이상치란 대부분 값의 범위에서 벗어나 극단적으로 크거나 작은 값을 의미한다.
이상치를 발견하면 어떤 작업을 해줘야 하나.
- 이상치를 삭제한다.
- 원래 데이터에서 삭제
- 이상치끼리 따로 분석
- 다른 값으로 대체
- 데이터가 적을 경우, 이상치를 삭제하기보단 다른 값으로 대체하는 것이 나은 방안이다.
- 최댓값, 최솟값을 설정해 데이터의 범위를 제한할 수 있다.
- 결측치와 마찬가지로 다른 데이터를 활용하여 예측 모델을 만들어 예측값을 활용할 수도 있다.
- binning(구간화)을 통해 수치형 데이터를 범주형으로 바꿀 수도 있다.
등등 사실 이상치를 찾는 것(anomaly detection)은 방법이 매우 넓디(?) 넓다.
그 중에서 가장 간단하고 자주 사용되는 z-score를 우선 사용해보자.
z-score method
이상치 데이터의 인덱스를 반환하는 함수(Outlier)를 구현하는 순서는 아래와 같다.
컬럼(col), DataFrame(df), 기준(z)
[코드]
def outlier(df, col, z):
return df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].indexabs(df[col] - np.mean(df[col]))
데이터에서 평균을 빼준 것에 절대값을 취한다.abs(df[col] - np.mean(df[col]))/np.std(df[col])
위에 한 작업에 표준편차로 나눠줍니다.df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index
값이 z보다 큰 데이터의 인덱스를 추출합니다.
이렇게 간단해 보이는 z-score도 단점이 있다.
1. 평균과 표준편차 자체가 이상치의 존재에 크게 영향을 받는다.
2. 작은 데이터셋의 경우 z-score의 방법으로 이상치를 알아내기 어렵다. 특히 12개 이하인 데이터셋에서는 불가능하다.
z-score 방법의 대안으로 사분위범위수 IQR(Interquartile range)로 이상치를 알아낼수 있다.
IQR method
사분위범위수 IQR(Interquartile range)을 이용하여 이상치를 찾아낼 수 있다.
IQR=Q3−Q1
Q3, Q1 = np.percentile(data, [75 ,25])
IQR = Q3 - Q1
IQR 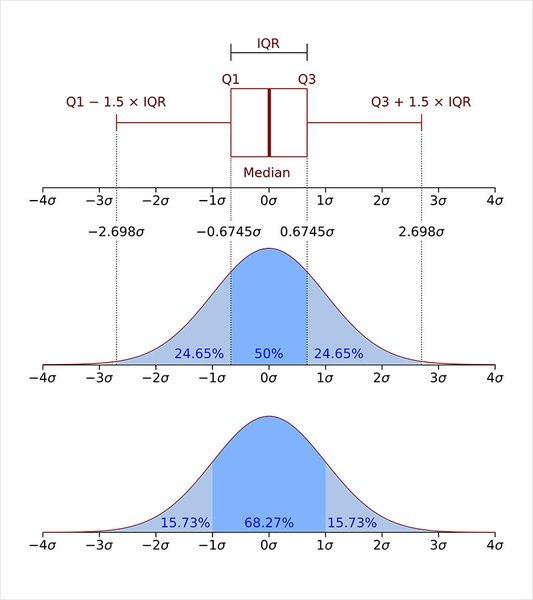
이상치를 가지고 있는 데이터만 추출하는 식을 아래처럼 구현하면 된다.
data[(Q1-1.5*IQR > data)|(Q3+1.5*IQR < data)]