강의 자료
Lecture 10 | RNN
이전시간까지 CNN 아키텍쳐들에 대해서 배웠다.
오늘은 Recurrent Neural Networks에 대해 배워보자!
Process Sequences
우리는 지금까지 아키텍쳐들을 1:1 로만 생각했다.
이를 Vanilla Neural Networks라고 한다.
하지만 좀 더 유연한 아키텍쳐들도 존재한다.
순환 신경망(recurrent neural networks) 아이디어로 전환하면 네트워크가 처리할 수 있는 입력 및 출력 데이터 유형을 다양하게 다룰 수 있게 된다.
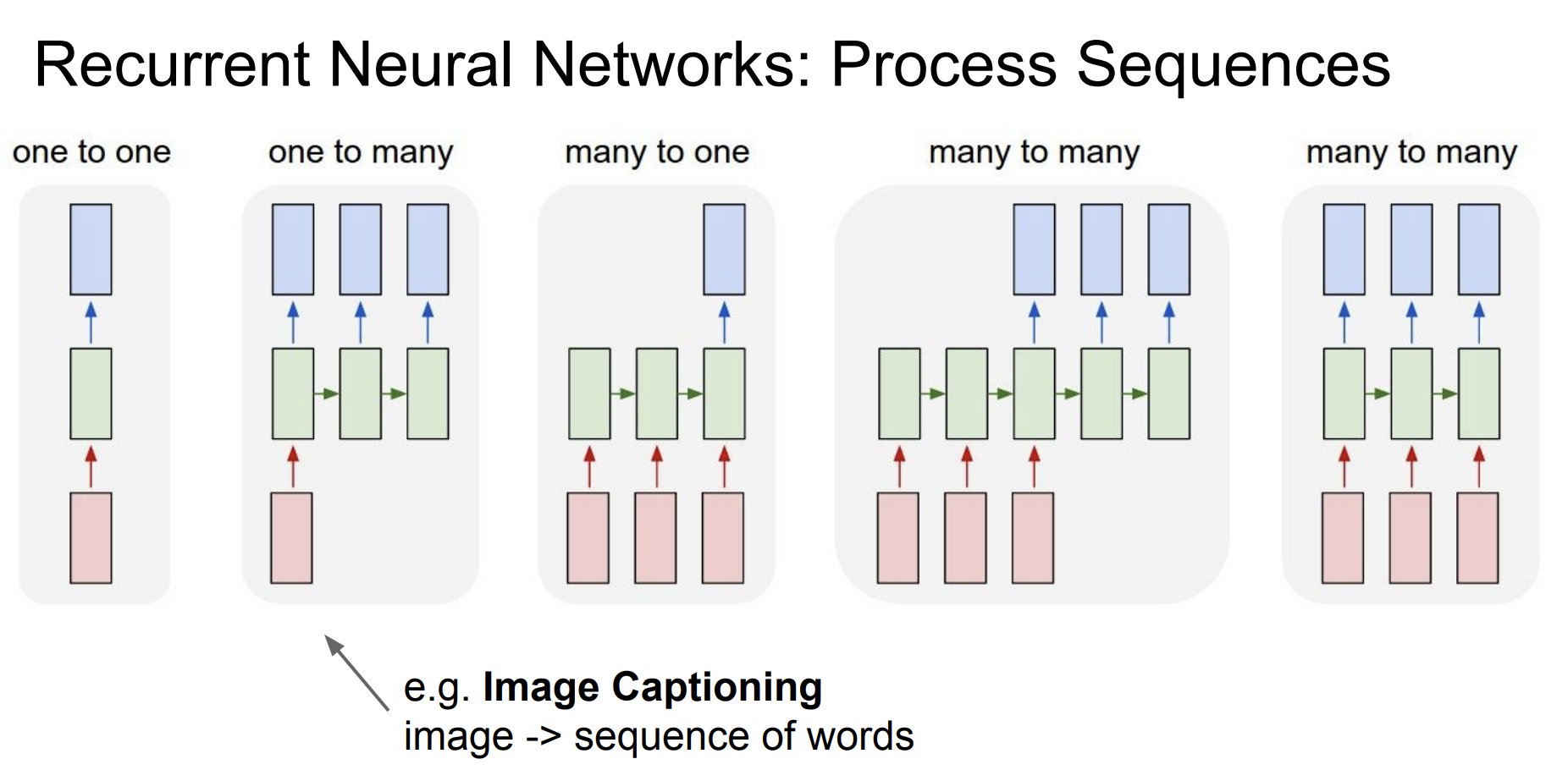
1:many, many:1, many:many 등등이 있다.
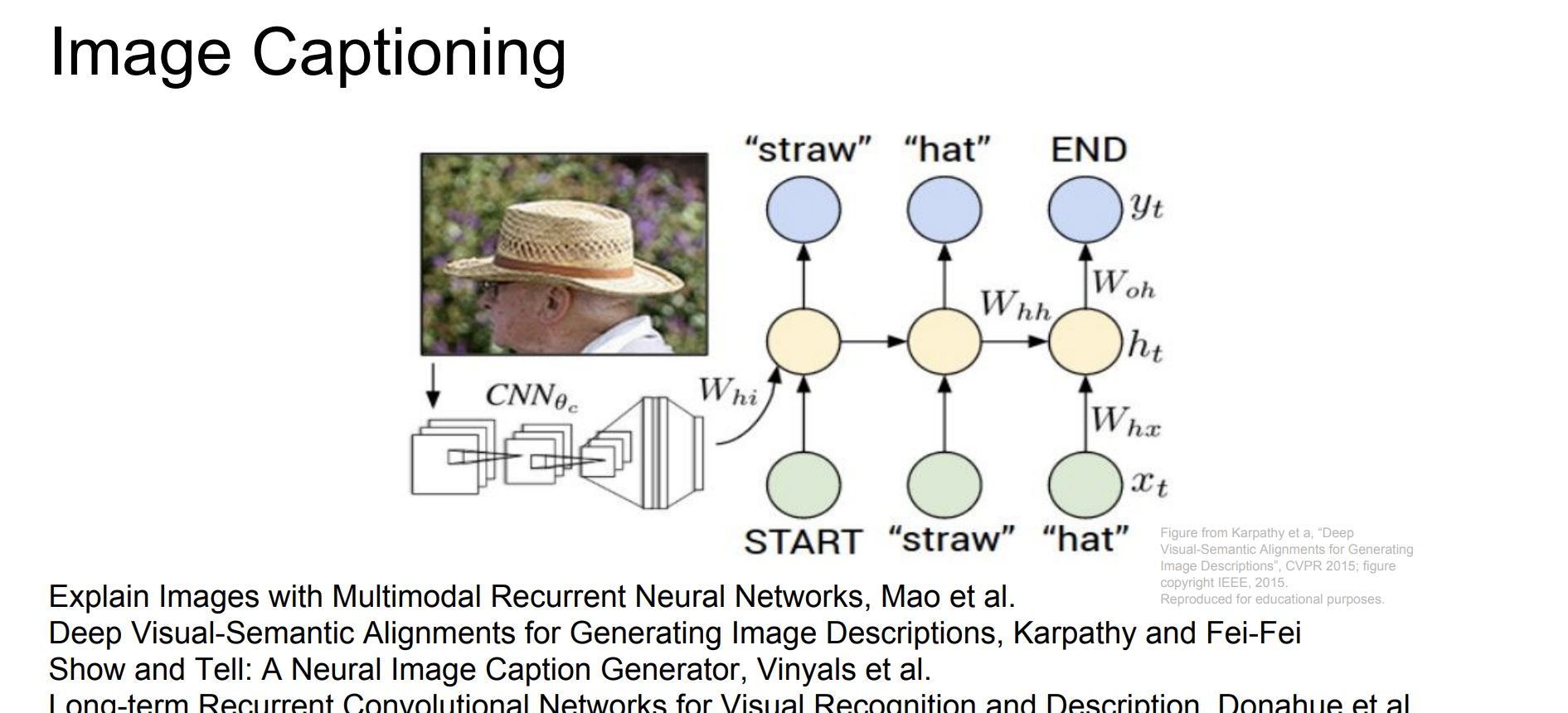
두번째 아키텍쳐의 경우는 Image Captioning에 적합하다.
이미지를 입력으로 주고나서, 일련의 문자열들을 출력하는 것이다.
세번째 아키텍쳐의 경우에는 Sentiment Clssification에 적합하다. 일련의 문자열들을 입력으로 주고나서, 그 문장에 대한 감정을 뽑아내는 것이다.
네번째 아키텍쳐의 경우에는 Machine Translation이 적합하다. 가변적인 입력 형태가 주어지고, 또한 가변적인 출력 형태가 나타난다.
마지막 아키텍쳐의 경우에는 Video classification on frame level이 적합하다. 비디오를 순간 순간 포착해서 분석하는 것에 적합한 아키텍쳐이다.

입력을 순차적으로 처리하는 등의 작업을 수행한다.
이미지와 같은 고정된 크기의 입력을 받고 이 이미지에 어떤 숫자가 표시되는지 알아보자.
단일 피드 포워드를 수행하는 대신, 이미지의 다양한 부분을 다양하게 살펴본다. 그리고 일련의 glimpses(잠깐 봄, 언뜻 봄)를 수행하고 어떤 숫자인지 결정을 내린다.
Architecture
RNN의 구조를 살펴보자.
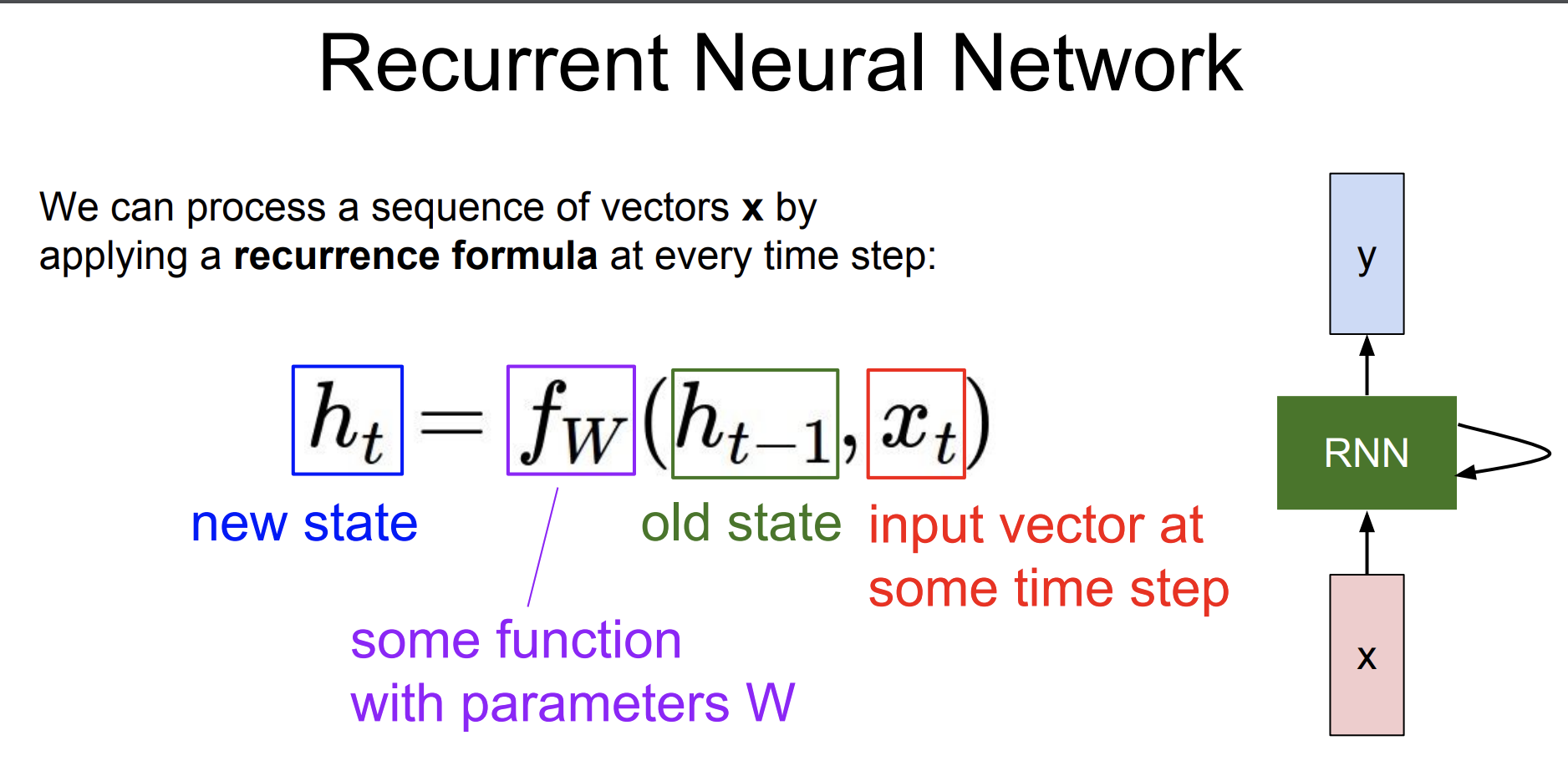
이전 cs224n수업에서 다루었던 기억이 있다.
새로운 히든 스테이트는 이전 히든 스테이트와 현재 입력 벡터를 함수 fW에 넣고 나온 것이다.
가장 단순한(Vanilla) 형태는
->
이고 순차적으로 hidden state를 다음처럼 계산한다.
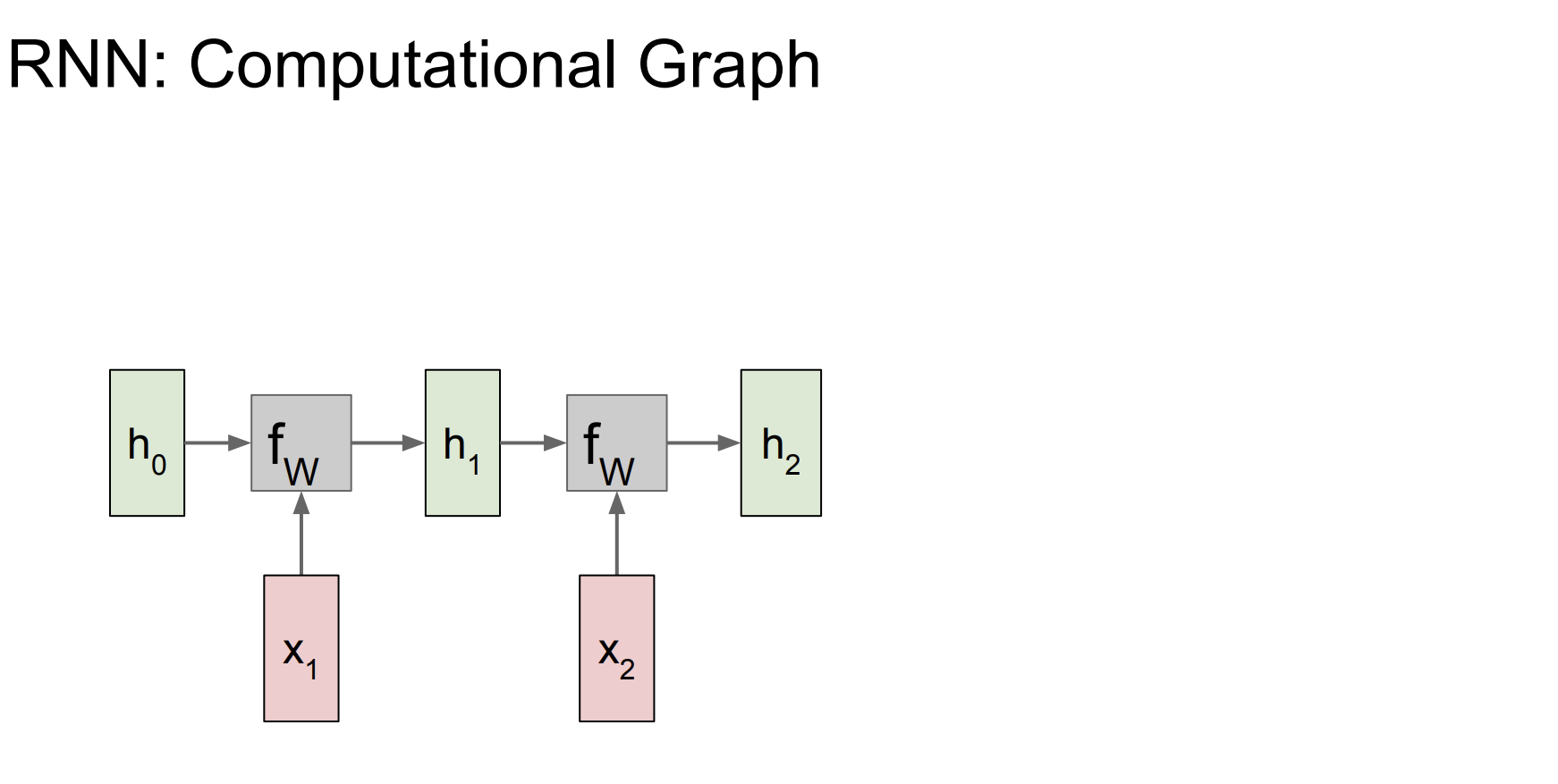
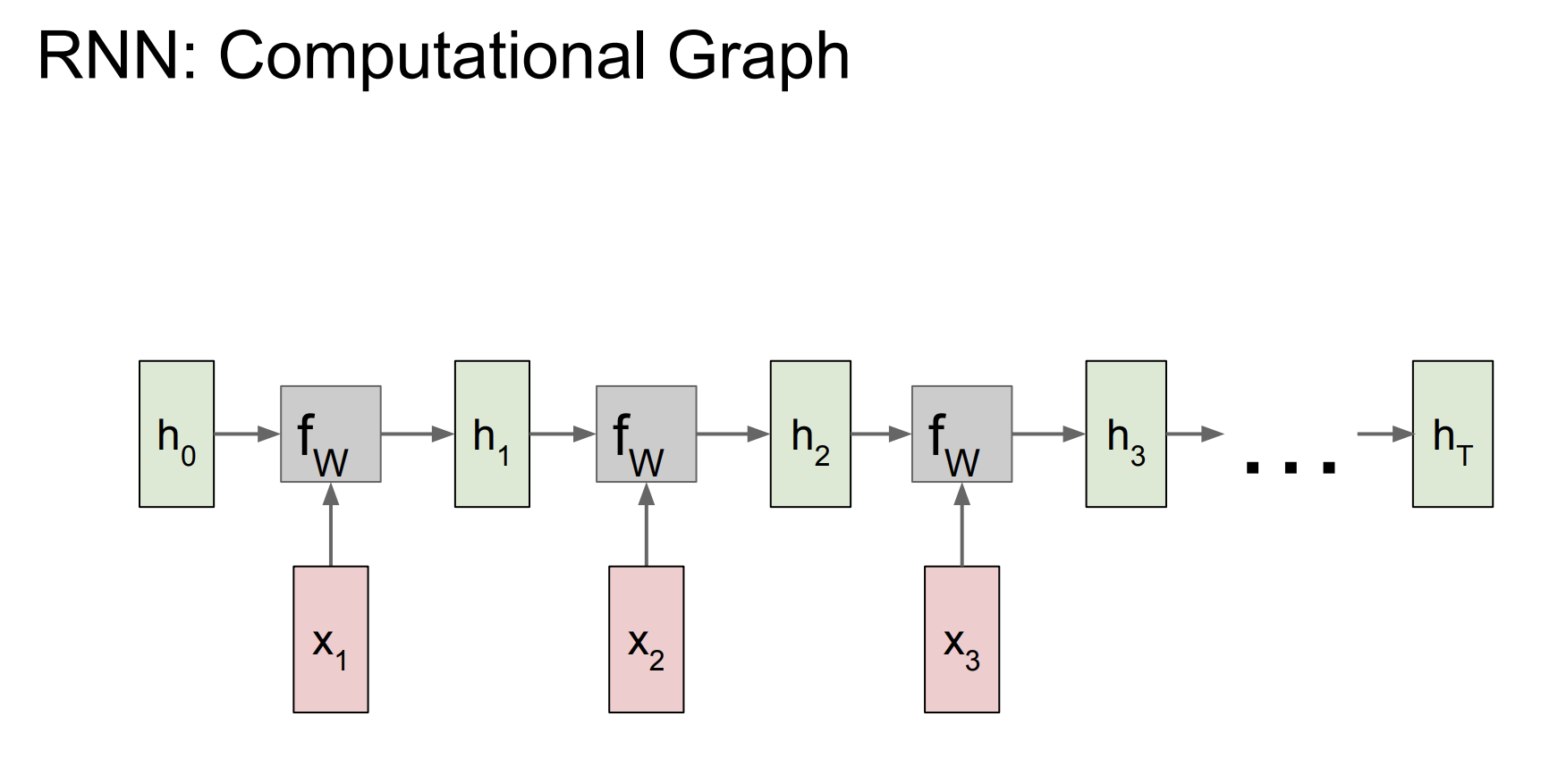
중요한 것은 가중치 행렬 W는 매 시간마다 동일한 행렬을 사용한다는 점이다.
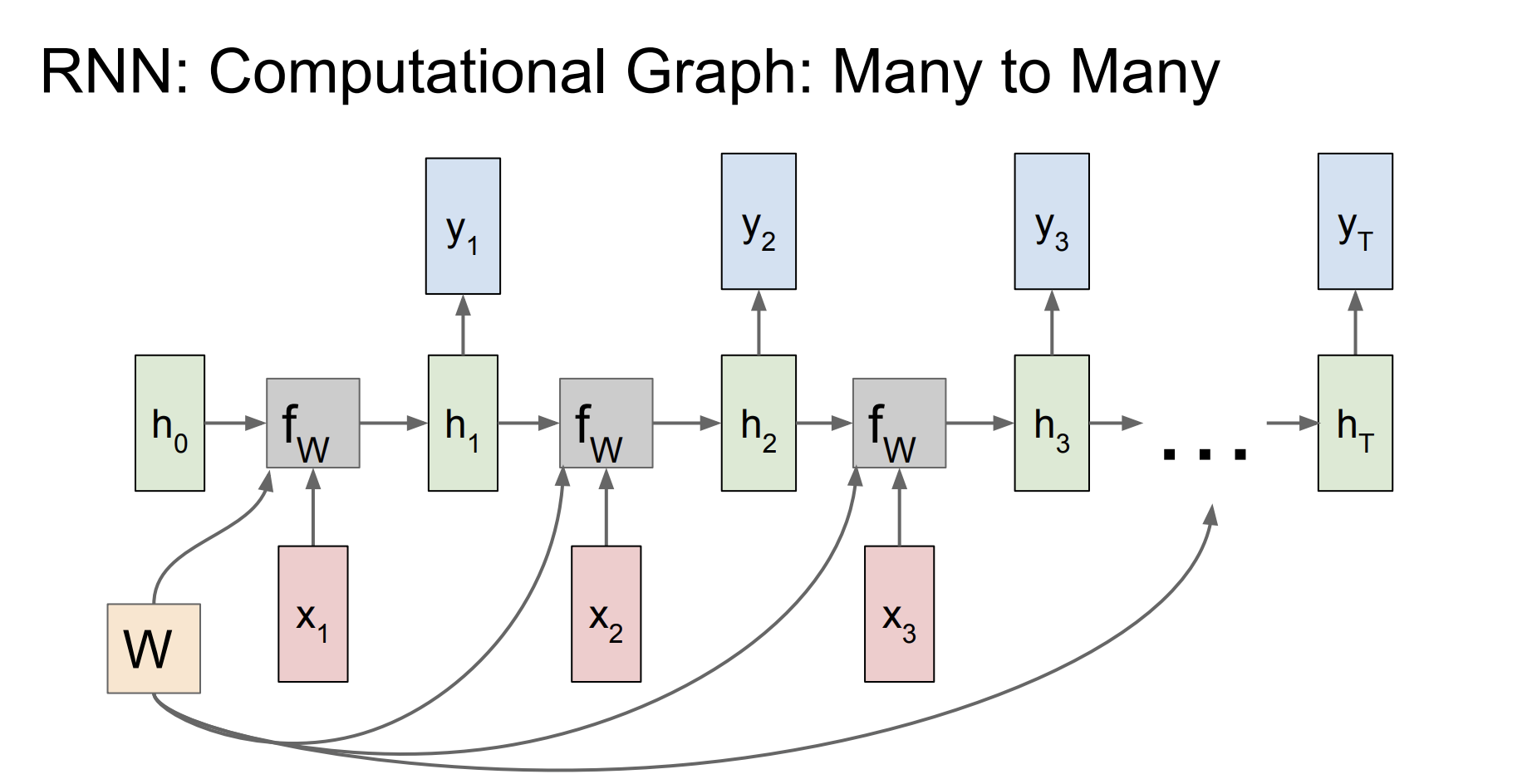
그리고 매 시간마다 출력을 구할 수 있다.
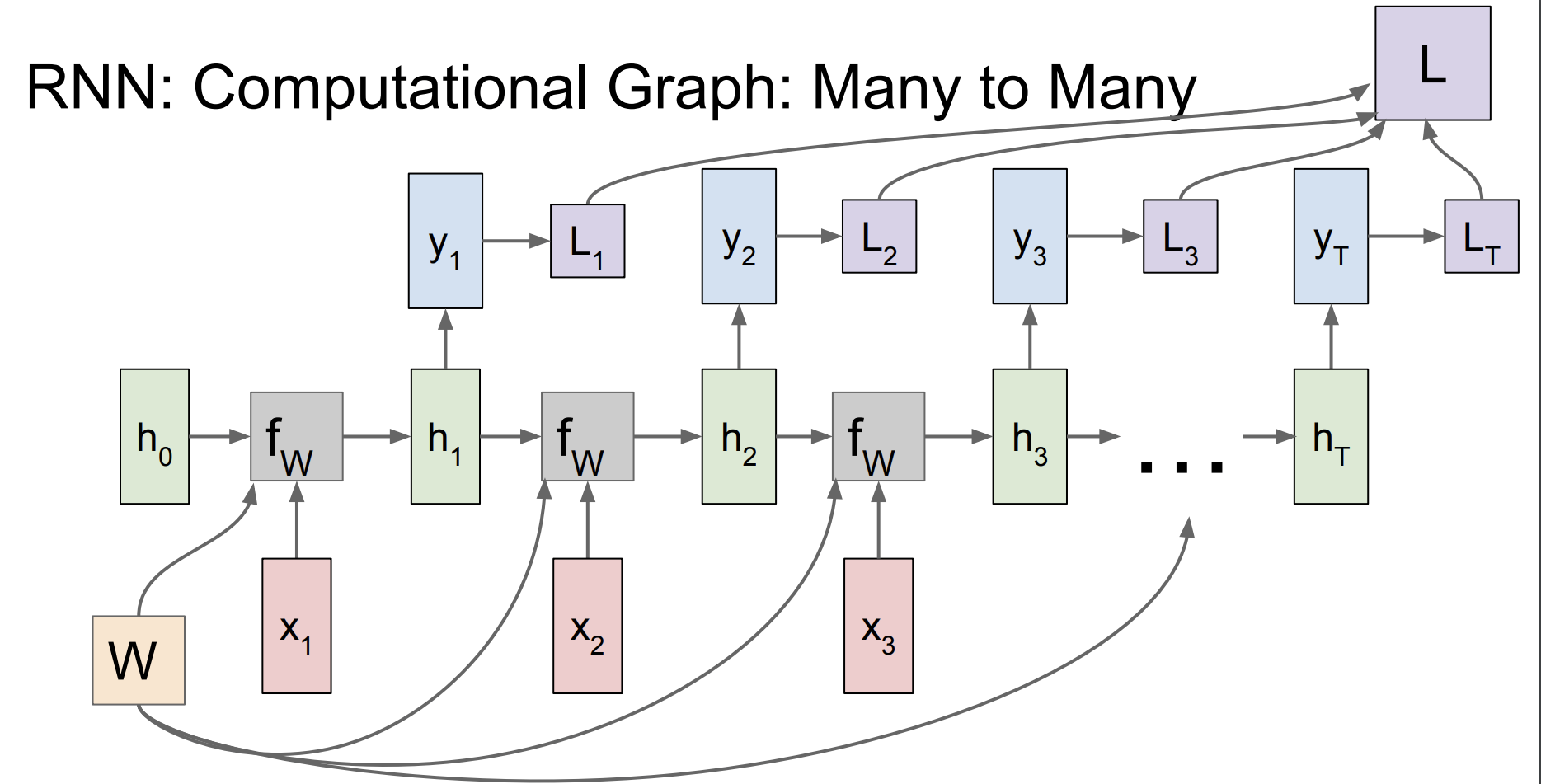
그리고 매 출력과 다음 입력값을 비교해서 loss를 구한다. 모든 loss를 더한 값이 L이된다.
위 그림은 입력도 여러개, 출력도 여러개인 구조를 가지고 있다.
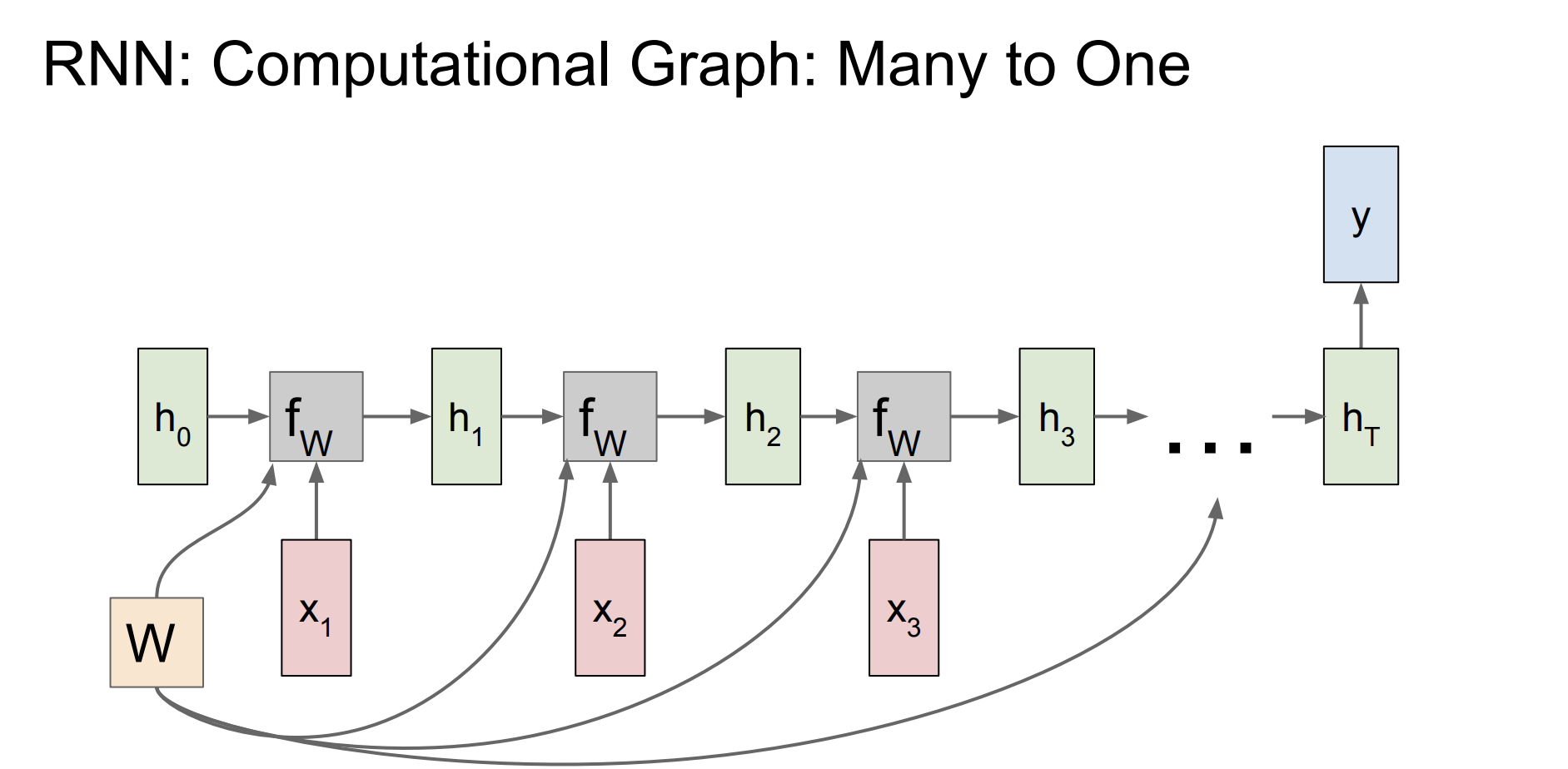
입력이 여러개, 출력은 마지막 hidden state만 고려하는 경우도 있다.
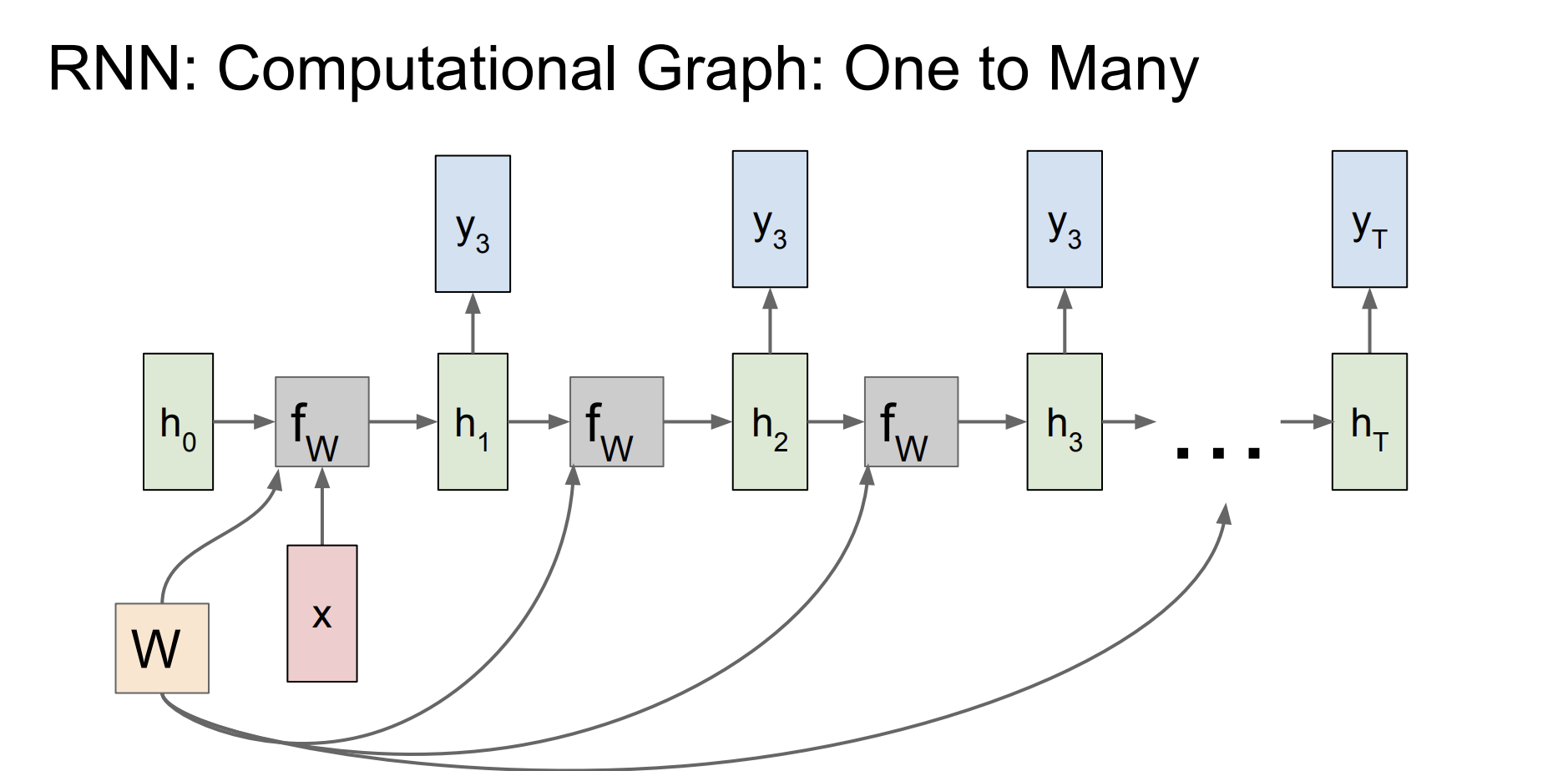
입력은 하나지만 매 출력을 하는 경우도 있다.
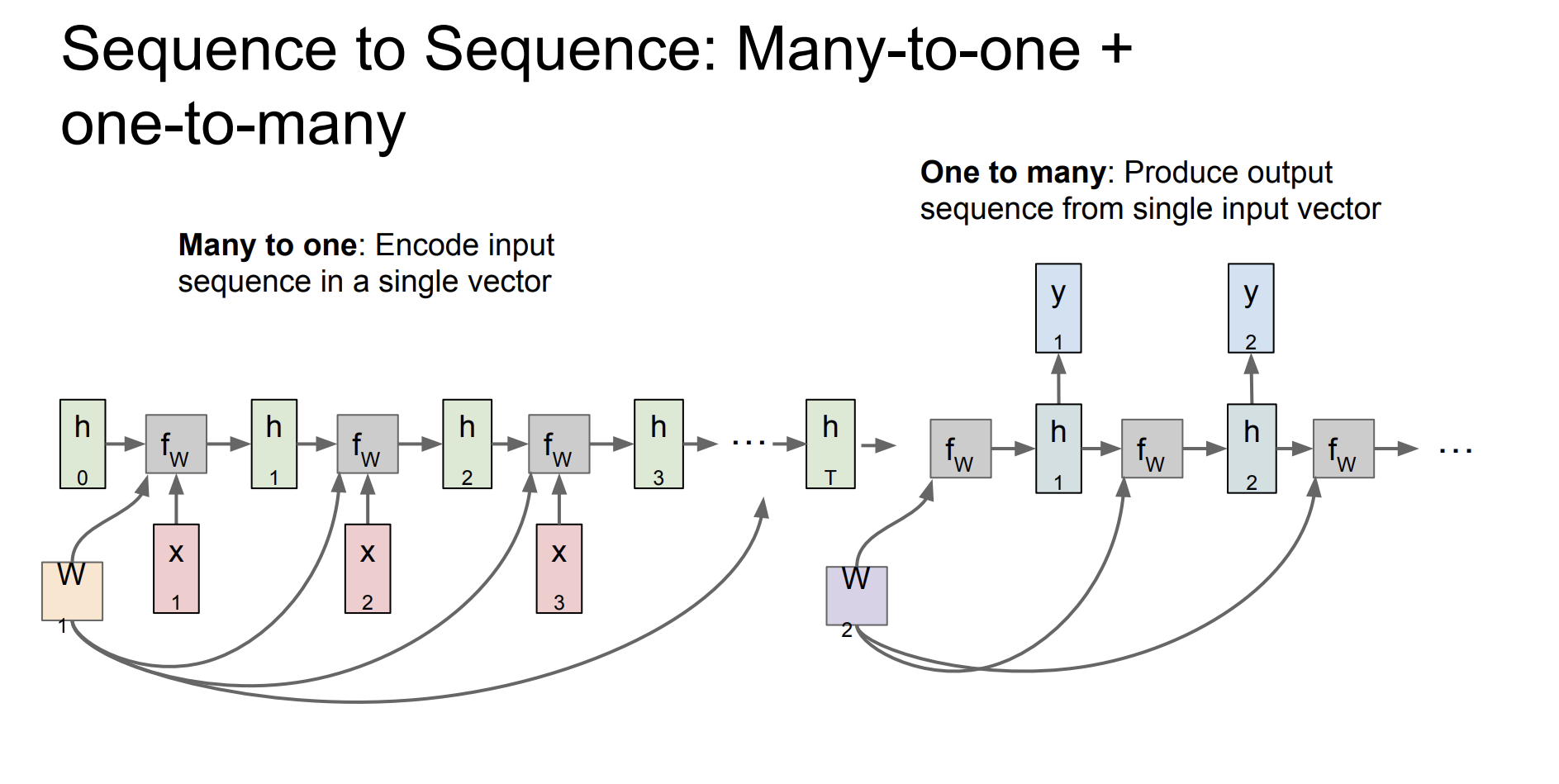
Many-to-one 과 one-to-many를 합치면 seq2seq구조가 된다.
Example
Character-level Language Model을 보자.
단어장에는 [h,e,l,o]만 있다.
"hello"라는 단어를 한번 훈련시켜보자.
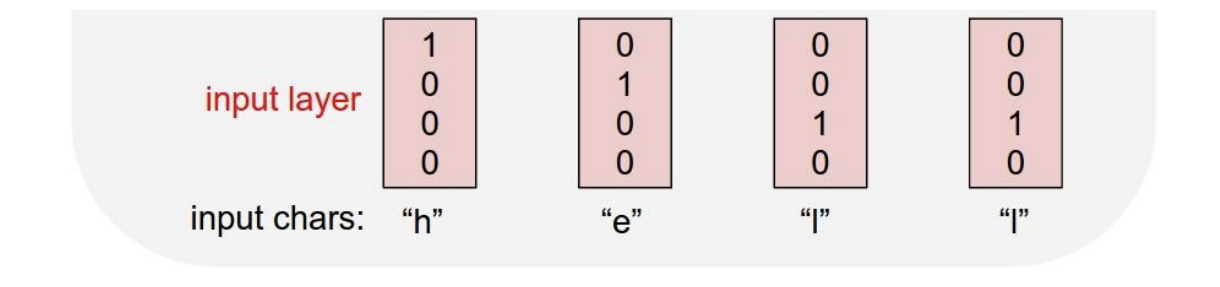
일단 우리는 단순하게 각 입력 문자를 one-hot vector로 임베딩을 한다.
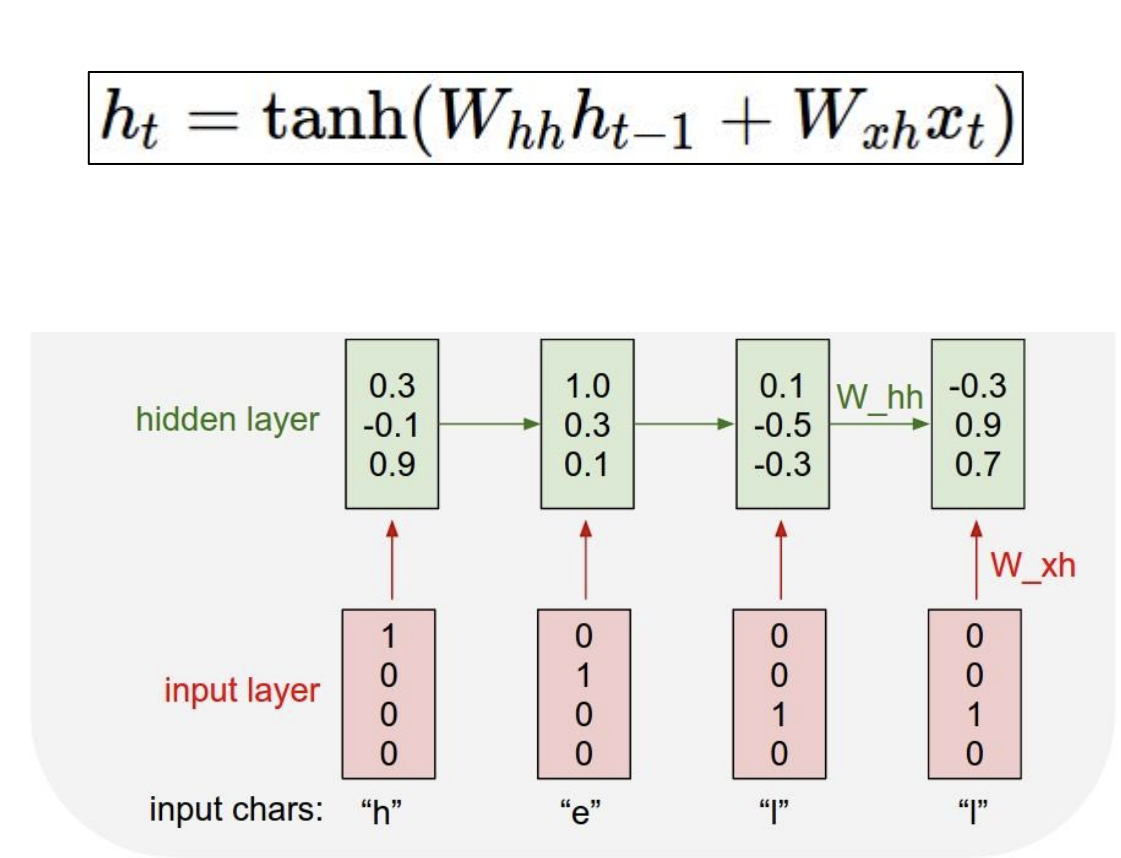
hidden state를 tanh함수를 통해서 구한다고 하자. 그리고 어떠한 W 행렬에 대해서 구했다고 하자.
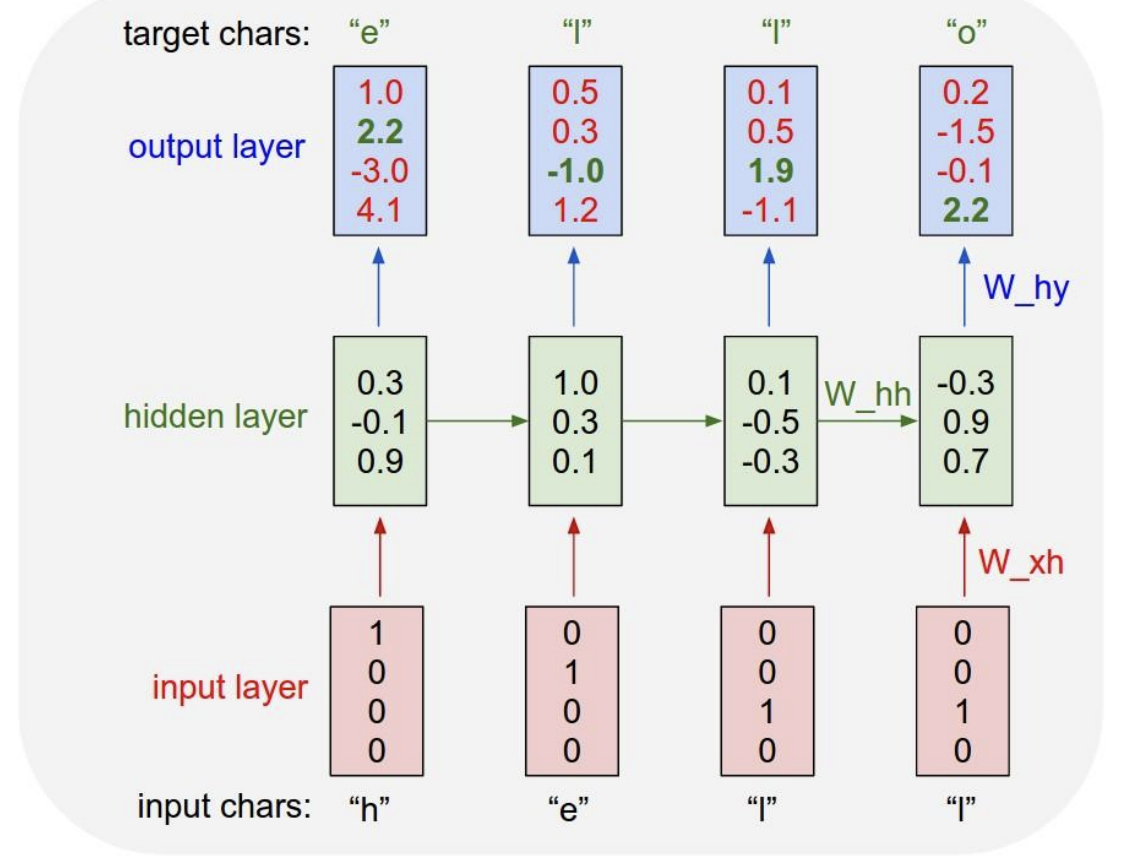
output layer를 보면 첫번째 은 다음 문자가 'o'이 올확률이 제일 높았다. 하지만 다음 문자(target chars)인 'e'가 아니였다. 따라서 이때는 손실을 감수해야 한다.
그 다음 를 보니 가장 점수가 높은건 'o'였다. 다음 문자는 'l'이다. 심지어 'l'에 대한 점수가 제일 낮았다. 이때는 꽤 큰 손실을 감수해야할 것이다.
이러한 손실 함수를 최적화하는 방향으로 진행하다 보면, 최적의 가중치 행렬인 W을 구할 수 있을 것이다.
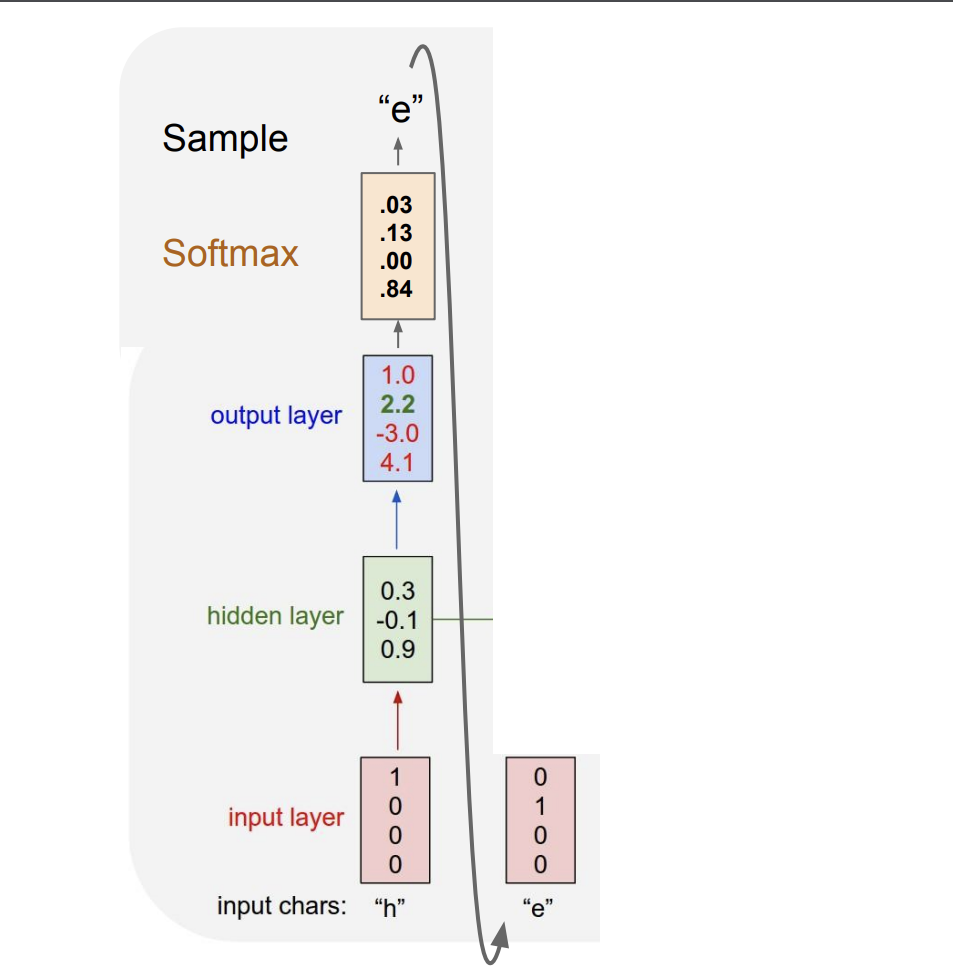
Character-level Language Model Sampling을 보자.
더 나아가서 output layer를 softmax 함수를 통해 확률 분포로 만들어보자. 그 다음, 확률 분포를 통해서 문자 하나를 sample로 뽑아 보자.
위 모델에서는 'e'를 뽑을 확률이 매우 작았지만 운이 좋게 올바른 문자인 'e'를 뽑았다.
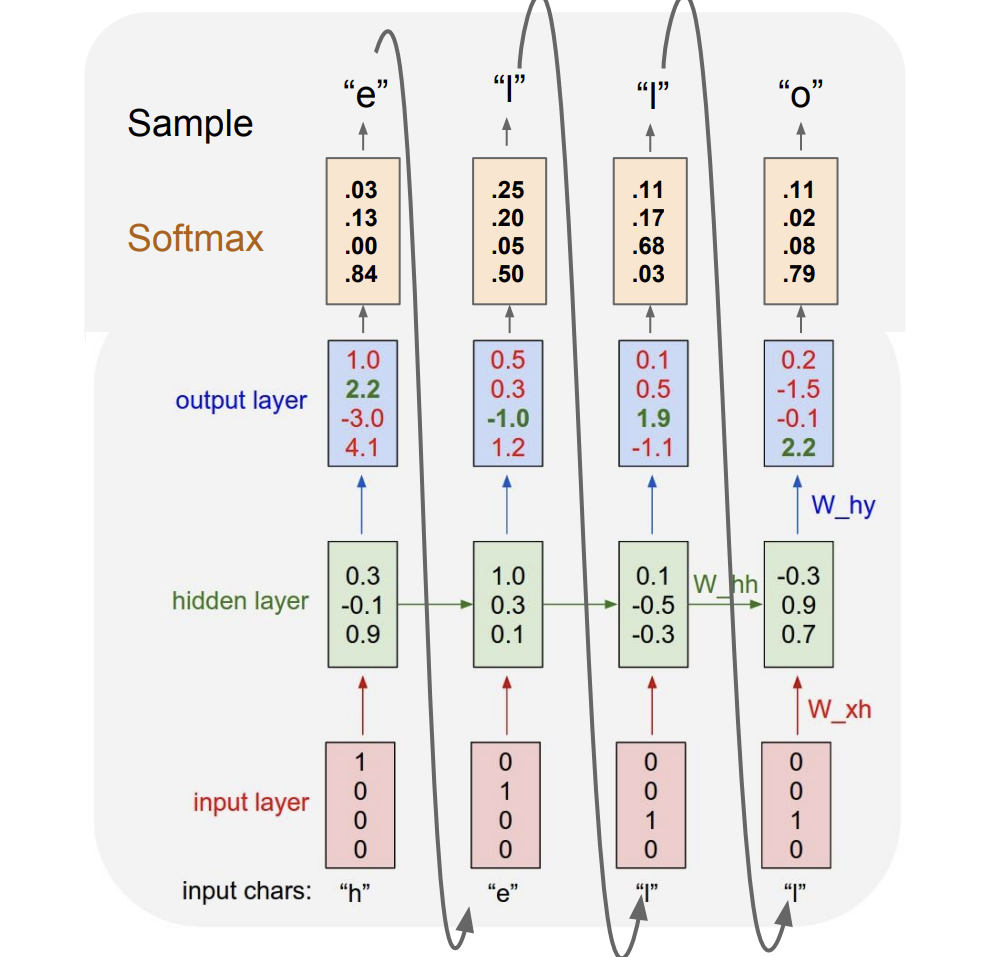
그리고 이 과정을 반복한다.
질문.
왜 가장 확률이 높은 문자를 선택하는 것이 아니라 확률분포에 따라 Sampling을 하는건지?
cs224에서 다뤘던 내용이다. 가장 확률이 높은 단어(문자)만을 선택하게 되면 텍스트의 다양성을 잃게 된다. 그리고 repetition과 같은 문제가 발생했다. 확률 분포에 따라 sample을 뽑게 되면 문장이 어느정도 다양해진다.
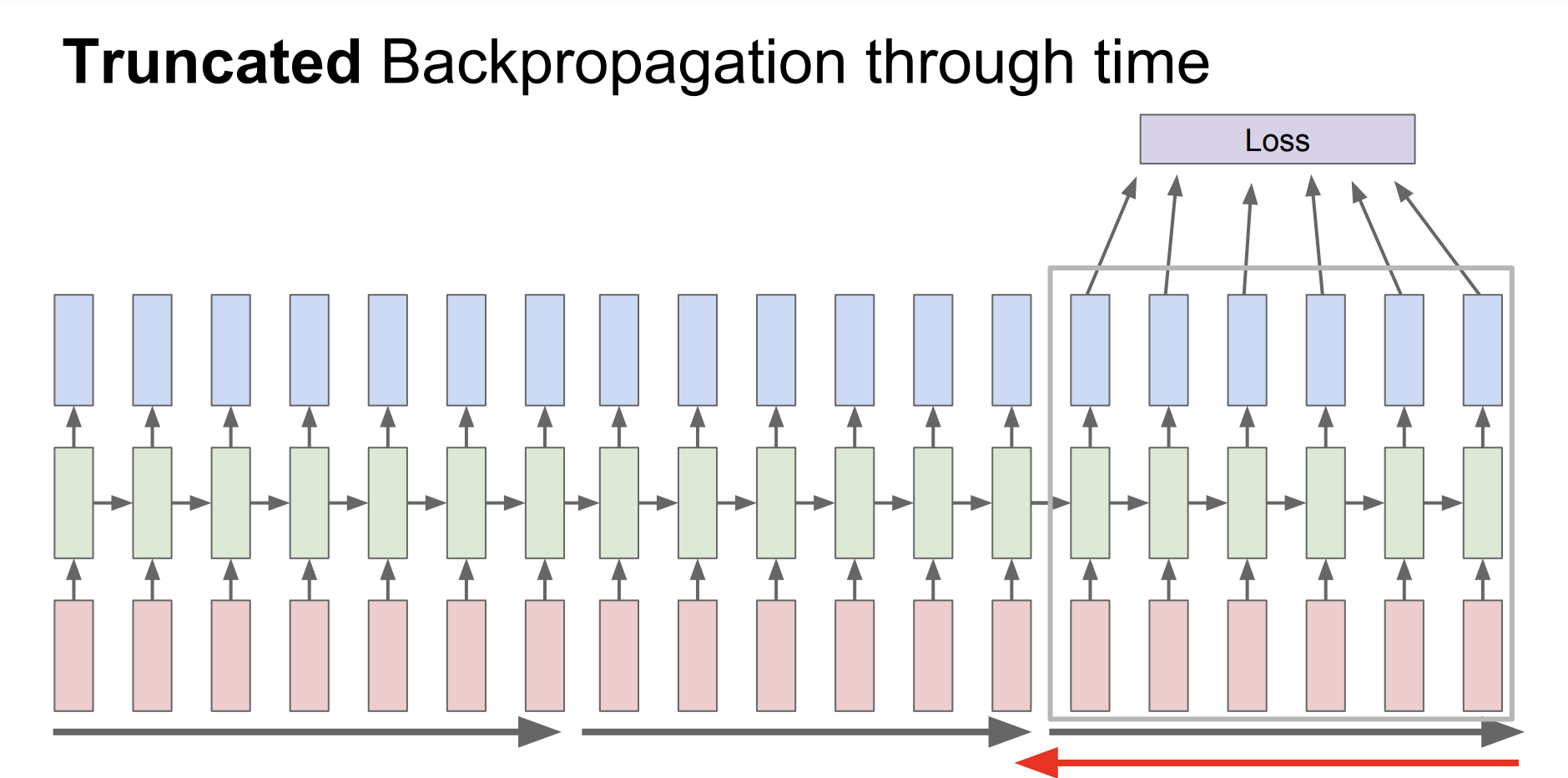
Truncated Backpropagation
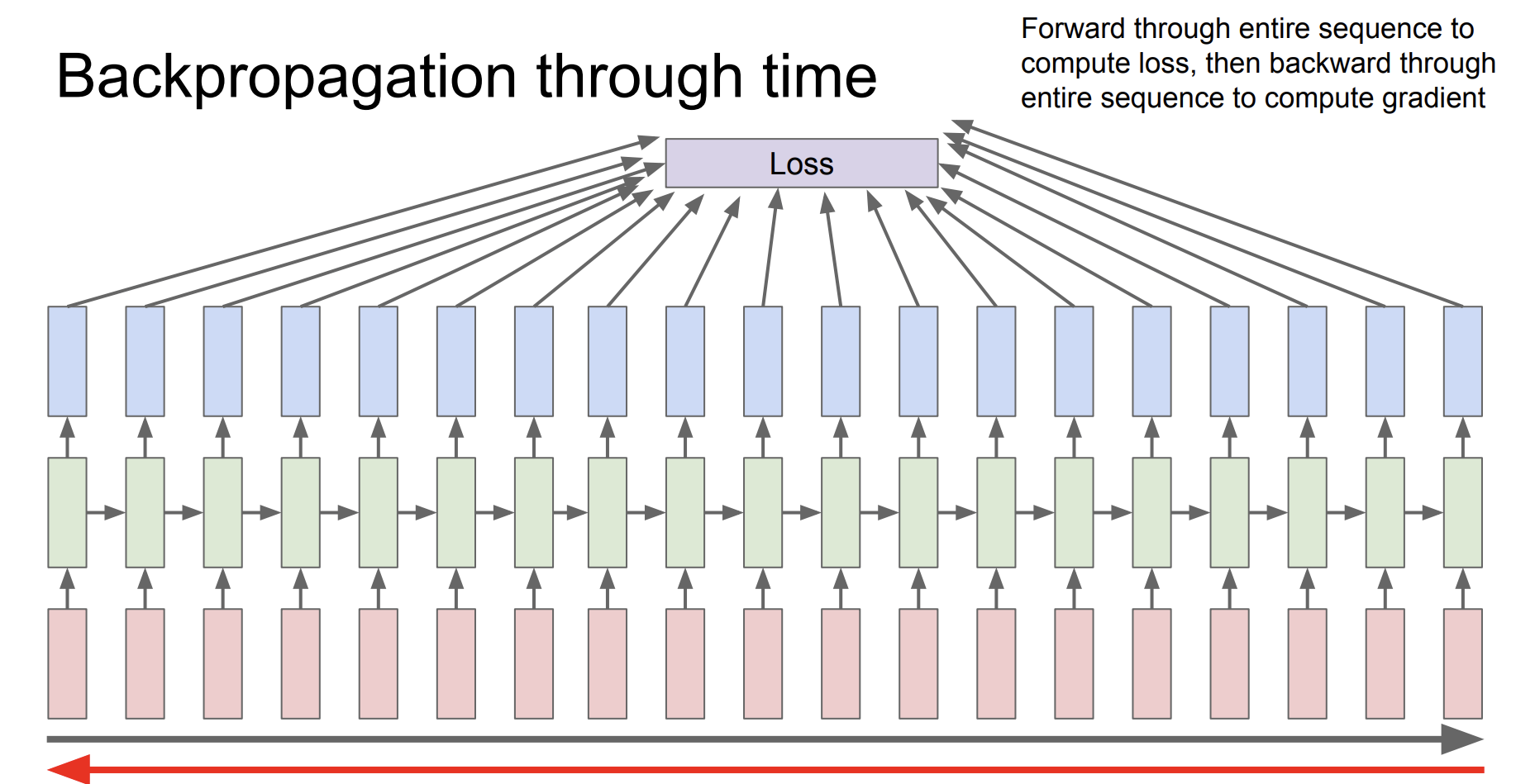
RNN을 엄청 많이 수행한다면, Backpropagation을 수행하기 힘들어진다. 이 문제를 해결하기 위해서 시간을 나눠서 Backpropagation을 수행할 것이다.
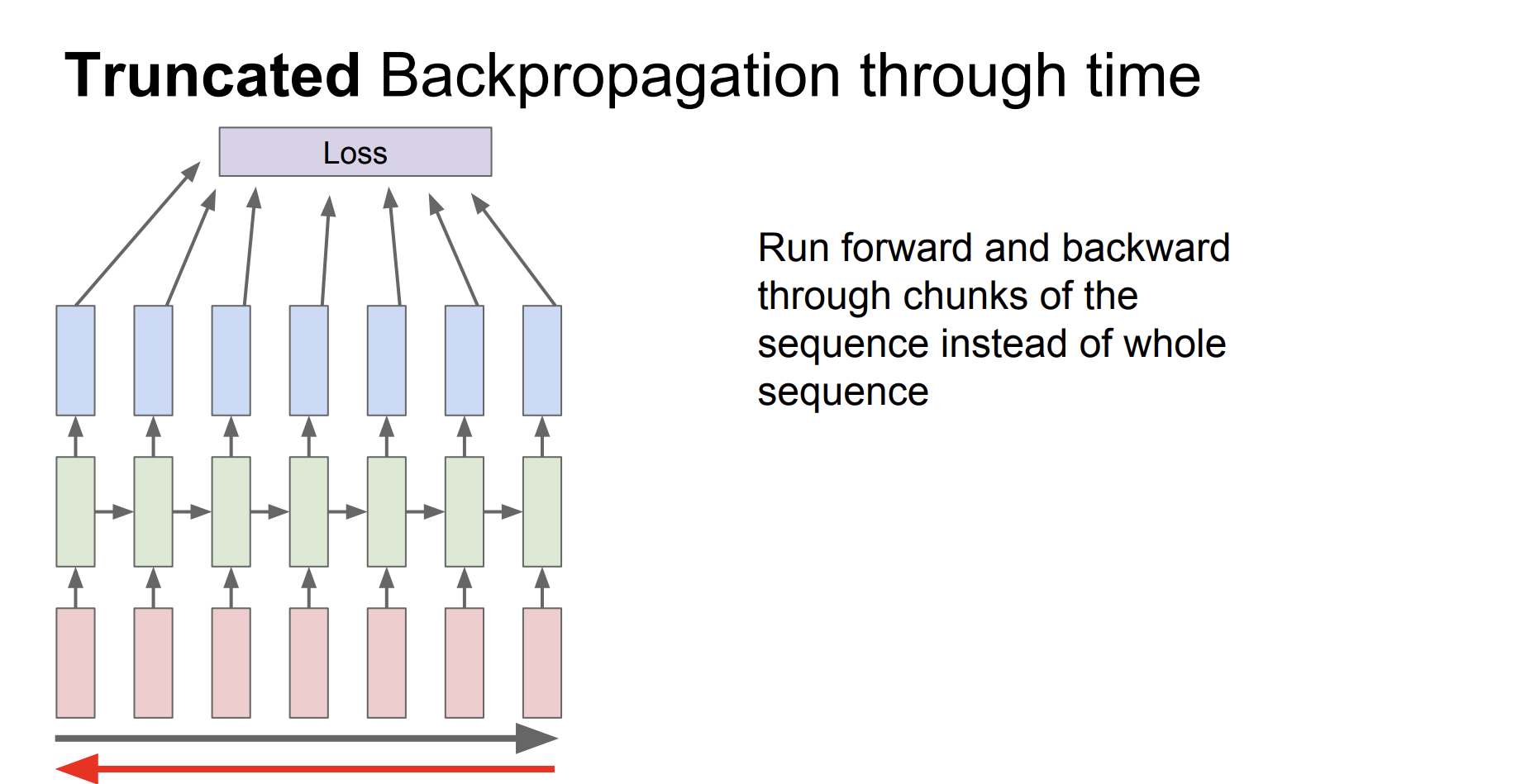
이를 Truncated Backpropagation이라고 한다.
전체 sequence를 수행하기 보다는 sequence를 조금 나눠서 forward와 backward를 수행하는 것이다.
forward를 수행할 때에는 이전의 hidden state를 이어서 수행하지만 backpropagate는 일부분만 진행한다.
RNN examples
RNN을 활용해서 셰익스피어 글을 훈련시켜보자.

처음에는 결과물이 그닥 좋지 않았지만, 점점 학습할수록 더 좋아지는 것을 알 수 있다.

데이터의 구조에 대해서는 잘 학습한다.
하지만 내용은 그닥이다.
또 다른 예시로 위상 수학 교과서를 한번 훈련시켜보자.

정말 그럴듯한 교과서를 만들어냈다.
하지만 이는 교과서의 ^형태^만 학습한 것이고 자세히 내용을 보면 텅비었음을 알 수 있다.
그리고 웃긴점은, 가끔 정의를 하고, 증명은 생략한다는 점이다.ㅋㅋㅋㅋㅋ

c언어를 학습시켜보면 꽤나 잘 학습한 모습이다.
변수를 어떻게 선언하는지, 조건문과 반복문의 문법을 정확히 알고 있다.
하지만 c언어를 학습한 결과, 사용하지 않는 변수를 선언한다는지 아니면 필요한 변수를 선언하지 않는 등의 문제가 있었다.
실제로는 컴파일이 되지 않는 코드를 생성해낸다.
Searching for interpretable cells
우리의 hidden state가 궁금하다.
그래서 hidden state 중 일부가 어떤 일을 수행하고 있는지 알고 싶어졌다.

사실 hidden state가 어떤일을 하는지 명확히 알 수 없다.
하지만 위 색깔을 보면 인용문자인 "가 시작하고 나서 두번째 "가 나올때까지 파란색인 것을 확인할 수 있었다. 이는 hidden state cell중에서 인용문구를 찾는 일을 하는 cell이 있음을 간접적으로 알 수 있다.

또 다른 예시로는 줄바꿈 cell이다. 처음 글을 시작할 때는 파란색이다가 점점 줄을 바꿔야할 때가 다가올 수록 빨간색이 된다. 이는 hidden state에서 줄바꿈 역할을 하는 cell이 있는 것을 알 수 있다.

코딩할 때도 if 의 조건문을 수행하는 cell이 있다.

주석을 처리하는 cell이 있다.

반복문 내부에서 얼마나 깊게 들어가는지를 파악하는 cell도 있다.
지금까지 '자연어'분야에서 rnn활용을 보았다면, '컴퓨터 비전'분야에서 어떻게 활용되고 있는지도 알아보자.
Image Captioning
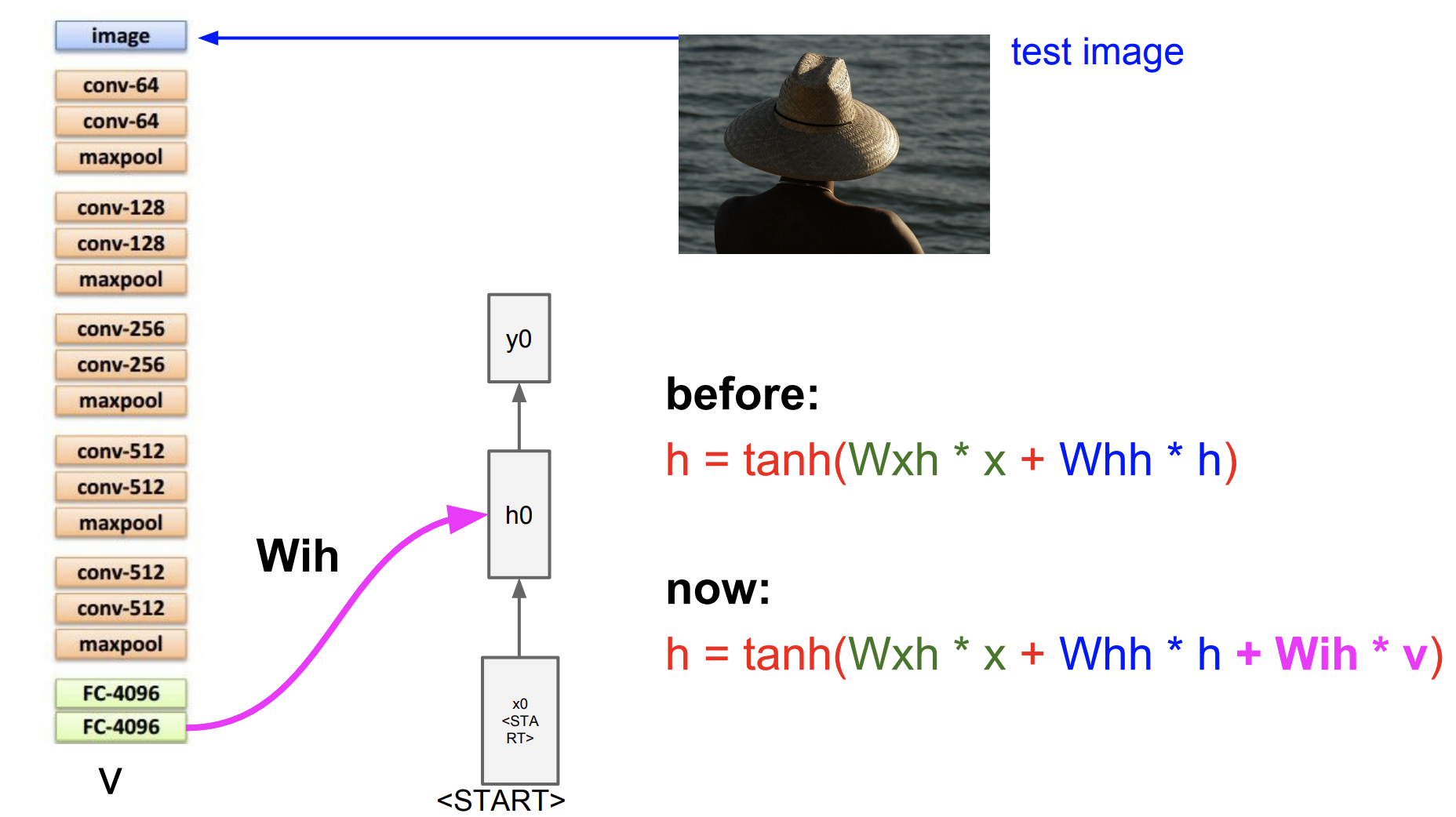
test image를 주고 FC에서 나온 가중치 행렬을 통해서 맨처음 hidden state를 구해보자.
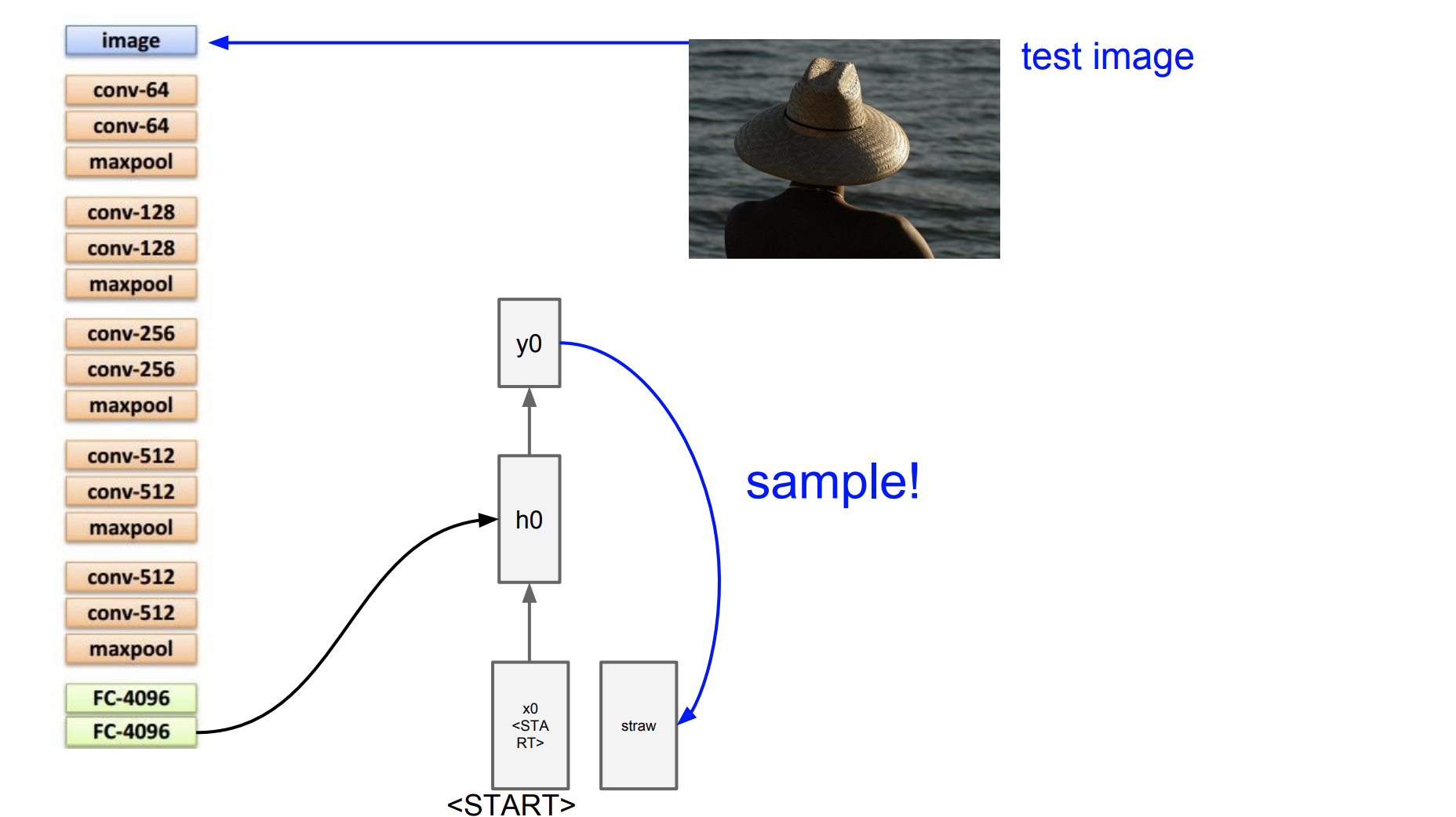
처음 y0을 구하고 이를 다음 input으로 넣는다.
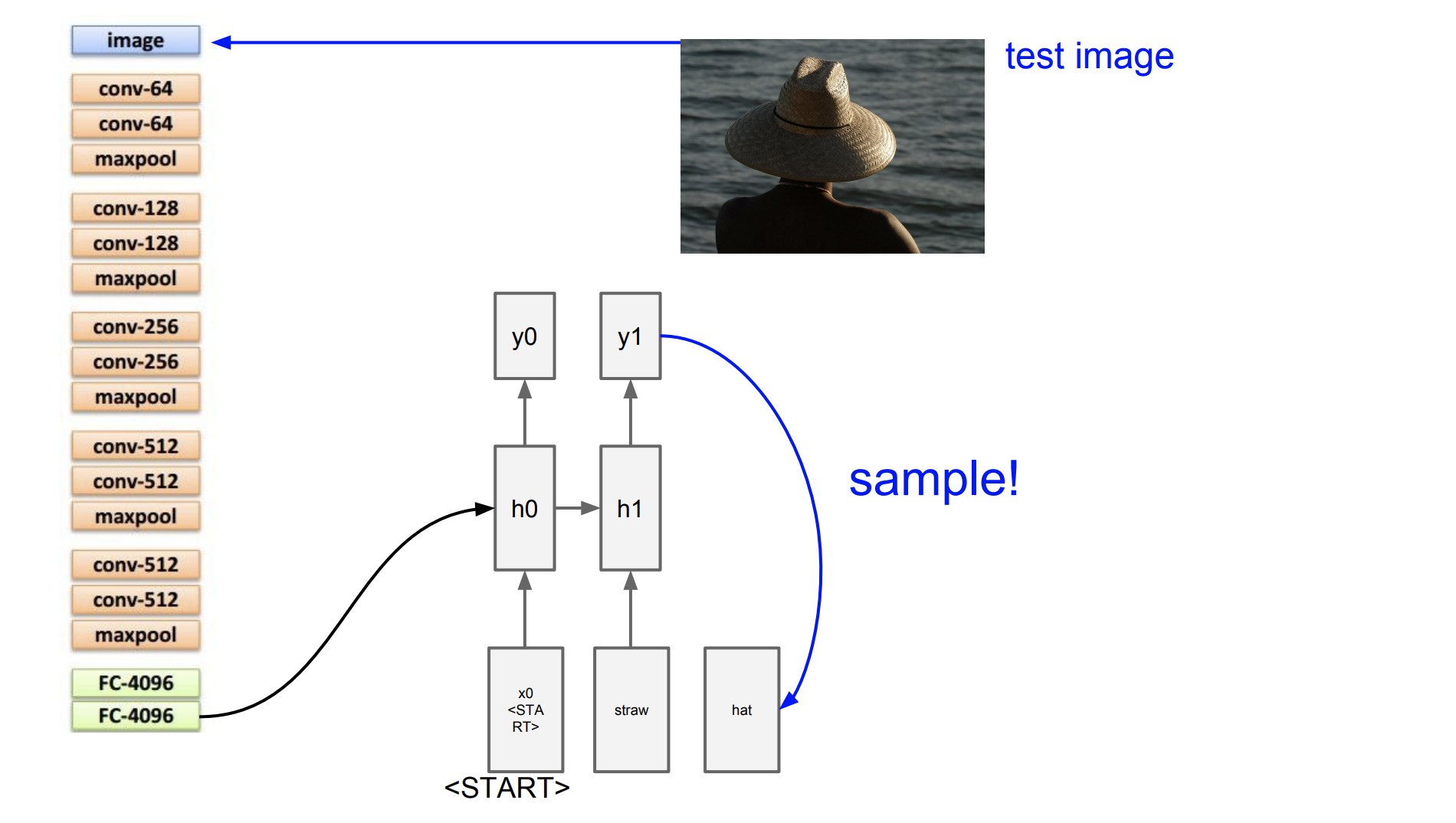
그리고 y1을 또 반복해서 구한 다음 input으로 또 넣는다.
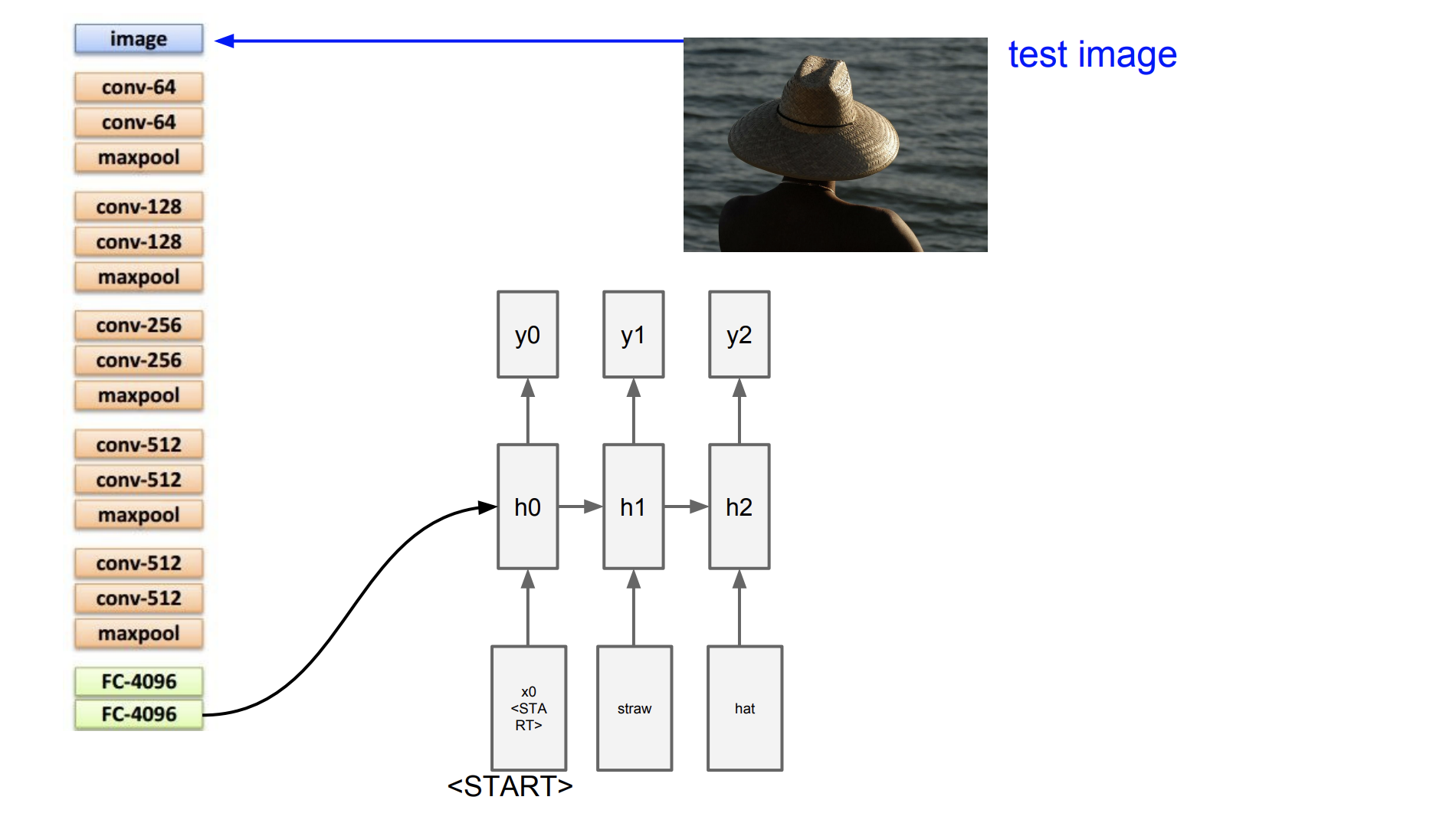
만약 y2가 end토큰이면 rnn이 종료된다.

이미지 captioning의 예시이다. 꽤나 잘 설명하고 있다.

하지만 완벽하지 않다. 첫번째 사진을 보면 여자는 손에 고양이를 들고 있다고 묘사하지만, 여자는 그저 고양이 질감의 모피 코트를 입었을 뿐이다.
오른쪽 위 사진을 보면 나무에는 거미가 있지만, 새라고 인식한다. 이는 훈련 데이터 안에 거미가 없어서 이렇게 묘사했을 확률이 높다.
Image Captioning with Attention
RNN을 수행할 때, Attention도 함께 수행해보자. 그러니까 다른 공간적 요소에 RNN이 집중하도록 하는 것이다.
Attention을 결합해서 RNN을 수행하는 내용은 겉핥기식으로 알아볼 것이다.
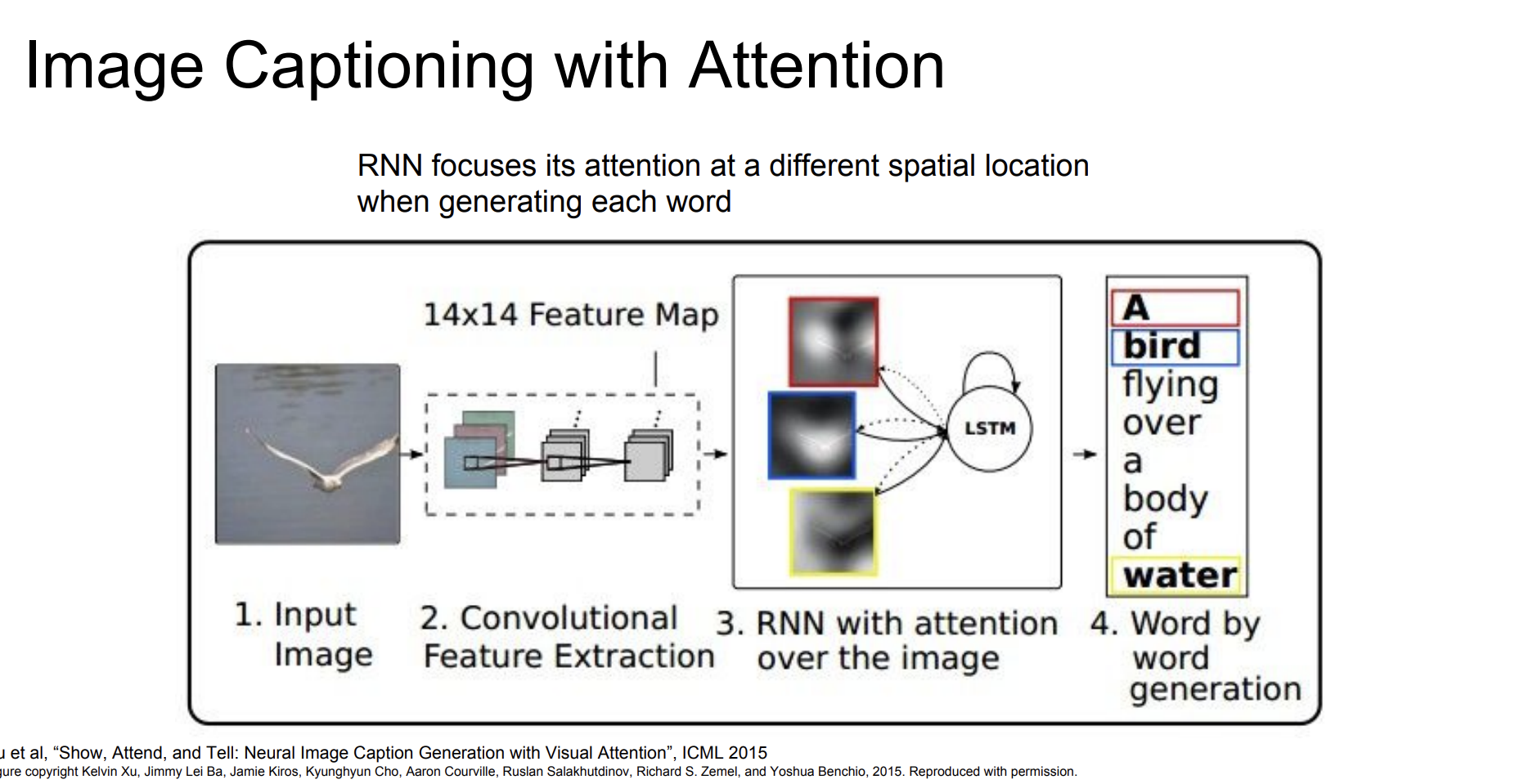
첫번째로 입력 이미지를 받는다.
Feature Map을 통해서 Feature들을 추출한다. 그리고 attention을 결합해서 RNN을 수행한다.
이를 통해 어떤 단어가 어떤 이미지의 위치를 나타내는지 알 수 있게 된다.
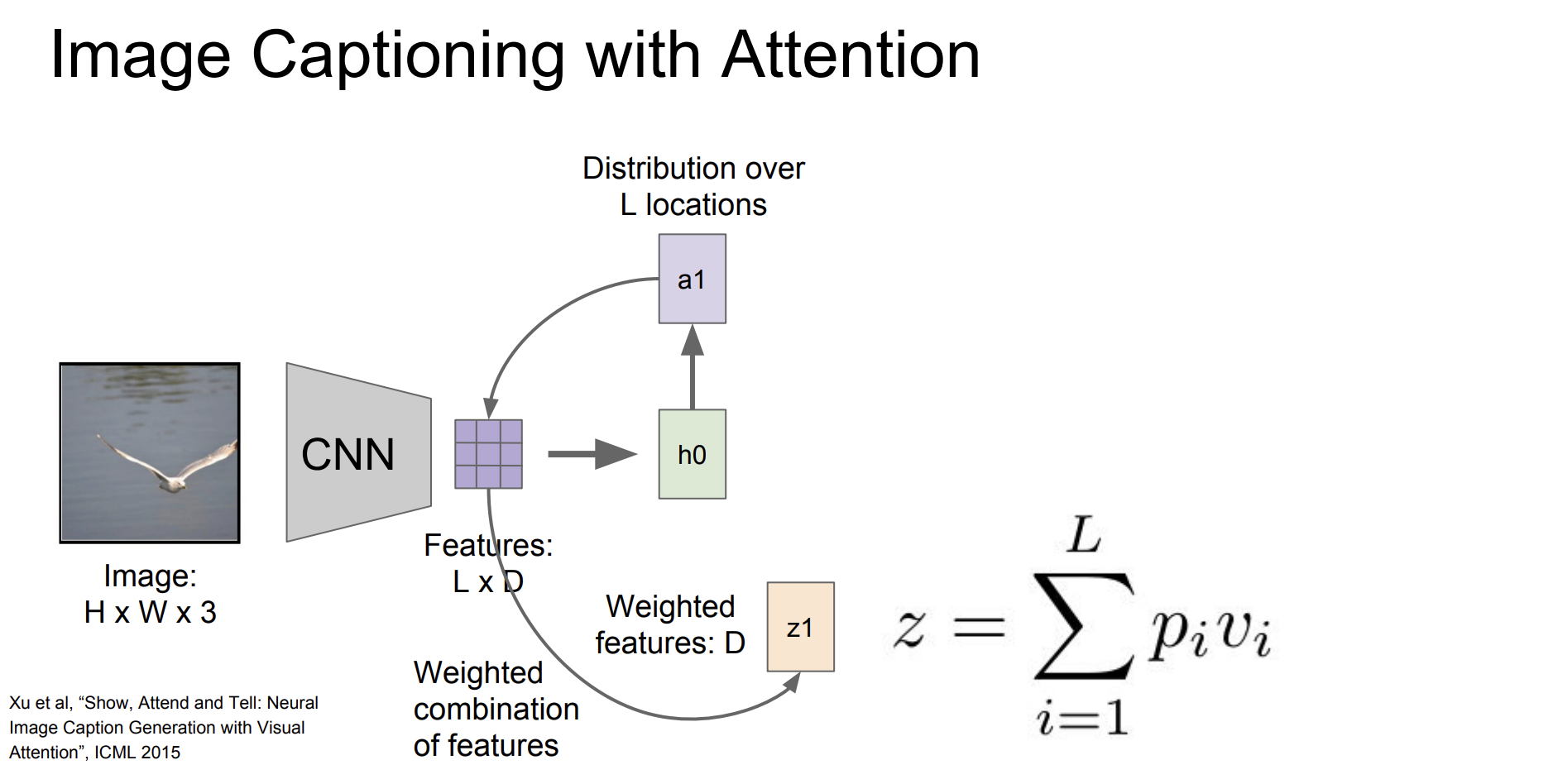
이전과 다른 것은 이미지를 grid로 표현한다는 점이다. 먼저 이미지 특징을 추출한다. CNN을 통해서 이미지에서 시각적 특징을 추출한다. L location에 대해서 분포를 구한 다음에 가중치 행렬을 구하고
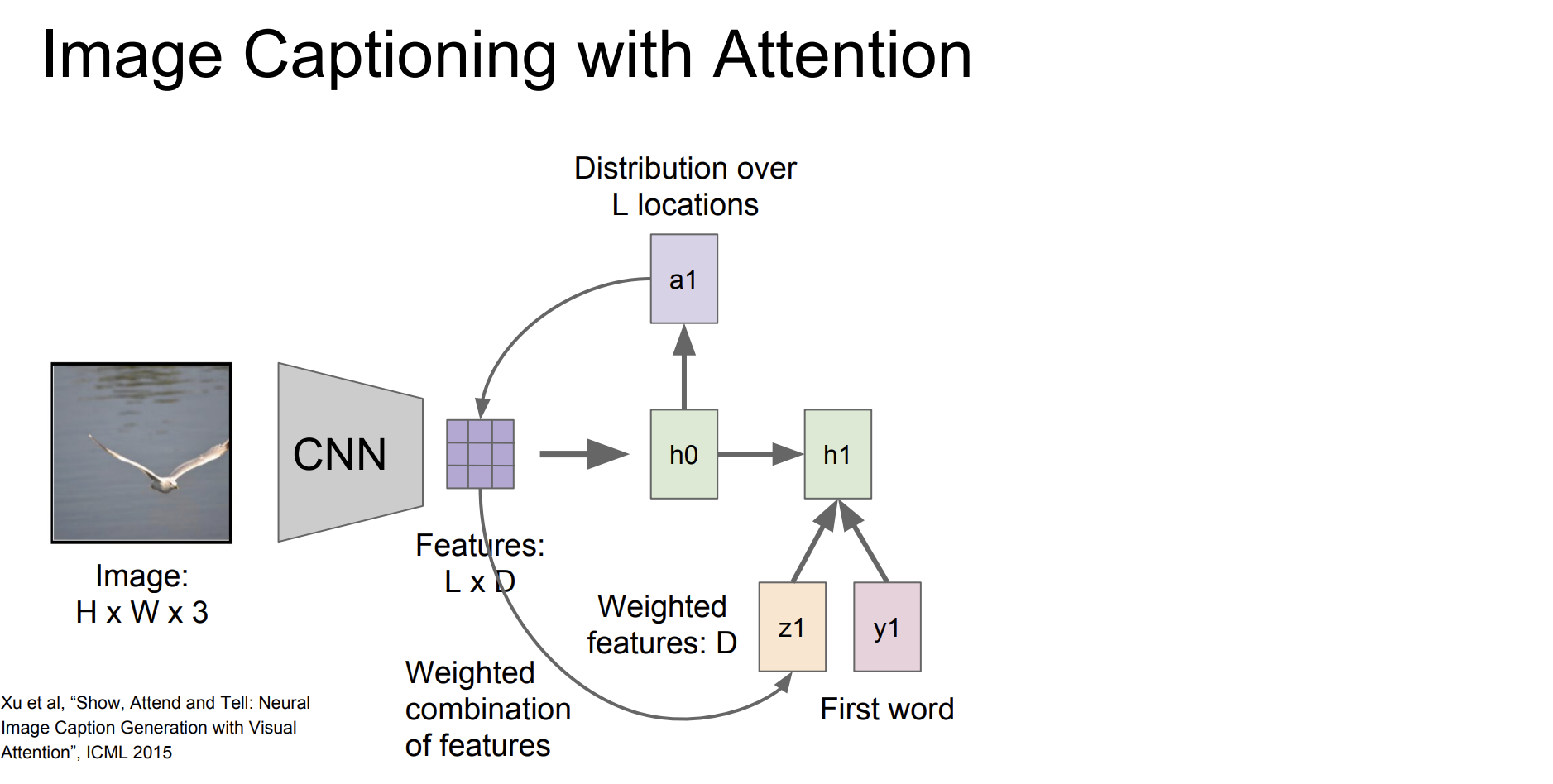
가중치 행렬과 첫번째 단어를 통해 다음 hidden state를 구한다.
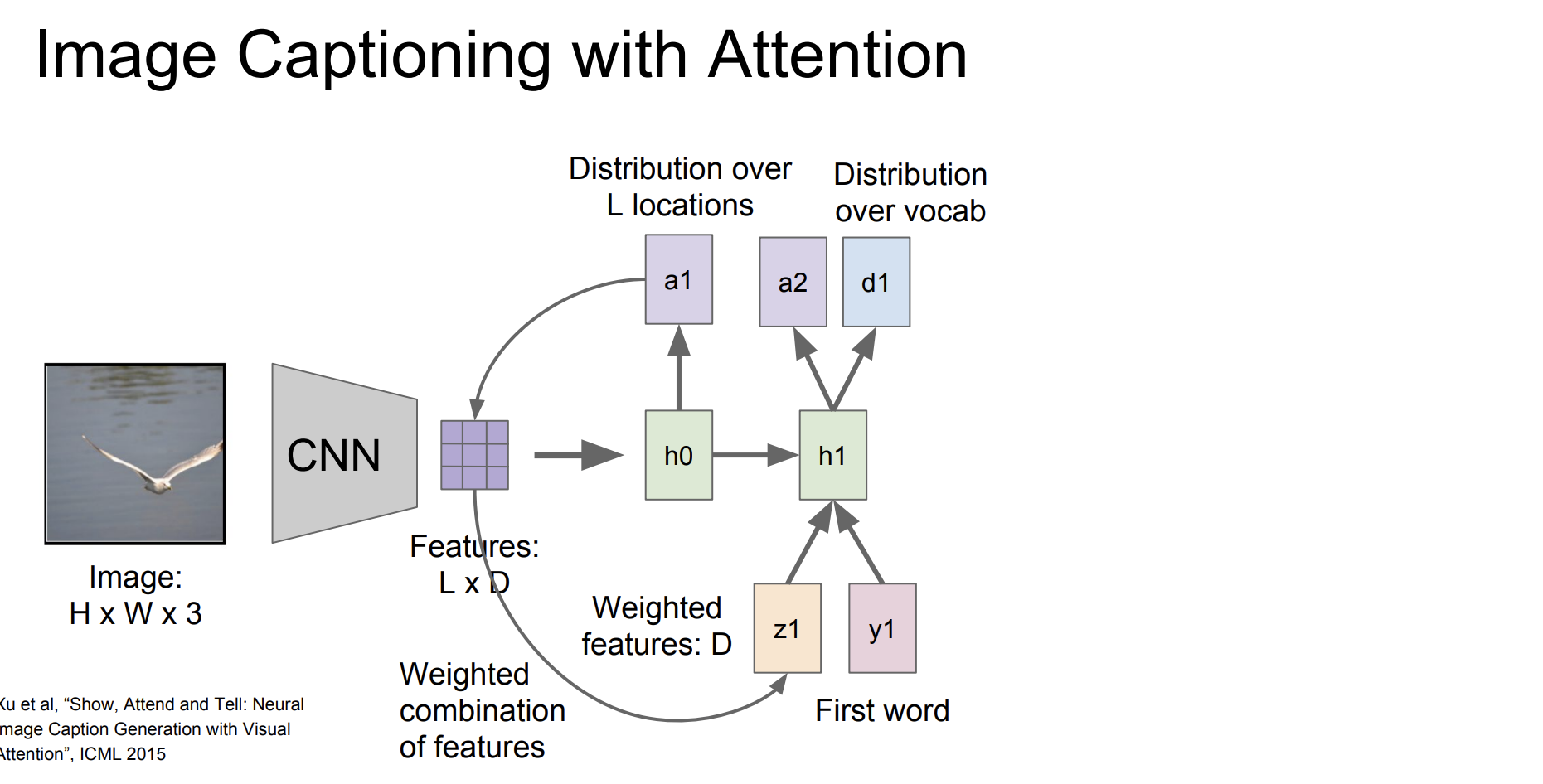
hidden state로 다음 L location에 대한 확률 분포와 vocab에 대한 확률 분포를 구한다. 따로 구하는 것이다.
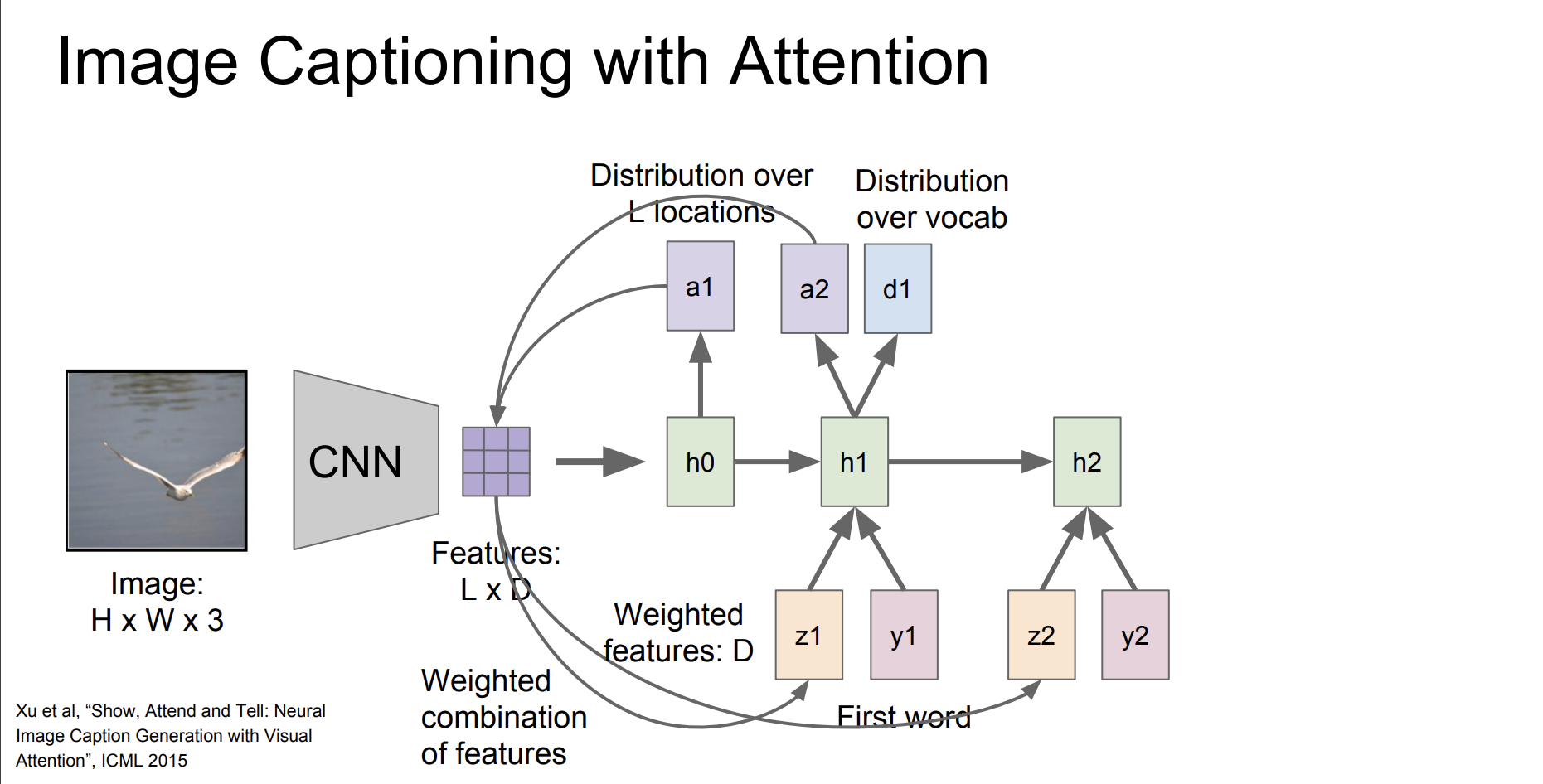
그리고 그 과정을 반복한다.
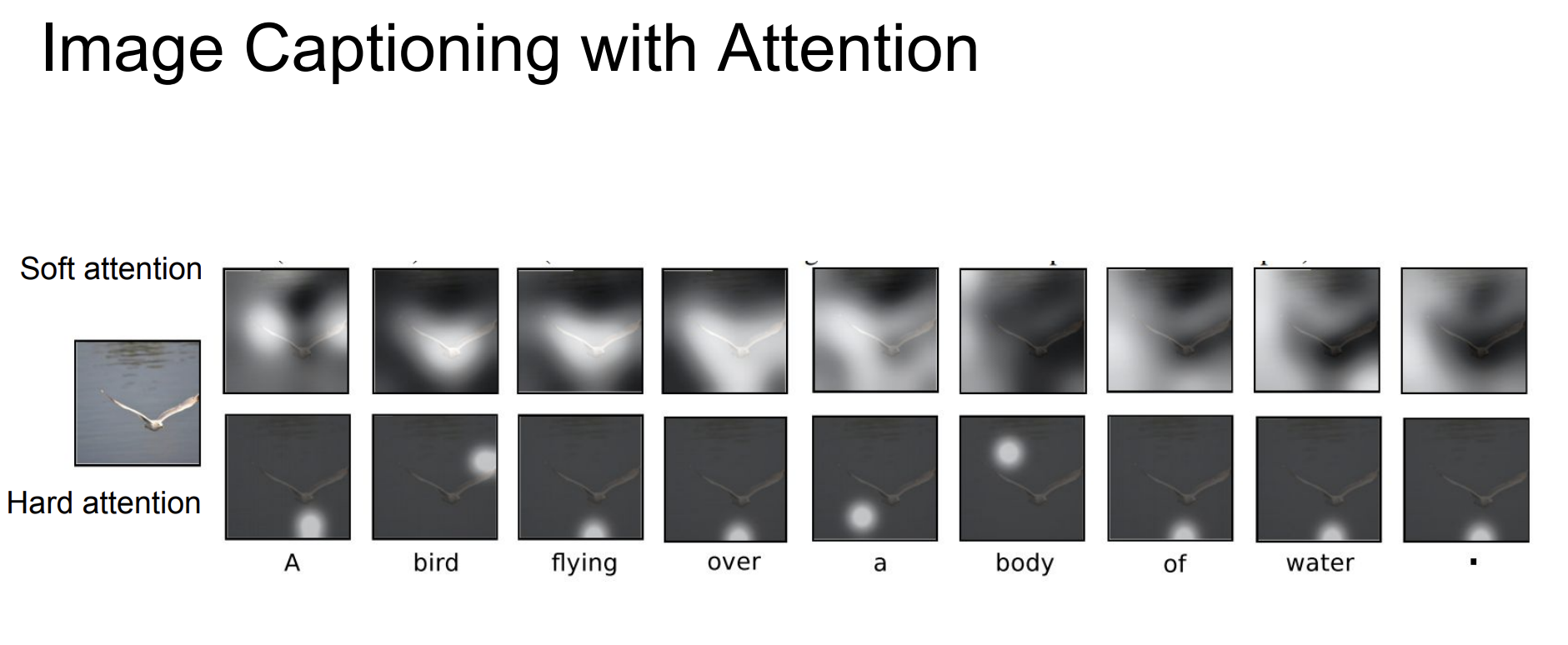

이렇게 한 단어에 대해서 attention을 통해 이미지의 어떤 특징에 집중해야하는지 알 수 있게 된다.
LSTM
Vanilla RNN Gradient Flow
기존 RNN 아키텍쳐의 문제점이 있다.
바로 기울기 폭발/소멸 문제이다.
우리는 forward 로 진행할 때, 항상 같은 W를 곱하게 된다.
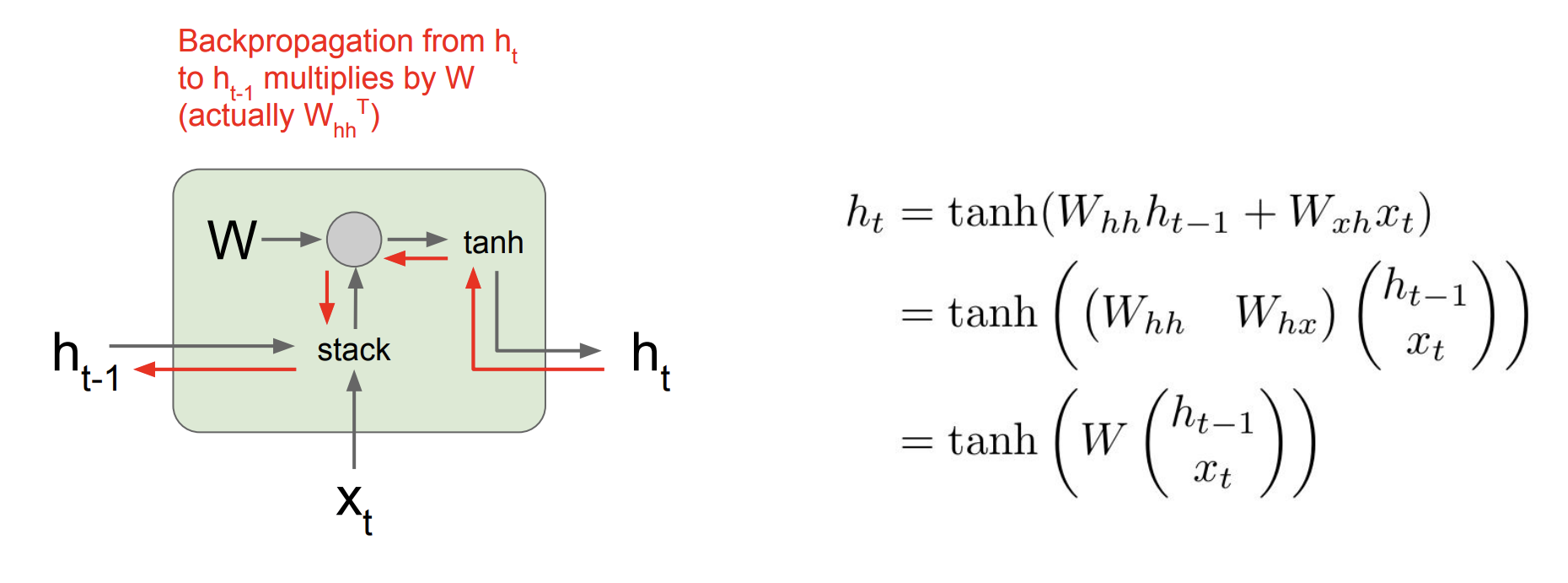
여기서 backpropagation을 진행하게 되면,
이전 기울기 ht와 W의 local gradient를 곱하면 ht-1의 기울기를 구할 수 있다. 문제는 항상 같은 W의 local gradient를 곱하게 되는 것이다. RNN의 가중치 행렬 W는 변하지 않기 때문이다.
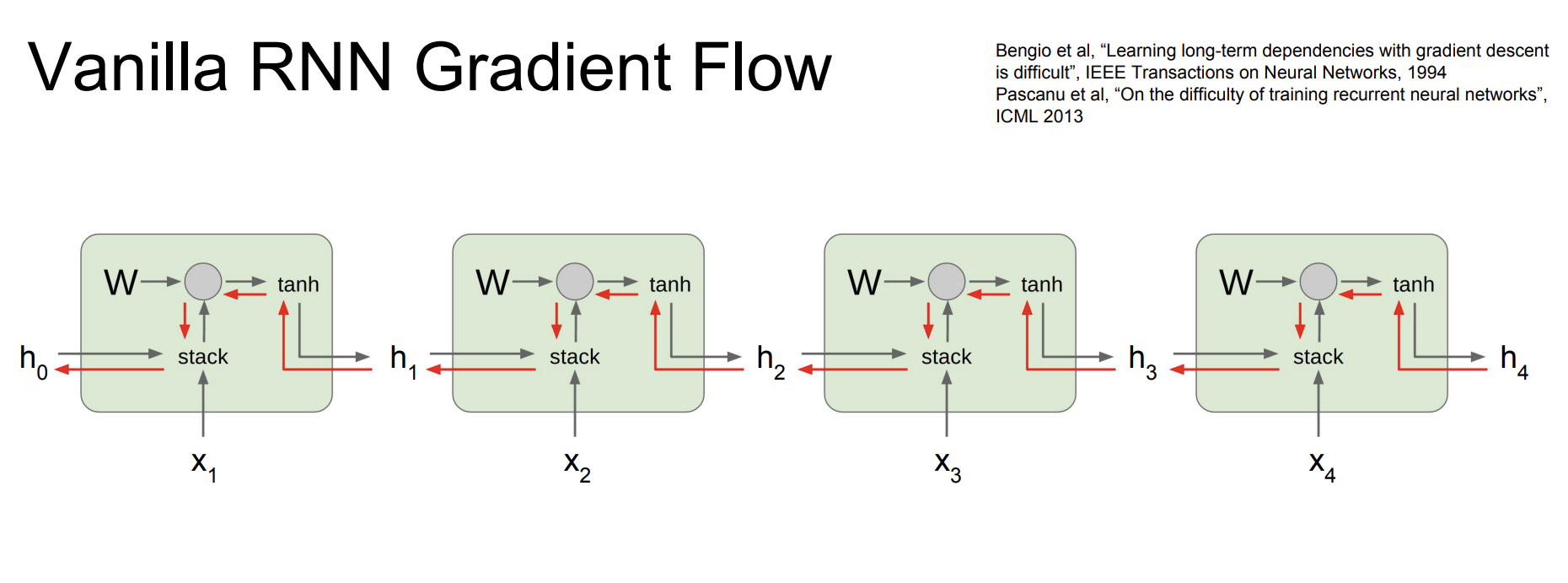
그래서 만약 W의 Largest singular value가 1보다 크면? Exploding gradients문제가 발생하고, Largest singular value가 1보다 작으면? Vanishing gradients문제가 발생한다.
그런데 Exploding gradients문제는 Gradient clipping이라는 방법으로 어찌저찌 해결은 가능하다.
하지만 기울기가 소멸하는 Vanishing gradients문제는 RNN자체 구조 문제라 해결할 수 없었다.
그래서 LSTM 구조를 도입했다.
Vanilla RNN의 구조는
라면,
LSTM의 구조는 좀 더 복잡하다.
RNN은 hidden state 즉 저장하는 cell이 하나지만 LSTM은 두개이다. c와 h가 있다.
이전 x, h를 곱하는 것이 아니라 4가지의 gate를 곱하게 된다.
- Forget gate : 잊을지를 정한다.
- Input gate : 남길지를 정한다.
- Gate gate : 얼마나 cell에 적을지 정한다.
- Output gate : 얼마나 cell에 들어낼지? 정한다.
input, forget, output gate는 모두 sigmoid함수를 사용한다. 즉 결과값이 0과 1사이다. Gate gate는 tanh함수를 사용하는데 결과값은 -1에서 1사이다.
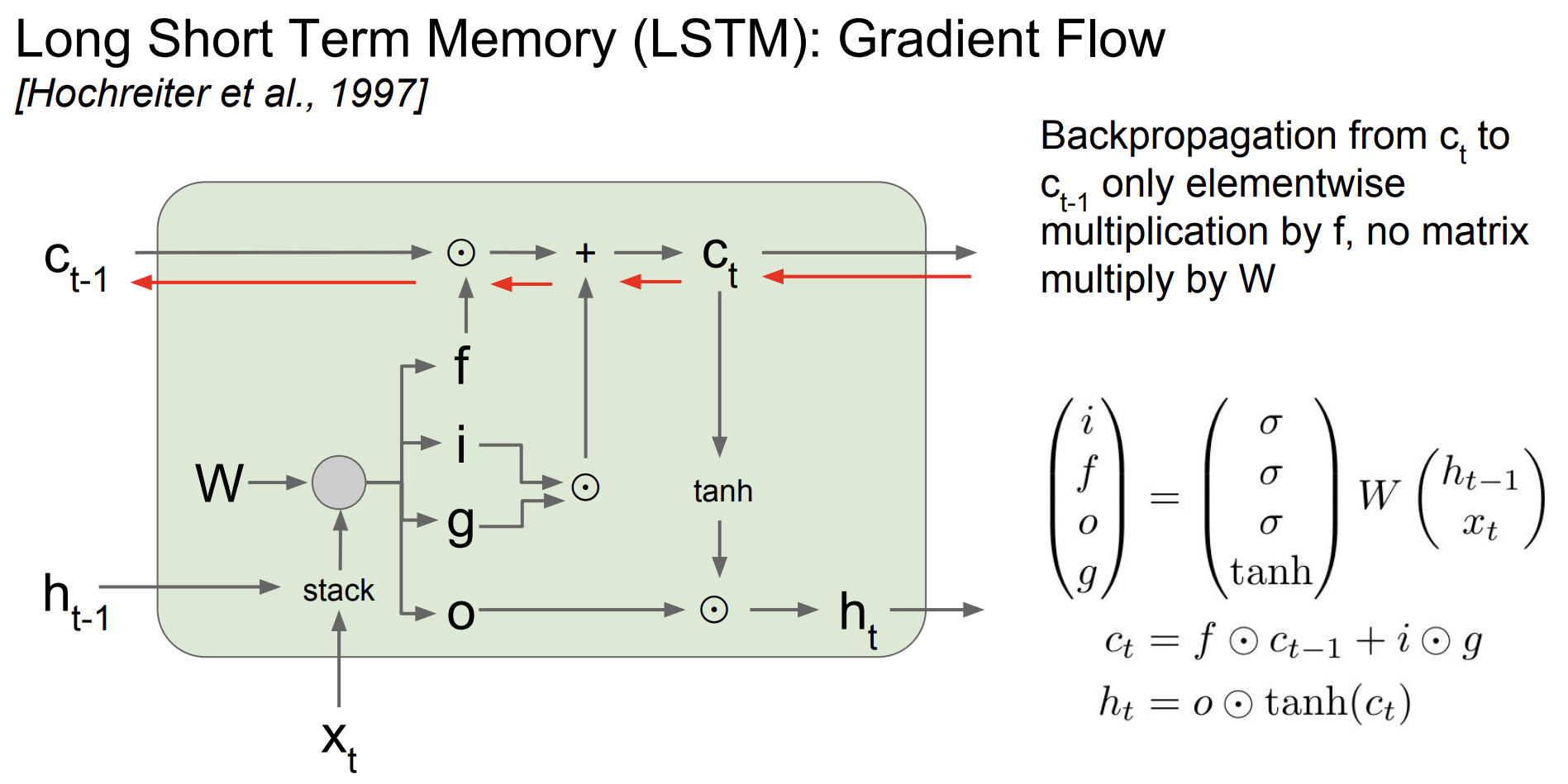
(LSTM는 위 그림과 식을 이해하는 것이 중요하다.)
LSTM이 vanilla RNN보다 backpropagation 관점에서 좋은 이유 2가지가 있다.
- 망각 게이트가 전체 행렬을 곱하는 것이 아니라 요소별로 곱하는 것이기 때문이다. 요소별 곱셈은 전체 행렬 곱셈보다 더 좋을 것이다.
- 모든 시간 단계마다 다른 가중치 행렬을 곱하게 될 것이다. 망각 게이트는 각 시간 단계마다 다를 것이기 때문에 그라디언트 소멸 및 폭발 문제가 해결된다.
- 망각게이트는 시그모이드 함수를 사용하기 때문에 0과 1사이의 값이 보장된다. 이러한 것들을 반복해서 곱하는것은 더 좋은 수치적 속성으로 나타나게 된다.
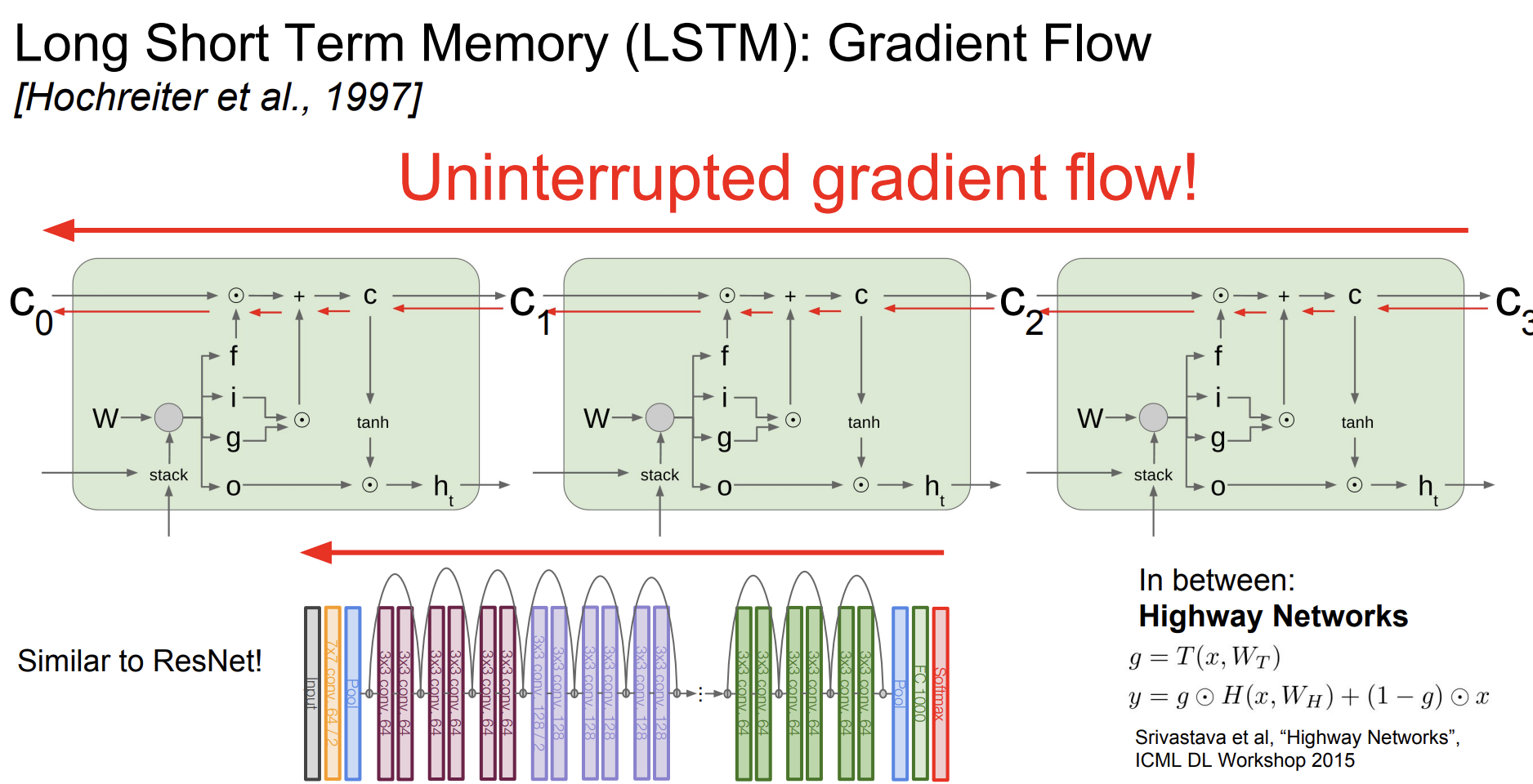
그래서 graident flow는 방해를 받지않고 구할 수 있게된다.
LSTM이 완전히 기울기 소멸에 대한 문제를 해결한 것은 아니다. 하지만 RNN에 비교하여는 확실히 기울기 소멸에 대한 문제를 해결했다.
LSTM보다 더 나은 아키텍쳐들은 요즘 연구의 hot topic이 되고 있다~!
