
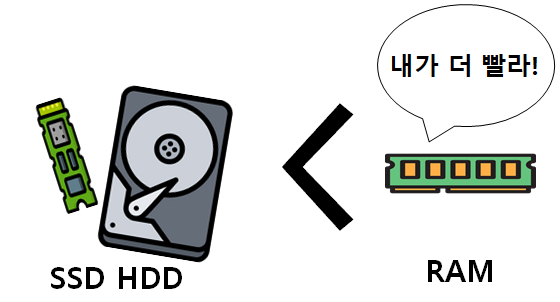
1. 레디스란?
레디스는 시스템 메모리를 사용하는 키-값 데이터 스토어
인메모리 상태에서 데이터를 처리함으로 흔히 사용하는 RDBMS나 NOSQL보다 빠르고 가볍게 동작
기존 관계형 데이터베이스는 디스크에 저장하고 조회하기 때문에 상대적으로 느림
2. 어디에서 사용하는가?
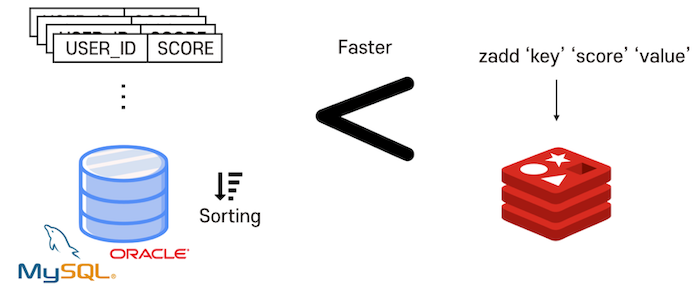
조회수와 같은 실시간 데이터를 조회하거나 데이터를 삽입할 때 사용
실시간 데이터를 RDBMS로 사용하게 되면 조회수가 늘어날 때마다 넣고 조회하는 것을 계속 반복해야함 → 엄청난 자원 소모됨
레디스를 이용해서 데이터를 캐싱 처리하고, 일정한 주기에 따라 RDBMS를 업데이트 한다면 DB에 가해지는 부담을 크게 줄일 수 있음
3. 레디스 데이터 구조
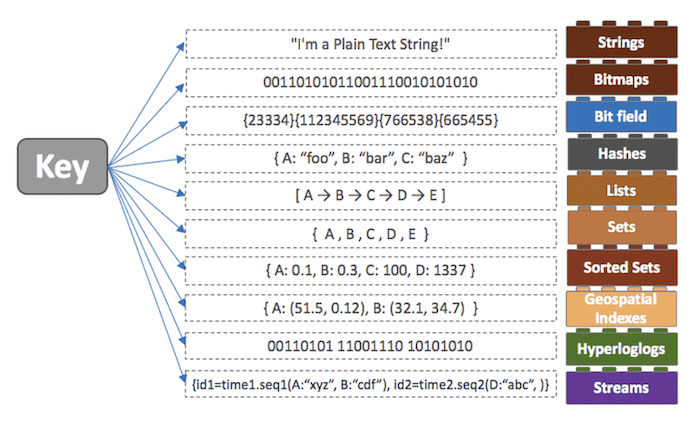
레디스는 데이터 타입을 지원하지 않고 오직 몇 가지 로우 레벨의 데이터 타입을 지원함
- 문자열(String)

거의 대부분의 데이터를 문자열로 표현
> set hello world
OK
> get hello
"world"2.해시(Hash)


해시는 필드를 가질 수 있는데 사용자 정보라는 해시가 있으면 이메일과 닉네임을 가질 수 있고 전체를 가져오거나 개별 필드를 가져올 수 있다.
key에 대한 filed의 개수에는 제한이 없어서 여러 방법으로 사용이 가능하다.
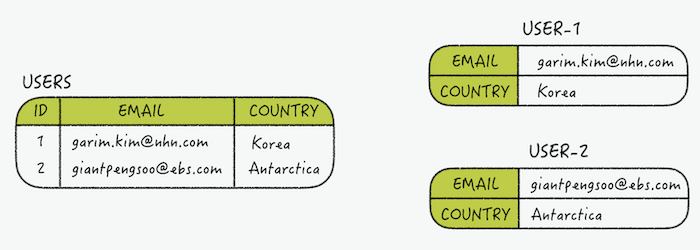
> hmget user-2 email country
1) "giantpengsoo@ebs.com"
2) "Antarctica"- 리스트(List)
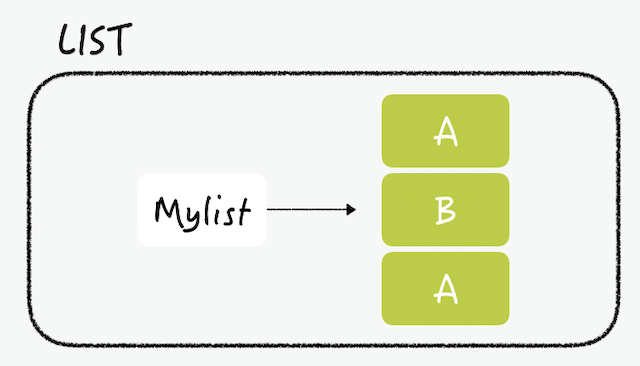
리스트 안의 데이터는 문자열만 가능
LPUSH mylist B # now the list is "B"
LPUSH mylist A # now the list is “A","B"
RPUSH mylist A # now the list is “A”,”B","A"4.셋(Set)
리스트와 유사한 특징을 보이지만 고유 값을 저장한다는 점에서 차이점
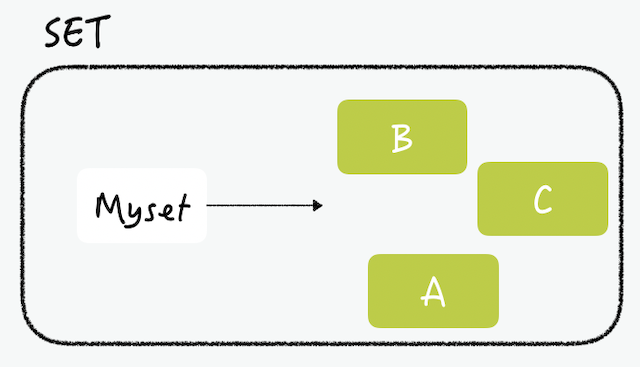
set은 정렬되지 않은 문자열의 모음, 아이템 중복 불가
교집합, 합집합, 차집합 연산을 레디스에서 수행할 수 있기에 set은 객체 간의 관계를 표현할 때 좋다.
> sadd project:1000:tags 1 2 5 77
(integer) 4
> smembers project:1000:tags
1. 5
2. 1
3. 77
4. 2- stored set

stored set은 주로 sort가 필요한 곳에 사용된다.
정렬된 형태로 저장되기에 인덱스를 이용하여 빠르게 조회할 수 있다.
> zrange birthyear 2 3
2) "WILLIAM"
3) "BENTLEY"Redis key
어떻게 생성하는가?
보통 ‘user:1000’처럼 object-type:id의 형태를 권장함
‘comment:reply.to’ 또는 ‘comment:reply-to’ 와 같이 . - : 등의 부호를 사용해서 관계를 나타냄
배치 돌려보면 console에 이렇게 찍힘

다음과 같이 키가 생성되는 것을 확인할 수 있음
