e_juhee.log
로그인
e_juhee.log
로그인
[c언어] Malloc Lab :: 동적 할당기 구현하기 (Implicit List, Explicit List, Segregated List, Buddy System)
이주희
·
2023년 4월 12일
팔로우
0
C언어
목록 보기
5/9
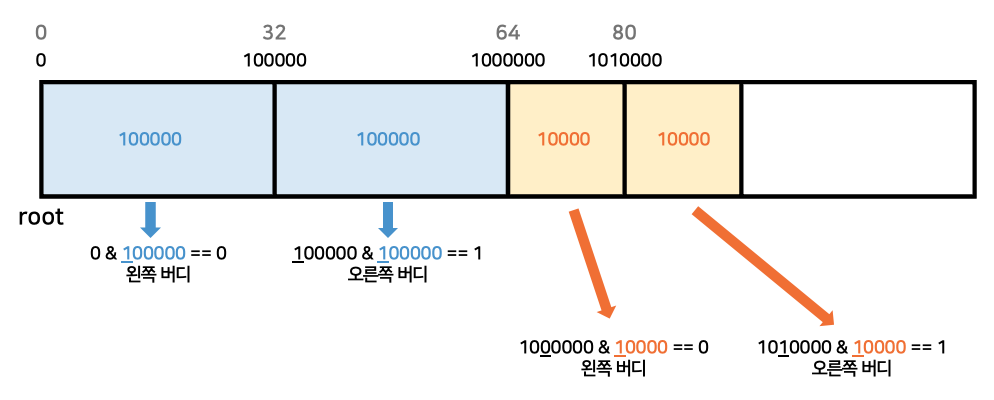
🔎 Malloc Lab 구현하기
이주희
🍓e-juhee.tistory.com 👈🏻 이사중
팔로우
이전 포스트
[c언어] Red-Black Tree 구현하기
다음 포스트
[c언어] Proxy Lab :: Proxy Server 구현하기 (Sequential proxy, Concurrent proxy, Caching)
0개의 댓글
댓글 작성