
여기를 참고해서 작성했습니다
0. 설치 환경
OS: Ubuntu 20.04
JDK: OpenJDK 11.0.18
Hadoop: Hadoop 3.3.0
1. JDK 설치
Hadoop은 Java 언어로 쓰여 있어 이를 실행하기 위한 Java runtime이 필요
이전 버전까지는 JDK 8 버전만 지원했으나, Hadoop 3.3 이후로 JDK 11 버전도 지원
1.1. JDK 설치
설치 가능한 패키지 리스트 최신화 후, OpenJdk 11 설치
(Oracle JDK 설치해도 무방 - 라이선스 확인 필요)
$ sudo apt update
$ sudo apt install openjdk-11-jdk1.1. Java 버전 체크
아래와 같이 자신이 설치한 버전이 출력되는지 체크
$ java -version
openjdk version "11.0.18" 2023-01-17
OpenJDK Runtime Environment (build 11.0.18+10-post-Ubuntu-0ubuntu120.04.1)
OpenJDK 64-Bit Server VM (build 11.0.18+10-post-Ubuntu-0ubuntu120.04.1, mixed mode, sharing)2. Hadoop 계정 추가
보안상 계정을 분리하는게 좋기 때문에 새 계정을 추가
계정 이름을 hadoop으로 설정
$ sudo adduser hadoop
Adding user `hadoop' ...
Adding new group `hadoop' (1002) ...
Adding new user `hadoop' (1002) with group `hadoop' ...
Creating home directory `/home/hadoop' ...
Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] Y3. SSH 인증키기반 인증 설정
서버간 통신할 때, 매번 암호를 입력하고 들어가는 대신 SSH 인증키를 생성하여 암호 없이 접속하게끔 설정
3.1. SSH 키 생성 및 추가
계정 변경 후 SSH 키를 생성
키 경로는 수정하지 않고 기본값을 그대로 사용
$ su - hadoop
$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
...생성된 공개키(id_rsa.pub)를 authorized_keys에 추가하고 권한을 바꿔준다
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 640 ~/.ssh/authorized_keys아래의 명령어를 통해 known hosts에 등록
$ ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ECDSA key fingerprint is
...
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes4. Hadoop 설치
4.1 파일 다운로드 및 확인
hadoop 유저로 계정전환
$ su - hadoop아래 명령어를 통해 압축 파일 및 해시값 다운
$ wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
$ wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz.sha512다운 받은 hadoop-3.3.0.tar.gz의 해시값과 hadoop-3.3.0.tar.gz.sha512파일의 내용 비교
$ shasum -a 512 hadoop-3.3.0.tar.gz
9ac5a5a8d29de4d2edfb5e554c178b04863375c5644d6fea1f6464ab4a7e22a50a6c43253ea348edbd114fc534dcde5bdd2826007e24b2a6b0ce0d704c5b4f5b hadoop-3.3.0.tar.gz
$ cat hadoop-3.3.0.tar.gz.sha512
SHA512 (hadoop-3.3.0.tar.gz) = 9ac5a5a8d29de4d2edfb5e554c178b04863375c5644d6fea1f6464ab4a7e22a50a6c43253ea348edbd114fc534dcde5bdd2826007e24b2a6b0ce0d704c5b4f5b일치하지 않으면, 받은 파일을 제거하고 네트워크가 안정적인 곳에서 파일을 다시 다운로드 받는다
4.2. Hadoop 설치
4.2.1. 압축해제
다운로드 받은 압축 파일을 압축 해제하고, 심볼릭 링크를 생성
$ tar -xvzf hadoop-3.3.0.tar.gz
$ ln -s hadoop-3.3.0 hadoop 4.2.2. 시스템 환경변수 추가
~/.bashrc 파일을 에디터로 열고
$ vim ~/.bashrc아래 내용을 ~/.bashrc 파일의 제일 밑에 추가
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"만약, 다른 JDK를 사용하고 있다면, JAVA_HOME 변수만 아래와 같이 수정
export JAVA_HOME=$(dirname $(dirname $(readlink $(readlink $(which java)))))아래 명령어를 통해 환경변수를 업데이트
$ source ~/.bashrc 4.2.4. Hadoop 다운로드 링크 만료시
만약, 링크가 만료되어 다운받을수 없다면 아래를 참고
Apache Hadoop Releases page에 접속해서 archive 페이지로 이동
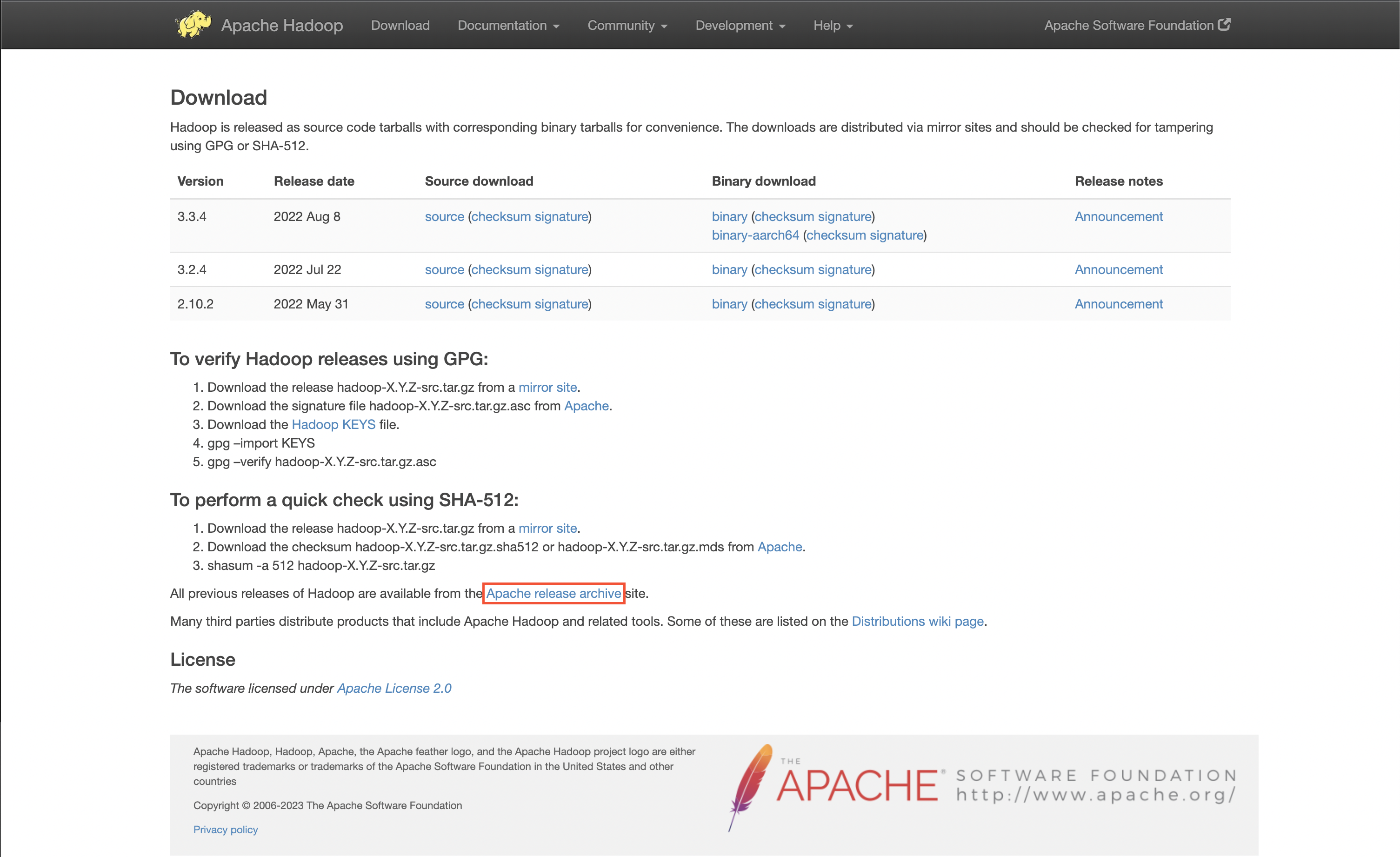
아카이브 페이지로 이동한 뒤, 최근 수정된 Hadoop-3.3.0/ 폴더에 들어간다
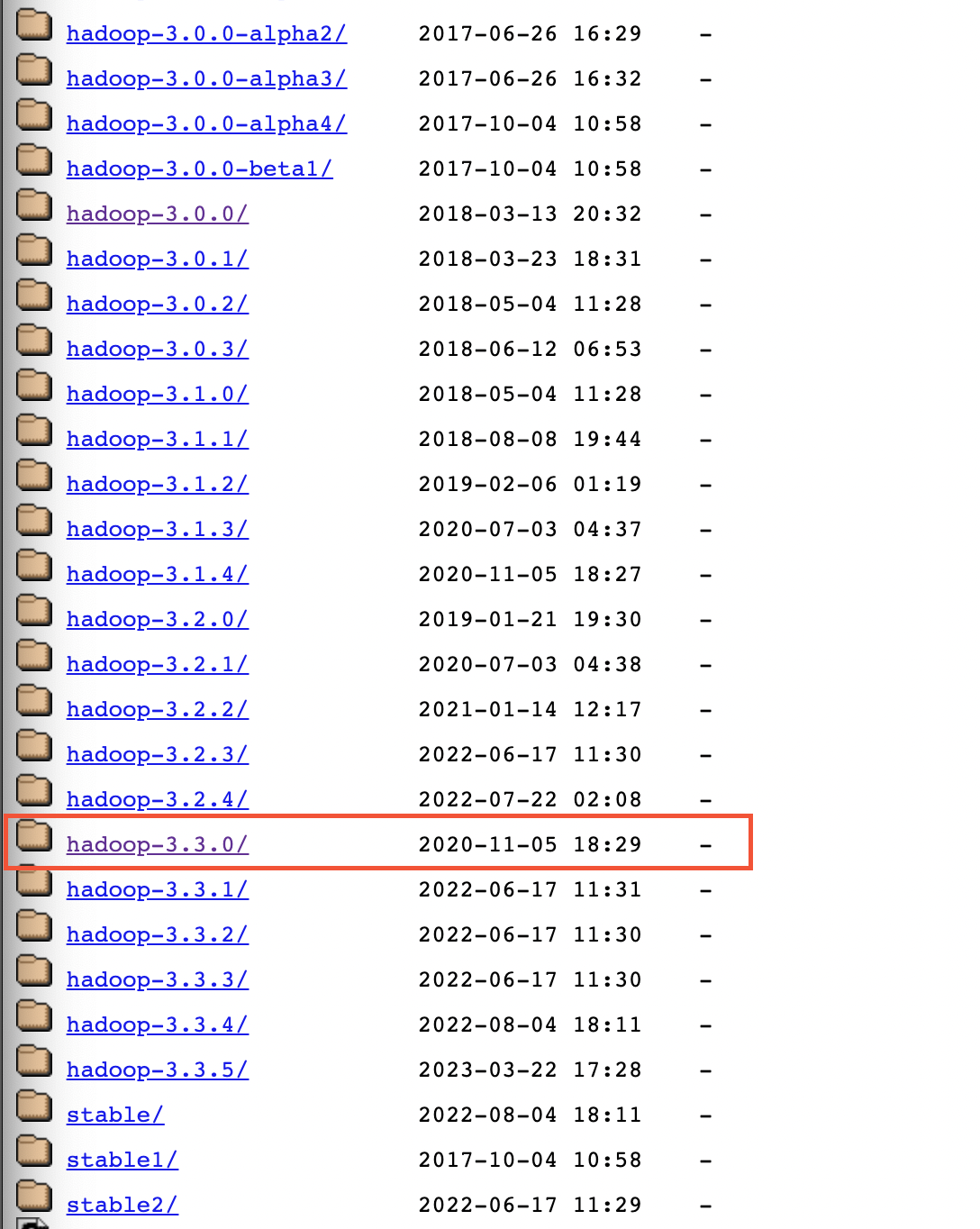
hadoop-3.3.0.tar.gz 및 hadoop-3.3.0-src.tar.gz.sha512를 오른쪽 마우스 버튼으로 링크 주소를 복사해 새로운 링크로 교체해서 다운
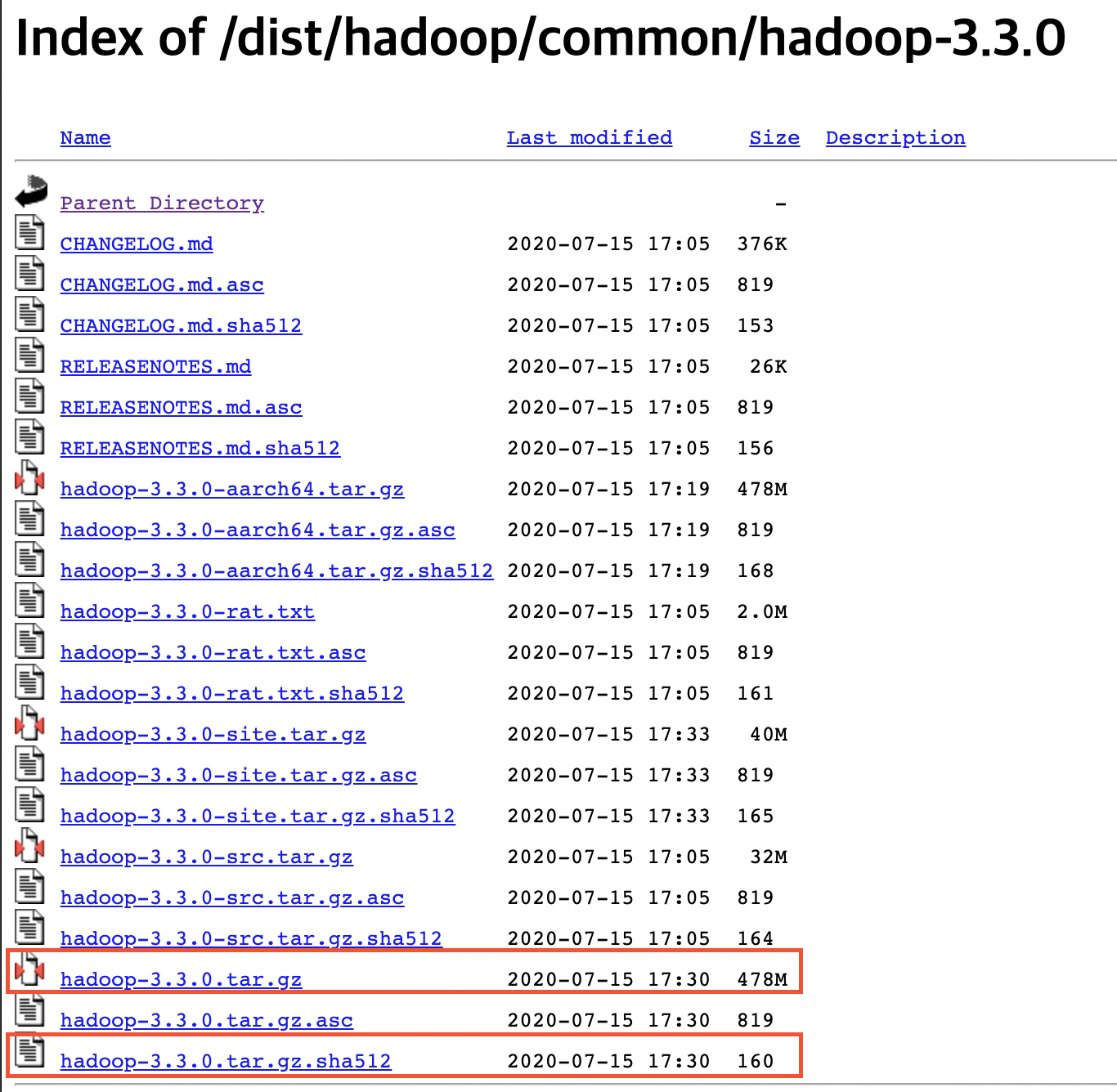
5. Hadoop 설정
아래 명령어를 실행해서 NameNode와 DataNode 디렉토리를 생성
앞으로 이 디렉토리에 데이터가 저장될 예정
$ mkdir -p ~/hadoopdata/hdfs/namenode
$ mkdir -p ~/hadoopdata/hdfs/datanode /home/hadoop/hadoop/etc/hadoop 경로에는 Hadoop 설정 파일이 존재
hadoop-env.sh: Hadoop을 실행하는 쉘스크립트 파일workers: DataNode 서버 지정core-site.xml: HDFS와 MapReduce에서 공통적으로 사용할 정보들을 설정, hdfs-site와 mapred-site의 공통 설정 부분hdfs-site.xml: HDFS와 관련된 환경 변수를 설정mapred-site.xml: MapReduce의 어플리케이션 환경 설정yarn-site.xml: Resource Manager, Node Manager 환경 설정yarn-env.sh: YARN을 실행하는 쉘스크립트 파일
여기서 변경할 파일은 hadoop-env.sh, core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml
5.1. hadoop-env.sh
hadoop-env.sh을 수정해서 Java 경로를 지정
$ vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh 아래 내용을 hadoop-env.sh 파일의 제일 밑에 추가
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd645.2. core-site.xml
$ vim $HADOOP_HOME/etc/hadoop/core-site.xml아래 내용을 core-site.xml 파일의 configuration 항목을 이렇게 수정
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>5.3. hdfs-site.xml
$ vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml아래 내용을 hdfs-site.xml 파일의 configuration 항목을 이렇게 수정
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>5.4. mapred-site.xml
$ vim $HADOOP_HOME/etc/hadoop/mapred-site.xml아래 내용을 mapred-site.xml 파일의 configuration 항목을 이렇게 수정
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5.5. yarn-site.xml
$ vim $HADOOP_HOME/etc/hadoop/yarn-site.xml아래 내용을 yarn-site.xml 파일의 configuration 항목을 이렇게 수정
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>5.6. NameNode 포맷
아래 명령어를 통해 네임노드를 포맷
$ hdfs namenode -format
2023-03-23 14:25:33,758 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-03-23 14:25:33,760 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-03-23 14:25:33,760 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at data_server01/127.0.1.1
************************************************************/6. Hadoop 클러스터 실행
NameNode 포맷후 아래 명령어를 통해 Haddop 클러스터 실행
$ start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [data_server01]다음, YARN 서비스 실행
$ start-yarn.sh
Starting resourcemanager
Starting nodemanagersJps 명령어를 통해 Hadoop 서비스 상태 체크
$ jps
88720 DataNode
89223 ResourceManager
88502 NameNode
89592 NodeManager
89851 Jps
88971 SecondaryNameNode7. 방화벽 설정
방화벽이 설정되어 있으면 외부에서 접속이 안되므로, 사용하고 있다면 아래 명령어를 통해 포트를 개방
firewall-cmd --permanent --add-port=9870/tcp
firewall-cmd --permanent --add-port=8088/tcp
firewall-cmd --reload 8. NameNode 및 Resource Manager 액세스
NameNode 및 Resource Manager 접근은 웹브라우저 상에서 가능
-
NameNode (http://name-server-ip:9870)
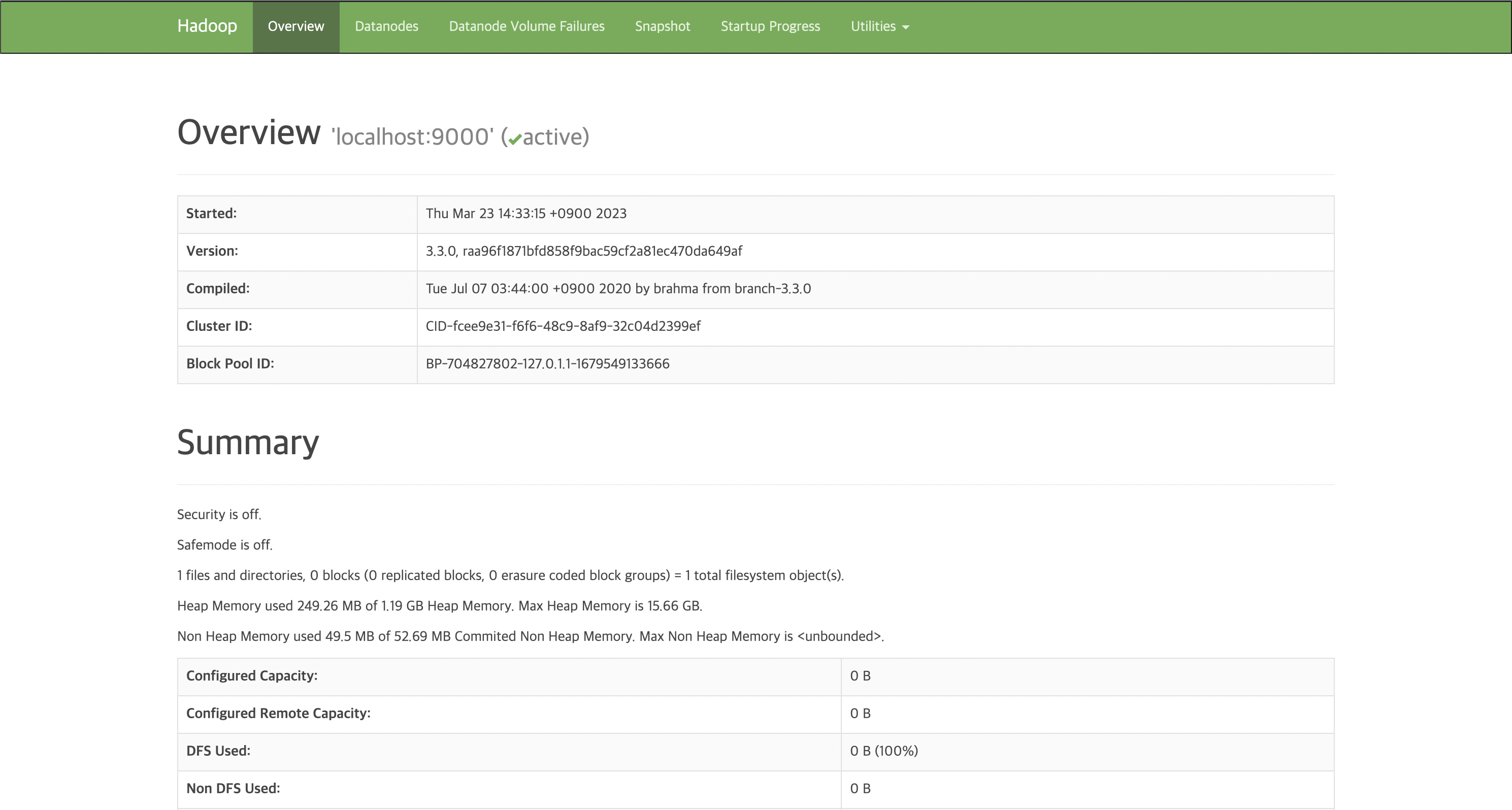
-
Resource Manager (http://name-server-ip:8088)

외부에서 Namenode와 Resource Manager에 접근을 하지 못한다면 포트포워딩 설정 필요
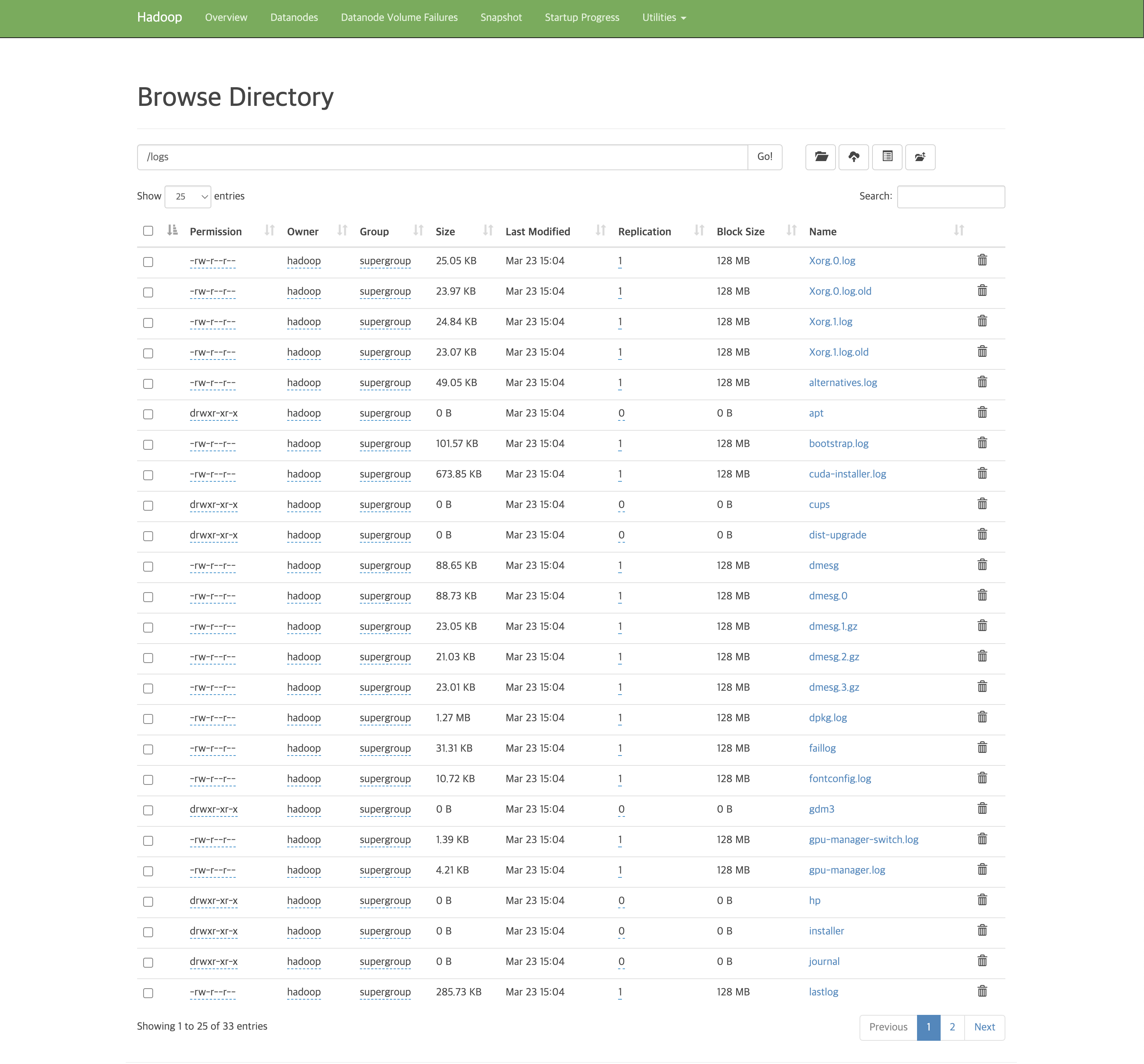
9. Hadoop 클러스터 확인
클러스터가 잘 설정되었는지 검증하기 위해 폴더 생성과 업로드가 되는지 확인
아래의 명령어를 통해 2개 폴더를 만들고 잘 생성되었는지 확인
$ hdfs dfs -mkdir /test1
$ hdfs dfs -mkdir /logs
$ hdfs dfs -ls /
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2023-03-23 14:44 /logs
drwxr-xr-x - hadoop supergroup 0 2023-03-23 14:44 /test1HDFS에 파일 업로드도 잘 수행되는지 확인
아래의 명령어를 통해 시스템 로그를 업로드 후 확인
$ hdfs dfs -put /var/log/* /logs/
$ hdfs dfs -ls /logs/
Found 33 items
-rw-r--r-- 1 hadoop supergroup 25656 2023-03-23 15:04 /logs/Xorg.0.log
-rw-r--r-- 1 hadoop supergroup 24544 2023-03-23 15:04 /logs/Xorg.0.log.old
-rw-r--r-- 1 hadoop supergroup 25437 2023-03-23 15:04 /logs/Xorg.1.log
-rw-r--r-- 1 hadoop supergroup 23620 2023-03-23 15:04 /logs/Xorg.1.log.old
-rw-r--r-- 1 hadoop supergroup 50226 2023-03-23 15:04 /logs/alternatives.log
drwxr-xr-x - hadoop supergroup 0 2023-03-23 15:04 /logs/apt
...NameNode 웹에서도 확인 가능
Utilities→Browse the file system에서 확인 가능
10. Hadoop 클러스터 종료
$ stop-dfs.sh
$ stop-yarn.sh 