[231N] Lecture 8 review
Lecture 8
이제 8번째 강의이다.
이번 강의에서는
- CPU VS GPU
- Deep Learning Frameworks
- Caffe / Caffe 2
- Theano / TensorFlow
- Torch / PyTorch
를 배우고자 한다.
CPU VS GPU
컴퓨터 내에 있는 CPU는 생각보다 공간을 많이 차지 하지 않는다.

하지만 컴퓨터 내의 GPU는 공간차지를 굉장히 많이한다.
자체 전력 소비도 크기 때문에 냉각 장치도 따로 존재한다.

CPU (Central Processing Unit)
- Cores의 숫자가 더 적은 대신, 각 코어의 속도는 빠르다.
- 연속적 처리에 유리하다.
- Cache 가 있지만 메모리는 컴퓨터 디스크에서 사용한다.
GPU(Graphics Processing Unit)
- Cores의 숫자가 cpu보다 훨씬 많다.
- 하지만 각 코어의 속도는 느리다.
- 동시에 작업이 가능해서 병렬적 처리에 유용하다.
GPU에 완벽하게 적합한 Prototype 알고리즘이 바로 행렬 계산이다.
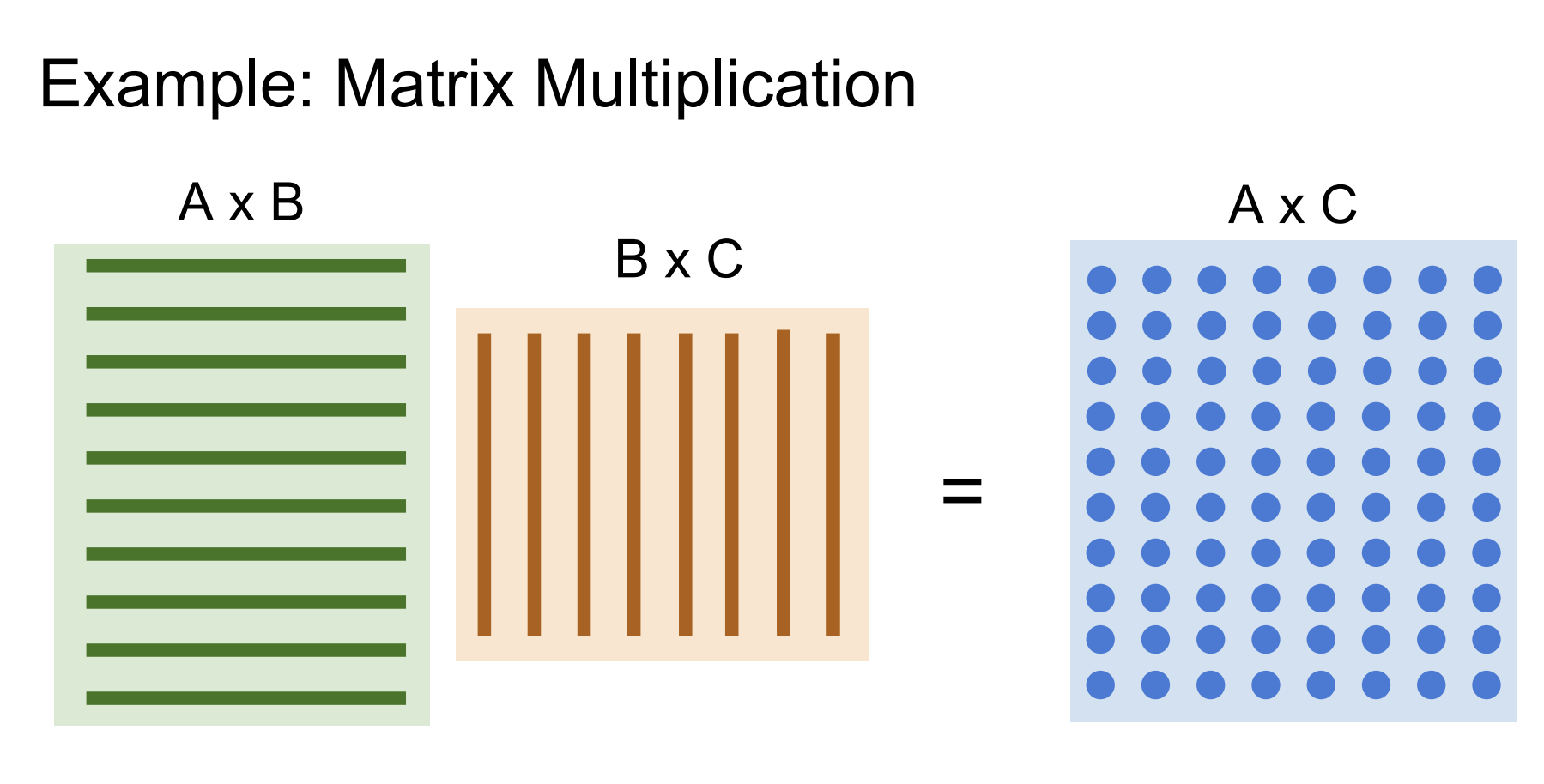
- 행렬의 모든 내적은 독립적이다.
- 병렬적으로 계산이 가능하다.
- 결과적으로, 더 빠른 속도를 가진다.
GPU programming
GPU를 프로그래밍하기 위한 언어도 존재한다.
자세히 알지는 않아도 되지만 뭐가 있는지는 알아보자.
- CUDA(NVIDIA only)
NVIDIA는 딥러닝을 위한 GPU개발을 많이 연구했고, 지금 선두주자이다.
GPU만을 실행하는 c언어 같은 코드를 작성한다.
높은 수준의 API로는 cuBLAS, cuFFT, cuDNN, etc 등이 있다. - OpenCL
CUDA와 비슷하지만 이는 GPU만이 아니라 다른 것도 실행한다.
CUDA보다 느리다.
물리적으로 DATA와 GPU는 분리되어 있다.
실제 모델의 가중치는 GPU 개별 RAM에 저장되어 있고, 훈련 데이터는 컴퓨터 저장장치인 HHD, SSD에 저장되어있다.
따라서 데이터를 읽는 과정에서 병목현상이 일어날 수 있다.
이를 해결할 방법은,
- 데이터 셋이 작은 경우는 일단 모든 데이터를 RAM에 저장해라.
- HHD보다 SSD를 사용하는 것이 데이터를 읽는 속도가 더 빠르다.
- 멀티 CPU 스레딩을 사용해서 미리 데이터를 RAM에 올려놓자. (prefetch)
Deep Learning Frameworks
딥러닝 Frameworks에는
- Tensorflow
- Pytorch
- Caffe / Caffe2
가 있다.
딥러닝 프레임워크를 사용하면 좋은 점은
1. 큰 계산 그래프를 쉽게할 수 있다.
2. 미분이 편하다. 즉 기울기를 쉽게 구한다.
3. GPU 작동을 효과적으로 구현했다.
Numpy vs TensorFlow vs PyTorch

그래프를 계산하는 방법으로 우선 Numpy를 사용해보자.
문제점은
- gpu에서 실행하지 못한다.
- 각자의 gradient를 구해야한다.
그럼 TensorFlow를 사용하는 경우는 어떤가?
- tf.gradients로 backward pass를 한번에 구할 수 있다.
- tf.device로 gpu에서 실행할 지, cpu에서 실행할 지 정할 수 있다.
PyTorch는 어떤가?
- Forward pass 는 numpy와 비슷해 보이지만 c.backward()를 통해서 한번에 gradients를 구할 수 있다.
- 변수를 선언할 때 동시에 .cuda()를 설정해서 GPU에서 실행할 수 있다.
TensorFlow
예시로는 L2 loss와 랜덤 데이터를 기반으로 two-layer의 ReLU를 Train하는 것을 보자.
일단 맨 처음에는
import numpy as np
import tensorflow as tf를 추가해야 한다.

일단 처음은 computational graph를 define 한다.
그리고 여러번 run 하는 구조이다.
처음 2~5번째 줄을 보면 x, y, w1, w2를 위해서 placeholder 들을 사용한 것을 볼 수 있다.

Forward pass 과정에서는 y와 loss를 predict한 것을 알 수 있다.
여기서는 실제 계산이 일어나지 않는다. 그저 그래프를 빌딩한 것 뿐이다.
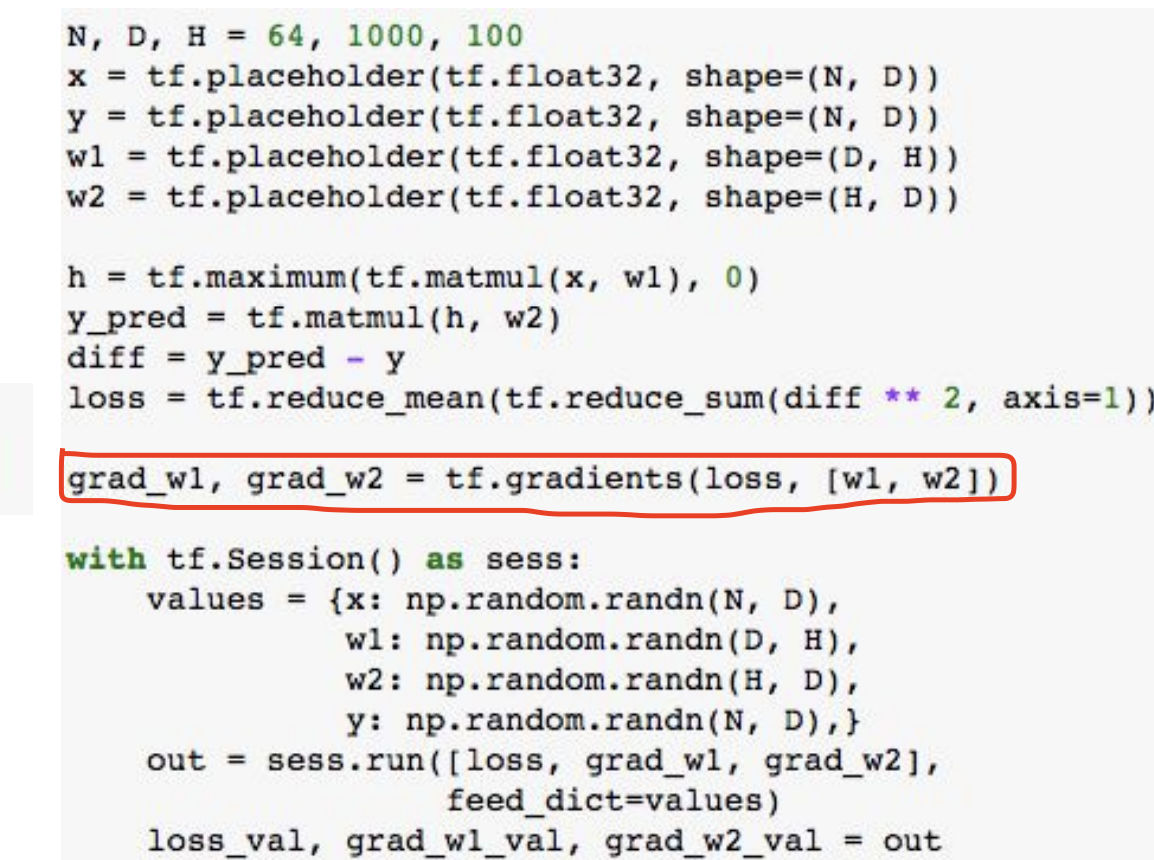
여기서도 마찬가지로 w1, w2에 근저하여 기울기의 loss를 구한다.
이것 또한 실제 계산이 일어나지 않는다.
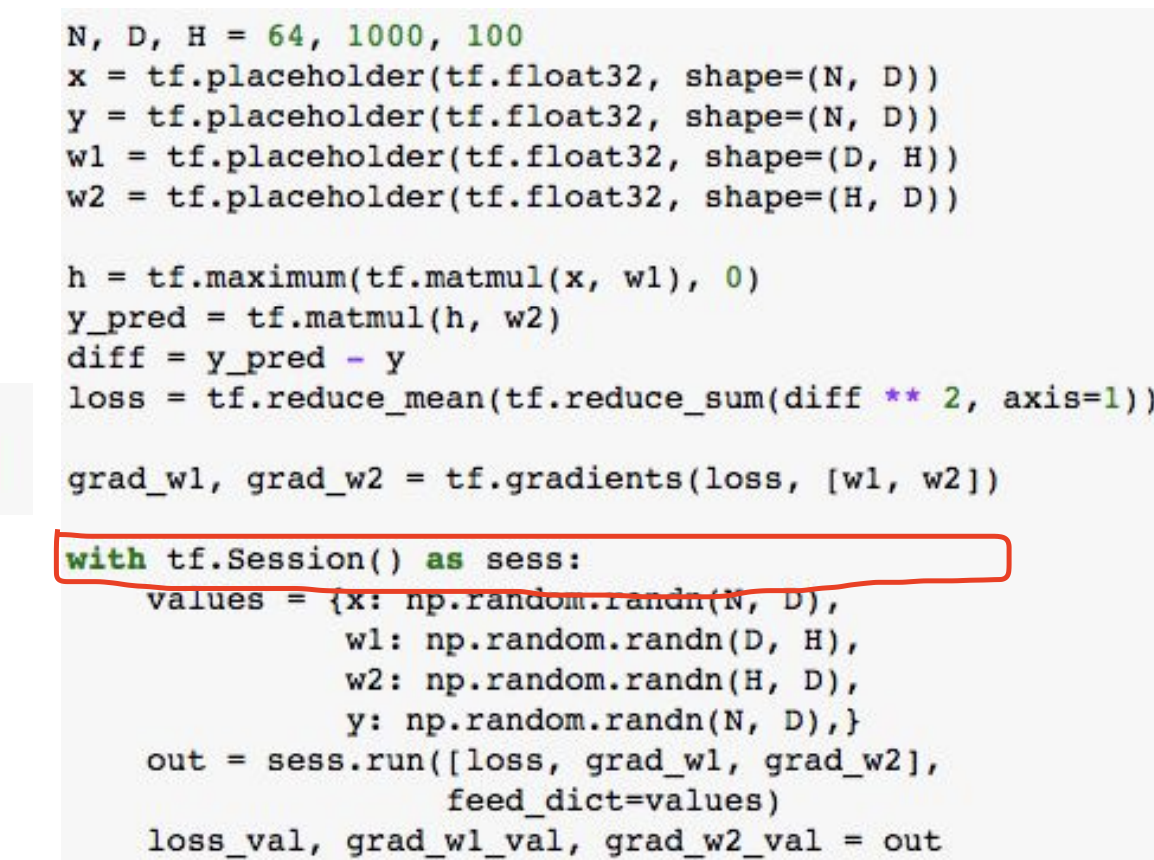
우리의 그래프를 지금까지 그렸고 이제야 session에 들어가서 실제로 그래프를 실행할 것이다.
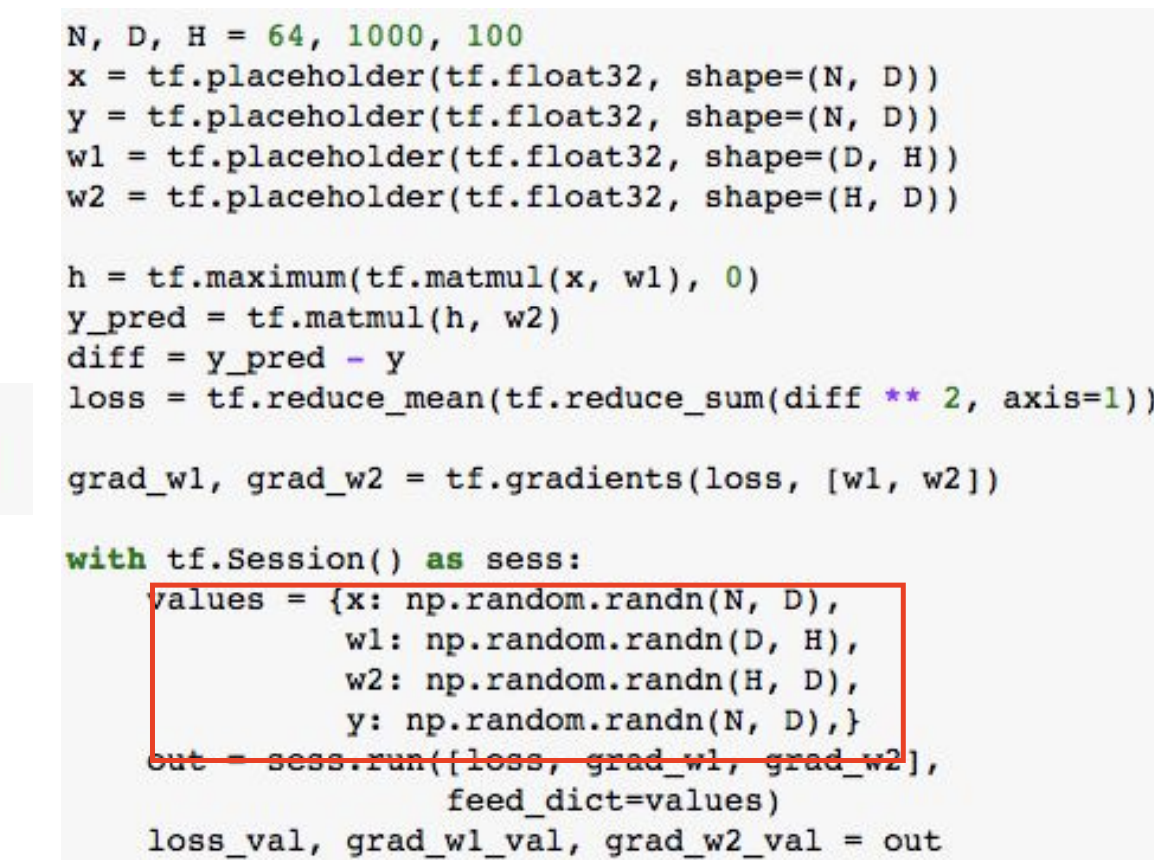
numpy arrays를 만든다. -> values에 저장한다.
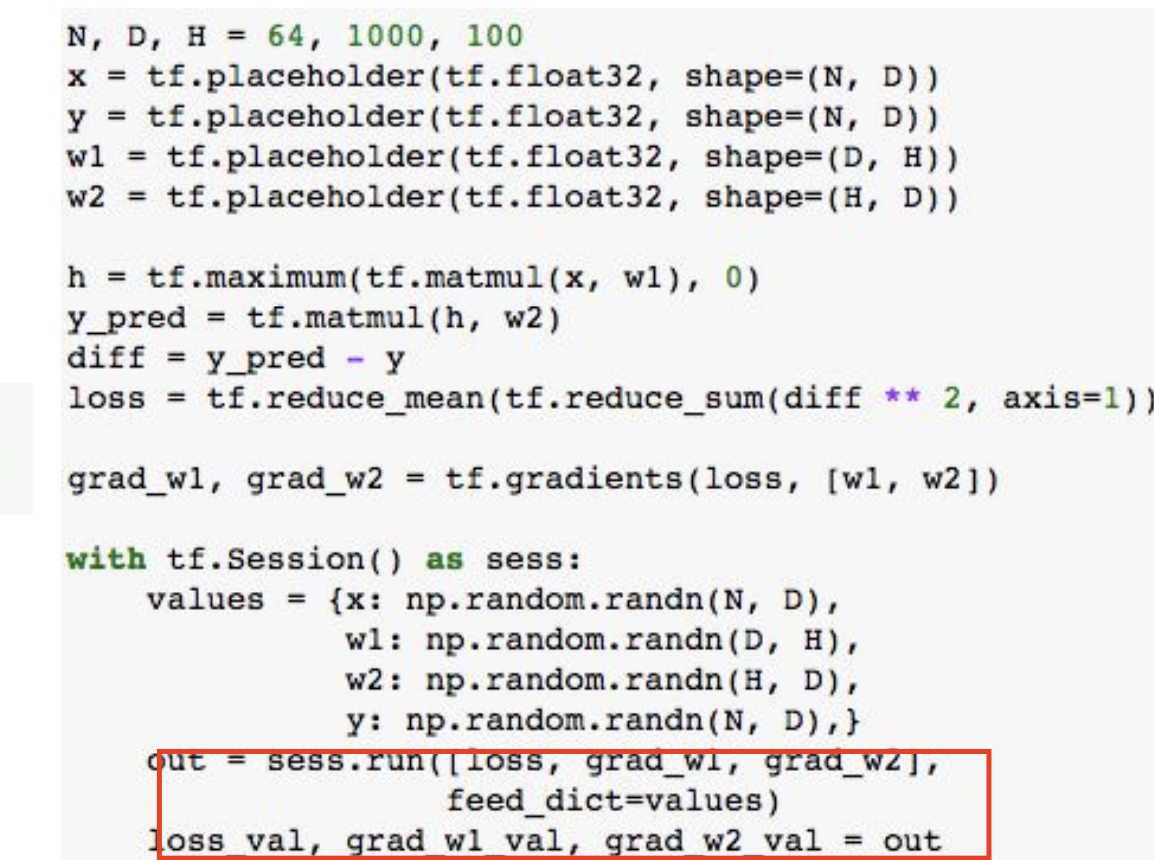
graph를 실행한다.
out에서 계산해서 반환할 값을 지정한다.

graph 연산을 반복해서 gradient를 이용해 weight 업데이트 한다.
왼쪽 그림을 보면 loss값이 점점 줄어드는 것을 보아 weigths가 잘 업데이트 되는 것을 볼 수 있다. 하지만 for문 반복 시 cpu에 저장한 weight 값을 다시 gpu연산에 사용하고 다시 cpu에 출력하기 때문에 계산이 무겁다. weight값은 큰 값이기 때문이다.
그래서 첫번째 방법.
1. w1, w2 를 placeholder가 아닌 Variable로 설정하기 placeholder로 저장하면 cpu에 저장되지만 varialbe로 저장하면 gpu 메모리에 저장된다.

- w1, w2 업데이트 계산을 그래프 계산의 일부로 넣는다.
- 맨 처음 global_varialbes_initializer()로 w1과 w2를 초기화하고 여러번 train을 한다.
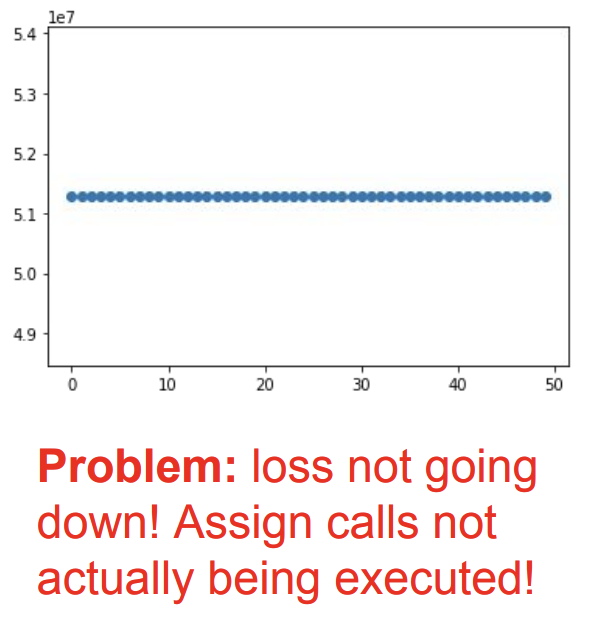
그런데 이렇게 되면 loss가 줄어들지 않았다. 뭐가 문제일까?
두번째 방법인 Assign call이 실행되지 않았다는 것이다. 왜?
왜냐하면 정의만 하고 실제 실행하는 run 부분에서 실행을 안했기 때문이다. 따라서 다시 아래와 같이 수정한다.

근데 여기서도 new_w1, new_w2가 큰 텐서라면 다시 cpu->gpu->cpu 연산이 수행된다고 한다. 그래서 group을 사용해서 dummy node 역할을 수행하도록 한다. 그러니까 new_w1를 실행하고 new_w2도 마찬가지로 실행한다.
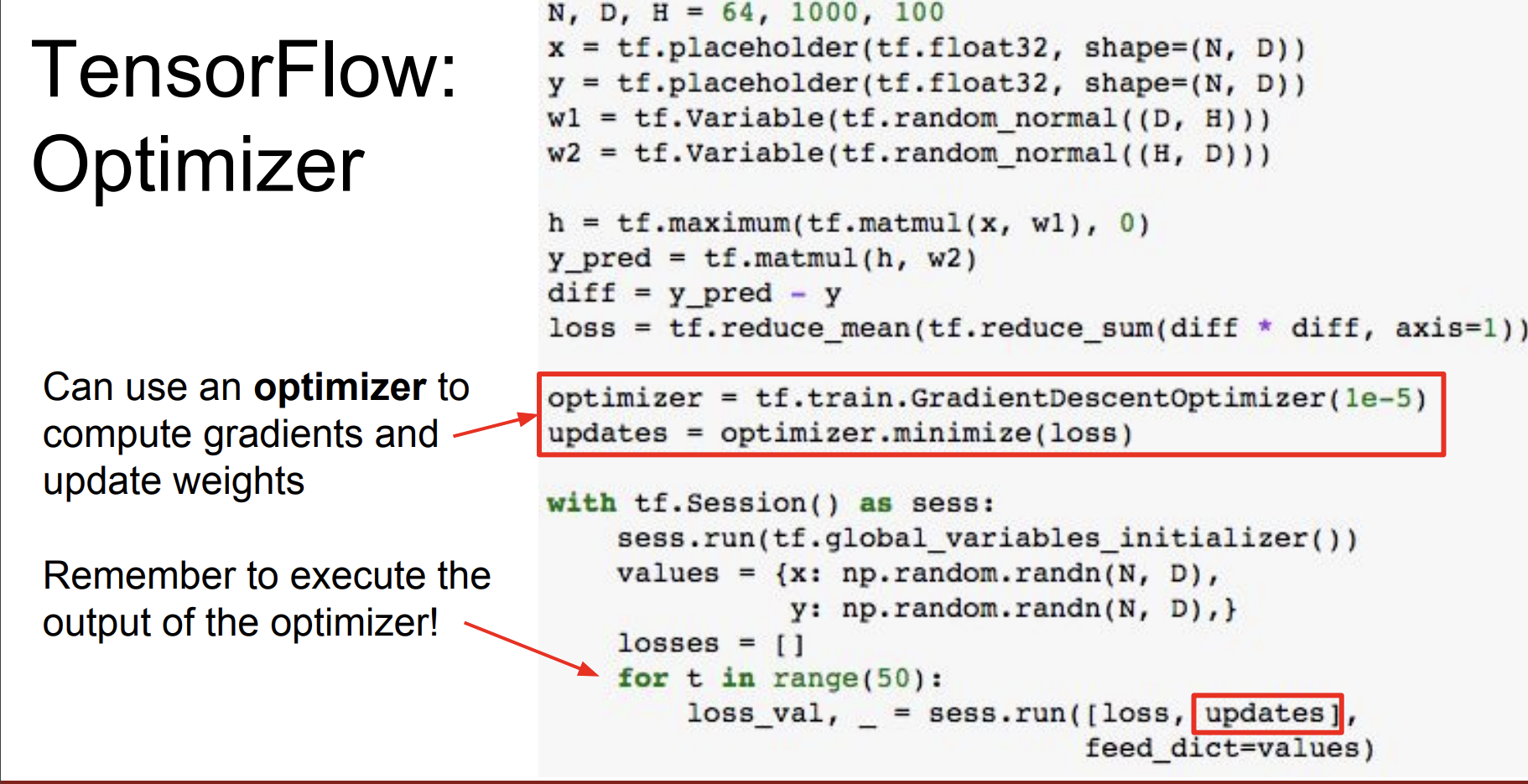
tf.group을 이용하는 것 보다 Optimizer를 이용해서 변수들을 loss값이 최소가 되도록 조절해준다. learning_rate를 정해주면 weight 계산도 알아서 다 해준다고 한다.
Keras라는 High - level Wrapper라는 것도 있다. 여러 일반적인 일들을 쉽게 해준다.
- 모델의 객체를 여러 시퀀스의 레이어로 몇줄이면 구성할 수 있다.
- 또한 optimizer 객체를 정의할 수 있다.
- 모델을 만들고 loss function을 명시하고 모델 훈련하는 코드를 한줄씩이면 구현할 수 있다.
이처럼 많은 wrappers가 tensorflow에 존재한다.

그 다음 Theano에 대해서도 설명하는데 이는 생략하도록 한다. 요즘은 잘 사용을 안하기 때문이다.
PyTorch
Facebook이 개발한 딥러닝 프레임워크로 동적 계산 그래프를 사용해서 모델을 정의하고 학습할 수 있다.
- Tensor : ndarray이지만 GPU에서 실행된다.
- Variable : computational graph에 있는 노드이고 이는 데이터와 기울기를 저장한다.
- Module : 신경망 모델의 layer이고 learnable 한 weight와 state를 저장한다.
파이토치의 텐서들은 numpy array 같지만 GPU에서 동작한다.
여기도 예를 들어서 설명해보자.

여기서는 random tensor들을 데이터와 weight를 위해 만들었다.

forward pass 이다. predictions과 loss를 계산했다.

여기는 backward pass 이다. 기울기를 계산했다.
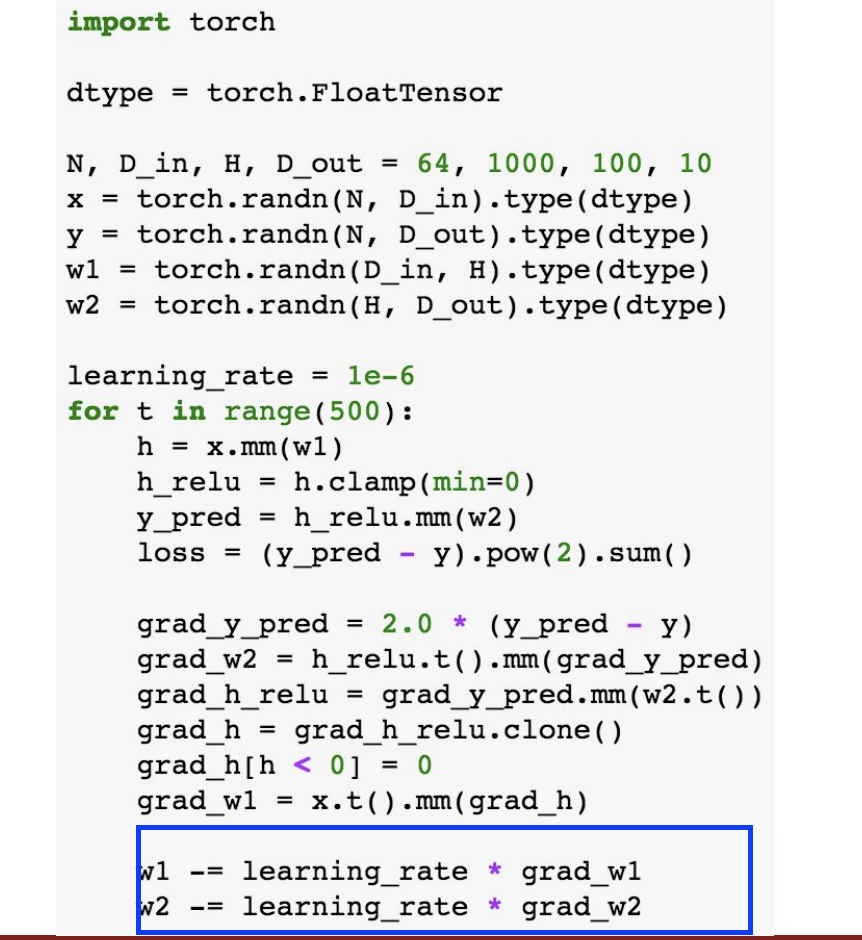
경사하강법에 따라 weight를 조절한다.
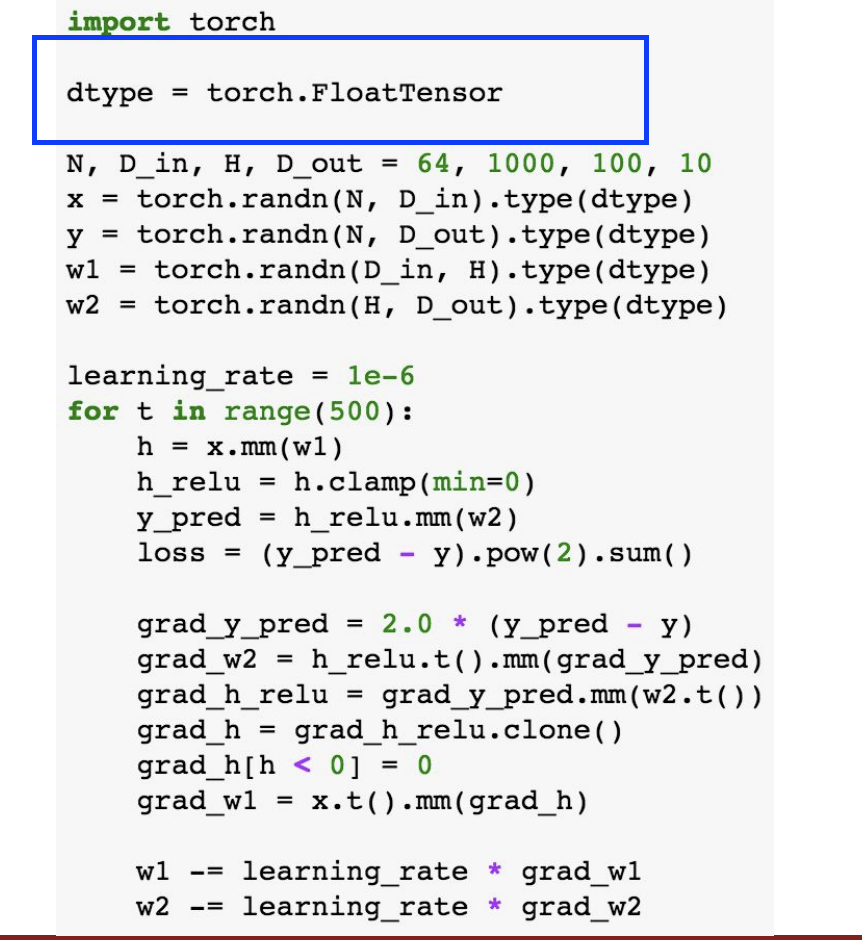
GPU에 실행하기 위해서 cuda datatype을 설정한다.

x.data : 텐서이다.
x.grad : 텐서를 이용해 계산한 변수의 기울기이다.
x.grad.data : 기울기를 담은 텐서이다.
- Variable 과 Tensor는 동일한 API 이고 Tensor를 Varialbe로 바꿔 코드를 실행해도 된다.
- 하지만 Computational graph를 정의할 때는 Variable로 해준다.
- requires_grad : True일 때 해당 데이터에 대해 gradients 구한다는 의미이다. 따라서 핑크색인 경우에 True로 설정했는데, 이 의미는 weight에 대해서 경사하강법을 진행하겠다는 것이다.

첫번째 자주색 부분을 보면, Forward pass 는 Tensor 버전과 똑같아 보인다. 하지만 여기서는 모두 Variable로 설정되어있다.
두번째 주황색 부분은 w1, w2에 대한 손실 기울기를 계산하는 것이다.
마지막 빨간색 부분은 학습률에 따라 새로운 가중치 값을 저장하는 것이다.
Tensorflow에서는 computational graph를 먼저 그린다음, 그래프를 실행하는 단계로 나뉘어져 있다. PyTorch에서는 미리 정의를 하지 않고 forward, backward를 실행할 때마다 새로 그린다.
또한 자동으로 gradient를 계산하는 AutoGrad 함수를 정의할 수 있다. 
PyTorch에는 여러 operations이 있다.
- nn : 신경망에서 작동하는 higher-level 수준의 wrapper이다. 마치 텐서플로우의 Keras 이다.
- optim : PyTorch에도 optimizer가 있다. loss 최적화 함수를 사용하는 것이다. learning rate는 정해주어야 한다.
- nn module :
모듈은 neural net layer이다. 이것의 입력과 결과값은 Variable이다.
모듈은 다른 모듈 또는 weights를 가질 수 있다.
사용자는 자신의 Module을 정의할 수 있다. - DataLoaders : 데이터셋을 쉽게 불러올 수 있다. 미니 배치, 셔플링, 멀티스레딩을 제공한다. 만약 custom data가 필요하다면, 그냥 자신의 데이터셋을 불러오면 된다.
- Pretrained Models :
사전 학습된 모델을 제공한다. torchvision을 사용하면 사전 학습된 모델을 사용하기 쉽다.
https://github.com/pytorch/vision
Aside : Torch
Torch는 PyTorch의 조상격이다.
- Lua 라는 언어로 작성되었다. PyTorch는 아시다시피 Python이다.
- PyTorch는 3개의 abstraction이 있다. :
Tensor, Variable, and Module - Torch는 두가지 이다. : Tensor, Module
결과적으로 PyTorch를 이제 더 많이 사용한다.
Tensorflow vs PyTorch

Static graph의 장점?
Tensorflow 는 static graph로서 computational graph를 정의하고 정의한 그래프를 매 훈련마다 재사용한다.
그에 반해 PyTorch는 Dynamic graph로서 매 훈련마다 새로운 computational graph를 정의해 사용한다.
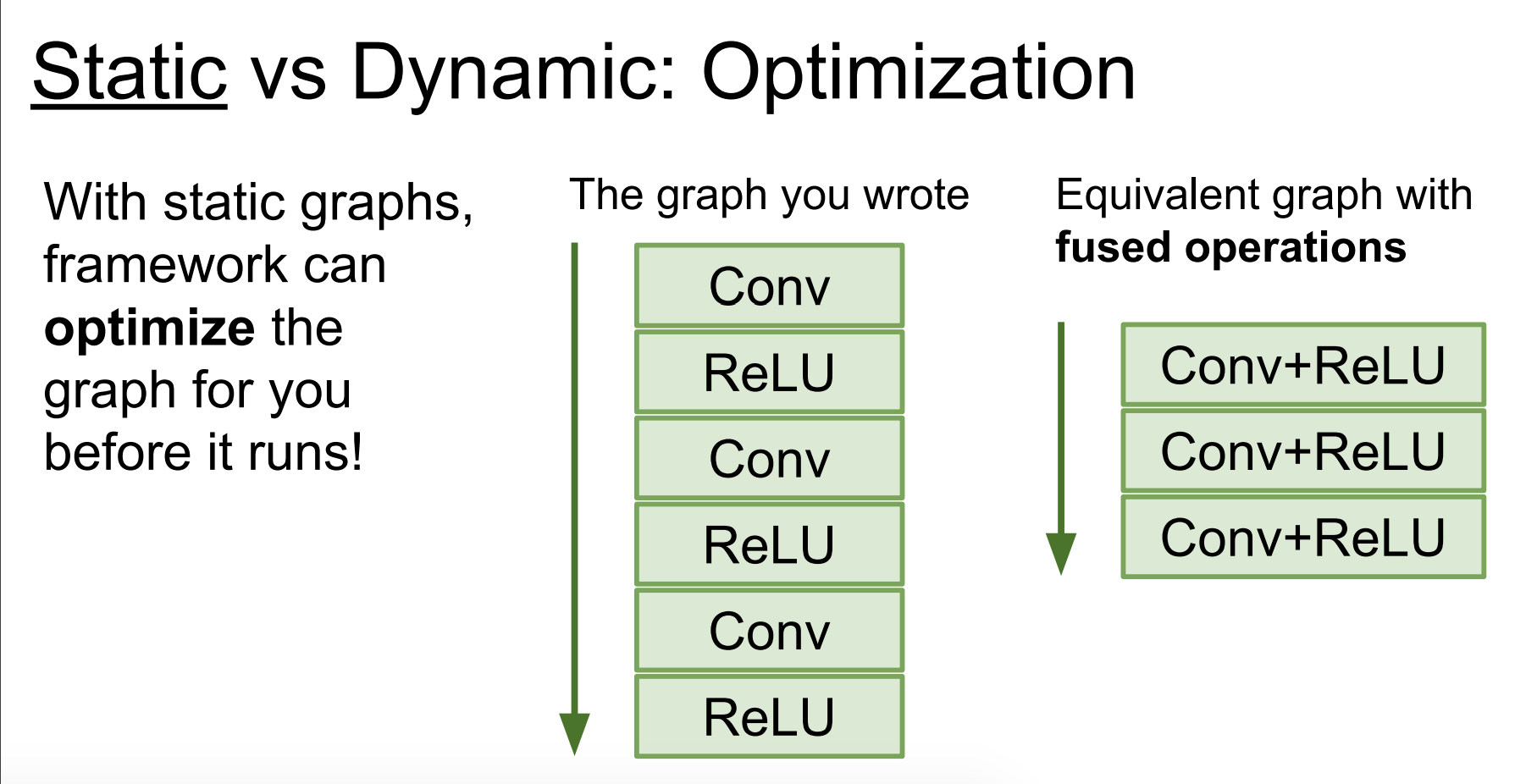
static graph로 프레임워크는 실행전에 그래프를 optimize할 수 있다.
Dynamic graph의 장점?
z 값을 기준으로 y값이 달라질 때, 파이썬 조건문을 사용한다. PyTorch의 경우에는 우리가 아는 파이썬으로 작성하고, 매 iteration 마다 새로운 그래프를 만들기 때문에 경로를 나누어 매번 선택할 수 있고, 역전파처리도 자동적으로 수행할 수 있다.
Tensorflow의 경우에는 graph를 define할 때, 조건 분기 코드를 넣어야한다. tf.cond 와 같은 코드로 작성해야 하고 이는 작성할 때 불편한 점이다.
또한 Dynamic graph의 장점으로 Loops가 있다. 만약 변수가 매번 달라지는 (이전의 값을 사용하는) Loops가 있다고 한다면 PyTorch의 경우 그대로 작성하면 되지만 Tensorflow의 경우에는 foldl이라는 또 다른 문법을 사용해야하는 불편한 점이 있다.
Dynamic Graph Applications
- Recurrent networks
- Recursive networks
- Modular Networks
등이 있다.
대부분의 경우 매번 입력이 달라지거나, loops를 사용하는 경우이다.
정리
Google의 경우에는 Tensorflow 로 하나의 프레임워크를 사용해서 모든 것을 진행하려 한다.
Facebook 같은 경우에는 PyTorch는 연구용, Caffe2의 경우에는 생산용으로 사용한다고 한다.
Justin 교수님께서는
텐서플로우는 대부분의 프로젝트에서 안전하다. 하지만 크고 넓은 사용성에 대해서는 완벽하지 않다. high-level wrapper를 사용해야 할 것이다.
파이토치는 연구에 최적이다.
만약 하나의 그래프를 여러 머신에 대해 적용시키려면 텐서플로우를 사용해라.
Caffe, Caffe2, TensorFlow 는 production deployment로 사용하고 TensorFlow, Caffe2는 모바일에도 사용한다.
이렇게 설명하고 끝내셨다 :)
코드를 입력하세요
```---
끝!