어텐션
Attention은 Bahdanau가 제안한 기존 컴퓨터 비전 분야의 Visual Attention을 자연어 처리에 활용한 것이라고 한다.🤔
기존 seq2seq 모델의 단점
자연어 처리 분야 중 NMT(Nueral Machine Translation)에서는 인코더-디코더 방식의 번역 알고리즘이 대부분이었는데, 이는 고정된 크기의 벡터로 압축시켜서 병목 현상을 유발한다. 이러한 현상은 번역품질을 악화시킬 우려가 있고 그래서 제안된것이 어텐션을 이용한 기계번역이다.
어텐션 매커니즘
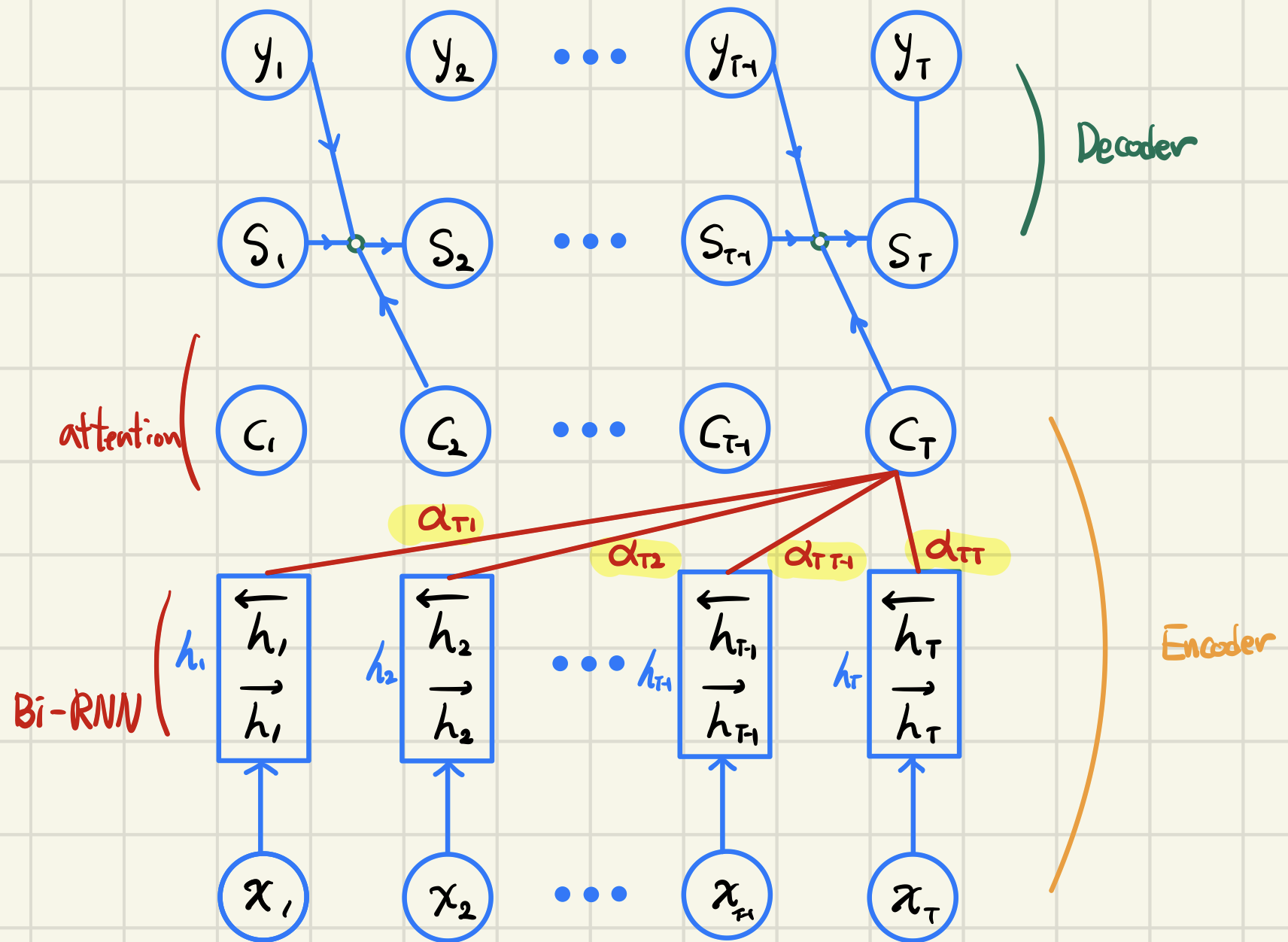
: 출력
: <확률: attention weight>
<를 기반으로 한 에너지>
: RNN셀의 순방향/역방향 hidden state concatenation
: 입력
어텐션 매커니즘의 의의
1.확률과 에너지를 기반으로 한 접근
: <확률; softmax 형태>
<를 기반으로 한 에너지>
- 를 확률적인 가중치로 를 해당 확률을 형성하는 에너지로 볼 수 있음
2.긴 거리에서의 의존성(Long Dependencies) 문제를 해결
 기존의 RNN은 문장이 매우 길어지면 depenency가 생길 수 밖에 없다.
기존의 RNN은 문장이 매우 길어지면 depenency가 생길 수 밖에 없다.
하지만, Attention을 적용하면 각각의 hidden state에 대한 attention weight가 반영이 되기 때문에 손쉽게 해결 할 수 있다.

.