[231N] Lecture 5, 6 review
Lecture 5
5강에서는 Convolutional Neural Networks에 대해 배운다.
나는 일단 컴퓨터비전 기초를 대학교 수업에서 배웠어서 복습하는 기분이었다.
근데 스탠포드 박사과정 조교님이 강의를 잘하셨다. (약간 학생들 질문에 답변은 애매하긴 하지만...) 그래서 다시 잘 배우는 기분이라 좋았다.
일단 과제1 을 7강 전까지 내라는데 낼 수 있겠지??
아무튼 이전 4강에서 우리는 Neural Networks애 대해 배웠다.
그리고 neural networks의 history에 대해서 배우는데, 이는 스킵한다.
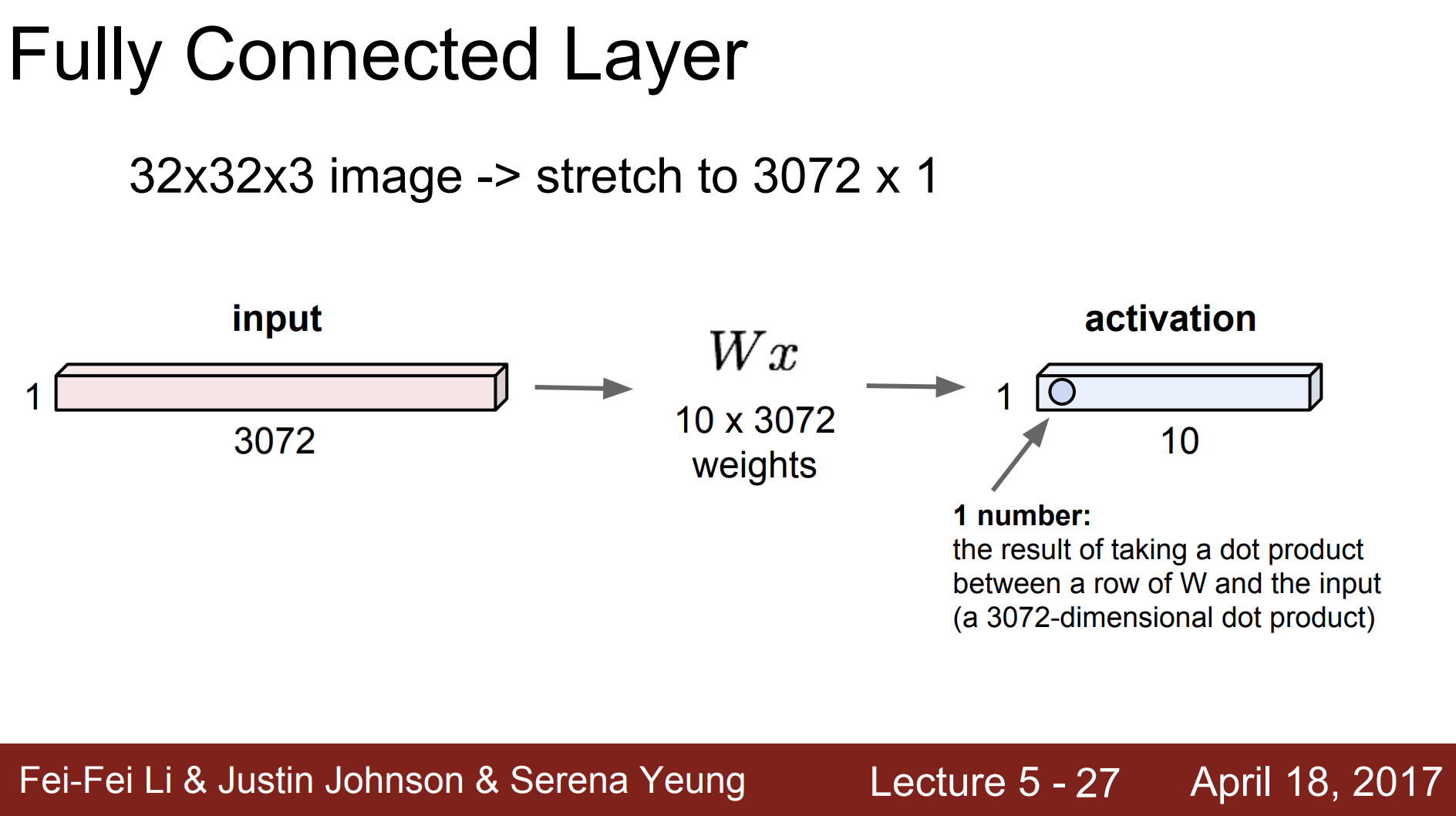
Fully Connected Layer
32 x 32 x 3 이미지가 있다면 이를 3072 x 1로 쭉 늘린다.
그리고 W를 곱한 다음에 활성화 결과 1 x 10을 만든다.
정확히는
10 x 3072 (W) X 3072 x 1 (x) = 10 x 1 (activation)이 된다.
그리고 activation 중 하나의 숫자는 W와 인풋의 내적 곱을 통한 결과를 의미한다.
Convolution Layer
컨볼루션 레이어에서는 공간 구조를 보존한다.
즉 아까처럼 3072 x 1 로 늘리는 것이 아니라 32 x 32 x 3 이미지 그대로 진행하고, 필터는 5 x 5 x 3 크기가 된다.
필터는 공간적으로 이미지위를 슬라이드하며 내적한다.
필터는 항상 인풋 volume의 깊이를 확장한다.
내적한 결과를 activation map이라 한다.
하나의 필터가 아닌 두번째 필터도 동일하게 진행한다.
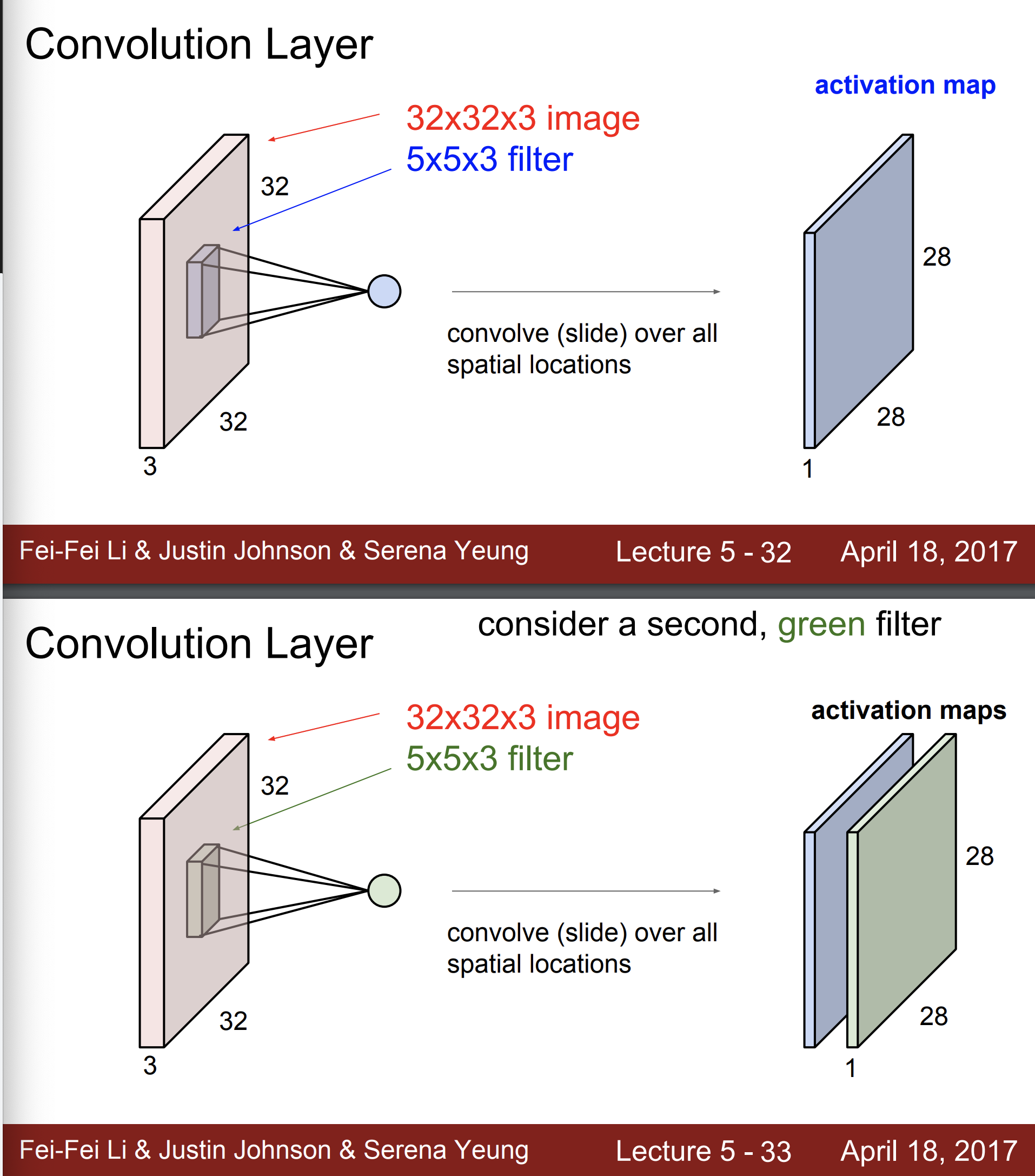
만약 32 x 32 x 3 input image가 있고 5x5 필터가 6개 있다면, 최종적으로 28 x 28 x 6을 얻게 된다.
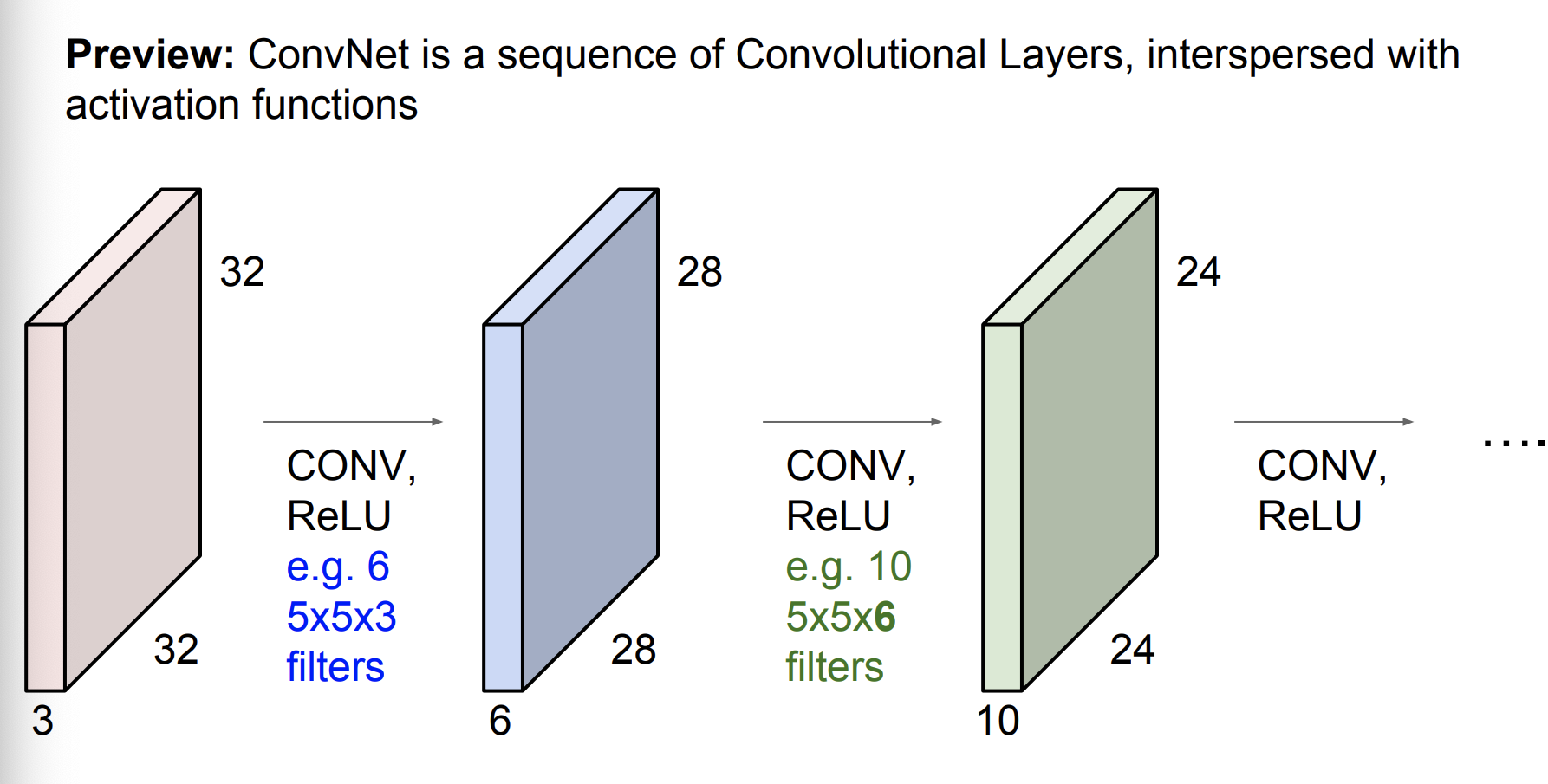
ConvNet은 컨볼루셔널 레이어들의 연속이다. 활성화 함수들을 통한 결과가 다시 인풋으로 들어가고 ~ 이를 반복한다.
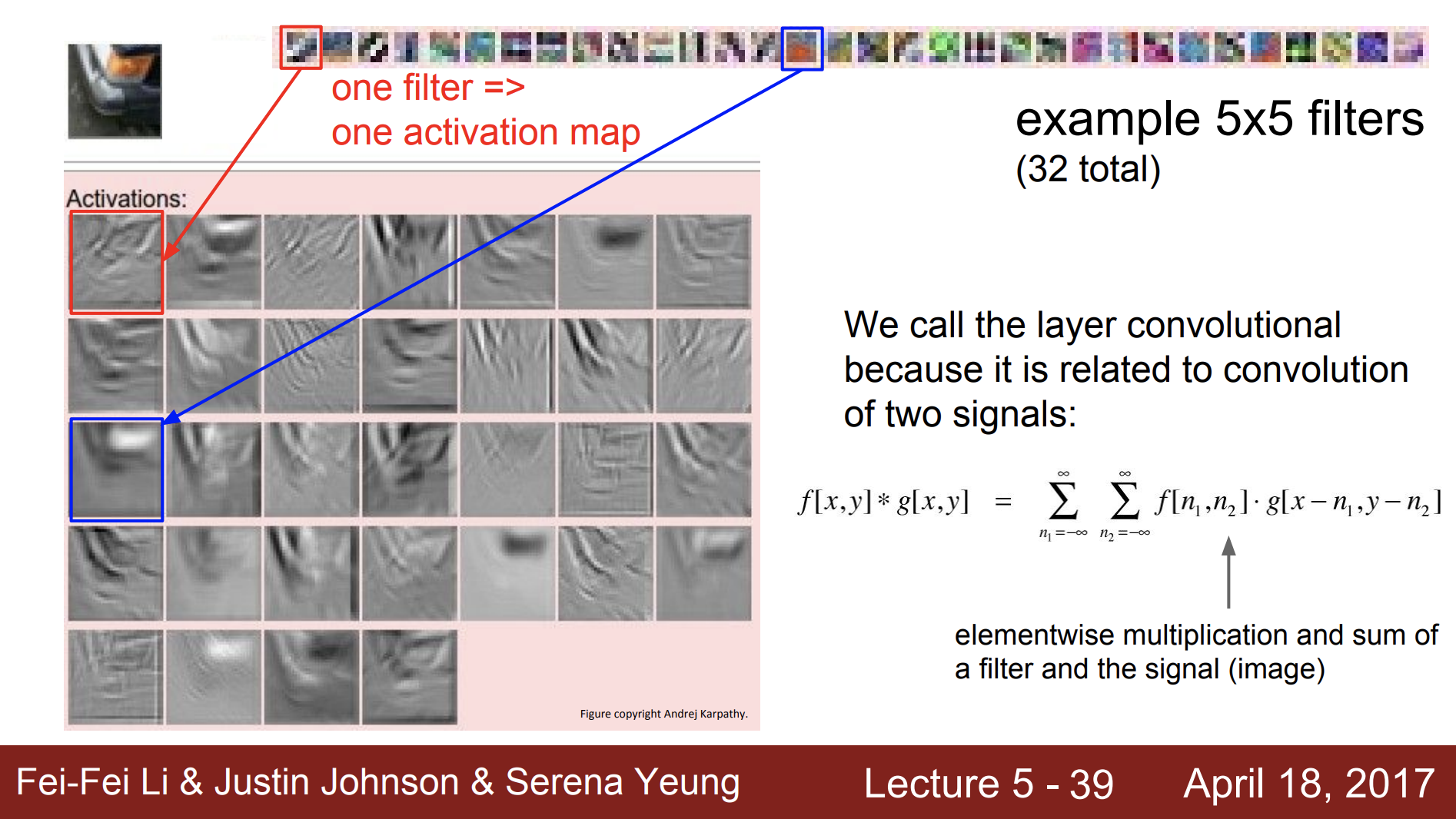
이 예시는 하나의 필터를 통해 하나의 activation map을 얻은것을 알 수 있고, 총 32개의 필터로 32개의 activation map을 얻은 것을 확인할 수 있다.
각각의 activation map을 더하는 식을 확인할 수 있다.
나아가 자동차 이미지에 대해서도 CONV -> RELU -> CONV -> RELU -> POOL -> CONV -> RELU -> CONV -> RELU -> POOL 를 진행해서 최종 점수를 얻는다.
그러면 32 x 32 x 3 이 어떻게 28 크기가 되는가?
예시로 7x7을 들어 설명한다.
만약 3x3 필터가 있고, stride(보폭)은 1이라 가정하면
5칸을 오른쪽으로 움직일 수 있다.
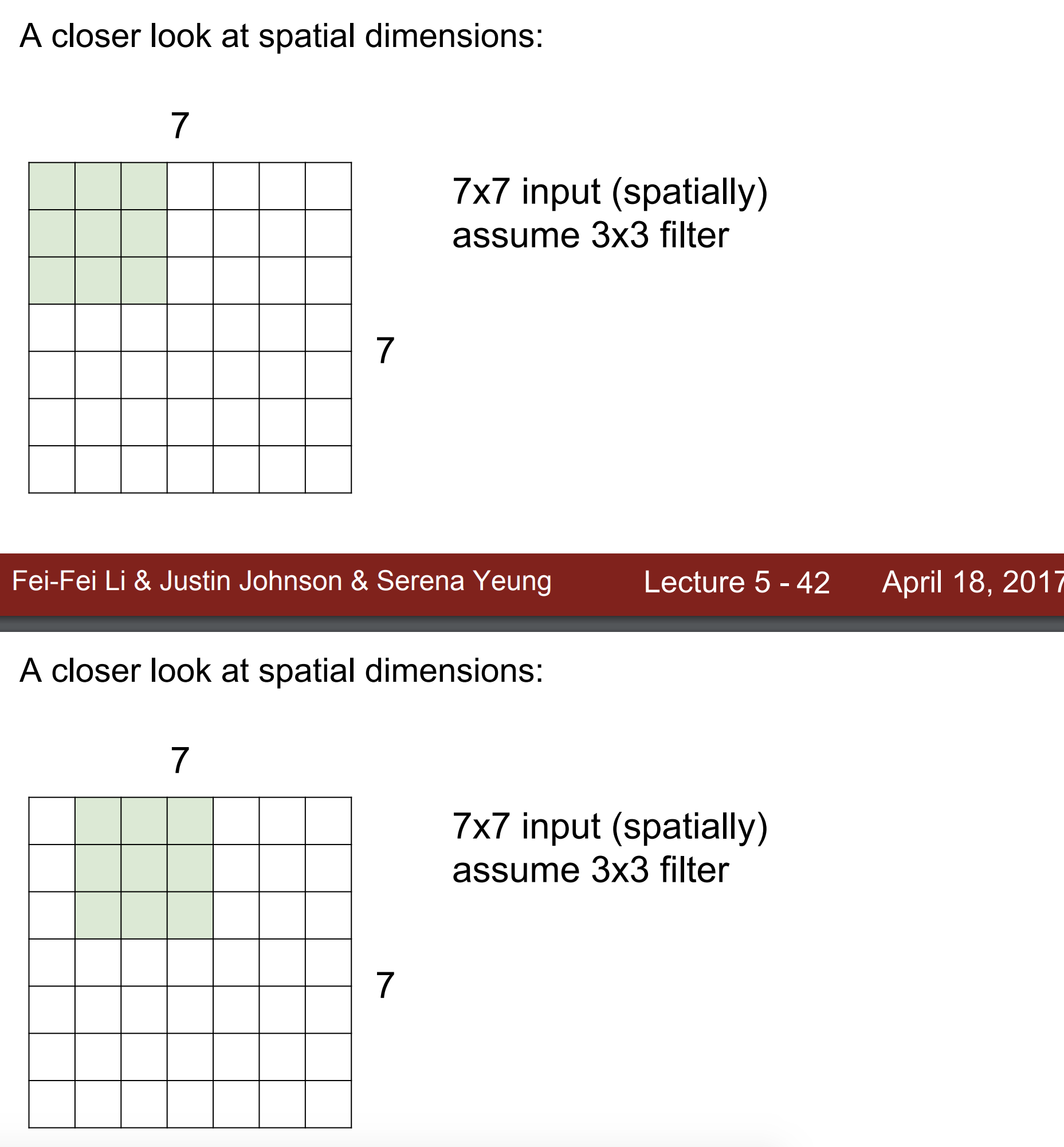
그래서 output은 5x5가 된다.
Stride
만약 stride 를 2로 설정하면?
3x3 output이 만들어진다.
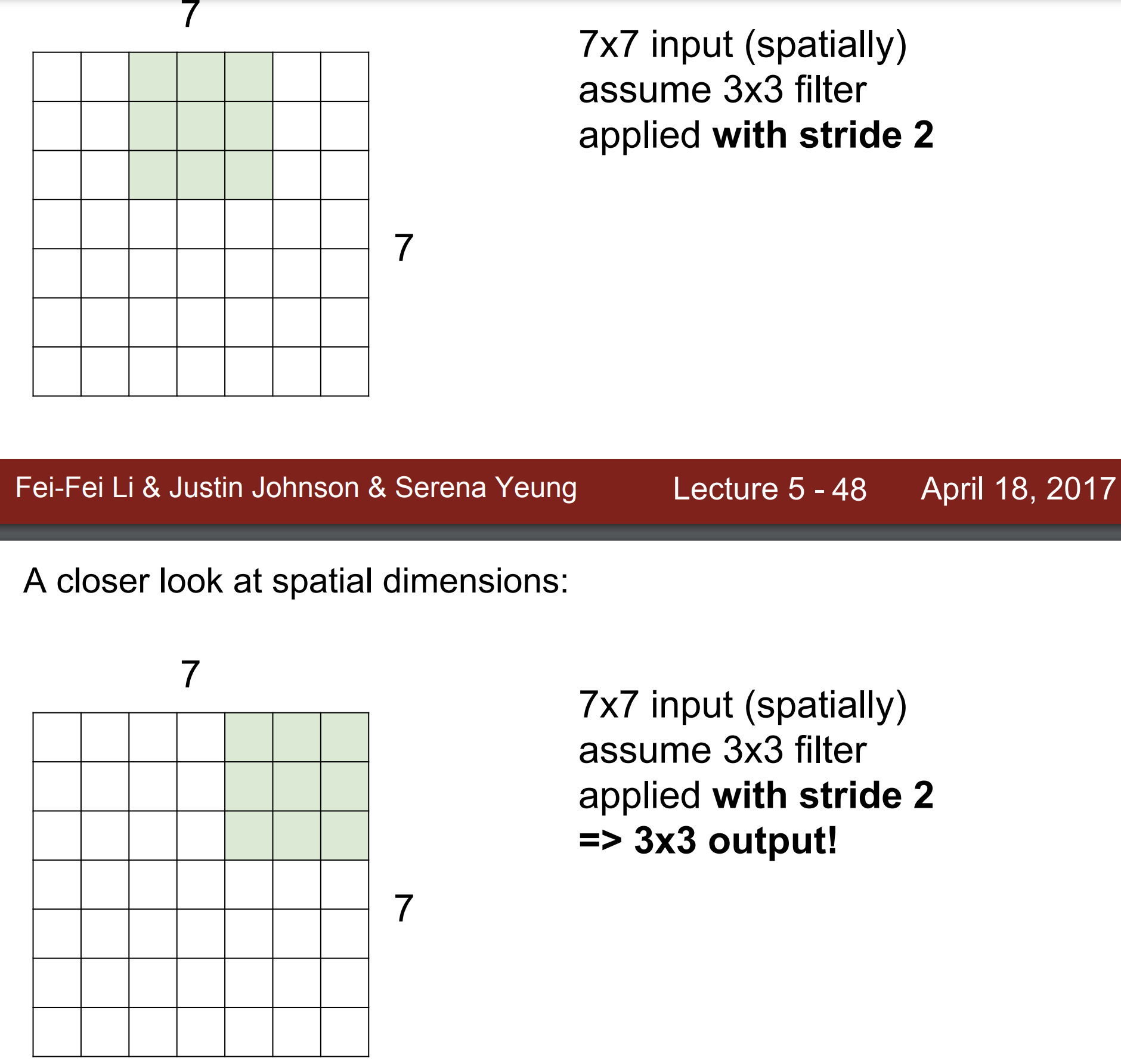
만약 stride 를 3으로 설정하면?
-> 설정할 수 없다!
그럼 우리는 공식을 유추할 수 있다.
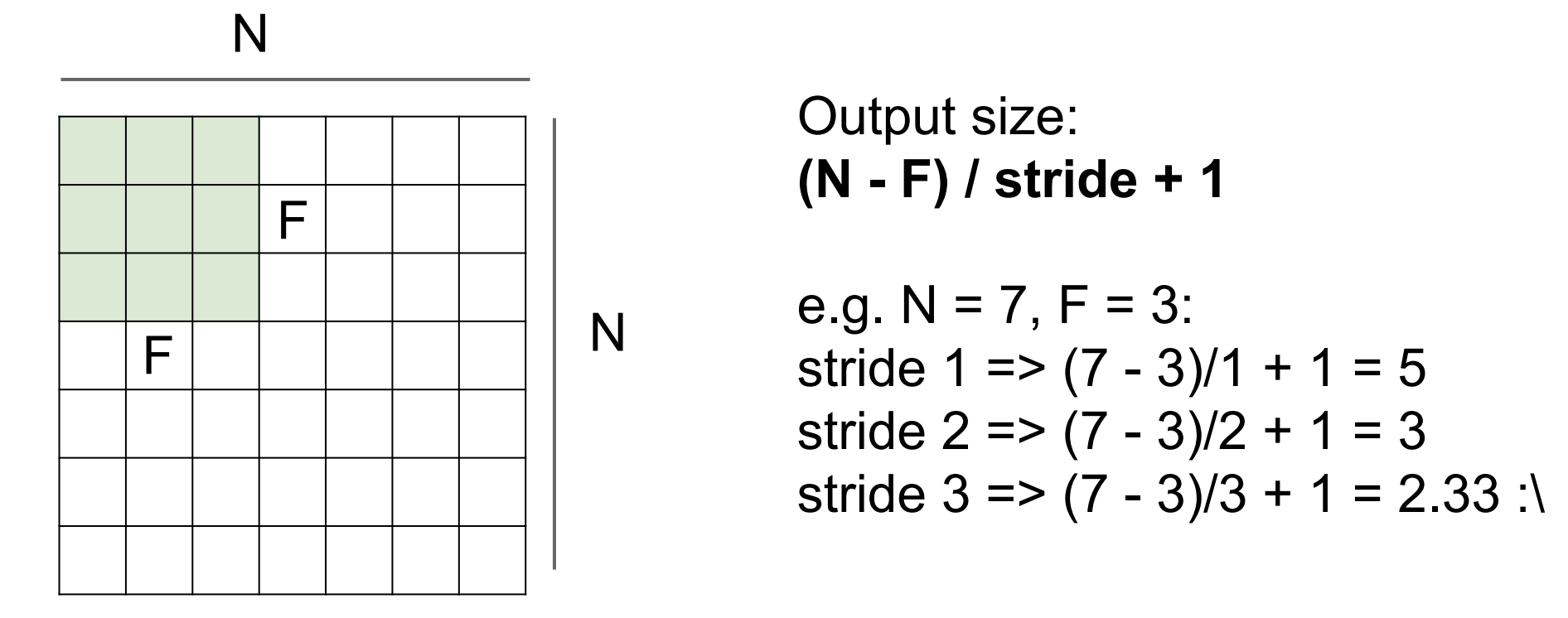
아니 근데 Output이 계속 작아지는데, 이를 어떻게 방지할 것인가?
Zero pad
우리는 zero pad를 통해 방지할 수 있다.
만약 zero pad가 1이고, 7x7 input, 3x3 필터에 stride가 1이라면?
7x7 아웃풋이 만들어진다.
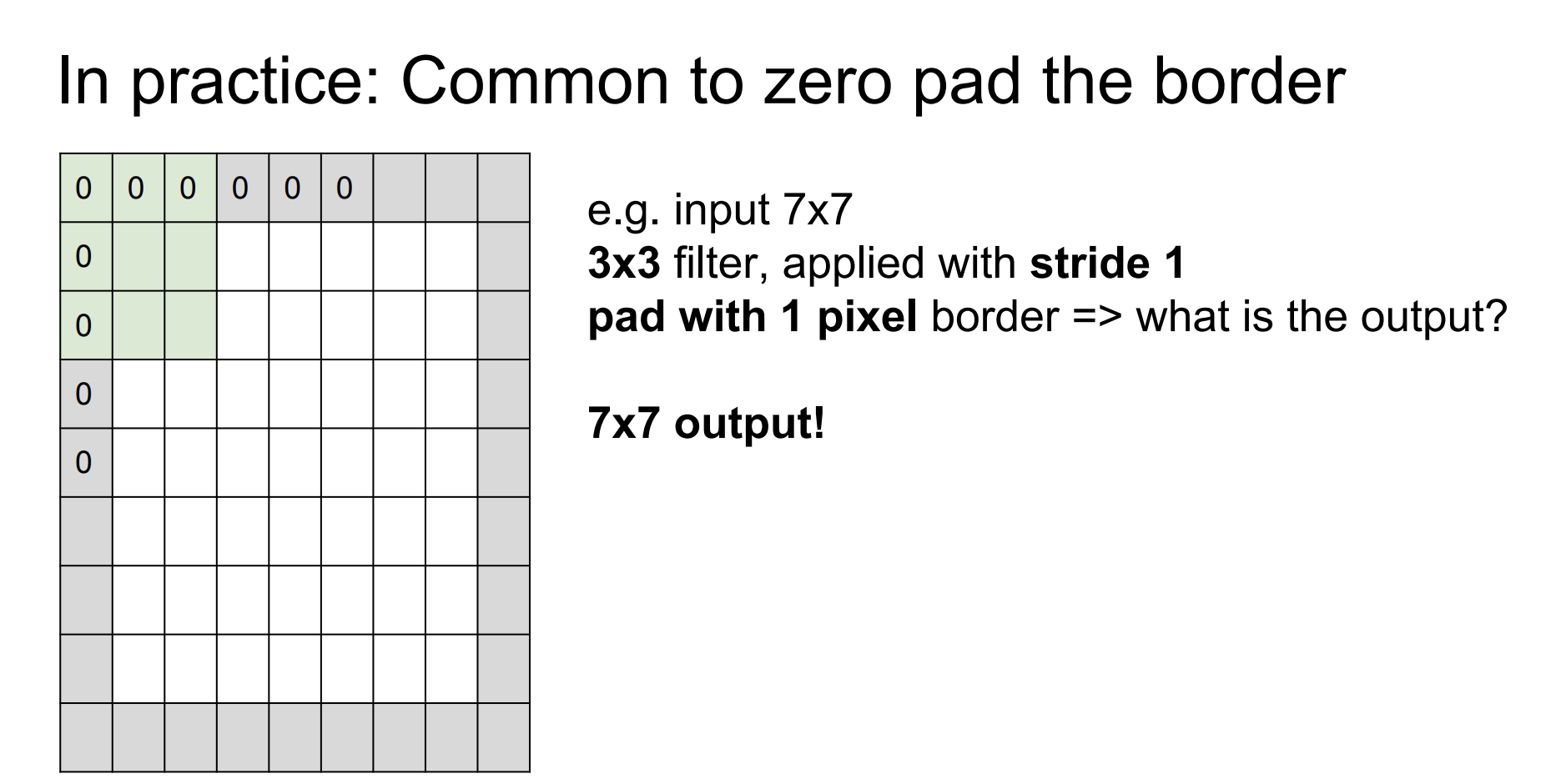
보통의 zero pad는 필터 사이즈가 F일 때, (F-1)/2 로 설정한다.
만약 zero pad를 하지 않게 된다면, output의 크기가 급진적으로 줄어들고, 이는 우리가 필요한 정보가 급격하게 감소함을 의미한다.
또 다른 예시를 들어보자.
Examples
input volume : 32 x 32 x 3
10 개의 5x5 filters
stride : 1
pad : 2
output volume size:?
(32+4-5) / 1 + 1 = 32
32 x 32 x 10
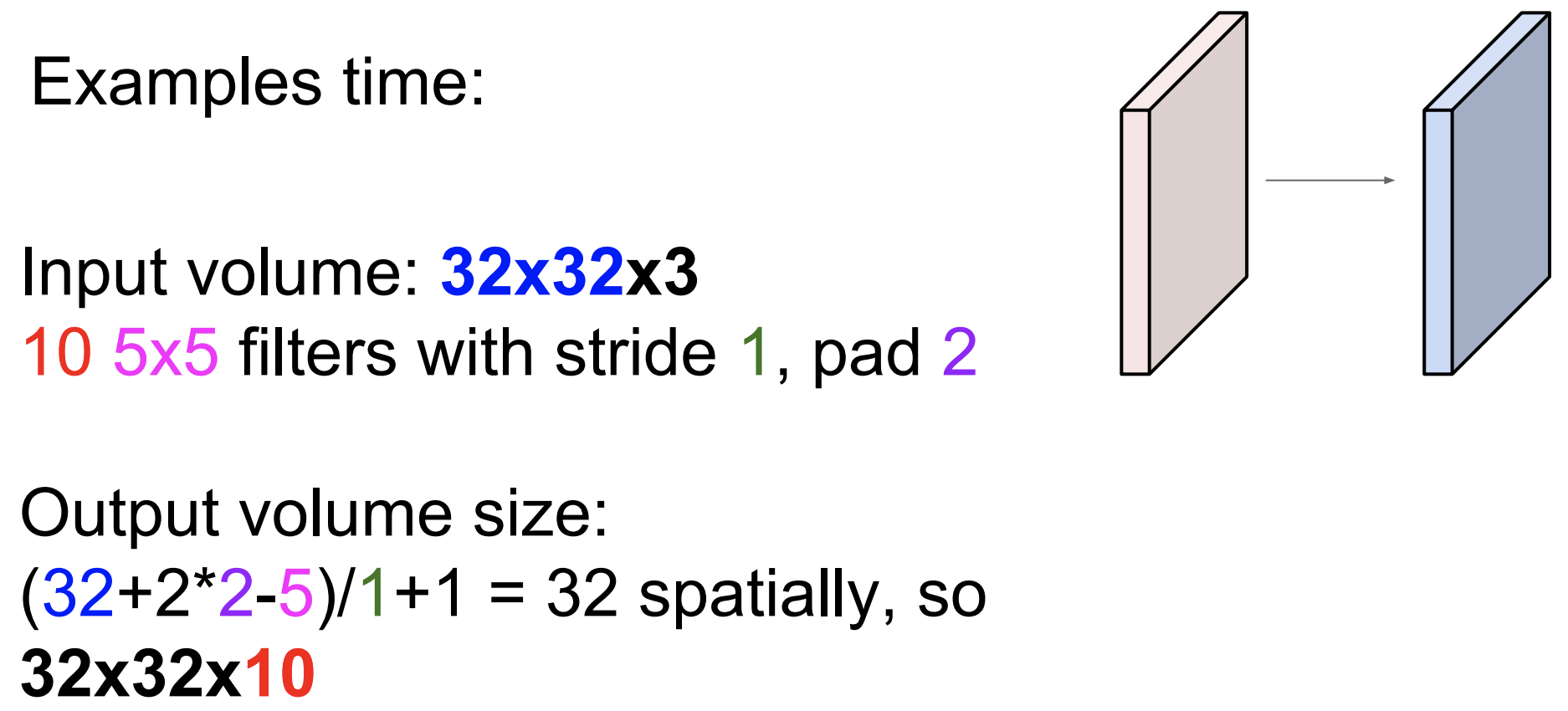
이렇게 구할 수 있다!
또 다른 예시
input volume : 32 x 32 x 3
10개의 5x5 filters
stride : 1
pad : 2
이 레이어의 파라미터의 개수는?
일단 한 필터의 크기는 5x5x3 이다.
그리고 필터 하나당 우리는 편향이 하나 존재한다.
그렇다면 각각의 필터의 파라미터의 개수는 5x5x3 + 1 = 76 이다.
그리고 필터의 개수는 10이므로 총
76 x 10 = 760이다
Conv Layer에서 흔히 파라미터를 이렇게 설정한다.

그리고 1x1 필터 또한 존재한다.
이러한 예시들은 직접 Torch와 Caffe 에서 직접할 수 있다.
Brain view of Conv Layer
그렇다면 뇌의 관점에서 Conv Layer에 대해 알아보면, 각각의 활성맵은 neuron outputs이라고 생각할 수 있다.
- 각각은 입력의 작은 지역에 연결된다.
- 그들 모두는 파라미터를 공유한다.
5x5 filter를 5x5 각각의 receptive field 라고 생각하면 된다.
그럼, 5개의 필터가 있을 때는? 3d grid를 배열해서 5개의 각각 다른 neurons이 같은 input volume에서 나온 것이라 생각하면 된다.
Pooling Layer
풀링 레이어는 뭘까?
이는 표현을 좀 더 작고 관리하기 쉽게 만드는 것이다.
이는 활성화 맵에서 독립적으로 작동한다.
즉 크기를 다운그레이드 시킨다.

가장 많이 사용하는 풀링은 Max pooling 이다.
각 구역에서 가장 큰 수를 선택하는 것이다.
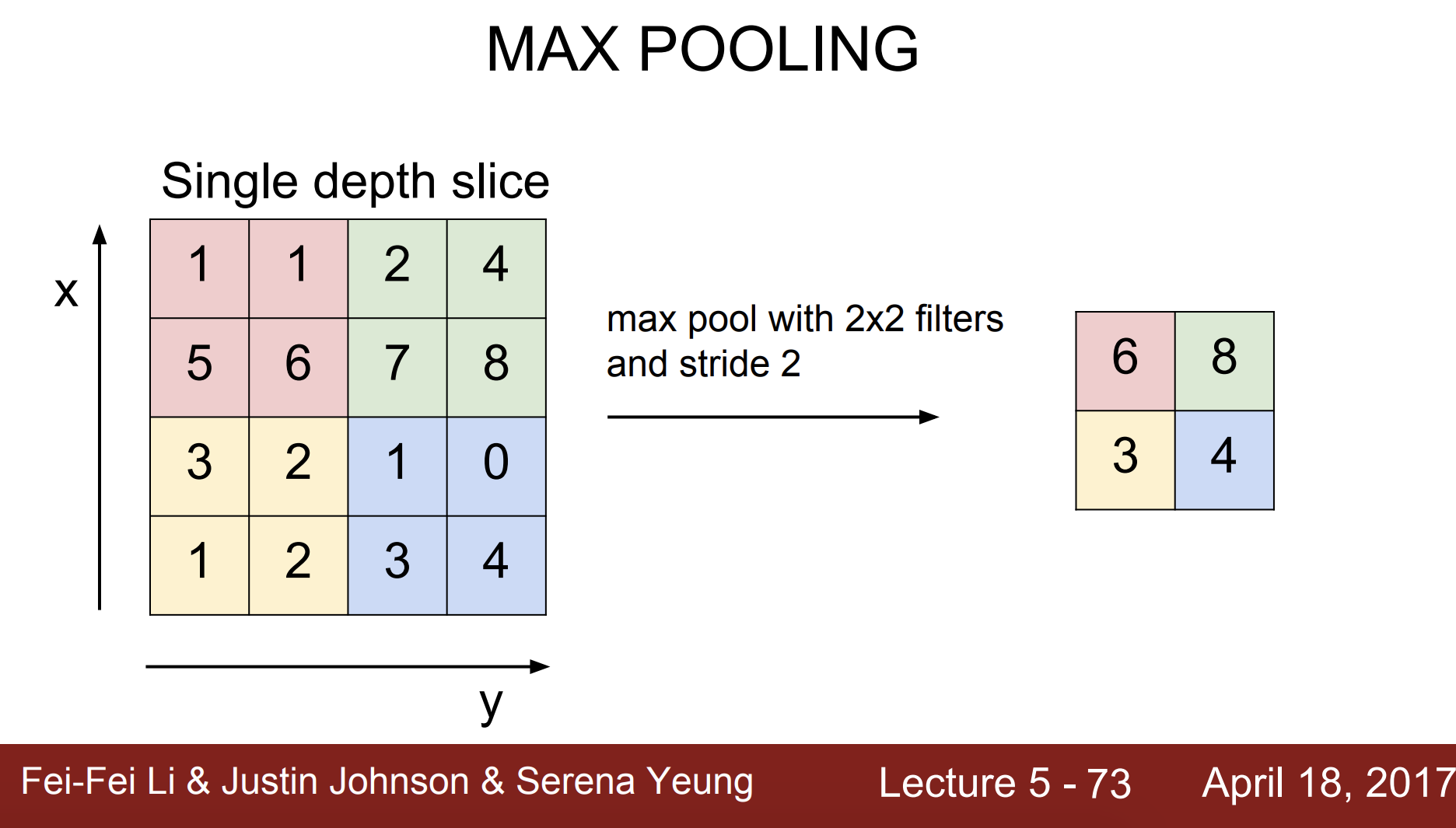
가장 흔한 세팅은
Zero pad : 2, Strid :2 라고 한다.

사실 다운그레이드 방식으로는 이제 stride 크기를 키우는 방법도 있다.
이는 요즘 논문에서도 많이 쓰인다고 한다. 하지만 결정적으로 다운그레이드가 뭐가 더 좋은지는 각자 알아봐야 한다고 한다.
전형적인 아키텍쳐의 모양은
[(CONV-RELU)*N-POOL?]M-(FC-RELU)K,SOFTMAX
where N is usually up to ~5, M is large, 0 <= K <= 2.
여기서 pool의 개수는 ? 인데, 이것도 뭐 정해진 것이 없다. 다운그레이드를 많이 하면 많이할 수록 당연히 정보의 크기도 줄어들어서 너무 정확도가 낮아질 수 있다.
Lecture 6
이게 Training Neural Networks 을 배운다.
이번 강의는 중요한 내용들만 다루고 분량이 많다!
2강에 나누어서 신경망을 훈련하는 방법에 대해 배워보자.
이번 6강에서는
- Activation Functions
- Data Preprocessing
- Weight Initialization
- Batch Normalization
- Babysitting the Learning Process
- Hyperparameter Optimization
을 배우게 된다.
Activation Functions
활성화 함수에 대해 배워보자.
활성화함수는 Neural networks에서 각 뉴런의 출력을 결정하는 역할을 한다.
뉴런의 입력을 받아서 비선형한 형태로 변환하고 다음 레이어의 뉴런에 전달한다. 신경망이 복잡한 함수를 근사하고 비선형성을 표현하는데 중요하다.
우리는 여러가지 활성화 함수들을 가지고 있다.

첫번째는 시그모이드 함수이다.
Sigmoid
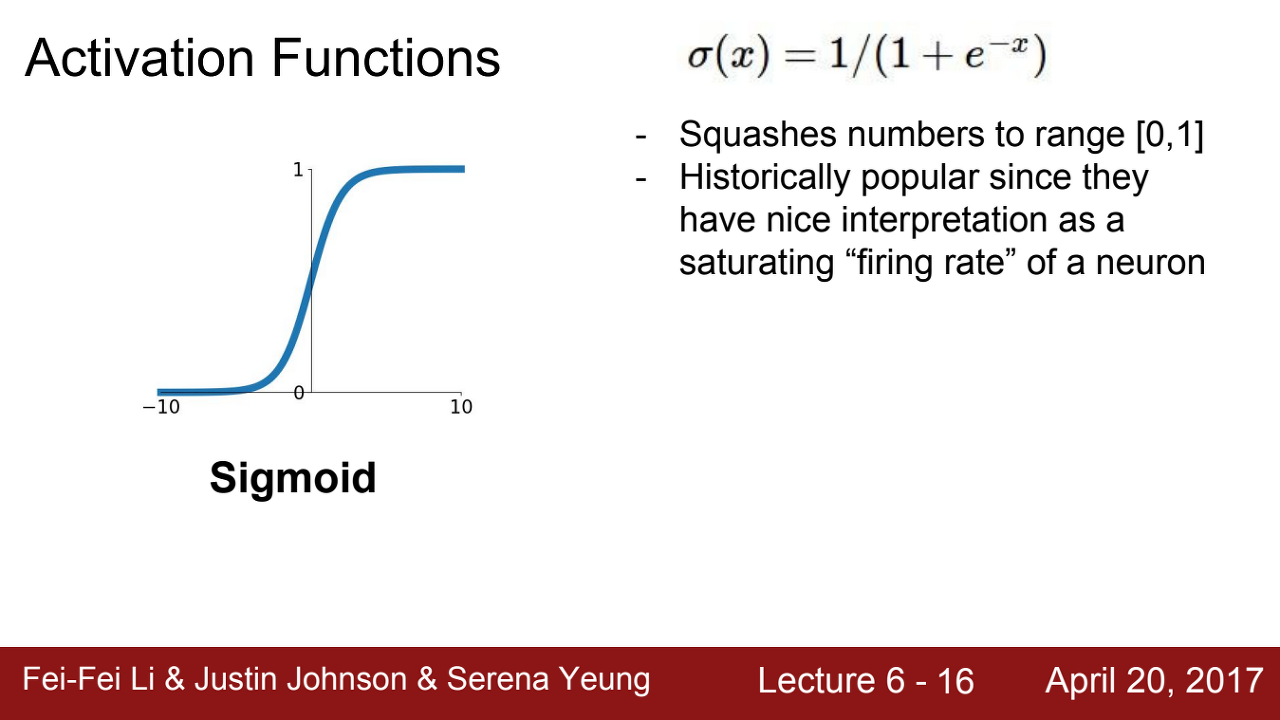
- 이 함수는 [0,1] 로 값을 Squash한다.
- 3가지 문제가 있다.
첫 번째 문제는 포화된 뉴런이 기울기를 '죽일'수 있다는 것이다.
기울기를 죽인다는 것은 무슨 말일까?

- x = =10 이면 기울기는?
- 거의 0이다. - x = 0 이면 기울기는?
- 적합한 기울기를 가지고 있다. - x = 10 이면 기울기는?
- 거의 0이다.
값이 매우 크거나 작으면 보면 알 수 있다 시피 경사 흐름이 거의 종료되었다. 즉 경사흐름이 '죽음'을 알 수 있다.
두번째 문제는 시그모이드의 결과가 zero-center가 아니라는 점이다.
zero-center가 왜 중요할까?
만약 항상 입력이 양수이면 어떤 문제가 발생할까?

만약 optimal 한 기울기가 파란 기울기라고 하자.
우리는 양수의 기울기 값을 가질 수 밖에 없기에 일련의 비 효율적인 단계 (지그재그)를 거쳐야 최적의 벡터 w를 구할 수 있다. 하지만 음수의 기울기 값을 가졌다면 바로 최적화된 벡터를 구할 수 있다.
즉 평균 0 의 데이터를 가져야 골고루 양수 음수의 데이터 값을 가질 수 있다는 의미이다.
마지막 3번째 문제점은 무엇일까?
exp 계산이 꽤나 expensive 하다는 점이다.
그래서 우리는 위 문제점을 조금 수정한 tanh 함수로 넘어간다.
tanh
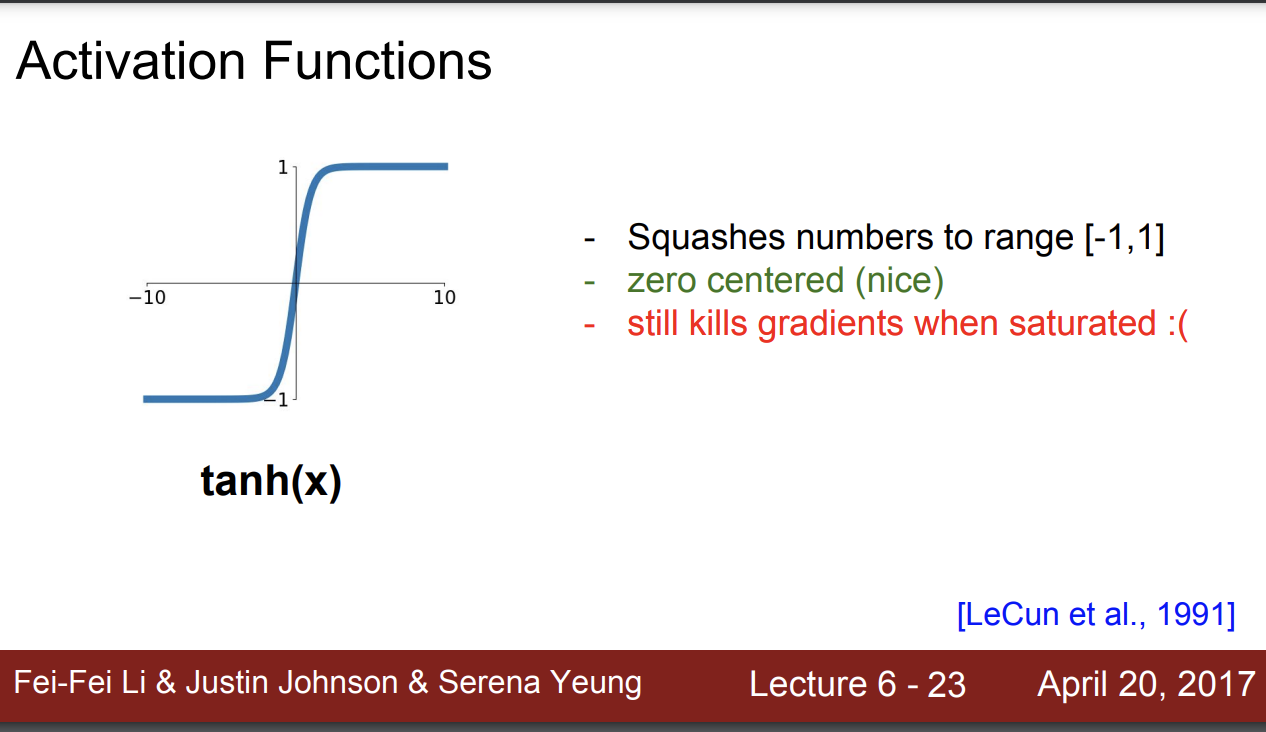
tanh 함수는 [-1,1] 범위로 output이 출력된다.
이제 0 center가 되었다.
하지만 너무 값이 음수이거나 양수인 경우는 경사 흐름이 여전히 kill 된다.
그럼 다음 함수인 ReLU로 넘어가자.
ReLU
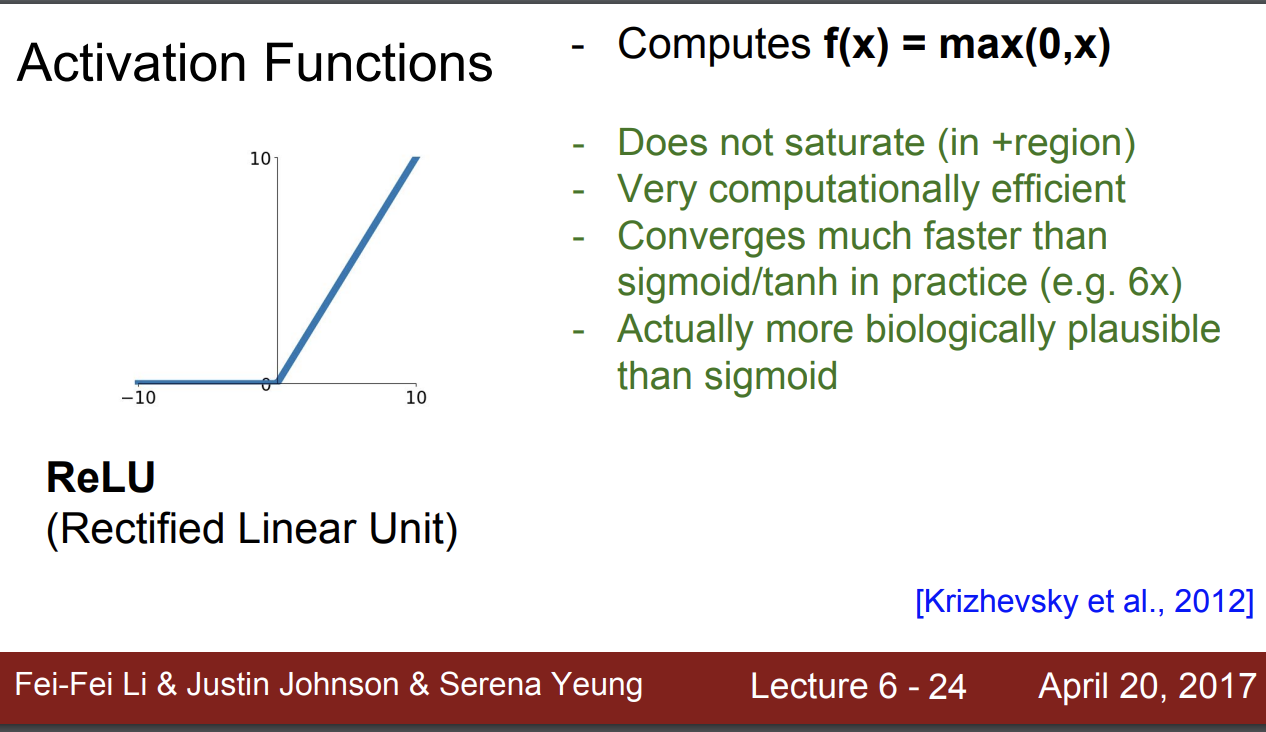
음수인 경우는 0이고 아닌 경우는 입력값이 출력값이 된다.
이 함수는
- 양수인 경우 더이상 kill 되지 않는다.
- 계산하기 편하다.
- 시그모이드와 tanh 보다 훨씬 빠르다.
- 생물학적으로도 시그모이드 함수봐 비슷하다고 한다..
하지만
- zero-center가 아니다.
- 음수인 부분에서의 기울기는 0이다.
x = 10이면 10 의 기울기이지만, x = -10 이면 0, x = 0 이어도 0이다.
Dead ReLU
이를 Dead ReLU라고 한다.
초기화에서 dead ReLU에 빠져버리면 아예 업데이트가 되지 않는 것이다.
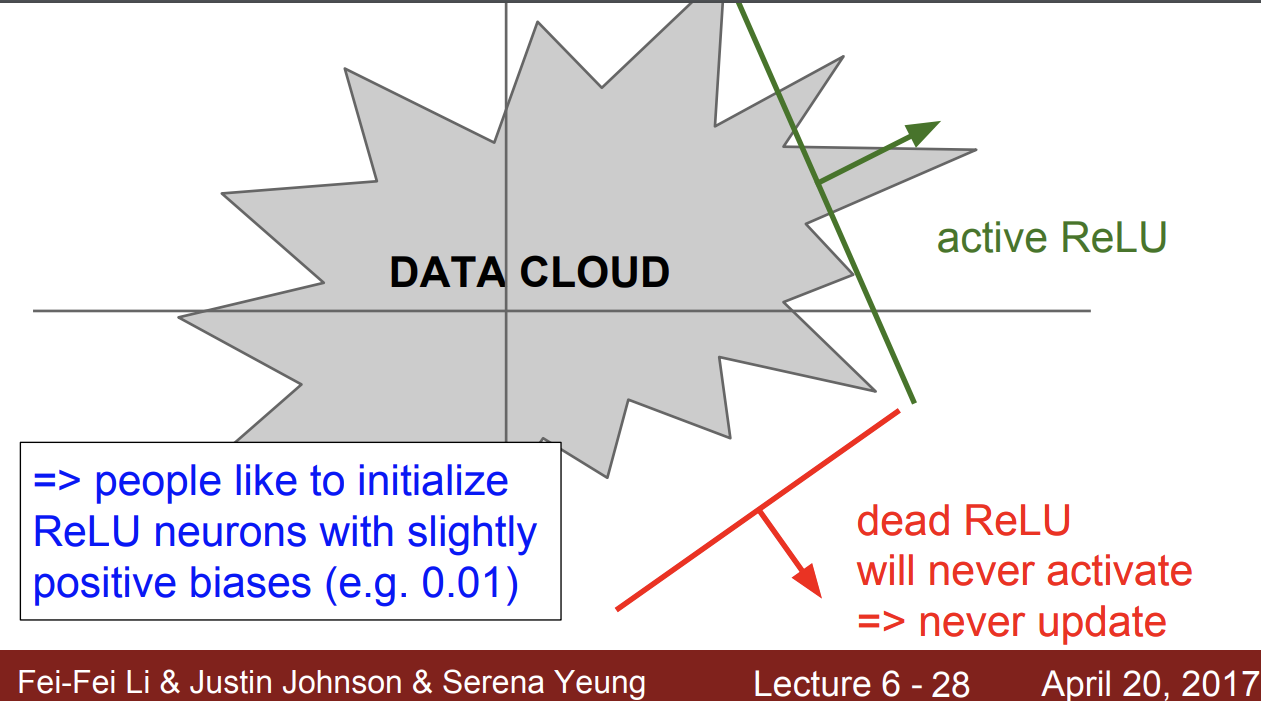
그래서 이를 해결하기 위해서 약간의 편향을 더한다.
하지만 이런 bias를 더하는 사람도 있고 안하는 사람도 있다고 한다. 효과는 엄청 좋은 편은 아닌 것 같다.
Leaky ReLU
위 문제를 해결한 Leaky ReLU가 있다.
음의 영역에서 경미하게 기울기를 줘서 vanishing gradient 문제를 해결하였다.
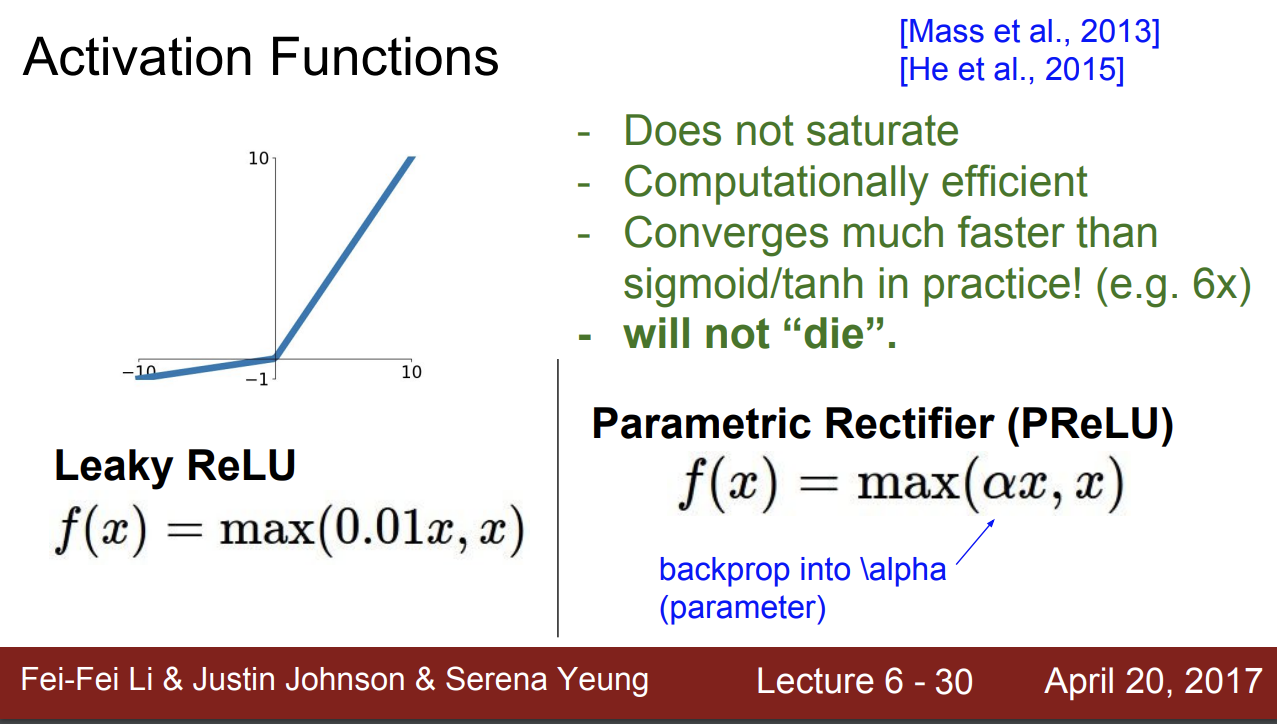
알파 매개변수를 통해 좀 더 유연성을 더한다.
ReLU에서 x = 0을 보면 사실, 미분이 불가능하다.
우미분 = 좌미분이어야 미분이 가능한데 둘 값이 다르기 때문이다.
따라서 이를 보완한 것이 ELU이다.
ELU

- Leaky ReLU와 비교해서 노이즈에 대해서는 좀더 Robustness를 가진다는 장점이 있다.
- zero mean의 결과값을 출력하는데 장점이 있다.
하지만
- exp 계산을 또 해야한다.
- 음의 영역에서의 기울기가 또 소실된다.
Maxout "Neuron"
위 함수들과는 좀 다르다. 파라미터를 더 두어서 각각 출력 값이 다른 함수 2개 중 max를 취하는 것이다.
- ReLU와 Leaky ReLU를 일반화한다.
- 기울기가 사라지는 단점을 보완한다.
- 하지만 연산량은 두배가 된다.
TLDR
결과적으로는 일단은 ReLU를 시도하고, 성능이 좋은 것을 이용하자.
tanh는 별로 좋지는 않고 sigmoid는 생각도 하지말자.
Data Preprocessing
데이터 전처리이다.
원래의 데이터가 있다면 이를
- zero - centered
- normalized data
할 수 있다.
보통은 zero-centered 한 후 normalize 한다.
하지만 이미지 데이터의 경우는 정규화를 안해도 된다. 그 이유는 픽셀 값이 모두 같기 때문이다.
그리고 zero-center를 하는 이유는 이전에 말했듯, 입력값이 모두 양수이면 optimal를 찾기 힘들기 때문이다.
훈련 단계에서의 전처리 과정을 test 데이터에 대해서도 똑같이 하는가? 질문에
"넵!" 똑같이 진행한다고 한다. 똑같은 mean을 이용한다. 근데 전체 이미지에서 평균을 추출할지, 각각의 독립된 채널의 평균을 추출할지를 선택할 수 있다.
Weight initialization
중요한 초기화 관련 개념을 다룬다.
뉴럴 넷에서 만약 W=0을 초기화로 사용하면 무슨 일이 일어날까?
뉴런이 전부 똑같이 동일한 작업을 수행한다. 즉 활성화함수가 작동을 하지 않는다.
그럼 이를 해결할 수 있는 방법 1
랜덤 값 부여하기
정규분포로 부터 가져온 편차들의 값들로 w initialization 한다.
이는 작은 네트워크에 대해서는 괜찮지만 deeper networks에 대해서 문제가 발생한다.
실험을 해보자.
현재 10-layer dlrh, 500개의 뉴런이 각 층에 있다고 하자.
활성화 함수는 tanh이다.
랜덤 값 * 0.01 을 통해서 아주 작은 값들로 w 를 초기화한다.
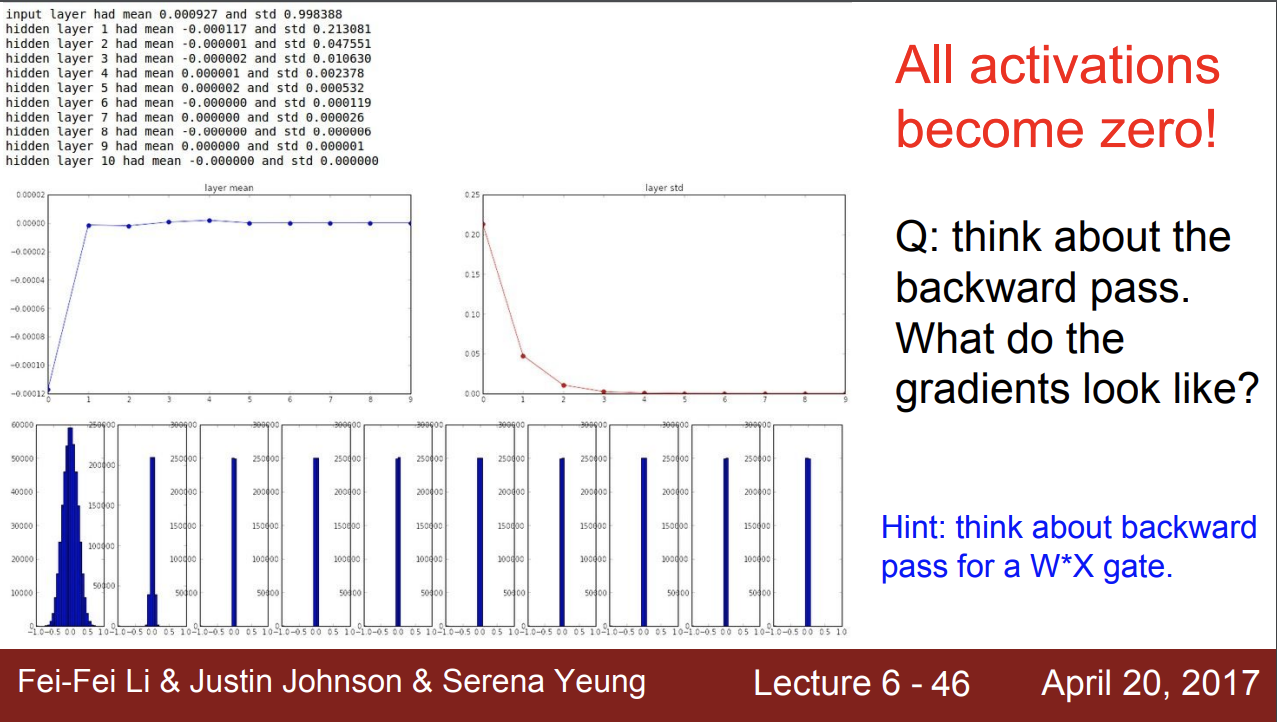
실험을 해본 결과, 점점 std의 값이 0에 가까워 진 것을 알 수 있다.
이는 각 레이어에 1 이하의 작은 숫자들을 계속 곱하면 값이 quickly shrinks한다는 것이다.
그러면 w 의 기울기는 어떻게 될까?
gradient = upstream graident * local gradient 인데
입출력 값들이 모두 작은 숫자들이니 기울기도 0에 수렴하고 update도 잘 안된다.
그럼 가중치를 1로 변경해서 실험을 다시 진행해보자.
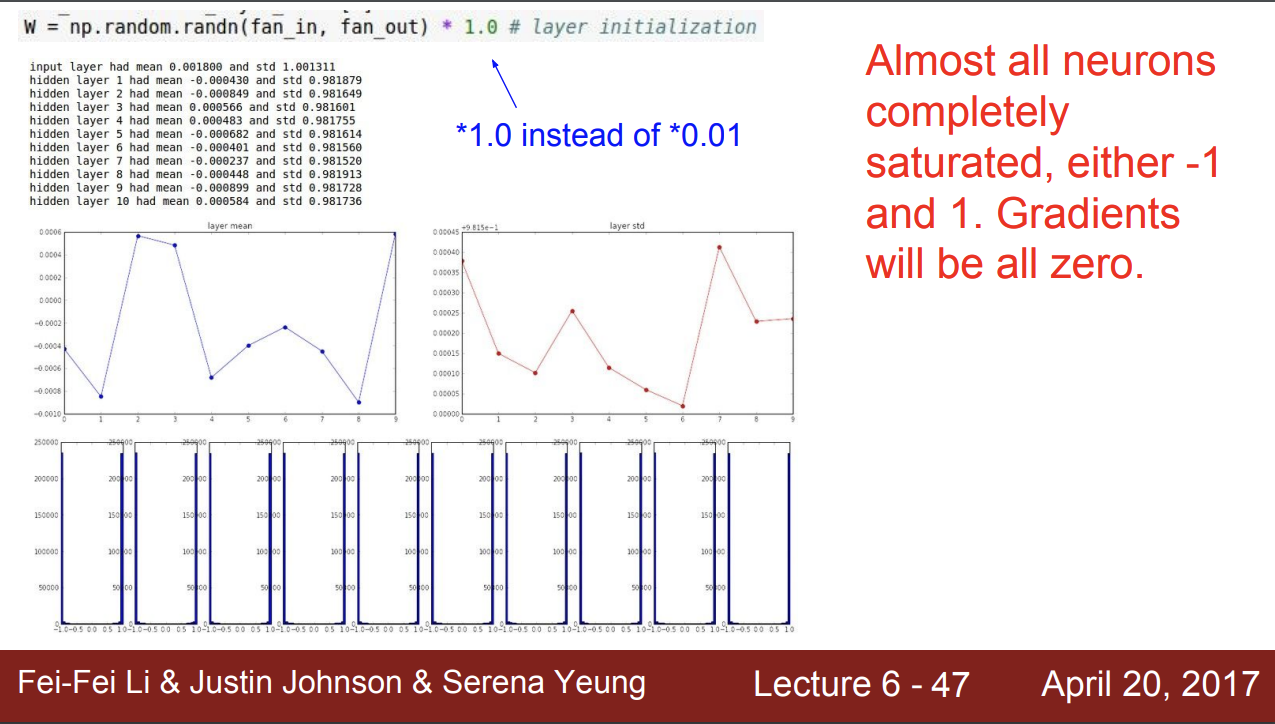
이 경우는 너무 편차가 커져서 -1, 1 값으로 값들이 포화된다.
tanh 함수 특성상 -1, 1값에서는 기울기가 거의 0이 되는 것을 알 수 있다.
초기화의 예시로 Xavier initialization이 있다.
랜덤의 가우시안 분포 값에서 np.sqrt 값으로 나누어 스케일링을 한다.
즉 고정값 보다 입력값의 개수에 따라 값을 조절해 초기화를 하기 때문에 합리적이다.
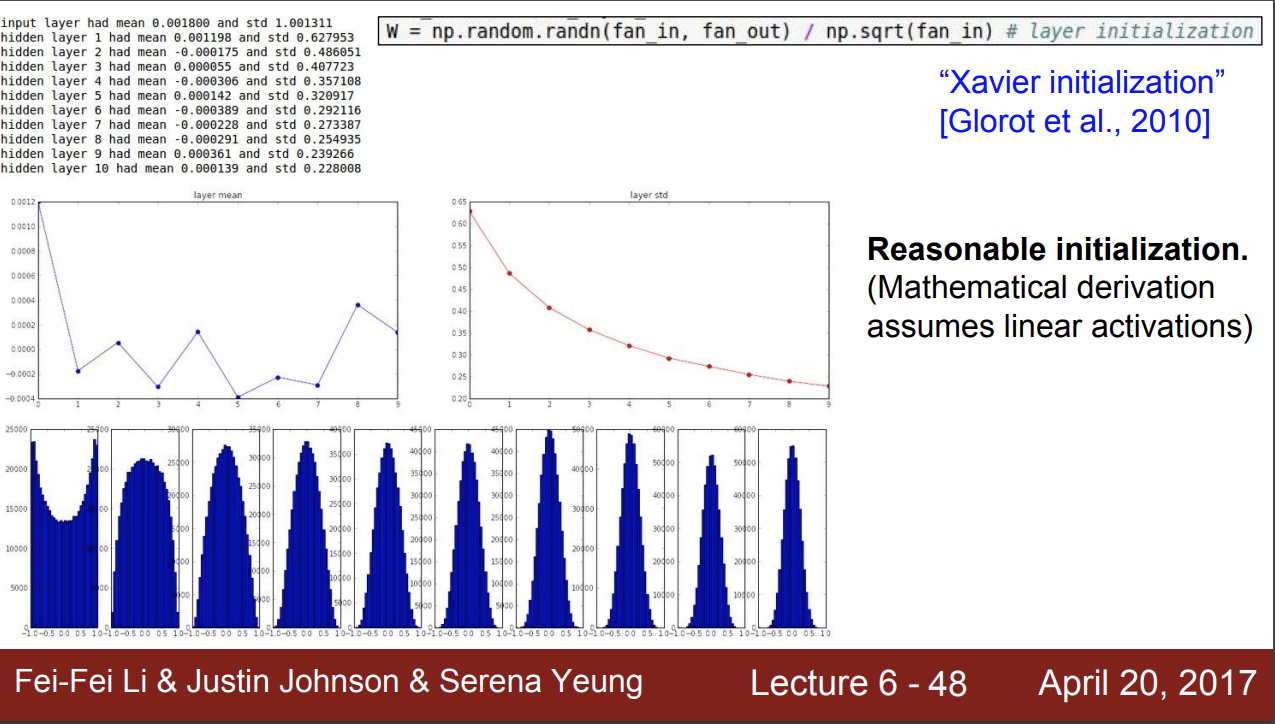
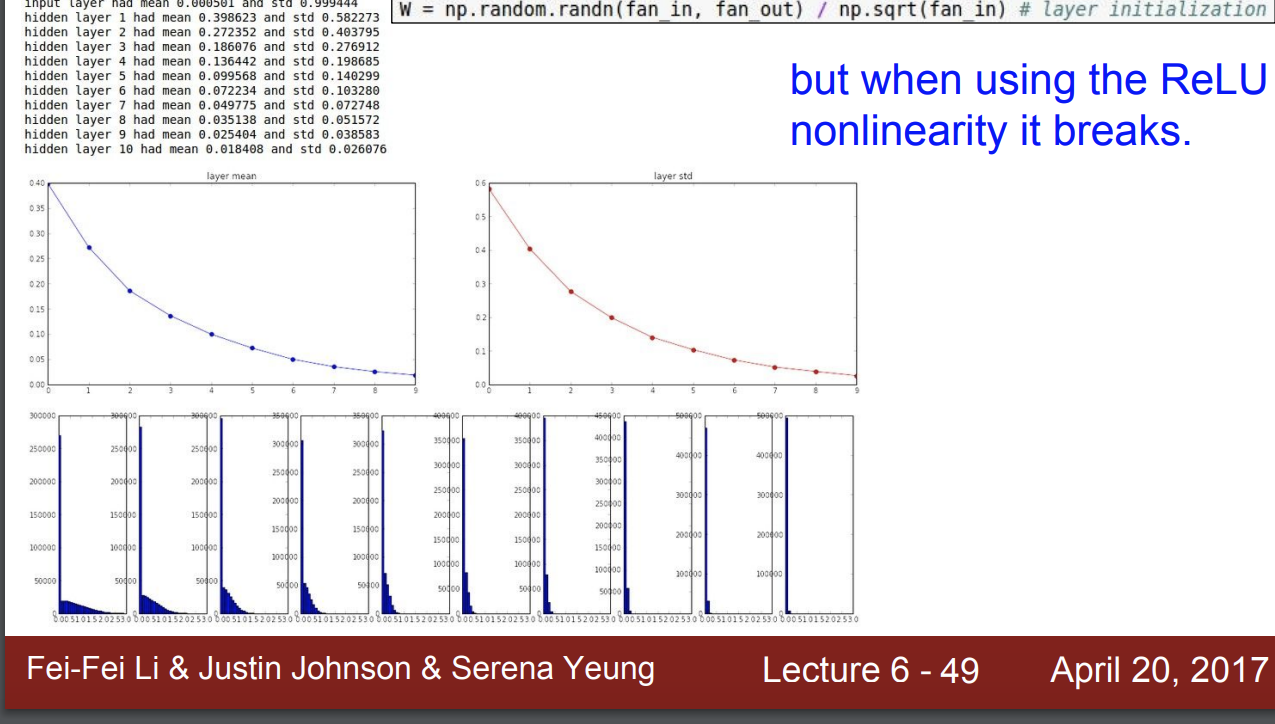
하지만 이는 ReLU를 사용하면 다시 문제가 발생한다.
왜냐하면 ReLU는 음수 부분에서 모두 0이되기 때문에 편차가 절반이 되기 때문이다.
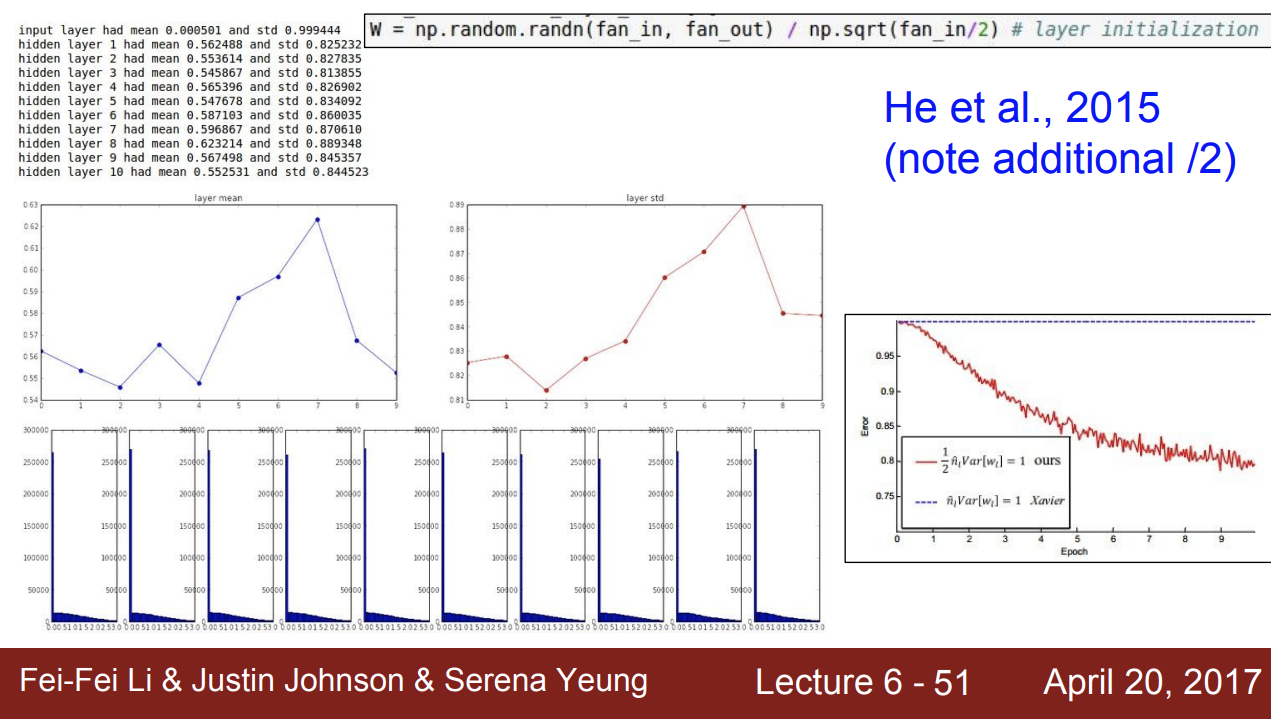
그래서 다시 np.sqrt(fan_in/2)를 통해 다시 2로 더 나누어 준다. 음수가 절반이 있다는 가정 하에, 즉 입력의 개수를 다시 2로 나누는 것이다.
좀 더 나아지는 모습을 확인할 수 있다.
Batch Normalization
가장 와닿지 않은 부분이다.
좀 더 공부가 필요할 것 같다.
교수님은 논문을 꼭읽으라고 하셨다. 여기 링크를 첨부한다.
batch에서 평균과 분산을 이용해 처음부터 batch 정규화를 취해서 모든 층에서 정규분포를 따르도록하는 것이다.
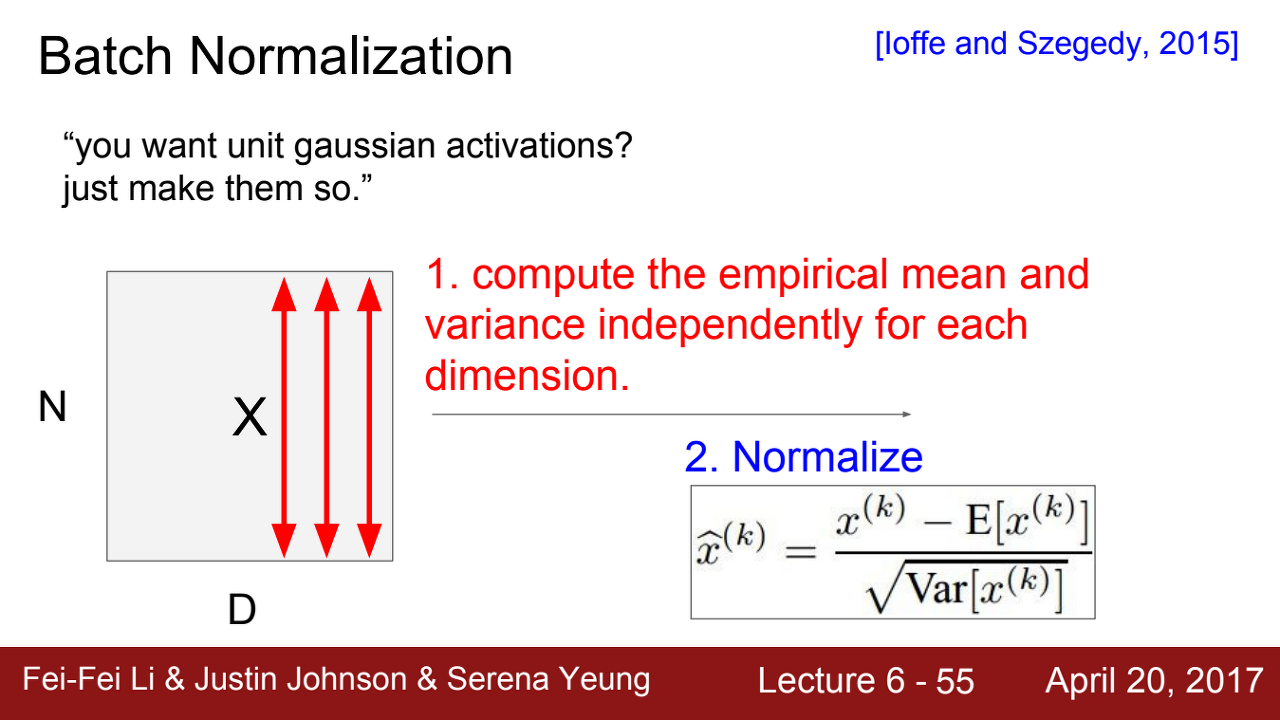
현재 batch에서 N개의 D차원 input data가 있다고 하자.
- 각각의 차원마다 평균과 분산을 계산할 수 있다.
- 계산한 평균과 분산으로 정규화를 진행한다.
ConV, FC 층 후에 batch norm을 진행한다. 활성화 함수를 하기 전에 넣어준다.
각각의 층에 가중치들이 곱해지고, layer를 지날 때마다 범위가 급격하게 튈 수 있다. 따라서 batch norm을 통해 안정화 시키는 것이다.
ConV, FC 층 모두 적용 가능한데 차이점이 존재한다.
컨볼루셔널에서는 activation map의 공간 위치 정보가 중요하다. 그래서 CNN에서는 채널(필터) 별로 독립적으로 배치 정규화를 수행하고 완전 연결 신경망에서는 각 레이어의 뉴런에 대해 배치 정규화를 수행한다.
Batch norm은 tanh으로 가는 입력값들을 기울기가 존재하는 부분으로 범위를 강제한다. 따라서 앞서 Saturate한 문제들을 어느정도 해결한다.
그리고 정규화한 값을 다시 identity한 값으로 변경하고 싶을 때는
감마를 곱하고 베타를 더한다.
감마는 표준편차이기에 Scaling 베타는 평균이기에 Shift 효과를 준다.
이처럼 Saturate 상황을 flexible 하게 control할 수 있다.
배치 정규화를 요약하면,
1. 미니배치의 평균: μ = (1 / m) Σ(x_i), 여기서 m은 미니배치의 크기, x_i는 입력 값이다.
2. 미니배치의 분산: σ^2 = (1 / m) Σ(x_i - μ)^2
3. 정규화된 값: z_i = (x_i - μ) / √(σ^2 + ε), 여기서 ε는 작은 양수로 분모가 0이 되지 않도록 한다.
4. 스케일(scale) 및 시프트(shift) 적용: y_i = γ * z_i + β, 여기서 γ와 β는 학습 가능한 매개변수이다.
위 4가지 순서로 진행할 수 있다.
배치 정규화는 다음과 같은 장점이 있다.
- gradient 소실 및 폭주를 방지할 수 있다. : 각 레이어의 입력을 평균과 분산으로 정규화하기 때문에 gradient 크기를 안정화시키기 때문이다.
- 초기화에 덜 민감하게 된다.
- 더 큰 학습률을 사용할 수 있다.
Babysitting the Learning Process
그러면 이제 훈련을 시작할 때, 전처리를 잘 수행했다고 하면 네트워크 아키텍쳐는 어떻게 구성하고 훈련 과정을 어떻게 봐야할까?
우선은 매우 작은 데이터로 시작해서 모든 훈련 데이터에 적합하게 과적합이 되는지 확인한다.
그리고 과적합을 해결하는 방법 중 하나인 regularization을 조금씩 수행해서 어떤 값을 가지는 지 확인한다. 그 다음 손실을 줄이는 학습률을 찾는다.
학습률이 너무 작으면 loss는 거의 바뀌지 않는다.
학습률이 너무 크면 폭발해서 NaN값들이 나올 수 있다.
이런 학습률은 [1e-3, ... ,1e-5] 이렇게 조금씩 cross-validating 하면서 값을 조정해 가야한다.
Hyperparameter Optimization
최적화 파라미터를 어떻게 찾을까?
Cross-validation strategy
Cross-validation strategy 이런 기법이 있다. 교차 검증이라고 하는데 데이터를여러 부분 집합으로 나누어서 학습 및 평가를 반복적으로 수행한다.
만약 예를 들어서 5 epochs를 수행한다고 하자.
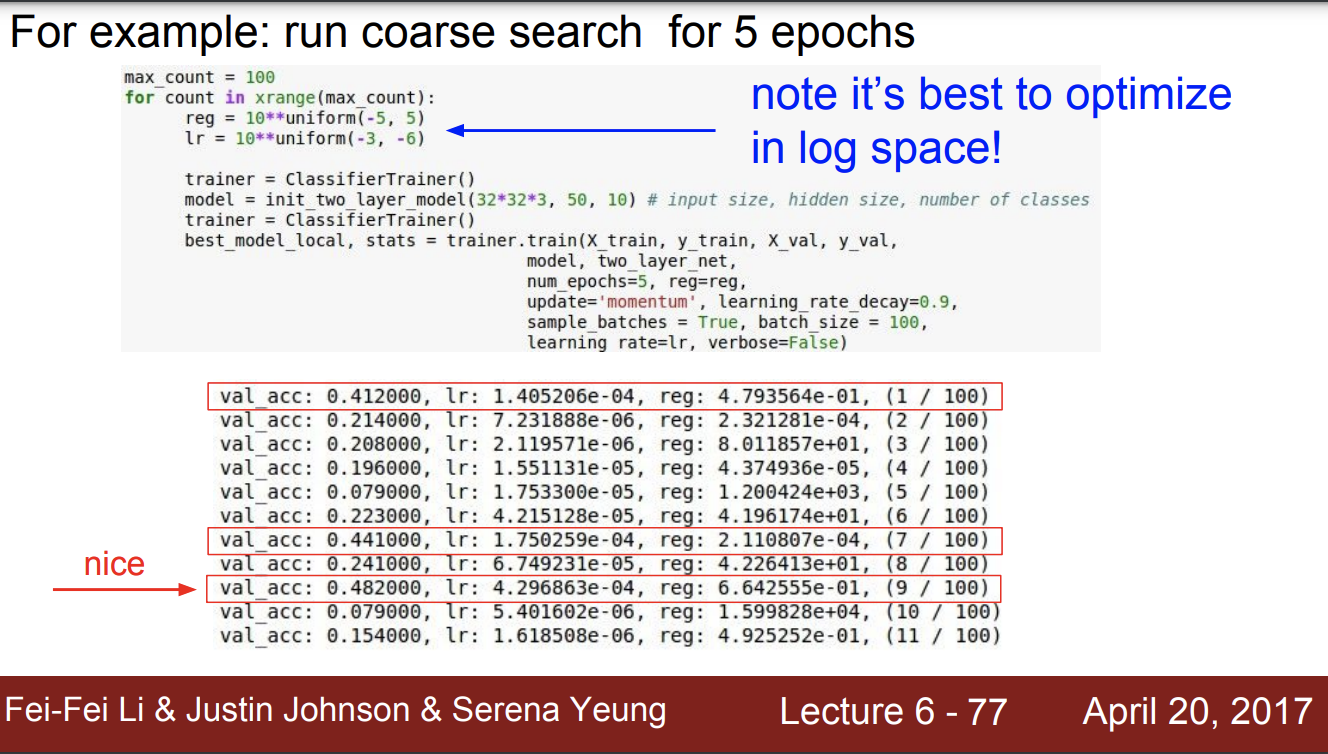
reg, lr는 log space를 취해준다. 값의 범위를 줄여주는 것이다.
값이 조금만 커져도 폭발하고 조금만 작아도 업데이트가 안되기 때문이다.
빨간색 박스들은 정확도가 좀 nice 한 것들이다. 이때의 lr과 reg 값들을 보면,
lr : e-04
reg : e-01, e-04 값들이다.
다시 그러면 값이 범위를 조절 한다.

정확도가 53% 까지 증가했다.
이는 best가 아닐 수 있다. 좀더 값을 세밀하게 조정하면 정확도가 더 증가할 수 있기 때문이다.
하이퍼파라미터들의 값들을 조합으로 고정시켜 좋은 조합을 뽑는 방식이 있다.
Grid vs Random
Grid 방식과 Random 방식이 있다.
Grid 방식은
- 서치 가능한 모든 하이퍼 파라미터 조합을 지정된 범위 내에서 모두 시도하여 최적의 조합을 찾는 방법이다.
- 탐색 과정이 철저하고 명확하다.
- 하지만 조합이 많은 경우 계산 비용이 높다.
Random 방식은
- 탐색을 무작위로 수행하는 방법이다.
- 계산 비용이 Grid 방식보다 상대적으로 적다.
- 모든 하이퍼파라미터의 공간을 탐색하지는 않지만 대부분의 경우 빠르게 좋은 성능을 얻는다.
이는 그리드 보다 랜덤 방식이 더 좋은데 그 이유는 그리드 방식은 모든 변수들을 중요도를 똑같이 하지만 랜덤의 경우는 이 벽을 허물어 변수들 사이의 중요도를 다르게 하여 찾기 때문이다.
하이퍼 파라미터는 디제잉을 하는 것이다.
감으로 시작해서 범위를 좁혀 나가는 것이기 때문이다.
loss curve
loss 그래프를 해석해보자.
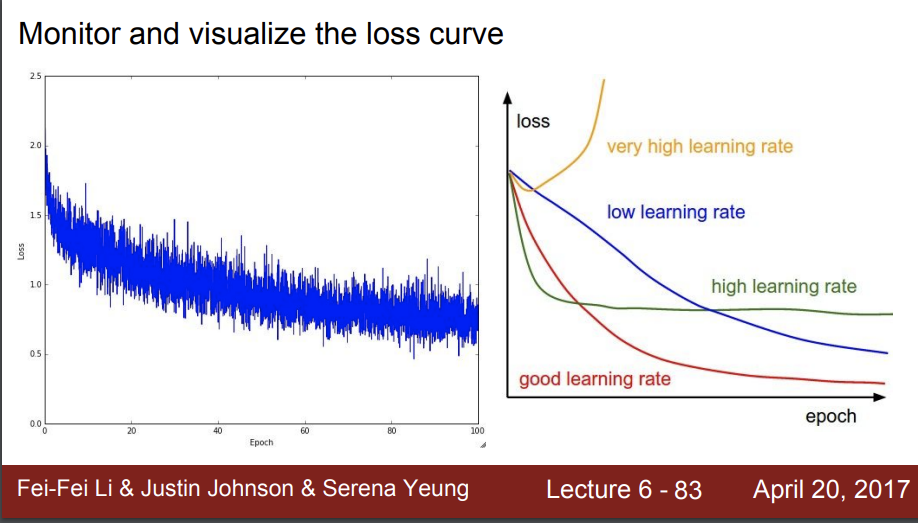
가장 좋은 선은 빨간색 선이다.
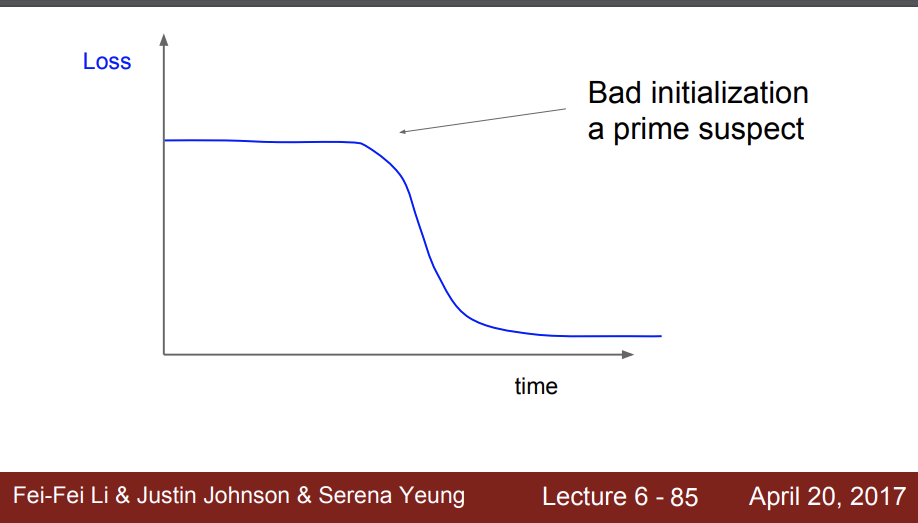
위 그래프는 초기 초기값을 잘못잡으면 처음에 update가 일어나지 않아서 best를 찾는데 시간을 너무 오래 끈것이다.
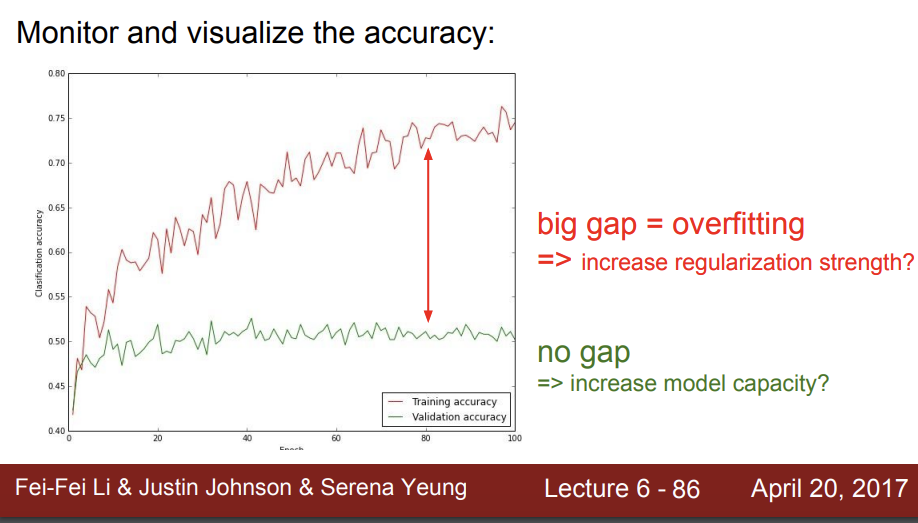
또한 검증 정확도와 훈련 정확도의 차이가 크면 안된다.
만약 크다는 것은 과적합이 일어난 것이다.
강의는 여기까지.. 다음 부터는 강의 리뷰를 한 강의당 하나씩 업로드를 하려 한다. 너무 블로그 내용이 길어지면 조금씩 렉이 발생하기 때문에..
