강의 자료
Lecture 11 | Detection and Segmentation
오늘 배울 내용은 !
Today: Segmentation, Localization, Detection
좀 재밌는거 배우는 것 같아서 신난당
지금까지 우리는 이미지 분류를 진행했다.
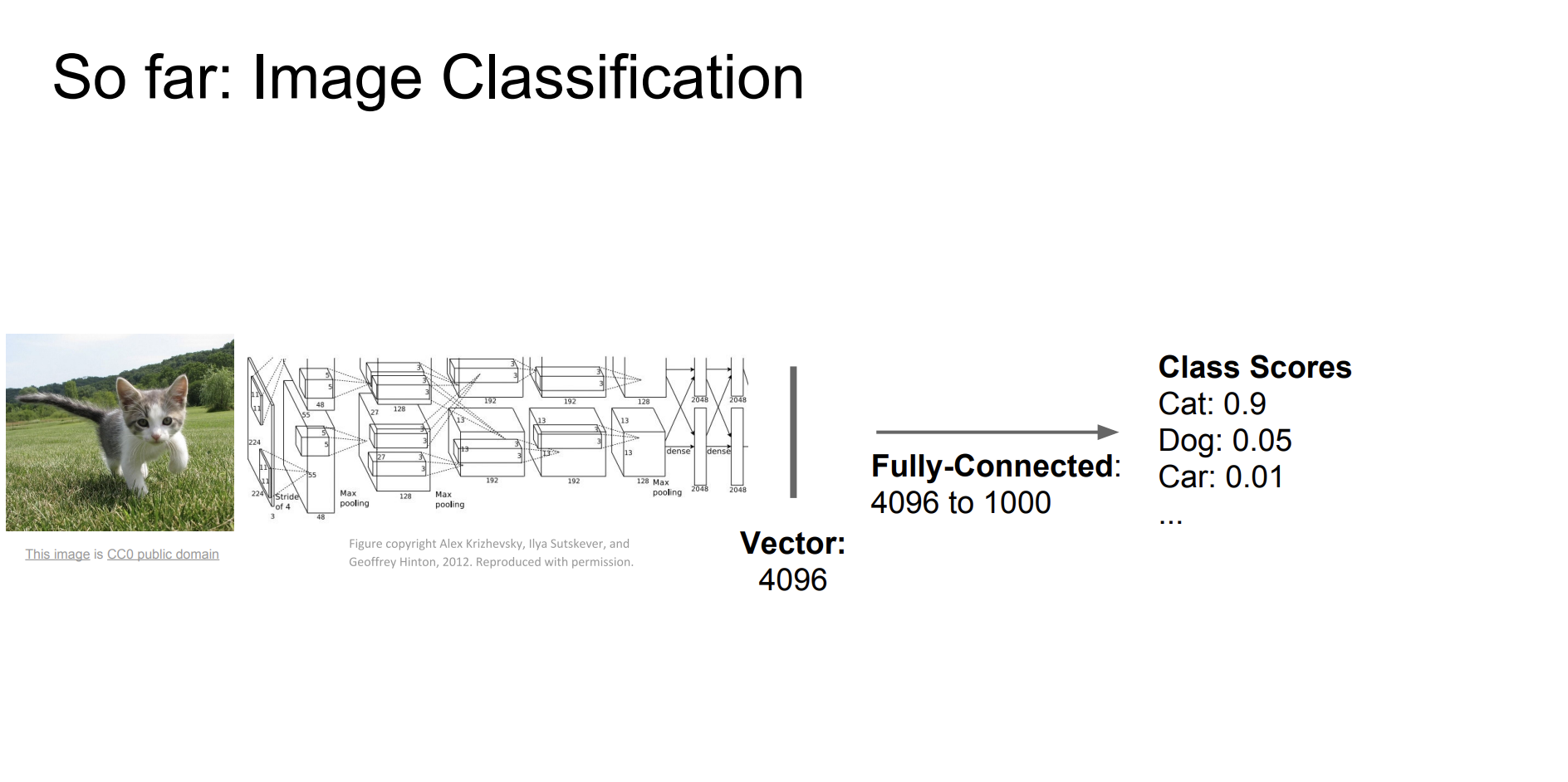
그럼 이제 다른 컴퓨터비전 작업에 대해서 알아보자!
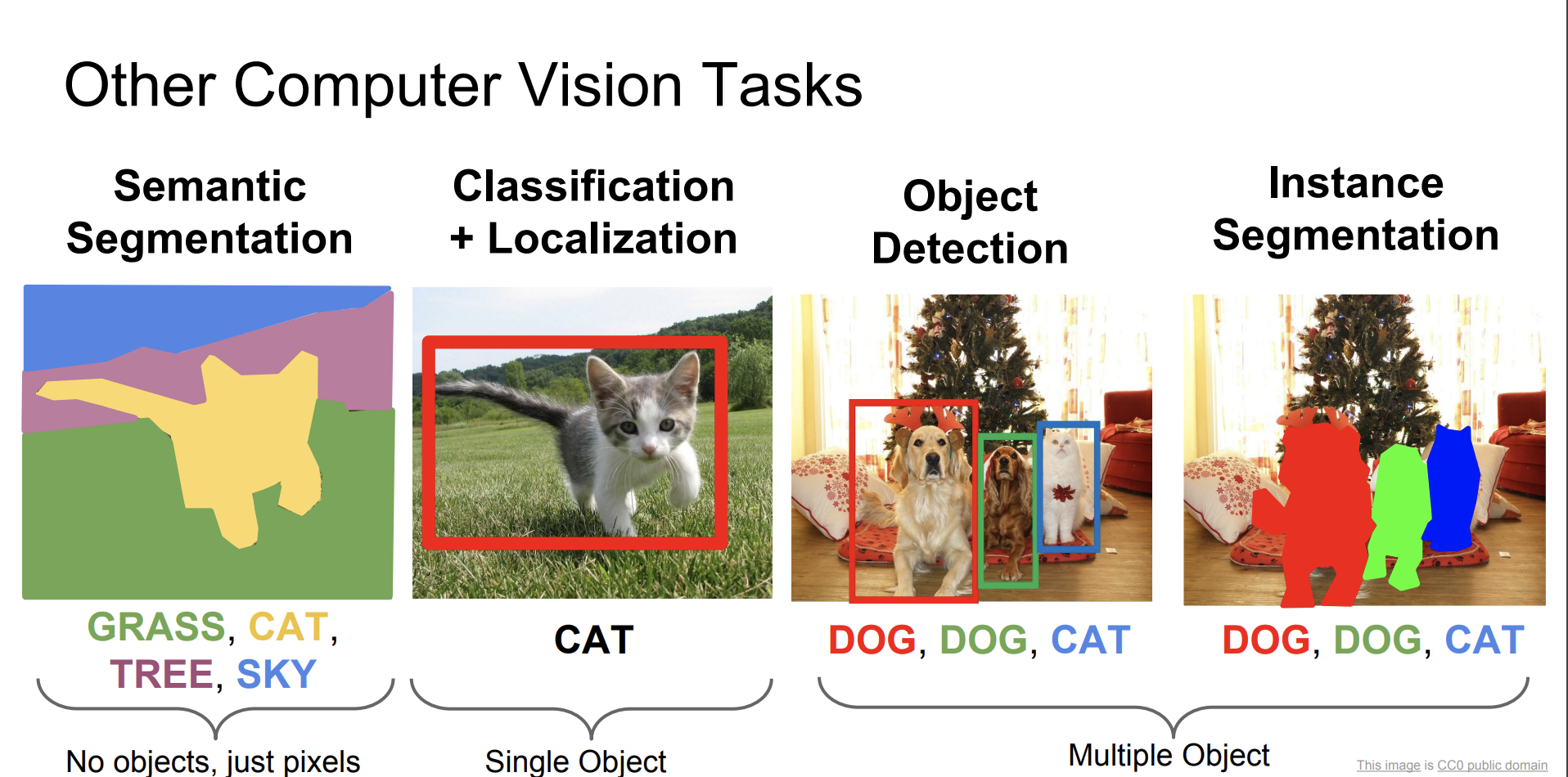
- Segmantic Segmentation
- Classification + Localization
- Object Detection
- Instance Segmentation
Segmantic Segmentation
의미론적 분할. 한국어로 그냥 번역한 것이다.
이미지를 카테고리별로 분할하는 것이다.
인스턴스별로 구별하는 것이 아니라, 픽셀별로 따진다는 것이다.
Segmantic Segmentation를 해결하기 위한 방법은 여러가지가 있는데 그중 가장 원초적인 방법은 바로 Sliding Window이다.
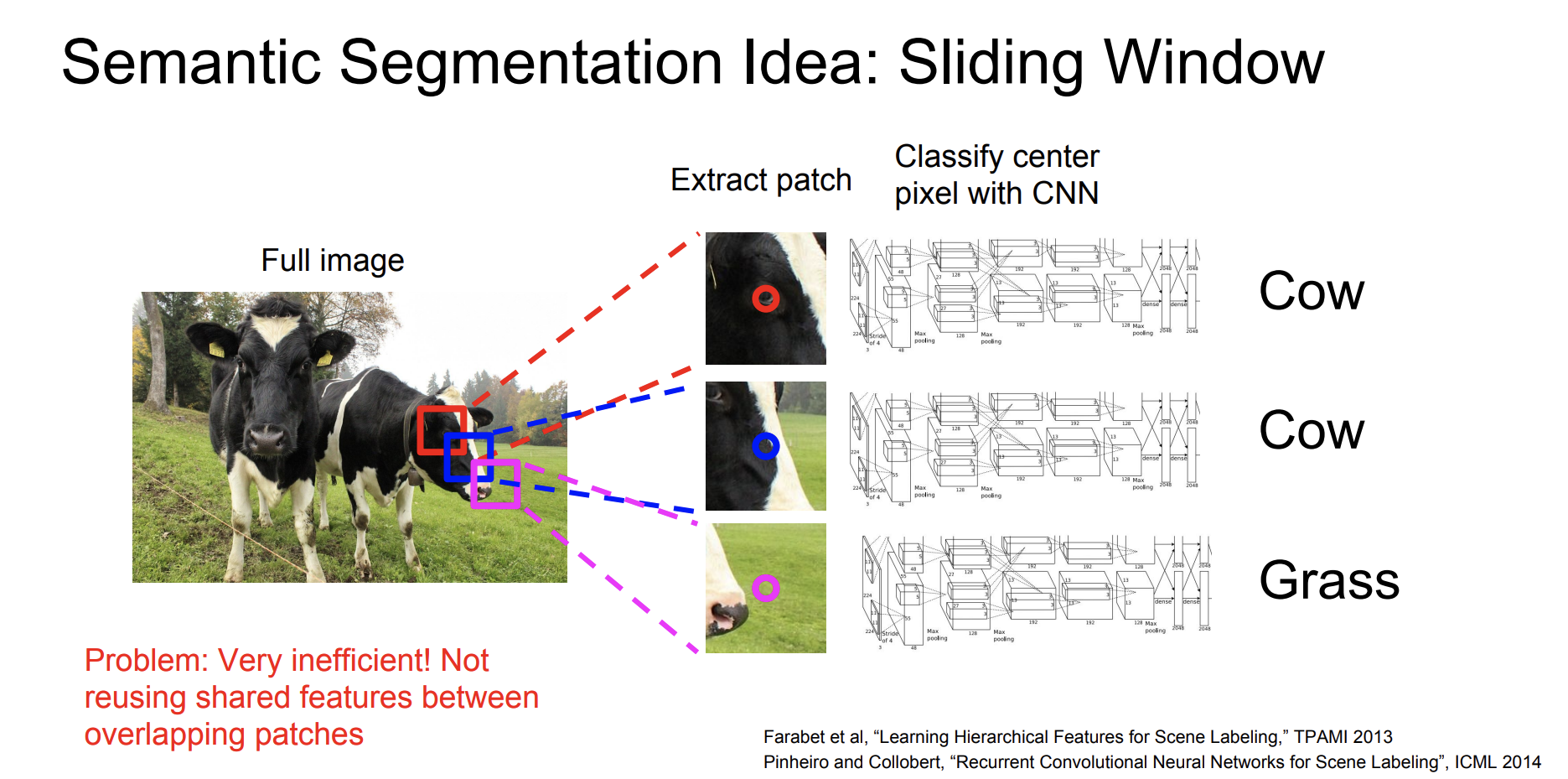
Sliding Window는 창을 이동시키면서 해당 창의 이미지를 분석하는 방법인데, 너무 시간이 오래걸리고 사진들간의 overlapping이 되고있는데, 심지어 새로 계산해야하기 때문에 정말 비효율적인 방법이다.
그럼 다음 방법은 뭘까?
바로 Fully Convolutional 방법이다.
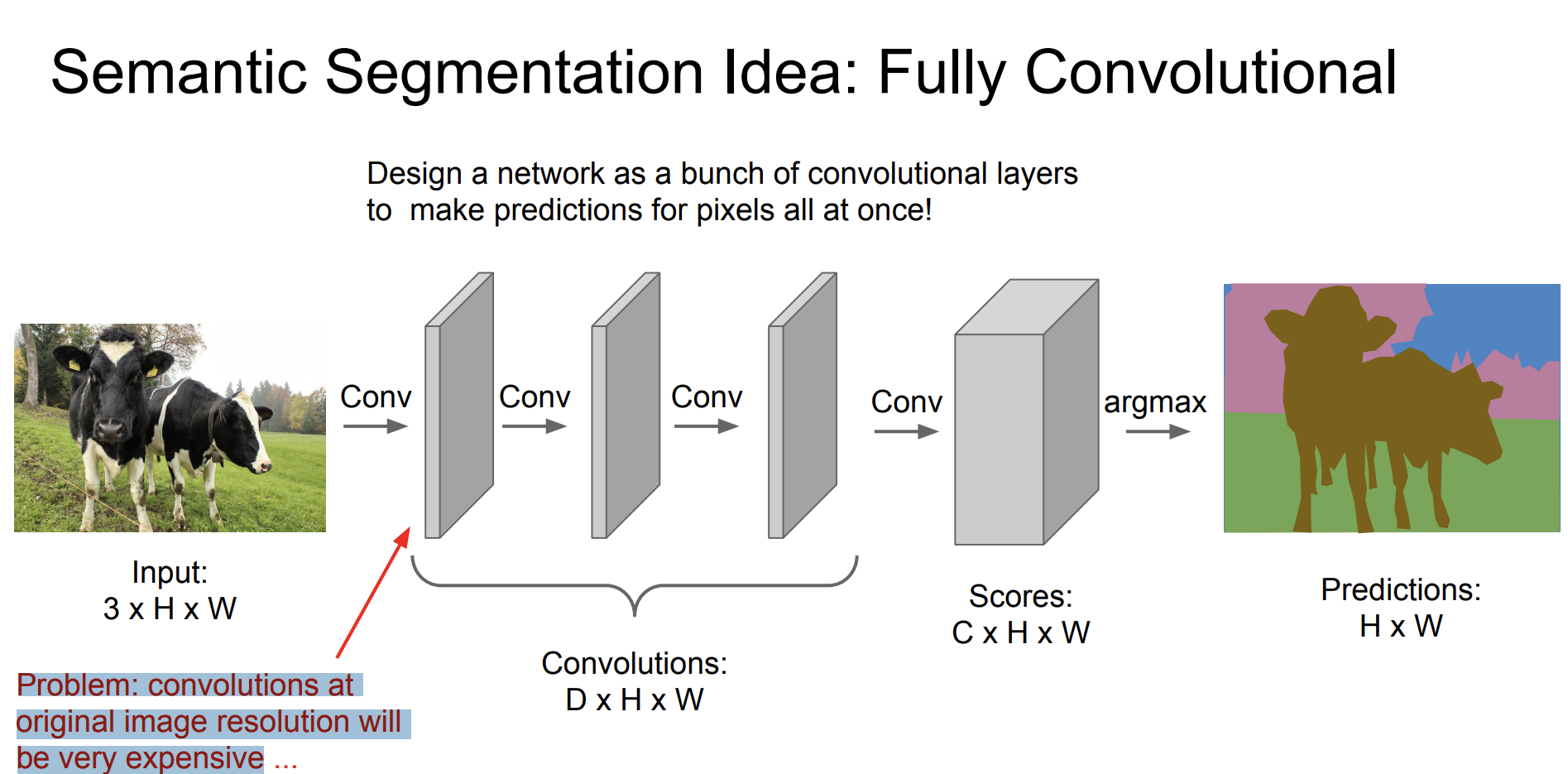
한번에 픽셀들을 예측할 수 있도록 여러개의 convolutional layers로 네트워크를 디자인하자.
문제점은 처음의 원본 해당도의 convolutions은 매우 비싸다고 한다!
그럼 훈련 데이터는 어떻게 얻는가?
훈련데이터를 얻는 것은 쉽지 않다. 매우 비싸다. 이미지에 대한 윤곽선을 딴 그림들을 수집해야한다.
손실함수는 어떻게 되는가?
우리는 픽셀별로 분류 결정을 내린다. 모든 픽셀에 대해서 교차 엔트로피를 적용한다. 우린 모든 픽셀에 대한 실측 카테고리 라벨이 있다. 따라서 라벨과 output에 대한 교차 엔트로피를 계산한 다음 합하거나 평균을 구하는 방법으로 계산한다.
그럼 원본 해상도를 fully convolutional하는 대신 해상도를 줄인 다음 convolution을 수행하고 다시 upsampling을 해서 원본 해상도로 늘리면 되지 않나?
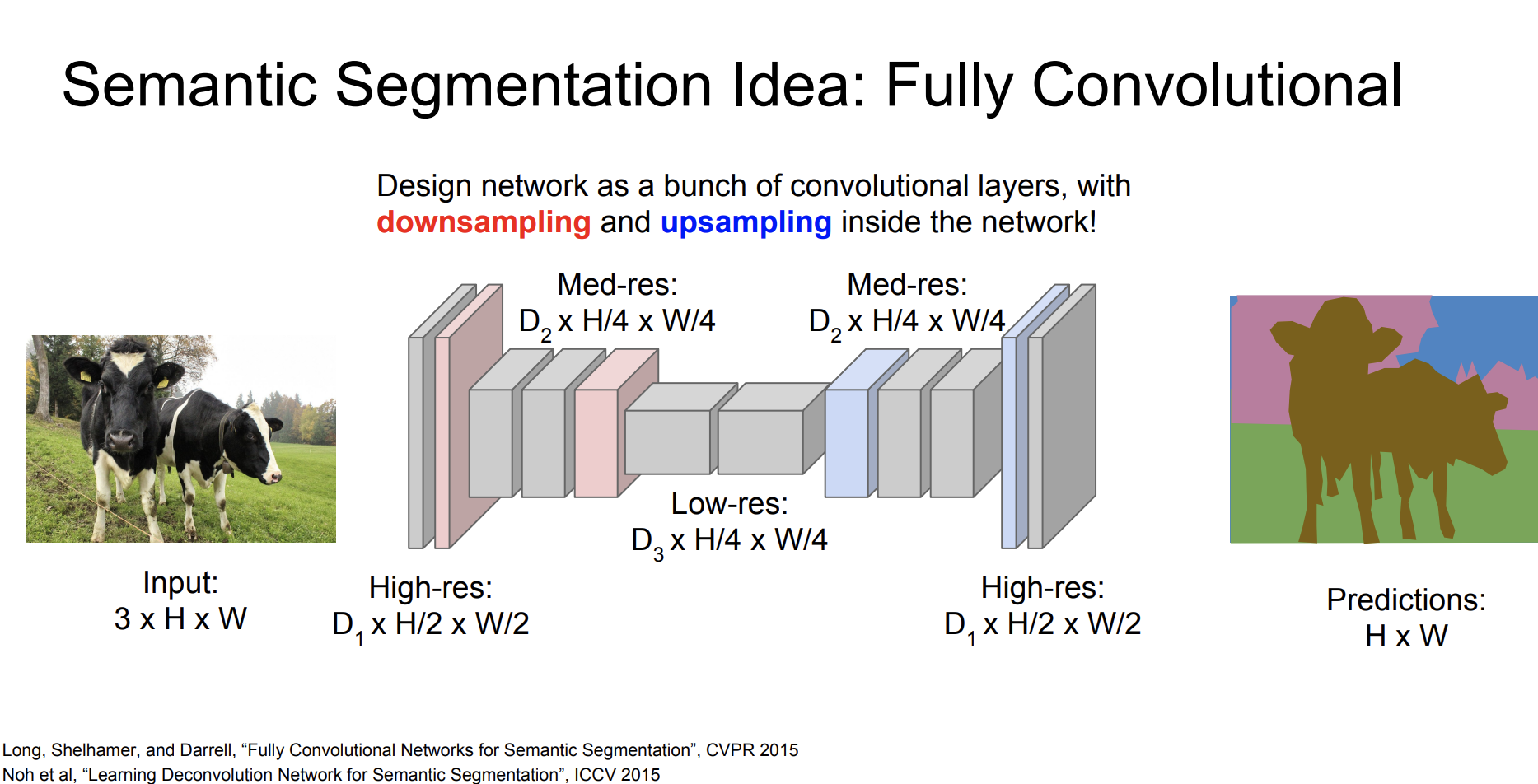
우리는 downsampling에 대해서는 잘 아는데, upsampling에 대해서는 잘 모르니까, 이에 대해서 알아보자.
Upsampling
upsampling에는 여러 방법이 있다.
첫번째, Unpooling 방법이다.
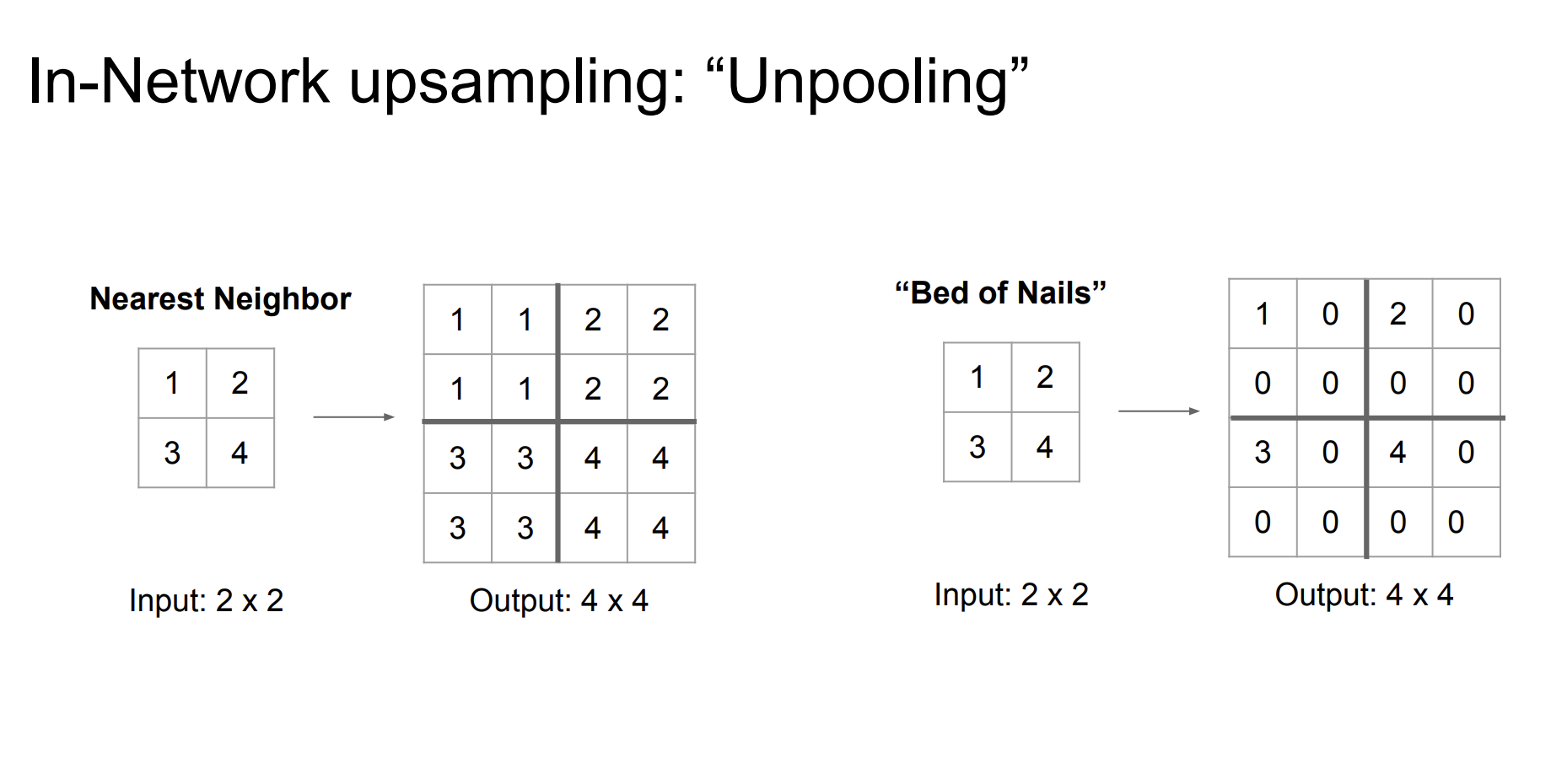
Nearest Neighbor는 가까이 있는 숫자를 그대로 복사해서 늘리는 방법이다.
Bed of Nails는 크기를 늘리되 다른 숫자들은 모두 0 으로 설정하는 방법이다. 이름의 유래는 평평한 바닥에서 못같은 것이 솟아있는 모양을 본떠 만들었다고 한다.
또 다른 방법이 있다.
우리가 이전에 downsampling에서 Max pooling이라는 방법을 배웠다. 이 방법은 칸을 나누어서 가장 큰 값을 선택하는 방법이다. 이 방법에서 아이디어를 가져온 Max Unpooling를 알아보자.
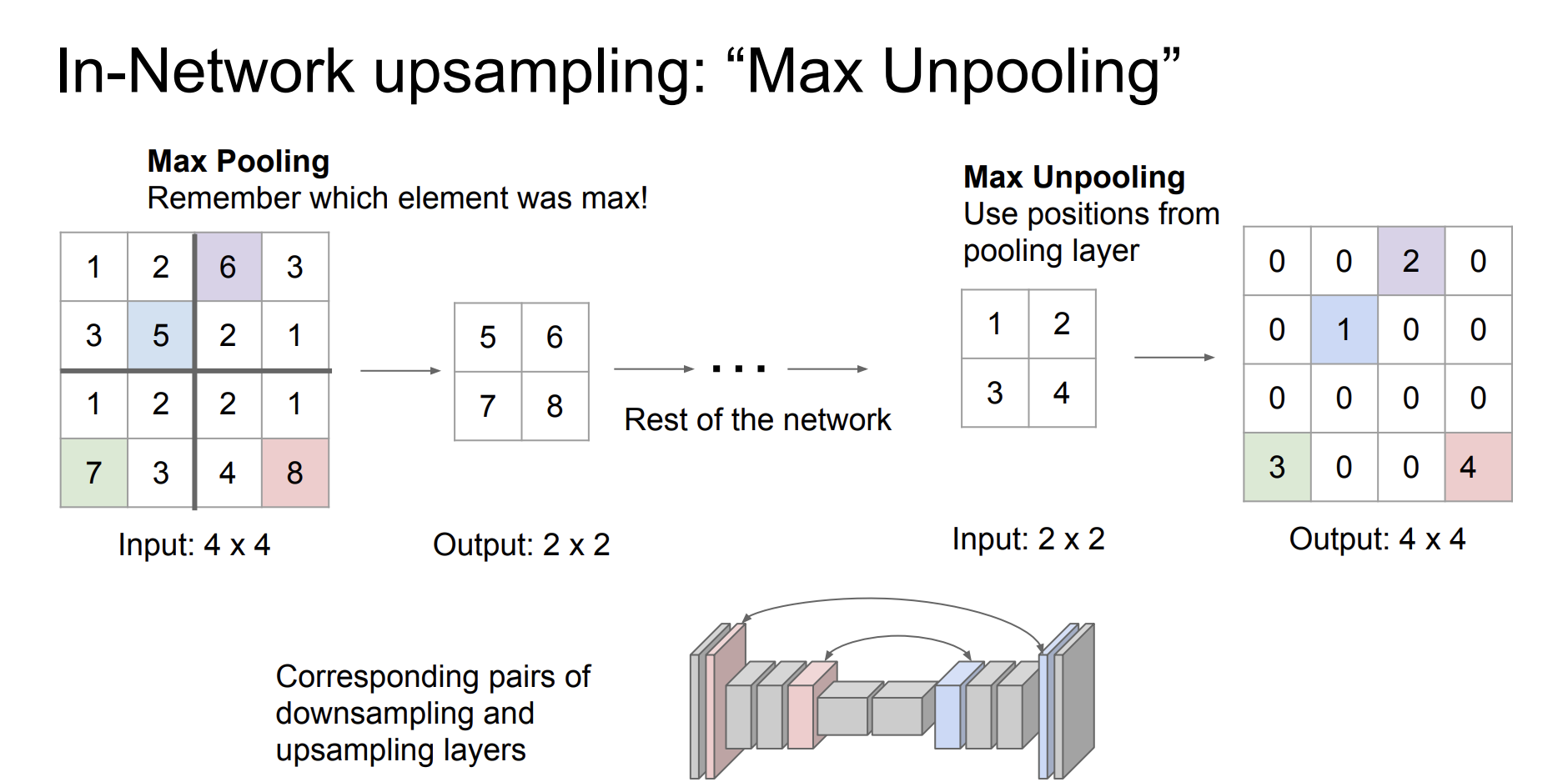
Max pooling을 알때 어떤 수로 pooling을 하는지 기억한 다음 unpooling을 할 때, 그 위치에 숫자를 넣고 다른 위치의 숫자들은 모두 0으로 세팅한다.
또 다른 방법으로는 Transpose Convolution 방법이다. 우리가 이전에 Stride convolution을 진행할 때, Stride의 크기를 크게할 수록 output의 크기가 줄어든 것을 확인할 수 있었다.
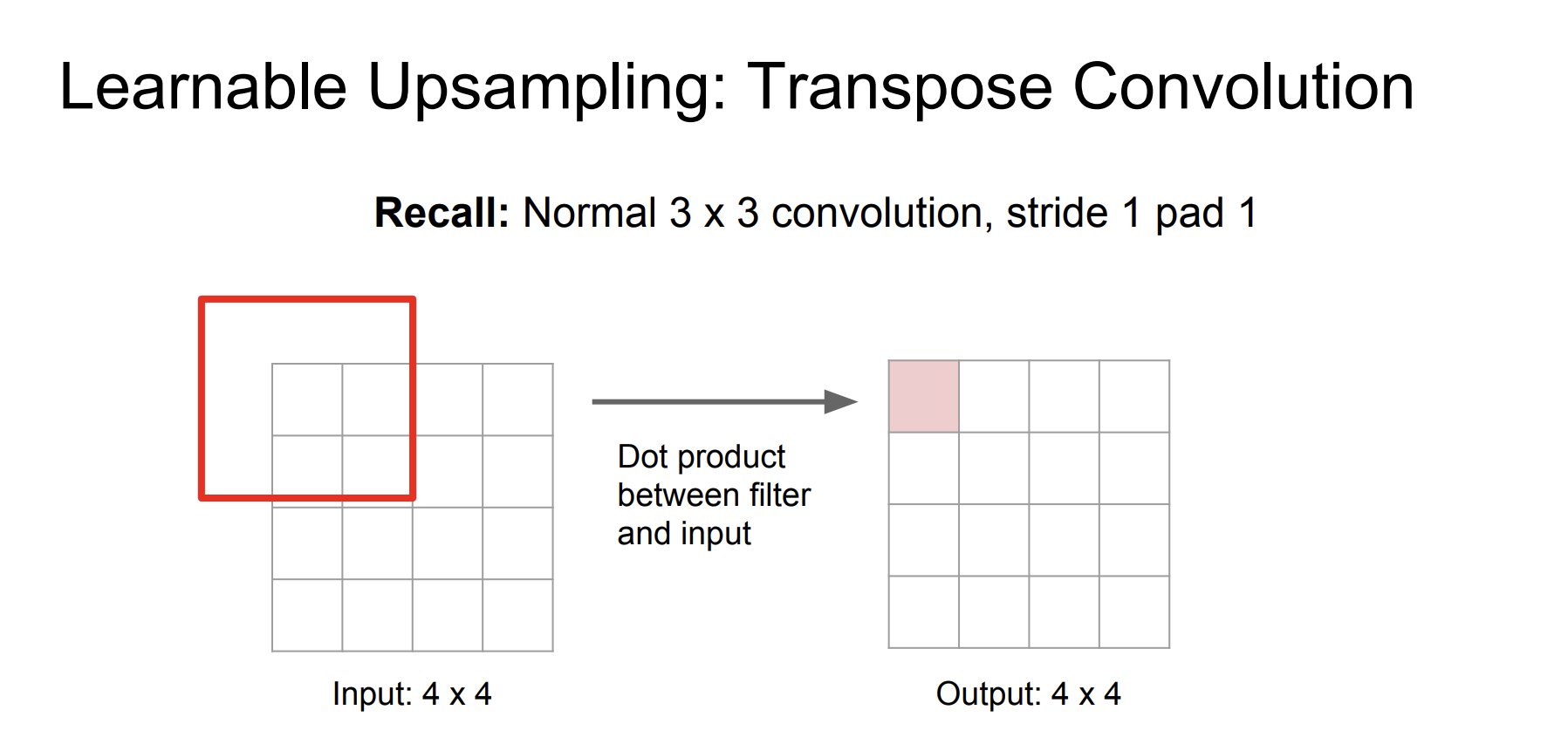
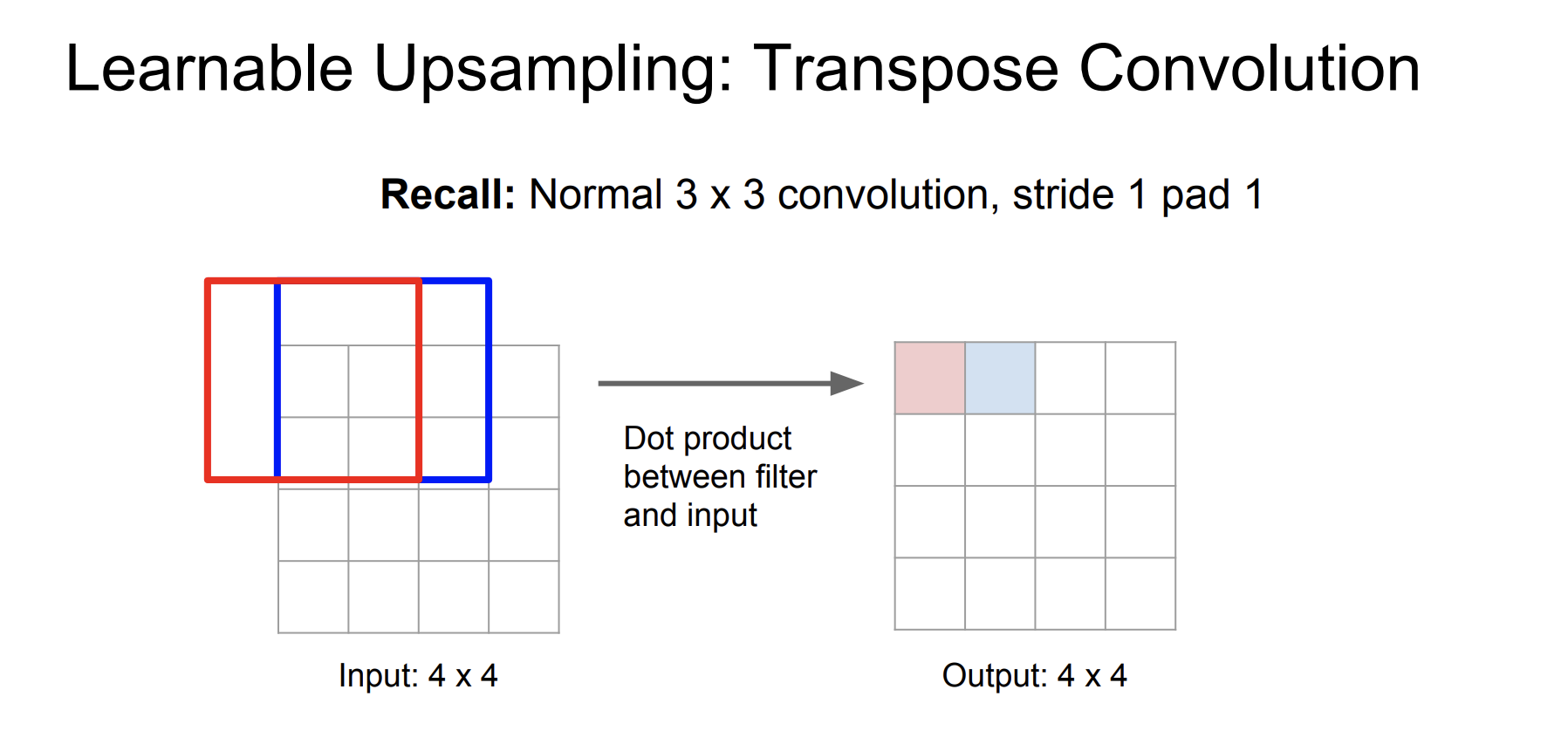
위 과정은 stride를 1로 설정한 경우이다. 2로 설정한 경우를 살펴보자.
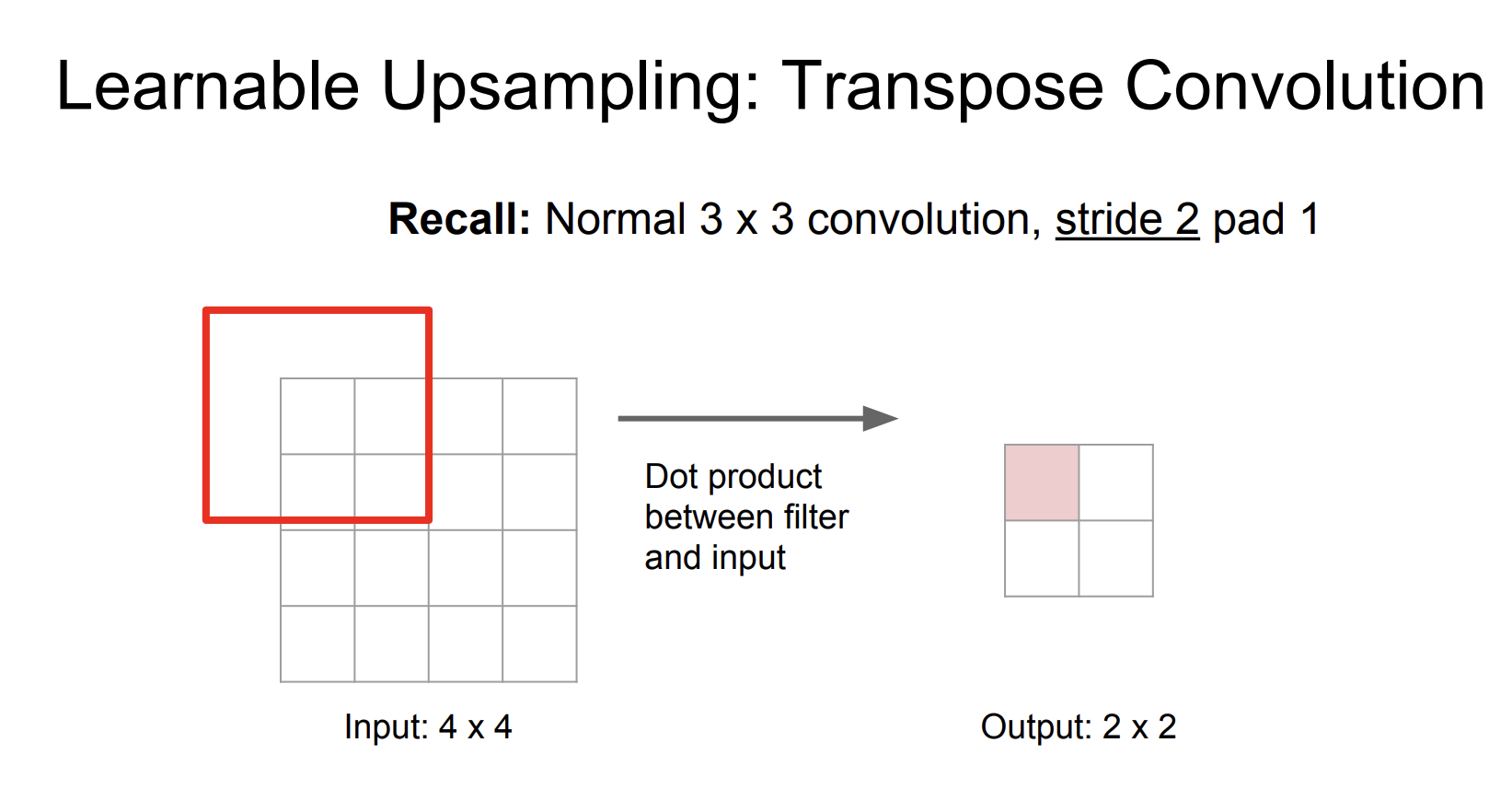
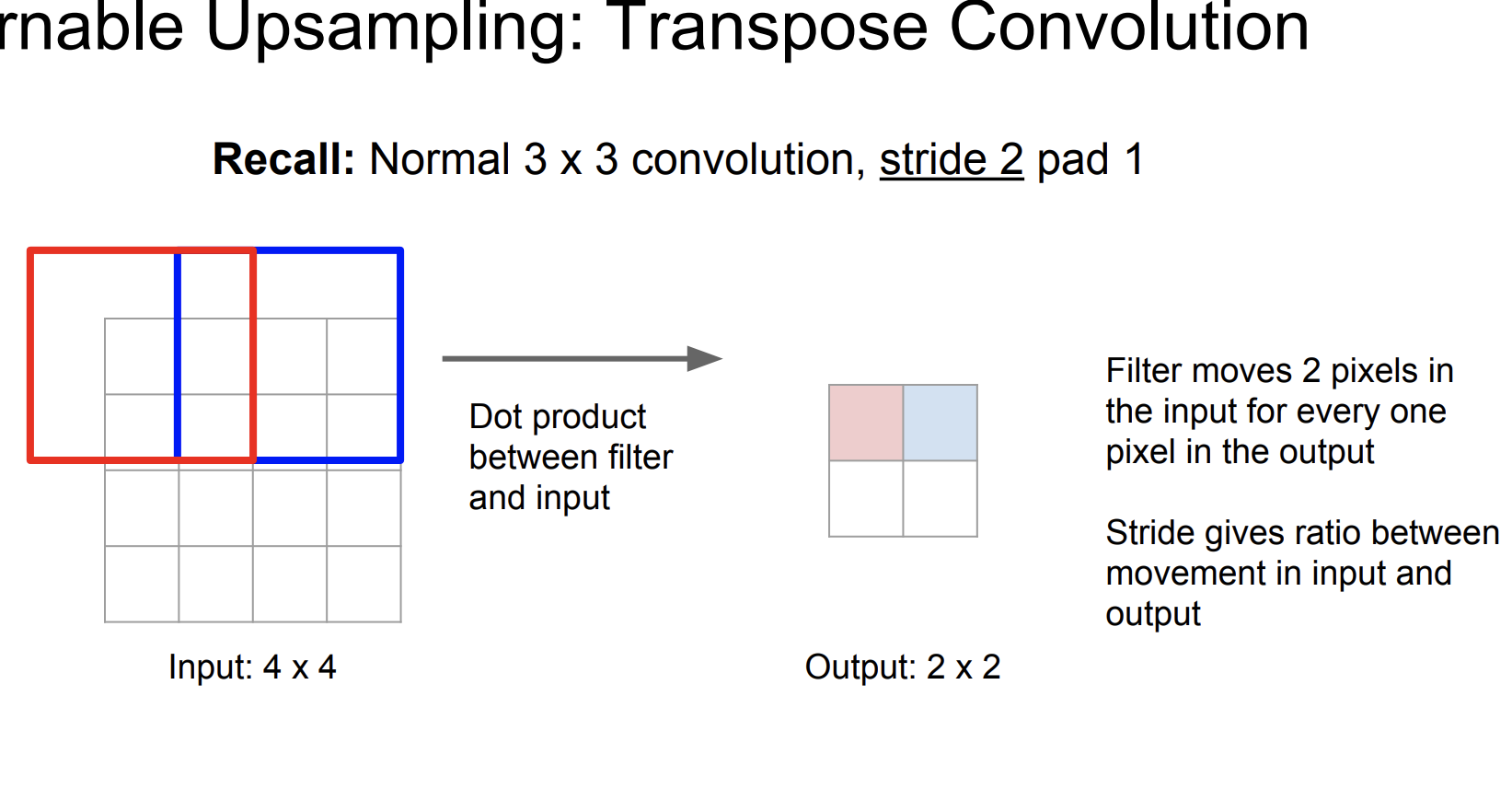
Stride를 2로 설정했더니 크기가 2배 줄어든 것을 확인할 수 있었다.
그럼 이 방법을 upsampling에 적용해보자.
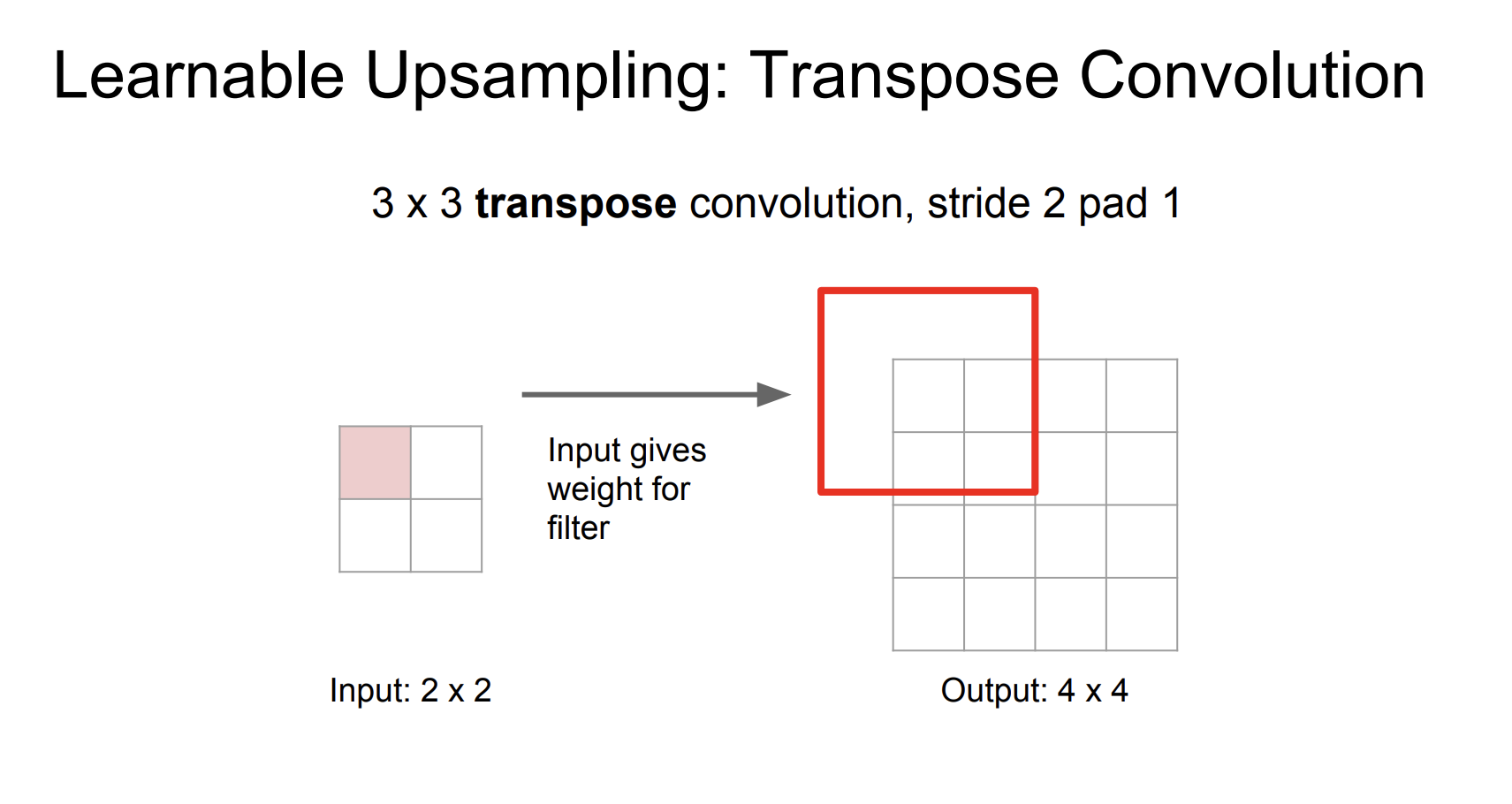
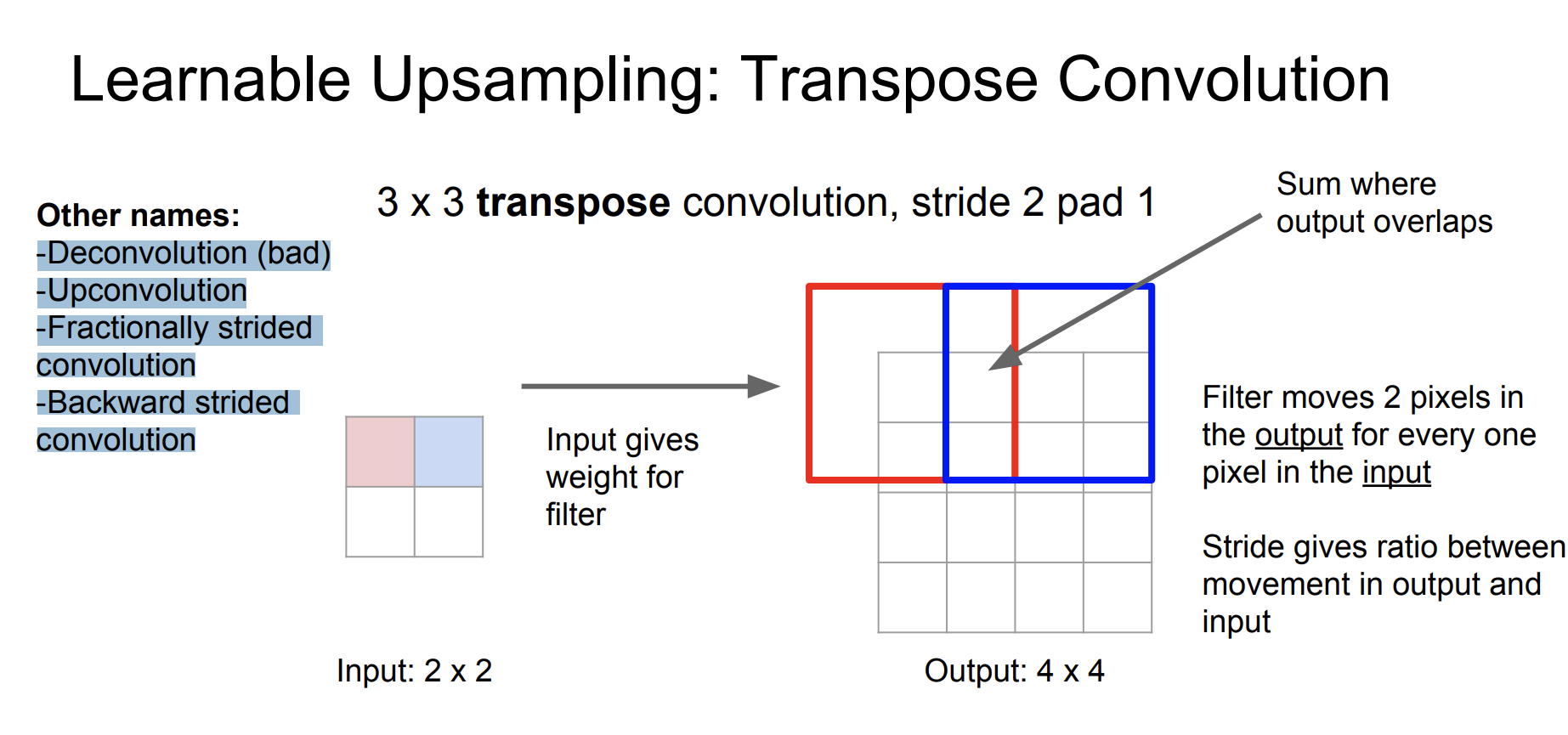
input은 필터에 대한 가중치를 제공한다. 그리고 필터는 2픽셀씩 움직인다. 만약 output이 overlap하는 경우 sum한다. stride는 input과 output의 비율을 제공한다.
여기서 stride를 2로 설정해서 input과 output의 결과가 2배 차이난다.
Transpose convolution의 다른 이름으로는
- Deconvolution (bad)
- Upconvolution
- Fractionally strided convolution
- Backward strided convolution
가 있다.
Transpose convolution을 1d example로 바꾸어 알아보자,
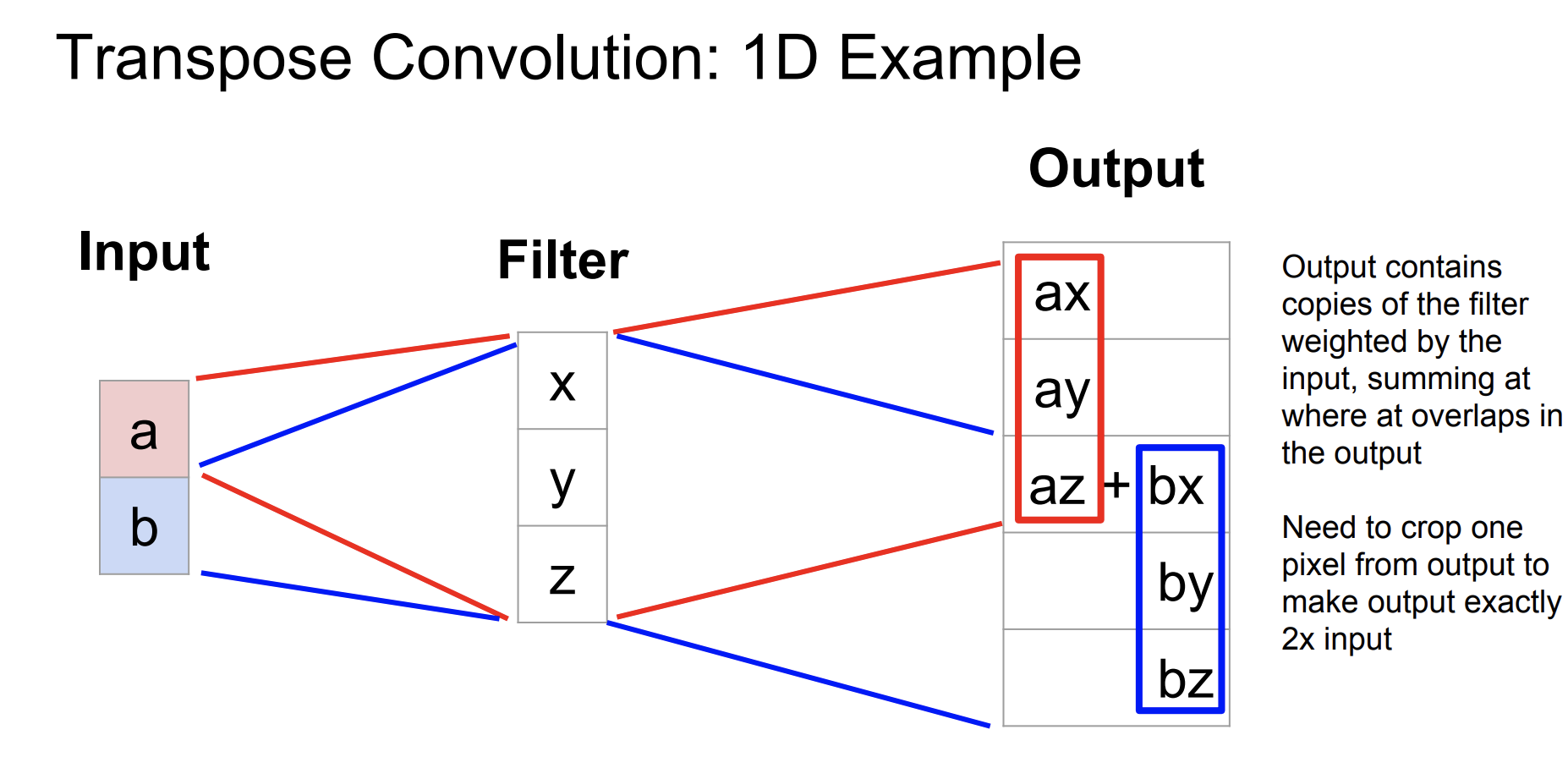
input과 filter가 곱해져서 stride가 2일때 결과를 보여준다. 정확히 input의 2배의 결과를 보여주기 위해서는 하나의 픽셀을 잘라야할 수도 있다.
그럼 왜 우리는 이러한 방법을 Transpose convolution이라고 할까?
강의자 Justin이 이 이름이 제일 적합하다고 말한다.
그 이유는, 모든 convolution은 행렬곱셈으로 나타낼 수 있는데, 예시를 한번 보자.

만약 stride=1이면 convolution transpose는 그냥 일반 convolution과 동일하다.
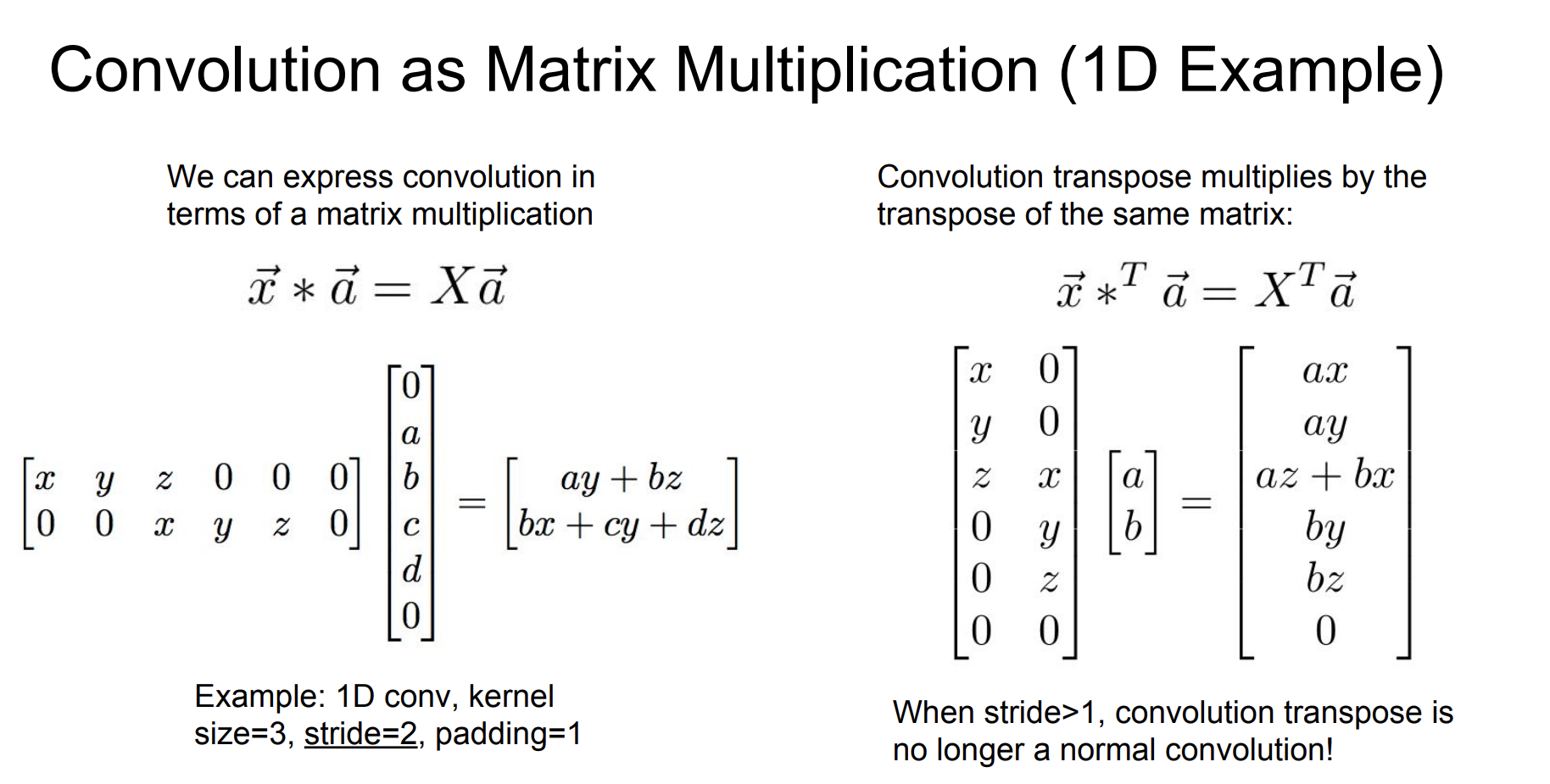
stride > 1 일때 확실히 기존 convolution과 다른 것을 확인할 수 있다.
(filter가 a,b,c,d에서 a,b로 줄어들었다.)
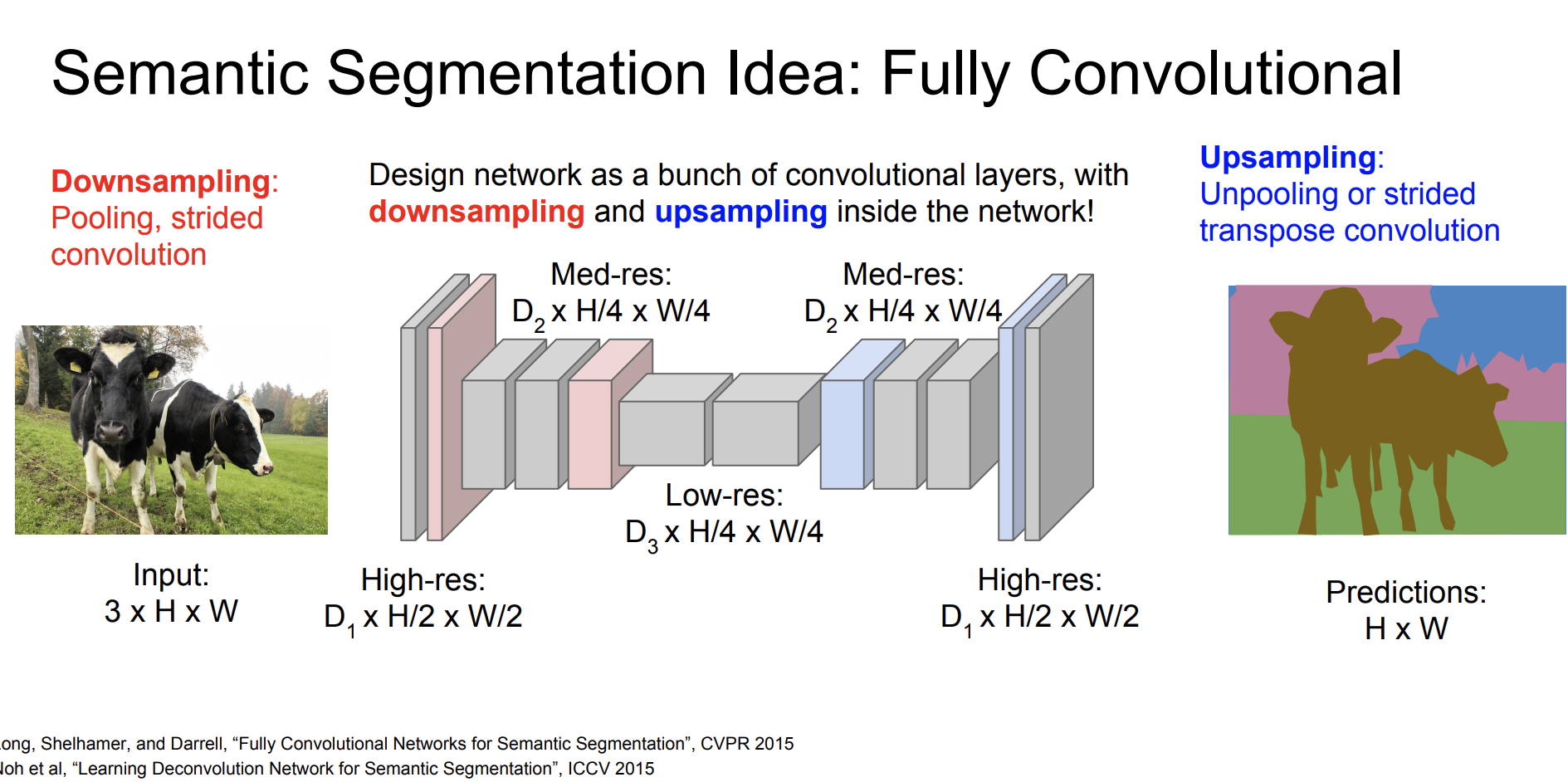
그래서 우리는 Semantic segmentation을
downsampling -> convolution -> upsampling. 을 순서로 수행할 수 있다.
Classification + Localization
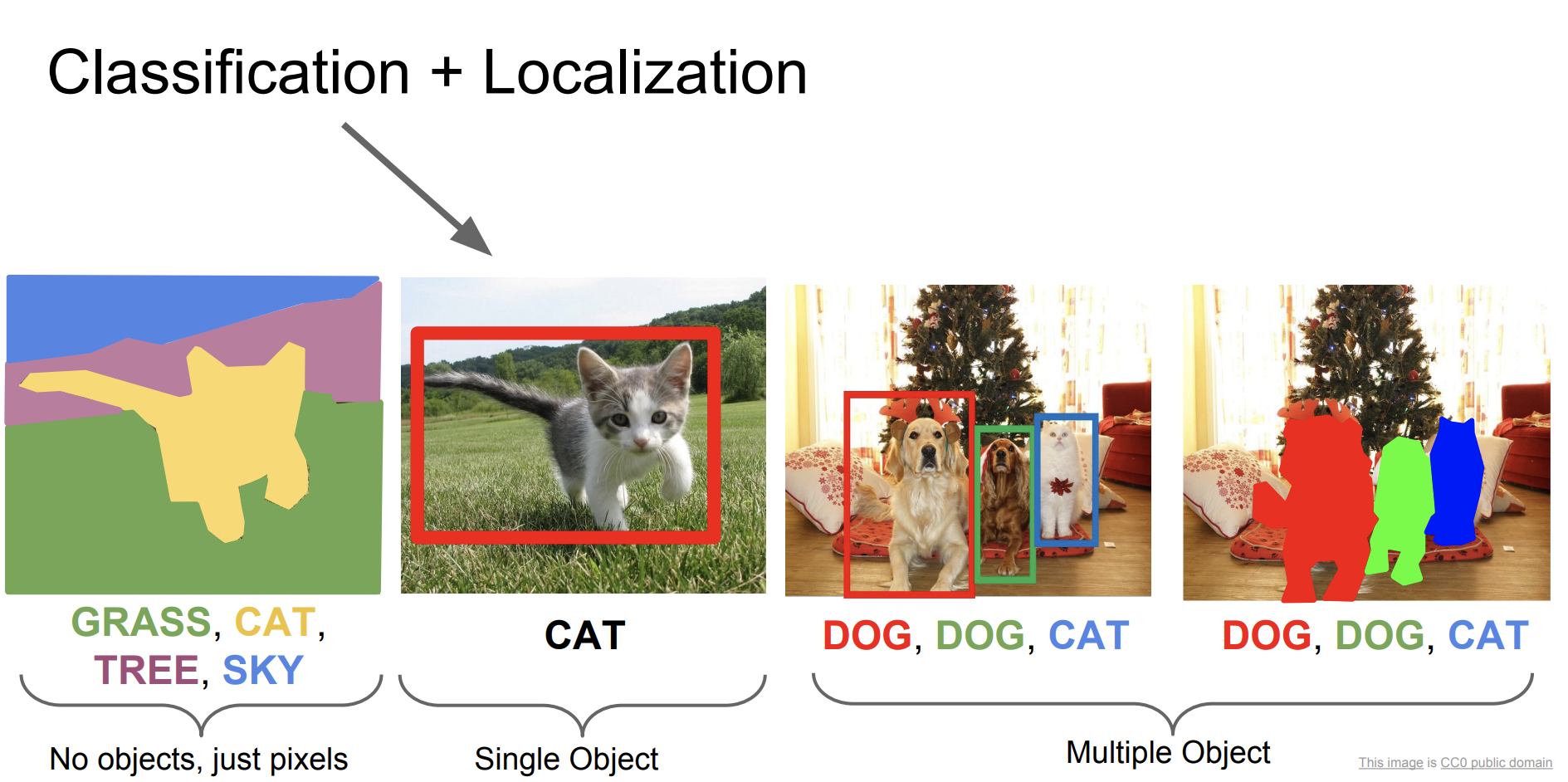
그럼 이 귀여운 고양이 object를 좀 더 자세히 설명하는 task에 대해서 알아보자!
기존의 task는 이 귀여운 고양이 사진을 가지고 cat이라고 분류하는 문제였다.
동시에 우리는 해당 cat이 어디에 위치하는지를 알아보는 task를 수행할 것이다.
이를 Multitask Loss라고 하는데 하나의 수행에서 두개의 loss function을 수행하는 것이다.
Multitask loss 의 기본 원리는 모델은 여러개의 작업을 동시에 수행하고, 각 작업에 대한 손실을 계산한다. 그리고 이러한 각각의 손실들은 최종적으로 하나의 손실값으로 결합된다.
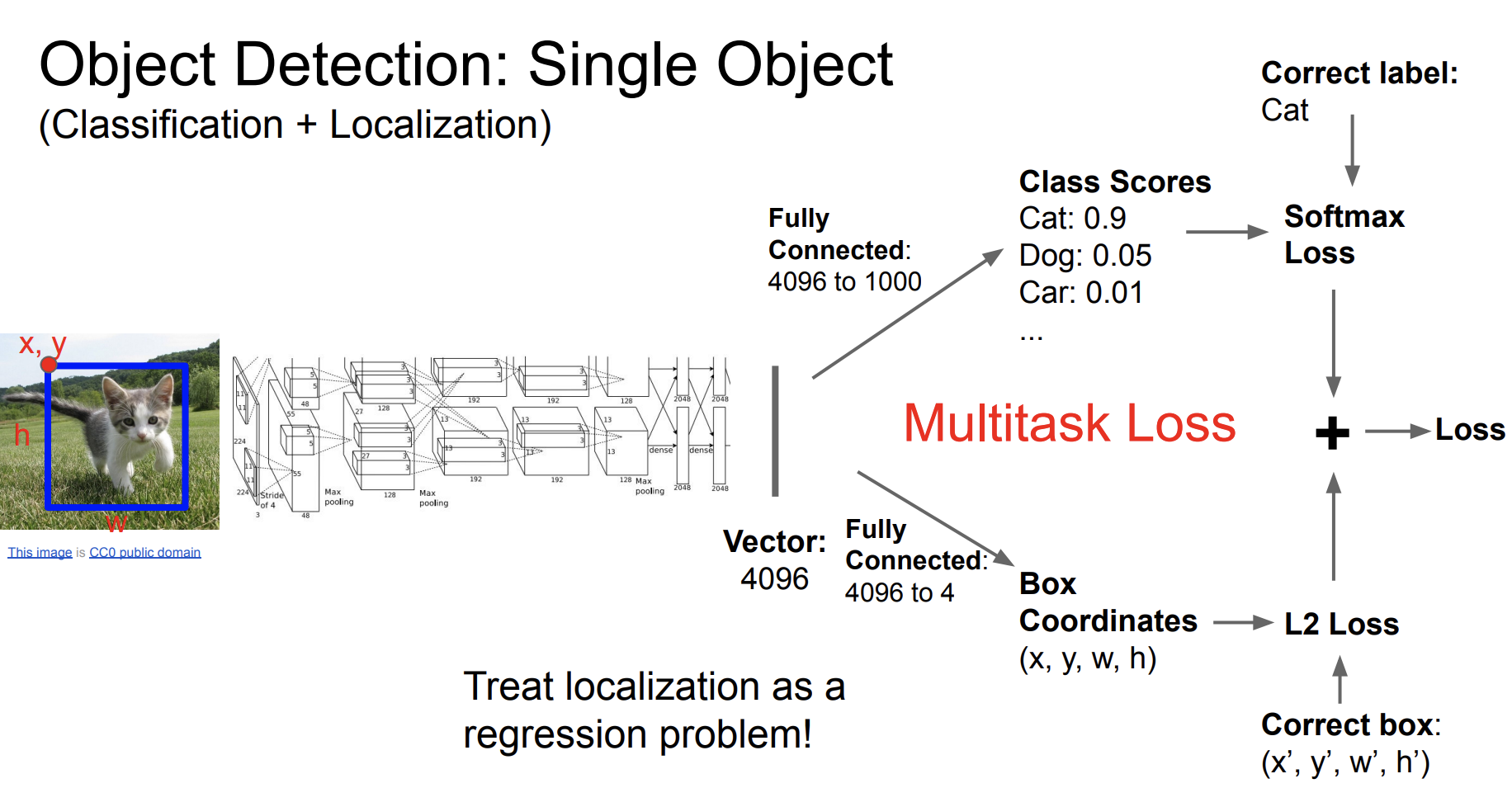
구성
- 각 작업에 대해 별도의 손실함수를 사용한다. 분류작업에는 크로스 엔트로피 손실, 회귀 작업에는 평균 제곱 오차 손실 등이 사용된다.
- 이러한 손실들을 결합한다. 손실에 대한 가중합을 계산하는 방법이 가장 일반적이다.
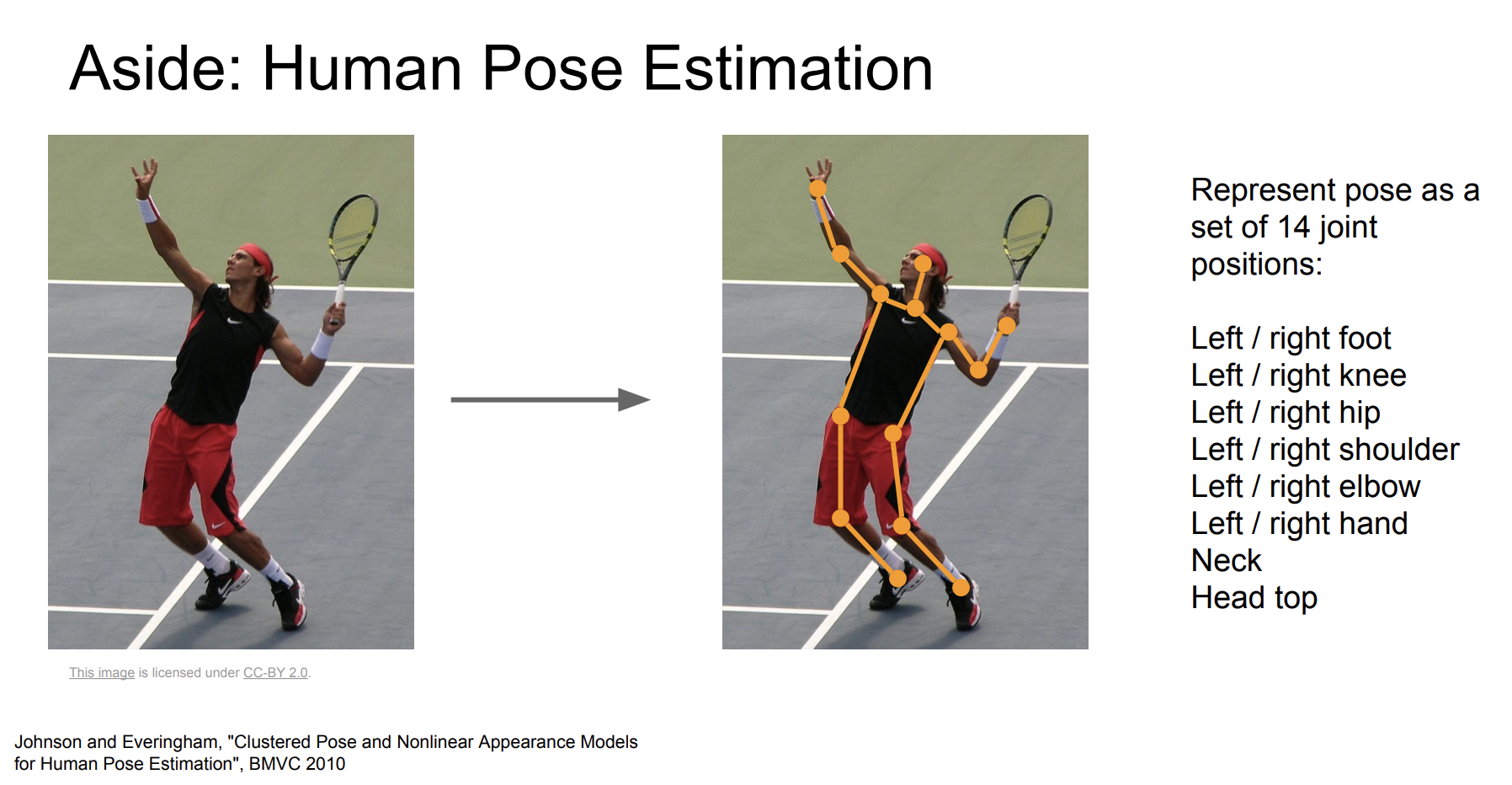
이런 Mutitask learning을 활용해서 인간의 자세를 추정할 수도 있다.
인간의 관절을 14개로 분류하여 자세를 추정할 수 있다.
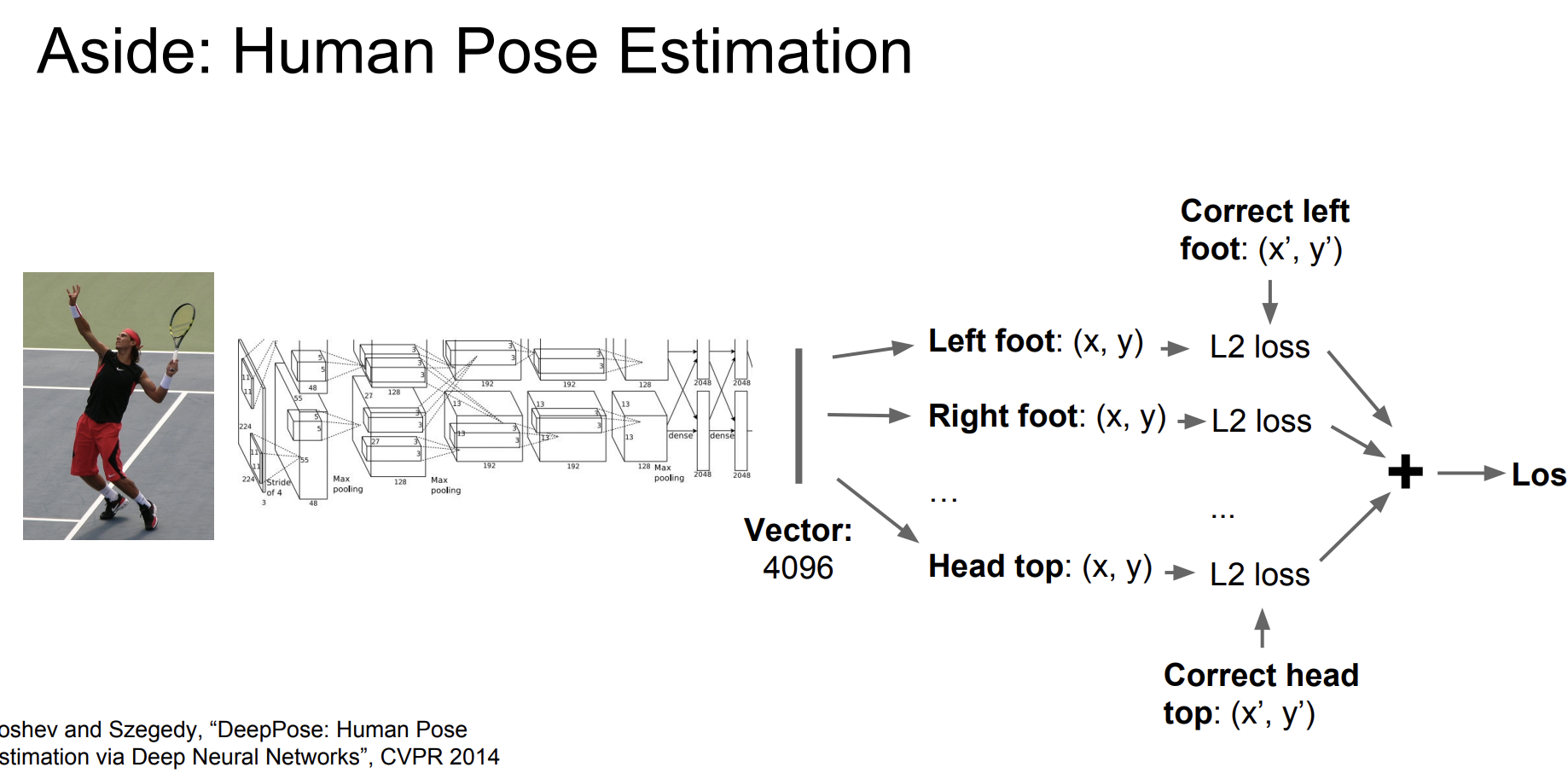
사진의 왼쪽 발, 오른쪽 발 , ... , 머리 등등으로 나누어 위치를 찾는다.
실제 발의 위치와 손실 값을 계산한 다음 모든 손실 값을 더해 최종 손실값을 구한다. 이런 학습 방법의 딥러닝으로 인간 자세를 추정할 수 있다.
Object Detection
그리고 중요한! Object detection(물체 탐지)에 대해 알아보자!
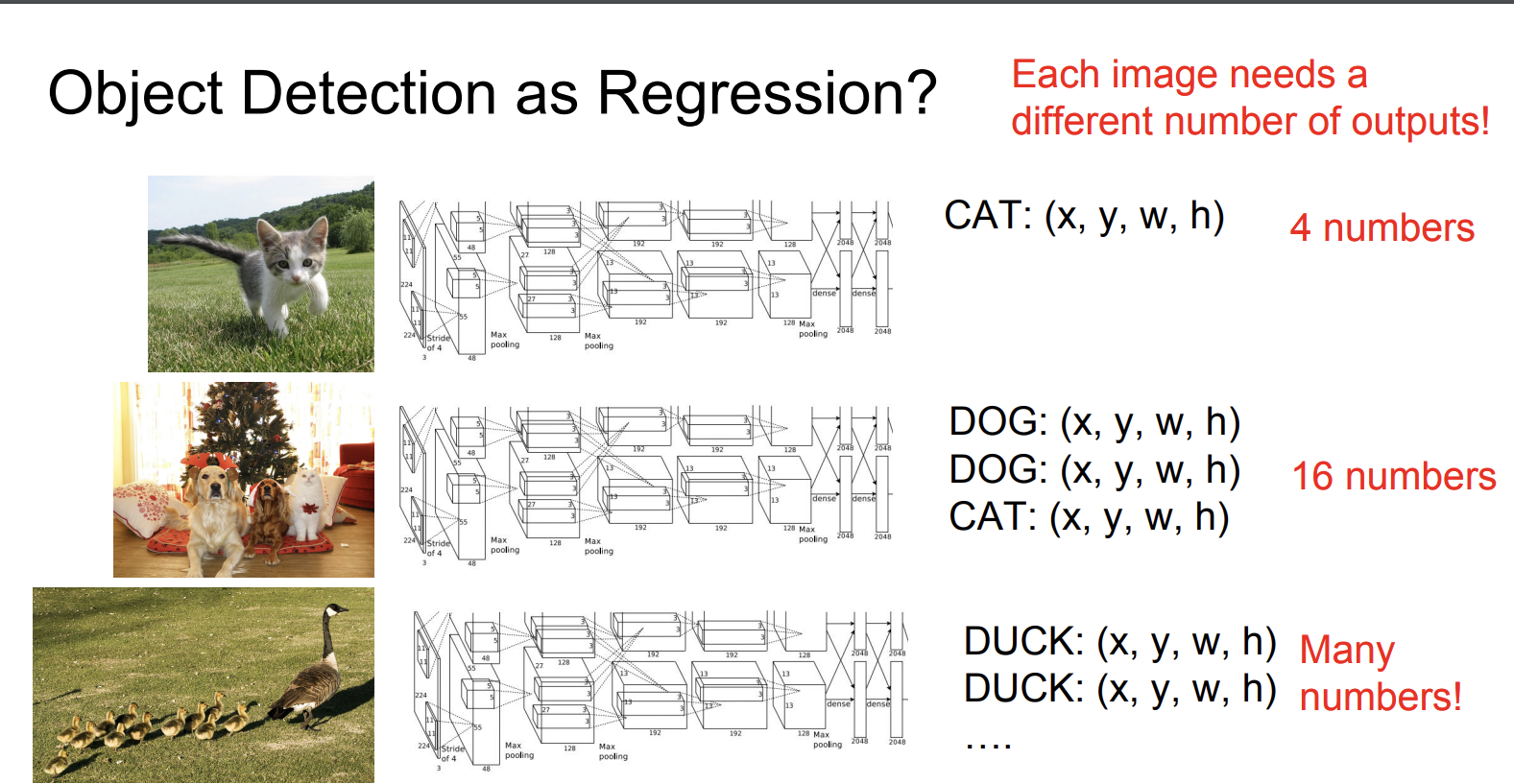
우리는 사진을 보고 이 사진에 해당 하는 물체가 카테고리에 있다면 그 물체에 대해 네모 박스를 쳐야한다.
사진안에 물체가 얼마나 많이 있을지 모르기 때문에 회귀문제로 푸는 것에는 한계가 있다.



이전에 알아본 sliding window방법으로 해결할 수 있지만, 이 방법은 매우 많은 장소를 탐색해야하고, 따라서 계산하기 매우 비싸다!
그래서 사진에 대한 지역적 접근을 해보자.
사진에 물체를 포함할 가능성이 높은 지역을 찾는 것이다.
상대적으로 매우 빠르게 실행된다고 한다. Selective Search는 cpu에서 몇초만에 2000개의 region을 제공한다고 한다.
Selective Search에 간단하게 살펴보면,
- 세분화 : 먼저 이미지를 여러 작은 영역으로 세분화한다.
- 영역 결합 : 세분화된 영역들을 점차적으로 합쳐나간다. 유사한 영역들이 하나의 더 큰 영역으로 결합된다.
- RoI(Regions of Interest)생성 : 다양한 크기와 모양을 가진 잠재적인 관심 영역이 생성
생성된 RoI를 바탕으로 R-CNN이라는 객체 탐지 기법에 대해 알아보자.
R-CNN
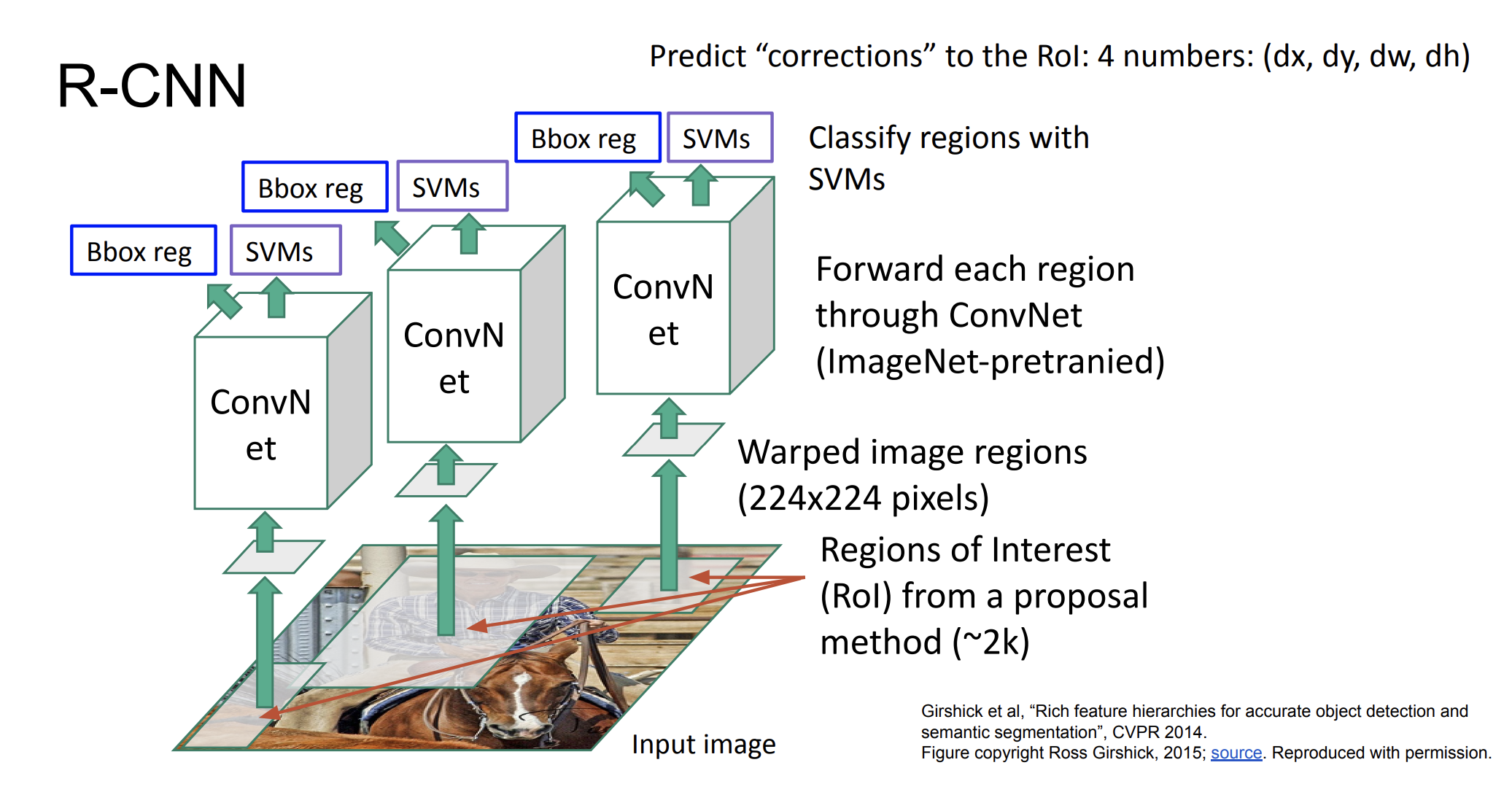
먼저 input image가 있다면, RoI를 생성한다. 여러 이미지들이 있을텐데, 이미지들은 각각 크기가 다를 것이다. convolution의 input은 이미지들의 크기가 일정해야하기 때문에 이미지의 영역을 고정시킨다(Warped image regions)
그 다음 해당 이미지들을 이미 사전 학습된 ConvNet에 넣는다. 그리고 SVMs를 실행한다.
결과적으로 각각의 이미지들이 어떤 것인지 예측한다.
하지만 이 방법은 문제가 있다.
최대 2000개의 이미지가 있는데, 이 이미지들에 대해서 각각 모두 forward pass를 해야하기 때문에 너무 느리다는 단점이 있다.
RoI가 객체를 탐지 못할 수도 있다.
모든 RoI이미지를 저장하기 위해서 수천개의 디스크가 필요할 수 있다.
좀 더 빠르게 수행하기 위해서 고정된 크기의 이미지로 자르는 동작을 빼고 그냥 RoI를 바로 ConvNet에 넣을 수 있다.
하지만 이미지당 30초씩 걸리는 문제로 너무 느리기 때문에 R-CNN을 좀 더 빠르게 수행하는 방법을 탐색했다.
Fast R-CNN
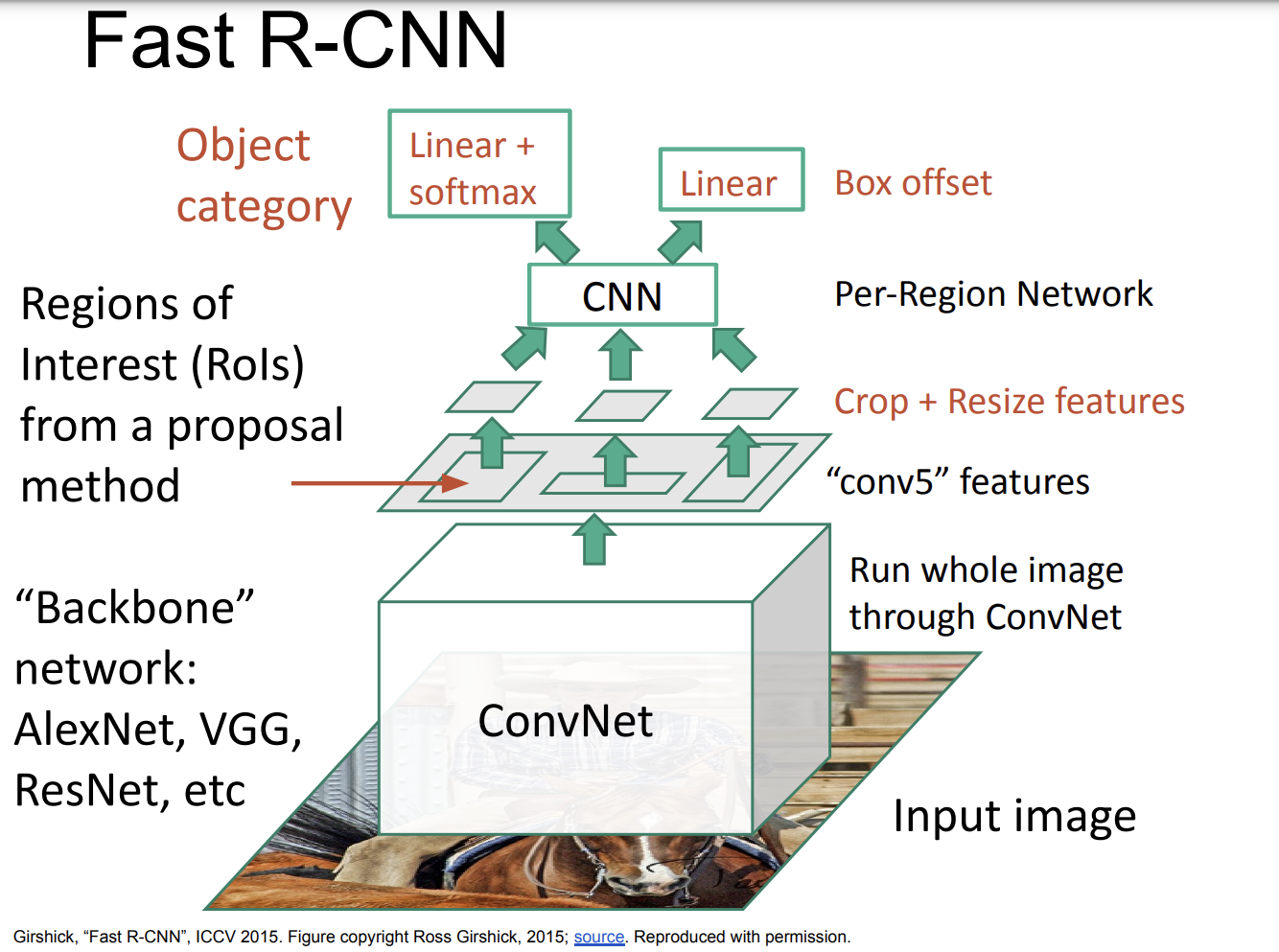
- 기존에는 RoI들을 전처리 단계에서 먼저 탐색했다면, 이번에는 전체 이미지를 ConvNet 레이어를 통해 한번에 실행하여 feature map을 추출한다.
- RoI Pooling: 추출된 특징 맵에서 관심영역을 식별한 후, RoI를 고정된 크기의 특징 벡터로 변환한다. 이 과정을 RoI 풀링이라 하고, 다양한 크기의 RoI를 동일한 길이의 특징 벡터로 변환한다.
- 분류 및 바운딩 박스 : RoI 풀링을 통해 얻은 특징 벡터는 두개의 fully connected layers를 통과한다. 하나는 객체의 클래스를 분류하는데 사용되고, 다른 하나는 바운딩 박스(객체의 위치와 크기를 정의하는 사각형)의 좌표를 조정하는데 사용된다.
그럼 RoI Pooling에 대해서 좀 더 자세히 살펴보자!
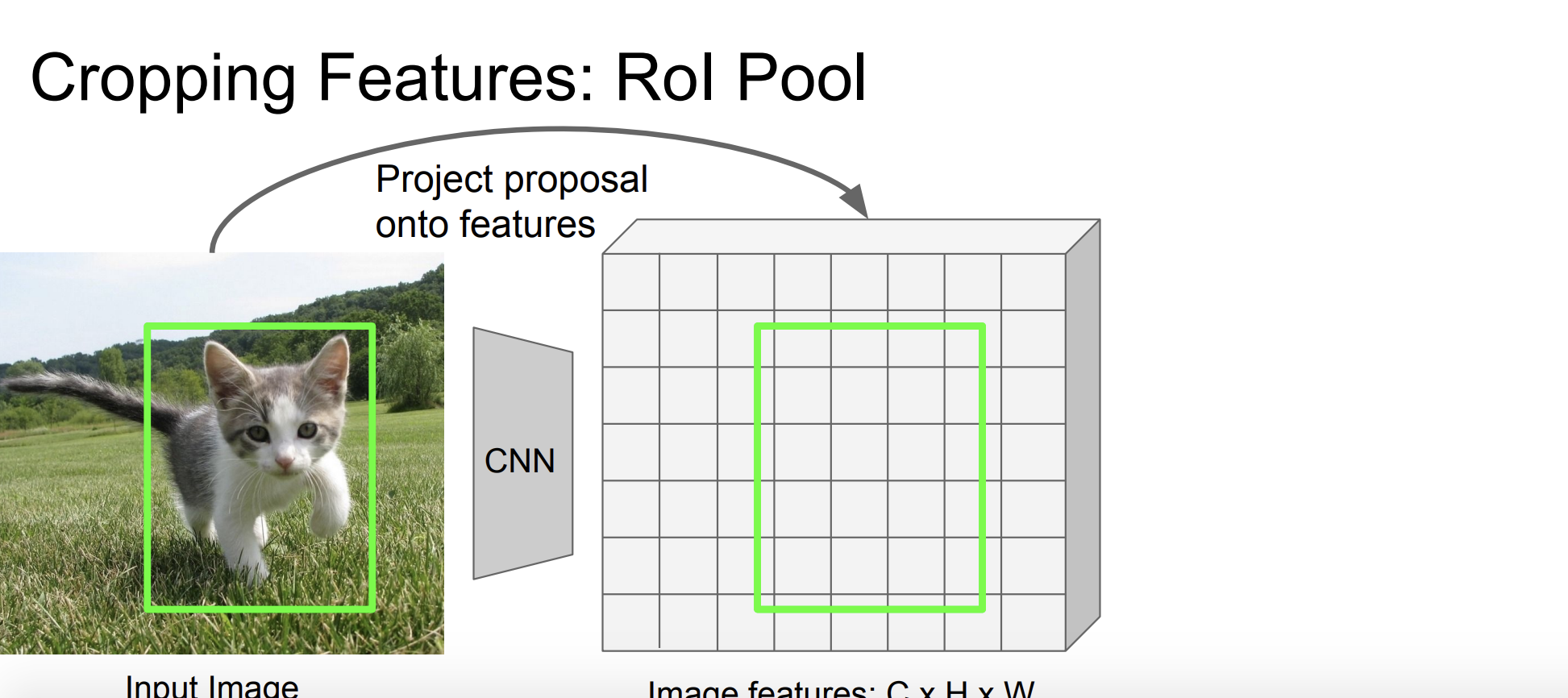
CNN을 통해 전체 이미지의 특징 맵(feature map)을 추출한다.
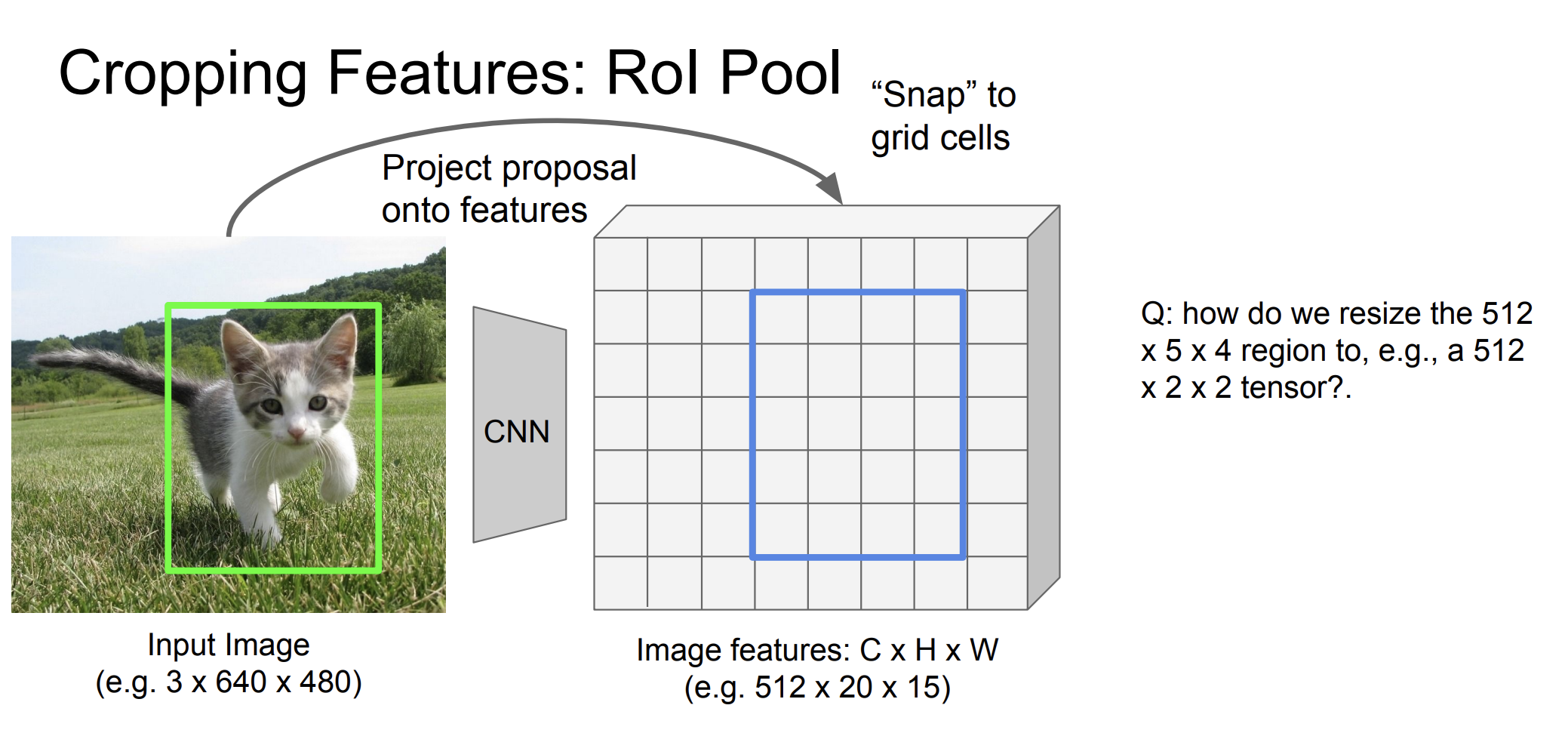
그리고 Grid cell로 snap시킨다.
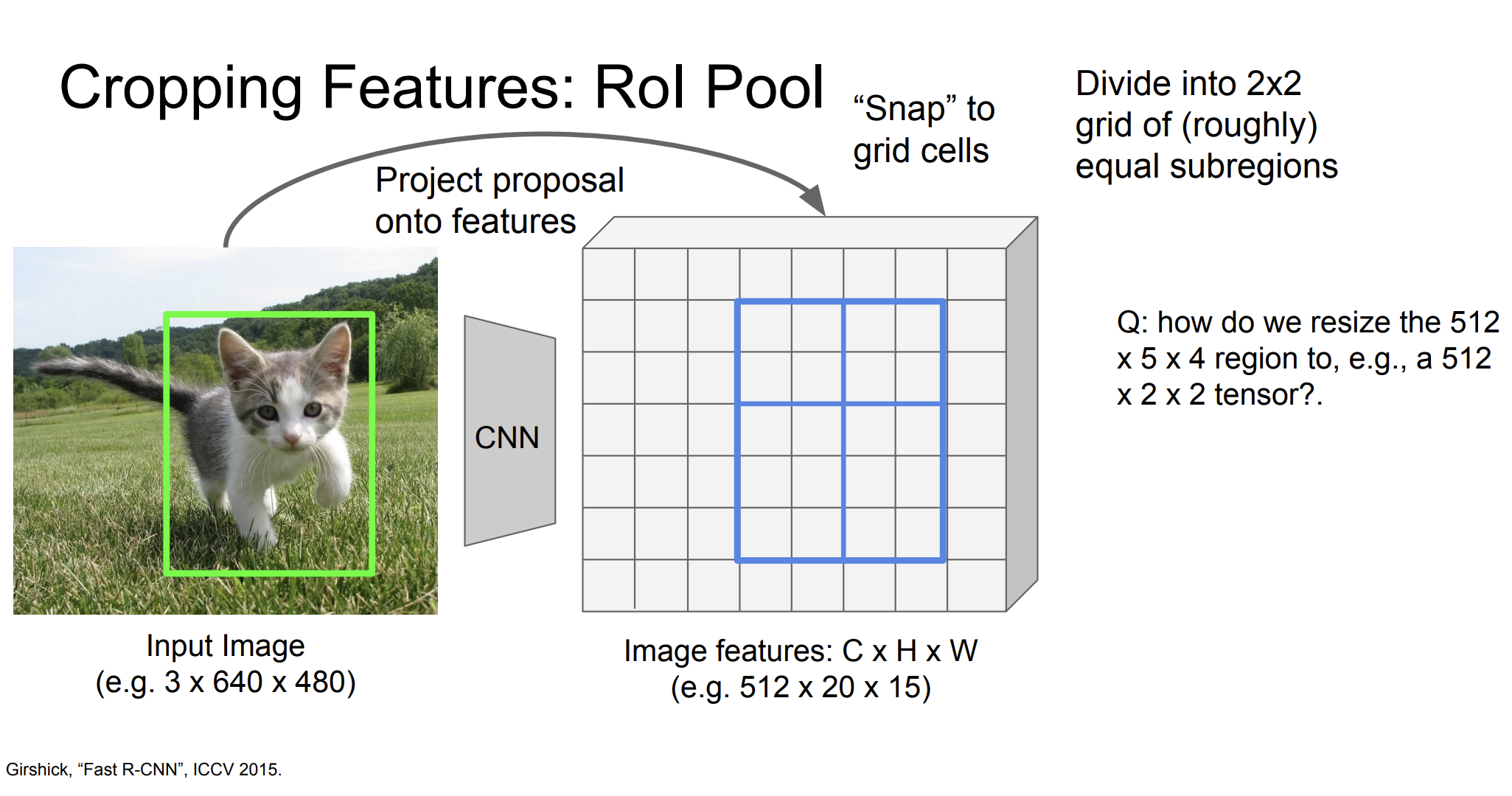
크기를 조정해야한다. 512x5x4를 어떻게 512x2x2로 바꿀 수 있을까? roughly하게 2x2로 나누면 된다.
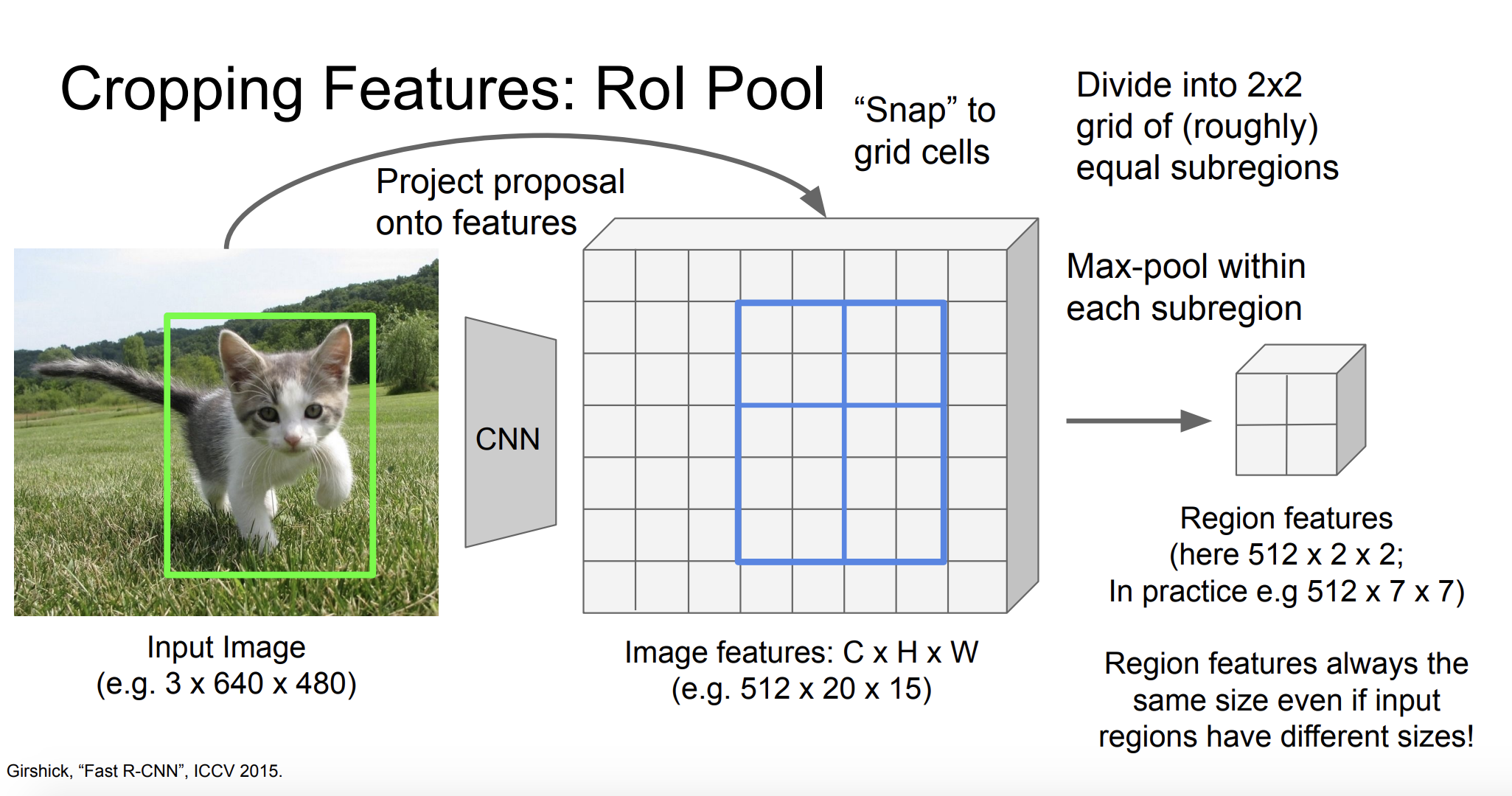
그 다음 각각의 영역에 대해 max-pooling을 수행한다.
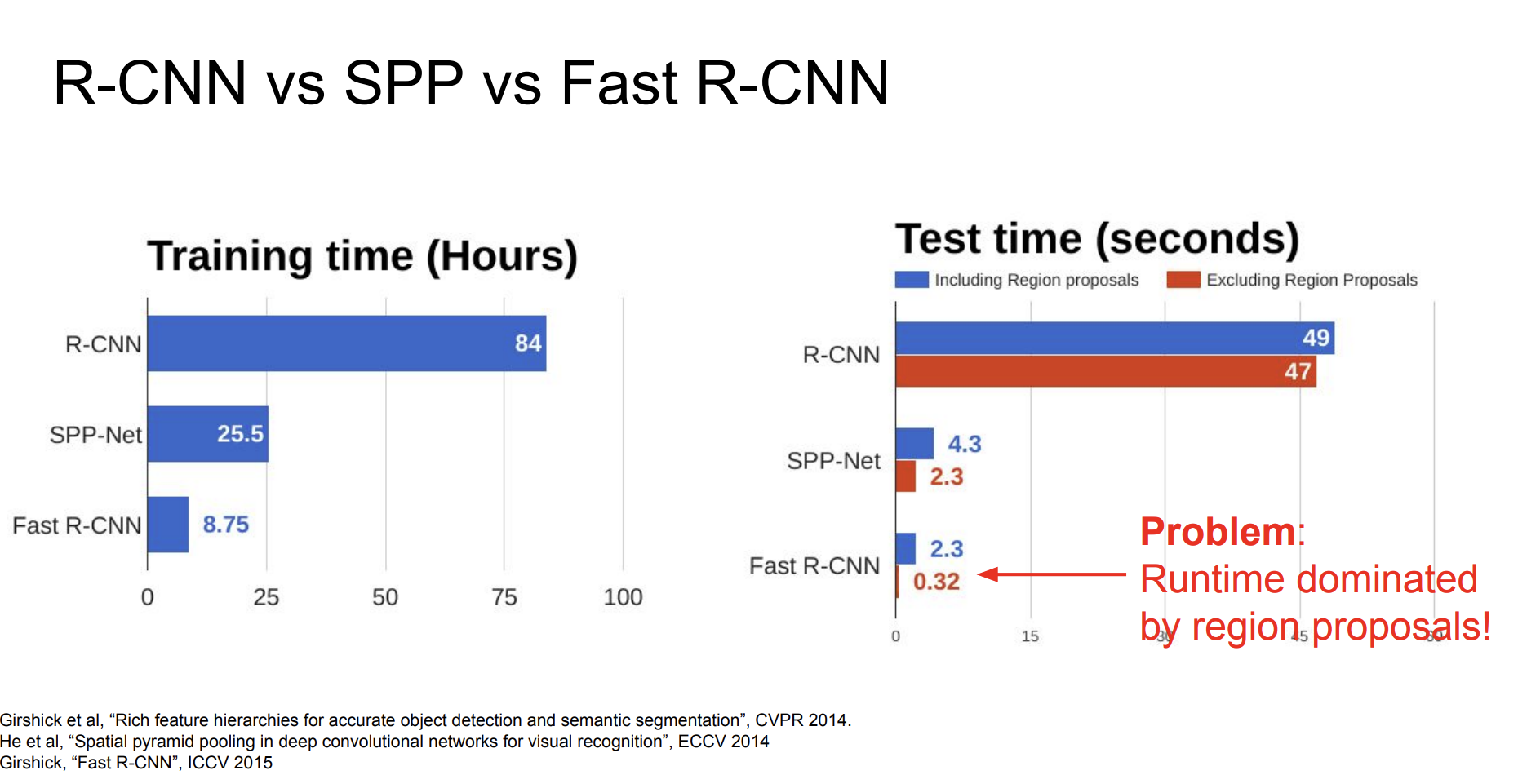
그래서 기존 R-CNN과 Fast R-CNN을 비교해봤는데, 압도적으로 Fast R-CNN이 빠른 것을 확인할 수 있다. 하지만 문제점은 객제 후보 영역(proposals)을 식별하기 위해 별도의 알고리즘에 의존을 하게 되는 점이었다.
Faster R-CNN
그래서 그 이후에 나온 Faster R-CNN은 객체 후보 영역을 신경망 내부에서 직접 생성했다. 이를 위해서 Region Proposal Network(RPN)이 도입되었다.
최종 4가지 loss function을 수행한다.
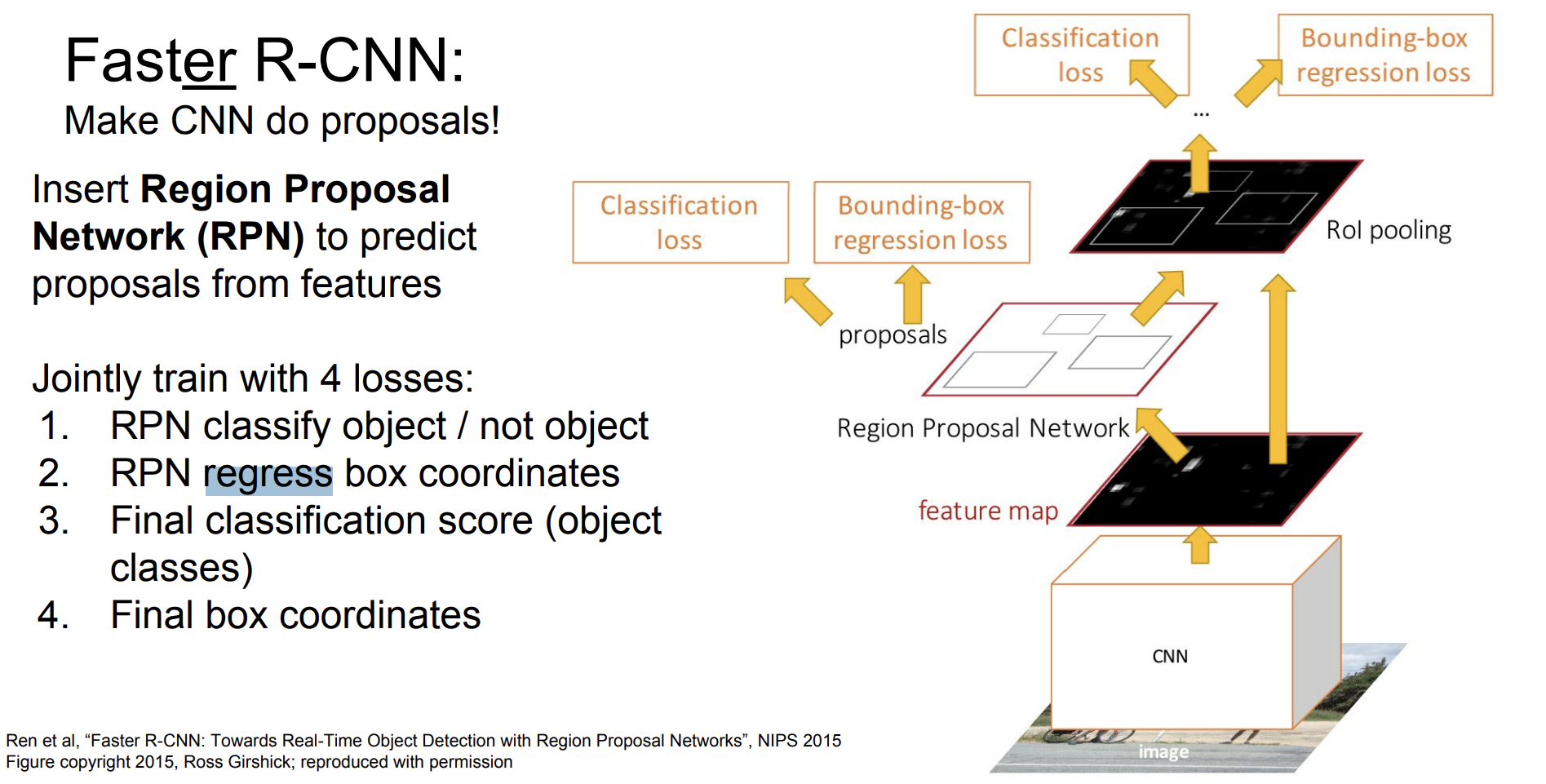
- RPN classify object / not object
- RPN regress box coordinates(
- Final classification score (object
classes) - Final box coordinates
Faster R-CNN의 작동과정은 다음과 같다.
- feature 추출 : 이미지를 입력으로 받아 CNN을 총과해서 feature map을 추출한다.
- RPN을 통해서 후보 영역 제안: 추출된 feature map에서 객체가 있을 영역들을 식별(classify)한 다음 bounding box를 예측한다.
- RoI pooling: RPN에서 제안된 영역들을 RoI pooling을 총해 고정된 크기의 특징 벡터로 변환된다.
- 객체 분류, bounding box : 특징 벡터는 객체의 class를 분류하고 bounding bos의 좌표를 정확하게 조정한다.
RPN
여기서 RPN은 이미지 내에서 객체 후보 영역을 빠르게 제안하는 역할을 한다. Feature map에서 슬라이딩 윈도우 방식을 사용해서 각 위치에서 객체가 있을 가능성과 함께 바운딩 박스의 좌표를 예측한다고 한다.
좀 더 자세히 예시를 들어 설명해보자.
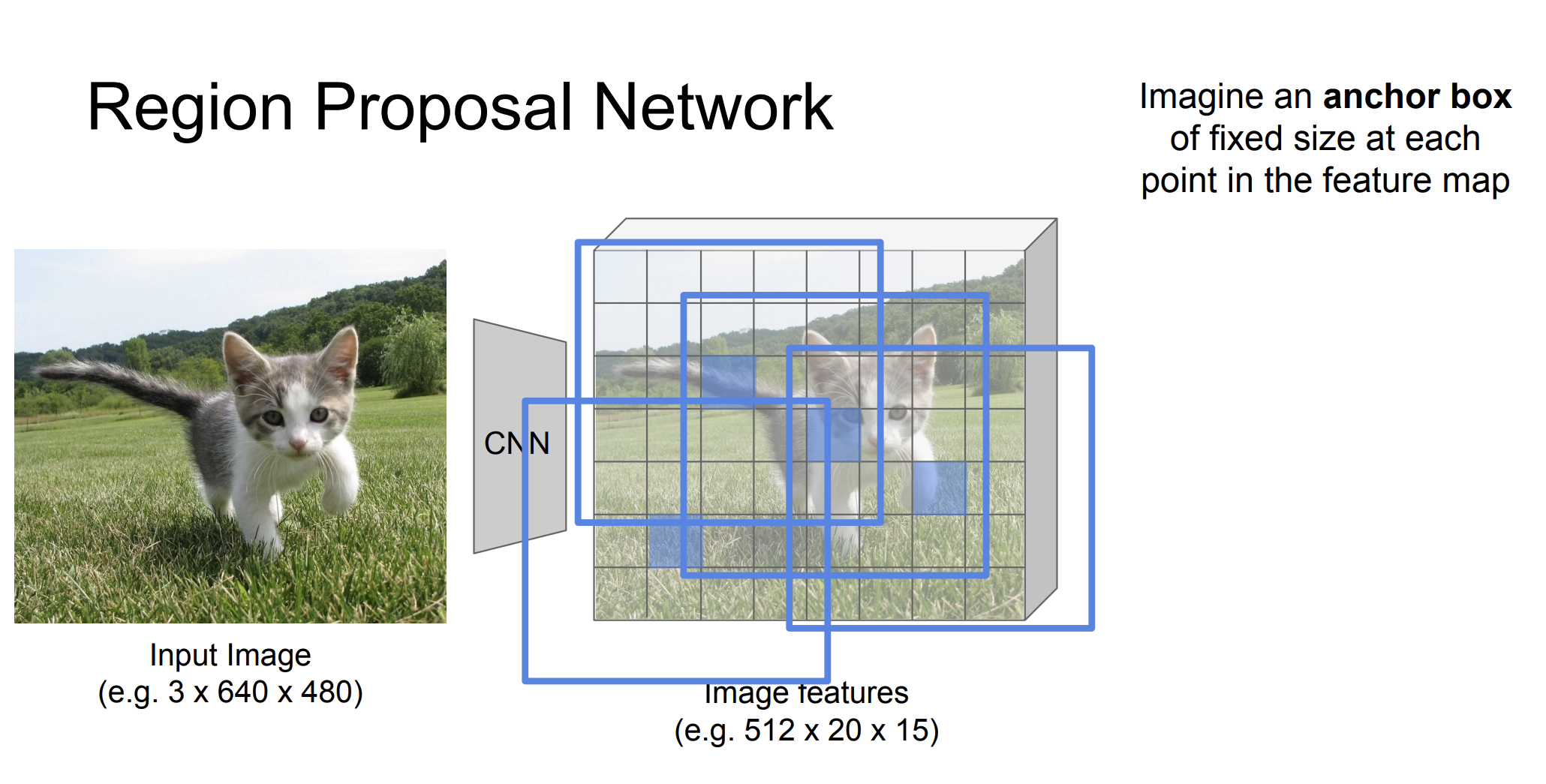
Feature map에 대해서 여러 고정된 크기의 anchor box를 본다.
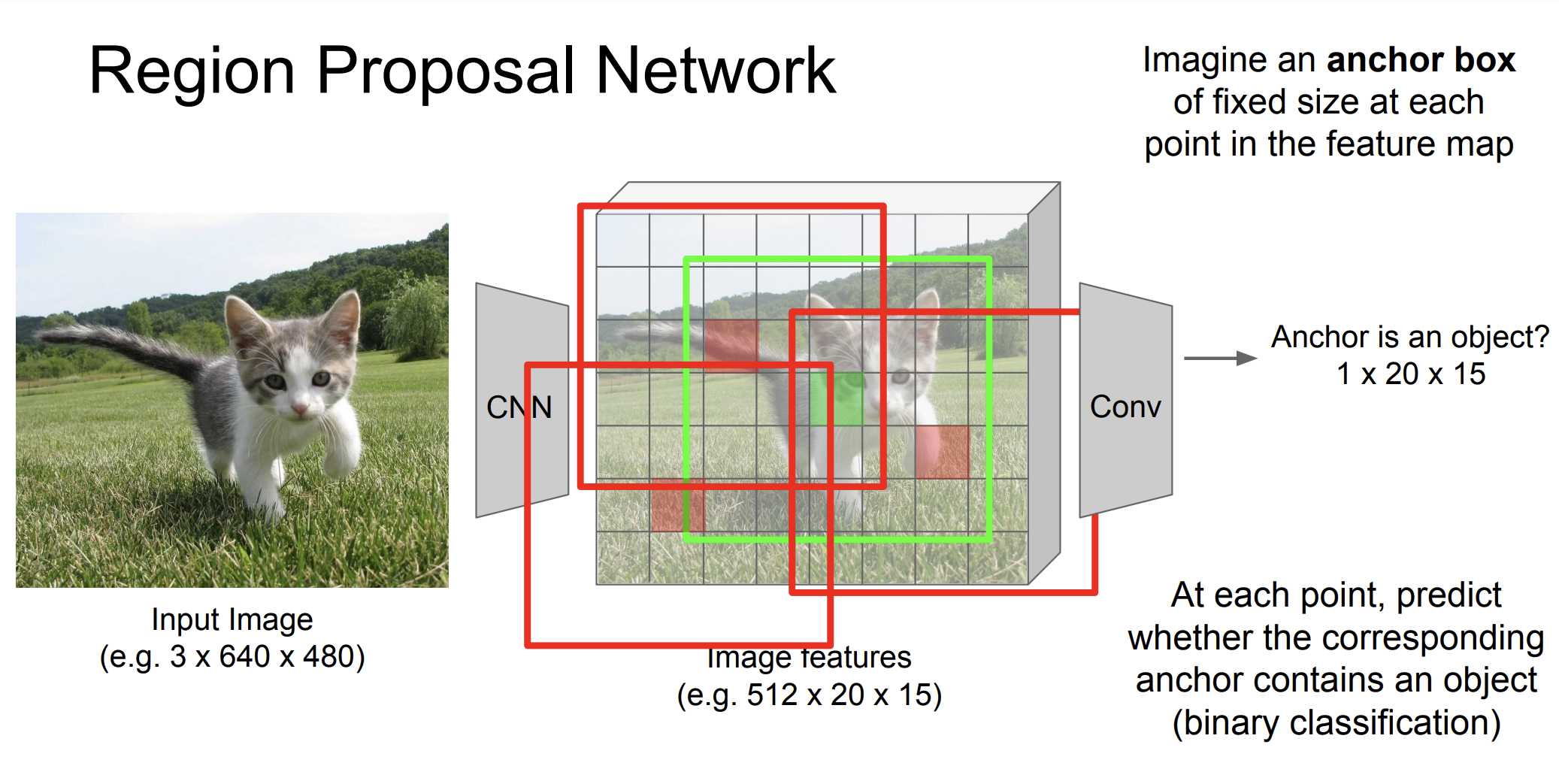
그 다음 anchor가 객체인가? 확인한다. 이때는 이진 분류를 통해 구분한다.
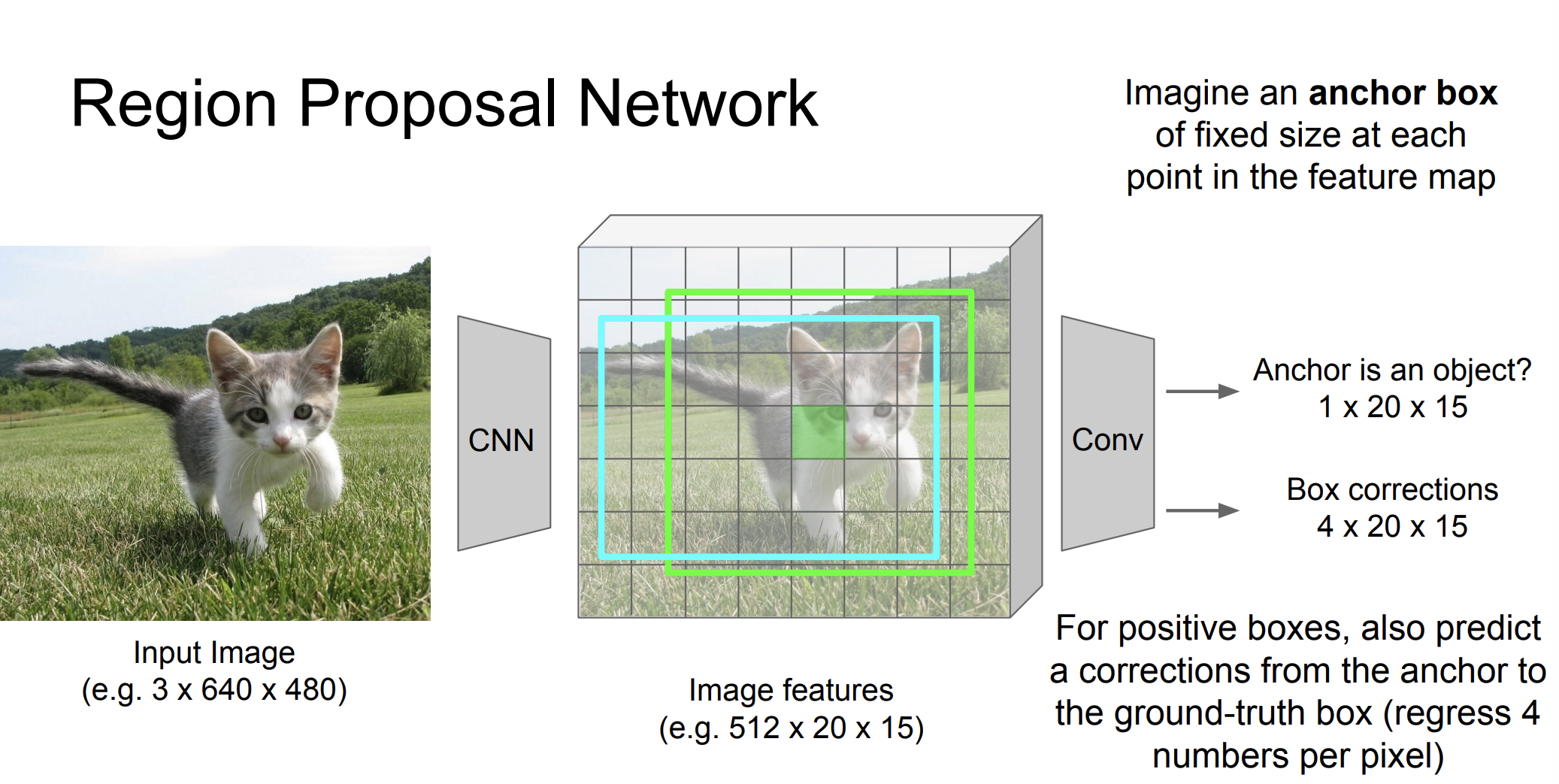
그 다음에는 Box 를 알맞게 설정한다. 왼쪽 위, 왼쪽 아래, 오른쪽 위, 오른쪽 아래 즉 4개의 숫자가 ground-truth box를 위해서 필요하다.
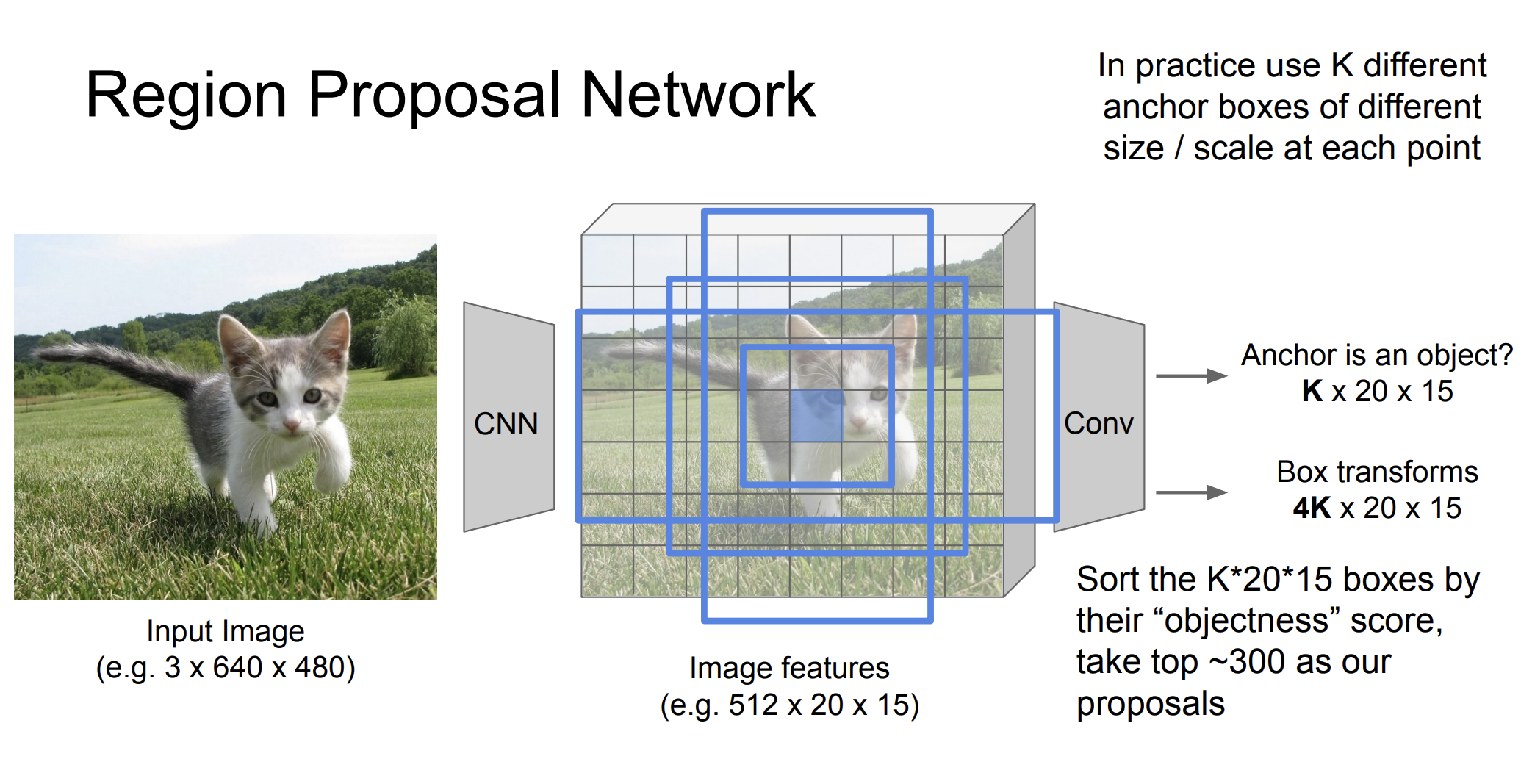
실제로는 여러 다른 k숫자들의 anchor box를 사용한다고 한다. 그리고 "objectness"점수를 통해서 정렬을 한다고 한다.
Results
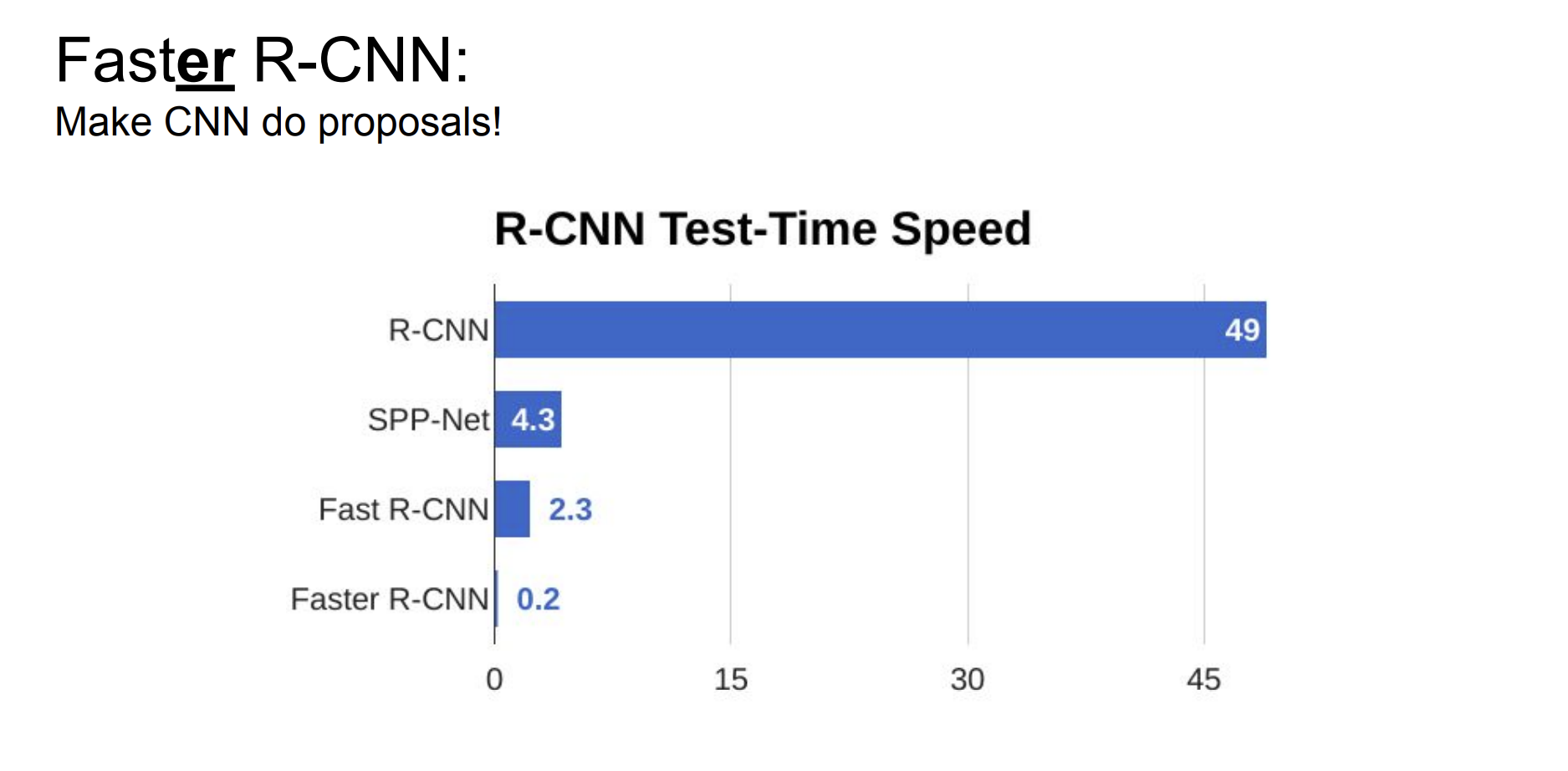
그리고 결과는 더욱 좋았다고 한다.
Faster R-CNN은 두가지 과정으로 객체를 탐지한다.
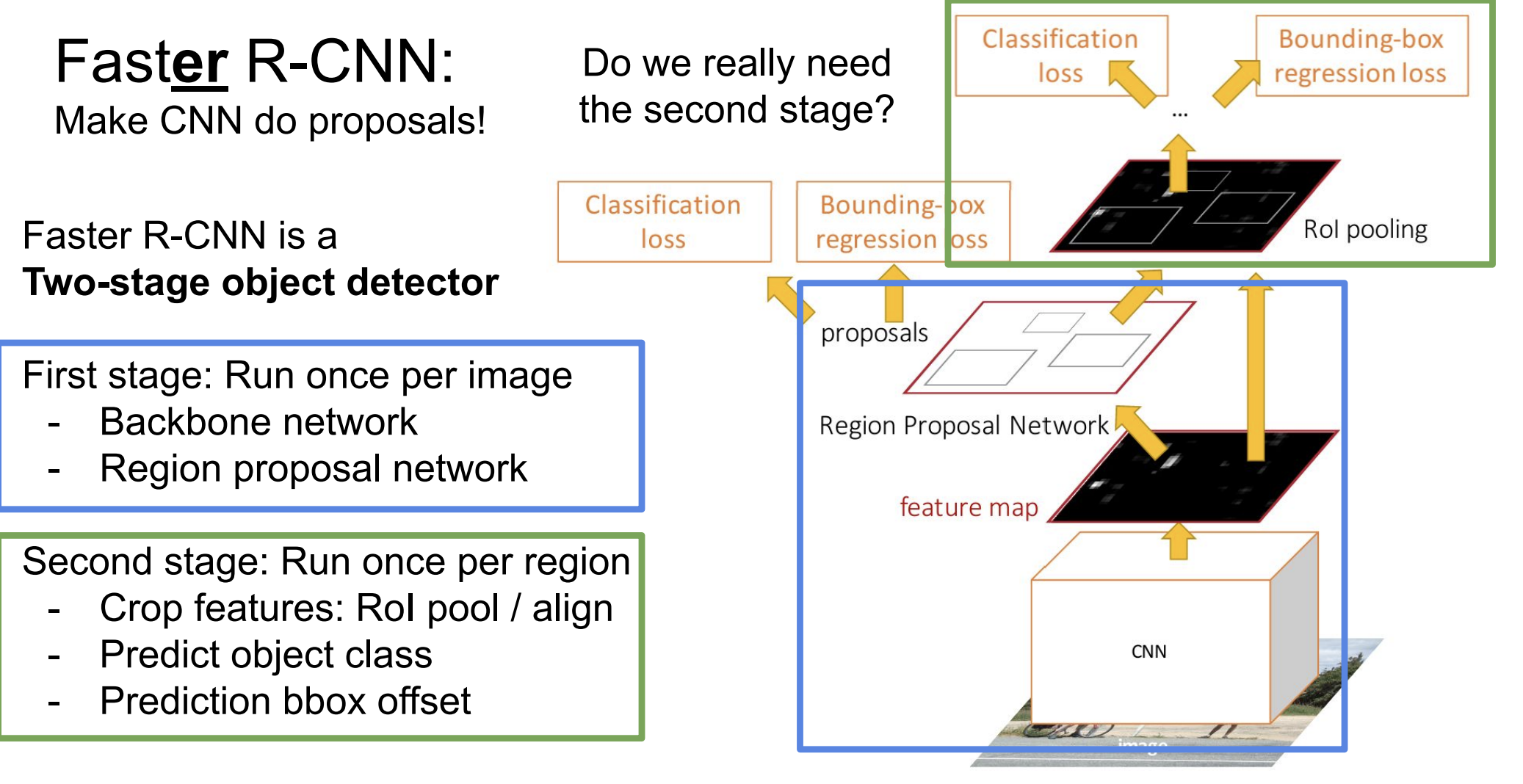
두번째 과정이 꼭 필요할까?
YOLO
YOLO는 you only look once의 줄임말로, 이미지 전체를 단 한번만 보고 여러 객체를 탐지하고 분류한다.
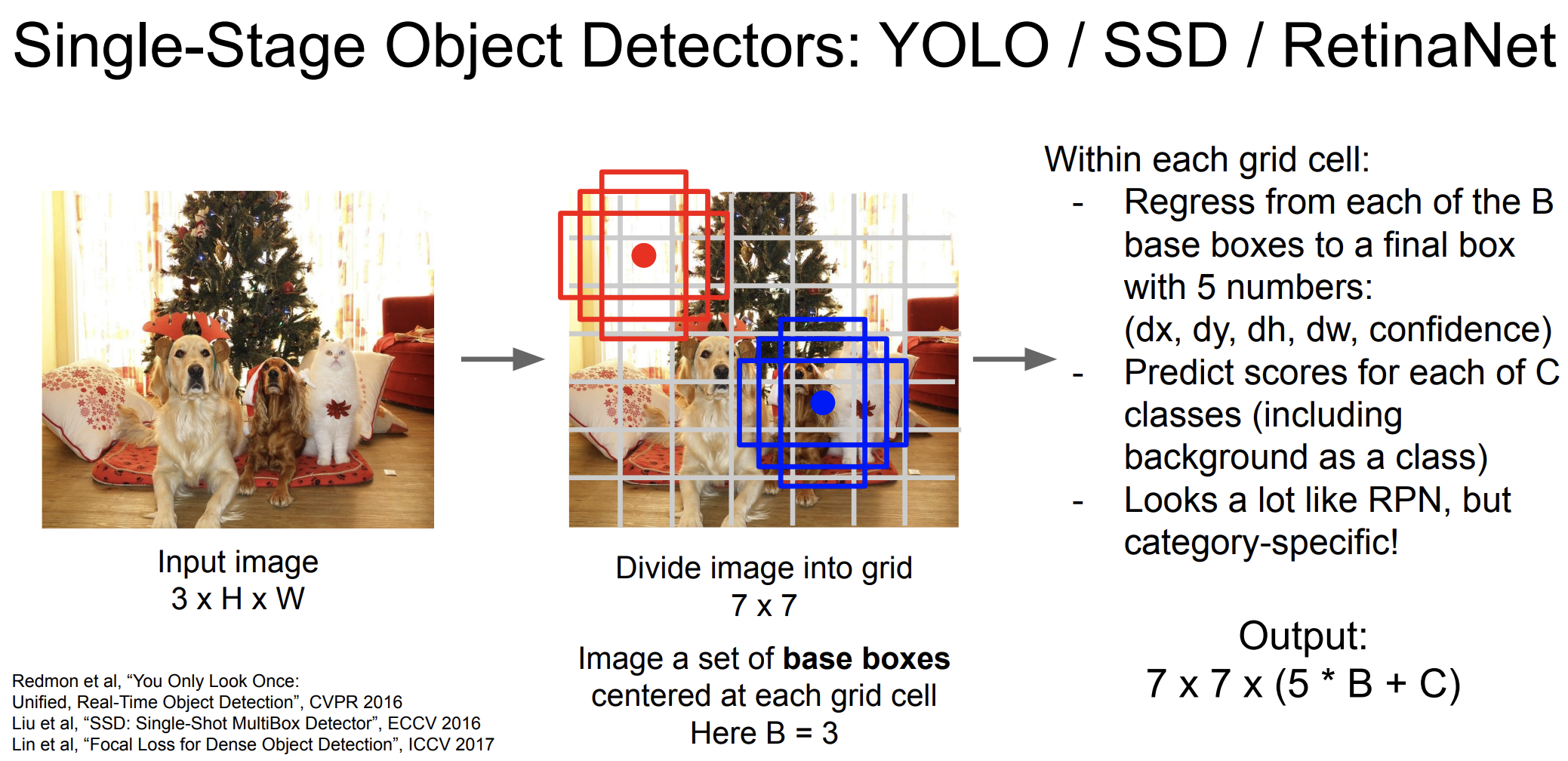
작동 원리
-
이미지 분할 : 이미지를 SxS 크기의 그리드로 분할 한다.
-
객체 탐지 및 분류 : 각 그리드 셀 마다 정사각형, 직사각형 등등 여러 base 박스를 setting한다. 각 박스에 대해 객체가 있을 확률을 계산한다.(dx, dy, dh, dw, confidence) 또한 각 그리드 셀에서 객체의 클래스를 예측한다. -> Predict scores for each of C classes (including background as a class)
-
신뢰도 점수 계산: 각 바운딩 박스에 대한 신뢰도 점수를 계산한다. 이 점수는 객체가 박스 내에 존재할 확률과 박스가 얼마나 정확하게 객체를 포함하는지에 대한 정보를 더한다.
-
여러 박스가 같은 객체를 탐지하는 경우, Non-maximum suppression을 사용해서 가장 높은 신뢰도를 가진 박스를 선택한다.
각각의 그리드에 대한 상자들에 대한 5가지 숫자들, 그리고 클래스 점수를 더한 결과가 나타난다.
=> 7x7x(5xB+C)
특징
- 하나의 컨볼루션 신경망을 통해 이미지 전체에서 특징을 추출하고 객체의 위치와 분류를 동시에 수행한다.
- 따라서 매우 빠른 처리 속도를 가지고 있다.
- 배경을 객체로 잘못 인식하는 경우가 적은 편이다.
Instance Segmentation
그럼 인스턴스 별로 이미지를 세분화해보자.
Mask R-CNN
⭐️ 작동 과정
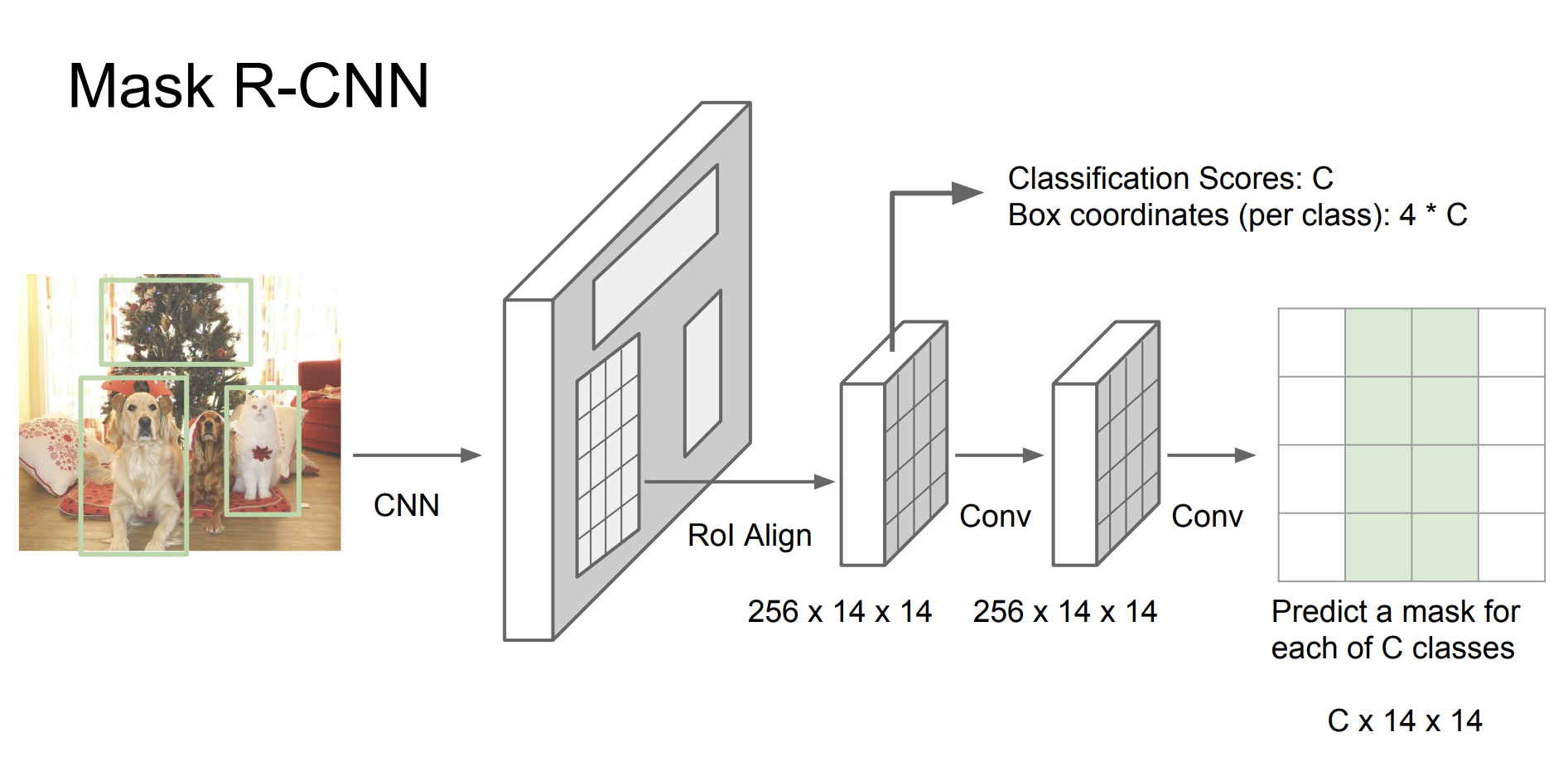
- Backbone Network: ResNet과 같은 CNN 신경망을 사용해서 이미지의 특징을 추출한다.
- Region Proposal Network(RPN): Faster R-CNN과 마찬가지로 RPN은 객체가 존재할 가능성이 있는 영역을 식별한다.
- RoI Align: 각 후보 영역에 RoI Align을 적용한다.
- 각 제안된 영역에 대해서 객체의 클래스를 분류하고, 바운딩 박스 위치를 조정한다.
- 각 객체에 대한 픽셀 단위의 MASK를 생성한다. 마스크 생성기는 각 객체에 대한 고유한 마스크를 생성하여 객체의 정확한 형태와 윤곽을 나타낸다.
RoI Align이 뭔지, 작동원리를 알아보자.

입력 이미지의 특징맵에서 RPN또는 다른 방법으로 객체가 존재할 것으로 예상되는 영역(여기서는 초록색)을 추출한다.
그리고 RoI를 그리드로 나눈다.
각 그리드 셀 내 특정 위치(일반적으로 그리드 셀의 중앙)에서 특징 맵의 값을 샘플링한다. 샘플링은 양선형 보간을 사용해 이루어진다.
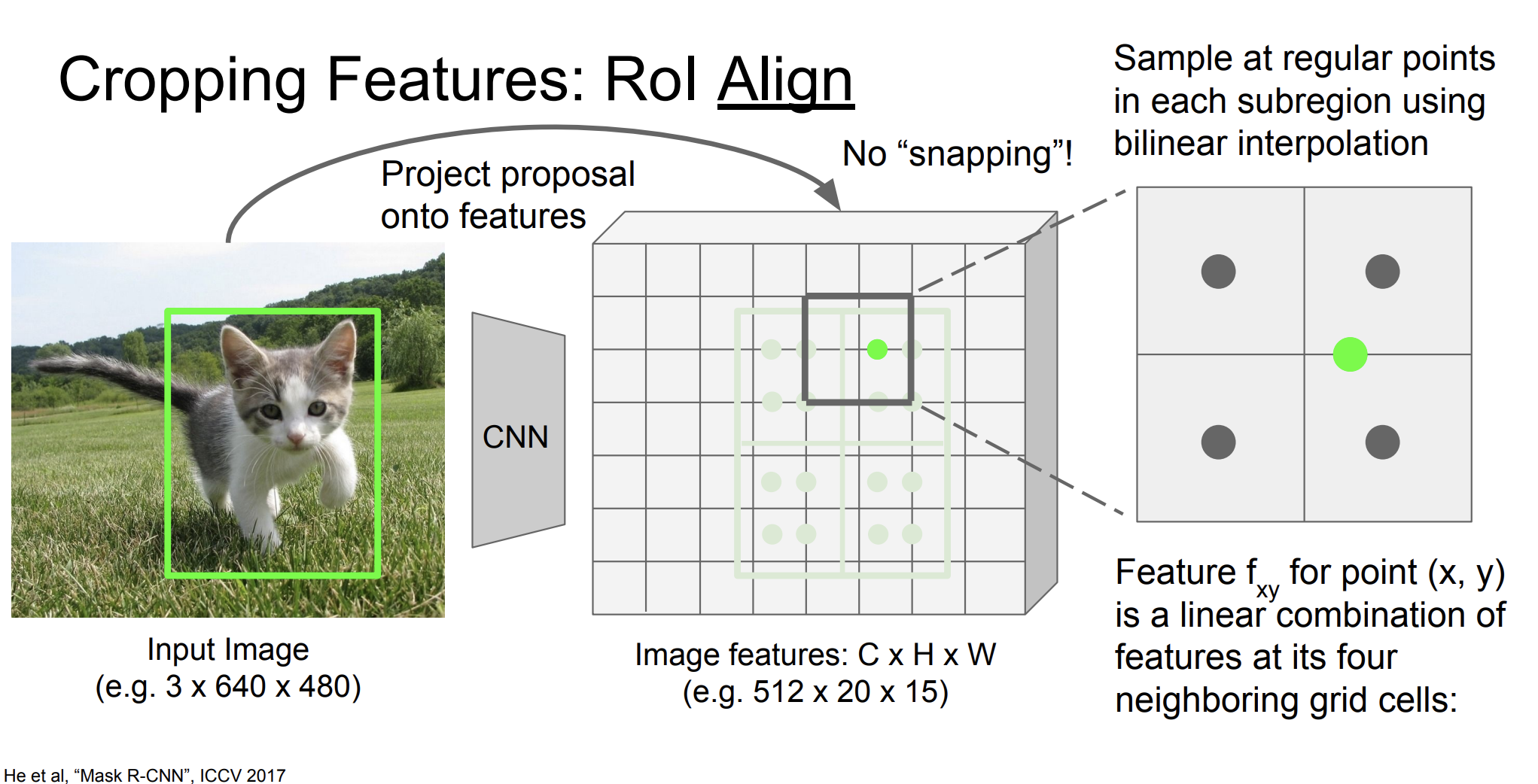
양선형 보간법은 위 그림처럼 한 점에 대한 값을 근처 4개의 셀들을 통해 구하는 것이다.
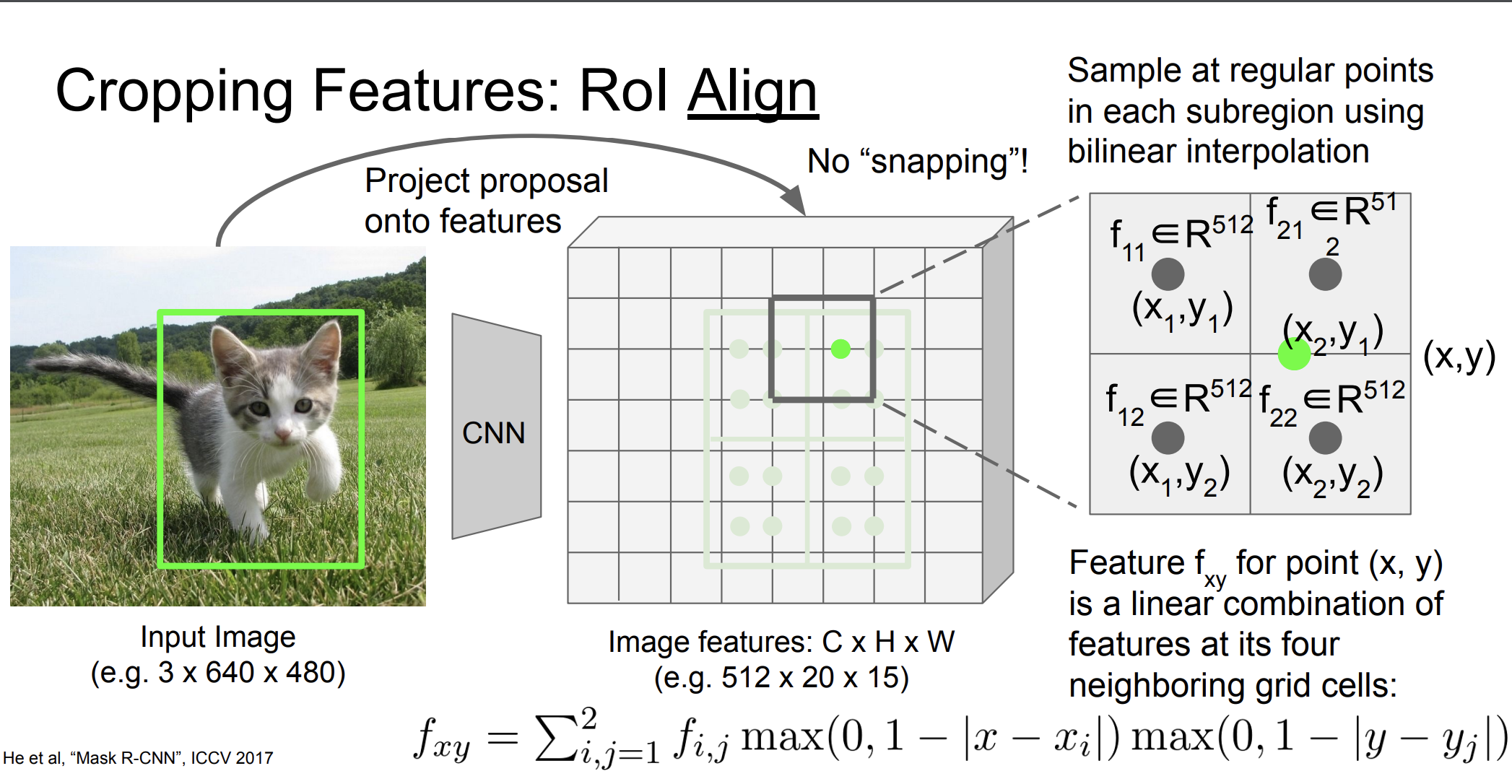
그 다음 max pooling을 수행한다.
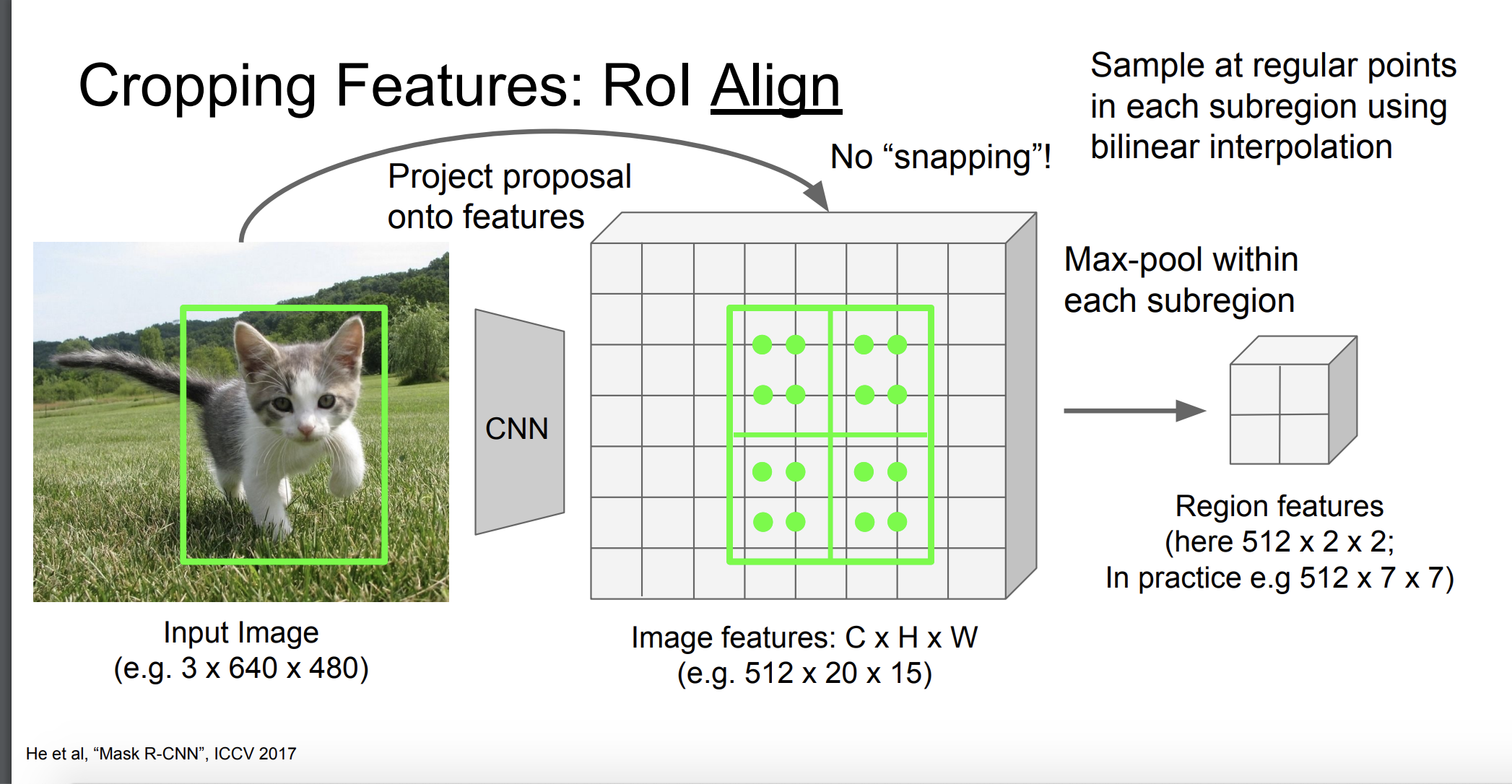
각 RoI들은 고정된 크기의 특징 벡터로 변환된다.
RoI Align 방법은 객체의 정확한 위치와 형태를 더 잘 포착해준다고 한다.

MASK R-CNN에 대한 예시로, 꽤 객체에 대해 잘 포착하고, 인스턴스화를 잘 하는 것을 알 수 있었다.


또한 사람의 포즈에 대해서도 잘 예측했다 🤸♀️
