
0. 판별 분석 (Discriminant Analysis)
-
집단에 대한 정보로부터 집단을 구별할 수 있는 판별함수(discriminant function) 또는 판별규칙(discriminant rule)을 만들고, 새로운 개체에 대해 어느 집단에 속하는지를 판별하여 분류하는 다변량 기법
-
정량적 자료로 측정된 독립 변수들을 이용하여 명목 자료인 종속변수의 집단 구분을 예측하는데 이용
= 은행에서 대출 기업의 부채 상태, 재산 상태, 영업 실적을 이용하여 대출이 가능한 기업과 불가능한 기업으로 나누는 것을 판별 분석의 예시라고 할 수 있다.
0.1 판별 분석의 종류
- 판별 분석 : 종속변수의 집단 수가 2개
- 다중 판별 분석 : 종속변수의 집단 수가 3개 이상
- 선형판별분석(LDA) : 정규분포의 분산-공분산이 범주에 관계없이 동일
- 이차판별분석(QDA) : 정규분포의 분산-공분산이 범주별로 다름
0.2 판별 분석의 특징
- 연속형 독립 변수와 범주형 종속 변수를 사용
- 이상치에 매우 민감하다는 특징
- 가장 작은 그룹의 크기는 예측 변수의 수보다 커야한다
0.3 분류(Classification) 분석과의 차이점
판별 분석은 분류 모형의 한 종류이지만 다른 점이 있다.
- 분류 : 자료를 보기 전까지는 대상이 몇 개의 그룹으로 나누어 지는지 모름
- 판별 : 존재하는 그룹의 수를 알고 있고, 새로운 대상이 어느 그룹에 속하는지 결정
1. 선형 판별 분석 (LDA)이란?
- 데이터 분포를 학습해 결정 경계를 만들어 데이터를 분류(Classification)하는 지도학습 모델
- 데이터를 저차원의 공간으로 사영해 차원을 축소하고 사영된 데이터들이 잘 분류되는가를 판단
- Fisher가 만들어서 FDA (Fisher Discriminant Analysis)라고도 부른다.
💡 LDA는 판별 + 차원 축소의 기능을 한다!
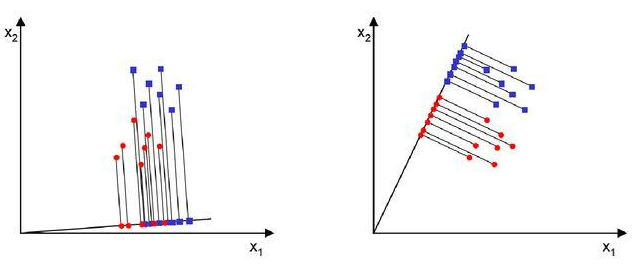
Q. 파란색과 빨간색을 서로 다른 집단으로 분류할 때, 왼쪽 축과 오른쪽 축 중에 어떤 것이 더 분류가 잘 되었다고 판단할 수 있을까?
A. LDA는 위 그림에서 오른쪽과 같이 분류해주는 기법이다.
왼쪽은 축으로 데이터 포인트들을 사영했을 때 서로 겹치는 부분이 있는 반면, 오른쪽은 축으로 사영했을 때 빨간색과 파란색이 명확히 분류되었다.
2. LDA의 원리
2.1 가정
- 각 클래스는 정규분포 형태를 가진다
- 각 클래스는 비슷한 형태의 공분산 구조를 가진다
✅ 공분산이란? 2개의 확률변수의 상관 정도를 나타내는 값각 클래스 모두가 아래의 3가지 형태 중 1가지 형태를 가져야 함
1. 완전 공분산 정규분포
2. 대각 공분산 정규분포
3. 구형 공분산 정규분포
2.2 어떤 직선을 찾는가?
💡 데이터를 특정 한 축에 사영한 후, 두 범주를 잘 구분할 수 있는 직선을 찾는 것이 LDA의 목적!
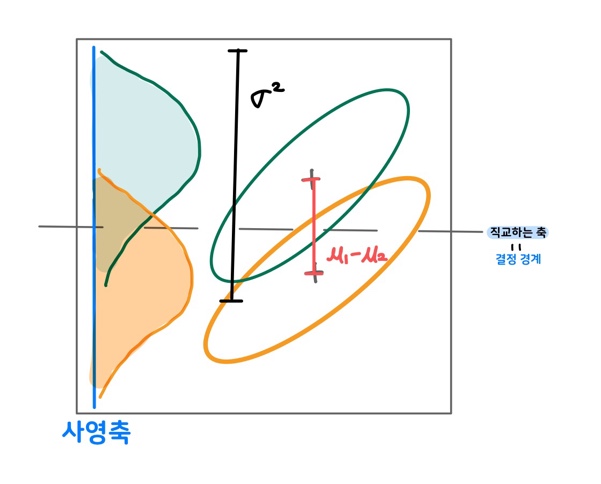
2.2.1 LDA의 결정 경계
위 그림에서 사영축(파란선)에 직교하는 축(점선)
사영한 두 분포가 만족해야 하는 것?
- 각 클래스의 평균의 차이가 큰 지점을 결정 경계로 지정
👉 빨간선 ()이 길어야 함 - 각 클래스 내의 분산이 작은 지점을 결정 경계로 지정
👉 검정선()이 짧아야 함
💡 두 분포가 겹치는 영역이 작은 지점을 경계로 지정해야한다!
벡터 개념으로 적용해보자!
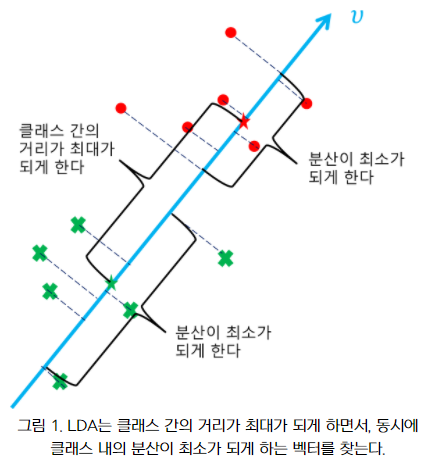
-
클래스 간 거리가 최대가 되게 하는 벡터
= 클래스 간 분산이 최대가 되게 하는 벡터
👉 각 집단의 중심(평균)이 서로 멀어지도록 분류 -
클래스 내의 분산이 최소가 되게 하는 벡터
= 데이터 포인트들을 사영시켰을 때 클래스 내의 사영들의 분산이 최소가 되게 하는 벡터
👉 하나의 집단 내의 데이터들은 잘 모여있다
즉, LDA는 특성 공간 상에서 클래스 분리를 최대화하는 축을 찾기 위해 클래스간 분산과 클래스 내부 분산의 비율을 최대화 하는 방향으로 차원을 축소한다.
3. PCA와의 차이점

-
PCA는 데이터들을 어떠한 벡터로 사영시켰을 때, 분산이 큰 벡터(축)를 찾는게 목표이다. 사영들의 분산이 적게 만드는 벡터들은 제거해줌으로 데이터의 차원을 감소시킨다.
-
LDA는 데이터의 타겟 값 클래스끼리 최대한 분리할 수 있는 축을 찾는다. 데이터를 하나의 선으로 사영시키고 데이터들이 어떤 클래스에 속하는지 알아야한다는 특징이 있다.
4. LDA의 특징
4.1 장점
- 변수 간 공분산 구조를 반영
- 공분산 구조가 가정에 위반되더라도 비교적 잘 작동
4.2 단점
- 정규분포에 크게 벗어나는 경우 잘 작동하지 못함
- 범주사이의 공분산 구조가 많이 다른 경우를 반영하지 못함
👉 이차 판별 분석(QDA)로 문제 해결 가능
5. Python 구현
iris 데이터셋을 이용하여 수치형 독립변수 4개 (꽃받침의 길이/너비, 꽃잎의 길이/너비)를 이용하여 아이리스의 종류를 예측 및 판별해보자.
✍ 입력
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
#붓꽃 데이터 로드
iris = load_iris()
#데이터 정규 스케일링
iris_scaled = StandardScaler().fit_transform(iris.data)
print(iris_scaled)
#LDA 생성 (n_components는 차원을 지정하는 파라미터)
lda = LinearDiscriminantAnalysis(n_components=2)
#fit()호출, 타겟값 입력
lda.fit(iris_scaled, iris.target)
iris_lda = lda.transform(iris_scaled)
print(iris_lda)
lda_columns = ['lda_component_1','lda_component_2']
irisDF_lda = pd.DataFrame(iris_lda,columns=lda_columns)
irisDF_lda['target'] = iris.target
print(iris_lda)
#setosa : 세모 , versicolor :네모, virginica : 동그라미
markers = ['^','s','o']
#시각화
for i,marker in enumerate(markers):
x_axis_data = irisDF_lda[irisDF_lda['target']==i]['lda_component_1']
y_axis_data = irisDF_lda[irisDF_lda['target']==i]['lda_component_2']
plt.scatter(x_axis_data, y_axis_data, marker=marker,label=iris.target_names[i])
plt.legend(loc='upper right')
plt.xlabel('lda_component_1')
plt.ylabel('lda_component_2')
plt.show()💻 출력

선형 판별 분석을 이용해 변수가 4개인 4차원 공간의 iris 데이터셋을 2차원으로 축소시켜 판별해본 결과, setosa와 versicolor + virginica로 분류된 걸 확인할 수 있다.
