강의 자료
Lecture 9
오늘 배울 내용은 바로 CNN Architectures 에 대해 배워보자.
- AlexNet
- VGG
- GoogLeNet
- ResNet
Also
- NiN
- Wide ResNet
- ResNeXT
- Stochastic Depth
- DenseNet
- FractalNet
- SqueezeNet
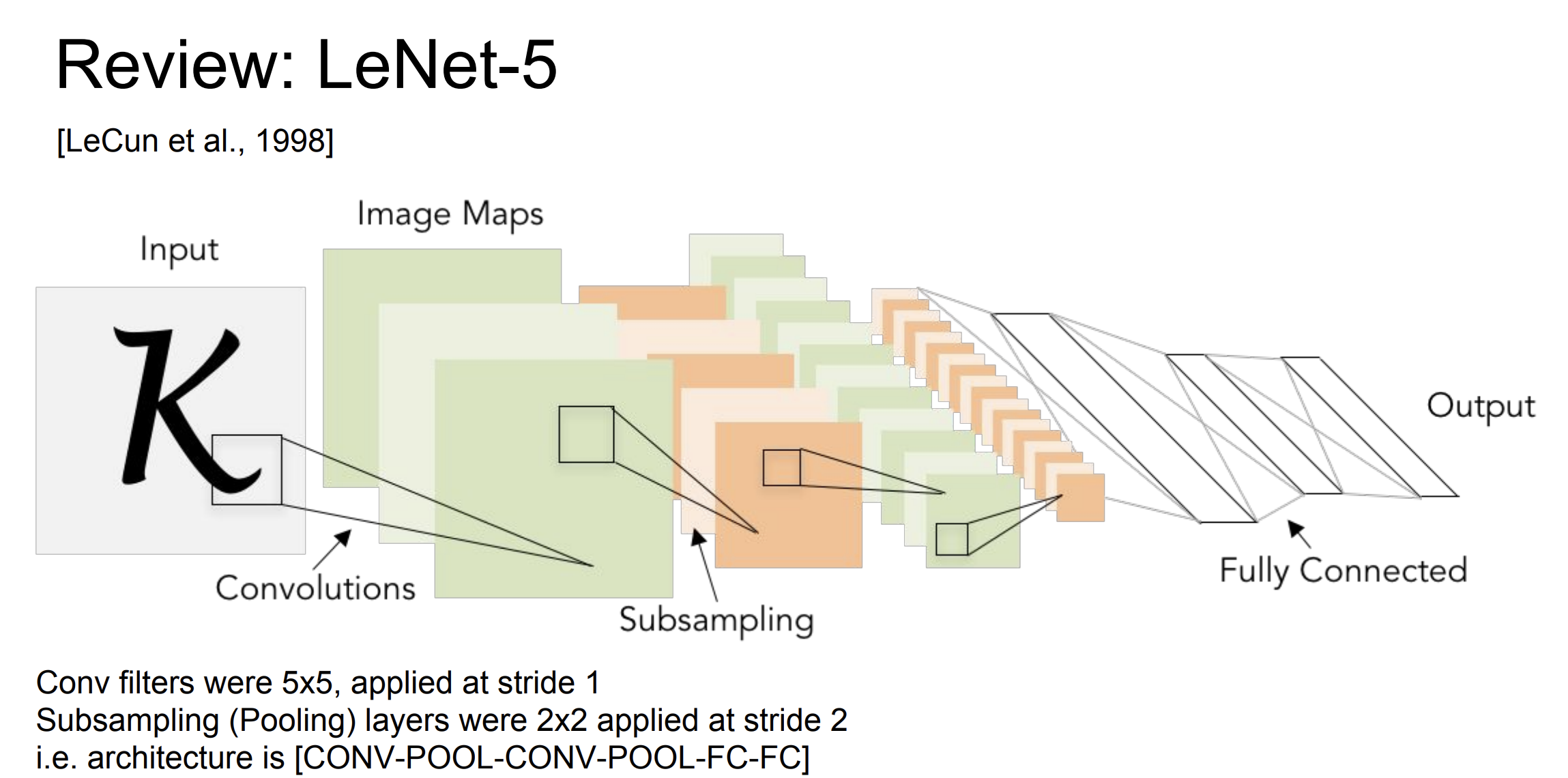
우리는 이전에 LeNet-5 에 대해서 배워보았다.
이 네트워크는 손으로 쓴 숫자 인식에 사용되었고 큰 성공을 거두었다.
- 아키텍쳐 : 2개의 합성곱 층과 3개의 완전 연결 층으로 구성되었다.
- 합성곱 층은 이미지의 특징을 추출하는데 사용되고, average pooling layer는 특징 맵의 차원을 줄이고 계산 효율성을 높이는 역할을 한다.
- 시그모이드, tanh 와 같은 활성화함수가 사용되었다.
이제 더 많은 CNN 아키텍쳐 구조에 대해서 알아보자.
AlexNet
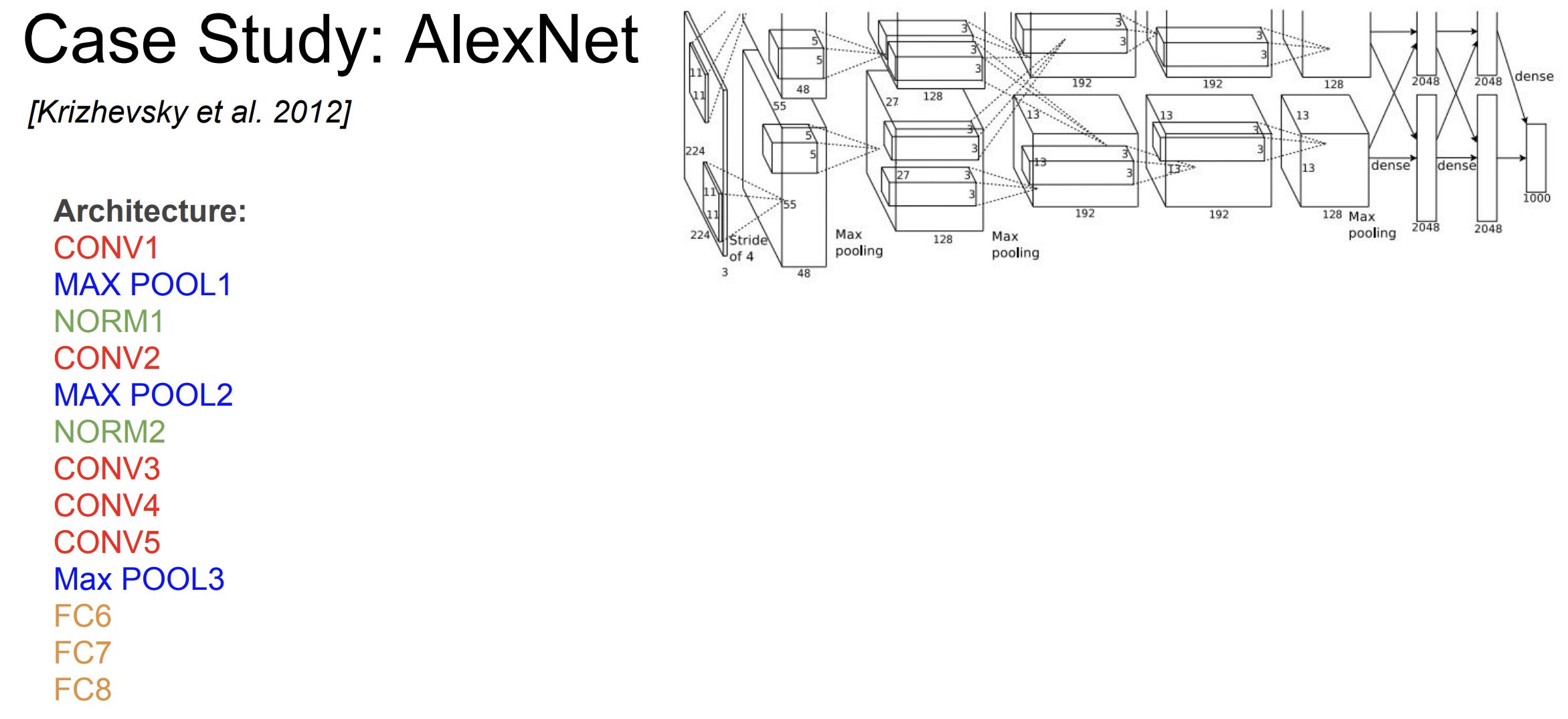
맨 처음 CNN 아키텍쳐는 바로 AlexNet이다.
아키텍쳐 구조는 위 그림과 같다.
input size : 227 x 227 x 3
Question.
first layer : 96 11x11 filters applied at stride 4
what is the output volume size?
A. (227 - 11)/4 + 1 = 55
so, 55 x 55 x 96
first 레이어에 있는 매개변수의 총 개수는 ?
11 x 11 x 3 x 96 = 35,000
이미지의 depth가 3이기 때문에 3을 곱해주어야 한다.
Second layer를 보자.
일단 첫번째 conv1 를 통한 사이즈는 55 x 55 x 96 이다.
이 레이어는 풀링 레이어이다.
(POOL1): 3x3 filters applied at stride 2
Output Volume Size가 뭘까?
(55 - 3)/2 + 1 = 27
so, 27 x 27 x 96
What is the number of parameters in this layer?
pooling layer에는 매개변수가 없다.
매개변수란, 우리가 학습하려는 가중치를 의미한다. 하지만 풀링 레이어에서는 그저 이미지를 축소하기 위함이기 때문에 모든 작업에 규칙이 있고, 학습을 필요로 하지 않는다. 따라서 풀링 레이어에는 매개변수가 없다!
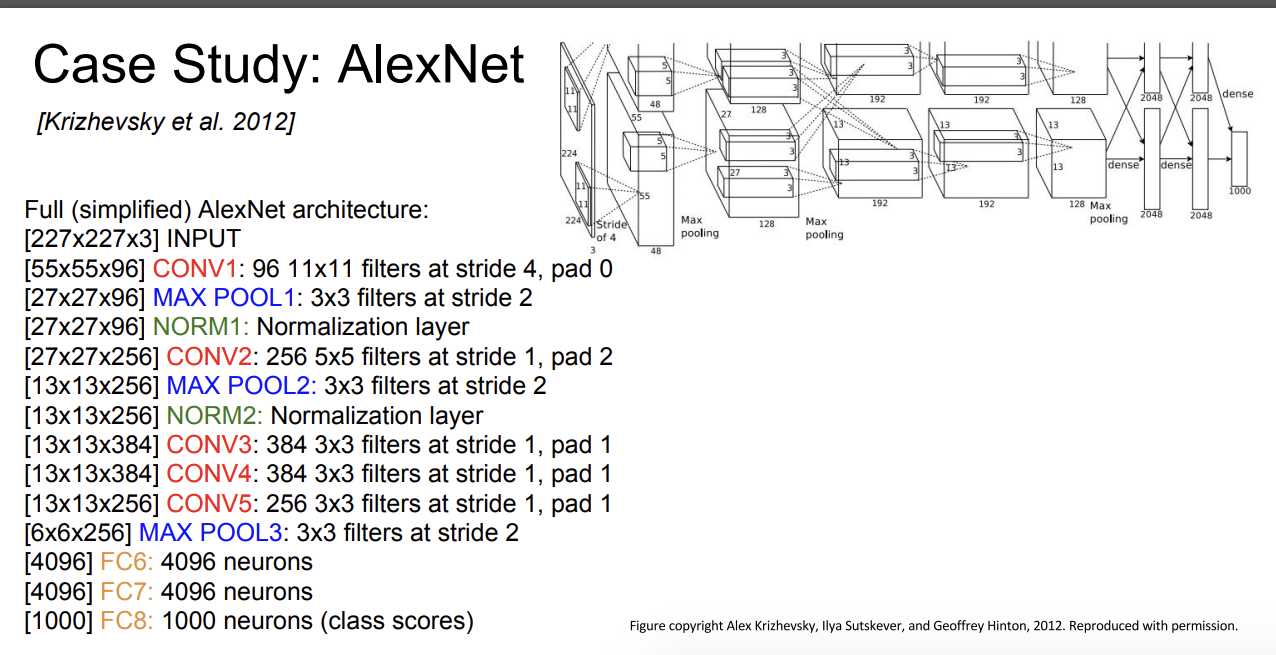
모든 층에 대해서 위 작업을 수행하면 volume size를 구할 수 있다.
Details/Retrospectives
- ReLU를 처음 사용하였다. 더 빠른 학습이 가능해졌다.
- Norm Layers를 사용했다. -> 하지만 별 다른 효과는 없는 것으로 확인
- heavy data augmentation : 자르기, jittering, flipping 등
- dropout 0.5
- batch size 128
- SGD Momentum 0.9
- Learning rate 1e-2, reduced by 10
manually when val accuracy plateaus - L2 weight decay 5e-4
- 7 CNN ensemble: 18.2% -> 15.4%
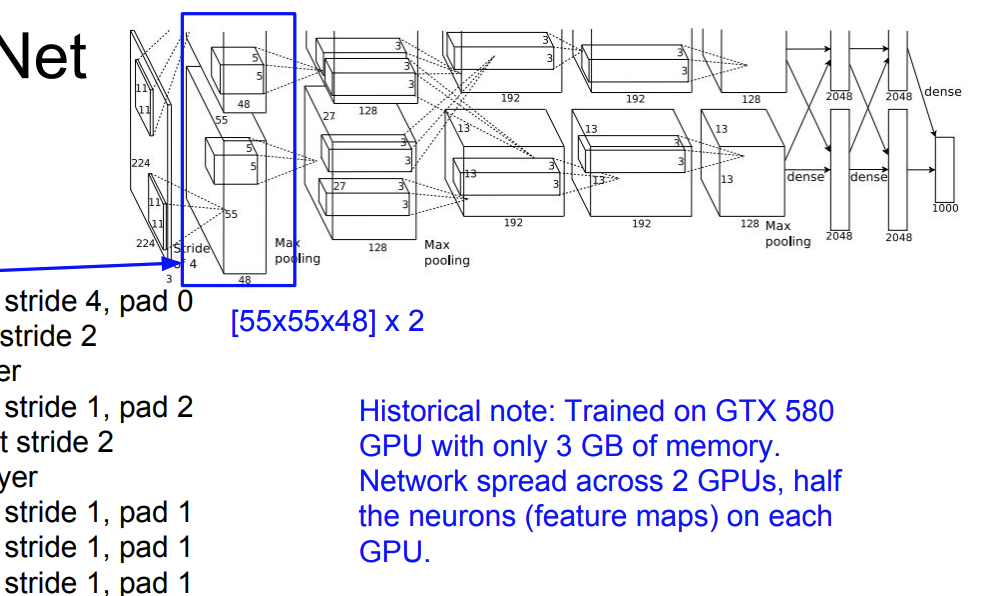
AlexNet은 2개의 NVIDIA GTX 580 GPU를 사용해서 학습시간을 단축시켰다.
당시에는 매우 혁신적인 방법이라 한다. GPU는 병렬 처리 능력이 뛰어나서 대량의 데이터를 빠르게 처리한다.
CONV1, CONV2, CONV4, CONV5 연결은 같은 GPU에서 실행했다.
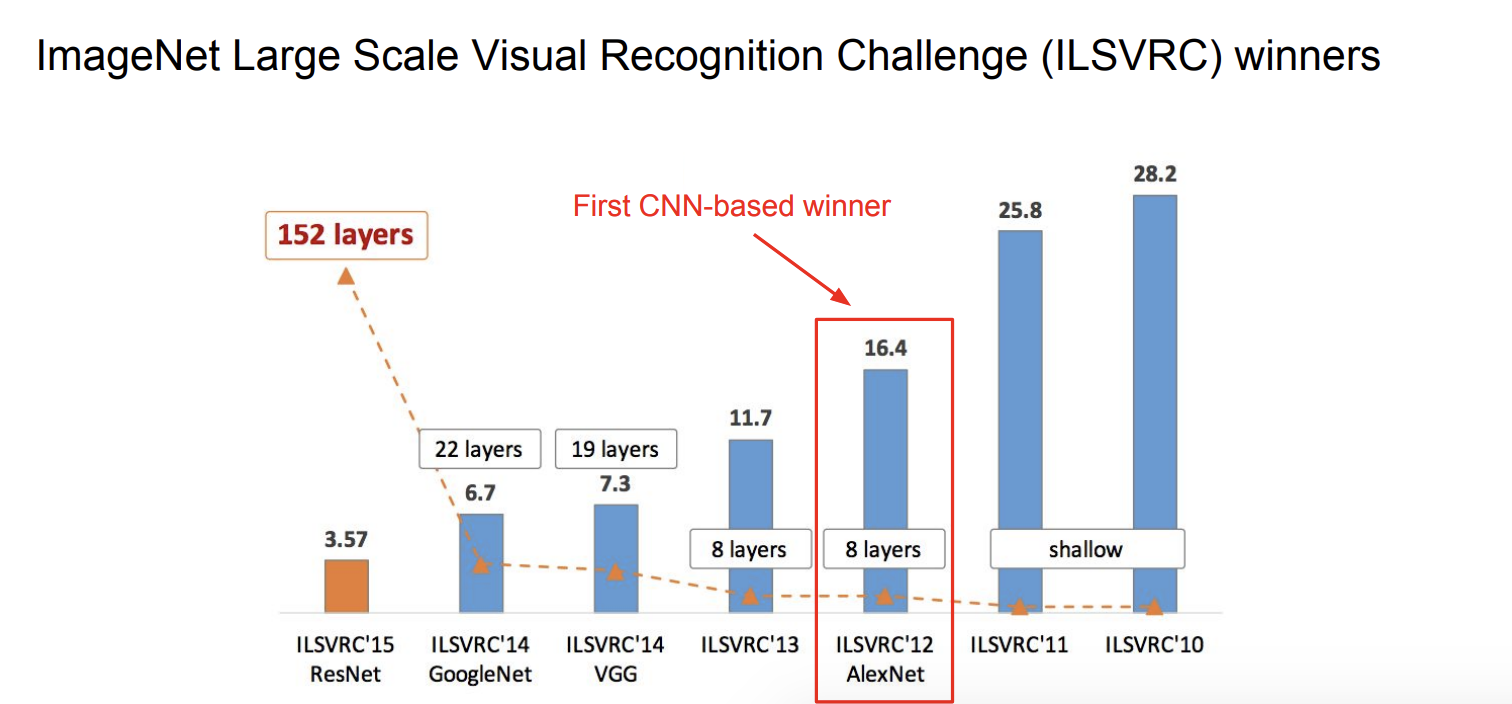
AlexNet은 2012년 ILSVRC에서 우승해서 주목을 받았다. 기존 모델들에 비해서 훨씬 낮은 오류율을 기록했다.
VGGNet
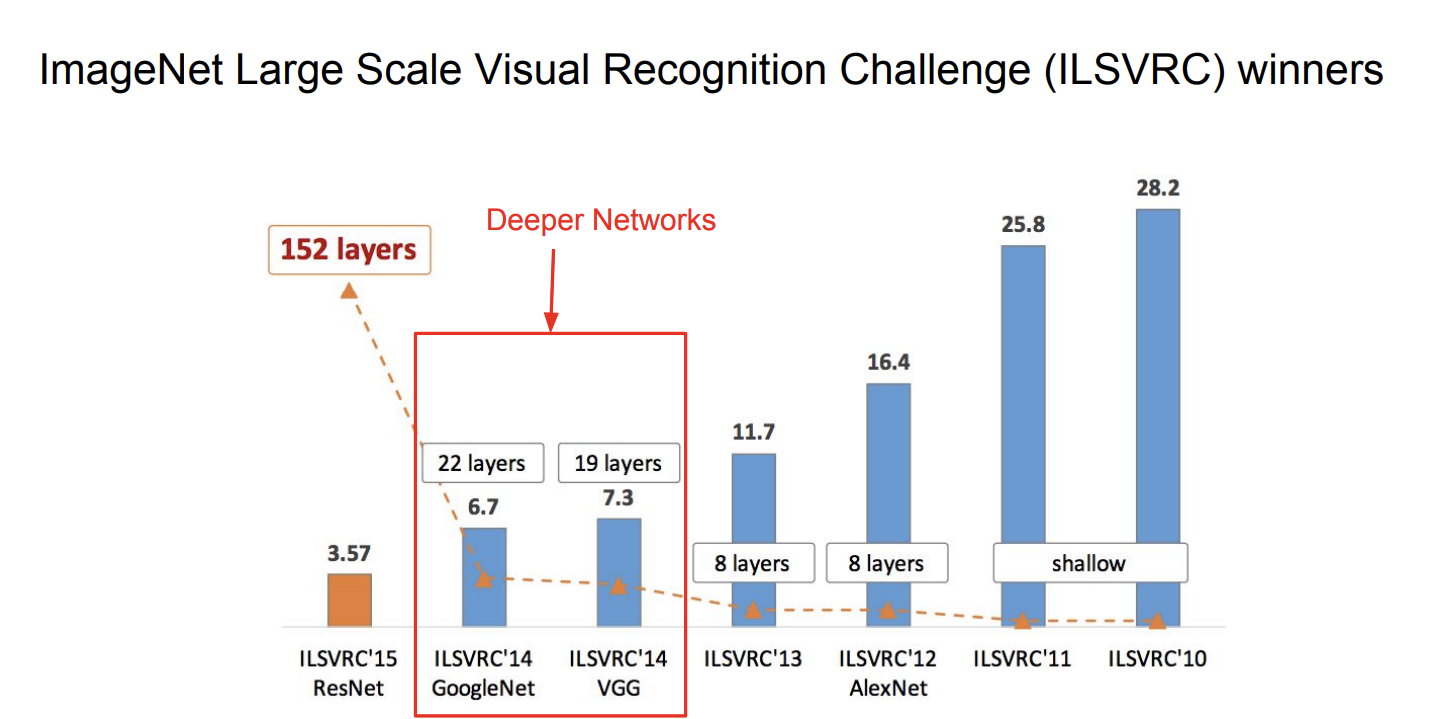
14년도를 보면 이전 레이어와 다르게 훨씬 더 깊은 networks를 구성한 것을 알 수 있다.
VGGNet은 2014년 옥스퍼드 대학에서 개발된 CNN이다.
특징
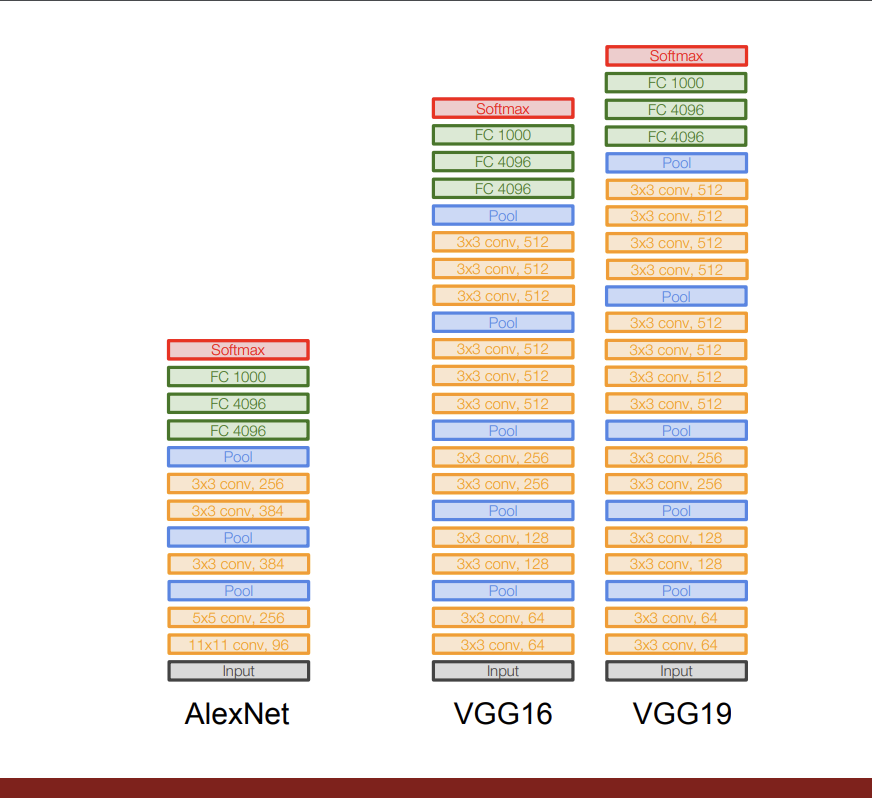
기존 AlexNet은 8개의 layer로 구성되어 있는 반면, VGG16Net의 경우에는 16개의 Layer로 구성되어있다.
VGG19Net의 경우에는 19개의 Layer로 구성되어 있다.
그리고 합성곱 층에서 오직 3x3 크기의 작은 필터를 사용한다.
최대 풀링은 2x2 크기이며 stride는 2이다.
그럼 왜 작은 필터들을 사용했을까? (합성곱층에서)
A. 모델의 학습 효율성 대문이다. 파라미터 수를 최소화할 수 있다. 만약 5x5 크기의 필터를 사용한다면 25개의 파라미터의 숫자가 필요하지만 3x3 크기의 필터 2개를 사용해도 파라미터의 숫자는 18개이기 때문이다.
Stack of three 3x3 conv (stride 1) layers
has same effective receptive field as
one 7x7 conv layer
-> 이말인 즉슨 3개의 3x3 컨볼루션 레이어는 하나의 7x7 컨볼루션 레이어를 가지는 것과 같은 유효 수용 필드를 갖는 것이다.
What is the effective receptive field of
three 3x3 conv (stride 1) layers?
7 x 7 이다.
이해하기 쉽게 그림을 그려보았다. 나같은 사람은 직접 해봐야 직성이 풀리는 사람이라 직접그려보니 이해가 되었다.
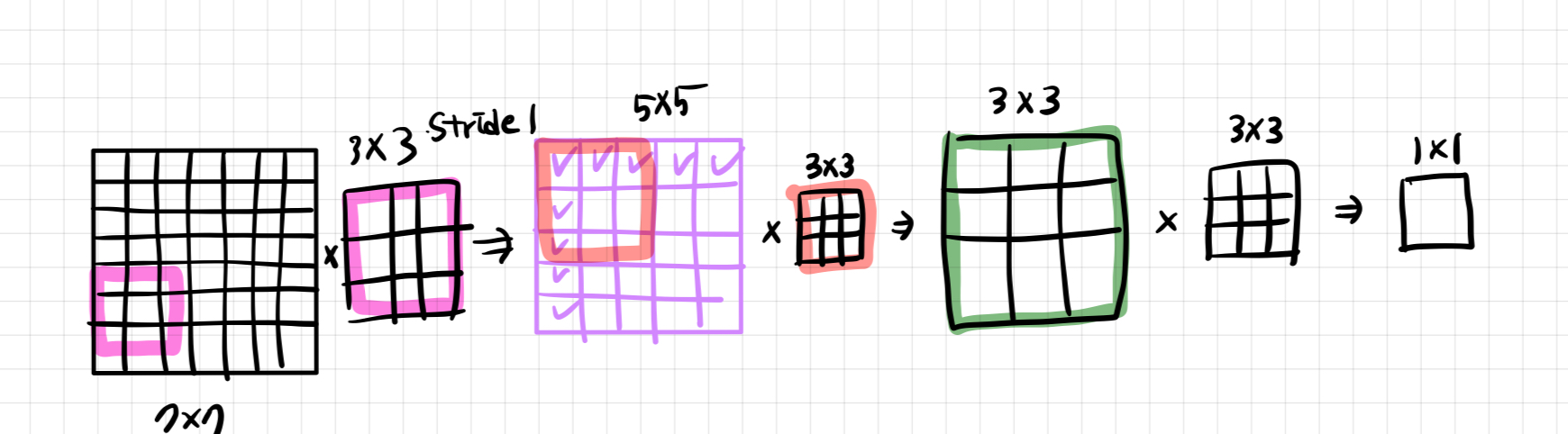
그럼에도 effective receptive field는 동일하지만 파라미터의 수를 비교하면
3 x vs
C는 레이어당 채널 수.
훨씬 3x3 크기 3개가 더 적게 파라미터가 필요한 것을 알 수 있다.

모든 층에서 메모리랑 파라미터의 숫자를 보면 위와 같다.
총 메모리는 24M 8 4byptes ~= 96MB / image 이고
총 파라미터 수는 138M 이다.
대부분의 메모리는 초기 컨볼루셔널 층에서 사용되었고 대부분의 파라미터들은 마지막 FC 층에서 사용된다.
Details:
- ILSVRC’14 2nd in classification, 1st in localization
- Similar training procedure as Krizhevsky 2012
- No Local Response Normalisation (LRN)
- Use VGG16 or VGG19 (VGG19 only slightly better, more memory) -> 19가 좀더 많은 메모리를 사용하지만 더 성능이 좋다. 하지만 보통은 16을 사용한다고 한다.
- Use ensembles for best results
- FC7 features generalize well to other
tasks
GoogLeNet
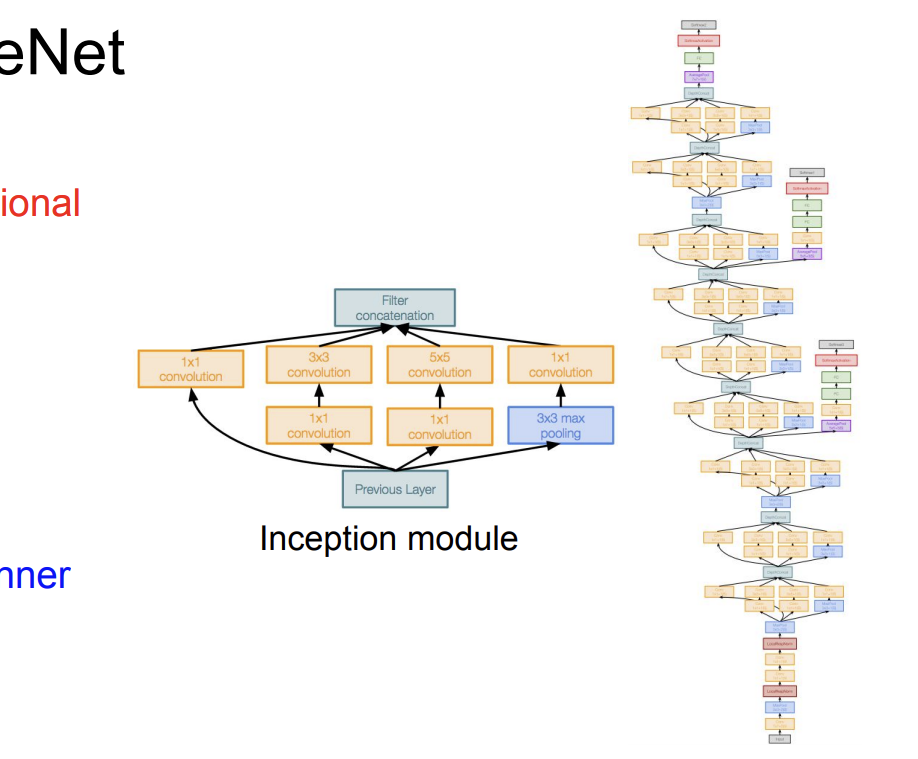
GoogLeNet은 2014년 구글 연구팀에 개발된 CNN 아키텍쳐이다.
이 모델에서 특이한 점인 '인셉션 모듈'이라는 독특한 구조를 가지고 있다는 점이다.
- 22개의 레이어층을 가진다.
- 인셉션 모듈을 가진다.
- FC 레이어층이 없다.
- 5 Million 개의 파라미터들을 가진다.(이건 AlexNet 와 비교해서 12배 적다고 한다)
- ILSVRC 14 분류기 우승자이다.
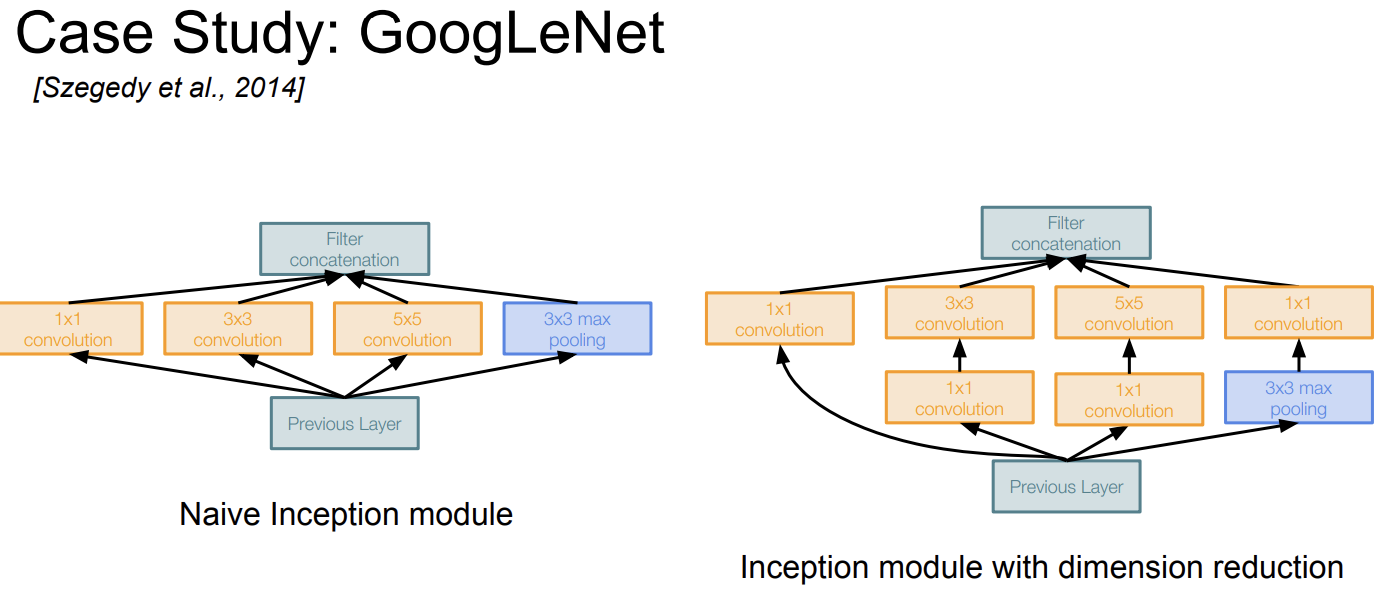
GoogLeNet에서 중요한 Inception Module이 대체 무엇인가?
Inception Module
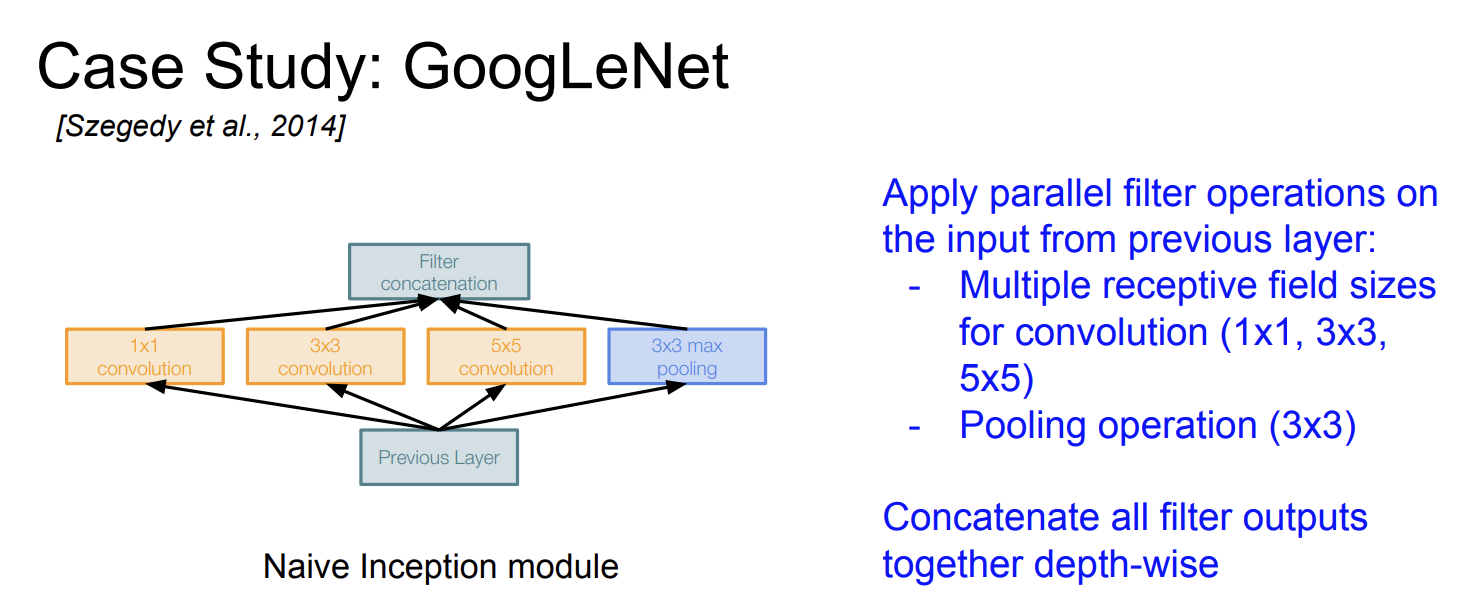
이 모듈은 다양한 크기의 컨볼루션 연산과 풀링 연산을 병렬적으로 수행하고 그 결과를 합치는 구조이다.
Q: What is the problem with this?
[Hint: Computational complexity]
그럼 인셉션 모듈은 단점이 없는가? 아니다.
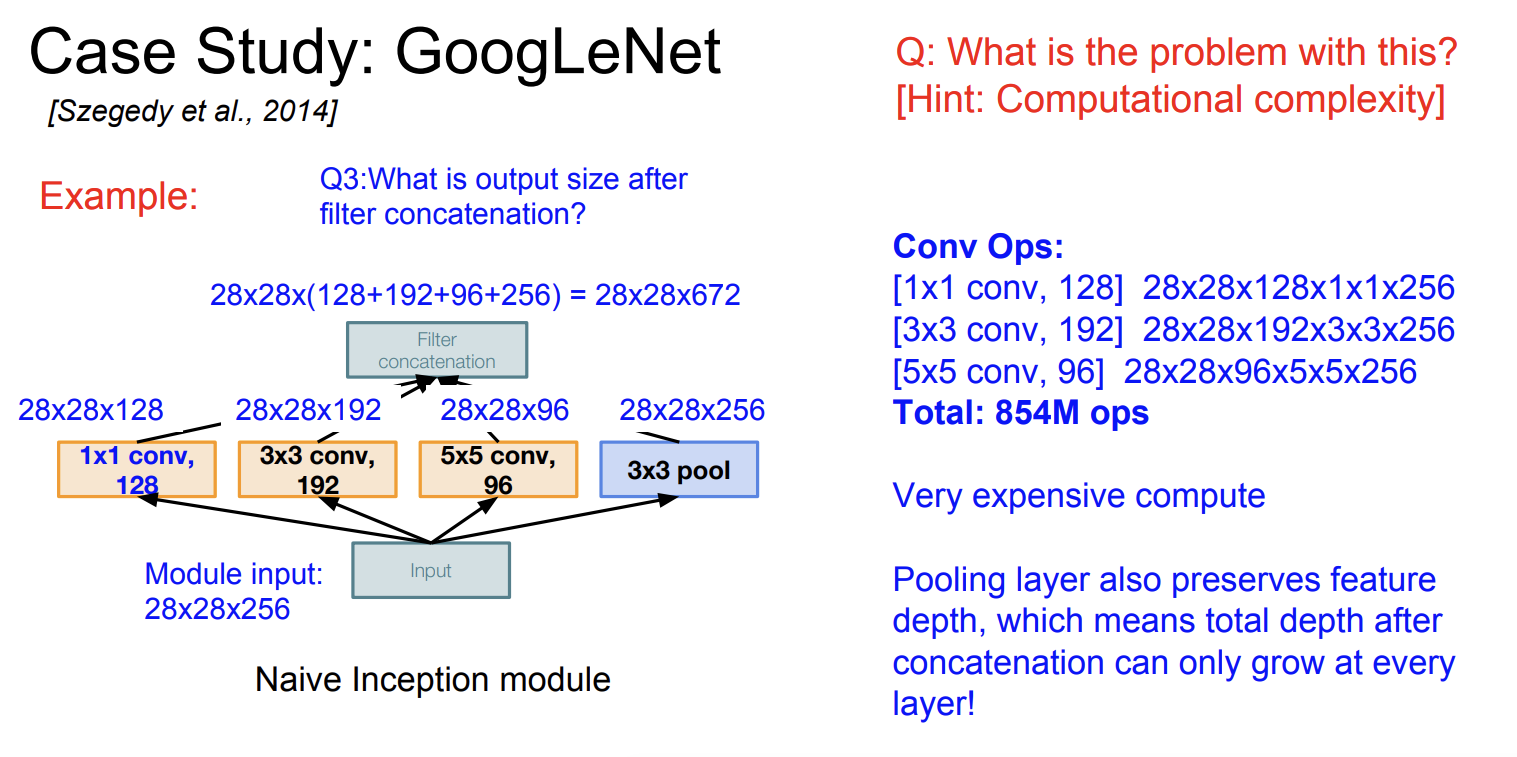
input module은 28 x 28 x 256 이라 하자.
일단 처음 1x1 conv 레이어에 대해서 결과 size는
28 x 28 x 128 이 된다.
두번째 conv layer를 보면 3x3 크기가 192개이다. output size는 28 x 28 x 192이다.
여기서 zero padding 을 더해서 크기가 줄어들지 않았다고 한다.
그래서 총 output filters를 다 더해서 보면
최종 size는
28 x 28 x (128 + 192 + 96 + 256) = 28 x 28 x 672 이다.
그럼 계산량은 얼마나 될까?
계산해보면 총 854M ops를 계산한다. (8억5천4백)
매우 expensive 계산이다.
그리고 문제는 점점 더 많은 depth가 생겨난다는 것이다.
그래서 구글이 제시한 해결 방법은 바로 bottleneck이다.
bottleneck은 병목현상인데, 우리는 1x1 conv layer를 사용해서 feature map의 depth를 줄이는 것이다.
이전에 5강에서 cnn에 대해 자세히 배웠는데, 이때 사용한 ppt를 보자.
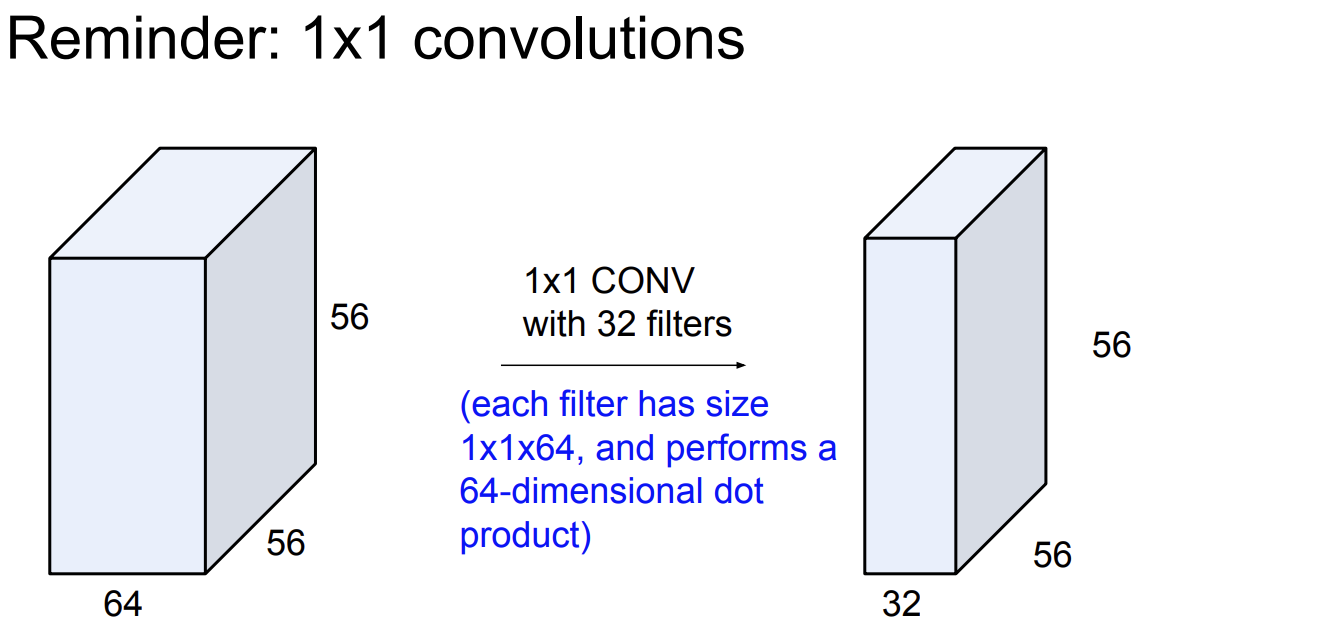
input 은 56x56x64 이고 32개의 1x1 conv layer가 있다고 하자.
하나의 필터는 1x1x64 인 것이다. 64개의 가중치가 있는 것이다. 그래서 1:1 대응 하고 64개를 곱하고 더한다음 하나의 픽셀이 되는 것이다.
그림으로 이해해보자.
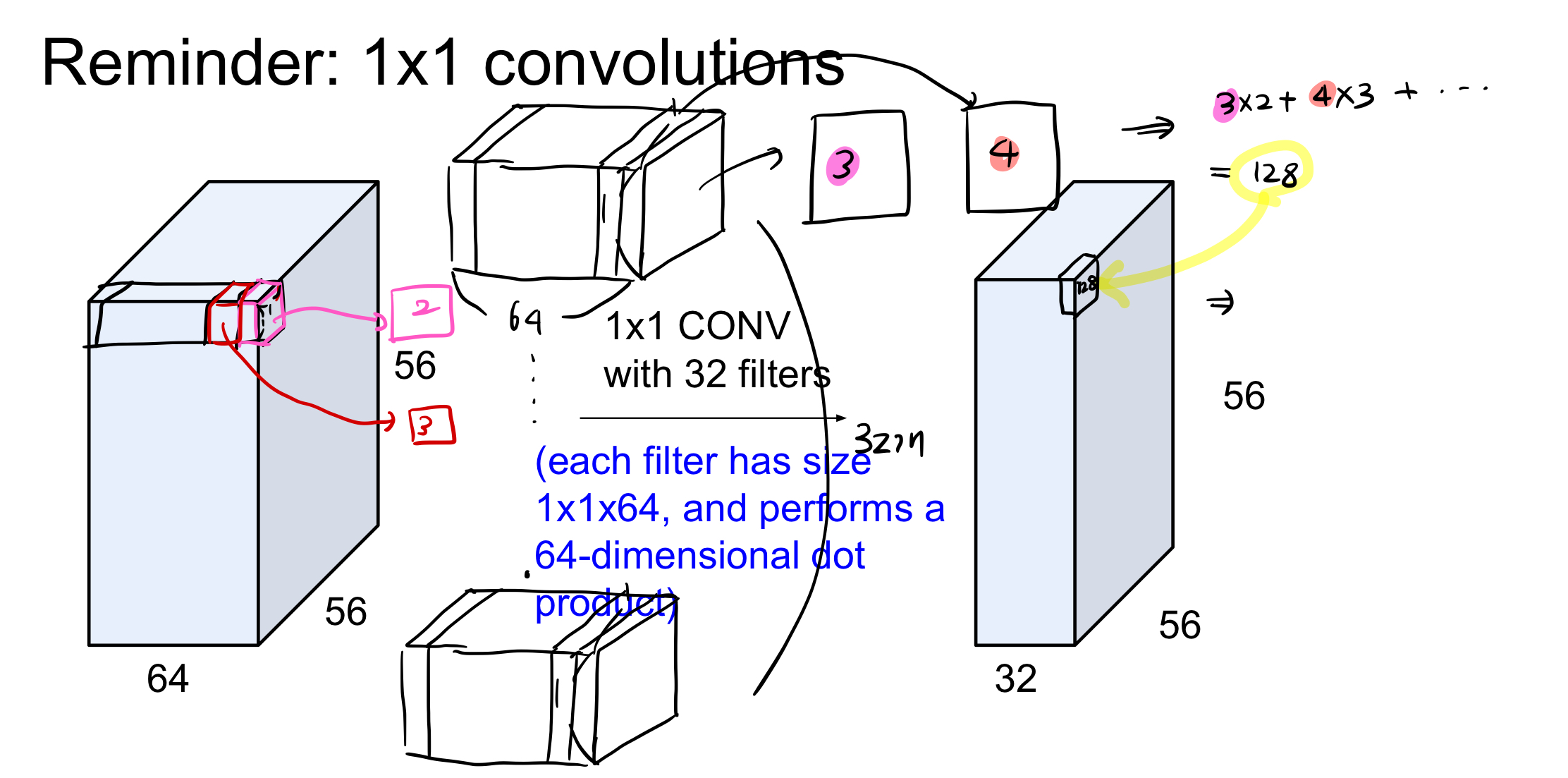
1x1 합성곱은 그래서 depth를 줄이기위해 사용된다.
총 output은 56x56x32가 된다.
그래서 1x1 conv layer를 추가한다.
이를 bottleneck layers라고도 한다.
그럼 얼마나 계산량이 줄었을까?
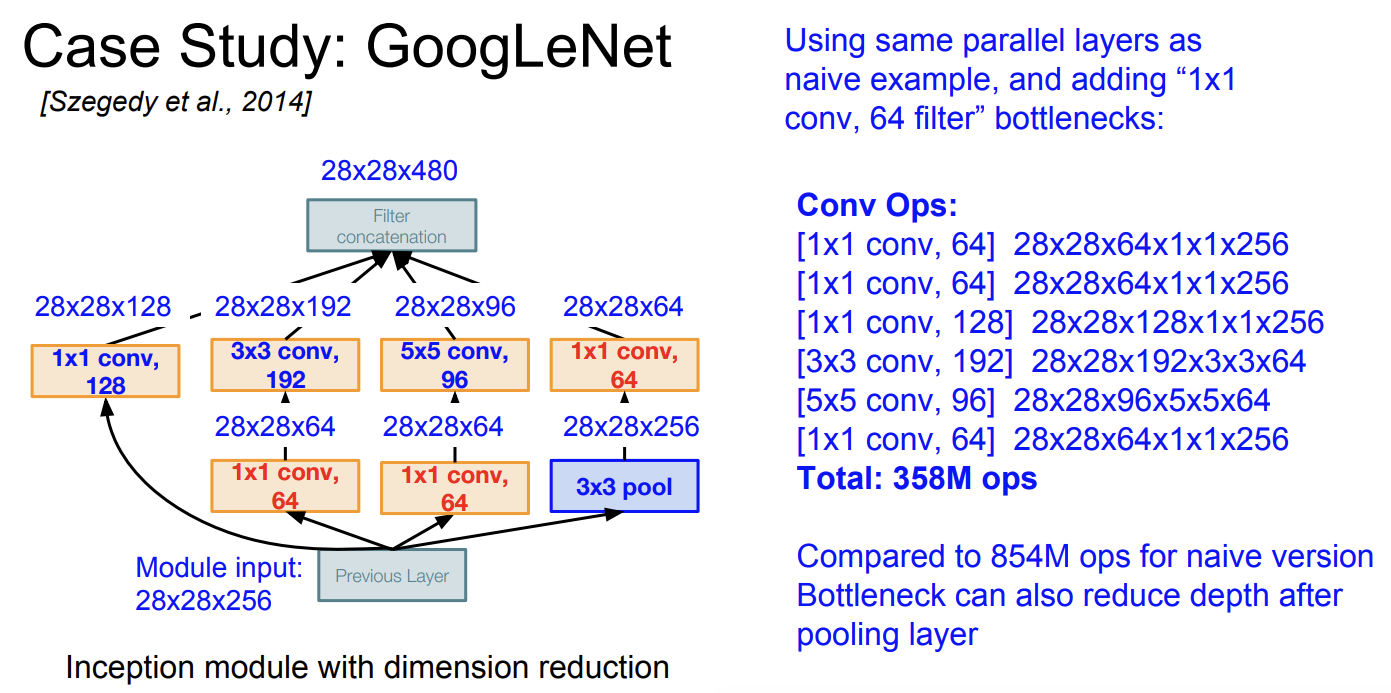
3억 5천 8백만개의 계산이다.
이전 854M 번의 계산과 비교하면 확실히 줄었다는 것을 알 수 있다.

Architecture
구조를 살펴보자.
일단 GoogLeNet의 초기 부분을 보면 여러개의 networks가 있다.
이를 Stem Network이라 한다.
다음과 같은 구조를 가지고 있다.
1. 합성곱
2. 최대 풀링
3. 2개의 합성곱
4. 최대 풀링
이러한 구조는 이미지에서 초기 고차원 특징들을 추출하고 네트워크 뒤부분에 있는 inception module이 더 복잡하고 정교한 특징을 추출할 수 있도록 기반을 만든다.
초기 단계에서 이미지의 크기를 줄여서 전체 계산량을 효율적으로 만든다는 것도 있다.
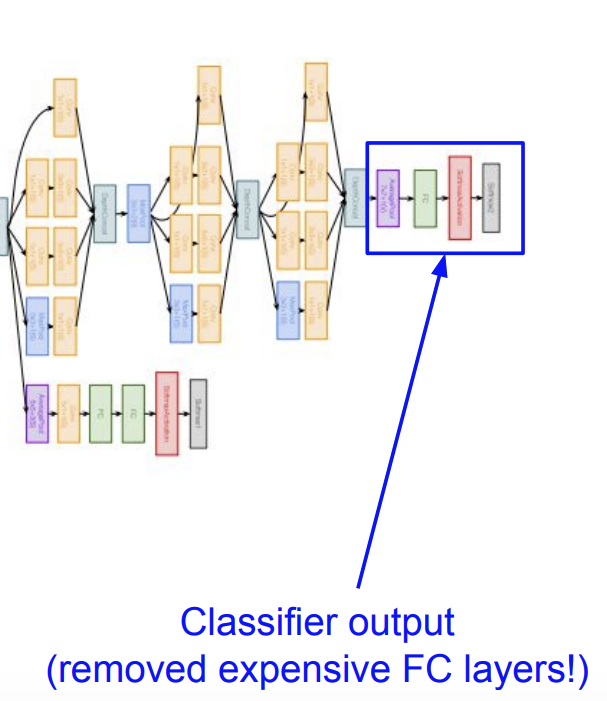
그리고 마지막 부분에서는 비싼 FC 레이어를 제거하고 대신에 분류기를 사용한 것을 알 수 있다.
그림은 화질이 안좋아서 뭐라 적혀있는지 안보인다. 다시 적자면,
- (보라색)Average Pooling : 이 층은 각 feature map에 대해 전체 공간적 영역에 걸쳐서 평균값을 계산한다. 이전 FC 방식 대신에 사용한 것이다.
- (연두색) FC : 아니 FC 방식이 그 다음에 추가되니까 똑같은거 아닌가? 라고 생각할 수 있지만, 이는 연산의 효과 보다는 label에 더 쉽게 접근하기 위함이라 한다.
- (빨간색) Softmax : 마지막 층의 출력은 소프트맥스 함수를 통과해서 각 클래스에 대한 예측 확률로 변환한다.
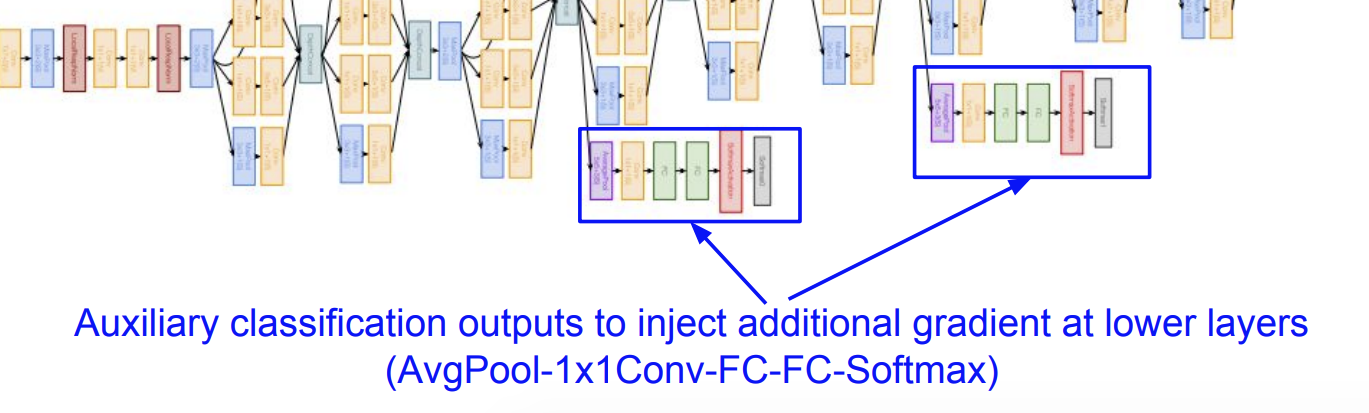
그리고 보조 분류기를 사용했다. 이들은 네트워크의 그래디언트 소실 문제를 완화한다. 하지만 최종 예측에서는 보조 분류기들의 출력이 사용되지 않는다고 한다.
그러니까 우리가 역전파를 실행할 때, 너무 깊은 층의 네트워크에 대해서는 당연히 역전파 기울기를 구하기 어렵다.
그래서 중간 중간 보조 분류기를 넣어서 기울기를 저장하는 개념으로 나는 생각했다.
하지만 GoogleNet Inception-v4에서는 보조 분류기를 사용하지 않았다.
그 이유는
- 그래디언트 소실 문제 해결 : 후속 모델들에서는 배치 정규화, 더 효율적인 활성함수의 사용으로 그래디언트 소실 문제를 해결했기 때문이다.
- 더 효율적인 네트워크 구조를 가져서 그래디언트 소실 문제에 덜 취약한 구조로 설계됨
등등의 이유로 보조 분류기는 사용되지 않는다고 한다.
ResNet
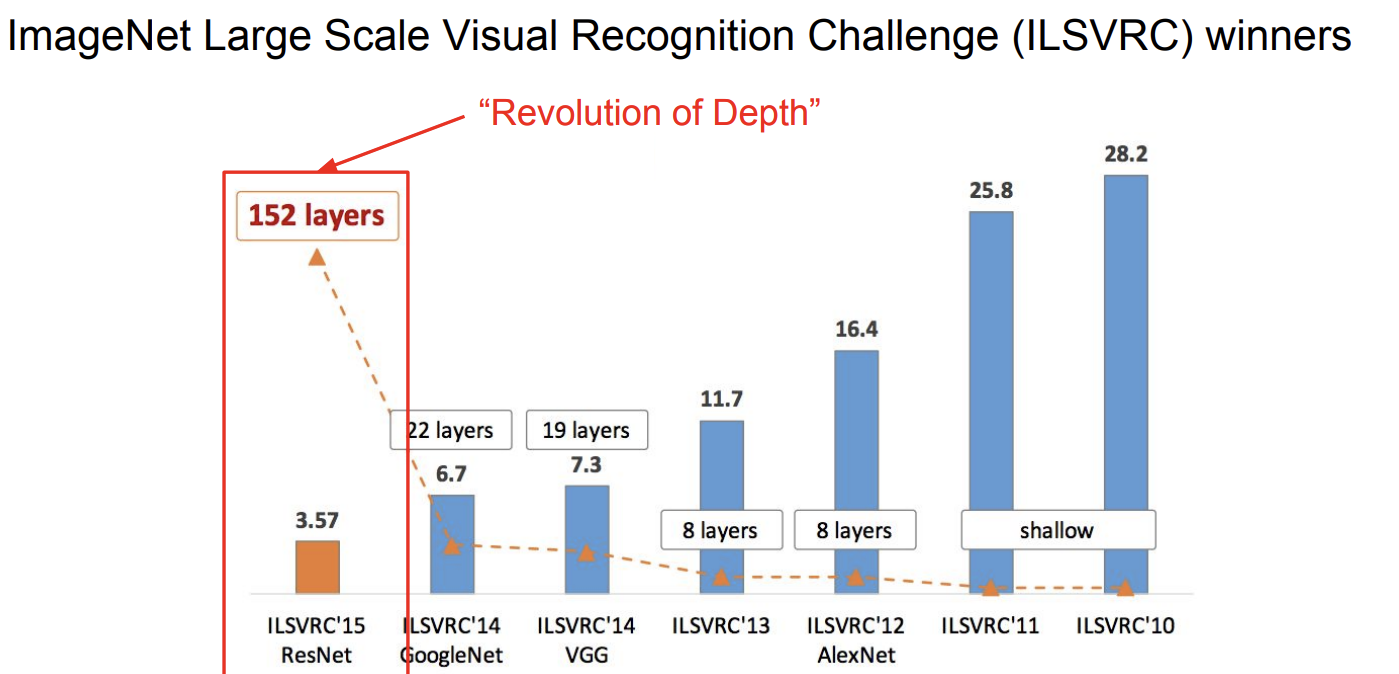
그리고 2015년에 Microsoft Research 에서 개발된 CNN인 ResNet에 대해 알아보자. 이 신경망 아키텍쳐는 15년 ILSVRC 우승자이다.
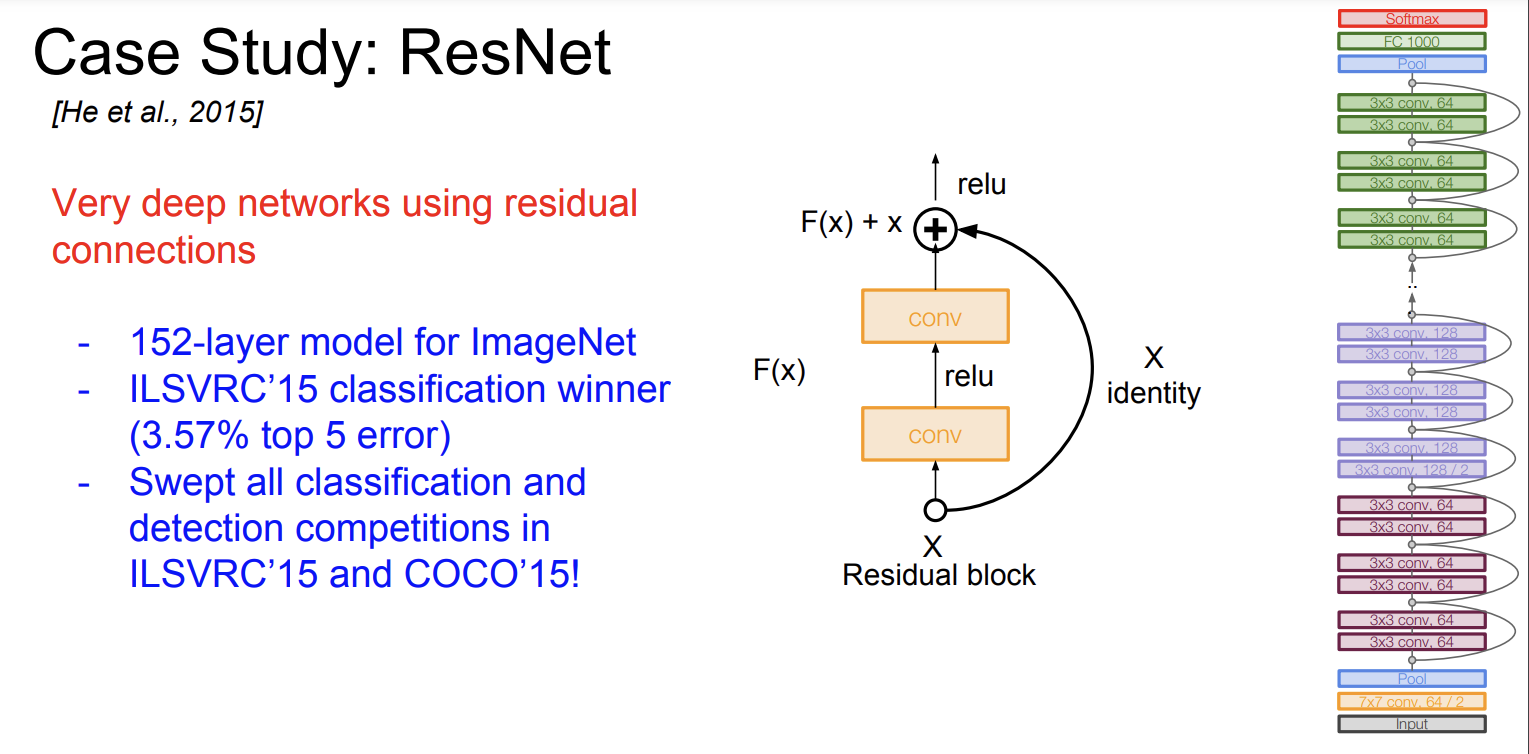
- 152개의 layer를 사용했다.
- residual connections (잔차 연결)을 사용했다
residual connections
이 residual connections을 사용해서 신경망이 더 깊어질수록 학습이 어려워지는 문제, 손실되는 기울기 문제를 해결했다.
(이전 224n의 transformer 구조에서 살짝 다루었다.)
손실되는 기울기 문제가 왜 일어나는지는 다음 블로그를 참고하자.
[DL] Exploding & Vanishing Gradient 문제와 Residual Connection
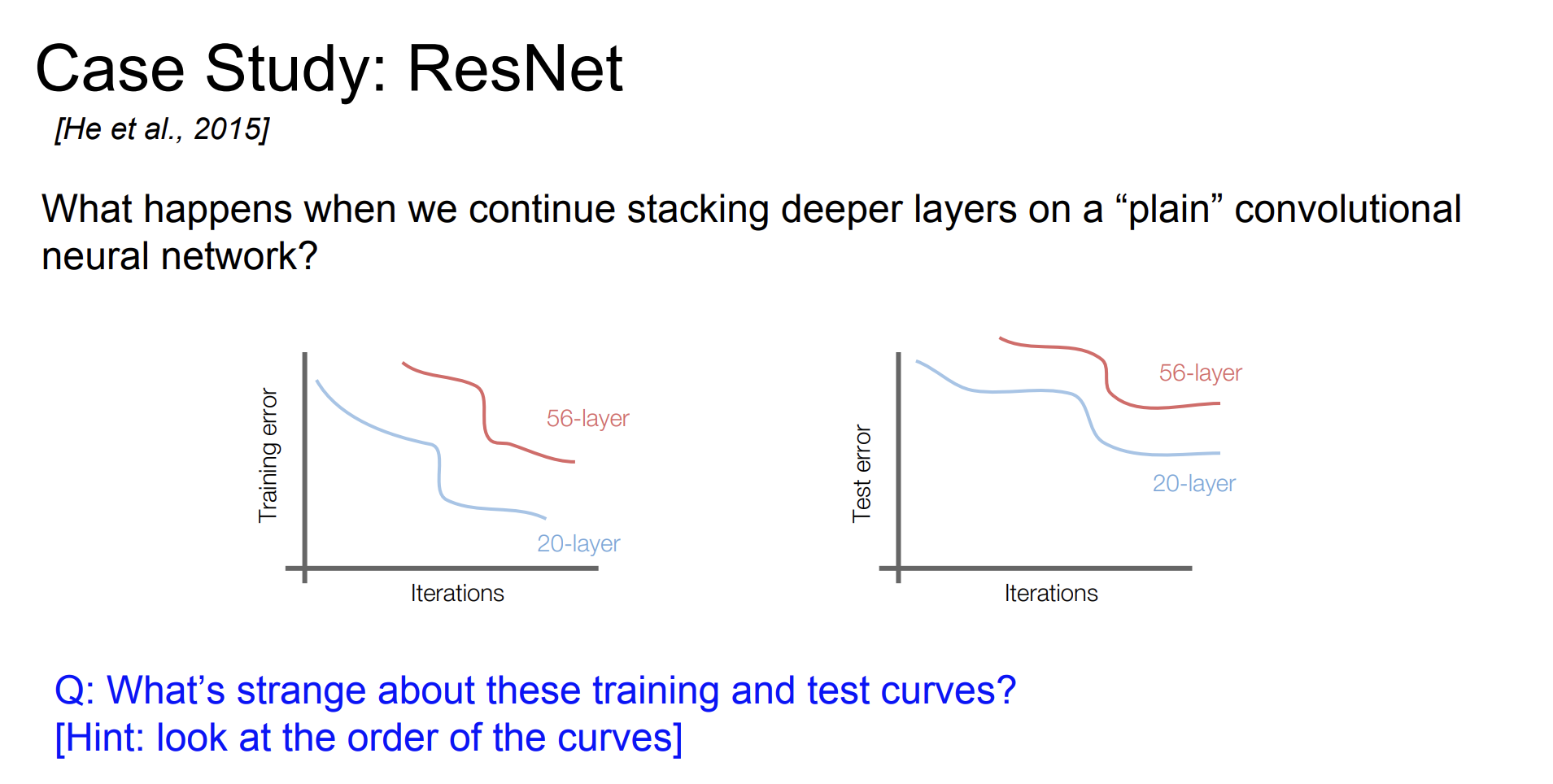
연구자들은 깊은 네트워크에서의 Training error 와 Test error를 비교했다. 오히려 깊은 네트워크의 오류율이 낮은 네트워크보다 더 높았다. 하지만 Train과 Test의 차이가 그렇게 크지 않은 것을 보아서 Overfitting 문제는 아니라고 생각했다.
그래서 가설을 세웠다.
문제는 최적화 때문이다. deeper 모델일 수록, 더 최적화 하기 힘들다.
더 깊은 모델은 얕은 모델만큼의 성능을 가져야만 한다. 그래서 방법이 바로 identity mapping을 해서 추가 레이어를 더하는 것이다.
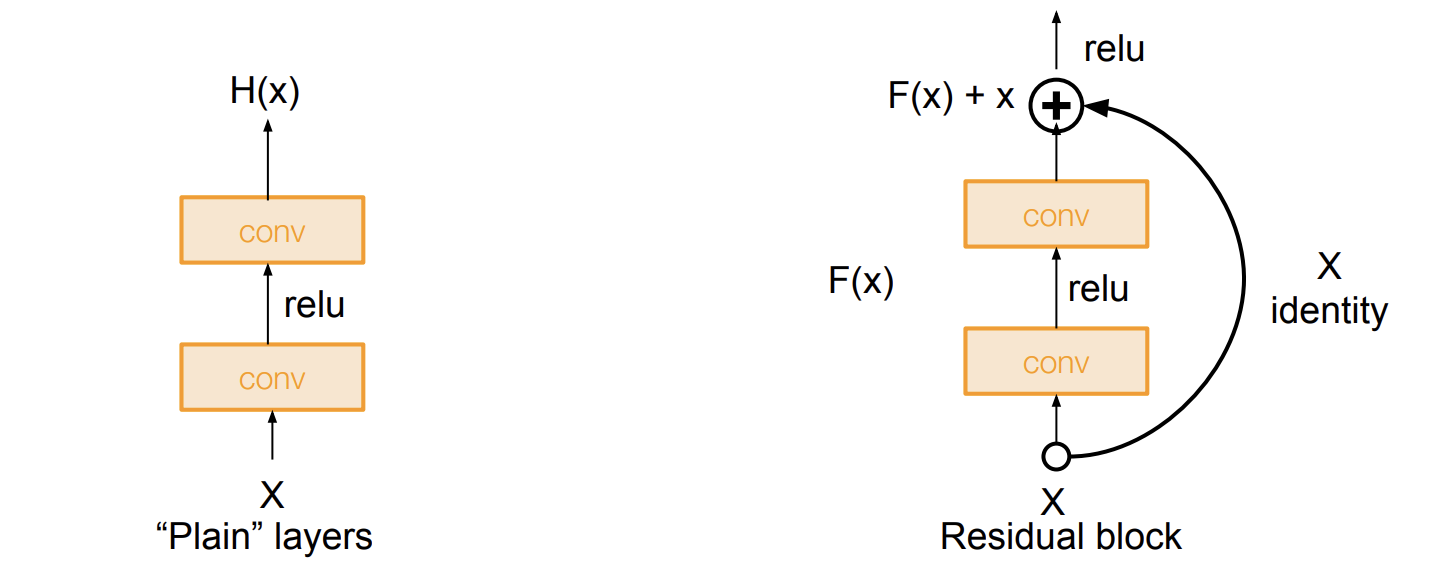
그래서 여기 H(x) = F(x) + x
로 둘 수 있다.
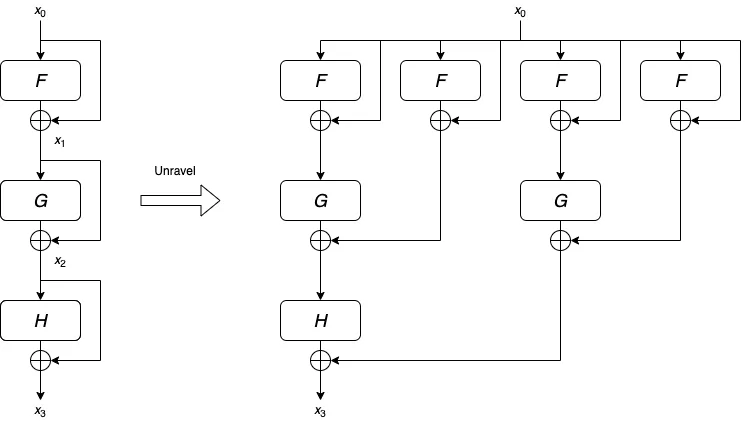
왼쪽 그래프를 풀어 오른쪽 그래프로도 나타낼 수 있다.
(그림 출처: https://towardsdatascience.com/what-is-residual-connection-efb07cab0d55)
Architecture
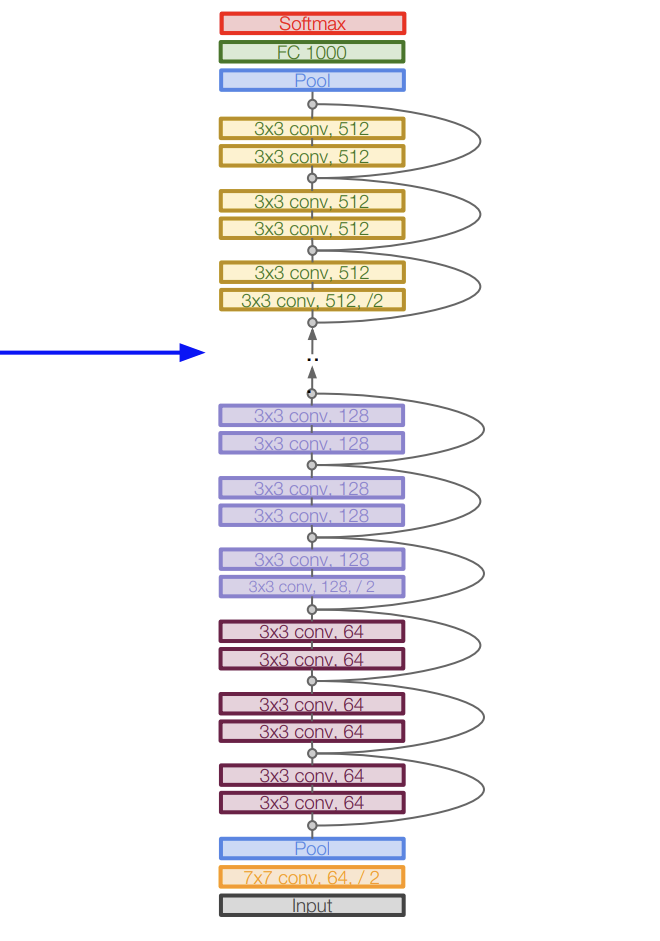
- 여러개의 Residual block 들로 구성되어 있다.
- 모든 Residual block emfdms 2개의 3x3 conv layer로 구성되어 있다.
- 주기적으로 필터 수를 2배씩 늘리고, stride를 2로 설정해서 다운샘플링을 한다.
- 초기에는 Conv layer를 추가한다.
- 마지막 conv layer 다음에는 Global average pooling layer가 있다.
- 마지막에 FC layers가 없다. 오직 FC 1000만 있는데, 이건 classes 들을 출력하기 위함이다.
- 총 깊이는 34, 50, 101, 152 개 layer가 종류별로 있다고 한다.

50개 이상의 층을 가진 네트워크에는 bottleneck을 사용해서 효율성을 증가시켰다.
1x1 conv layer를 추가했다.
Training ResNet in practice
- 모든 Conv layer 다음 배치 정규화를 했다.
- Xavier/2 초기화를 했다.
- SGD+ Momentum 0.9 사용
- 학습률을 처음에는 0.1로 설정하고 검증 오류가 정체 될 때 10으로 나눈다.
- 미니 배치 크기는 256
- Weight decay of 1e-5 : 가중치를 감소 시킨다. 오버피팅을 방지하기 위함
- 드롭아웃을 사용하지 않는다.
Comparing complexity
ResNet은 사람보다 더 좋은 성능을 보였다고 한다.
사람의 이미지넷 분류 오류율이 5%라면 ResNet은 3.6%라고 한다.
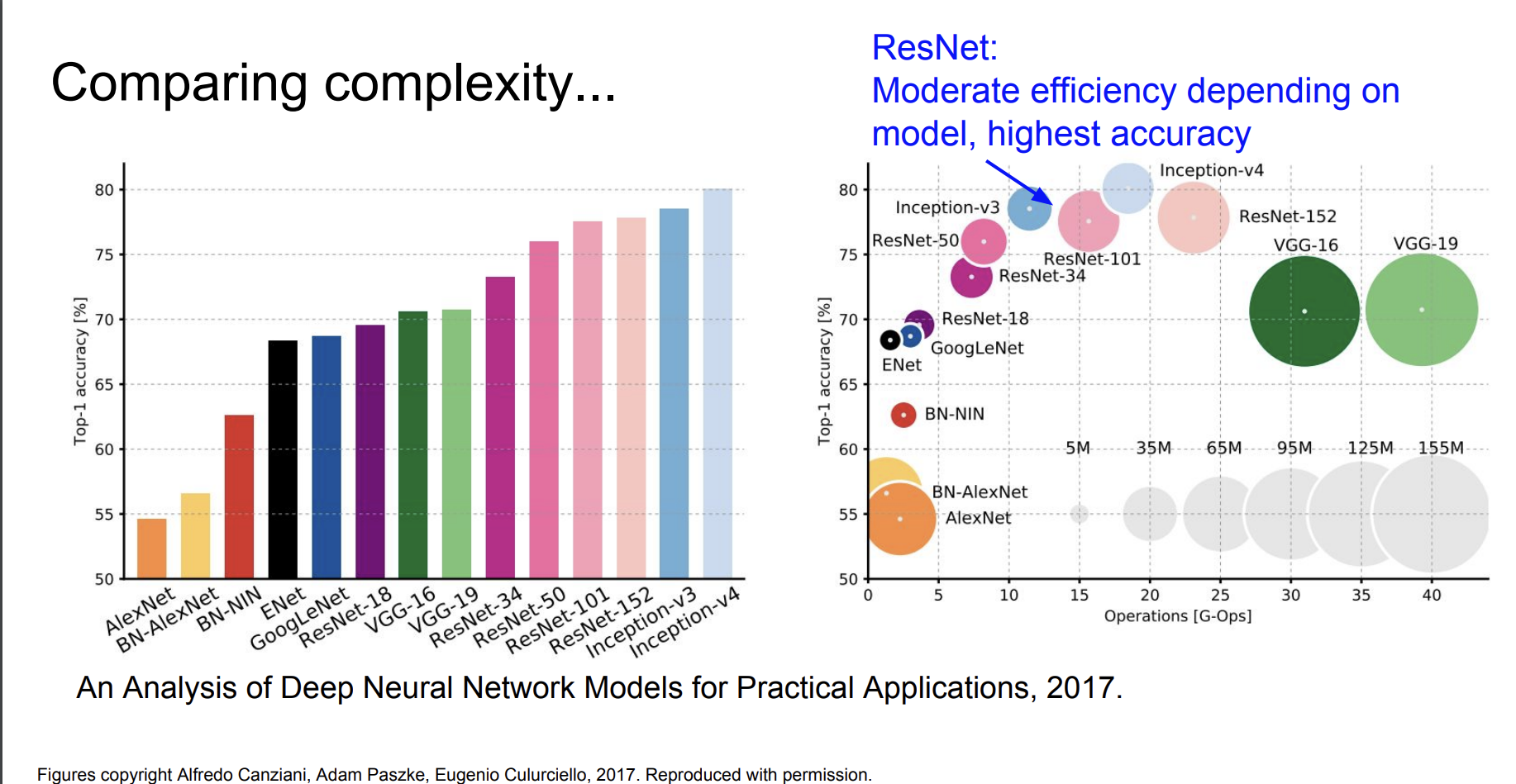
아키텍쳐들을 종합해서 비교해보자.
- 제일 정확도가 높은 Inception-v4는 Resnet + Inception이다.
- VGG 는 메모리도 많이 먹고 Operations도 많이 해야한다.
- GoogLeNet은 이중 가장 크기도 작고 Operations도 적어서 효율적이다.
- AlexNet은 가장 계산량이 적지만 메모리는 무겁고 정확도가 낮았다.
- ResNet의 경우 효율성은 중간정도이지만 가장 높은 정확도를 보였다.
Other Architectures
지금까지 4개의 아키텍쳐만 보았다면 이제는 다른 것들도 간단하게 살펴보자. 여기서는 집중적으로 어떤 아키텍쳐인지 보는 것은 아니고, 그저 이런것이 있다~ 이정도만 보고 지나갈 것이다. 더 궁금한 점이 있다면 알아서 논문을 참고하자.
NiN
Network in Network이다.
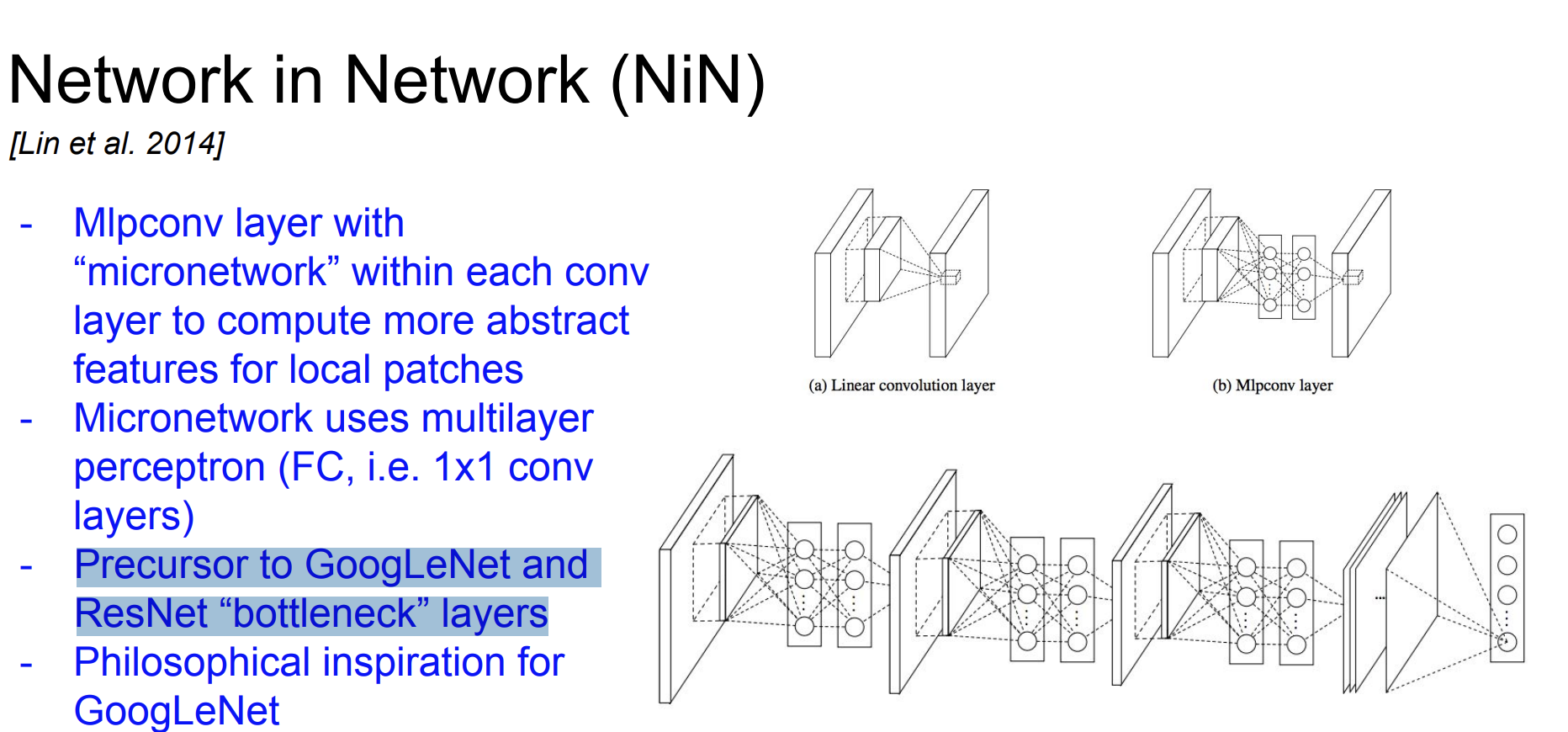
여기서 중요한 점은
- Precursor to GoogLeNet and ResNet “bottleneck” layers
즉 "병목현상"의 선두자였던 것이다.
Wide ResNet
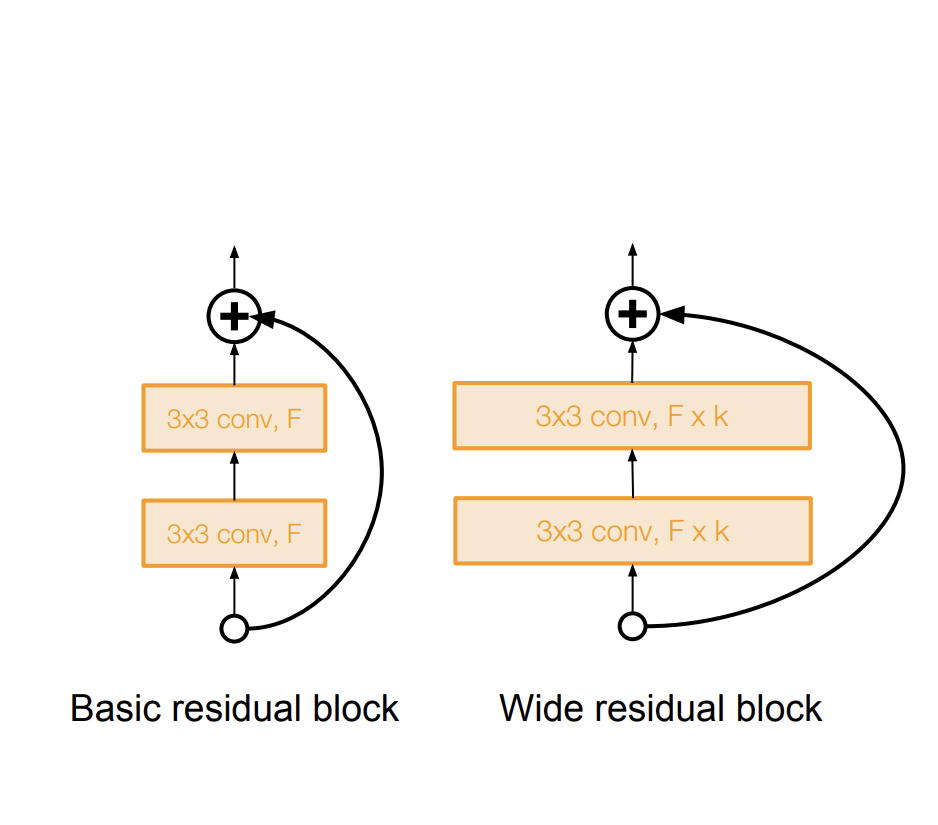
기존 ResNet의 residual block의 conv layer의 크기를 늘렸다. 그래서 계산 효율성을 늘렸다.
ResNeXt
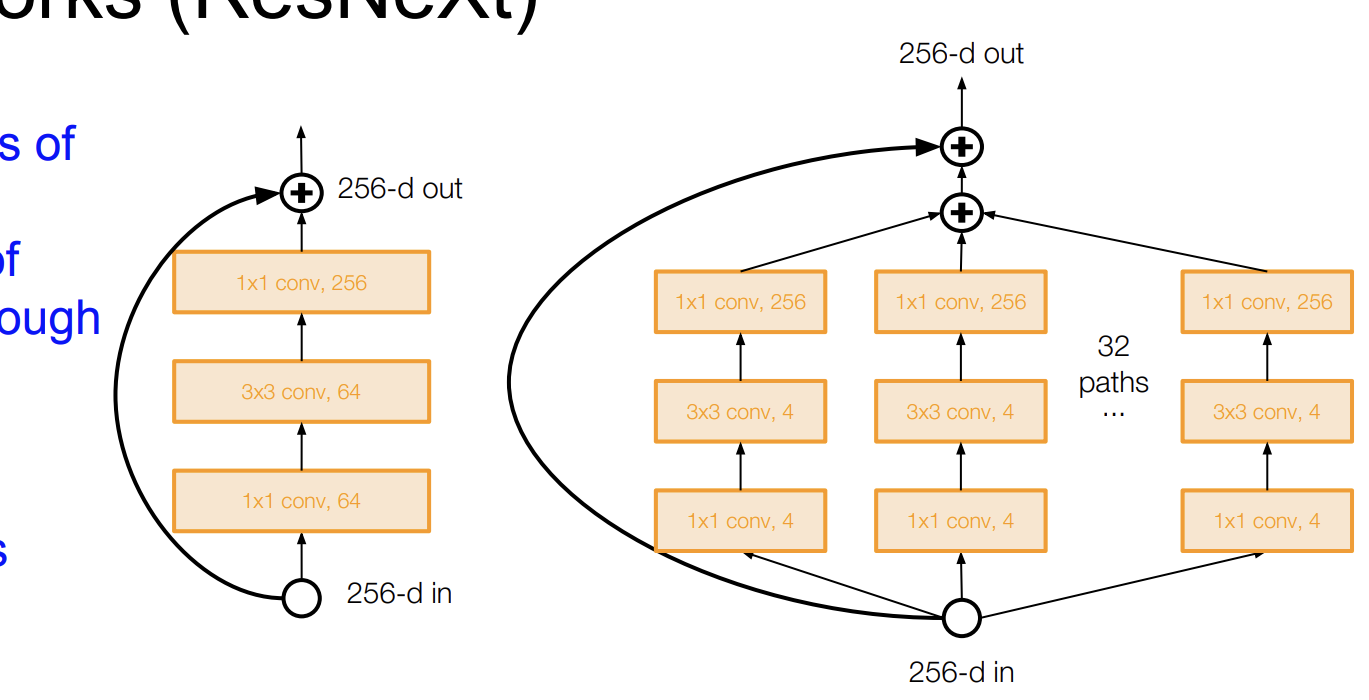
이것 또한 ResNet을 활용한 것이다.
더 많은 Residual block을 추가했다. 어떻게 보면 Inception moudle 처럼 보이기도 한다.
Stochastic Depth
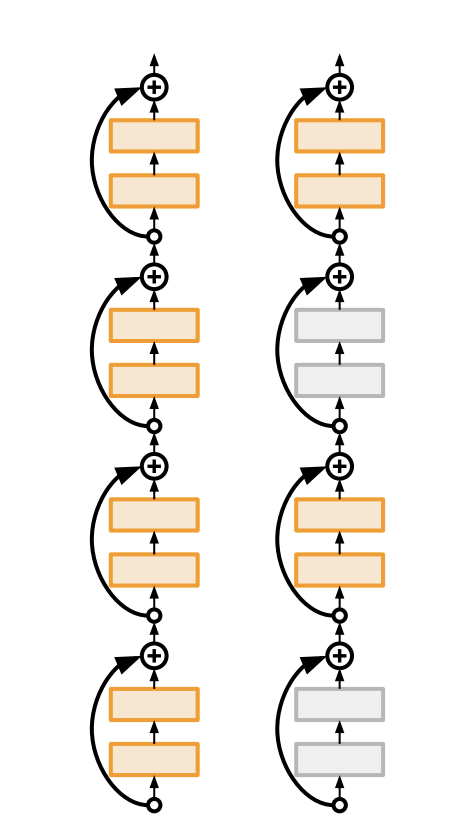
소멸되는 기울기를 줄이고, 훈련 시간을 단축시키기 위해 랜덤하게 몇몇의 layer의 subset들을 drop 한다.
그래서 identity function으로 bypass 하는 것이다.
FractaNet
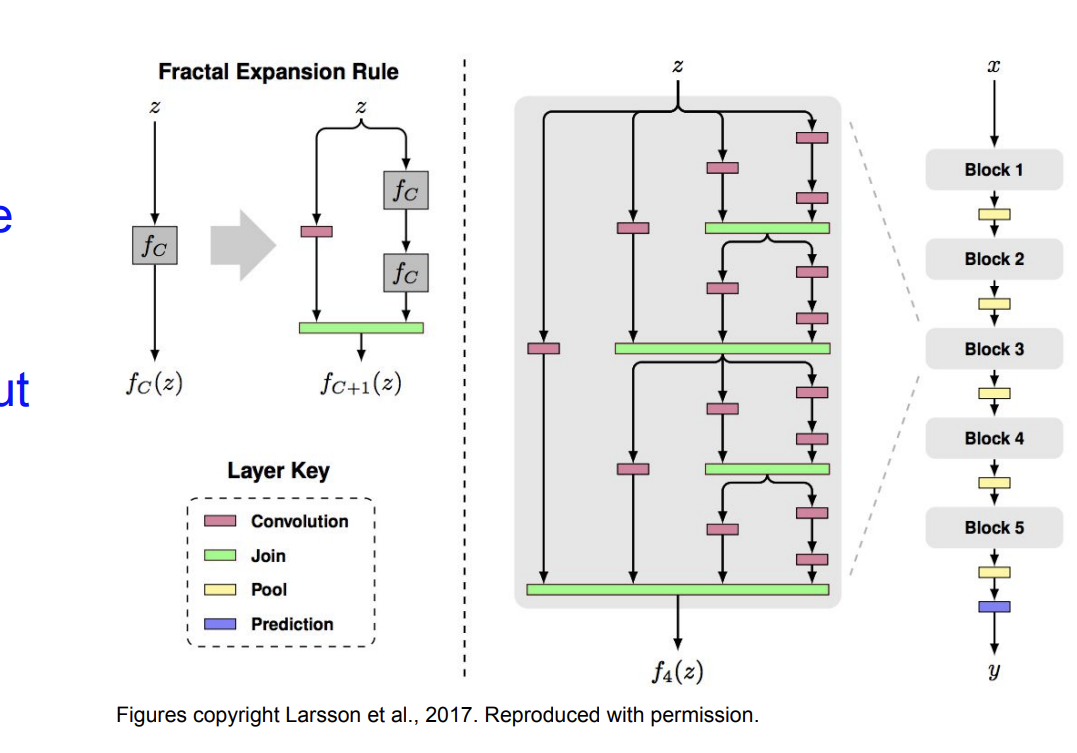
output에 대해서 얕은 네트워크와 깊은 네트워크 모두 있는 구조이다.
여기서는 residual connections가 필요하지 않다고 주장한다.
훈련할 때는 몇개의 sub path들을 drop out 하고 전체 네트워크를 한 테스트 시간에 실행한다.
SqueezeNet
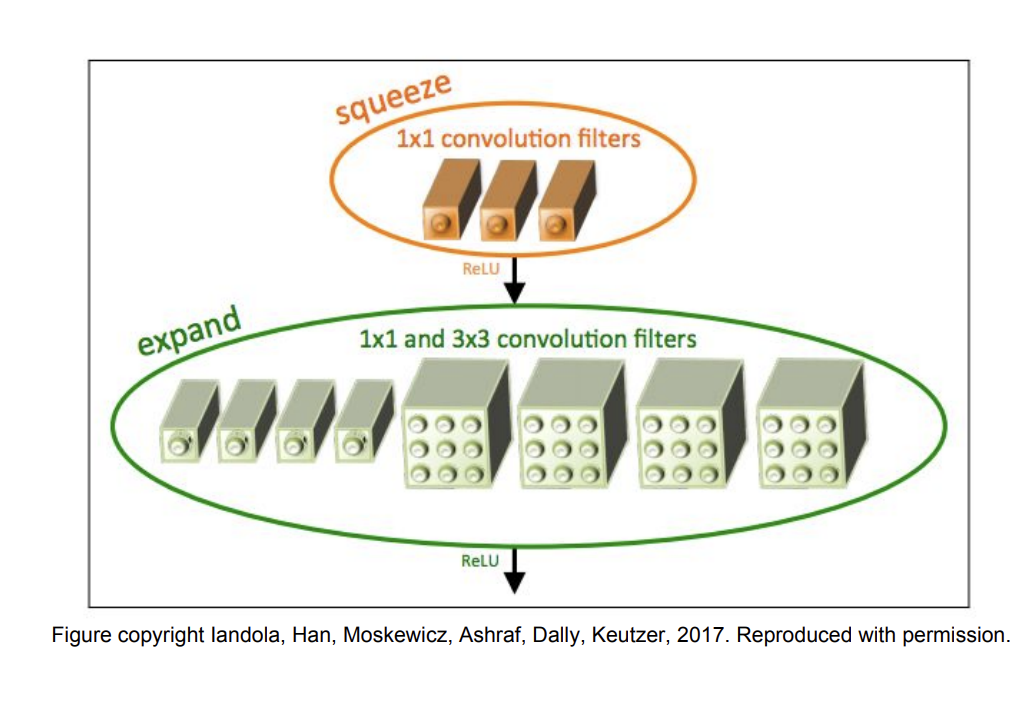
Squeeze 부분과 expand 부분으로 구성되어 있다.
Squeeze 부분은 1x1 conv layer로 구성되어 있고 expand 부분은 1x1과 3x3 conv layers 로 구성되어 있다.
AlexNet과 비교해서 50배 적은 파라미터를 사용하지만 성능은 비슷하고 또한 510배 크기를 줄였다고 한다. (0.5Mb)
Densely Connected Convolutional Networks
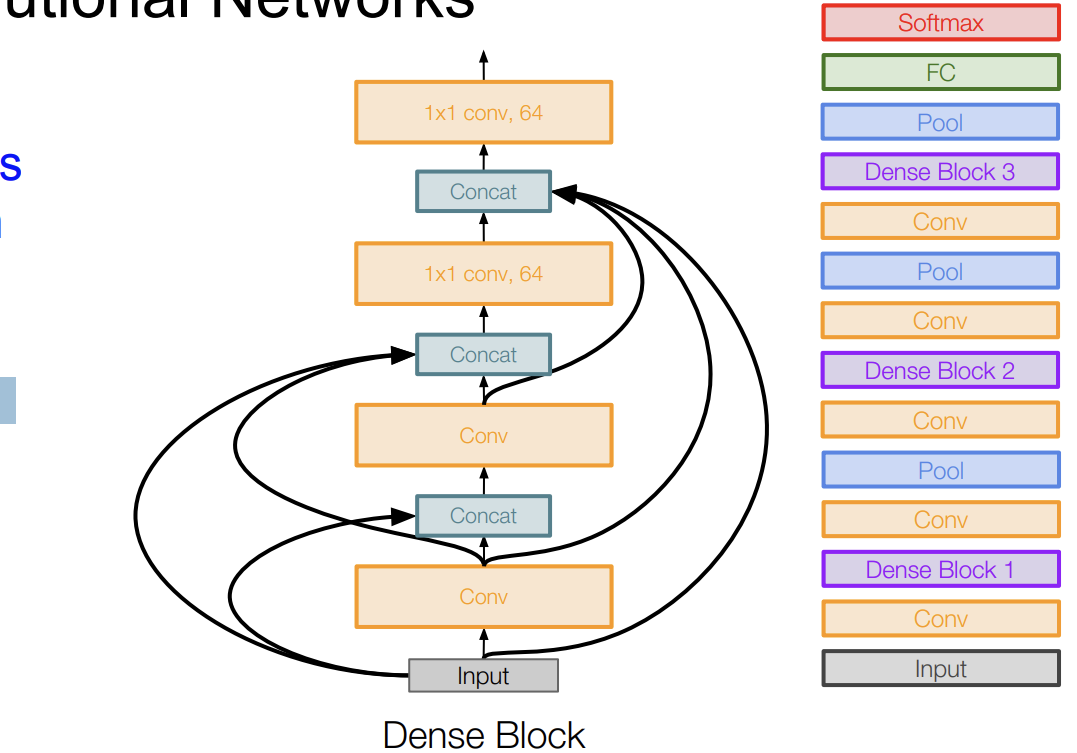
Dense Block을 만든다.
Dense Block을 각각의 층에 연결한다. 그래서 소실되는 기울기를 완화시키고 feature prpagation, feature reuse를 강화시킨다.
