빅'데이터 처리의 기본패턴
제타바이트(Zettabyte, ) 단위까지 증가한 데이터, 즉 빅데이터를 처리하기 위한 방법은 성능이 좋은 컴퓨터를 써야한다. 혹은 컴퓨터를 여러 대를 연결한 뒤 작업을 분할해 사용할 수도 있다.
멀티 코어, 멀티 프로세서 등등의 컴퓨팅 자원을 엮어서 병렬 컴퓨팅(Parallel Computing), 분산 컴퓨팅(Distributed Computing) 을 통해 단일 컴퓨터로는 처리는커녕 디스크에 담아둘 수조차 없을 만큼 큰 사이즈의 데이터로 다뤄 볼 수 있다.
비슷한 개념으로 클러스터 컴퓨팅(Cluster Computing) 이라는 것도 있다.
맵리듀스(Mapreduce) 라는 것은 하둡, 스파크 등 빅데이터를 다루는 솔루션들의 가장 근간이 되는 프로그래밍 모델이다.
만약 처리해야 할 데이터의 양이 매우 많다. 그럼 해결할 방법은 간단하다
1) 많은 것을 잘게 나누어서
2) 각각을 처리한 후에
3) 처리된 것들을 모아서 통합 결과물을 낸다
맵리듀스 개념의 전부이다.
빅데이터 처리의 기본 패턴
컴퓨터 한 대로는 처리할 수 없는 분량의 데이터를 여러 대가 나눠서 처리하는 작업의 원리는 빅데이터 처리의 기본이다. 이것을 데이터분석의 Split-Apply-Combine Strategy 라고 하며, MapReduce는 이런 모델의 한 특수한 형태이다.
Split-Apply-Combine
1) 많은 것을 잘게 나누어서 (Split)
2) 각각을 처리한 후에 (Apply)
3) 처리된 것들을 모아서 통합 결과물을 낸다 (Combine)
는 전략은 SQL의 GroupBy 문, R의 plyr 함수 등 다양한 곳에 적용되고 있으며,
살펴볼 MapReduce 도 그러한 사례가 될 것이다.
아래 링크는 2004년 구글의 제프리 딘(Jeffrey Dean)과 산제이 기마와트(Sanjay Ghemawat)가 발표한 MapReduce: Simplified Data Processing on Large Clusters 란 논문이다. 이 논문이 오늘날 빅데이터용 클러스터 컴퓨팅에 사용되는 주요 프로그래밍 모델인 맵리듀스를 최초로 제안한 공식 자료이다.
MapReduce: Simplified Data Processing on Large Clusters
- map() 함수는 Split된 부분 데이터를 가져다가 어떤 특별한 조작을 가하는, Apply 역할을 하는 함수
- reduce() 함수는 map() 함수가 만들어낸 결과물을 어떤 기준에 따라 한군데로 다시 모아내는, Combine 역할을 하는 함수
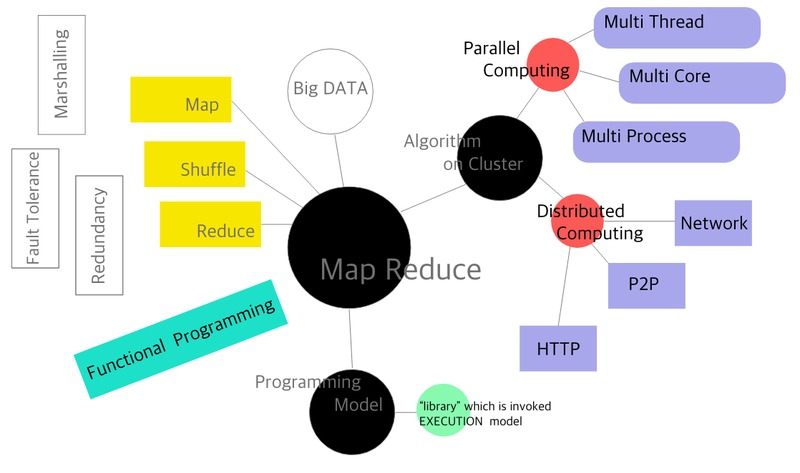
분산환경의 빅데이터 처리
[맵리듀스의 정의와 관련된 개념]
- 클러스터 위에 동작하는 알고리즘
- 프로그래밍 모델입니다.
[맵리듀스의 로직]
- Map, Reduce , Shuffle
함수형 프로그래밍(Functional Programming) 역시 중요한 개념이다.
병렬, 분산, 클러스터 컴퓨팅
병렬 컴퓨팅(Parallel Computing)
한 대의 컴퓨터 안에서 CPU 코어를 여러 개 사용해서,
한 대의 컴퓨터가 처리하는 데이터의 총량과 처리속도를 증가시키자는 것
[멀티 프로세스 (Multiprocessing)]
- 프로세스는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 의미.
스케줄링의 대상이 되는 작업(task)이라는 용어로도 쓰임. 프로세스 관리는 OS에서 함 - 멀티 프로세스는 2개 이상의 프로세스를 사용하는 것
[멀티 스레드 (Multithreading)]
- 스레드(thread)는 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위. 일반적으로 한 프로그램은 하나의 스레드를 가짐
- 멀티 스레드는 2개 이상의 스레드를 사용하는 것
분산 컴퓨팅
여러 대의 컴퓨터가 네트워크로 연결된 상황을 전제로 하는 것이다.
- P2P(Peer to Peer)
- HTTP
- Network
클러스터 컴퓨팅
클러스터 컴퓨팅이 위의 병렬 컴퓨팅과 분산 컴퓨팅을 통합하는 개념처럼 제시되어 있으며, 분산 컴퓨팅과 매우 혼용되고 있기도 하다.
- 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합
- 보통 노드와 관리자로 구성되어 있음
- 클러스터 노드 : 프로세싱 자원을 제공하는 시스템
- 클러스터 관리자 : 노드를 서로 연결하여 단일 시스템처럼 보이게 만드는 로직을 제공
- 대표적인 기술
- 병렬 컴퓨팅(Parellel Computing)
- 분산 컴퓨팅(Distributed Computing)
- 클라우드 컴퓨팅(Cloud Computing)
클러스터는 여러 대의 컴퓨터들이 연결되어 있는 것이며, 이때 컴퓨터를 어떻게 연결하고 컴퓨팅 자원을 관리할 것인지에 따라서 많은 클러스터 관련 기술이 알려져 있다.
하둡과 스파크
하둡은 대용량 데이터를 분산 처리할 수 있는 자바 기반의 오픈소스 프레임워크이다.
파이썬 함수
파이썬 함수는 다음과 같은 기능을 할 수 있다.
- 함수는 다른 함수의 인자로 전달될 수 있다. (= 인자(매개변수)로 전달이 가능)
- 함수는 변수에 할당될 수 있다.
- 함수는 다른 함수의 결과로서 반환될 수 있다. (=다른 함수의 반환값)
함수형 프로그래밍과 맵리듀스
데이터 컬렉션
파이썬 자료 구조 중에 List, Tuple, Dictionary, Set와 같은 형태의 자료형을 컬렉션(Collection) 이라고도 하며, 다른 말로는 컨테이너(Container)라고 부른다.
Collection을 사용하고 싶으면 다음과 같이 import 하면 된다.
import collectionscollection에서 제공하는 아래 링크에서 확인해보자. 너무 많다.
python collection
collection 모듈 중 deque, namedtuple(), defaultdict 은 많이 사용하게 되니 꼭 읽어보자.
컬렉션을 이야기한 이유는 빅데이터라는 대용량의 자료를 표현할 때, 해당 타입으로 저장하는 경우가 대부분이기 때문이다.
맵리듀스 기본 함수 알아보기
파이썬에서 함수를 데이터 컬렉션에 적용하는 패턴에는 대표적으로 3가지가 있다.
- map
- filter
- reduce
map(매핑)
컬렉션의 모든 요소에 함수를 적용(=매핑)한다.
함수 를 컬렉션 의 항목에 매핑하는 함수를 수식으로 나타내보자.
mynum = ['1','2','3','4']
mynum_int = list(map(int, mynum)) # mynum의 각 원소에 int 함수를 적용
print(mynum_int)
# mynum_int의 각 원소 x에 lambda x : x*x 함수를 적용
mynum_square = list(map(lambda x : x*x, mynum_int))
print(mynum_square)
---------------------------------------------------------------
[1, 2, 3, 4]
[1, 4, 9, 16]filter(필터링)
컬렉션 내의 요소를 선택(=필터링)한다.
컬렉션 의 요소 x에 대해서 조건 에 부합하는 만을 필터링하는 수식
mynum = range(-5, 5)
# mynum의 각 원소 x에 대해 lambda x: x > 0 인지 체크하는 필터를 적용
mynum_plus = list(filter(lambda x: x > 0, mynum))
print(mynum_plus)
------------------------------------------------------------
[1, 2, 3, 4]reduce(리듀싱)
reduce(리듀싱)은 컬렉션을 축약한다.
가장 일반적인 예로는 요소들을 합하는 시그마 연산이 있으며, 수식은 컬렉션 의 요소 의 합을 구해서 축약한다.
from functools import reduce
mynum = [1, 2, 3, 4, 5]
# reduce는 내부에 관리하는 x 변수에 mynum의 각 원소 y를 차례차례 더하여 x에 반영한다.
add = reduce((lambda x, y: x + y), mynum)
print(add)
------------------------------------------------------------
15정리
맵리듀스의 주요 개념
맵리듀스는 4가지 단계가 있다.
Split - Map - Shuffle - Reduce
Input과 Output은 각각의 키-값 쌍으로 존재한다.
| input | output | |
|---|---|---|
| split | Text file | k1, v1 |
| map | k1, v1 | list(k2, v2) |
| shuffle | list(k2, v2) | k2, list(v2) |
| reduce | k2, list(v2) | list(k3, v3) |
