앞선 포스팅에서 Model의 복잡함을 좀 더 단순한 W를 선택하도록 도와주는 역할을 하는 것이 Regularization(정규화)이라고 말했다.
일반적인 Loss Function에서는 2가지 항을 가지게 된다.
- data loss
- regularization loss
- hyperparameter : lambda : 두 항 간의 trade-off
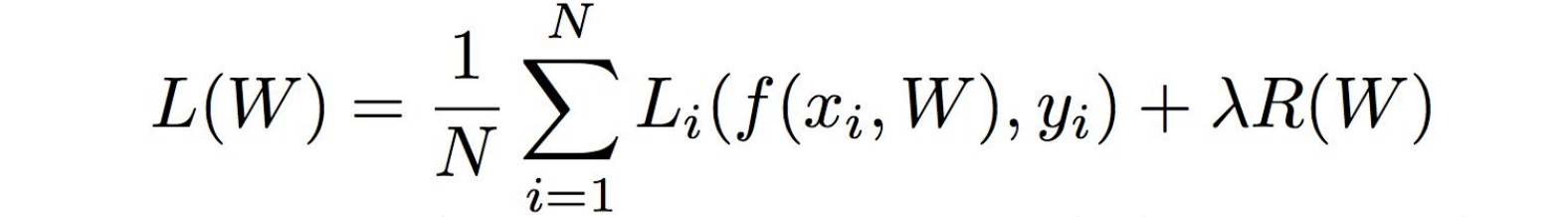
정규화의 2가지 역할에 대해 알 수 있다.
- 우리가 모델이 더 복잡해 지지 못하도록 한다.
- 모델에 soft penalty를 추가하는 것으로 본다.
모델은 여전히 더 복잡한 모델이 될 가능성이 있는 것이다.
하지만 soft한 제약을 추가하면 "만약 너가 복잡한 모델을 계속 쓰고 싶으면, 이 penalty를 감수해야 할 거야!"라는 것과 같다.
정규화의 종류
기계학습 분야를 통틀어서 자주 사용되며, 모델이 트레이닝 데이터 셋을 완벽하게 핏하지 못하도록 모델의 복잡도에 패널티를 부여하는 방법이다.
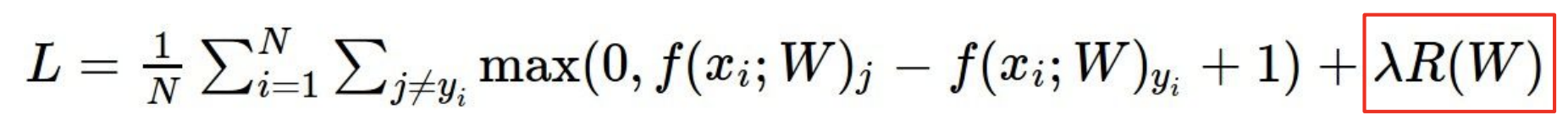

가장 일반적으로 쓰는 것은 L2이다.
그럼 L2나 L1은 어느때 쓸지 어떻게 판단하냐? 밑에와 같은 매개변수들이 있다고 생각해보자.
L2는 classifier의 복잡도를 상대적으로 , 중 어떤 것이 더 매끄러운지 측정한다. 그러므로 L2는 를 더 선호할 것이다. 왜냐하면 L2에서는 가 요소들의 norm이 전체적으로 퍼져있으므로 "덜 복잡하다"고 여길 것이다.
반면 L1은 가중치 에 0의 갯수레 따라 모델의 복잡도를 다루므로, 을 더 선호한다.
Softmax Classifier(Multinomial Logistic Regression)
Deep Learning에선 Multiclass-SVM Loss보단 softmax를 더 많이 쓴다.
Multiclass-SVM Loss에서는 스코어 자체에 대한 해석을 고려하지 않았다. 단지 정답 클래스가 정답이 아닌 클래스보다 더 높은 스코어를 내기만을 원했다.
반면에 Softmax Classifier의 손실함수(Loss Function)는 스코어 자체에 추가적인 의미를 부여한다.

위 수식을 이용해 스코어를 가지고 클래스별 확률분포를 계산하게 될 것이다. 스코어를 전부 이용하는데 스코어들에 지수를 취해서 양수가 되게 만든다. 그리고 그 지수들의 합으로 다시 정규화시킨다.
softmax함수를 거치게 되면 확률분포를 얻을 수 있으며, 그것은 바로 해당 클래스일 확률이 되는 것이다. 확률이기 때문에 0 ~ 1 사이의 값일 것이며 모든 확률들의 합은 1일 것이다.
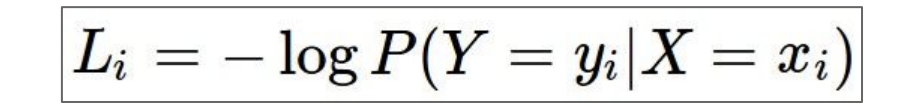
확률값과 실제값을 비교해보자.
만약 이미지가 고양이라면 실제 고양이일 확률은 1이 되며, 나머지 클래스의 확률은 0이 된다.
우리가 지금 하고자 하는 것은 softmax에서 나온 확률이 정답클래스에 해당하는 클래스의 확률을 1에 가깝게 하는 것이다. 그렇게 되면 Loss는 "-log(정답클래스확률)"이 될 것이다.
Log를 최대화 시키는 것이 그냥 확률값을 최대화 시키는 것보다 쉽다. Log는 단조증가함수이기 때문이다. 하지만 손실함수는 "얼마나 좋은지"가 아닌 "얼마나 구린지"를 측정하는 것이기 때문에 Log에 -를 붙힌다.
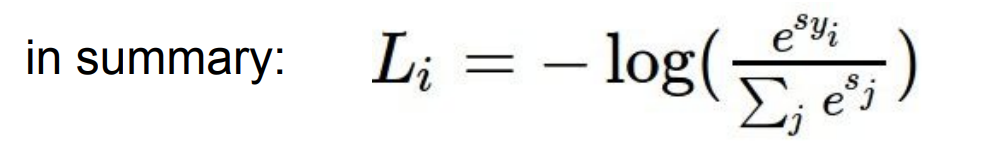
스코어가 있으면, softmax를 거치고, 나온 확률 값에 -log를 추가해주면 된다.
그럼 위 식의 연산과정은 어떻게 되는 것인지 그림으로 살펴보자.

첫번째, 파란색 박스의 점수들은 Linear Classifier로 나온 스코어들이다.
두번째, 빨간색 박스는 지수화한 숫자이다.
세번째, 초록색 박스는 스코어들의 합이 1이 되도록 정규화시켜준다.
네번째, 마지막 보라색은 정답 스코어에만 -log를 씌어준다.
[질문 time]
Q1. What is the min/max possible loss ?
softmax loss의 최소/최대값은?
A1. min: 0, max: inifinite. 고양이로 잘 분류했다면 Loss는 0에 가깝게 나올 것이다.
Q2. Usually at initialization W is small so all .
What is the loss?
만약 S가 모두 0 근처에 모여 있는 작은 수 일때 Loss는 어떻게 될까?
A2. -log 1/C 또는 log C
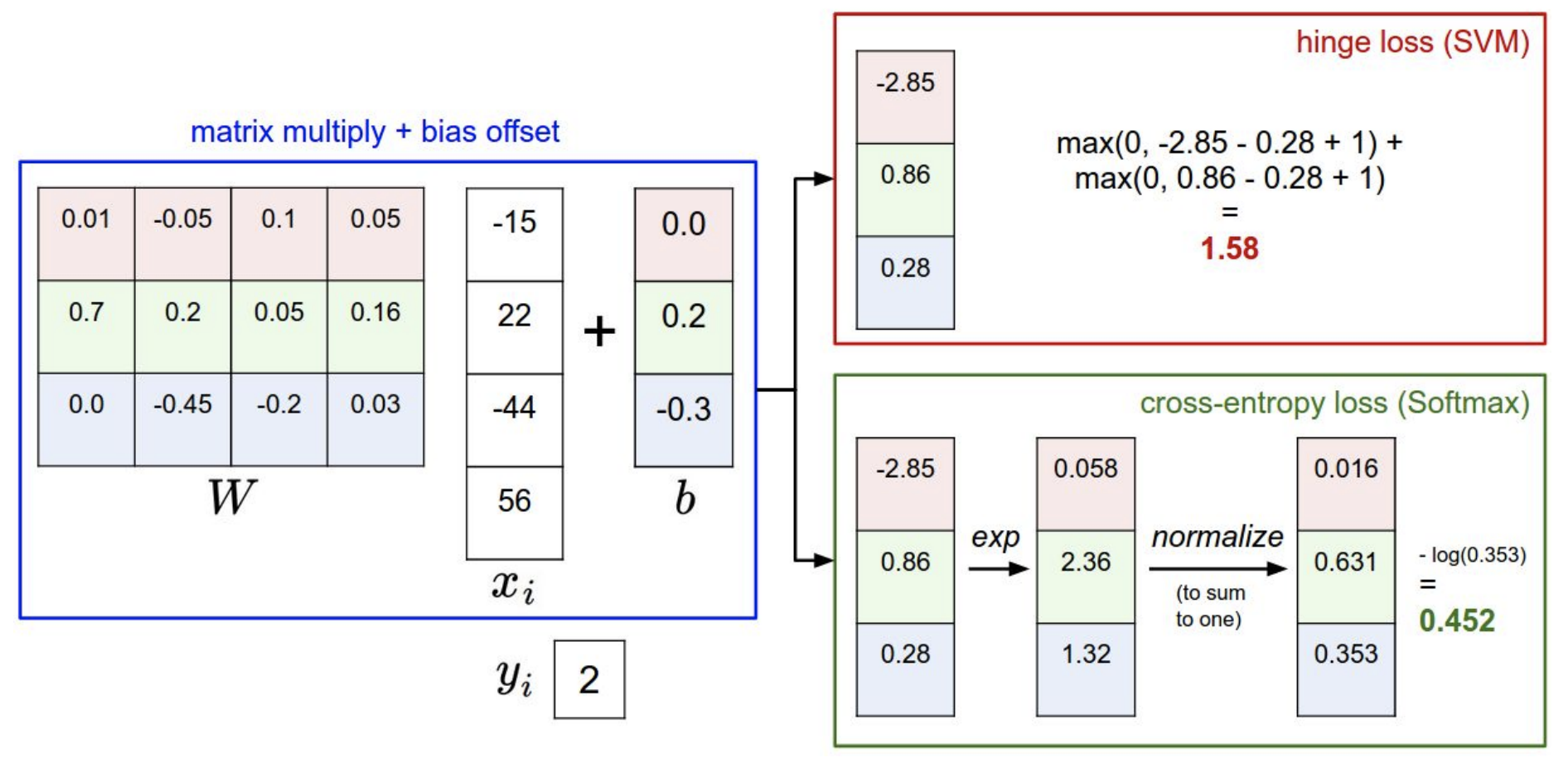
SVM에서는 정답 스코어와, 정답이 아닌 스코어 간의 마진(margins)를 신경쓴다.
softmax는 확률을 구해서 -log(정답클래스)에 신경을 쓴다.
SVM은 일정 선(margins)를 넘기만 하면 더이상 성능 개선에 신경쓰지 않지만,
softmax는 더~~~ 좋게 성능을 높이려 한다.
정리
지금까지 지도학습(Supervised Learning)에 관한 전반적인 개요를 알아보았다.
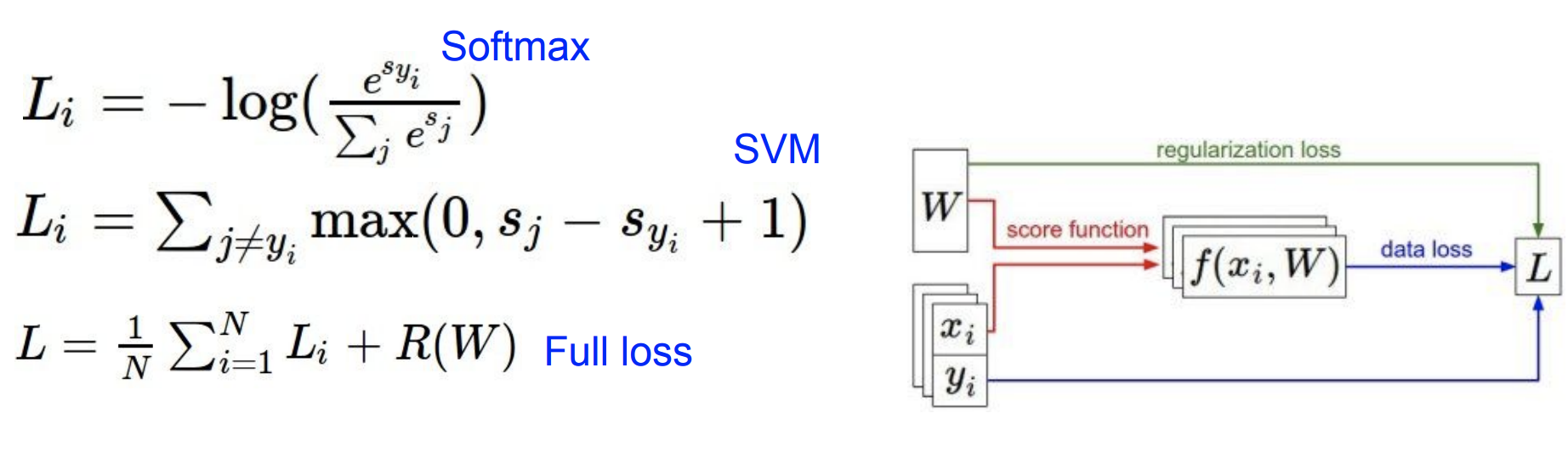
loss function은 모델의 예측값이 정답값에 비해 "얼마나 구린지"를 측정하며,
는 모델의 "복잡함"과 "단순함"을 통제하기 위해 Loss function에 Regularization term을 추가하는 것이다.
위 그림의 오른쪽 끝에 최종는 Loss Function가 최소가 되게 하는 가중채 행렬이자 파라미터인 행렬 를 구하게 되는 것이다.
그럼 최적, 최고의 는 어떻게 찾는 것일까?
이 내용은 다음 포스팅에서 Optimization으로 소개하겠다.
