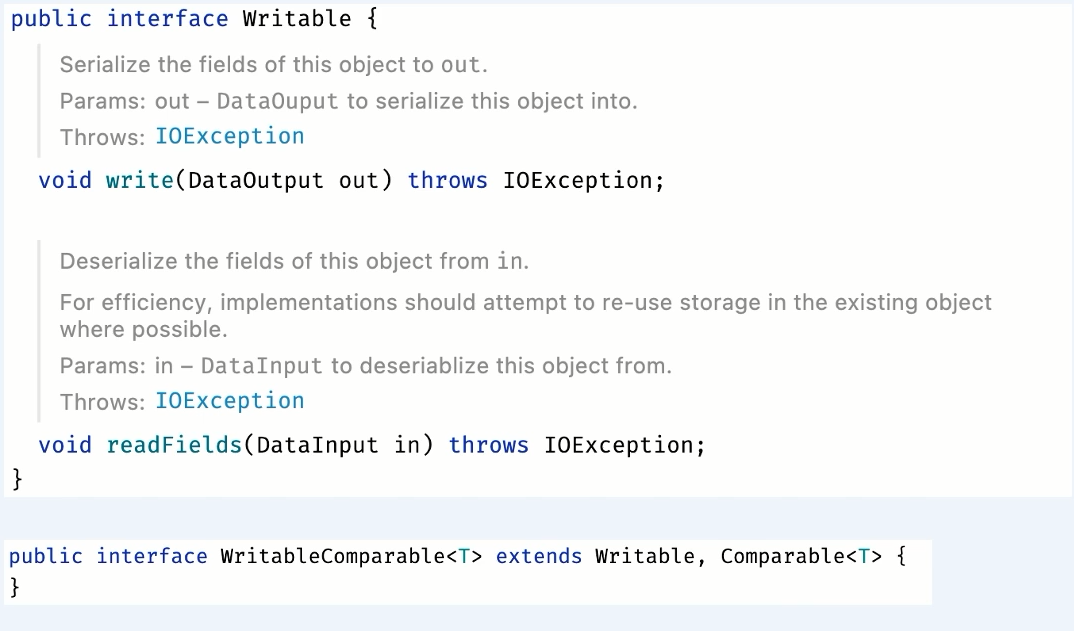
매퍼와 리듀서 사이에 데이터를 주고 받을 때 네트워크를 통해서 주고 받기 때문이다
객체를 네트워크를 통해 전송을 하게 되면 데이터의 형태가 변경되거나 다르게 해석될수도 있어서 이를 위해 직렬화랑 역직렬화 과정이 필요하고 이를 위한 자료형을 정의한다
직렬화란 네트워크 전송을 위해 구조화된 객체를 바이트스트림으로 전환하는것을 얘기하고 역직렬화란 바이트스트림을 구조화된 객체로 전환하는것을 말한다.
인터페이스를 살펴보면 write 메소드에는 객체가 직렬화 될때 호출되는 메소드고
readFields 는 역직렬화될때 호출되는 메소드이다.
그래서 Writable을 통해서 직렬화와 역직렬화 과정을 거치게 되는데 맵리듀스에서는 키를 서로 비교하는 정렬과정이 필요하기 때문에 타입비교에 대한 정의도 필요하다
그래서 다음과 같이 Comparable에 대한 인터페이스를 구현해야 하는데 그래서 실제로 IntWritable 같은 경우에는 컴페러블 내에 있는 컴 페어 투 함수가 구현되어 있는것을 확인 할 수 있을것이다.
Writable 클래스 종류
- Text
- BooleanWritable
- IntWritable
- LongWritable
- FloatWritable
- ArrayWritable
- NullWritable
MapReduce 기능
GenericOptionsParser

-conf : 환경설정이 되어 있는 컨피그레이션 파일을 전달해서 컨피그레이션을 설정하는 옵션
-D : 프로퍼티와 밸류값을 하둡설정에 추가를 해주게 된다.
-fs : 지정된 URI로 기본 파일시스템을 설정하게 된다.
-jt : 지정된 호스트와 포트로 얀의 리소스매니저를 설정하는 옵션
-files : 지정된 파일을 로컬파일시스템에서 맵리듀스가 사용하는 공유파일시스템 주로 HDFS 와 같은것으로 복사를 해서 태스크가 작업에서 사용할 수 있게 해줌
-libjars : 지정된 jar파일을 로컬파일시스템에서 맵리듀스가 사용하는 공유파일시스템 주로 HDFS 와 같은것으로 복사를 해서 맵리듀스태스크에서 맵리듀스태스크 클래스패스에 추가해주게 된다
-archives : 아카이브 파일을 맵리듀스가 사용하는 공유파일시스템으로 복사한 후에 압축해제 해준다.
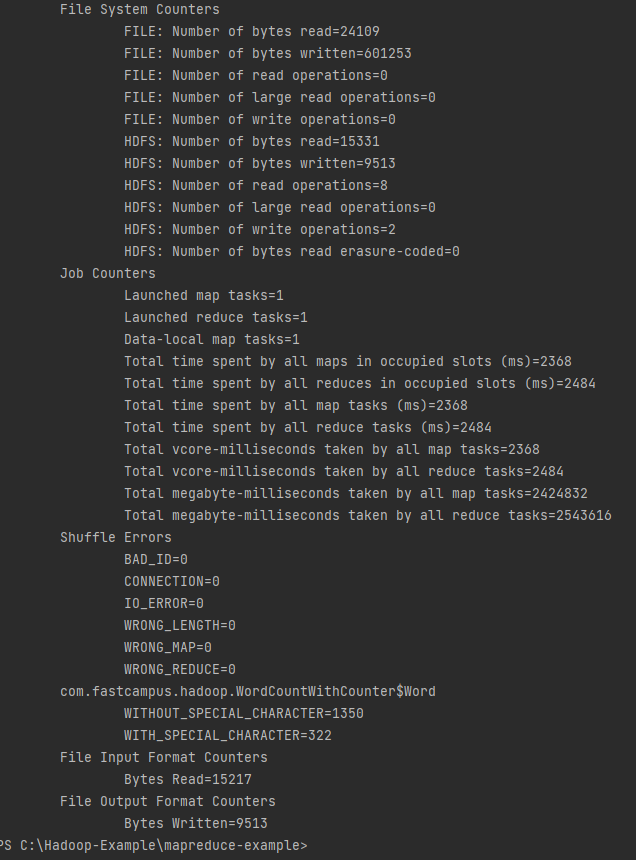
Counter
- 잡에 대한 통계 정보를 수집하는 기능
- 문제 진단에 유용
Counter 종류
- Built-in Counter
- Task counter
- Job count
- 사용자 정의 Counter
하둡에서는 모든 잡에 대한 빌트인 카운터를 제공하여 다양한 매트릭? 정보를 알려주고있다.
빌트인 카운터는 : 태스크가 진행되면서 업데이트 되는 태스크 카운터와 잡이 진행되면서 업데이트 되는 잡 카운터가 있다
태스크 카운터는 각 태스크가 실행 될 때 해당 태스크에 대한 정보를 수집한 후에 자료에 모든 태스크에대한 값을 취합하여 최종 결과를 알려줌
잡카운터는 애플리케이션마스터에 의해 유지가 되는데 잡 수준의 통계값을 측정해준다
사용자 정의 카운터 : 사용자가 카운터집합을 직접 정의한 후에 매퍼나 리듀서에서 원하는 방식으로 카운터 시킬 수 있다.
정렬
- 맵리듀스는 정렬이 기본 기능
- 맵리듀스에서 제공하는 정렬 과정 이용
Join
- MapReduce는 대용량 데이터셋 간의 조인을 지원
- 조인 종류
- Map-side 조인
- Reduce-side 조인
Map-side : 조인하려는 하나의 데이터셋이 좀 작은 경우에 분산캐쉬를 사용하여 구현하는 방법이있따.
각각의 입력 데이터셋이 동일한 개수의 파티션으로 분할되어 있고 동일한 조인키로 정렬이 되어있어야 한다. 즉 특정키에 대한 모든 레코드가 동일 파티션에 존재를 해서 매퍼에서 동일한 조인키에 대해서 입력을 받아오는 형태
Reduce-side : 맵리듀스의스포틀기능 ?이용해서 같은 키가 같은 리듀서로 모이는 원리를 사용하는 방식
분산 캐시
- 실행 시점에 파일과 아카이브의 사본을 태스크 노드에 복사하여 이를 이용할 수 있게 해주는 서비스
- GenericOptionParser를 이용하여 옵션으로 추가
- -files
- -archives
- API 이용
- Job 클래스에서 제공하는 API 이용
- addCacheFile(URI uri)
- addCacheArchive(URI uri)
- setCacheFiles(URI[] files)
- setCacheArchives(URI[] archives)
- addFileToClassPath(Path file)
- addArchiveToClassPath(Path archive)
GenericOptionParser와 ToolRunner 실습
GenericOptionParser
package com.fastcampus.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.Arrays;
// 제너릭옵션 파서의 경우 분산 캐시를 지원하기 위한 files나 아카이브 옵션 등을 사용할 수 있습니다. 또한 하둡 conf 설정도 cli의 옵션으로 처리하여 실행할 수 있습니다.
public class GenericOptionsParserExample {
public static void main(String[] args) throws IOException {
System.out.println(Arrays.toString(args));
Configuration conf = new Configuration();
// conf안에 arg로 들어온 부분들을 셋팅해준다
GenericOptionsParser optionsParser = new GenericOptionsParser(conf, args);
String value1 = conf.get("mapreduce.map.memory.mb");
Boolean value2 = conf.getBoolean("job.test", false);
System.out.println("value1 : " + value1 + " & value2 : " + value2);
// GenericOptionsParser에서 옵션을 세팅하고 나머지 argument를 받아서 처리
String[] remainingArgs = optionsParser.getRemainingArgs();
System.out.println(Arrays.toString(remainingArgs));
}
}
ToolRunner
package com.fastcampus.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.util.Arrays;
public class ToolRunnerExample extends Configured implements Tool {
@Override
public int run(String[] args) {
Configuration conf = getConf();
String value1 = conf.get("mapreduce.map.memory.mb");
Boolean value2 = conf.getBoolean("job.test", false);
System.out.println("value1 : " + value1 + " & value2 : " + value2);
System.out.println(Arrays.toString(args));
return 0;
}
public static void main(String[] args) throws Exception {
System.out.println(Arrays.toString(args));
int exitCode = ToolRunner.run(new ToolRunnerExample(), args);
System.exit(exitCode);
}
}

Counter 실습
package com.fastcampus.hadoop;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.StringTokenizer;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WordCountWithCounter extends Configured implements Tool {
static enum Word {
WITHOUT_SPECIAL_CHARACTER,
WITH_SPECIAL_CHARACTER
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private IntWritable one = new IntWritable();
private Text word = new Text();
// Pattern.CASE_INSENSITIVE : 대소문자를 구분하지 않겠다.
// regex : 정규표현식 , 특수문자가 포함되어있는지 안되어있는지 확인해서 카운터를 할 수 있게 함
private Pattern pattern = Pattern.compile("[^a-z0-9]", Pattern.CASE_INSENSITIVE);
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
String str = itr.nextToken().toLowerCase();
Matcher matcher = pattern.matcher(str);
// if문이 매칭이 된다면 특수문자가 포함이 된것임
if (matcher.find()) {
context.getCounter(Word.WITH_SPECIAL_CHARACTER).increment(1);
} else {
context.getCounter(Word.WITHOUT_SPECIAL_CHARACTER).increment(1);
}
word.set(str);
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
// (hadoop, 3)
}
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "wordcount with counter");
job.setJarByClass(WordCountWithCounter.class);
job.setMapperClass(WordCountWithCounter.TokenizerMapper.class);
job.setReducerClass(WordCountWithCounter.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new WordCountWithCounter(), args);
System.exit(exitCode);
}
}